1. Introduction
Tailing ponds are the primary facilities at mineral processing plants in mining enterprises and are typically situated at valley mouths or on flat terrain. These storage areas are surrounded by dams and are used to retain wastewater and slag generated from mining and ore processing [
1]. Beyond occupying large land areas, tailings ponds contain various types of heavy metals and pollutants that severely impact the ecological environment of mining regions. Scholars have conducted research on the hazards of tailings ponds, such as Tomás Martín-Crespo et al., who used LiDAR and geochemical methods to quantify pollutants in mine ponds in order to analyze the pollutant composition in tailings ponds [
2]. Therefore, tailings ponds are a potentially high source of environmental risk and can cause severe damage to the surrounding environment in the event of an accident [
3]. Environmental incidents linked to tailings ponds have become increasingly common in recent years [
3], causing numerous casualties and significant ecological damage. Therefore, to strengthen emergency management and achieve information security and disaster warning for tailings ponds, there is an urgent need for a fast, accurate, and comprehensive method for identifying tailings pond locations.
The location of tailings ponds is often remote [
4], and the transportation infrastructure is typically underdeveloped; therefore, traditional methods for identifying tailings ponds are predominantly based on ground surveys [
5], which are inefficient, labor-intensive, and unable to monitor the extent of tailings ponds in real time. However, remote sensing (RS) technology is a crucial means of data acquisition [
6], offering advantages such as rapid, large-scale, and real-time identification and minimal dependence on ground conditions; thus, it can compensate for the shortcomings of traditional identification methods. For example, Zhao [
7] applied RS identification to a Taishan tailings pond in Shanxi, where a large area of tailings ponds was monitored over a short period of time using 3S (geographic information system, RS, and global navigation satellite system) technology to extract information on the number of tailings ponds, their area, and the type of minerals present.
Lu [
8] used tailing ponds in Hebei Province as an example to identify tailing ponds via RS. He proposed a basic RS identification process for these ponds. Owing to the significant differences in the scale, shape, and background of the tailings ponds in the RS images, it is necessary to identify them individually through visual interpretation. However, visual interpretation has several drawbacks [
9], including high subjectivity, significant workload, and low efficiency when managing significant volumes of RS data. This makes it unsuitable for current environmental protection departments to rapidly obtain real-time positioning information for tailing ponds. Therefore, traditional RS technology cannot meet the current demands for large-scale and high-frequency data processing [
10].
RS feature recognition has progressed significantly with rapid advancements in computer vision and deep learning. Owing to its powerful feature extraction and pattern recognition capabilities, deep learning has been widely applied for tailing pond identification, making it a popular research focus. Currently, two main methods are commonly used to identify tailings ponds in RS images. The first is target detection [
11], which is a technique aimed at identifying the target of interest in an image and determining its location. In recent years, deep learning-based target detection algorithms, such as Faster Region-based Convolutional Neural Network (R-CNN) [
12], You Only Look Once [
13], and Single Shot MultiBox Detector (SSD) [
14], have performed well in tailings pond detection. For example, Li et al. [
15] developed an SSD-based fine-tuning model that extracted and analyzed data from 2221 tailings ponds in the Beijing–Tianjin–Hebei region of northern China. Their results demonstrated that deep learning methods are highly effective for detecting complex feature types in RS images. Yan et al. [
16] used the Faster R-CNN model and added the feature pyramid network [
17] to monitor tailings ponds in high-resolution RS images. The results showed that the method improved both the average precision and recall rate, making it highly significant for the large-scale, high precision, and intelligent identification of tailings ponds. These methods automatically learn the features of tailings ponds through Convolutional Neural Networks [
18] and rapidly locate their positions in high-resolution RS images. The advantage of the target detection method lies in its ability to simultaneously identify multiple tailings ponds and provide their precise bounding boxes in the image. However, the target detection cannot accurately segment the feature types and boundaries of each pixel.
The second method is semantic segmentation, which involves classifying each pixel in a remotely sensed image to determine whether it belongs to a tailing pond, thereby enabling tailings pond recognition. Semantic segmentation models, such as U-Net [
19], PSP-Net [
20], and DeepLabv3+ [
21], achieve precise segmentation of tailings pond areas in RS images. For example, Zhang et al. [
17] used the U-Net model and Gauge-Fractional-6 (GF-6) RS images with a spatial resolution of 2 m and achieved effective tailings pond extraction, surpassing the accuracy of conventional machine learning models. This approach not only identifies the overall shape of the tailings impoundment but also captures detailed features of the complex terrain, providing a more comprehensive way to monitor the condition of tailings ponds. The DeepLabv3+ model enhances DeepLabv3 by incorporating a simple yet powerful decoder module, which improves the segmentation accuracy, particularly around the target boundaries.
Due to the complexity of the feature types in the distribution area of the tailings pond, more attention should be paid to the local segmentation effect of the high-resolution image. Additionally, it has been demonstrated that using the DeepLabv3+ model for semantic segmentation in complex scenes yields good results. For example, Chen et al. [
22] proposed an improved DeepLabv3+ lightweight neural network to improve the semantic segmentation accuracy of RS images in complex scenes. They achieved this by adding a ResNet50 [
23] residual network after the feature fusion of DeepLabv3+, along with a normalization-based attention module [
24], to enhance shallow semantic information. Thus, the local segmentation effect was improved, and it performed well in both small- and multi-target segmentations. The above-improved method based on Deeplabv3+ has added a decoder module and a more effective feature fusion method than DeepLabv3, which can better deal with the complex background in the identification of tailing ponds and make it a significant advantage in terms of accuracy and practical application. However, there are few open-source semantic segmentation datasets for tailings ponds, making this area of research less explored.
This changed when Zhang et al. [
25] developed the TPSet semantic segmentation dataset for tailings ponds by visually interpreting GF-6 panchromatic multispectral scanner (PMS) images. The training and validation sets of the TPSet dataset consist of 1389 images, each with corresponding binary mask files, all with a size of 512 × 512 pixels. The test set contains 3564 images and corresponding binary mask files, each with a size of 512 × 512 pixels, completing the missing dataset.
However, in the semantic segmentation of remotely sensed images, the images contain rich details of ground objects, such as shape, location, and texture features [
26]. These details provide an image with high intra-class variance and low inter-class variance, which increases the difficulty of segmentation. To solve this problem, effective access to contextual information is needed for complex scenes. Zhao et al. [
27] combined an attention mechanism with a multi-scale module to improve the annotation accuracy of high-resolution aerial images.
Based on the above research issues and drawing inspiration from the studies of Zhao et al. [
27], we made the following two improvements in this study: We incorporated the Squeeze-and-Excitation (SE) module proposed by Hu et al. [
28] into the encoder of the DeepLabv3+ framework to enhance the representational capabilities of the model. The SENet module aims to improve the quality of the learned features by modeling the interdependencies between the convolutional feature channels. The improved ResNeSt module proposed by Zhang et al. [
29] was introduced into the encoder. Based on the special needs of the tailing pond recognition task: complex texture, multi-scale features, and high intra-class variance in high-resolution images, the SENet and ResNeSt modules are able to better capture and integrate the detailed information in tailing ponds by means of channel attention and multi-scale feature fusion, thus improving the segmentation accuracy and model robustness. ResNeSt is an improved version of ResNet [
30] that aims to enhance the feature representation capability of a network, particularly in processing complex feature representations, particularly when addressing complex visual tasks. It more efficiently extracts and fuses channel and spatial features by introducing Split-Attention blocks, a mechanism that enables the model to better capture both the global and local features of an image [
31], especially in tasks that require fine-grained details, such as semantic segmentation. The SENet and ResNeSt modules were integrated into the encoder to realize multi-scale module fusion, which effectively addressed the challenges of significant intra-class variability and minimal inter-class distinction present in high-resolution RS imagery. The integration of the SENet and ResNeSt modules into the DeepLabv3+ encoder not only addresses the challenges of high-resolution remote sensing image segmentation but also introduces a novel multi-scale attention fusion strategy that dynamically combines channel attention and Split-Attention mechanisms to enhance the model’s ability to capture fine-grained details and improve overall segmentation performance.
2. Materials and Methods
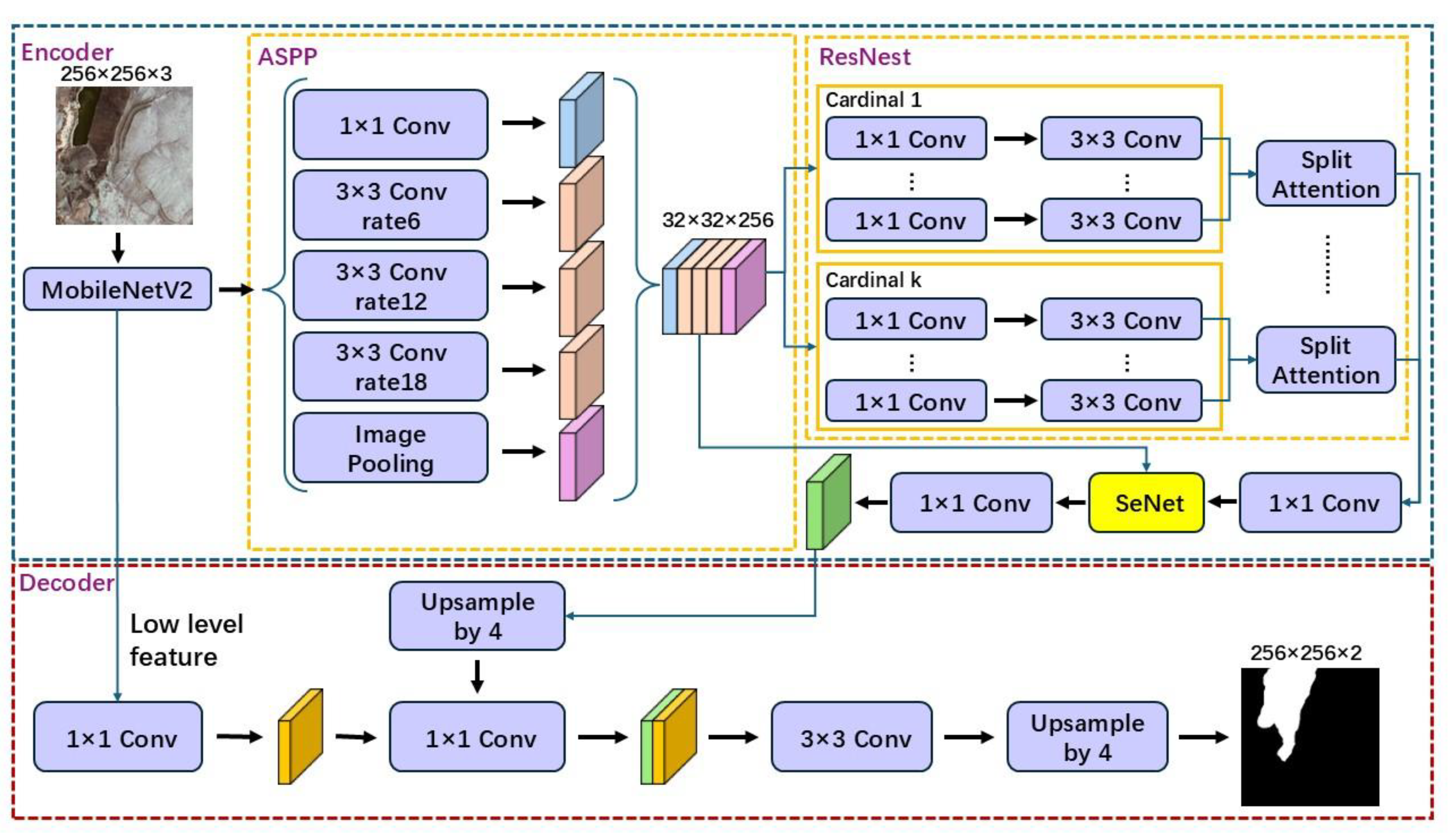
The proposed semantic segmentation network (RST-DeepLabv3+) is composed primarily of a construction module (encoder) and an enhancement module (decoder). Within the encoder, the Atrous Spatial Pyramid Pooling (ASPP) module was used to capture high-level features that included multi-scale information. The SENet and ResNeSt modules were introduced, and in the encoder, a multi-scale attention module was introduced to facilitate the dynamic merging of multi-scale feature maps.
Figure 1 illustrates the architecture of the proposed RST-DeepLabv3+ model. The model uses a single tailings pond image as the input, with an image size of 256 × 256 pixels, and outputs a binary segmented image of the tailings pond, followed by a brief description of the ASPP module. The attention modules, SENet and ResNeSt, are described in detail.
2.1. Encoder Backbone Using MobileNetv2
In this study, we used MobileNetV2 [
32] as the backbone of the encoder. The architecture of MobileNetV2 is based on depth-separable convolution, which primarily consists of channel-by-channel convolution and 1 × 1 convolutions; this design not only reduces computational complexity but also improves feature extraction efficiency. MobileNetV2 introduces inverted residuals and linear bottlenecks [
33], which are designed to efficiently extract features while maintaining computational efficiency. This efficient feature extraction capability helps preserve high spatial resolution while reducing sampling operations, thereby alleviating the loss of location information caused by multiple downsampling in traditional networks. MobileNetV2 is designed as a lightweight architecture that uses depth-wise separable convolutions, which significantly reduces the number of parameters and calculations.
2.2. Atrous Spatial Pyramid Pooling Module
The ASPP module can efficiently classify objects of different size ranges by extracting and combining multi-scale features [
34]. The module employs one 1 × 1 × 256 convolutional kernel and three 3 × 3 × 256 convolutional kernels (with dilation rates of 6, 12, and 18, respectively) to capture multi-scale feature information. Moreover, the ASPP module captures global image-level features through global average pooling, which helps address the problem of disappearing weights when using expanded convolutional kernels. In addition, null convolution can arbitrarily expand the sensory field without introducing additional parameters. The ASPP module up-samples the global feature map to the desired spatial dimensions [
35] by concatenating the extracted features through a 1 × 1 × 256 convolution. Finally, the number of channels in the feature map is compressed to 256 using a 1 × 1 × 256 convolution. Overall, the ASPP module captures features with different receptive fields using hollow convolutions with varying expansion rates, obtains global information through global pooling and 1 × 1 convolution, and enhances the expressive capacity of the model by stacking and fusing these features.
2.3. Encoder with the SENet Module
In this study, we incorporated the SE [
28] module, proposed by Hu et al., into the encoder of the DeepLabv3+ framework to enhance feature discrimination, specifically targeting the challenge of high intra-class variance in RS images with high resolution. The SE module improves the quality of the learned features by modeling channel interdependencies and recalibrating feature responses, thereby helping the network focus on essential information within the same class. This recalibration is achieved through two key operations: squeeze-and-excitation.
The SENet module is mainly divided into two components: squeeze-and-excitation, as well as scale. In the squeeze operation,
Fsq applies global average pooling across channels, reducing the
×
×
feature map with a global context into a 1 × 1 ×
vector. This is performed to transform each two-dimensional channel into a numerical value that captures the global sensing characteristics. In this case, each pixel represents a single channel, shielding the spatial distribution information and better utilizing the correlation between the channels. The formula used is as follows:
Fsq represents the excitation component. This function relies on the correlations between feature channels, assigning each channel a weight to indicate its relative importance. Feature vectors with different shades of color, that is, different degrees of importance, are obtained from the features of the
channels that were originally white. The formula is as follows:
S The weights of the excitation output were regarded as the importance of each feature channel. This is because for all values of
×
at each position of
U, the weights of the corresponding channels are multiplied by the values in question to complete the recalibration of the original features. The formula is as follows:
As illustrated in
Figure 2, the squeeze operation aggregates feature maps across spatial dimensions, thereby creating a compact channel descriptor using global average pooling. This step enables the network to effectively leverage the global context, which is critical for reducing intra-class variability by capturing global information from the lower layers. The excitation operation follows, in which two fully connected layers with nonlinearity, followed by sigmoid activation, generate a set of adaptive scaling factors for each channel. These factors allow the model to emphasize class-consistent features while suppressing less relevant variations, thereby mitigating intra-class variance. By integrating the SE module into DeepLabv3+, the model became more adept at capturing fine-grained details while maintaining robust class consistency.
2.4. Encoder with the ResNeSt Module
The DeepLabv3+ encoder incorporates the ResNeSt module, which employs a “split-attention” mechanism to address high intra-class variance and low inter-class variance, which are prevalent in RS images with high resolution. As illustrated in
Figure 3, ResNeSt utilizes a novel “split-attention” mechanism that applies channel attention across multiple branches of the network. This mechanism enables features from different branches to interact, allowing the model to adaptively select important features and enhance the perception of targets at different scales. The architecture of ResNeSt enables the model to capture complex cross-feature interactions and learn diverse representations from various feature subspaces, which is crucial for reducing intra-class variance by isolating subtle class-specific features.
Split-attention represents a key component of ResNeSt, whereby the adaptive fusion of features is achieved by partitioning the feature map into multiple branches within the residual block, followed by the application of an attention mechanism to these branches. This module enhances the performance of the model in multi-scale scenes. The primary processes are as follows:
Feature segmentation entails partitioning the input feature map into multiple sub-feature maps, which are then convolved across different branches. The formula is as follows:
where
Xs denotes the characteristics of the s-the branch and
αs is a weighting factor computed through the attention mechanism.
The computation of attention involves summarizing the features of each branch and then obtaining global information through a global pooling (squeezing) operation. This information is then sent to a series of fully connected layers, from which the attention weights for each branch are computed. The input feature maps in
Figure 3 were subjected to attention computation after excitation and weighted superposition; therefore, the final output was not consistent with the color depth of the input feature maps. The formula is as follows:
where
z is the feature vector obtained through global pooling,
W1 and
W2 are two fully connected layers,
δ represents the activation function, and
α denotes the attention weights.
The reweighting of features entails weighting and summing the features of each branch in accordance with the attention weights, thereby facilitating adaptive fusion of the features. ResNeSt splits an input into multiple lower-dimensional embeddings, processes them using different sets of convolutional filters, and merges the results. This enables the model to emphasize inter-class distinctions by capturing different aspects of the input data, thereby enhancing the separability between classes. The integration of ResNeSt not only improves the model’s ability to capture inter-class differences but also enhances the network’s computational efficiency, contributing to more accurate and efficient fine-grained segmentation.
2.5. Decoder
The encoder outputs a high-level semantic feature map, and the acquired deep and shallow semantic features are passed to the decoder [
36]. The deep semantic features enter the decoder after up-sampling, while the results of the shallow subsemantic feature map, following a 1 × 1 convolution, are stacked sequentially. To complete the feature fusion, a 3 × 3 convolution is then employed for feature extraction. Finally, the output image is resized through up-sampling to match the dimensions of the input image. At this point, the output image represents the species to which each pixel in the input image belongs.
2.6. Loss Function
Due to the small sample size of the tailings pond and the sample imbalance problem, the loss function selects the focal loss:
Focal loss [
37] prompts the model to prioritize hard-to-classify samples (tailings reservoirs) during training by incorporating an adjustable factor.
assigns less weight to samples that are easily categorizable and more weight to those that are challenging to categorize, thereby reducing the impact of category imbalance on model training. The formula for the focal loss is as follows:
where
is the model’s probability of predicting the correct category,
is the category weight used to balance the impact of different categories, and
γ is a moderator used to control the model’s focus on difficult and easy samples. Using focal loss, this experiment effectively alleviates the sample imbalance problem pertaining to the relatively low number of pixels in the tailings ponds, thereby enhancing the ability of the model to recognize a few classes.
2.7. Evaluation Metrics
To evaluate the model performance, a test set was used for precise performance assessment. This study employed five main evaluation metrics: precision, recall,
, IoU, and mPA. Precision indicates the fraction of correctly predicted positive instances among all positive predictions made by the model. It is a critical metric when minimizing false positives is important, as it highlights the model’s ability to avoid classifying non-tailings pond areas as tailings ponds.
measures the fraction of actual positive cases in the dataset that are correctly identified by the model. It indicates how well the model can detect all tailings pond regions, including harder-to-identify areas. The F1 score is calculated as the harmonic means of precision and recall, balancing both to provide a single metric that represents the trade-off between them. IoU (Intersection over Union) measures the extent to which the segmented region predicted by the model overlaps with the true labeled region. IoU improvements reduce false positives and enhance boundary accuracy, helping to avoid unnecessary resource allocation and monitoring of only the relevant areas. The mPA (Mean Pixel Accuracy) is a measure of the accuracy of the classification of each category of pixels and can reflect how well the model classifies each category over the entire image. The mPA enhancement helps to minimize confusion between the tailings ponds and the background and ensures that the tailings ponds can be accurately identified in large-area monitoring. This is especially useful in this scenario, where a balance between identifying tailings ponds (high recall) and avoiding false alarms (high precision) is crucial.
In this context, TP represents the number of pixels correctly predicted as tailings ponds, FN refers to the number of tailings pond pixels misclassified as background pixels, and FP denotes the number of background pixels incorrectly predicted as tailings ponds.
In addition, more comprehensive evaluation metrics include the Intersection over Union (IoU) [
38] and mean pixel Accuracy (
mPA). IoU refers to the fraction of correctly predicted pixels with respect to the actual pixels in the merged set, while
mPA aims to calculate the proportion of correctly categorized pixels within each class. The formulas for IoU and
mPA are as follows:
When there are K classes, the current task involves only two classes: tailings ponds (class 1) and background.
5. Discussion
The proposed model for tailings pond identification, based on an enhanced DeepLabv3+ architecture, demonstrates improvements in both extraction accuracy and robustness compared to those of traditional models. By integrating the ResNeSt and SENet modules, the model captures more nuanced multi-scale features and addresses key challenges in tailings pond identification, including diverse textures, complex environmental conditions, and high intra-class variance and low inter-class variance in high-resolution tailings ponds remote sensing imagery due to mixing of constituents within the tailings ponds.
One notable advantage of our approach is its ability to perform fine-grained segmentation, which is particularly useful for identifying small, irregularly shaped tailings ponds. Traditional methods, such as image processing techniques, are often prone to noise and may miss subtle features owing to variations in lighting and texture. Compared with the extraction of tailing ponds using SC-SS(Spectral–Spatial Masked Transformer With Supervised and Contrastive) [
40], RST-DeepLabv3+ pays more attention to the special target of tailing ponds in the segmentation process by introducing the SENet module and ResNeSt module. Tailings ponds are usually composed of tailings residues and wastewater, and their colors and textures, as shown in
Figure 3; the segmentation attention mechanism res are extremely similar to objects such as water bodies, vegetation, and clouds, and this similarity often leads to misidentification in traditional methods. Our improved model can effectively alleviate this problem and improve segmentation accuracy. However, with the addition of the SENet and ResNeSt modules, the computational complexity of the model may increase. The computational efficiency is lower than that of the original DeepLabv3+. As shown in
Figure 6 and
Figure 7, this resulted in more accurate predictions, especially in complex scenes where tailings ponds may be visually similar to other elements, such as water bodies, vegetation, or shadows. The efficacy of the model in multi-scale scenarios is notably enhanced by the incorporation of the SENet and ResNeSt modules. SENet’s squeezing and excitation mechanism facilitates the network’s adept utilization of global context information, while ResNeSt attains adaptive fusion of features by segmenting the feature map into multiple residual blocks and implementing the attention mechanism on these branches through the segmentation attention mechanism. This enhancement not only mitigates false positives but also substantially improves segmentation in challenging categories. This finding aligns with the observations reported in other studies, such as the enhanced performance of SSAtNet [
21] in distinguishing between buildings and trees. However, misidentification is minimal, primarily because of the inherent similarities between tailings ponds and other natural elements.
The effectiveness of integrating attention modules is consistent with findings from other semantic segmentation studies [
41]. Observing
Figure 6,
Figure 7,
Figure 8 and
Figure 9, we find that even the improved RST-DeepLabv3+ method still differs from the ground truth, and we speculate that it may be due to the fact that the dataset has only three bands of RGB, and some detailed information is more sensitive to other multispectral bands. We may need to add multispectral data and other sensor data to solve this problem.
However, the current model has limitations, particularly in scenarios where the dataset lacks diversity in RS imagery [
42]. In this paper, only RGB images are used for image recognition, and no other spectral bands are fused, and the model may miss texture information that is more sensitive to multiple spectra. Similar to previous studies, where the generalizability of the model was limited by the size and variety of the dataset, expanding the range of images to include different sensors (such as synthetic aperture radar and light detection and ranging) and varying temporal conditions (such as seasonal variations) will further enhance the robustness and applicability of the model. Because the ground truth of the NX-TPSet dataset is subjectively labeled, there is a subjective error in the accuracy of the image of the real tailings pond identification. In addition, future research should explore the classification of tailings ponds based on their operational status, such as active or inactive, which could provide more targeted identification strategies. The status of tailings ponds may change over time as a result of changes in mining activities, environmental conditions, and waste accumulation. Temporal monitoring can be integrated into the proposed method, and we can introduce time series remote sensing data into the model in order to realize the continuous monitoring of tailing ponds. Due to the relatively decentralized distribution of tailings ponds, the number of realistic small- and medium-sized tailings ponds is still large. Therefore, when using high-resolution images to identify small tailings ponds, the sample imbalance problem can lead to low detection accuracy. Therefore, with the increasing popularity of drones, a combination of drone data and high-resolution images can be explored. UAV data can be used to identify small- and medium-sized tailings ponds, thereby improving the detection accuracy. Therefore, with the popularity of UAVs, UAV data can be combined with high-resolution images [
43], and UAV data can be used to identify small- and medium-sized tailing ponds, thus improving recognition accuracy [
44]. The method still needs to be tested in real scenarios and improved to meet the real-time monitoring requirements of tailings ponds in large scenarios.
The segmentation outputs can be used to track changes in the surface area or volume of the tailings pond over time, thereby providing valuable data for capacity monitoring. As tailings accumulate, the pond capacity can change, and precise segmentation can help calculate the remaining storage capacity.
6. Conclusions
In this study, we present an enhanced DeepLabv3+ model for the detection and segmentation of tailings ponds. By incorporating multi-scale attention modules—ResNeSt and SENet—into the encoder of the DeepLabv3+ model, our approach effectively captures and integrates multi-scale features for more accurate segmentation, particularly along the complex and often irregular boundaries of tailings ponds. As shown in
Figure 3, the segmentation attention mechanism in ResNeSt enhances the perception of targets at different scales as a way to capture complex cross-feature interactions and learn different representations from different feature subspaces. The problem of high within-class variance and low between-class variance in the identification of tailings ponds is solved. The proposed model consistently exhibited excellent performance in comprehensive experiments on both the self-built NX-TPSet dataset, which was developed specifically for this study, and the publicly available TPSet dataset, which contained 500 pairs of samples, to provide a foundation for testing the generalizability and validity of the model. The TPSet dataset, which serves as a public benchmark, further validates the ability of the model to detect tailings ponds in various environments.
The experimental results demonstrated a recall of 92.2% and an IOU extraction accuracy of 86.35% for the RST-DeepLabv3+ model, which is an improvement of 1.11% in recall and 1.19% in IOU extraction accuracy compared to those of the DeepLabv3+ model. The augmented model exhibits robust capability in distinguishing tailings ponds from similar objects, such as water bodies, vegetation, and other landscape features.
The proposed model not only advances the development of tailings pond identification techniques but also provides a solution for the dynamic identification of tailings ponds. This study enhances tailings pond identification through the RST-DeepLabv3+ model, which improves disaster prevention by accurately monitoring tailings pond boundaries and enabling early warning systems for potential risks, thereby contributing to environmental protection.
Future research should explore multimodal and dynamic monitoring by combining InSAR or UAV data with semantic segmentation techniques to improve the accuracy and adaptability of tailings pond monitoring. This method should be actively used in regulatory and industrial settings to enable real-time monitoring of tailings ponds to prevent potential disasters.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}