
Hybrid Offset Position Encoding for Large-Scale Point Cloud Semantic Segmentation
Abstract
1. Introduction
- We review current mainstream positional embedding methods, compare these methods intuitively, and summarize their advantages and disadvantages.
- We propose Hybrid Offset Position Encoding (HOPE), which enhances relative position encoding within the local receptive field through an attention mechanism guided by explicit structures. Additionally, we introduce offset position encoding derived from the global receptive field. These two encodings are adaptively combined, boosting the spatial awareness of the network’s deep encoder with minimal computational overhead, thereby improving performance on large-scale point cloud semantic segmentation tasks.
- We validate the effectiveness and generalizability of our module through experiments on point cloud semantic segmentation tasks across multiple large-scale datasets and baselines.
2. Related Work
2.1. Point-Based Network
2.2. Attention Mechanism
2.3. Positional Encoding
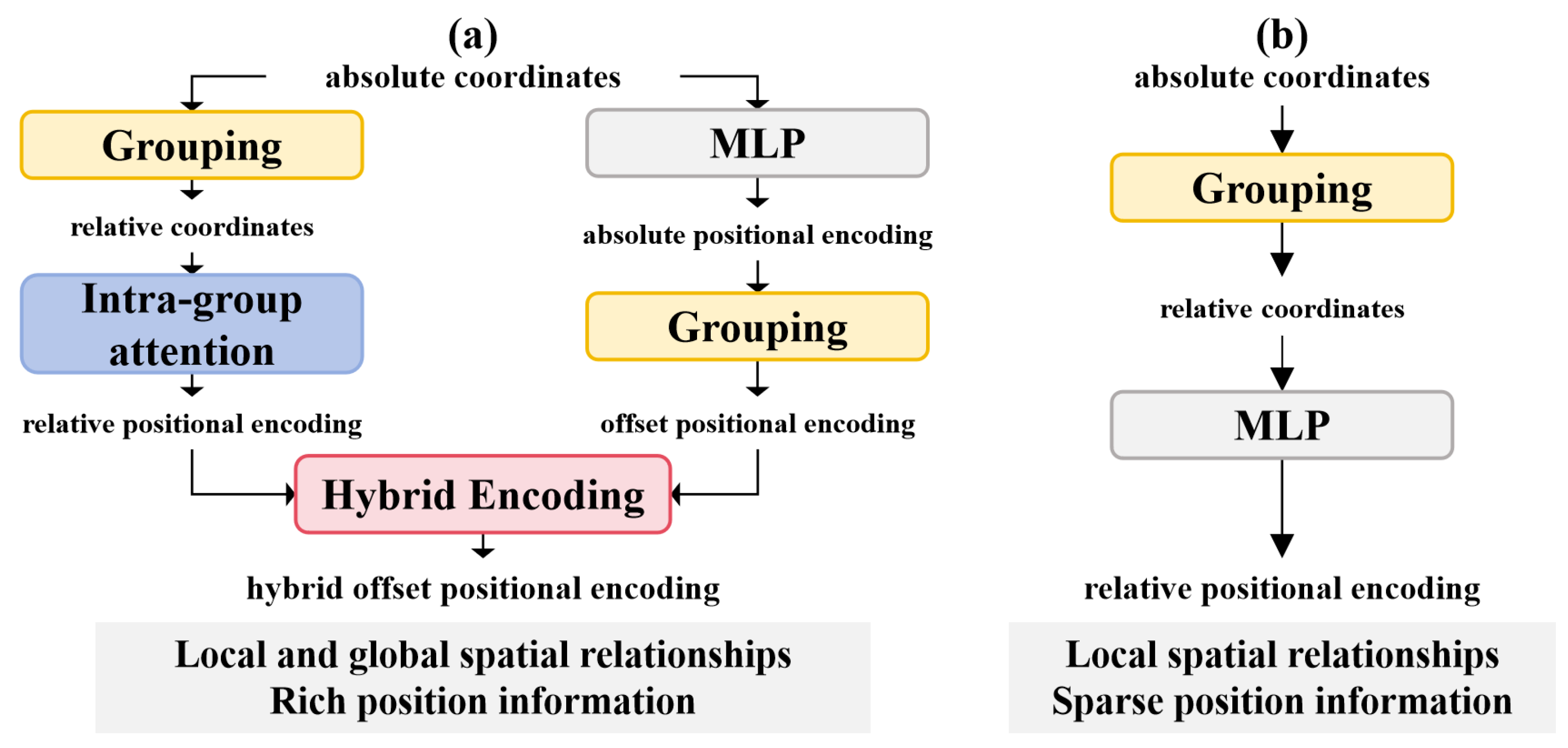
3. Rethinking Point Cloud Position Embedding
- -
- -
- -
3.1. The Background of Local Aggregation
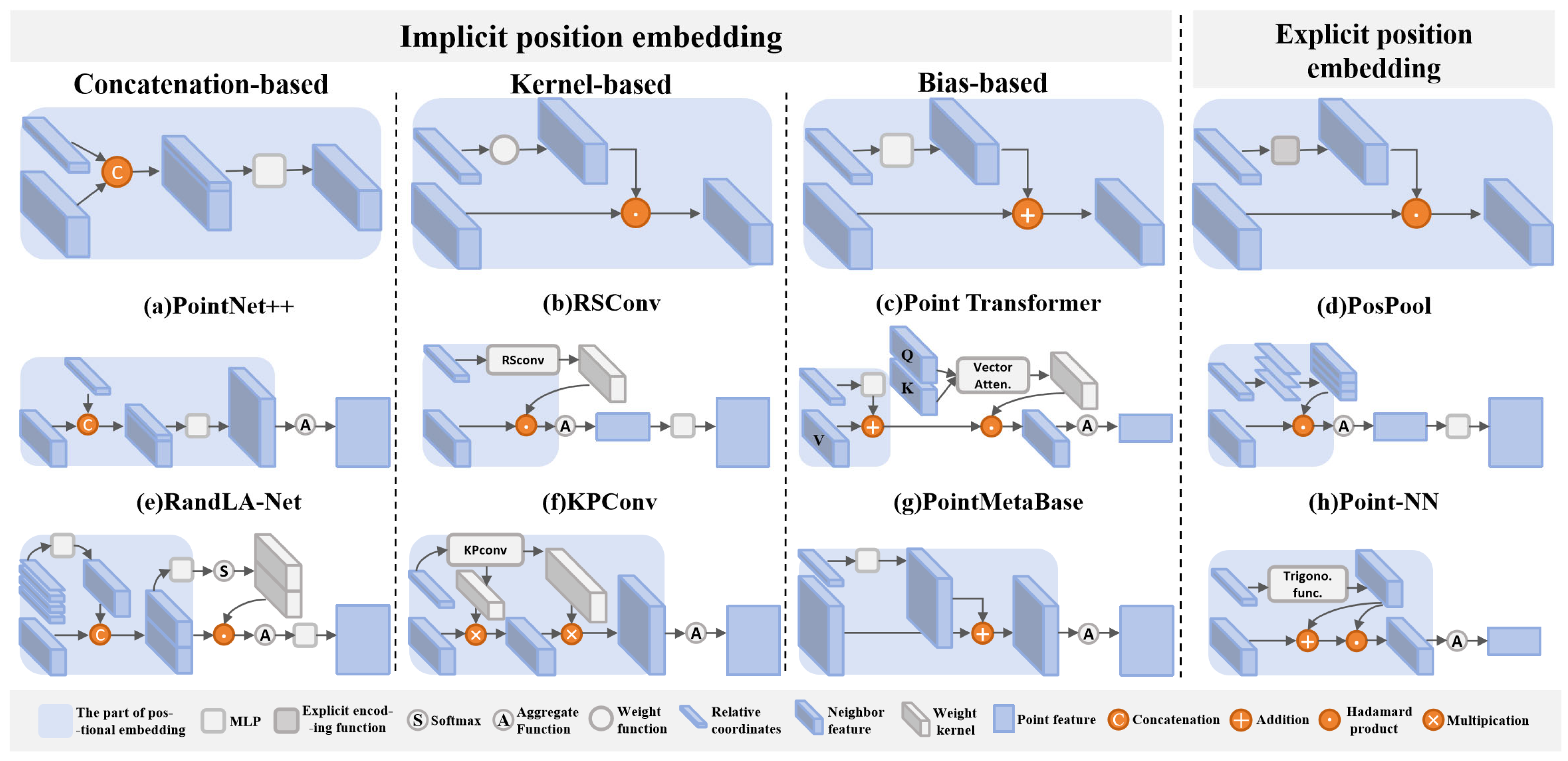
3.2. Implicit Position Embedding
3.2.1. Concatenation-Based Position Embedding
3.2.2. Kernel-Based Position Embedding
3.2.3. Bias-Based Position Embedding
3.3. Explicit Position Embedding
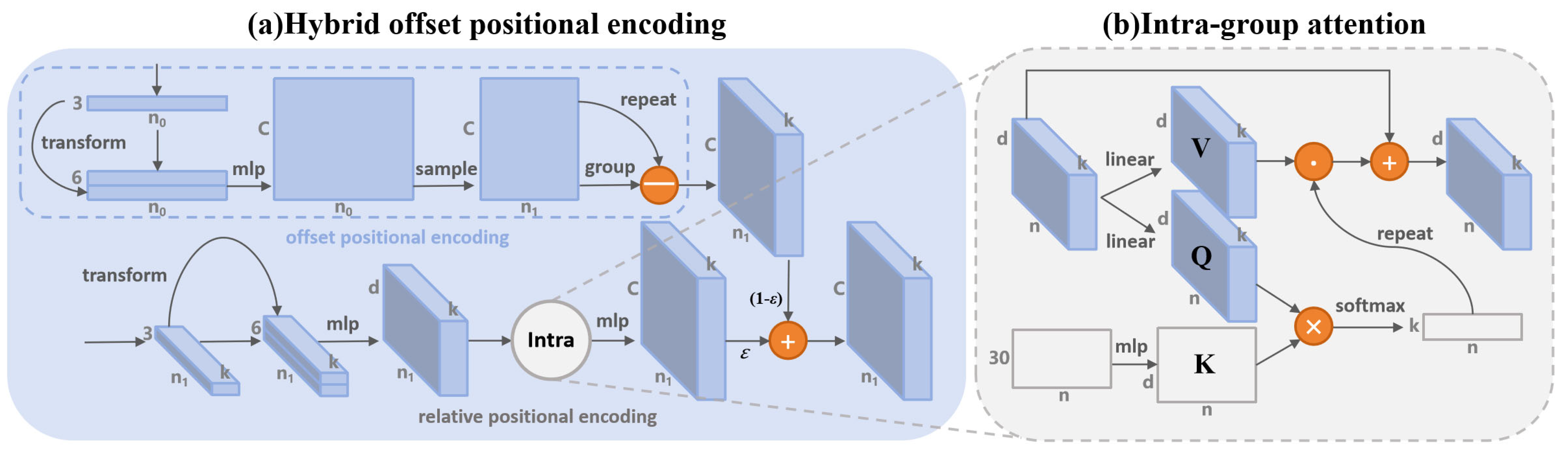
4. Method
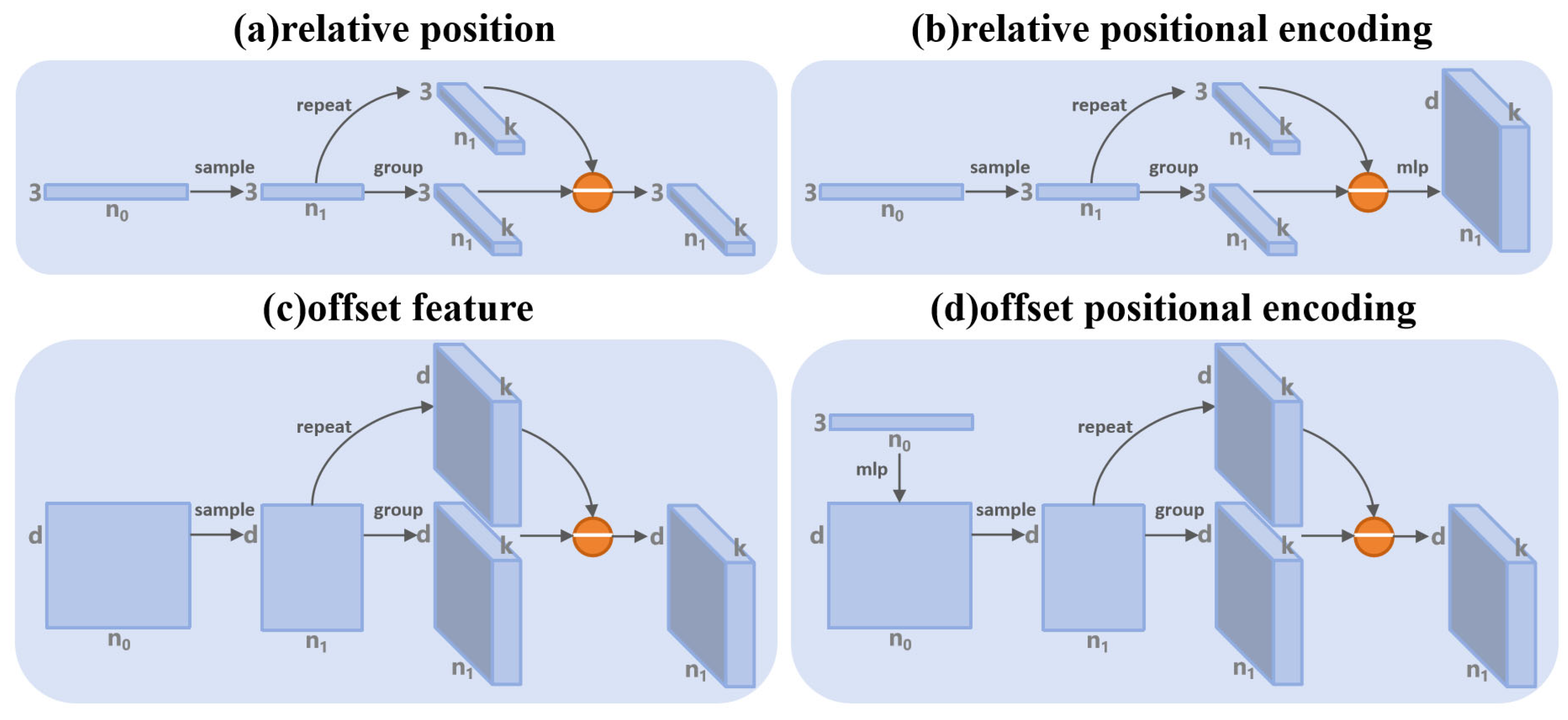
4.1. Relative Positional Encoding
4.2. Offset Positional Encoding
4.3. Hybrid Encoding
5. Experiments
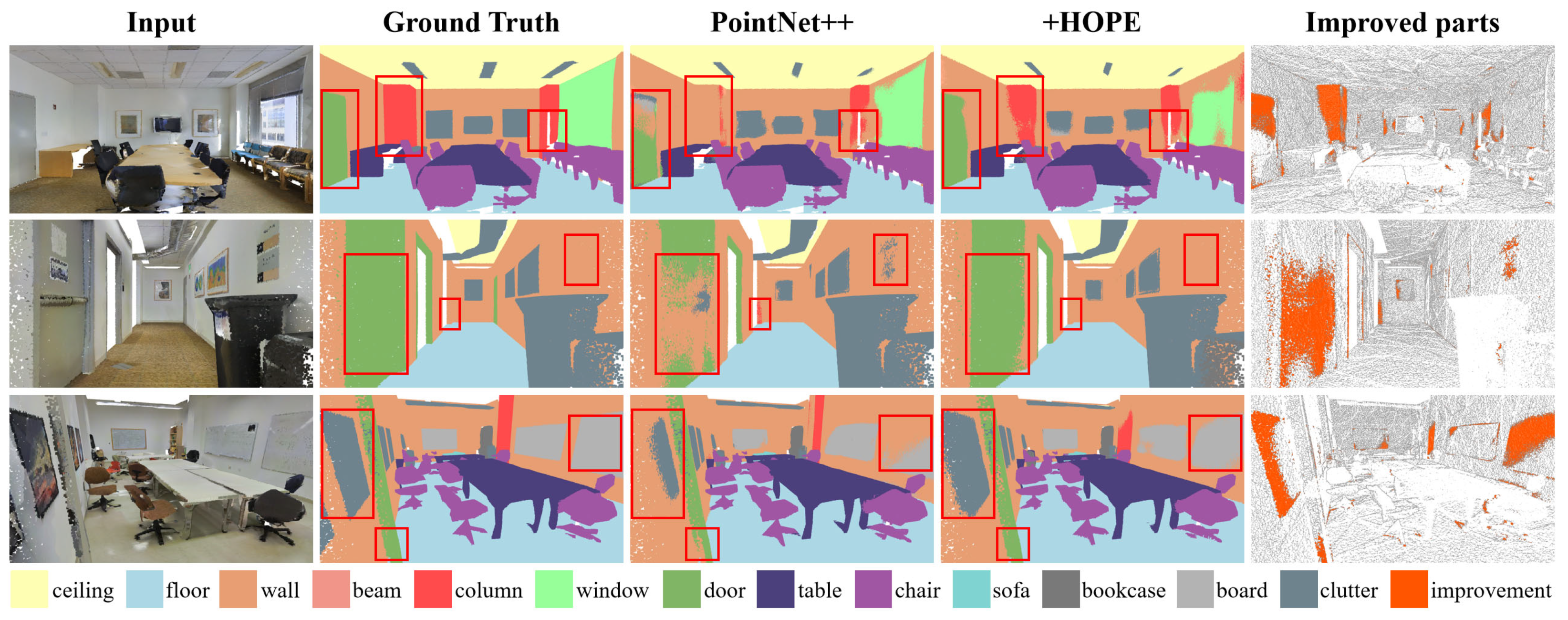
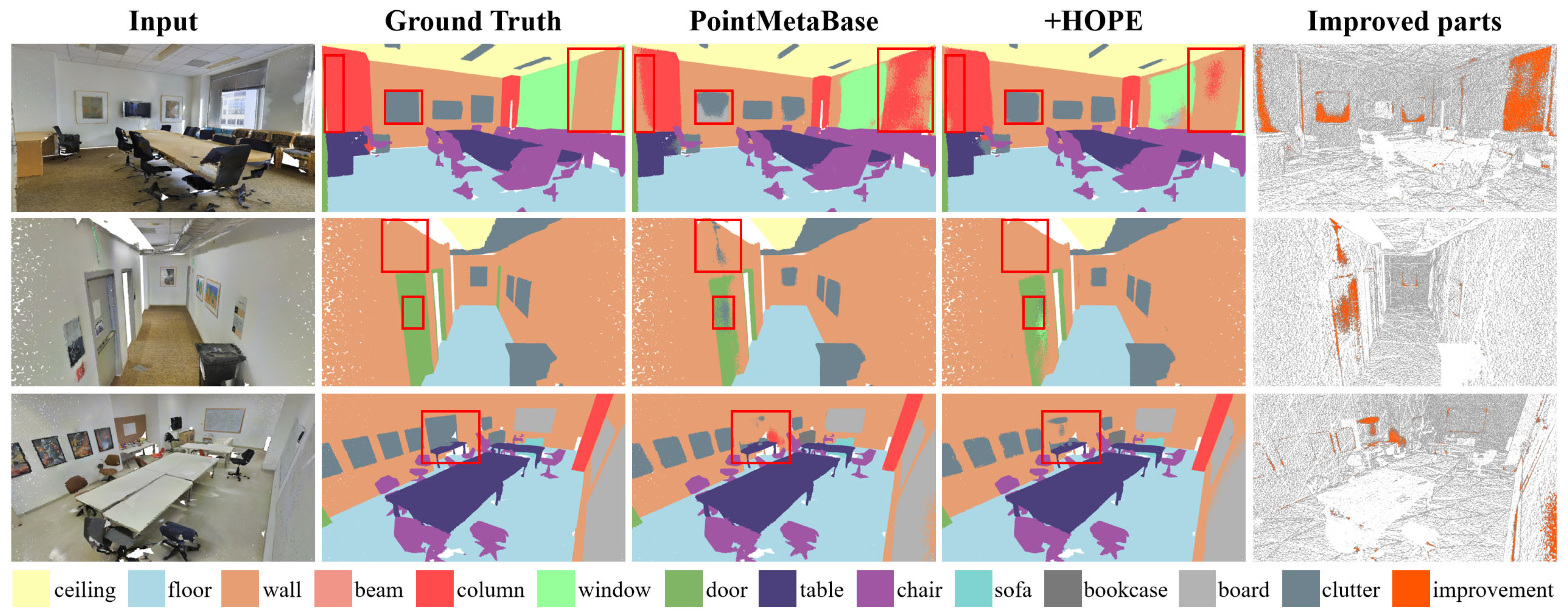
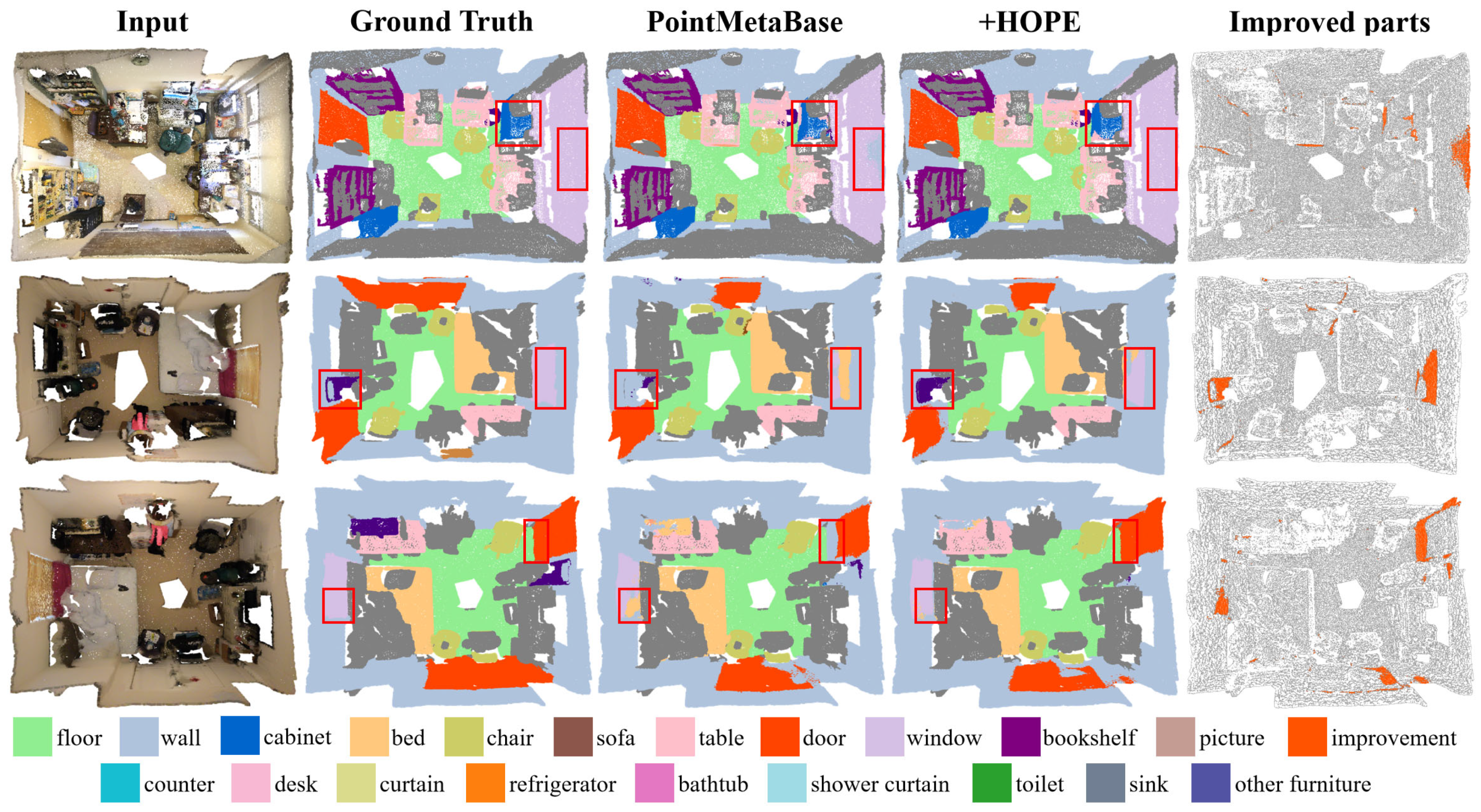
5.1. Large-Scale Point Cloud Semantic Segmentation
5.1.1. Evaluation on S3DIS
5.1.2. Evaluation on ScanNet
5.1.3. Evaluation on Toronto3D
5.2. Ablation Experiments
5.2.1. Ablation of HOPE’s Internal Modules
5.2.2. Ablation of Hybrid Encoding
5.2.3. Complexity Analysis
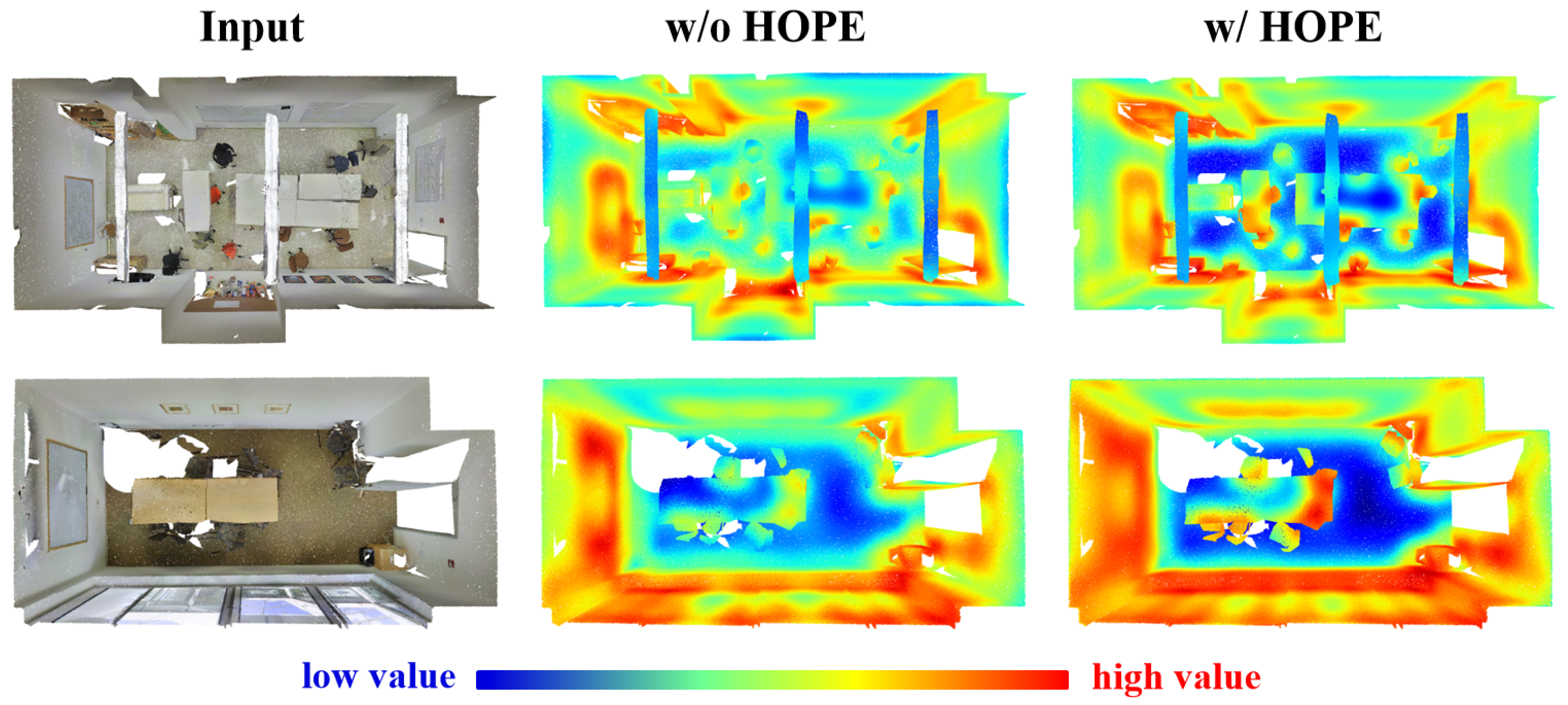
5.2.4. Heatmap Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (Tog) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-shape convolutional neural network for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 8895–8904. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Qian, G.; Li, Y.; Peng, H.; Mai, J.; Hammoud, H.; Elhoseiny, M.; Ghanem, B. Pointnext: Revisiting pointnet++ with improved training and scaling strategies. Adv. Neural Inf. Process. Syst. 2022, 35, 23192–23204. [Google Scholar]
- Lin, H.; Zheng, X.; Li, L.; Chao, F.; Wang, S.; Wang, Y.; Tian, Y.; Ji, R. Meta architecture for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 17682–17691. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Hu, H.; Wang, F.; Zhang, Z.; Wang, Y.; Hu, L.; Zhang, Y. GAM: Gradient attention module of optimization for point clouds analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, Pennsylvania, 26 June 2023; Volume 37, pp. 835–843. [Google Scholar]
- Choe, J.; Park, C.; Rameau, F.; Park, J.; Kweon, I.S. Pointmixer: Mlp-mixer for point cloud understanding. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer Nature Switzerland: Cham, Switzerland; pp. 620–640. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. Spidercnn: Deep learning on point sets with parameterized convolutional filters. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 87–102. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep parametric continuous convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2589–2597. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. Paconv: Position adaptive convolution with dynamic kernel assembling on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 3173–3182. [Google Scholar]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point transformer v2: Grouped vector attention and partition-based pooling. Adv. Neural Inf. Process. Syst. 2022, 35, 33330–33342. [Google Scholar]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 8500–8509. [Google Scholar]
- Zhang, R.; Wang, L.; Guo, Z.; Wang, Y.; Gao, P.; Li, H.; Shi, J. Parameter is not all you need: Starting from non-parametric networks for 3d point cloud analysis. arXiv 2023, arXiv:2303.08134. [Google Scholar]
- Zhu, X.; Zhang, R.; He, B.; Guo, Z.; Liu, J.; Xiao, H.; Fu, C.; Dong, H.; Gao, P. No Time to Train: Empowering Non-Parametric Networks for Few-shot 3D Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024, Seattle, WA, USA, 16–22 June 2024; pp. 3838–3847. [Google Scholar]
- Qian, G.; Hammoud, H.; Li, G.; Thabet, A.; Ghanem, B. Assanet: An anisotropic separable set abstraction for efficient point cloud representation learning. Adv. Neural Inf. Process. Syst. 2021, 34, 28119–28130. [Google Scholar]
- Liu, Z.; Hu, H.; Cao, Y.; Zhang, Z.; Tong, X. A closer look at local aggregation operators in point cloud analysis. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 326–342. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 18 May 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 5565–5573. [Google Scholar]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking network design and local geometry in point cloud: A simple residual MLP framework. arXiv 2022, arXiv:2202.07123. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning spatial contextual features for large-scale point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 14504–14513. [Google Scholar]
- Liu, Z.; Zhou, S.; Suo, C.; Yin, P.; Chen, W.; Wang, H.; Li, H.; Liu, Y.H. Lpd-net: 3d point cloud learning for large-scale place recognition and environment analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2831–2840. [Google Scholar]
- Shuai, H.; Liu, Q. Geometry-injected image-based point cloud semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–10. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 1757–1767. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef]
- Chu, X.; Zhao, S. Adaptive Guided Convolution Generated With Spatial Relationships for Point Clouds Analysis. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–12. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2626–2635. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Hermans, A.; Leibe, B. Exploring spatial context for 3D semantic segmentation of point clouds. In Proceedings of the IEEE International Conference on Computer Vision Workshops 2017, Venice, Italy, 22–29 October 2017; pp. 716–724. [Google Scholar]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3d recurrent neural networks with context fusion for point cloud semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 403–417. [Google Scholar]
- Liu, X.; Han, Z.; Liu, Y.S.; Zwicker, M. Point2sequence: Learning the shape representation of 3d point clouds with an attention-based sequence to sequence network. In Proceedings of the AAAI Conference on Artificial Intelligence 2019, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8778–8785. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9267–9276. [Google Scholar]
- Landrieu, L.; Boussaha, M. Point cloud oversegmentation with graph-structured deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 7440–7449. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 10296–10305. [Google Scholar]
- Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar]
- Kenton, J.D.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 7 January 2025).
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Alexey, D. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 2019, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615. [Google Scholar]
- Yang, J.; Zhang, Q.; Ni, B.; Li, L.; Liu, J.; Zhou, M.; Tian, Q. Modeling point clouds with self-attention and gumbel subset sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3323–3332. [Google Scholar]
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S.Z.; Mian, A. Point attention network for semantic segmentation of 3D point clouds. Pattern Recognit. 2020, 107, 107446. [Google Scholar] [CrossRef]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set transformer: A framework for attention-based permutation-invariant neural networks. In Proceedings of the International Conference on Machine Learning 2019, Long Beach, CA, USA, 10–15 June 2019; pp. 3744–3753. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3d object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 7463–7472. [Google Scholar]
- Park, J.; Lee, S.; Kim, S.; Xiong, Y.; Kim, H.J. Self-positioning point-based transformer for point cloud understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 21814–21823. [Google Scholar]
- Wu, K.; Peng, H.; Chen, M.; Fu, J.; Chao, H. Rethinking and improving relative position encoding for vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 10033–10041. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the International Conference on Machine Learning 2017, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Dai, Z. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Chen, B.; Xia, Y.; Zang, Y.; Wang, C.; Li, J. Decoupled local aggregation for point cloud learning. arXiv 2023, arXiv:2308.16532. [Google Scholar]
- Duan, L.; Zhao, S.; Xue, N.; Gong, M.; Xia, G.S.; Tao, D. Condaformer: Disassembled transformer with local structure enhancement for 3d point cloud understanding. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Zeng, Z.; Qiu, H.; Zhou, J.; Dong, Z.; Xiao, J.; Li, B. PointNAT: Large Scale Point Cloud Semantic Segmentation via Neighbor Aggregation with Transformer. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Ran, H.; Liu, J.; Wang, C. Surface representation for point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 18942–18952. [Google Scholar]
- Deng, X.; Zhang, W.; Ding, Q.; Zhang, X. Pointvector: A vector representation in point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 9455–9465. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Vázquez, P.P.; Vinacua, À.; Ropinski, T. Monte carlo convolution for learning on non-uniformly sampled point clouds. ACM Trans. Graph. (TOG) 2018, 37, 1–12. [Google Scholar] [CrossRef]
- Sun, S.; Rao, Y.; Lu, J.; Yan, H. X-3D: Explicit 3D Structure Modeling for Point Cloud Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024, Seattle, WA, USA, 16–22 June 2024; pp. 5074–5083. [Google Scholar]
- Zhang, M.; You, H.; Kadam, P.; Liu, S.; Kuo, C.C. Pointhop: An explainable machine learning method for point cloud classification. IEEE Trans. Multimed. 2020, 22, 1744–1755. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Robert, D.; Raguet, H.; Landrieu, L. Efficient 3D semantic segmentation with superpoint transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 1–6 October 2023; pp. 17195–17204. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A large-scale mobile LiDAR dataset for semantic segmentation of urban roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 2020, Seattle, WA, USA, 14–19 June 2020; pp. 202–203. [Google Scholar]
- Du, J.; Cai, G.; Wang, Z.; Huang, S.; Su, J.; Junior, J.M.; Smit, J.; Li, J. ResDLPS-Net: Joint residual-dense optimization for large-scale point cloud semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 182, 37–51. [Google Scholar] [CrossRef]
- Shuai, H.; Xu, X.; Liu, Q. Backward attentive fusing network with local aggregation classifier for 3D point cloud semantic segmentation. IEEE Trans. Image Process. 2021, 30, 4973–4984. [Google Scholar] [CrossRef]
- Zeng, Z.; Xu, Y.; Xie, Z.; Tang, W.; Wan, J.; Wu, W. LEARD-Net: Semantic segmentation for large-scale point cloud scene. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102953. [Google Scholar] [CrossRef]
- Xu, Y.; Tang, W.; Zeng, Z.; Wu, W.; Wan, J.; Guo, H.; Xie, Z. NeiEA-NET: Semantic segmentation of large-scale point cloud scene via neighbor enhancement and aggregation. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103285. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Z.; Li, Y.; Huang, M.; Zhang, J. SFL-Net: Slight filter learning network for point cloud semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | S3DIS Area-5 | FLOPs (G) | Params. (M) | Throughput (ins./s) | ||
|---|---|---|---|---|---|---|
| mIoU (%) | mAcc (%) | OA (%) | ||||
| PointNet++ [2] | 53.5 | - | 83.0 | 7.2 | 1.0 | 186 |
| ASSANet [21] | 63.0 | - | - | 2.5 | 2.4 | - |
| Point Transformer [10] | 70.4 | 76.5 | 90.8 | 5.6 | 7.8 | 34 |
| PointNeXt-XL [8] | 71.1 | 77.5 | 91.0 | 84.8 | 41.0 | 46 |
| PointVector-XL [73] | 72.3 | 78.1 | 91.0 | 58.5 | 24.1 | 40 |
| ConDaFormer [70] | 72.6 | - | 91.6 | - | - | - |
| PointNAT [71] | 72.8 | - | 91.5 | 12.9 | 24.9 | 135 |
| PointNet++* [2] | 63.6 | 70.2 | 88.3 | 7.2 | 1.0 | 186 |
| +HOPE | 65.7 (+2.1) | 72.2 (+2.0) | 88.9 (+0.6) | 6.9 | 1.1 | 185 |
| PointNeXt-L [8] | 69.5 | 76.1 | 90.1 | 15.2 | 7.1 | 115 |
| +HOPE | 71.2 (+1.7) | 77.5 (+1.4) | 90.7 (+0.6) | 14.8 | 7.2 | 117 |
| PointMetaBase-L [9] | 69.7 | 75.6 | 90.6 | 2.0 | 2.7 | 187 |
| +HOPE | 71.0 (+1.3) | 77.1 (+1.5) | 90.9 (+0.3) | 2.2 | 2.8 | 182 |
| PointMetaBase-XL [9] | 71.6 | 77.9 | 90.6 | 9.2 | 15.3 | 104 |
| +HOPE | 72.6 (+1.0) | 78.9 (+1.0) | 91.0 (+0.4) | 9.6 | 15.4 | 100 |
| Method | mIoU | OA | Ceil. | Floor | Wall | Beam | col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [1] | 47.6 | 78.6 | 88.0 | 88.7 | 69.3 | 42.4 | 23.1 | 47.5 | 51.6 | 54.1 | 42.0 | 9.6 | 38.2 | 29.4 | 35.2 |
| DGCNN [3] | 55.5 | 84.5 | 93.2 | 95.9 | 72.8 | 54.6 | 32.2 | 56.2 | 50.7 | 62.8 | 63.4 | 22.7 | 38.2 | 32.5 | 46.8 |
| PointCNN [6] | 65.4 | 88.1 | 94.2 | 97.3 | 75.8 | 63.3 | 51.7 | 58.4 | 57.2 | 71.6 | 69.1 | 39.1 | 61.2 | 52.2 | 58.6 |
| KPConv [5] | 70.6 | - | 93.6 | 92.4 | 83.1 | 63.9 | 54.3 | 66.1 | 76.6 | 57.8 | 64.0 | 69.3 | 74.9 | 61.3 | 60.3 |
| RandLA-Net [7] | 70.0 | 88.0 | 93.1 | 96.1 | 80.6 | 62.4 | 48.0 | 64.4 | 69.4 | 69.4 | 76.4 | 60.0 | 64.2 | 65.9 | 60.1 |
| Point Transformer [10] | 73.5 | 90.2 | 94.3 | 97.5 | 84.7 | 55.6 | 58.1 | 66.1 | 78.2 | 77.6 | 74.1 | 67.3 | 71.2 | 65.7 | 64.8 |
| SPTransformer [78] | 76.0 | - | 93.9 | 96.3 | 84.3 | 71.4 | 61.3 | 70.1 | 78.2 | 84.6 | 74.1 | 67.8 | 77.1 | 63.6 | 65.0 |
| PointNAT [71] | 77.8 | 91.7 | 94.7 | 97.9 | 85.8 | 65.3 | 63.5 | 72.8 | 79.7 | 77.3 | 81.7 | 78.4 | 76.8 | 72.1 | 65.3 |
| PointNet++* [2] | 68.1 | 87.6 | 93.5 | 94.0 | 81.4 | 54.2 | 48.8 | 59.8 | 74.0 | 71.6 | 67.8 | 56.6 | 64.3 | 62.7 | 56.5 |
| +HOPE | 70.6 (+2.5) | 88.6 (+1.0) | 92.8 | 93.9 | 83.7 | 50.7 | 56.6 | 61.4 | 81.7 | 74.5 | 66.4 | 58.2 | 67.6 | 66.6 | 63.5 |
| PointMetaBase-L [9] | 75.6 | 90.6 | 94.9 | 97.6 | 85.4 | 68.6 | 62.0 | 66.8 | 80.1 | 76.5 | 71.1 | 77.3 | 69.5 | 68.6 | 64.8 |
| +HOPE | 76.7 (+1.1) | 91.1 (+0.5) | 95.0 | 97.2 | 84.3 | 65.2 | 64.2 | 67.5 | 81.2 | 79.6 | 75.8 | 80.2 | 72.1 | 69.2 | 65.5 |
| Method | ScanNet | FLOPs (G) | Params. (M) |
|---|---|---|---|
| mIoU (%) | |||
| PointCNN [6] | 45.8 | - | 0.6 |
| PointNet++ [2] | 53.5 | 7.2 | 1.0 |
| KPConv [5] | 68.4 | - | 15.0 |
| Point Transformer [10] | 70.6 | 5.6 | 7.8 |
| RepSurf [72] | 70.0 | - | - |
| PointNeXt-XL [8] | 71.5 | 84.8 | 41.0 |
| PointMetaBase-XL [9] | 71.8 | 9.2 | 15.3 |
| PointNet++* [2] | 57.2 | 7.2 | 1.0 |
| +HOPE | 58.7 (+1.5) | 6.9 | 1.1 |
| PointMetaBase.-L [9] | 71.0 | 2.0 | 2.7 |
| +HOPE | 71.6 (+0.6) | 2.2 | 2.8 |
| Method | OA (%) | mIoU (%) | Road | Road mrk. | Natural | Buil. | Util.line | Pole | Car | Fence |
|---|---|---|---|---|---|---|---|---|---|---|
| ResDLPS-Net [81] | 96.5 | 80.3 | 95.8 | 59.8 | 96.1 | 91.0 | 86.8 | 79.9 | 89.4 | 43.3 |
| RandLA-Net [7] | 94.4 | 81.8 | 96.7 | 64.2 | 96.9 | 94.2 | 88.0 | 77.8 | 93.4 | 42.9 |
| BAF-LAC [82] | 95.2 | 82.2 | 96.6 | 64.7 | 96.4 | 92.8 | 86.1 | 83.9 | 93.7 | 43.5 |
| BAAF-Net [35] | 94.2 | 81.2 | 96.8 | 67.3 | 96.8 | 92.2 | 86.8 | 82.3 | 93.1 | 34.0 |
| LEARD-Net [83] | 97.3 | 82.2 | 97.1 | 65.2 | 96.9 | 92.8 | 87.4 | 78.6 | 94.5 | 45.2 |
| NeiEA-Net [84] | 97.0 | 80.9 | 97.1 | 66.9 | 97.3 | 93.0 | 87.3 | 83.4 | 93.4 | 43.1 |
| SFL-Net [85] | 97.6 | 81.9 | 97.7 | 70.7 | 95.8 | 91.7 | 87.4 | 78.8 | 92.3 | 40.8 |
| RandLA-Net* [7] | 94.8 | 81.2 | 95.3 | 66.6 | 96.8 | 92.6 | 86.7 | 85.6 | 85.5 | 40.1 |
| +HOPE | 96.0 (+1.2) | 82.6 (+1.4) | 95.9 | 58.3 | 98.0 | 95.5 | 89.4 | 85.1 | 94.3 | 44.6 |
| ID | Module | mIoU | ||||
|---|---|---|---|---|---|---|
| RPE | Sphere | Intra Atten. | OPE | PointNet++ | PointMeta.-L | |
| A1 | 63.6 | 69.7 | ||||
| A2 | 63.2 | 69.1 | ||||
| A3 | 64.0 | 69.7 | ||||
| A4 | 64.1 | 70.0 | ||||
| A5 | 64.8 | 70.5 | ||||
| A6 | 65.7 | 71.0 | ||||
| ID | The Method of Fusion | mIoU | |
|---|---|---|---|
| PointNet++ | PointMeta.-L | ||
| B1 | OPE | 65.3 | 70.6 |
| B2 | OPE | 63.9 | 69.3 |
| B3 | OPE | 63.5 | 69.8 |
| B4 | )OPE | 65.7 | 71.0 |
| ID | Module | FLOPs (G) | Params. (M) | Throughput (ins./s) |
|---|---|---|---|---|
| C1 | PointMeta.-L + RPE | 1.98 | 2.74 | 189 |
| C2 | PointMeta.-L + RPE + Sphere | 2.01 | 2.74 | 189 |
| C3 | PointMeta.-L + RPE + Sphere + IntraAtten. | 2.20 | 2.77 | 187 |
| C4 | PointMeta.-L + RPE + Sphere + IntraAtten. + OPE | 2.23 | 2.79 | 182 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Wu, H.; Chen, Y.; Chen, C.; Dong, R.; Lin, D. Hybrid Offset Position Encoding for Large-Scale Point Cloud Semantic Segmentation. Remote Sens. 2025, 17, 256. https://doi.org/10.3390/rs17020256
Xiao Y, Wu H, Chen Y, Chen C, Dong R, Lin D. Hybrid Offset Position Encoding for Large-Scale Point Cloud Semantic Segmentation. Remote Sensing. 2025; 17(2):256. https://doi.org/10.3390/rs17020256
Chicago/Turabian StyleXiao, Yu, Hui Wu, Yisheng Chen, Chongcheng Chen, Ruihai Dong, and Ding Lin. 2025. "Hybrid Offset Position Encoding for Large-Scale Point Cloud Semantic Segmentation" Remote Sensing 17, no. 2: 256. https://doi.org/10.3390/rs17020256
APA StyleXiao, Y., Wu, H., Chen, Y., Chen, C., Dong, R., & Lin, D. (2025). Hybrid Offset Position Encoding for Large-Scale Point Cloud Semantic Segmentation. Remote Sensing, 17(2), 256. https://doi.org/10.3390/rs17020256