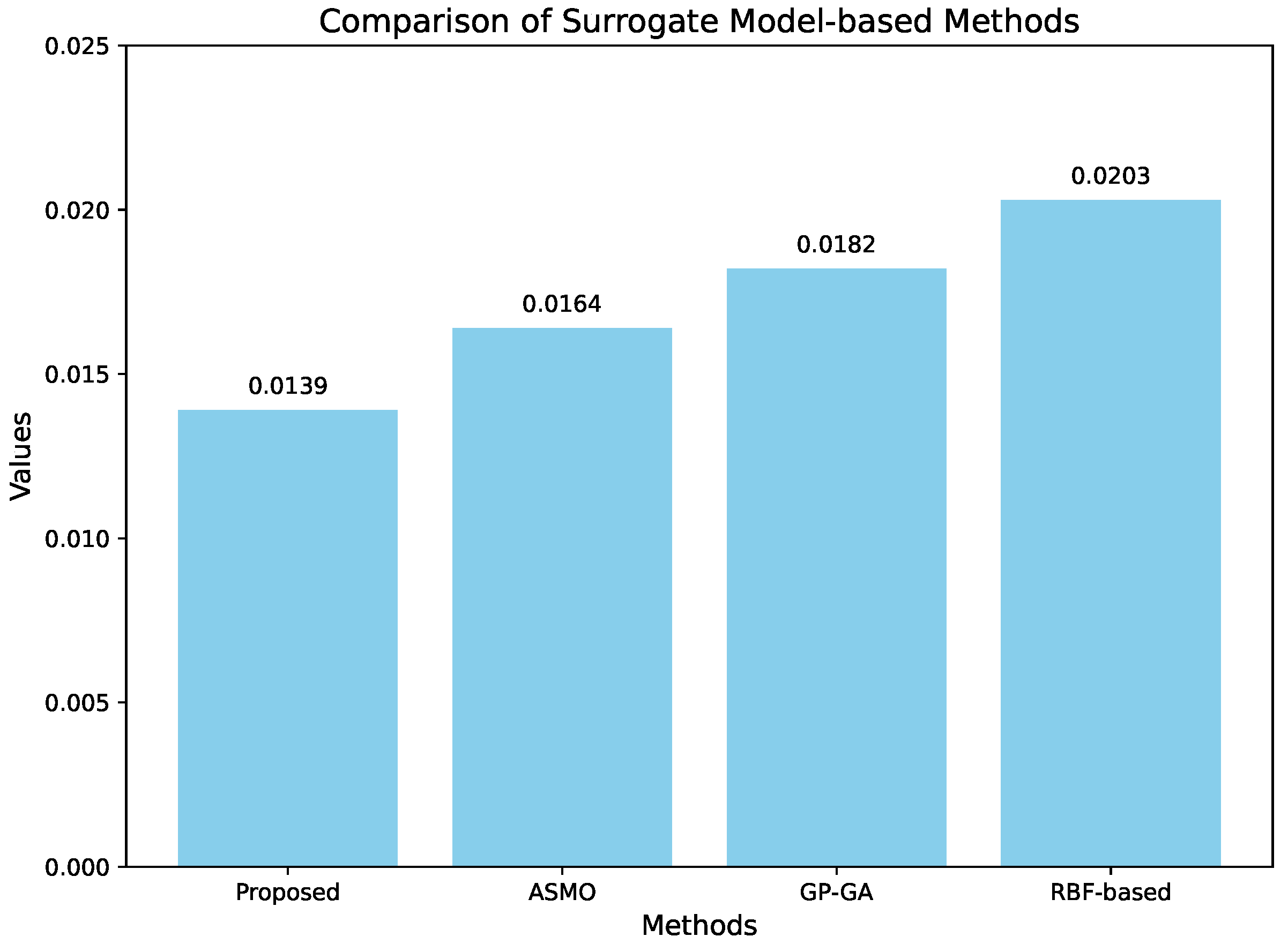
3.1. The Limitations of Global Optimization
The global-based tuning results and default parameter simulation results are shown in
Figures S1 and S2. In comparing these figures, it can be seen that the global-based tuning result is not significant. There are slight positive changes in the outcomes only in certain regions of East Asia, the Indian Ocean, and the Pacific. As mentioned earlier, CAM5 is a well-tuned model, and the results based on global tuning are not significant. However, this tuning method struggles to eliminate errors in simulated results in some regions caused by default parameters. Therefore, we need to explore other feasible ways and determine the most suitable parameter optimization use scenario for the surrogate model-based tuning method.
To give full play to the best performance of the surrogate model, we researched the relationship between the parameter change and result change in CAM5 precipitation, explore the influence of a single parameter disturbance on the result, and compare it with the default precipitation value; thus, the influence mode and intensity of parameter changes in global precipitation are obtained. Using the samples generated in
Section 2.4.1, we first calculate the difference between the disturbance value and the default value of 60 groups of single-parameter samples. Then, a short-term hindcast named the cloud-associated parameterizations Trestbed (CAPT) [
53] with an interval day 3 hindcast, as proposed by [
15], was simulated 60 times to obtain the precipitation value corresponding to the disturbance parameters and to calculate the difference with the default precipitation value. Pearson correlation analysis was carried out between them to calculate the symbolic consistency of the two groups of differences to determine the impact of the same parameter value on different regions. In taking rhminl as an example, the results are shown in
Figure 8. The impact of parameter changes on the world is different. There is a strong negative correlation in marine regions, such as the South and North Pacific, the Indian Ocean, and the Atlantic, while there is a positive correlation on land, mainly concentrated in Eurasia, South America, Central Africa, and other regions. This means that when the rhminl value is disturbed relative to the default value, the change in precipitation in some regions may be completely opposite, similar to a “rocker” effect. In such a situation, it is difficult to use one parameter value to optimize global change, and the increase in parameter numbers will further enhance this rocker effect, making the mapping between parameters and precipitation complicated. To some extent, the surrogate model has difficulty approximating this complex change through a limited number of samples and iterations, which will greatly reduce the surrogate model’s optimization performance.
The influence of the parameters on different regions and the simulation results of each region are considered. We chose region-based optimization, abided by the parameter disturbance characteristics of the model, and gave full play to the performance advantages of the surrogate model as much as possible.
3.2. Region-Based Optimization Result
Based on
Section 3.1, because of the “rocker” effect in CAM5, the optimization result of the region may be inconsistent with the global optimization result. Therefore, region-based optimization is more suitable than global optimization. In considering the global precipitation distribution, six regions were selected in this study, as shown in
Table 2. They were WarmPool, South Pacific, Nino, South America, South Asia, and East Asia. We constructed a top surrogate model and a bottom surrogate model for each selected region, and each region was tuned using the methods proposed in
Section 2. The RMSE of each region was calculated according to the range shown in
Table 2 in the corresponding optimization process, and each region was optimized separately. The region optimization result is shown in
Table 4. The results show that after the top-level optimization step, each region has different degrees of improvement compared with the default experiment. The simulation result in each region advanced after the bottom-level optimization step, and the results of South Pacific, East Asia, Nino, and South Asia are notably improved. We will discuss these results.
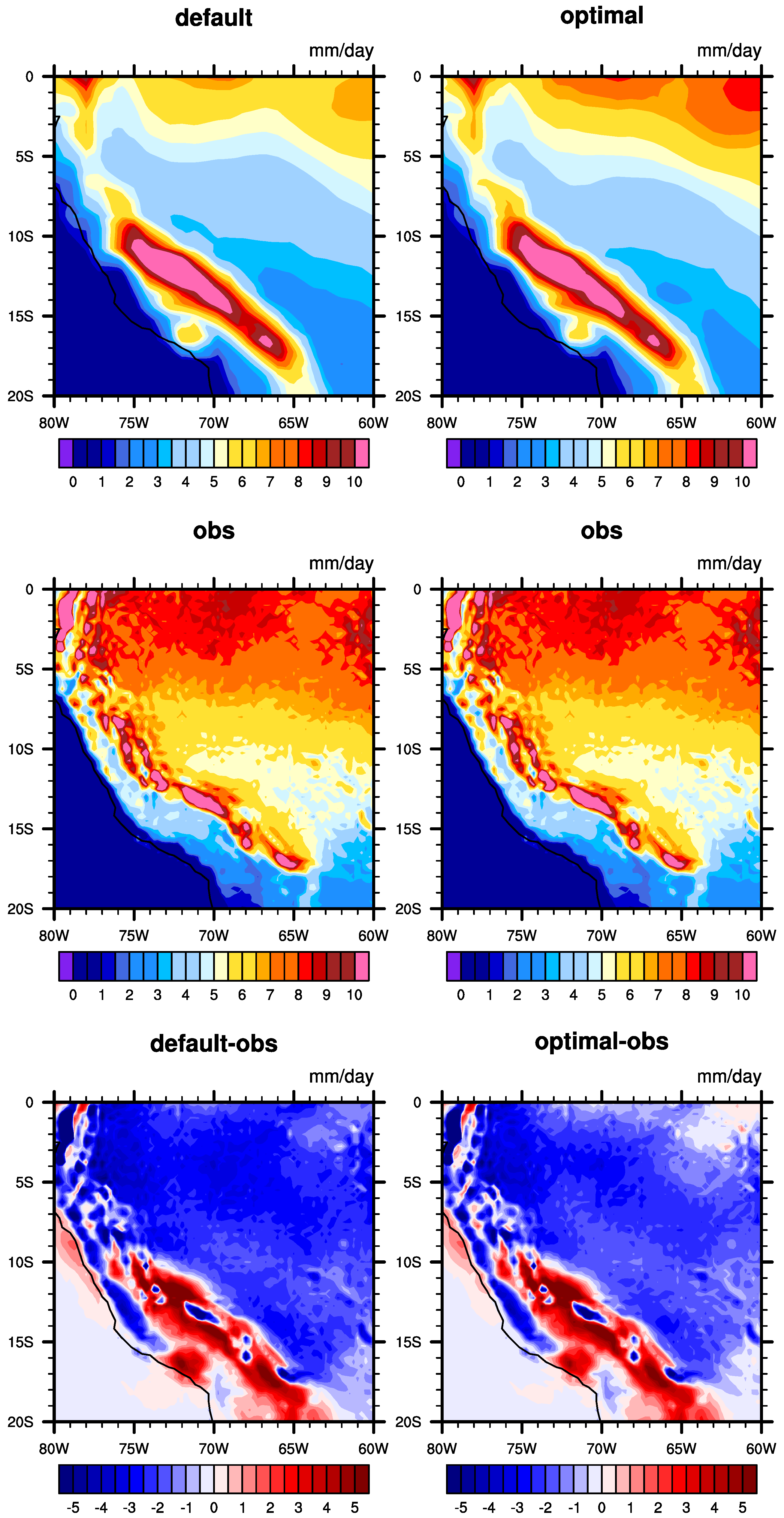
The observation data show that the precipitation in the South Pacific region generally reveals a ladder-like decline from east to west. The default experiment can simulate the changes in precipitation. However, there is a huge deviation in the precipitation value during the precipitation decline in the default simulation. In
Figure 9, in the observation data, the precipitation in most areas is less than 3 mm/day. In the default experiment, the precipitation in many areas is over 3 mm/day, which leads to the fact that the precipitation values obtained by the default simulation are larger than the observation data, and the xy plot of the zonal mean in
Figure 10a can also capture the large difference between them. The optimization experiment preserves the change patterns of the default experiment, which align with the observed data, and reduces the area where precipitation exceeds 3 mm/day. This positive change is more obvious in areas far from the equator. In the southeast, the error is reduced by 90%, from 2 mm/day to approximately 0.2 mm/day.
Figure S10 depicts the difference between the optimal experiment and the default experiment, clearly showing significant improvements over the default parameter experiment, with a marked reduction in precipitation across most of the South Pacific region. Moreover, the optimization did not cause a new deviation. The xy plot of the zonal mean shows that the optimization results over
–
S are significantly better than those of the default experiment. Although it did not bring a significant improvement over the two edges, the precipitation remained at a level almost equal to the default value, without causing a new error. From a macro perspective, the improvement of the RMSE also reaches 46.78%, which is the most significant effect in the region selected in this study.
Compared with several other optimization areas, the Warm Pool area spans multiple longitude and latitude ranges, the oceans and continents are intertwined, and the precipitation is relatively large but the optimization results are still positive in many areas. In the southern area near
S, there is a phenomenon of heavy precipitation inconsistent with the observed data in the default experiment. The optimized results in
Figure 11 and
Figure S9 show that the precipitation in these areas has been effectively weakened in the model simulation, and the result is closer to the observation data. This improvement can be clearly shown in the xy plot of the zonal mean in
Figure 10b. Furthermore, the problem of negative precipitation bias in the default simulation over Sulawesi Island (near
S and
E) has been reduced, and the regions centered on the island have been positively changed. The improvement in the Northern Hemisphere is mainly concentrated in the areas of
–
N and
–
E. The precipitation intensity of the default simulation in this area is far less than the observation data, and the optimization experiment increases the precipitation in this area. The situation of excessive precipitation in the northwest of the Warm Pool has also been improved to a certain extent in the optimization experiment. However, in areas poleward of
N, the simulation results of the optimization experiment are not ideal, which also makes the deviation in the corresponding areas in the XY plot of the zonal mean larger and leads to an insufficient improvement in the RMSE. Nevertheless, for the Warm Pool, the optimization results still reflect changes that are consistent with the observations.
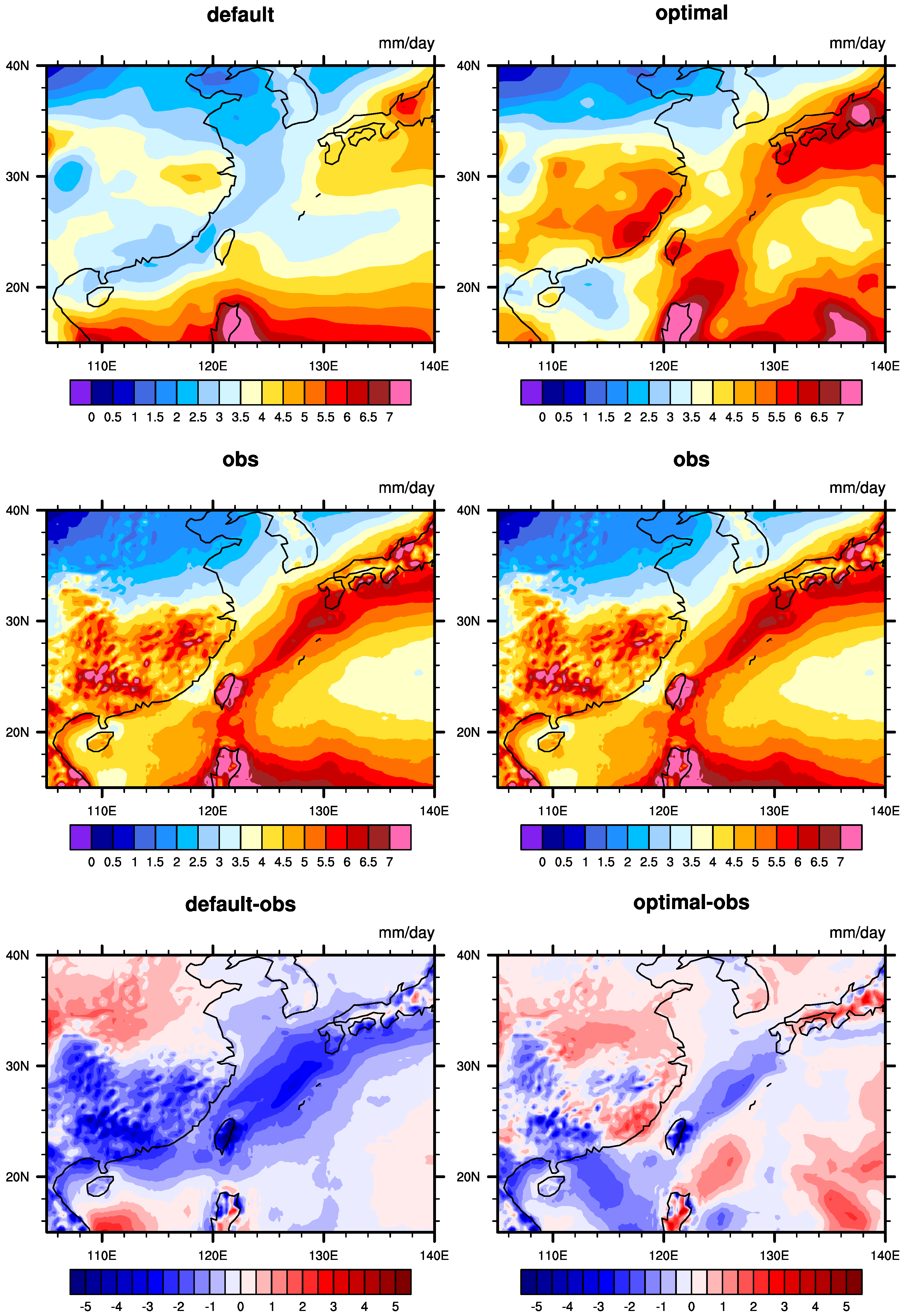
The xy plot of the zonal mean of South Asia is shown in
Figure 10c, and it can be seen that the variation in precipitation with latitude has completely changed after optimization compared with the default simulation. The overall precipitation in the default experiment increases with latitude, while after optimization, it decreases, aligning with the reanalysis data. The optimized values are closer to the reanalysis data compared to the default simulation. The precipitation distribution of the default simulation and optimization result are shown in
Figure 12. Compared with the default simulation, ocean precipitation is increased over western Indonesia so that the negative error is almost eliminated, and it is decreased over
–
E. For land precipitation, the changes are smaller than for ocean precipitation, and there also exist differences in magnitude.
Figure S13 depicts the precipitation changes across different regions of South Asia. Overall, precipitation has increased in the southwestern part compared to the default experiment, while the northeastern region shows lower precipitation values than in the default experiment. However, the error between simulation and observation is significantly reduced.
In the default simulation of the Nino region (
Figure 13), the observation inconsistency is mainly concentrated in two areas, the negative error area on the western side and the positive error area on the eastern side of the selected domain. For the improvement and optimization results of these two areas, there are obvious heavy rainfall centers; the positive error area is basically consistent with the observation data, and the negative error area is also reduced. The central region with a large error generated by the default experiment still exists after optimization but the value is closer to that of the observation data than of the default result. On the whole, this shows a positive optimization; however, in the xy plot of the meridional mean in
Figure 10d, the precipitation over the high-value area in the optimization result is lower than in the observation. Due to the small latitudinal range of the region, we considered analyzing the variation in precipitation with longitude.
Figure 13 shows the curve of precipitation variation with longitude in the Nino region. It can be seen that precipitation in the western area has increased compared to in the default experiment, while it has decreased in the eastern area. However, in most of the optimized areas, the results are closer to the reanalysis data.
Figure S11 more clearly illustrates the different trends on both sides of the region. The reason is that when improving the area of positive difference, a new small part of the negative error is introduced from the area east of
W, which is the reason for the large difference in the zonal mean between the simulation and default values.
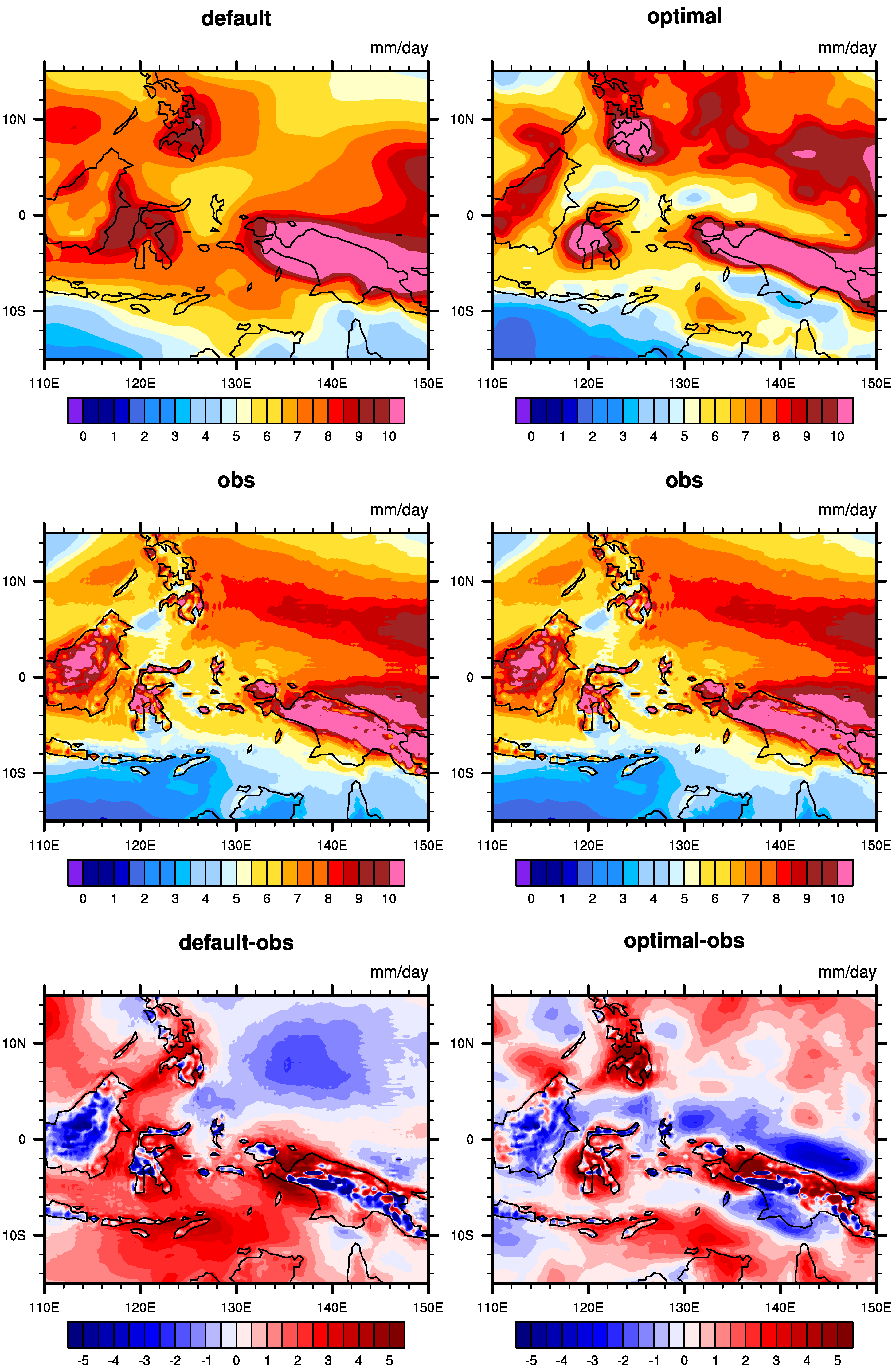
The results in East Asia are similar to those in South Asia, which are shown in
Figure 14. In East Asia, the precipitation of the default experiment is generally less than that of the reanalysis data, with the discrepancy being more pronounced in southern China and the Huanghai Sea region. We can see that in the default experiment, there is a relatively large error over the Donghai Sea, centered around the area between Taiwan and Japan, even extending to the Huanghai Sea, the Sea of Japan, and the Korean Peninsula. The optimization results suggest that this error is almost eliminated over these regions, and it is also markedly reduced over the central area. The same is true in southern China. Precipitation in southern China is increased after parameter optimization, which is low in default simulation and hard to match with observations.
Figure S14 shows that compared to the default experiment, the optimized CAM precipitation values have increased across most of the East Asia region. In addition, other areas are also improved to different degrees, such as central China and the South China Sea. We observe such positive changes using the xy plot of the zonal mean (
Figure 10e), which demonstrates that the optimization result is better than that of the default simulation in most cases, especially at
N–
N, which corresponds to the changes over southern China and the Donghai Sea.
As shown in
Figure 15, the characteristics of the precipitation in South America are wide-ranging and high in quantity, and it is difficult to obtain results consistent with the observations. Compared with the default, the optimized results reflect precipitation changes that are more consistent with the observations in some areas. The zonal mean (
Figure 10f) shows that the optimization result has better performance at
S–
N, and the spatial distribution shows that a small area at approximately
W–
W near the south of the equator has improved after a parameter optimization. Even so, there is a great difference between the model simulation and the observation when evaluating South America. And
Figure S12 shows that the difference between the default experiment and the optimized experiment is not as significant as in the other regions. Overall, the optimization effect is not significant.
The impact of parameters on precipitation is not entirely linear; it may even exhibit drastic oscillations. The effects on a global scale can be quite different from those on a regional scale. Therefore, for parameter tuning in precipitation simulations, efficient methods are crucial. Apart from expert knowledge, it is essential to have a rapid approach for exploring the parameter space and finding optimal solutions with limited computational resources. The method we proposed in this paper, based on a multilevel surrogate model, leverages the advantages of surrogate models in iteration and computing the objective function, enabling a swift search within the parameter space to identify superior solutions. The increase in these parameters is the main reason for the increase in precipitation.
3.3. Ensemble Optimization Results of the Nonuniform Parameter Parameterization Scheme
In the local optimization experiments, we found that a local optimization may lead to the simulation results of other regions moving in a worse direction; that is, the optimization of one region is at the cost of worse results in other regions, which is unacceptable. Therefore, we designed a nonuniform parameter parameterization scheme to integrate the optimal parameters of multiple regions into one case. In the selected region, we use the parameters obtained through the surrogate model-based optimization methods and use default values in other regions. To prevent the large difference in parameter values between the two sides of the regional boundary from affecting the experimental results, we designed a boundary smoothing scheme to achieve a smooth transition of parameter values from the center to the boundary of each region. The same or similar parameter values are obtained at the boundary:
where
x is used to evaluate the distance from each point in the region to the center of the region.
represent the latitude and longitude of the point, respectively, and
represent the latitude and longitude of the center point.
represent the width and length of the selected region. The denominator is equal to the distance between two boundaries and the center point.
x means the maximum distance from the point to the length or width of the region, and the value is between 0 and 1.
is the weight of the distance for each point. The closer to the center point, the closer the weight is to 1, and the closer the parameter value is to the optimized value. The closer to the boundary, the closer the weight is to 0, and the closer the parameter value is to the default value. Equation (
7) provides a cosine weight function that allows each real number between 0 and 1 to correspond to a 0–1 variation interval, and the dependent variable gradually decreases as the independent variable increases.
The ensemble parameter experiment results are shown in
Table 5. In this case, different parameters were set according to different regions, and out of the six regions, four regions achieved better simulation results than the default experiment, with two regions performing slightly worse than the default experiment. We know that the simulation results of each region are, to some extent, influenced by the parameter values of other regions, so it is difficult to achieve a level of individual optimization for each region in
Section 3.2. Among them, the South Pacific, Nino, South America, and East Asia regions all achieved varying degrees of improvement, while the results of the Warm Pool and South Asia regions slightly decreased compared to the default values. The distribution map of precipitation is shown in
Figure 16. Compared with the default experiment, the new experimental results have undergone many positive changes; precipitation in North China was reduced, and precipitation in the East China Sea and the ocean area east of the East China Sea increased, which are the reasons for the improvement of the simulation results over East Asia. In the Pacific region, a portion of the precipitation within the
W–
W,
–
S region was reduced; however, there was an increase in precipitation in the western region and near the equator, which also resulted in the simulation results in the South Pacific region not being as significant as the regional optimization results in
Section 3.2. The precipitation levels in the Nino region located in the eastern Pacific Ocean near Central America are reduced, and the improvements in some areas to the west are all positive. On the South American continent, some small-scale increases in precipitation are the reason for improving the simulation effect in South America, as such areas are relatively small, so the overall improvement is not significant. In addition, in regions such as Southern Africa, Central Asia, and the Gulf of Mexico, precipitation decreases to varying degrees compared to the default experiments. However, the increase in precipitation in the Warm Pool and South Asian regions result in a slight increase in error between the simulation results and the default experiment. Overall, the results of such simulation experiments can reach a level close to that in the default experiment in most regions, with relatively positive changes in some regions, and only a small portion of the results are slightly lower than the level of the default experiment. Beyond the selected regions in this study, other areas also show varying degrees of improvement. For example, there is a reduction in precipitation near the Cuban islands and the Gulf of Mexico, precipitation suppression in the northeastern part of the Australian islands, and slightly better precipitation performance in the North Pacific around
W–
W compared to the default experiment, as well as improvements in southern Africa’s precipitation. These regions within
N–
S have all seen varying levels of precipitation enhancement.
3.4. Evaluation of Simulation Results Related to Precipitation Using Remote Sensing Data
To further elucidate the results of parameter tuning and the nonuniform parameter parameterization scheme, we introduce comparisons with other metrics. Given that our approach is a single-objective parameter optimization method and cannot simultaneously optimize multiple objective metrics. We aimed to demonstrate, by examining the variations in other metrics, that our method improved precipitation without introducing significant errors in other aspects. We used remote sensing data for analyzing these variables because, compared to reanalysis data, remote sensing data directly reflect the actual conditions of the Earth’s surface, making them more intuitive. We selected relative humidity (RELHUM), Top of Atmosphere (TOA), Upward Longwave Flux (FLUT), and Temerature (T). The observations of the RELHUM and T were from an Atmospheric Infrared Sounder (AIRS) Pagano et al. [
54], and FLUT, from an Earth Radiation Budget Experiment (ERBE) Barkstrom [
55].
Pressure–latitude distributions of the RELHUM are shown in
Figures S3 and S4. Combining the results from the simulation experiments and the differences with remote sensing data, we find that the changes between the two sets of experiments are not significant. Under the majority of pressure and latitude conditions, there is hardly any noticeable difference between the two datasets. Only in a very few latitude regions, such as the
–
S area at 400 mb and the vicinity of
N at 500 mb, do we observe extremely subtle differences. In summary, compared to the default parameter experiment, the optimized experiment shows no significant change in relative humidity (RELHUM).
As can be seen in
Figures S5 and S6, the optimized experiment and the default experiment show consistent simulation results for temperature (T) across different pressures and latitudes.
Figure 1 and
Figure 2 indicate that, except for extremely minor differences at a few specific altitudes and latitudes, there are virtually no significant discrepancies. This suggests that, despite improvements in precipitation, there has been no significant change to the temperature simulation. The simulation results for T in the optimized experiment continue to be on par with those of the default experiment.
The spatial distribution of FLUT is shown in
Figures S7 and S8. The simulation results of T850 obtained from the nonuniform parameterization scheme experiment, similar to the simulation results for relative humidity (RELHUM) and temperature (T) experiments with the nonuniform parameterization scheme, maintain a high level of consistency with the default experiment in most areas. Comparisons with reanalysis data show slight improvements in the simulation over the default experiment in regions like East Asia and the Indian Ocean. However, in areas such as the South Pacific and North Atlantic, the default experiment performs slightly better results. In terms of mean and extreme values, the simulation results of both experiments are very close. Overall, the simulation values remain at the same level.
The reasons for this situation are believed to be primarily the following. First, the parameters chosen for optimization specifically target precipitation sensitivity and may not be as sensitive to other metrics, hence the limited impact on these metrics. Second, in this study, the compset selected utilizes climatological sea surface temperature (SST) data for ocean simulation. If CMIP-related compsets with variable SST data were employed, it is possible that more variations could be observed. In conclusion, our proposed optimization method based on a multilevel surrogate model and the nonuniform parameterization scheme, while optimizing precipitation simulation results, does not introduce significant errors in other metrics.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}