
Contrastive Dual-Pool Feature Adaption for Domain Incremental Remote Sensing Scene Classification


Abstract
1. Introduction
- We propose a novel dual-pool architecture, where each domain is assigned its specific prompt tokens and adapter modules. This domain-specific design enables effective feature extraction and adaptation for each individual domain while maintaining minimal computational overhead.
- We introduce a dual loss mechanism that enhances intra-domain classification performance through image feature attraction and text embedding separation, improving the model’s ability to learn discriminative features for each domain’s classification task.
- Extensive experiments show that our proposed method consistently outperforms state-of-the-art methods in the DIL setting.
2. Related Work
2.1. Remote Sensing Scene Classification
2.2. Domain Incremental Learning
2.3. Vision-Language Models
3. Method
3.1. Problem Formulation
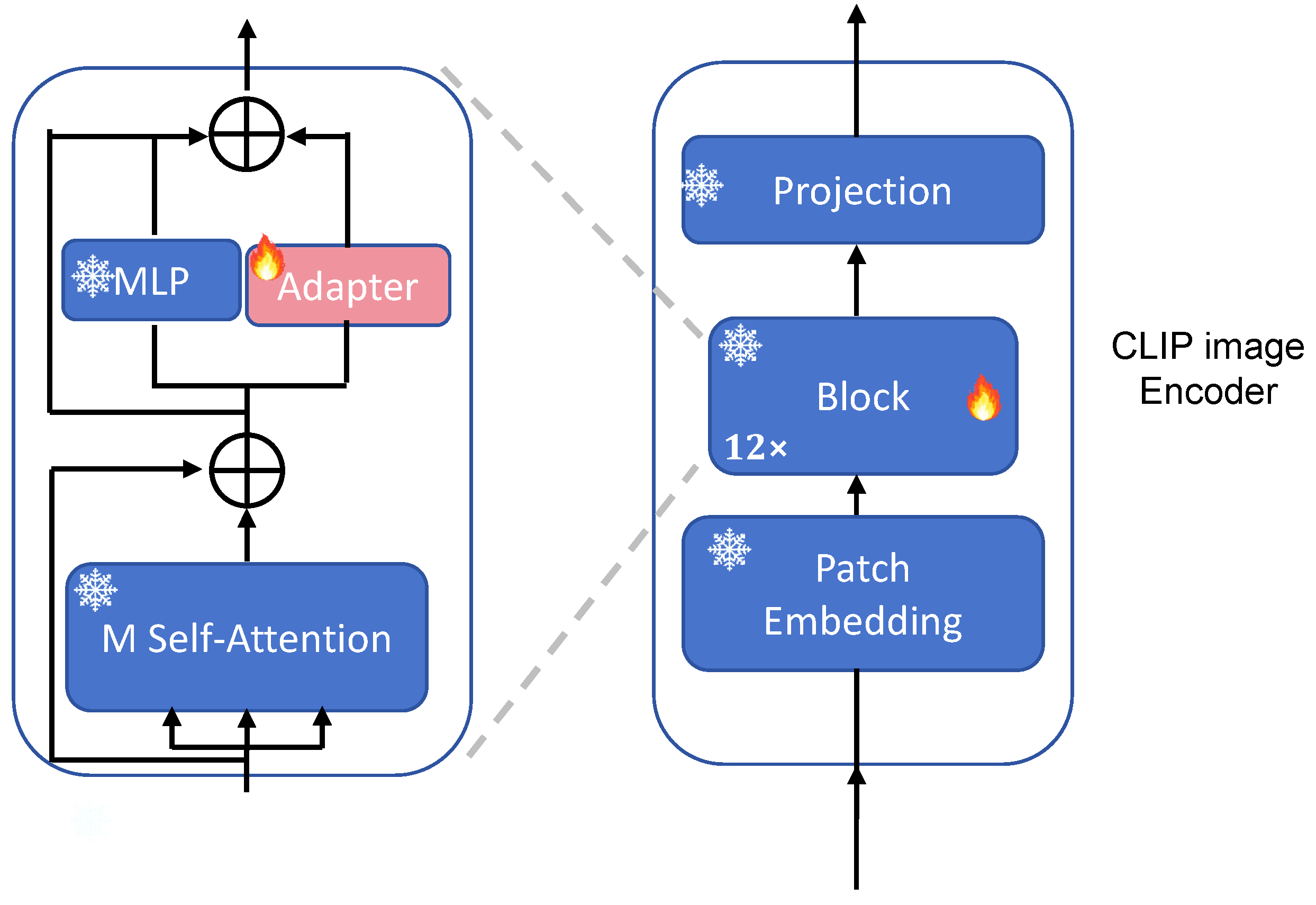
3.2. Framework Overview
3.3. Prompt Design
3.3.1. Image Prompt Design
3.3.2. Language Prompt Design
3.4. Adapter Pool Design
3.4.1. Visual Adapter Architecture
3.4.2. Textual Adapter Architecture
3.5. Training Objectives
3.5.1. Image Feature Attraction Loss
3.5.2. Text Feature Repulsion Loss
3.5.3. Cross-Modal Alignment Loss
3.6. K-Means Domain Selector
Domain Selection and Inference
| Algorithm 1: Domain incremental learning with dynamic component selection. |
|
4. Experiment
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison Results
4.2.1. Results on Remote Sensing Datasets
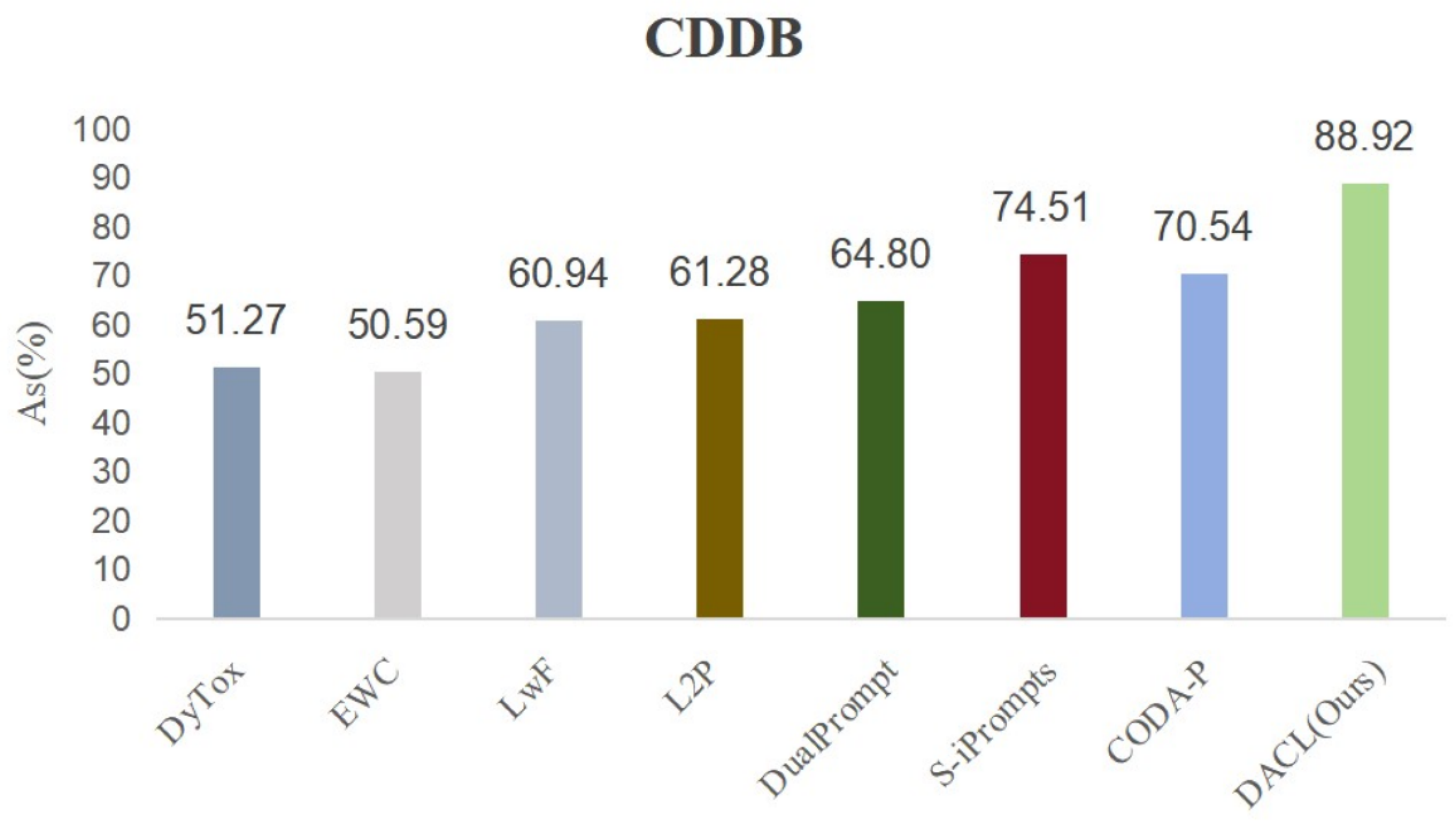
4.2.2. Results on Classic DIL Datasets
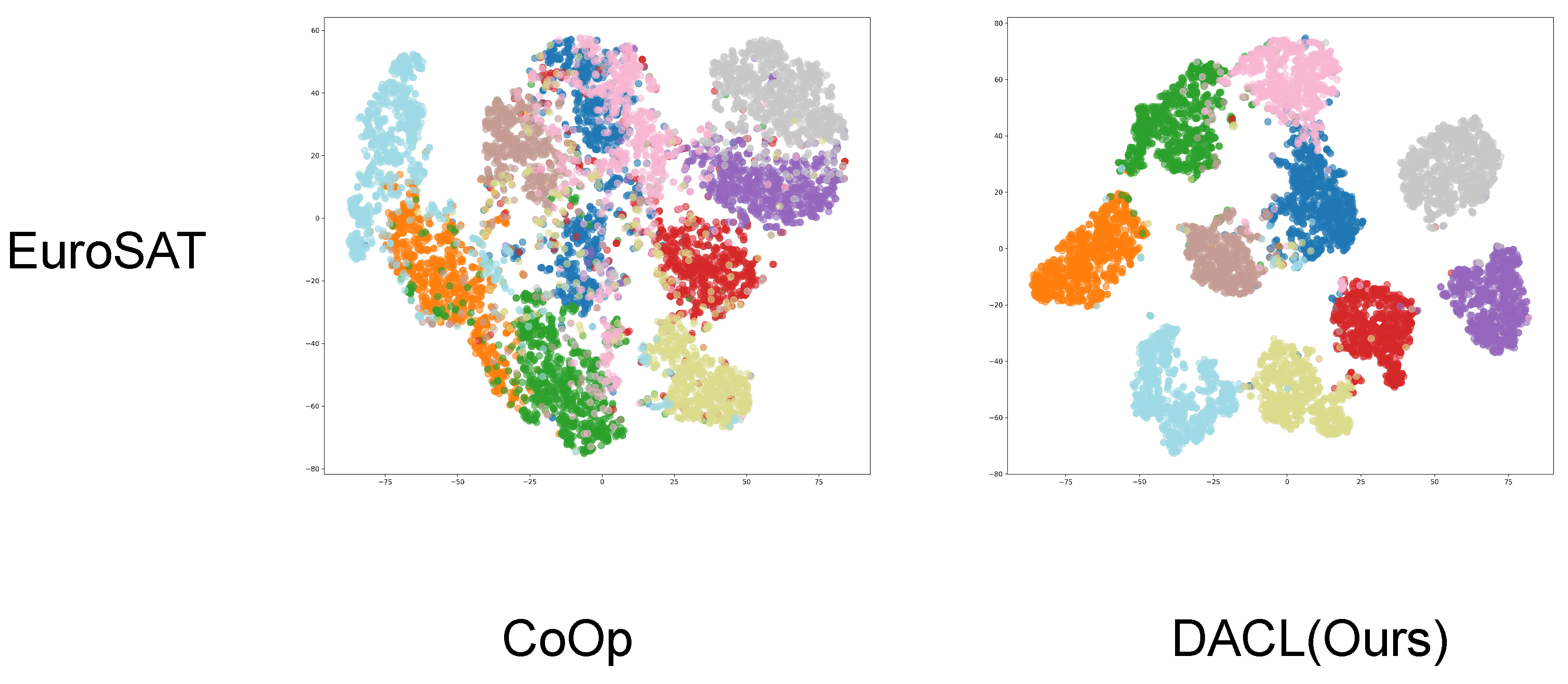
4.3. Ablations
4.3.1. Ablation Study on Loss Components
4.3.2. Component Ablations
4.3.3. Dimensional Ablation in Adapter Architectures
4.3.4. Ablation Study of Loss Function Coefficients
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS-J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Khan, A.H.; Fraz, M.M.; Shahzad, M. Deep learning based land cover and crop type classification: A comparative study. In Proceedings of the 2021 International Conference on Digital Futures and Transformative Technologies (ICoDT2), Islamabad, Pakistan, 20–21 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Zang, N.; Cao, Y.; Wang, Y.; Huang, B.; Zhang, L.; Mathiopoulos, P.T. Land-use mapping for high-spatial resolution remote sensing image via deep learning: A review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5372–5391. [Google Scholar] [CrossRef]
- Singh, G.; Singh, S.; Sethi, G.; Sood, V. Deep learning in the mapping of agricultural land use using Sentinel-2 satellite data. Geographies 2022, 2, 691–700. [Google Scholar] [CrossRef]
- Prudente, V.H.R.; Skakun, S.; Oldoni, L.V.; Xaud, H.A.; Xaud, M.R.; Adami, M.; Sanches, I.D. Multisensor approach to land use and land cover mapping in Brazilian Amazon. ISPRS-J. Photogramm. Remote Sens. 2022, 189, 95–109. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Bai, L.; Du, S.; Zhang, X.; Wang, H.; Liu, B.; Ouyang, S. Domain adaptation for remote sensing image semantic segmentation: An integrated approach of contrastive learning and adversarial learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, Y.; Huang, C.; Meng, R.; Pang, Y.; Jia, W.; Zhou, J.; Huang, Z.; Fang, L.; Zhao, F. Assessing Landsat-8 and Sentinel-2 spectral-temporal features for mapping tree species of northern plantation forests in Heilongjiang Province, China. For. Ecosyst. 2022, 9, 100032. [Google Scholar] [CrossRef]
- Mello, F.A.; Demattê, J.A.; Bellinaso, H.; Poppiel, R.R.; Rizzo, R.; de Mello, D.C.; Rosin, N.A.; Rosas, J.T.; Silvero, N.E.; Rodríguez-Albarracín, H.S. Remote sensing imagery detects hydromorphic soils hidden under agriculture system. Sci. Rep. 2023, 13, 10897. [Google Scholar] [CrossRef]
- Ghamisi, P.; Plaza, J.; Chen, Y.; Li, J.; Plaza, A.J. Advanced spectral classifiers for hyperspectral images: A review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef]
- Douillard, A.; Ramé, A.; Couairon, G.; Cord, M. Dytox: Transformers for continual learning with dynamic token expansion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9285–9295. [Google Scholar]
- Zhu, K.; Zhai, W.; Cao, Y.; Luo, J.; Zha, Z.J. Self-sustaining representation expansion for non-exemplar class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9296–9305. [Google Scholar]
- Peng, L.; He, Y.; Wang, S.; Song, X.; Dong, S.; Wei, X.; Gong, Y. Global self-sustaining and local inheritance for source-free unsupervised domain adaptation. Pattern Recognit. 2024, 155, 110679. [Google Scholar] [CrossRef]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 709–727. [Google Scholar]
- Wang, Y.; Huang, Z.; Hong, X. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning. Adv. Neural Inf. Process. Syst. 2022, 35, 5682–5695. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1461–1474. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1793–1802. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Dong, R.; Xu, D.; Jiao, L.; Zhao, J.; An, J. A fast deep perception network for remote sensing scene classification. Remote Sens. 2020, 12, 729. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M. Deep vision transformers for remote sensing scene classification. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2815–2818. [Google Scholar]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, N.; Liu, W.; Chen, H.; Xie, Y. MFST: A multi-level fusion network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef]
- Ma, D.; Tang, P.; Zhao, L. SiftingGAN: Generating and sifting labeled samples to improve the remote sensing image scene classification baseline in vitro. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1046–1050. [Google Scholar] [CrossRef]
- Wei, Y.; Luo, X.; Hu, L.; Peng, Y.; Feng, J. An improved unsupervised representation learning generative adversarial network for remote sensing image scene classification. Remote Sens. Lett. 2020, 11, 598–607. [Google Scholar] [CrossRef]
- Perkonigg, M.; Hofmanninger, J.; Langs, G. Continual active learning for efficient adaptation of machine learning models to changing image acquisition. In Proceedings of the International Conference on Information Processing in Medical Imaging, Virtual, 28–30 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 649–660. [Google Scholar]
- Hayes, T.L.; Kafle, K.; Shrestha, R.; Acharya, M.; Kanan, C. Remind your neural network to prevent catastrophic forgetting. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 466–483. [Google Scholar]
- Iscen, A.; Zhang, J.; Lazebnik, S.; Schmid, C. Memory-efficient incremental learning through feature adaptation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 699–715. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Van De Ven, G.M.; Li, Z.; Tolias, A.S. Class-incremental learning with generative classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3611–3620. [Google Scholar]
- Ostapenko, O.; Puscas, M.; Klein, T.; Jahnichen, P.; Nabi, M. Learning to remember: A synaptic plasticity driven framework for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11321–11329. [Google Scholar]
- Riemer, M.; Cases, I.; Ajemian, R.; Liu, M.; Rish, I.; Tu, Y.; Tesauro, G. Learning to learn without forgetting by maximizing transfer and minimizing interference. arXiv 2018, arXiv:1810.11910. [Google Scholar]
- Buzzega, P.; Boschini, M.; Porrello, A.; Abati, D.; Calderara, S. Dark experience for general continual learning: A strong, simple baseline. Adv. Neural Inf. Process. Syst. 2020, 33, 15920–15930. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–17. [Google Scholar]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 139–154. [Google Scholar]
- Zenke, F.; Poole, B.; Ganguli, S. Continual learning through synaptic intelligence. In Proceedings of the International Conference on Machine Learning—PMLR, Sydney, Australia, 6–11 August 2017; pp. 3987–3995. [Google Scholar]
- Schwarz, J.; Czarnecki, W.; Luketina, J.; Grabska-Barwinska, A.; Teh, Y.W.; Pascanu, R.; Hadsell, R. Progress & compress: A scalable framework for continual learning. In Proceedings of the International Conference on Machine Learning—PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4528–4537. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef]
- Serra, J.; Suris, D.; Miron, M.; Karatzoglou, A. Overcoming catastrophic forgetting with hard attention to the task. In Proceedings of the International Conference on Machine Learning—PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4548–4557. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Liu, Y.; Schiele, B.; Sun, Q. Rmm: Reinforced memory management for class-incremental learning. Adv. Neural Inf. Process. Syst. 2021, 34, 3478–3490. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7765–7773. [Google Scholar]
- Golkar, S.; Kagan, M.; Cho, K. Continual learning via neural pruning. arXiv 2019, arXiv:1903.04476. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Qin, Y.; Peng, D.; Peng, X.; Wang, X.; Hu, P. Deep evidential learning with noisy correspondence for cross-modal retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa Portugal, 10–14 October 2022; pp. 4948–4956. [Google Scholar]
- Qin, Y.; Chen, Y.; Peng, D.; Peng, X.; Zhou, J.T.; Hu, P. Noisy-correspondence learning for text-to-image person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27197–27206. [Google Scholar]
- Tu, C.H.; Mai, Z.; Chao, W.L. Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7725–7735. [Google Scholar]
- Wang, Z.; Zhang, Z.; Lee, C.Y.; Zhang, H.; Sun, R.; Ren, X.; Su, G.; Perot, V.; Dy, J.; Pfister, T. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 139–149. [Google Scholar]
- Wang, Z.; Zhang, Z.; Ebrahimi, S.; Sun, R.; Zhang, H.; Lee, C.Y.; Ren, X.; Su, G.; Perot, V.; Dy, J.; et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 631–648. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Zhu, B.; Niu, Y.; Han, Y.; Wu, Y.; Zhang, H. Prompt-aligned gradient for prompt tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 15659–15669. [Google Scholar]
- Smith, J.S.; Karlinsky, L.; Gutta, V.; Cascante-Bonilla, P.; Kim, D.; Arbelle, A.; Panda, R.; Feris, R.; Kira, Z. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11909–11919. [Google Scholar]
- Khattak, M.U.; Rasheed, H.; Maaz, M.; Khan, S.; Khan, F.S. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19113–19122. [Google Scholar]
- He, H.; Cai, J.; Zhang, J.; Tao, D.; Zhuang, B. Sensitivity-aware visual parameter-efficient fine-tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11825–11835. [Google Scholar]
- Zhang, R.; Fang, R.; Zhang, W.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tip-adapter: Training-free clip-adapter for better vision-language modeling. arXiv 2021, arXiv:2111.03930. [Google Scholar]
- Wang, W.; Shi, Y.; Wang, X. RMFFNet: A Reverse Multi-Scale Feature Fusion Network for Remote Sensing Scene Classification. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Xu, Q.; Yuan, X.; Ouyang, C.; Zeng, Y. Attention-based pyramid network for segmentation and classification of high-resolution and hyperspectral remote sensing images. Remote Sens. 2020, 12, 3501. [Google Scholar] [CrossRef]
- Yuan, B.; Han, L.; Gu, X.; Yan, H. Multi-deep features fusion for high-resolution remote sensing image scene classification. Neural Comput. Appl. 2021, 33, 2047–2063. [Google Scholar] [CrossRef]
- Hou, Y.E.; Yang, K.; Dang, L.; Liu, Y. Contextual spatial-channel attention network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2023. [Google Scholar] [CrossRef]
- Cui, Y.; Li, W.; Chen, L.; Wang, L.; Jiang, J.; Gao, S. Feature fusion network model based on dual attention mechanism for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 2023, 20, 6008805. [Google Scholar] [CrossRef]
- Kim, J.; Chi, M. SAFFNet: Self-attention-based feature fusion network for remote sensing few-shot scene classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Michieli, U.; Zanuttigh, P. Knowledge distillation for incremental learning in semantic segmentation. Comput. Vis. Image Underst. 2021, 205, 103167. [Google Scholar] [CrossRef]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 2024, 132, 581–595. [Google Scholar] [CrossRef]
- Yuan, L.; Chen, D.; Chen, Y.L.; Codella, N.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A new foundation model for computer vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International conference on machine learning—PMLR, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS-J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Peng, X.; Bai, Q.; Xia, X.; Huang, Z.; Saenko, K.; Wang, B. Moment matching for multi-source domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 1406–1415. [Google Scholar]
- Li, C.; Huang, Z.; Paudel, D.P.; Wang, Y.; Shahbazi, M.; Hong, X.; Van Gool, L. A continual deepfake detection benchmark: Dataset, methods, and essentials. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 1339–1349. [Google Scholar]
- Lomonaco, V.; Maltoni, D. CORe50: A new dataset and benchmark for continuous object recognition. In Proceedings of the Conference on Robot Learning—PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 17–26. [Google Scholar]
- Cho, E.; Kim, J.; Kim, H.J. Distribution-aware prompt tuning for vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 22004–22013. [Google Scholar]
- Nicolas, J.; Chiaroni, F.; Ziko, I.; Ahmad, O.; Desrosiers, C.; Dolz, J. MoP-CLIP: A mixture of prompt-tuned CLIP models for domain incremental learning. arXiv 2023, arXiv:2307.05707. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | EuroSAT | NWPU | PatternNet | All |
|---|---|---|---|---|
| Order 1: EuroSAT→NWPU→PatternNet | ||||
| VPT [15] | 97.15 (↓0.57) | 72.48 (↓14.62) | 84.51 (↓—) | 84.71 |
| CoOp [17] | 92.40 (↓0.91) | 68.63 (↓19.39) | 89.54 (↓—) | 83.48 |
| Clip-Adapter [70] | 92.09 (↓1.02) | 67.12 (↓20.12) | 88.42 (↓—) | 82.54 |
| CoCoOp [57] | 90.84 (↓0.99) | 66.24 (↓17.12) | 87.27 (↓—) | 81.45 |
| DAPT [78] | 96.52 (↓0.55) | 69.88 (↓16.24) | 87.25 (↓—) | 84.55 |
| S-Prompts [16] | 96.91 (↓1.05) | 68.12 (↓21.40) | 89.61 (↓—) | 84.88 |
| DACL (Ours) | 99.38 (↓0.61) | 77.28 (↓17.09) | 90.20 (↓—) | 88.95 |
| Methods | EuroSAT | PatternNet | NWPU | All |
|---|---|---|---|---|
| Order 2:EuroSAT→PatternNet→NWPU | ||||
| VPT [15] | 96.95 (↓0.66) | 90.26 (↓7.55) | 61.84 (↓—) | 83.02 |
| CoOp [17] | 92.38 (↓0.93) | 90.81 (↓6.95) | 65.61 (↓—) | 82.93 |
| Clip-Adapter [70] | 91.67 (↓1.44) | 89.24 (↓7.24) | 64.62 (↓—) | 81.84 |
| CoCoOp [57] | 91.09 (↓0.74) | 89.12 (↓18.84) | 64.17 (↓—) | 81.46 |
| DAPT [78] | 96.82 (↓0.25) | 91.77 (↓6.78) | 65.97 (↓—) | 84.85 |
| S-Prompts [16] | 96.98 (↓0.95) | 92.11 (↓6.89) | 66.93 (↓—) | 85.34 |
| DACL (Ours) | 99.38 (↓0.61) | 92.55 (↓6.94) | 75.31 (↓—) | 89.08 |
| Methods | NWPU | EuroSAT | PatternNet | All |
|---|---|---|---|---|
| Order 3: NWPU→EuroSAT→PatternNet | ||||
| VPT [15] | 70.09 (↓14.42) | 96.74 (↓0.04) | 84.18 (↓—) | 83.67 |
| CoOp [17] | 68.58 (↓19.48) | 91.94 (↓0.16) | 89.67 (↓—) | 83.40 |
| Clip-Adapter [70] | 67.24 (↓17.88) | 90.85 (↓0.08) | 85.62 (↓—) | 81.24 |
| CoCoOp [57] | 68.26 (↓18.94) | 90.27 (↓0.11) | 86.73 (↓—) | 81.75 |
| DAPT [78] | 68.55 (↓18.32) | 97.08 (↓0.09) | 88.72 (↓—) | 84.78 |
| S-Prompts [16] | 68.88 (↓20.14) | 97.23 (↓0.16) | 90.76 (↓—) | 85.62 |
| DACL (Ours) | 77.68 (↓16.72) | 99.25 (↓0.09) | 91.02 (↓—) | 89.32 |
| Methods | NWPU | PatternNet | EuroSAT | All |
|---|---|---|---|---|
| Order 4: NWPU→PatternNet→EuroSAT | ||||
| VPT [15] | 66.60 (↓17.91) | 87.48 (↓0.02) | 96.60 (↓—) | 83.56 |
| CoOp [17] | 65.56 (↓22.50) | 90.28 (↓0.04) | 91.35 (↓—) | 82.30 |
| Clip-Adapter [70] | 65.27 (↓19.85) | 88.94 (↓0.09) | 92.08 (↓—) | 82.10 |
| CoCoOp [57] | 64.54 (↓22.66) | 87.82 (↓0.06) | 90.88 (↓—) | 81.08 |
| DAPT [78] | 66.18 (↓20.69) | 90.97 (↓0.03) | 96.37 (↓—) | 84.51 |
| S-Prompts [16] | 65.90 (↓23.16) | 91.53 (↓0.02) | 96.86 (↓—) | 84.76 |
| DACL (Ours) | 76.56 (↓17.84) | 91.76 (↓0.03) | 99.09 (↓—) | 89.14 |
| Methods | PatternNet | EuroSAT | NWPU | All |
|---|---|---|---|---|
| Order 5: PatternNet→EuroSAT→NWPU | ||||
| VPT [15] | 91.50 (↓6.36) | 96.55 (↓0.53) | 61.37 (↓—) | 83.14 |
| CoOp [17] | 89.79 (↓8.15) | 92.01 (↓0.66) | 65.41 (↓—) | 82.40 |
| Clip-Adapter [70] | 89.24 (↓8.33) | 91.76 (↓0.49) | 62.87 (↓—) | 81.29 |
| CoCoOp [57] | 88.18 (↓9.79) | 91.24 (↓0.08) | 61.92 (↓—) | 80.45 |
| DAPT [78] | 90.89 (↓7.72) | 97.17 (↓0.71) | 65.13 (↓—) | 84.40 |
| S-Prompts [16] | 90.54 (↓8.01) | 97.29 (↓0.68) | 66.61 (↓—) | 84.81 |
| DACL (Ours) | 91.93 (↓7.72) | 99.07 (↓0.63) | 77.16 (↓—) | 89.39 |
| Methods | PatternNet | NWPU | EuroSAT | All |
|---|---|---|---|---|
| Order 6: PatternNet→NWPU→EuroSAT | ||||
| VPT [15] | 89.70 (↓8.16) | 68.94 (↓0.04) | 96.52 (↓—) | 85.05 |
| CoOp [17] | 90.05 (↓7.69) | 65.53 (↓0.03) | 91.41 (↓—) | 82.33 |
| Clip-Adapter [70] | 88.72 (↓8.85) | 64.49 (↓0.05) | 91.82 (↓—) | 81.68 |
| CoCoOp [57] | 88.24 (↓9.73) | 63.98 (↓0.04) | 91.04 (↓—) | 81.09 |
| DAPT [78] | 90.54 (↓8.07) | 66.78 (↓0.03) | 96.03 (↓—) | 84.45 |
| S-Prompts [16] | 90.87 (↓7.68) | 65.86 (↓0.04) | 96.95 (↓—) | 84.56 |
| DACL (Ours) | 91.45 (↓8.20) | 76.17 (↓0.14) | 98.99 (↓—) | 88.87 |
| Domain | EuroSAT | NWPU | PatternNet | All |
|---|---|---|---|---|
| Accuracy (%) | 99.94 | 79.33 | 94.64 | 91.30 |
| Methods | |
|---|---|
| VPT [15] | 77.82 |
| CoOp [17] | 76.54 |
| Clip-Adapter [70] | 75.88 |
| CoCoOp [57] | 75.02 |
| DAPT [78] | 78.53 |
| S-Prompts [16] | 78.75 |
| DACL (Ours) | 82.16 |
| Method | Backbone | Buffer Size | Parameters | ||
|---|---|---|---|---|---|
| DyTox [12] | ViT | 50/class | - | 62.94 | - |
| EWC [39] | ViT | 0/class | 100/100 | 47.62 | - |
| LwF [44] | ViT | 100/100 | 49.19 | −5.01 | |
| L2P [55] | ViT | 1.8/101.8 | 40.15 | −2.25 | |
| DualPrompt [56] | ViT | 2.8/102.8 | 43.79 | −2.03 | |
| CODA-P [59] | ViT | 5.9/105.9 | 47.42 | −3.46 | |
| S-iPrompts [16] | ViT | 1.8/101.8 | 50.62 | −2.85 | |
| S-liPrompts [16] | CLIP | 0/class | 0.06/100.06 | 67.78 | −1.64 |
| MoP-CLIP [79] | CLIP | 0.06/100.06 | 69.70 | − | |
| DACL (Ours) | CLIP | 0/class | 0.82/100.82 | 72.34 | −1.27 |
| Baseline | ||||
|---|---|---|---|---|
| ✓ | 53.24 | |||
| ✓ | ✓ | 86.94 | ||
| ✓ | ✓ | ✓ | 87.44 | |
| ✓ | ✓ | ✓ | 88.07 | |
| ✓ | ✓ | ✓ | ✓ | 88.95 |
| Adapter-Pool | Prompt-Pool | EuroSAT | NWPU | PatternNet | All |
|---|---|---|---|---|---|
| 35.80 | 62.60 | 61.33 | 53.24 | ||
| ✓ | 95.92 | 68.79 | 78.14 | 80.95 | |
| ✓ | 97.83 | 69.42 | 90.78 | 86.01 | |
| ✓ | ✓ | 99.38 | 77.28 | 90.20 | 88.95 |
| Dimensions | EuroSAT | NWPU | PatternNet | All |
|---|---|---|---|---|
| 32 | 99.23 | 77.58 | 87.47 | 88.09 |
| 64 | 99.38 | 77.28 | 90.20 | 88.95 |
| 0.1 | 0.3 | 0.5 | 0.7 | 1 | |
| 87.92 | 88.29 | 89.23 | 88.33 | 88.95 | |
| 0.1 | 0.3 | 0.5 | 0.7 | 1 | |
| 87.79 | 88.32 | 88.75 | 89.14 | 88.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Li, Y.; Han, X. Contrastive Dual-Pool Feature Adaption for Domain Incremental Remote Sensing Scene Classification. Remote Sens. 2025, 17, 308. https://doi.org/10.3390/rs17020308
Shao Y, Li Y, Han X. Contrastive Dual-Pool Feature Adaption for Domain Incremental Remote Sensing Scene Classification. Remote Sensing. 2025; 17(2):308. https://doi.org/10.3390/rs17020308
Chicago/Turabian StyleShao, Yingzhao, Yunsong Li, and Xiaodong Han. 2025. "Contrastive Dual-Pool Feature Adaption for Domain Incremental Remote Sensing Scene Classification" Remote Sensing 17, no. 2: 308. https://doi.org/10.3390/rs17020308
APA StyleShao, Y., Li, Y., & Han, X. (2025). Contrastive Dual-Pool Feature Adaption for Domain Incremental Remote Sensing Scene Classification. Remote Sensing, 17(2), 308. https://doi.org/10.3390/rs17020308