

Enhancing Long-Term Flood Forecasting with SageFormer: A Cascaded Dimensionality Reduction Approach Based on Satellite-Derived Data



Abstract
1. Introduction
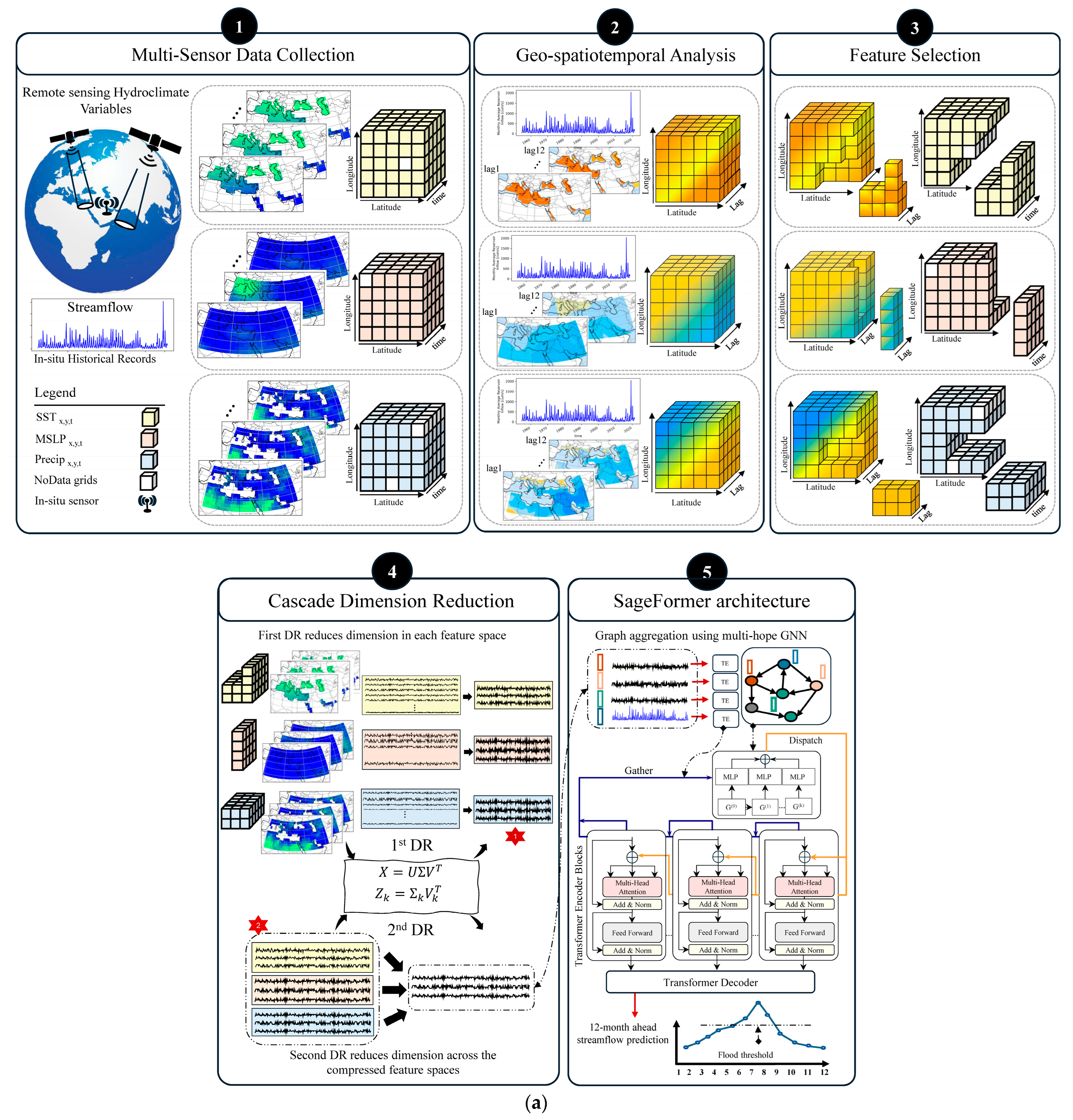
2. Materials and Methods
2.1. Overview of Transformer Architecture
2.2. SageFormer for Hydroclimate Modeling
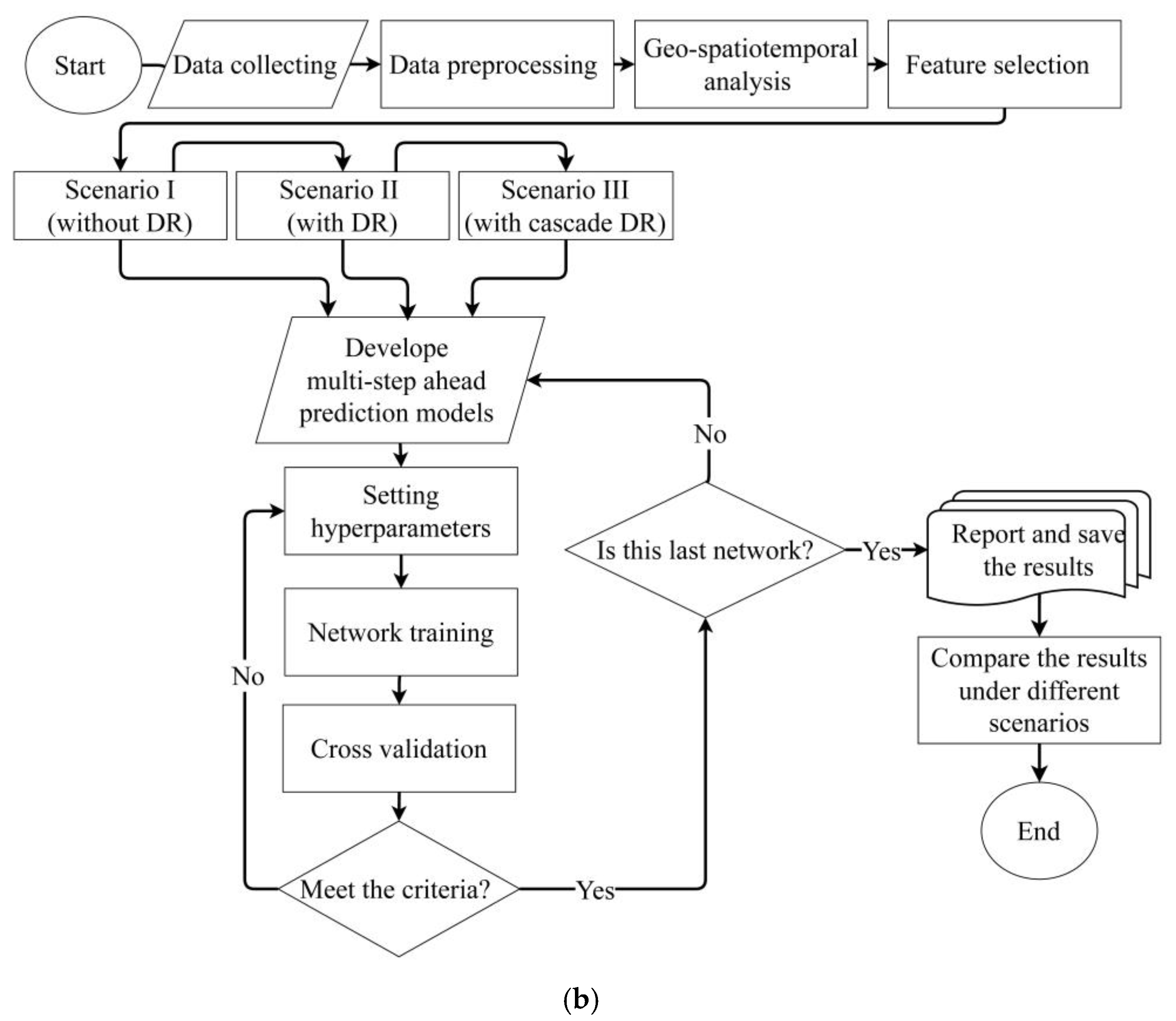
2.3. Proposed Framework
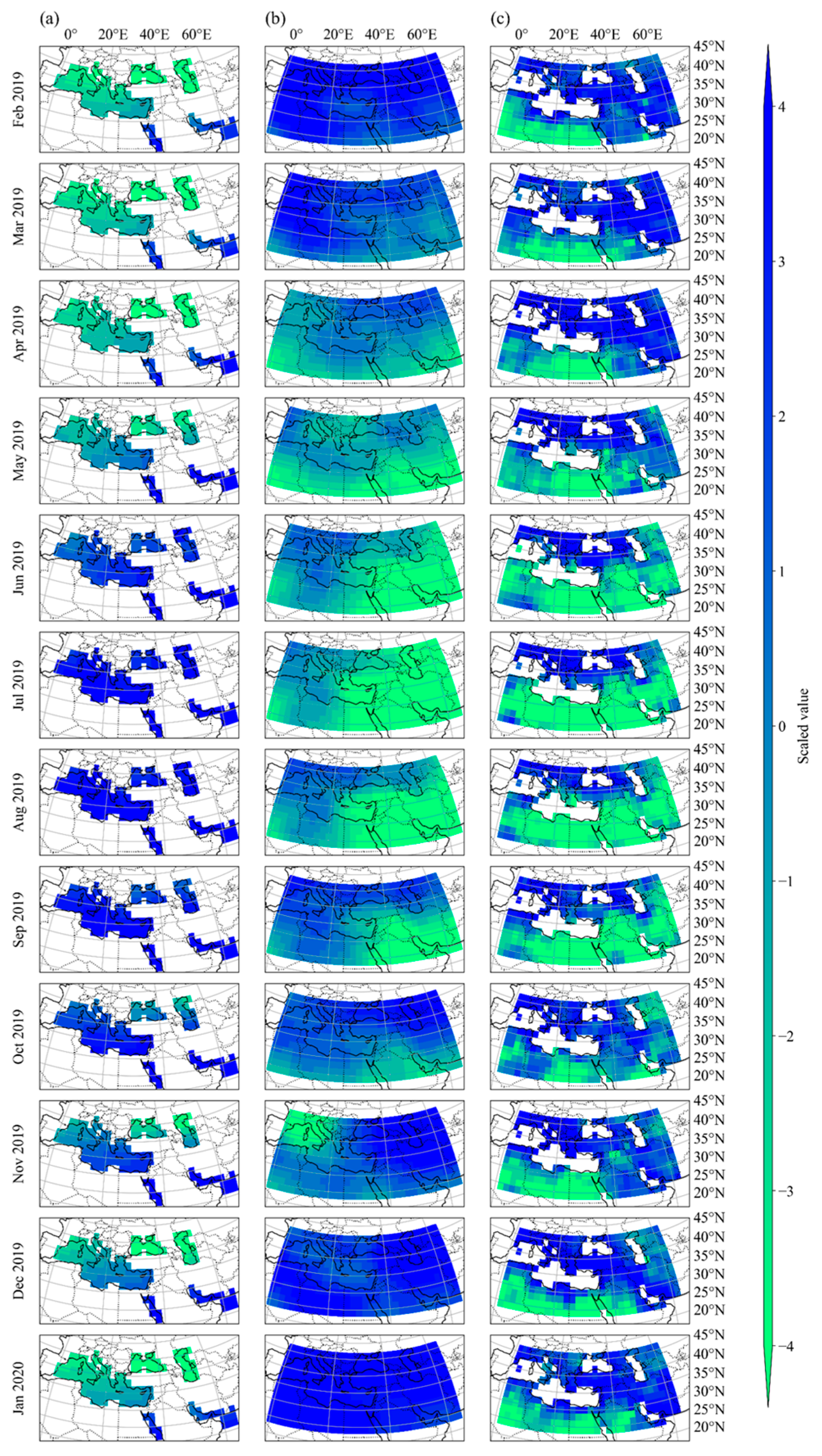
2.4. Case Study Basin and Data Acquisition
2.5. Performance Evaluation Metrics
2.6. Experimental Settings
3. Results
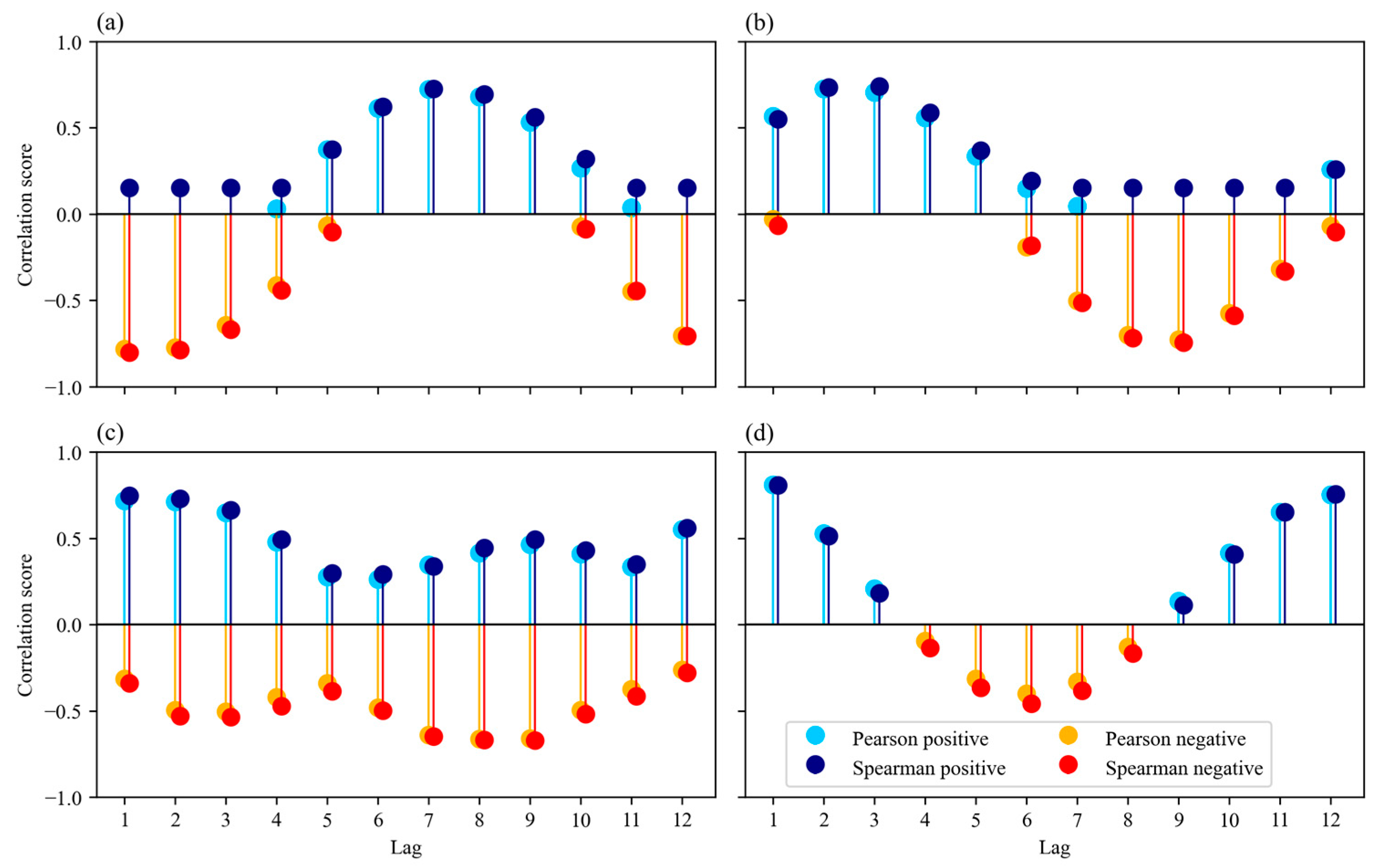
3.1. Geo-Spatiotemporal Data Feature Selection
3.2. Flood Forecasting Model Evaluation
4. Discussion
5. Conclusions
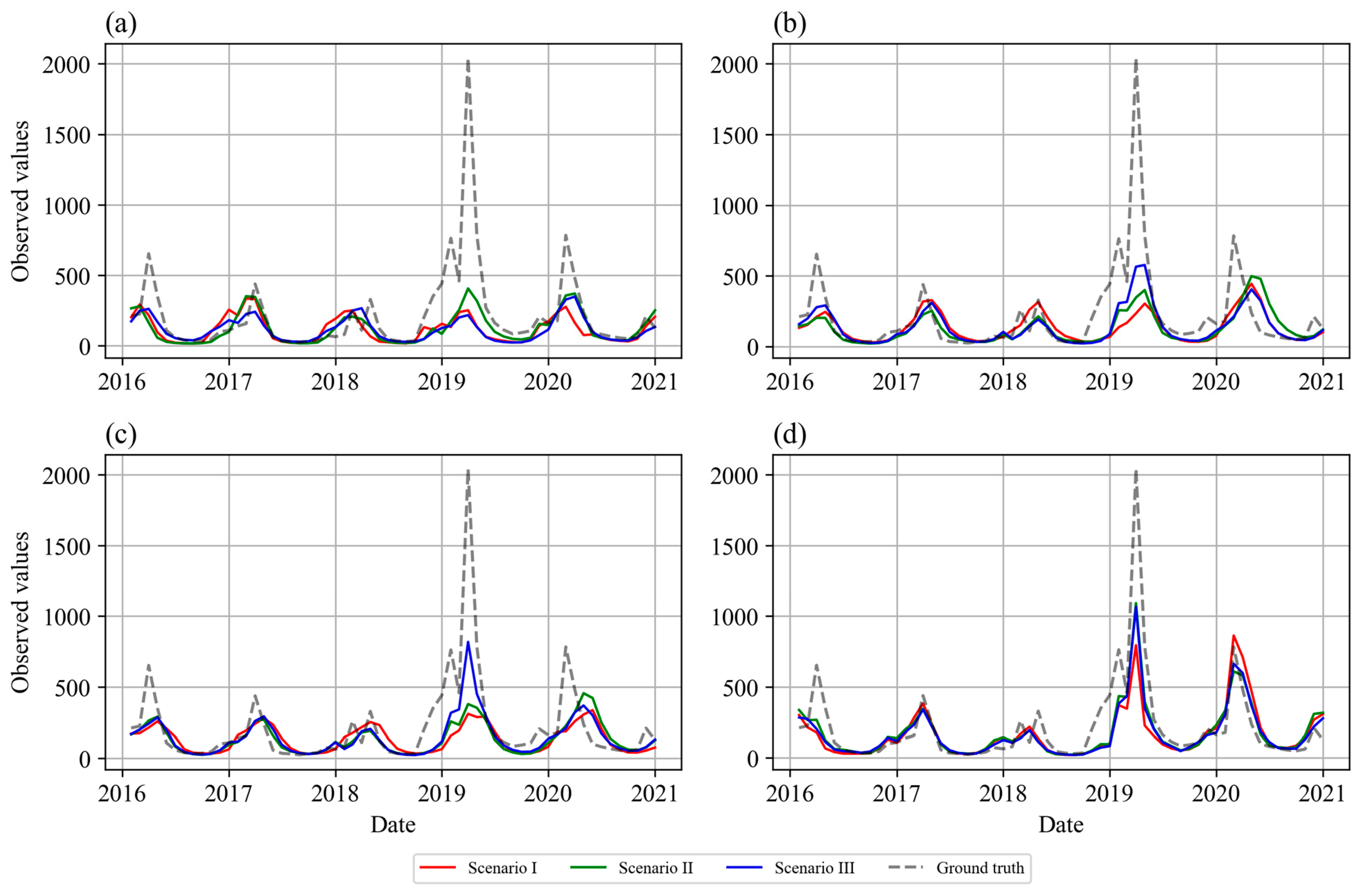
- Across all models, Scenario II consistently yielded better results compared to Scenario I, highlighting the importance of applying DR to select highly correlated grids and reduce computational time. For instance, Vanilla LSTM’s MAE decreased from 0.776 in Scenario I to 0.685 in Scenario II, and R2 improved from 0.234 to 0.396.
- SageFormer achieved its lowest MAE (0.482) and MSE (0.360) in Scenario II, reflecting the impact of DR in preserving 95% of the variance while improving feature relevance. SageFormer exhibited the highest R2 values, reaching 0.590 in Scenario I, 0.685 in Scenario II, and 0.661 in Scenario III, reflecting its ability to model complex inter- and intra-series dependencies effectively. Its superior Pearson correlation (up to 0.833 in Scenario II) underscores its strong predictive alignment with observed streamflow values, even for challenging 12-step-ahead flood forecasting.
- SageFormer demonstrated its capability to predict the April 2019 flood event with the highest accuracy. The event, characterized by a 400-year return period, is inherently challenging to predict due to its rarity and intensity. While all other models underestimated the flood peak, SageFormer provided a near-accurate prediction, underscoring its effectiveness in modeling extreme hydrological events. This capability has significant implications for disaster risk reduction, particularly in data-scarce regions.
- In Scenario III, where cascading dimensionality reduction (DR) was applied, the curse of dimensionality was effectively mitigated, leading to improved prediction accuracy for attention-based models. SageFormer demonstrated its robustness in handling further dimensionality reduction, maintaining high accuracy (MAE: 0.481, MSE: 0.387) with only a minor decline in R2 (0.661) compared to Scenario II. Informer also showed noticeable improvement in Scenario III, with MAE reducing from 0.591 to 0.523 and R2 increasing from 0.470 to 0.573, underscoring the particular benefits of cascading DR for attention-based architectures.
- The improvement from Scenario I to Scenario II was the most pronounced for SageFormer, with a 10.6% reduction in MAE (0.539 to 0.482) and a 22.9% reduction in MSE (0.467 to 0.360).
- The Informer and Transformer models demonstrated moderate improvements, with Informer performing slightly better than Transformer in terms of R2 (0.573 vs. 0.450) and Pearson correlation (0.782 vs. 0.730) in Scenario III. SageFormer outperformed Informer and Transformer significantly in all scenarios, particularly in Scenario III, where SageFormer achieved 8% lower MAE and 21% lower MSE compared to Informer.
- Vanilla LSTM showed the poorest-performing model across all scenarios, with limited capacity to model long-term dependencies and complex spatiotemporal relationships. While DR improved its performance from Scenario I (MAE: 0.776) to Scenario II (MAE: 0.685), cascading DR in Scenario III led to a slight degradation in R2 (0.355) due to its inability to effectively handle further feature reduction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, X.; Xie, F.; Zhou, X. Research on Spatial and Temporal Characteristics of Drought Based on GIS Using Remote Sensing Big Data. Cluster Comput. 2016, 19, 757–767. [Google Scholar] [CrossRef]
- Pham, T.M.; Dinh, H.T.; Pham, T.A.; Nguyen, T.S.; Duong, N.T. Modeling of Water Scarcity for Spatial Analysis Using Water Poverty Index and Fuzzy-MCDM Technique. Model. Earth Syst. Environ. 2024, 10, 2079–2097. [Google Scholar] [CrossRef]
- Dolan, F.; Lamontagne, J.; Link, R.; Hejazi, M.; Reed, P.; Edmonds, J. Evaluating the Economic Impact of Water Scarcity in a Changing World. Nat. Commun. 2021, 12, 1915. [Google Scholar] [CrossRef] [PubMed]
- Hussain, Z.; Wang, Z.; Yang, H.; Arfan, M.; Wang, W.; Faisal, M.; Azam, M.I.; Usman, M. Evolution and Trends of Water Scarcity Indicators: Unveiling Gaps, Challenges, and Collaborative Opportunities. Water Conserv. Sci. Eng. 2024, 9, 8. [Google Scholar] [CrossRef]
- Fasihi, S.; Lim, W.Z.; Wu, W.; Proverbs, D. Systematic Review of Flood and Drought Literature Based on Science Mapping and Content Analysis. Water 2021, 13, 2788. [Google Scholar] [CrossRef]
- Trong, N.G.; Quang, P.N.; Van Cuong, N.; Le, H.A.; Nguyen, H.L.; Tien Bui, D. Spatial Prediction of Fluvial Flood in High-Frequency Tropical Cyclone Area Using TensorFlow 1D-Convolution Neural Networks and Geospatial Data. Remote Sens. 2023, 15, 5429. [Google Scholar] [CrossRef]
- El Garnaoui, M.; Boudhar, A.; Nifa, K.; El Jabiri, Y.; Karaoui, I.; El Aloui, A.; Midaoui, A.; Karroum, M.; Mosaid, H.; Chehbouni, A. Nested Cross-Validation for HBV Conceptual Rainfall–Runoff Model Spatial Stability Analysis in a Semi-Arid Context. Remote Sens. 2024, 16, 3756. [Google Scholar] [CrossRef]
- Dommo, A.; Aloysius, N.; Lupo, A.; Hunt, S. Spatial and Temporal Analysis and Trends of Extreme Precipitation over the Mississippi River Basin, USA during 1988–2017. J. Hydrol. Reg. Stud. 2024, 56, 101954. [Google Scholar] [CrossRef]
- UN Water. Climate Change and Water: UN-Water Policy Brief; UN Water: Geneva, Switzerland, 2019. [Google Scholar]
- Sene, K. Hydrological Forecasting. Hydrometeorology 2024, 167–215. [Google Scholar] [CrossRef]
- Sene, K. Hydrometeorology: Forecasting and Applications; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Zhou, F.; Chen, Y.; Liu, J. Application of a New Hybrid Deep Learning Model That Considers Temporal and Feature Dependencies in Rainfall–Runoff Simulation. Remote Sens. 2023, 15, 1395. [Google Scholar] [CrossRef]
- Lo, W.C.; Wang, W.J.; Chen, H.Y.; Lee, J.W.; Vojinovic, Z. Feasibility Study Regarding the Use of a Conformer Model for Rainfall-Runoff Modeling. Water 2024, 16, 3125. [Google Scholar] [CrossRef]
- Ghobadi, F.; Kang, D. Application of Machine Learning in Water Resources Management: A Systematic Literature Review. Water 2023, 15, 620. [Google Scholar] [CrossRef]
- Ghobadi, F.; Kang, D. Improving Long-Term Streamflow Prediction in a Poorly Gauged Basin Using Geo-Spatiotemporal Mesoscale Data and Attention-Based Deep Learning: A Comparative Study. J. Hydrol. 2022, 615, 128608. [Google Scholar] [CrossRef]
- Ghobadi, F.; Yaseen, Z.M.; Kang, D. Long-Term Streamflow Forecasting in Data-Scarce Regions: Insightful Investigation for Leveraging Satellite-Derived Data, Informer Architecture, and Concurrent Fine-Tuning Transfer Learning. J. Hydrol. 2024, 631, 130772. [Google Scholar] [CrossRef]
- Sharafkhani, F.; Corns, S.; Holmes, R. Multi-Step Ahead Water Level Forecasting Using Deep Neural Networks. Water 2024, 16, 3153. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, N.; Bao, X.; Wu, J.; Cui, X. Spatio-Temporal Deep Learning Model for Accurate Streamflow Prediction with Multi-Source Data Fusion. Environ. Model. Softw. 2024, 178, 106091. [Google Scholar] [CrossRef]
- Fayer, G.; Bolotari, N.; Miranda, F.; Ferreira, J.S.; da Silva, R.R.C.; Cândido, V.B.R.; Andrade, M.P.; Morais, M.; Ribeiro, C.B.M.; Capriles, P.V.Z.; et al. A Temporal Fusion Transformer Deep Learning Model for Long-Term Streamflow Forecasting: A Case Study in the Funil Reservoir, Southeast Brazil. Knowl. Based Eng. Sci. 2023, 4, 73–88. [Google Scholar]
- Xu, Y.; Lin, K.; Hu, C.; Wang, S.; Wu, Q.; Zhang, L.; Ran, G. Deep Transfer Learning Based on Transformer for Flood Forecasting in Data-Sparse Basins. J. Hydrol. 2023, 625, 129956. [Google Scholar] [CrossRef]
- Dtissibe, F.Y.; Ari, A.A.A.; Abboubakar, H.; Njoya, A.N.; Mohamadou, A.; Thiare, O. A Comparative Study of Machine Learning and Deep Learning Methods for Flood Forecasting in the Far-North Region, Cameroon. Sci. Afr. 2024, 23. [Google Scholar] [CrossRef]
- Malik, H.; Feng, J.; Shao, P.; Abduljabbar, Z.A. Improving Flood Forecasting Using Time-Distributed CNN-LSTM Model: A Time-Distributed Spatiotemporal Method. Earth Sci. Inform. 2024, 17, 3455–3474. [Google Scholar] [CrossRef]
- Bennett, A.; Tran, H.; De la Fuente, L.; Triplett, A.; Ma, Y.; Melchior, P.; Maxwell, R.M.; Condon, L.E. Spatio-Temporal Machine Learning for Regional to Continental Scale Terrestrial Hydrology. J. Adv. Model. Earth Syst. 2024, 16, e2023MS004095. [Google Scholar] [CrossRef]
- Kow, P.Y.; Liou, J.Y.; Sun, W.; Chang, L.C.; Chang, F.J. Watershed Groundwater Level Multi-step Ahead Forecasts by Fusing Convolutional-Based Autoencoder and LSTM Models. J. Environ. Manag. 2024, 351, 119789. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Liu, C.; Xu, Y.; Niu, C.; Li, R.; Li, M.; Hu, C.; Tian, L. An Interpretable Hybrid Deep Learning Model for Flood Forecasting Based on Transformer and LSTM. J. Hydrol. Reg. Stud. 2024, 54, 101873. [Google Scholar] [CrossRef]
- Perera, U.A.K.K.; Coralage, D.T.S.; Ekanayake, I.U.; Alawatugoda, J.; Meddage, D.P.P. A New Frontier in Streamflow Modeling in Ungauged Basins with Sparse Data: A Modified Generative Adversarial Network with Explainable AI. Results Eng. 2024, 21, 101920. [Google Scholar] [CrossRef]
- Bloemheuvel, S.; van den Hoogen, J.; Atzmueller, M. Graph Construction on Complex Spatiotemporal Data for Enhancing Graph Neural Network-Based Approaches. Int. J. Data Sci. Anal. 2024, 18, 157–174. [Google Scholar] [CrossRef]
- Taccari, M.L.; Wang, H.; Nuttall, J.; Chen, X.; Jimack, P.K. Spatial-Temporal Graph Neural Networks for Groundwater Data. Sci. Rep. 2024, 14, 1–12. [Google Scholar] [CrossRef]
- Zhang, Z.; Meng, L.; Gu, Y. SageFormer: Series-Aware Framework for Long-Term Multivariate Time-Series Forecasting. IEEE Internet Things J. 2024, 11. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar]
- Ghobadi, F.; Saman, A.; Charmchi, T.; Kang, D. Feature Extraction from Satellite-Derived Hydroclimate Data: Assessing Impacts on Various Neural Networks for Multi-Step Ahead Streamflow Prediction. Sustainability 2023, 15, 15761. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.S.; Peng, J.; Zhang, S.S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Freeman, E.; Woodruff, S.D.; Worley, S.J.; Lubker, S.J.; Kent, E.C.; Angel, W.E.; Berry, D.I.; Brohan, P.; Eastman, R.; Gates, L.; et al. ICOADS Release 3.0: A Major Update to the Historical Marine Climate Record. Int. J. Climatol. 2017, 37, 2211–2232. [Google Scholar] [CrossRef]
- Schneider, U.; Finger, P.; Meyer-Christoffer, A.; Rustemeier, E.; Ziese, M.; Becker, A. Evaluating the Hydrological Cycle over Land Using the Newly-Corrected Precipitation Climatology from the Global Precipitation Climatology Centre (GPCC). Atmosphere 2017, 8, 52. [Google Scholar] [CrossRef]
- Bennett, N.D.; Croke, B.F.W.; Guariso, G.; Guillaume, J.H.A.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.H.; Norton, J.P.; Perrin, C.; et al. Characterising Performance of Environmental Models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Gitau, M.W.; Pai, N.; Daggupati, P. Hydrologic and Water Quality Models: Performance Measures and Evaluation Criteria. Trans. ASABE 2015, 58, 1763–1785. [Google Scholar] [CrossRef]
- Kingston, D.G.; McGregor, G.R.; Hannah, D.M.; Lawler, D.M. River Flow Teleconnections across the Northern North Atlantic Region. Geophys. Res. Lett. 2006, 33. [Google Scholar] [CrossRef]
- Abbasi, M.; Farokhnia, A.; Bahreinimotlagh, M.; Roozbahani, R. A Hybrid of Random Forest and Deep Auto-Encoder with Support Vector Regression Methods for Accuracy Improvement and Uncertainty Reduction of Long-Term Streamflow Prediction. J. Hydrol. 2021, 597, 125717. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAE | MSE | R2 | Pearson Correlation |
|---|---|---|---|---|
| Scenario I | ||||
| Vanilla LSTM | 0.776 | 0.874 | 0.234 | 0.714 |
| Transformer | 0.712 | 0.830 | 0.272 | 0.589 |
| Informer | 0.712 | 0.824 | 0.277 | 0.593 |
| SageFormer | 0.539 | 0.467 | 0.590 | 0.791 |
| Scenario II | ||||
| Vanilla LSTM | 0.685 | 0.689 | 0.396 | 0.748 |
| Transformer | 0.677 | 0.727 | 0.363 | 0.685 |
| Informer | 0.591 | 0.604 | 0.470 | 0.730 |
| SageFormer | 0.482 | 0.360 | 0.685 | 0.833 |
| Scenario III | ||||
| Vanilla LSTM | 0.685 | 0.735 | 0.355 | 0.687 |
| Transformer | 0.598 | 0.627 | 0.450 | 0.730 |
| Informer | 0.523 | 0.487 | 0.573 | 0.782 |
| SageFormer | 0.481 | 0.387 | 0.661 | 0.822 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghobadi, F.; Tayerani Charmchi, A.S.; Kang, D. Enhancing Long-Term Flood Forecasting with SageFormer: A Cascaded Dimensionality Reduction Approach Based on Satellite-Derived Data. Remote Sens. 2025, 17, 365. https://doi.org/10.3390/rs17030365
Ghobadi F, Tayerani Charmchi AS, Kang D. Enhancing Long-Term Flood Forecasting with SageFormer: A Cascaded Dimensionality Reduction Approach Based on Satellite-Derived Data. Remote Sensing. 2025; 17(3):365. https://doi.org/10.3390/rs17030365
Chicago/Turabian StyleGhobadi, Fatemeh, Amir Saman Tayerani Charmchi, and Doosun Kang. 2025. "Enhancing Long-Term Flood Forecasting with SageFormer: A Cascaded Dimensionality Reduction Approach Based on Satellite-Derived Data" Remote Sensing 17, no. 3: 365. https://doi.org/10.3390/rs17030365
APA StyleGhobadi, F., Tayerani Charmchi, A. S., & Kang, D. (2025). Enhancing Long-Term Flood Forecasting with SageFormer: A Cascaded Dimensionality Reduction Approach Based on Satellite-Derived Data. Remote Sensing, 17(3), 365. https://doi.org/10.3390/rs17030365