
Infrared Dim Small Target Detection Algorithm with Large-Size Receptive Fields

 , ,
, ,
Abstract
1. Introduction
2. Related Work
2.1. Object Segmentation
2.2. Large-Size Convolution Layers
2.3. Attention Mechanism
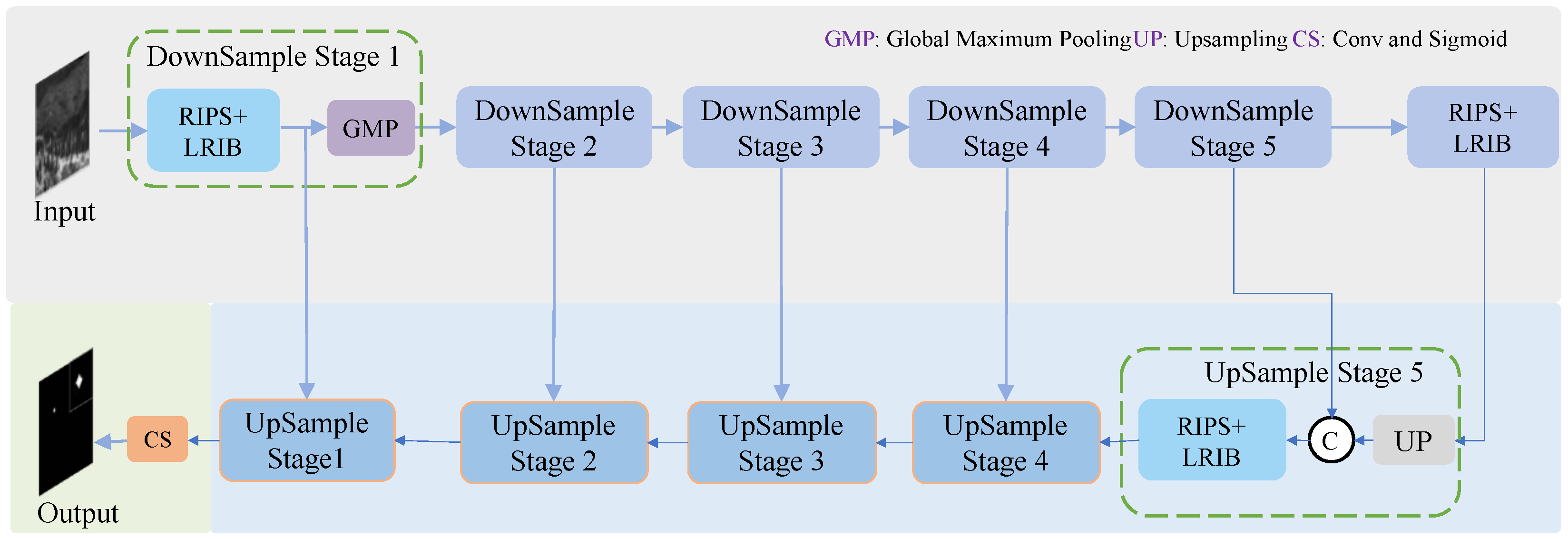
3. Method
3.1. Overall Structure
3.2. Residual Network with an Inverted Pyramid Structure
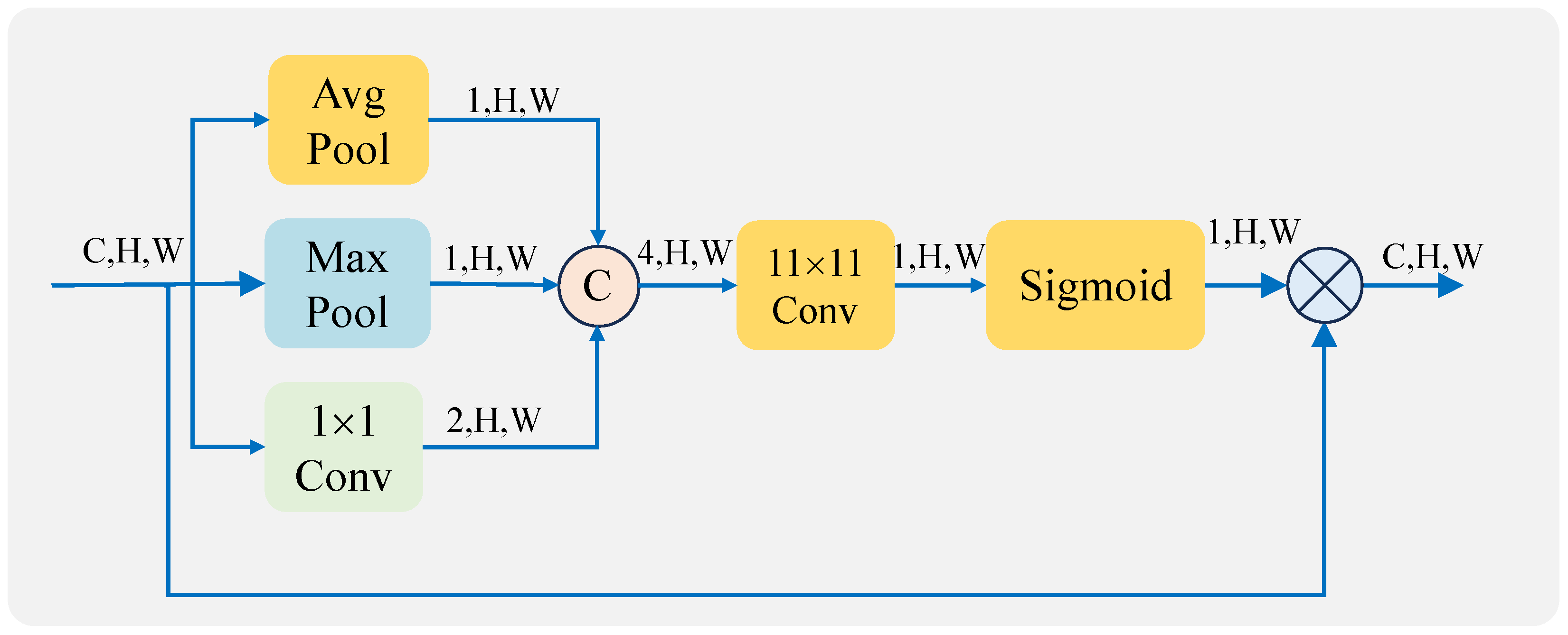
3.3. Attention Mechanism with Large-Size Receptive Field and Inverse Bottleneck Structure
3.4. Loss Function
4. Experiments
4.1. Datasets and Implementation Details
4.2. Evaluation Metrics
4.3. Ablation Study
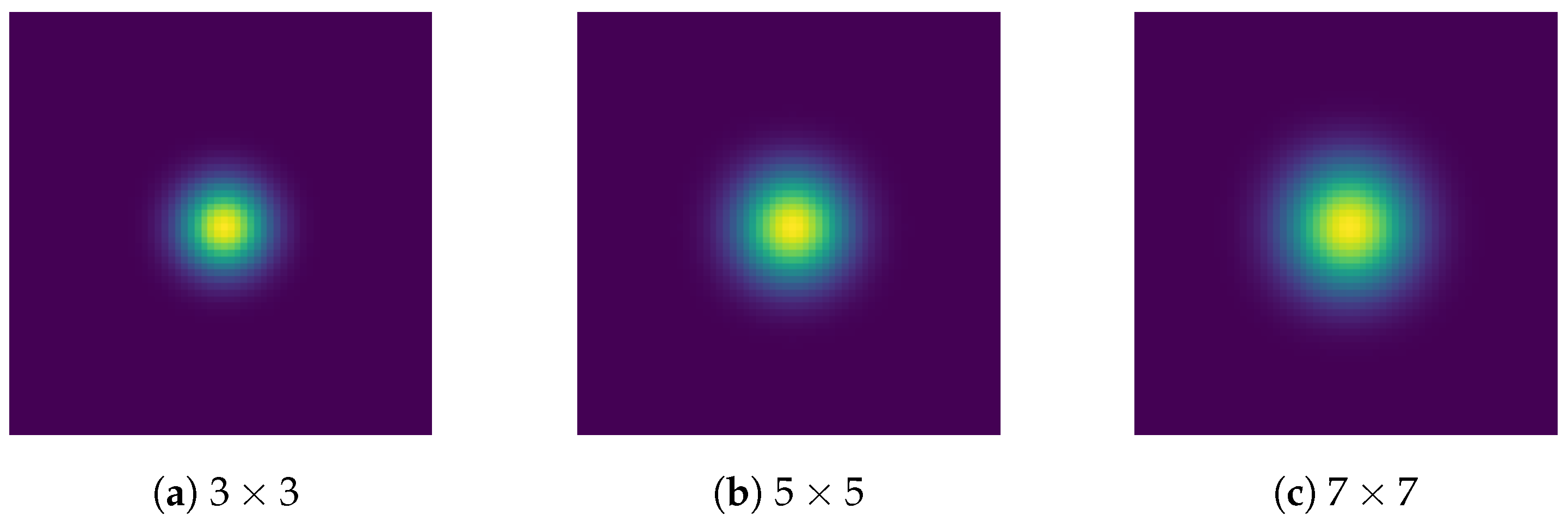
4.3.1. Comparison of Convolutional Layers of Different Sizes
4.3.2. Comparison of Networks Using Different Attention Mechanisms
4.4. Comparison with Other Advanced Algorithms
4.4.1. Quantitative Comparison
4.4.2. Visual Comparison
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, T.; Yang, Z.; Liu, B.; Sun, S. A Lightweight Infrared Small Target Detection Network Based on Target Multiscale Context. IEEE Geosci. Remote Sens. Lett. 2023, 20, 7000305. [Google Scholar] [CrossRef]
- Rawat, S.S.; Verma, S.K.; Kumar, Y. Review on recent development in infrared small target detection algorithms. Procedia Comput. Sci. 2020, 167, 2496–2505. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-Frame Infrared Small-Target Detection: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Hu, Z.; Su, Y. An infrared dim and small target image preprocessing algorithm based on improved bilateral filtering. In Proceedings of the 2021 International Conference on Computer, Blockchain and Financial Development (CBFD), Nanjing, China, 23–25 April 2021; pp. 74–77. [Google Scholar] [CrossRef]
- Han, J.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Xu, Y.; Qian, W.; Ren, K.; Chen, Q. Total Variation-Based Interframe Infrared Patch-Image Model for Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7003305. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, C.; Fu, Q.; Han, Z. A Novel Pattern for Infrared Small Target Detection with Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4481–4492. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef]
- Ma, T.; Yang, Z.; Wang, J.; Sun, S.; Ren, X.; Ahmad, U. Infrared Small Target Detection Network with Generate Label and Feature Mapping. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6505405. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 949–958. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11965. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Lin, F.; Bao, K.; Li, Y.; Zeng, D.; Ge, S. Learning Contrast-Enhanced Shape-Biased Representations for Infrared Small Target Detection. IEEE Trans. Image Process. 2024, 33, 3047–3058. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 3279–3298. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, NIPS’15, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 2017–2025. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Chung, W.Y.; Lee, I.H.; Park, C.G. Lightweight Infrared Small Target Detection Network Using Full-Scale Skip Connection U-Net. IEEE Geosci. Remote Sens. Lett. 2023, 20, 7000705. [Google Scholar] [CrossRef]
- Chen, F.; Gao, C.; Liu, F.; Zhao, Y.; Zhou, Y.; Meng, D.; Zuo, W. Local Patch Network with Global Attention for Infrared Small Target Detection. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3979–3991. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Pan, Z.; Liu, Y.; Lei, B.; Hu, Y. APAFNet: Single-Frame Infrared Small Target Detection by Asymmetric Patch Attention Fusion. IEEE Geosci. Remote Sens. Lett. 2023, 20, 7000405. [Google Scholar] [CrossRef]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5–10 December 2016; pp. 4905–4913. [Google Scholar]
- Wei, W.; Ma, T.; Li, M.; Zuo, H. Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition. Remote Sens. 2024, 16, 34. [Google Scholar] [CrossRef]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-imbalanced NLP Tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar] [CrossRef]
- Qin, Y.; Bruzzone, L.; Gao, C.; Li, B. Infrared Small Target Detection Based on Facet Kernel and Random Walker. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7104–7118. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Zhang, L.; Tan, F.; Xi, Y.; Zheng, H.; Li, N. ISTDU-Net: Infrared Small-Target Detection U-Net. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7506205. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Y.; Wu, S.; Hu, Z.; Xia, X.; Lan, D.; Liu, X. Infrared small target detection based on multiscale local contrast learning networks. Infrared Phys. Technol. 2022, 123, 104107. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5002013. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maxks | Params/MB | MFIRST Dataset | SIRST Dataset | IRSTD-1k Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IoU | IoU | IoU | ||||||||
| 5 | 27.69 | 0.736 | 8.48 × 10−5 | 0.436 | 0.946 | 4.81 × 10−5 | 0.638 | 0.868 | 4.44 × 10−5 | 0.669 |
| 7 | 26.18 | 0.786 | 5.90 × 10−5 | 0.439 | 0.982 | 3.45 × 10−5 | 0.646 | 0.893 | 1.01 × 10−5 | 0.668 |
| 9 | 21.40 | 0.786 | 4.66 × 10−5 | 0.456 | 0.991 | 2.03 × 10−5 | 0.660 | 0.950 | 1.53 × 10−5 | 0.689 |
| 11 | 24.95 | 0.886 | 5.08 × 10−5 | 0.494 | 0.991 | 8.95 × 10−6 | 0.693 | 0.965 | 8.01 × 10−6 | 0.732 |
| 13 | 20.33 | 0.829 | 8.25 × 10−5 | 0.466 | 0.954 | 2.36 × 10−5 | 0.661 | 0.912 | 8.01 × 10−6 | 0.702 |
| Attention Mechanism | MFIRST Dataset | SIRST Dataset | IRSTD-1k Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IoU | IoU | IoU | |||||||
| CBAM | 0.857 | 6.71 × 10−5 | 0.465 | 0.912 | 5.86 × 10−6 | 0.656 | 0.894 | 3.45 × 10−6 | 0.661 |
| AMLR | 0.857 | 4.98 × 10−5 | 0.487 | 0.938 | 3.68 × 10−5 | 0.671 | 0.937 | 2.65 × 10−5 | 0.684 |
| LRIB | 0.886 | 5.08 × 10−5 | 0.494 | 0.991 | 8.95 × 10−6 | 0.693 | 0.965 | 8.01 × 10−6 | 0.732 |
| Method | Params/MB | MFIRST Dataset | SIRST Dataset | IRSTD-1k Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IoU | IoU | IoU | ||||||||
| IPI | - | 0.861 | 3.86 × 10−4 | 0.411 | 0.923 | 2.22 × 10−3 | 0.532 | 0.75 | 3.15 × 10−5 | 0.469 |
| MPCM | - | 0.828 | 9.58 × 10−3 | 0.402 | 0.945 | 1.30 × 10−2 | 0.120 | 0.956 | 6.09 × 10−3 | 0.483 |
| FKRW | - | 0.607 | 4.82 × 10−4 | 0.233 | 0.814 | 3.43 × 10−4 | 0.229 | 0.709 | 1.31 × 10−4 | 0.235 |
| ISTDU | 10.80 | 0.828 | 3.67 × 10−4 | 0.439 | 0.954 | 1.07 × 10−4 | 0.470 | 0.780 | 2.41 × 10−4 | 0.563 |
| DNANet | 54.26 | 0.692 | 2.35 × 10−4 | 0.351 | 0.889 | 2.63 × 10−4 | 0.464 | 0.815 | 1.84 × 10−5 | 0.611 |
| MDvsFA | 15.03 | 0.928 | 5.94 × 10−3 | 0.445 | 0.917 | 2.82 × 10−4 | 0.579 | 0.962 | 1.86 × 10−4 | 0.610 |
| MLCL | 6.44 | 0.478 | 9.46 × 10−5 | 0.251 | 0.565 | 1.65 × 10−5 | 0.350 | 0.808 | 2.81 × 10−5 | 0.616 |
| LPNet | 3.68 | 0.785 | 9.39 × 10−4 | 0.247 | 0.929 | 8.89 × 10−5 | 0.577 | 0.621 | 1.64 × 10−4 | 0.320 |
| ACM | 1.97 | 0.743 | 3.50 × 10−4 | 0.353 | 0.788 | 1.45 × 10−3 | 0.435 | 0.872 | 5.69 × 10−3 | 0.498 |
| ISNet | 4.21 | 0.700 | 1.69 × 10−5 | 0.482 | 0.859 | 7.87 × 10−5 | 0.459 | 0.886 | 4.47 × 10−5 | 0.541 |
| IAANet | 75.37 | 0.876 | 1.30 × 10−4 | 0.508 | 0.947 | 1.01 × 10−5 | 0.546 | 0.922 | 2.36 × 10−4 | 0.345 |
| AGPC | 47.33 | 0.607 | 2.12 × 10−5 | 0.322 | 0.823 | 3.72 × 10−5 | 0.538 | 0.829 | 1.74 × 10−4 | 0.411 |
| Ours | 24.95 | 0.886 | 1.08 × 10−5 | 0.494 | 0.991 | 8.95 × 10−6 | 0.693 | 0.965 | 8.01 × 10−6 | 0.732 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Han, C.; Li, J.; Nie, T.; Li, M.; Wang, X.; Huang, L. Infrared Dim Small Target Detection Algorithm with Large-Size Receptive Fields. Remote Sens. 2025, 17, 307. https://doi.org/10.3390/rs17020307
Wang X, Han C, Li J, Nie T, Li M, Wang X, Huang L. Infrared Dim Small Target Detection Algorithm with Large-Size Receptive Fields. Remote Sensing. 2025; 17(2):307. https://doi.org/10.3390/rs17020307
Chicago/Turabian StyleWang, Xiaozhen, Chengshan Han, Jiaqi Li, Ting Nie, Mingxuan Li, Xiaofeng Wang, and Liang Huang. 2025. "Infrared Dim Small Target Detection Algorithm with Large-Size Receptive Fields" Remote Sensing 17, no. 2: 307. https://doi.org/10.3390/rs17020307
APA StyleWang, X., Han, C., Li, J., Nie, T., Li, M., Wang, X., & Huang, L. (2025). Infrared Dim Small Target Detection Algorithm with Large-Size Receptive Fields. Remote Sensing, 17(2), 307. https://doi.org/10.3390/rs17020307