5.1. Datasets and Experimental Settings
The experiments were performed on an Ubuntu 23.04 system with an Intel Xeon E5-2620 CPU (Intel, Santa Clara, CA, USA) and NVIDIA GeForce Titan Xp GPU (NVIDIA, Santa Clara, CA, USA), utilizing CUDA 12.2 for GPU acceleration. The deep learning model was implemented using PyTorch 2.1.0 in a Python 3.10 environment. To validate SFDGNet’s effectiveness, both S3DIS [
59] and ScanNet v2 [
60] datasets were employed. For S3DIS processing, rooms were divided into
blocks, with each block center represented by a 9D vector containing XYZ coordinates, RGB values, and normalized spatial coordinates. From each block, 4096 points were randomly sampled for feature extraction. The dataset was split into five areas for training and one for testing, followed by 6-fold cross-validation across all areas to evaluate semantic segmentation performance. The schematic visualization of
1 and
6 on the S3DIS dataset is shown in
Figure 7. Training parameters included: 100 epochs per area, initial learning rate of 0.01 (SGD optimizer), with
, and neighborhood ranges
. The ScanNet v2 dataset underwent identical preprocessing, using scenes 01-06 for training and 07-08 for testing. Training employed the Adam optimizer with an initial learning rate of 0.01, decay rate of 0.0001, and ran for 200 epochs. The schematic visualization of Scene05 on the ScanNet v2 datasets is shown in
Figure 8.
5.2. Evaluation Metrics
The evaluation criteria used to assess the effectiveness of network models for feature selection and semantic segmentation are . The evaluation metric for feature sparsity is sparsity.
is a metric utilized in semantic segmentation tasks to assess the overall accuracy of the entire scene segmentation. It primarily determines the proportion of all pixels that are correctly categorized, irrespective of the specific category to which they belong, provided that they are correctly categorized, as defined in Equation (
19).
where
, and
represent the number of true positives, false positives, true negatives, and false negatives, respectively.
is defined as the mean of the classification accuracy for each category. Classification accuracy is calculated as the ratio of the number of correctly classified pixels for a given category to the total number of pixels in that category, as defined in Equation (
20).
is a measure of the degree of overlap between the predicted segmentation region and the true segmentation region.
is the average of all category
and is used to assess the average performance of the model for each category of segmentation effect, as defined in Equation (
21).
Sparsity is evaluated by assuming that weights with absolute values less than
are zero, and by calculating the ratio of zero weights to the total number of weights in order to measure the sparsity of the learned features. Here,
denotes the total number of elements in the weight matrix, and
denotes the number of points in the weight matrix whose absolute values are less than a certain threshold (which is 0.001 in this paper) as defined in Equation (
22).
5.3. Analysis of the k Value in the Neighborhood Search Range
The network obtains neighborhood information of each center point using a k-nearest neighborhood algorithm (k-NN). Based on the center point and its neighboring points, the SEConv module constructs a local neighborhood graph to extract local geometric features of our point cloud. The value of k primarily affects the search scope of the k-NN algorithm and the size of the constructed neighborhood graph, thereby directly influencing the granularity of feature extraction and computational efficiency. When k is small, the search range is limited and the resulting local graph is more compact, leading to lower computational costs and faster training and inference. However, the limited neighborhood information may result in insufficient feature representation and degraded segmentation accuracy. In contrast, a larger k allows the model to capture more comprehensive local structures and contextual relationships, enhancing its discriminative ability. Nevertheless, this also significantly increases the computational complexity of both the k-NN search and feature aggregation, resulting in longer training and inference times.
To analyze the impact of different
k-value configurations on the semantic segmentation performance of the network and to determine the most effective multi-neighborhood range, we conducted comparative experiments on
2 and
4 of the S3DIS dataset. The baseline model, DGCNN, yields the lowest segmentation accuracy on
2 among all six regions, while performing relatively well on
4. Therefore, selecting these two regions allows us to effectively observe performance variations under different k settings. The experimental results are summarized in
Table 1. To further analyze which semantic categories are most affected by different k-values, we also present per-class IoU results for
2 across all 13 semantic categories in
Table 2.
The experimental results in
Table 1 demonstrate that the value of k significantly influences segmentation performance. Optimal outcomes can be observed across all four evaluation metrics (
and
) when
k equals (4,8,12). When
k is set to (6,8,10), the selected neighborhood ranges are relatively large, which limits the model’s ability to capture small-range local features, resulting in small-range and large-range neighborhood features not being complementary. When
k is set to (4,6,8) and (4,8,12), the ability to include both medium-range and smaller-range neighborhoods allows the model to learn more diverse and rich local features. Analysis of
Table 2 reveals that setting
k to (2,4,6) yields inferior
values for all semantic categories except clutter in
2 compared to other parameter groups. This performance drop is attributed to the insufficient feature information captured within small neighborhood ranges, which results in unrepresentative local features and degraded segmentation performance. In contrast, the
k values of (4,8,12) achieve peak
scores across nine out of thirteen categories, confirming that balanced consideration of both small and large neighborhood ranges during feature extraction substantially improves semantic segmentation accuracy. Therefore, based on comprehensive evaluations of
Table 1 and
Table 2, (4,8,12) is determined as the optimal neighborhood range for parameter
k.
5.4. Comparative Experiments
To verify the effectiveness of the proposed sparse feature selection-based point cloud semantic segmentation model, we conducted comparative experiments between SFDGNet and six mainstream semantic segmentation models on the S3DIS dataset: PointNet++ [
34], RSNet [
61], DGCNN [
43], Point-PlaneNet [
62], DeepGCNs-Att [
63], and HPRS [
64]. The comparison results are summarized in
Table 3.
The experimental results presented in
Table 3 indicate that the proposed SFDGNet model achieves state-of-the-art performance in terms of
and
metrics. The parallel acquisition of local neighborhood graphs with three different search ranges effectively enriches the feature information of central points. By incorporating the SEConv module, more comprehensive local features are extracted from point clouds, thereby overcoming the local feature deficiency inherent to the baseline DGCNN model. Additionally, the combined application of feature sparsity regularization and SEConv enables dynamic partitioning of input feature channels. This approach not only resolves the feature redundancy issue arising from multi-scale neighborhood feature extraction, but also enhances the model’s ability to learn sparse features in point clouds. As a result, the SFDGNet model demonstrates excellent performance in point cloud semantic segmentation tasks.
Table 4 compares the
performance of the proposed SFDGNet model with PointNet++ [
34], Point-PlaneNet [
62], and DeepGCNs-Att [
63] across all areas of the S3DIS dataset for 13 semantic categories. The results demonstrate that SFDGNet outperforms existing methods in most categories, showcasing its strong semantic understanding and feature discrimination capabilities. Notably, SFDGNet achieves the highest
scores in eight categories, namely, ceiling, wall, beam, column, window, table, chair, and board. Particularly significant improvements are observed in structurally distinct categories like beam and column, where SFDGNet surpasses DeepGCNs-Att by 18.2% and 8.1%, respectively, indicating its superior ability in extracting sparse geometric features. While SFDGNet does not achieve top performance in semantically ambiguous categories such as sofa and clutter, it maintains high performance levels, demonstrating balanced capabilities in feature suppression and semantic boundary preservation. Analysis of
Table 3 and
Table 4 confirms that SFDGNet excels in all evaluation metrics for point cloud semantic segmentation, with superior
performance across most categories, thus validating its effectiveness for this task.
Figure 9 illustrates the segmentation performance comparison among SFDGNet, RSNet [
61], DGCNN [
43], Point-PlaneNet [
62], and DeepGCNs-Att [
63] across five different scenes in
1 of S3DIS. Combining the results of the visualization in
Figure 9 and the statistical data in
Table 4, we can conclude that SFDGNet shows advantages in recognizing small objects, such as beam, column, window, board, bookcase, and the model achieves higher
scores than other methods. When processing complex spatial arrangements, such as furniture layouts in copy rooms, SFDGNet significantly reduces erroneous clutter labeling that undermines the performance of Point-PlaneNet. Moreover, SFDGNet demonstrates enhanced boundary discrimination, effectively minimizing inter-class mistake classification errors.
Figure 10 illustrates the segmentation performance comparison among SFDGNet, RSNet [
61], DGCNN [
43], Point-PlaneNet [
62], and DeepGCNs-Att [
63] in five different scenes from Area6 of S3DIS. The visualization reveals that SFDGNet achieves accurate segmentation of multiple object categories, including bookcases, chairs, and walls in both conference room and copy room scenarios, successfully addressing the inter-class confusion commonly found in other models. For Office1 and Office2 environments, SFDGNet demonstrates superior recognition accuracy for tables, sofas, and clutter compared to DGCNN and DeepGCNs-Att, which show noticeable mistake classification patterns for these objects.
In order to verify the effectiveness and generalization ability of the feature sparse regularization method, we introduce the feature sparse regularization method and the
-norm regularization approach on the PointNet++ and DGCNN network models, and conduct semantic segmentation experiments on the S3DIS dataset. The results are summarized in
Table 5.
The experimental results show that there are inherent limitations that lead to performance degradation when applied to semantic segmentation networks, such as sensitivity to outliers and neglect of parameter correlations, although the -norm regularization method can effectively improve the ability of the network model to extract sparse features. By contrast, the proposed feature sparsity regularization method addresses these issues through a weighted linear combination of sparse regularization and structured hierarchical sparsity regularization, effectively mitigating the -norm regularization method’s outlier sensitivity and tendency to produce excessive sparsity. This approach allows the network model to better utilize sparse features in point clouds, consequently enhancing the effectiveness of point cloud semantic segmentation.
To verify the effectiveness of the proposed SEConv module, comparative experiments were performed on
2 of the S3DIS by employing various local neighborhood feature extraction methods with the baseline DGCNN model.
Figure 11 illustrates the different feature extraction approaches. Subgraph (a) shows the serial structure of the baseline DGCNN, (b) shows the parallel multi-layer EdgeConv structure, (c) shows the parallel single-layer EdgeConv structure, and (d) shows the proposed parallel SEConv structure. The corresponding experimental results are summarized in
Table 6.
The experimental results in
Table 6 show that the proposed SEConv module significantly improves the semantic segmentation performance of the network. While the parallel single-layer EdgeConv structure, shown in
Figure 11c, adopts a relatively lightweight design with a parameter of 0.98M, its shallow representation capability limits its ability to capture deep semantic features of different neighborhood configurations, resulting in inferior performance to the serial EdgeConv baseline. While the parallel multi-layer EdgeConv structure, shown in
Figure 11b, increases the model depth and achieves a modest performance improvement with a parameter of 1.14M, it fails to mitigate the feature redundancy associated with the overlap of multi-neighborhood information. Compared to serial EdgeConv, as shown in
Figure 11a, the increase in the number of parameters in
Figure 11b derives from the replication of multiple deep EdgeConv branches, each of which independently processes features from different neighborhoods. This replication enhances feature diversity, but also leads to parameter duplication and inefficiency. In contrast, the parallel SEConv structure, shown in
Figure 11d, introduces a channel feature separation mechanism that distinguishes between representative and redundant features. This design learns features and suppresses redundancy more efficiently, and achieves the best segmentation performance with a slight increase in parameters.
5.5. Ablation Experiments
To further verify the generalization ability and effectiveness of the proposed feature sparsity regularization method, parallel SEConv module, and multi-neighborhood feature fusion strategy, experiments were conducted on the base model DGCNN, and the segmentation performance was compared on the S3DIS dataset and the ScanNet v2 dataset, respectively. Specifically, FS-DGCNN denotes the DGCNN model enhanced with feature sparsity regularization, while MSE-DGCNN represents the FS-DGCNN architecture further augmented with the parallel SEConv module. The comprehensive SFDGNet integrates all three proposed components. The ablation study results are presented in
Table 7 and
Table 8 for S3DIS and
Table 9 for ScanNet v2.
The experimental results presented in
Table 7 reveal consistent performance improvements
, and sparsity metrics through the progressive integration of feature sparsity regularization, the parallel SEConv module, and a multi-neighborhood feature fusion strategy. FS-DGCNN demonstrates notable gains over DGCNN, with
, and
increasing by
, and
respectively, while sparsity dramatically improves from
to
. These results confirm that feature sparsity regularization effectively enables the network to extract sparse point cloud features, emphasize critical semantic information, and consequently, enhance both generalization capability and segmentation performance. Further improvements are observed in MSE-DGCNN, which surpasses FS-DGCNN by
in
in
, and
in
, while achieving
sparsity. This advancement suggests that combining multi-scale local neighborhood graphs with the SEConv module strengthens geometric feature perception and enriches local point cloud feature extraction. The final SFDGNet configuration outperforms the baseline DGCNN by
in
in
, and
in
, with sparsity reaching
, demonstrating the multi-neighborhood feature fusion strategy’s effectiveness in enhancing global feature representation.
Analysis of the experimental results in
Table 8 indicates that the introduction of feature sparsity regularization enables FS-DGCNN to outperform the baseline DGCNN model in
across all categories except sofa. This demonstrates that the proposed regularization method enhances segmentation performance for complex semantic categories featuring blurred boundaries or small structures by improving the network’s sparse feature extraction capability from point clouds. When the parallel SEConv module is further integrated into FS-DGCNN, MSE-DGCNN achieves additional performance improvements in most categories, with notable gains of
for beam,
for sofa, and
for board. These results confirm that enhanced local feature representation from diverse neighborhoods effectively improves the network’s segmentation capacity for complex categories. Compared with the baseline DGCNN, SFDGNet demonstrates consistent performance improvements across all 13 semantic categories, proving its effectiveness in segmenting structurally complex and semantically ambiguous point cloud data.
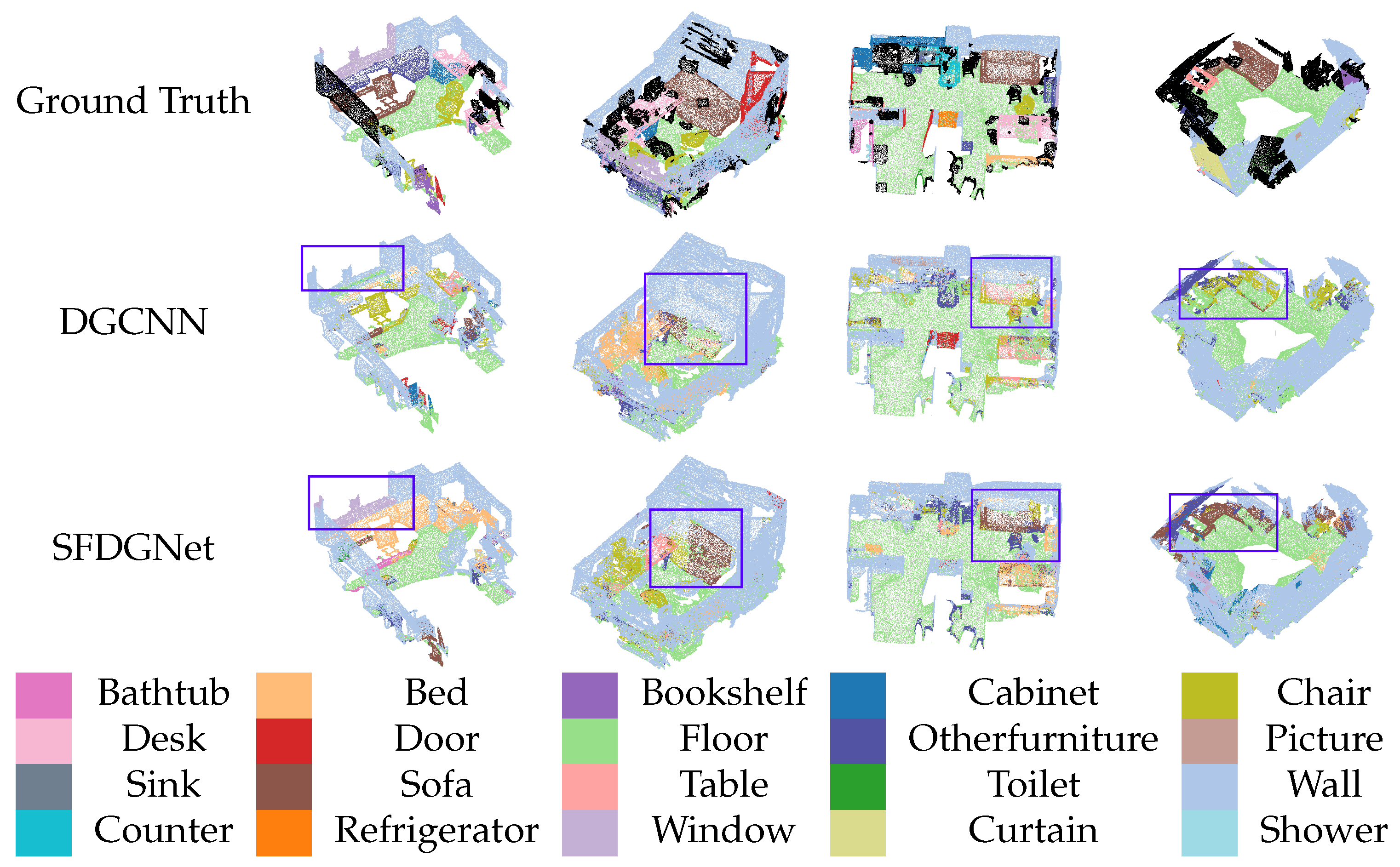
The experimental results in
Table 9 and
Figure 12 indicate that the proposed FS-DGCNN enhances the network’s sparse feature acquisition capability through sparse regularization algorithms, leading to improved segmentation performance across various test scenarios. Compared with the baseline model, MSE-DGCNN demonstrates significant
mIoU improvement, confirming that the parallel construction of multi-range local neighborhood graphs, combined with SEConv modules, effectively extracts diverse neighborhood features and captures richer local point cloud characteristics. SFDGNet achieves marked improvements in both
mIoU and sparsity metrics, demonstrating that the integrated approach of feature sparse regularization, parallel SEConv, and multi-neighborhood feature fusion not only enables deep feature extraction from different neighborhoods but also effectively emphasizes critical semantic features. However, its segmentation accuracy is significantly lower compared to the segmentation results of the network model on the S3DIS, primarily because the ScanNet contains more real-world noise, occlusions, complex environmental variations, and more severe class imbalance, which collectively impair the model’s ability to learn minority class features effectively.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}