Abstract
Infrared small target detection (ISTD) means distinguishing small and faint targets from IR images. Small targets typically span only a handful of pixels, lacking distinct texture and clear structural details. For the past few years, deep learning has made big strides in the field of ISTD. Yet, a persistent challenge remains: the lack of high-level semantic information may cause the disappearance of small target features in the network’s deep layers, ultimately impairing detection accuracy. To tackle this problem, we introduce WT-HMFF, an innovative network architecture that combines the Wavelet Transform Convolution (WTConv) module with the Hierarchical Multi-Scale Feature Fusion (HMFF) module to enhance the ISTD algorithm’s performance. WTConv expands the receptive field through wavelet convolution, effectively capturing global contextual information while preserving target shape characteristics. The HMFF module enables the efficient fusion of shallow and deep features, maintaining the high resolution of deep feature maps and preventing the disappearance of small target features. We have tested it out on public datasets, SIRST and IRSTD-1k, and validated the superiority and robustness of WT-HMFF compared to other methods.
1. Introduction
The principle of infrared imaging differs from that of visible light imaging. Visible light imaging relies on natural or artificial light sources to capture light within the range visible to the human eye, generating images highly dependent on lighting conditions. In contrast, infrared imaging does not rely on external light sources but generates images by detecting the thermal radiation emitted by objects. This allows infrared imaging devices to work in low-light or dark environments, perceive temperature differences, and provide excellent concealment [1]. As a result, infrared imaging offers distinct benefits and finds broad employment across numerous sectors, such as military applications [2], fire hazard detection [3], and maritime monitoring [4]. However, in practical scenarios, when the target is at a considerable distance and affected by external noise factors such as atmospheric refraction and scattering, the targets captured in infrared images often exhibit the characteristics of being “small” and “faint” [5]. “Small” denotes the target covering minimal pixels of the whole infrared image; “faint” refers to the typically low contrast between the object and the background. Therefore, the target is easily overwhelmed by the background, especially when the background is complex.
To address the above challenges, researchers have come up with a myriad of approaches that typically fall into two categories: traditional approaches and deep learning-based approaches.
Traditional methods primarily depend on grayscale information and textural features of images, employing tactics like image sharpening, background masking, and edge enhancement to highlight small target regions. Traditional methods include filtering-based techniques, local contrast mechanism-based approaches, and low-rank-based methods. Filtering-based techniques are split into those that operate in the spatial domain and those that work in the frequency domain. Using spatial domain filter-based techniques, the process starts by distinguishing the background from the foreground, constructing an estimated background representation. The saliency map is subsequently derived by taking the difference between this background estimate and the original image. Finally, a segmentation algorithm is applied to generate the predicted target map. For example, Deshpande et al. [6] proposed the MaxMean/MaxMedian filter method. Bai et al. [7] developed the top-hat transformation, a go-to mathematical morphology technique. Zhang et al. [8] crafted multi-scale Robinson guard filter windows that adeptly use target neighborhood data. Frequency domain filters transform images from spatial to frequency-based representation, acquire the salience map through inverse transformation, and perform threshold segmentation—for example, the non-negativity-constrained variational mode decomposition (NVMD) approach [9]. Techniques utilizing the local contrast mechanism have gained extensive implementation. For example, Kim et al. [10] introduced the Laplacian of Gaussian (LoG) filter. Considering the non-local self-correlation of infrared image backgrounds and the fact that targets occupy a sparse number of pixels [11], scholars have turned to low-rank and sparse matrix decomposition techniques for infrared small target detection. This approach capitalizes on the distinct statistical properties between background patterns and sparse anomalies. In other words, the target detection problem is reframed as a mathematical optimization challenge covering low-rank and sparse components [12]. Deng et al. [13] proposed the infrared patch-image (IPI) model for single-image small target detection. Traditional methods depend on preset assumptions and manual tuning of hyperparameters, rendering them less robust and with performance limitations when applied to images that deviate from their assumptions.
Recent advances in deep learning have significantly impacted ISTD. Most of these techniques rely on convolutional neural networks (CNNs). Huang et al. [14] designed the dense convolutional network (DenseNet), a clever design that connects every layer to every other layer in a forward-moving pattern. Wang et al. [15] introduced the MDvsFA framework by treating missed detections (MDs) and false alarms (FAs) as two sub-tasks, where an adversarial learning approach is employed to balance them. Dai et al. [16] brought forth the asymmetric contextual modulation (ACM) module, which combines a bottom-up attention-based approach with top-down global feedback. Zhao et al. [17] crafted a new detection scheme using a generative adversarial network (GAN), which can pick up on target features independently. Zhang et al. [18] developed the infrared shape network (ISNet) to pinpoint the extracted shapes of targets. Since the introduction of the Vision Transformer (ViT) [19], some researchers have applied the ViT to infrared small target detection, capitalizing on its ability to handle long-range relationships [20,21,22,23]. However, the ViT’s quadratic computational complexity imposes a heavy computational burden, making it less optimal for our purposes. Nevertheless, many studies have proposed lightweight Transformer variants that significantly reduce the computational cost of ViT while retaining its long-range modeling capabilities. Examples include the Pyramid Vision Transformer (PVT) [24] and Swin Transformer [25], which introduce hierarchical structures and window-based self-attention, respectively, to reduce computational overheads while maintaining long-range modeling capacity. These developments suggest that Transformer-based approaches still hold promise for ISTD when computational efficiency is further optimized.
Considering that infrared small targets are compact and possess minimal discernible features, including finer details and textures that are not as noticeable, it is easy for small target features to disappear when the network depth increases. This study presents an innovative design to enhance target feature extraction in infrared images. Additionally, we integrate global contextual information with local details to enhance target recognition algorithms. Specifically, we use the Wavelet Transform Convolution (WTConv) [26] module to expand the receptive field and improve the network’s capability to preserve low-frequency and high-frequency details. Furthermore, we employ a Hierarchical Multi-Scale Feature Fusion (HMFF) module to achieve an interactive fusion of local and global features, ensuring a crisp internal feature map resolution. This module also dynamically calculates feature weights, fine-tuning the receptive field size to emphasize the features of small target regions and improving target segmentation accuracy. The WTConv module is applied to the network’s encoder, while the HMFF module is embedded in the encoder–decoder skip connections. Our tests on the widely used IRSTD-1k and SIRST datasets show the advantages of the proposed WT-HMFF network structure.
In a nutshell, this paper’s key advancements are as follows:
- (1)
- Applying the WTConv module to ISTD networks, enlarging the receptive field, preserving detailed information, and emphasizing the shape information of targets.
- (2)
- The introduction of the HMFF, which achieves the multi-scale fusion and interaction of local and global features, combining features from different network levels to retain crucial target information.
- (3)
- Extensive experiments on the IRSTD-1k dataset and the SIRST dataset, demonstrating the accuracy of the WT-HMFF network.
The remainder of this paper is organized as follows: Section 2 offers a glimpse into the existing literature. Section 3 outlines the overall architecture and key components of WT-HMFF. Section 4 presents the experimental details and results. Lastly, Section 5 wraps up our research with a comprehensive summary.
2. Related Work
2.1. Infrared Small Target Detection
Deep learning-based methods involve multiple layers, and by combining nonlinear modules, they are capable of learning highly complex functions, which is crucial for feature extraction. These methods do not rely on manually designed features but instead learn features directly from the data during training. As a result, quite a few cutting-edge techniques in deep learning are focused on optimizing the architectures of models to beef up feature extraction capabilities. Wang et al. [15] designed the MDvsFA network to strike a balance between missed detection (MD) and false alarm (FA) metrics; Dai et al. [16] introduced an asymmetric context modulation (ACM) module; Zhao et al. [17] introduced a detection approach grounded in a generative adversarial network (GAN); Li et al. [27] designed a dense convolutional network that connects each layer feed-forwardly; Zhang et al. [28] introduced the AGPCNet, a network that uses attention to guide the pyramid context; Hou et al. [29] presented the RISTDNet, a resilient detection system for ISTD that merges both handcrafted features and CNNs; Wu et al. [30] achieved fast inference through network structural reparameterization; Yang et al. [31] proposed a plug-and-play convolutional module, Pconv, to enhance the CNN’s ability to analyze bottom-layer features of ISTD; Liu et al. [32] proposed a model named STPSA-NET, which effectively enhances the representation capability for small targets by integrating a Semantic Token Transformer (STT) module and a Patch Spatial Attention Module (PSAM); Chen et al. [33] applied Mamba to the field of ISTD and proposed a nested architecture named Mamba-in-Mamba (MiM-ISTD); and the SAM [34] serves as a foundational model in the field of segmentation. Building upon it, Zhang et al. [35] proposed IRSAM, which adapts SAM for the task of ISTD. Although these deep neural network methods effectively identify small objects in infrared imagery, some notable shortcomings still need to be overcome. Most existing deep neural networks capture deep information by step-down sampling, which can sometimes result in key information getting lost. Furthermore, due to the targets’ small and faint characteristics, features such as color and texture are not prominent. Therefore, it is essential to emphasize small target feature information and maintain a high resolution of internal network features. To address this, we designed the WT-HMFF network to enhance the contour features and contextual information of targets while fusing both the local and global data, thereby improving the target detection algorithm’s overall performance.
2.2. Wavelet Transform Convolutions
Over the last several decades, convolutional neural networks (CNNs) have occupied a significant position in computer vision. ISTD is a highly challenging task due to its limited pixel size, low signal-to-noise ratio, and lack of texture or semantic information. Traditional convolutional operations, especially standard convolution with small respective fields, tend to struggle to capture sufficient contextual information around small, sparse targets. Later, a game-changing shift emerged with the rise of the Vision Transformer (ViT), an algorithm originally developed for natural language processing, which has posed a challenge to CNNs. The main advantage of ViT lies in its multi-head attention layer, which enables global feature interaction. Researchers have sought to close the performance disparity between CNNs and ViT, for example, by increasing the kernel size to expand the receptive field [36,37,38]. Still, this approach reaches performance saturation when the kernel size is , meaning that increasing the kernel further does not help [26], and it dramatically increases the number of parameters, which can result in overfitting and limited performance gains. Although large-kernel convolutions can effectively enlarge the respective field, they introduce a substantial number of parameters. Moreover, such convolutions tend to overlook local image details, potentially missing important small-scale features, which is detrimental to infrared small target detection.
Wavelet Transform Convolutions (WTConv) propose a novel approach that achieves a large receptive field through small kernel convolutions combined with wavelet transform (WT), without significantly increasing the number of parameters. WT has been widely used since the 1980s, and with the advancement in neural network technology, researchers have integrated it into neural network architectures. Liu et al. [39] introduced wavelet transform for downsampling in an improved U-Net architecture, using inverse wavelet transform for upsampling; Fujieda et al. [40] introduced a wavelet CNN structure, which combines multi-resolution analysis with CNNs in a single model. However, these methods cannot be directly applied as plug-and-play modules to other CNN architectures. In contrast, the WTConv we use is a lighter, more user-friendly linear layer that can substitute for deep convolutions, expanding the receptive field without significant complexity. WTConv decomposes the input feature map into low-frequency and high-frequency components using a discrete wavelet transform, allowing the network to capture the global context through low-frequency channels, preserve fine edges and target details through high-frequency components, and process at multiple scales natively without excessive computation. Compared to standard convolution, WTConv provides stronger feature discrimination by separating background and target responses. Compared to large-kernel convolution, it achieves a similar or better receptive field coverage with a lower parameter cost and better localization sensitivity. Therefore, it is reasonable to apply WTConv to the task of ISTD.
2.3. Multi-Scale Feature Fusion Module
Multi-scale feature fusion has emerged as a dominant approach in computer vision in recent years. The U-Net architecture designed by Olaf Ronneberger et al. [41] employs skip connections to merge encoder and decoder outputs at matching layers. Li et al. [42] designed SKNet, which implements a top-down pathway to combine high-level and low-level features. A similar hierarchical strategy was adopted by Lin et al. [43] in their Feature Pyramid Network (FPN). Wu et al. [44] introduced the Pyramid Pooling Transformer (P2T) network, which uses a pyramid pooling module as a feature extractor for multi-scale information processing. Kolahi et al. [45] developed the Multi-Scale Attention Guided (MSA2Net) network, which fuses local information with global context information. Dai et al. [16] designed the asymmetric contextual modulation (ACM) to harmonize high-level semantics with low-level details. Xie et al. [46] introduced the Multi-Features Extraction block (MFEblock), which achieves multi-scale feature extraction using convolutional layers with different dilation rates. After designing ACM, Dai et al. [47] refined their work with the Attentional Local Contrast Networks (ALCNs), which enhances deep feature integration through low-level feature guidance.
One of our contributions in this paper is the Hierarchical Multi-Scale Feature Fusion (HMFF) module, which achieves dynamic weights and combines multi-scale features, thereby improving the network’s capacity for identifying minuscule objects and improving the segmentation accuracy for such challenging cases.
3. Methods
This section offers an in-depth breakdown of the WT-HMFF network. We first introduce the whole architecture of the system, and then we give a thorough explanation of the key components of the network: the WTConv module, the HMFF module, and the loss function.
3.1. Overall Architecture
The WT-HMFF network is implemented through a general encoder–decoder framework, with the core structure based on ResNet-20 U-Net. After inputting an infrared image into the encoder of WT-HMFF, the network extracts rich multi-scale feature maps through a cascade of encoders embedded with the WTConv module. These feature maps are then progressively reconstructed via the cascade of decoders. Additionally, the encoder and decoder’s output features at every level are fused through the HMFF module to enable efficient information interactions. Finally, the network outputs high-quality detection results for the infrared image, as shown in Figure 1.
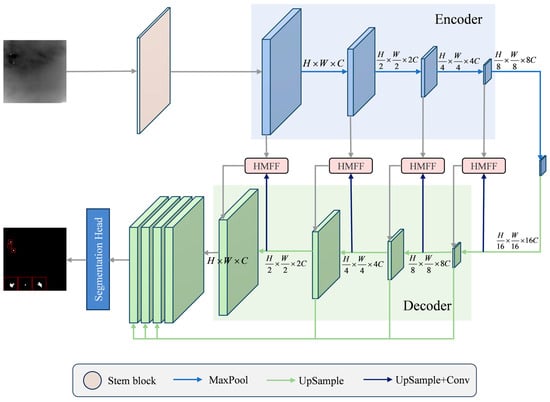
Figure 1.
Overview of the proposed WT-HMFF, which contains WTConv and HMFF modules.
3.2. WTConv
Through WT, the input is decomposed into multiple frequency components to preserve the low-frequency and high-frequency details, thus minimizing the information loss during downsampling.
To expand the model’s receptive field and improve its ability to capture details of the entire infrared image, we employ a plug-and-play convolution module—WTConv. The WTConv layer is embedded in each encoder. After embedding, the single encoder layer architecture is shown in Figure 2. This module effectively expands the receptive field while maintaining computational efficiency by cascading wavelet decomposition, local convolution processing, and inverse wavelet transform (IWT), thereby improving the detection performance of small targets.
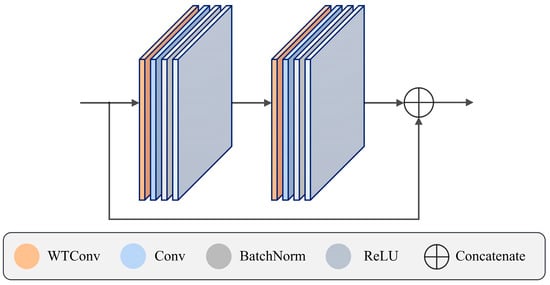
Figure 2.
Single-encoder-layer structure.
The two-dimensional discrete wavelet transform (2D-DWT) process can be divided into two steps. Row-wise filtering: Each row of the input image is convolved with a low-pass filter and a high-pass filter, followed by downsampling. Column-wise filtering: The intermediate results from the row-wise filtering step are then convolved along the columns with low-pass, high-pass filters and downsampling. Taking the Daubechies 1 (db1) filter as an example, the low-pass filter is defined as , and the high-pass filter is defined as . The output of the WT can thus be expressed as
where denotes the input image and and represent the transposes of the low-pass filter and the high-pass filter , respectively. denotes the convolution operation, and refers to downsampling. represents the low-frequency component of , while , , and correspond to the horizontal, vertical, and diagonal high-frequency components, respectively.
The cascaded wavelet decomposition results are obtained by recursively decomposing the low-frequency components, as expressed by the following equation:
where and is the current wavelet decomposition level.
In the WTConv computation process, the input low- and high-frequency components are first filtered and reduced through WT. Then, before constructing the output using the IWT, a compact depth-wise convolutional kernel across various frequency domains is applied to different frequency maps. The operation can be formulated as
where refers to the output tensor and is the weight tensor of the depth-wise kernel. This operation separates the convolutions between frequency components while increasing the receptive field.
The following operation can be expressed as
where refers to the input at this layer, while indicates the high-frequency maps of the level described in Equation (1). and denote the convolution outputs of and , respectively.
In the reconstruction stage of WTConv, each layer combines the convolved sub-band features and the upsampled reconstruction output from the next layer via a separate IWT. That is,
Based on the linearity of both WT and IWT, we can derive , which in turn can be derived:
This equation shows the sum of convolutions at different levels, where represents the total output from the layer. Taking the 2-level wavelet decomposition as an example, Figure 3 illustrates the computational flow of WTConv.
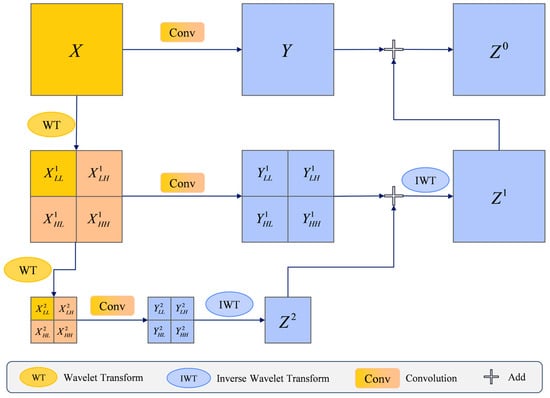
Figure 3.
The computational process of WTConv (taking the 2-level wavelet decomposition as an example).
This paper uses the Daubechies wavelet (db wavelet) as the wavelet basis for two-level wavelet decomposition. Due to its compact support, orthogonality, and high-order vanishing moments, it exhibits excellent smoothness and edge detection capabilities, making it well-suited to distinguishing small targets embedded in cluttered infrared backgrounds. We also conducted a comparative study between the Daubechies wavelet and the Haar wavelet in Section 4, and the results demonstrate that the Daubechies wavelet performs better in this task.
WTConv enhances the network’s global perception of infrared images and effectively captures details, thus improving the model’s precision and reliability. For each frequency component after decomposition, WTConv applies small kernel convolutions independently to each frequency component, extracting features from different frequencies. Furthermore, depth-wise convolution is used to process each channel individually to further cut down both computational costs and parameter counts, thereby sidestepping the heavy processing demands caused by cross-channel convolutions. After the convolution process, all frequency components are reconstructed through the IWT, merging the individual frequency components into a complete output tensor to obtain a more comprehensive feature representation.
3.3. HMFF Module
To enhance the detection performance of the ISTD network and address the issue of feature disappearance in deep layers, we fully leverage low-level features by integrating the HMFF module into the detection network. The HMFF module performs spatially weighted fusion and adaptive enhancement, enabling feature amplification in crucial target areas and suppression of background noise through skip connections. Figure 4 shows the HMFF module structure. In the WT-HMFF network, the HMFF module is embedded in the skip connections between the encoder and decoder. This integration strengthens the representation of target features, optimizes the fusion between global and local data, and maintains the high resolution of internal features.
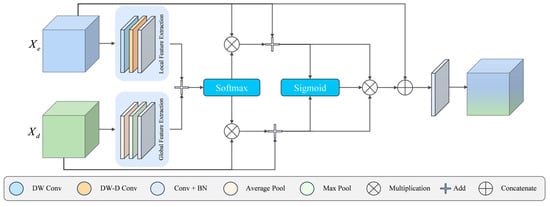
Figure 4.
Structure of HMFF.
Specifically, the detailed workflow of the HMFF module can be described as follows: First, the multi-scale feature fusion part is responsible for extracting local contextual features and global contextual features to fuse the high-resolution spatial feature information () from the encoder with the semantic information () from the decoder. This operation can be formulated as
where denotes depthwise convolution, represents dilated convolution, refers to point-wise convolution used for channel modeling, represents max pooling, and represents average pooling.
Next, the fusion features are mapped to two channels and normalized by softmax:
The weights are then divided into and , and element-wise multiplication is performed with the corresponding input branches, followed by residual connections:
This approach helps emphasize important regions in the spatial domain while suppressing irrelevant areas.
Next, and are interwoven to achieve adaptive enhancement segmentation. The global contextual information from enriches the local details of . Specifically, is processed by a sigmoid function to generate weights. These weights are then multiplied element-wise with . Similarly, the detailed local information contained in adjusts the global features :
Then, element-wise multiplication between and further stabilizes the features:
Then, a residual connection is added to the stabilized feature map:
This final output is processed through a convolution layer to ensure that the adaptive multi-scale receptive field from the previous stages is used to enhance the feature map , and this process results in the final output of HMFF, which enhances the model’s performance by effectively combining global and local information.
In our detection task, the target usually occupies a very small region, while the background occupies a large portion, leading to a very low proportion of the target in the image. To address this significant class imbalance issue, our training employs Binary Cross Entropy (BCE) as the loss function. It can be defined as
where refers to the ground truth, represents the model input, and denotes the predicted output of the network.
4. Experiment
This section introduces the dataset, evaluation metrics, detailed experimental setup, results, and discussion.
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
Experiments were conducted on the IRSTD-1k dataset and the SIRST dataset. The IRSTD-1k dataset contains 1001 manually annotated real-world infrared images showcasing diverse target shapes, scales, and cluttered backgrounds from various environments. The SIRST dataset consists of 427 infrared images selected from hundreds of infrared sequences suitable for various scenes. The specifics of both datasets are outlined in Table 1. Each dataset was split into training, validation, and test sets in a 6:2:2 ratio.

Table 1.
The information on the IRSTD-1k and SIRST datasets.
4.1.2. Evaluation Metrics
- 1.
- Intersection over Union
Intersection over Union () serves as a performance indicator for evaluating how closely a predicted region aligns with the actual target area. Essentially, it computes the proportion between the overlapping section of the predicted region and the ground truth region compared to their combined total area:
where and represent the intersection and union areas of the predicted and ground truth regions, respectively. refers to the pixels predicted as part of the target, refers to the pixels of the ground truth target, represents the correctly predicted pixels, and denotes the number of test images.
- 2.
- Normalized Intersection over Union
Normalized Intersection over Union () is a standardized form of . not only evaluates the accuracy of segmentation but also assesses its completeness. It is defined as
- 3.
- Probability of Detection
Probability of Detection () measures the ratio of correctly predicted targets to the total number of targets . It is defined as
- 4.
- False Alarm Rate
Following the evaluation protocol of DNANet [27], we define Fa as a pixel-level metric, which measures the proportion of falsely predicted pixels across the entire test set. It is defined as
where represents the number of pixels incorrectly identified as targets by the model. represents the total pixel count of the image. Although this is not the standard target-level definition (i.e., number of false detections per image), it allows for a more fine-grained analysis of pixel-wise errors and is consistent with prior work.
- 5.
- ROC Curve
The receiver operating characteristic (ROC) curve is a powerful tool for evaluating how well a classification model performs. By graphing the trade-off between the true positive rate () and the false positive rate () across different decision thresholds, it provides a clear visual representation of a model’s diagnostic ability:
where and represent the number of background pixels correctly classified as non-target and the number of target pixels incorrectly classified as background, respectively. A larger ROC curve area indicates a superior model performance.
4.2. Implementation Details
We used AdaGrad as the optimizer for WT-HMFF, with a learning rate set to 0.05. The training process lasts for 400 epochs, with a batch size of 4. The model is implemented using PyTorch 1.12.0 and runs on an Nvidia GeForce RTX 3090 GPU.
4.3. Quantitative Results
As shown in Table 2, our WT-HMFF model outperforms the competition on both the SIRST and IRSTD-1k datasets, edging out the most current techniques and traditional methods alike. Among these comparison algorithms, MDvsFA [15], ACM [16], DNANet [27], Pconv [31], ALCNet [47], IRPruneDet [48], UIUNet [49], and SCTransNet [50] are all deep learning-based methods, while the others are traditional model-based methods. In Table 2, PConv(4, 3) means that the first PConv kernel size is 4 and the second is 3. This configuration follows the optimal setting described in the original paper, where PConv was applied to MSHNet [51]. Model-driven traditional algorithms have limited capabilities in handling challenging datasets, and their performance metrics are significantly lower than those of deep learning-based methods. However, infrared small target detection via deep learning methods encounters limitations, causing imprecise mask estimations and reduced and .
Table 2.
Comparisons with other methods on IRSTD-1k and SIRST in (%), (%), Pd (%), Fa ().
Interestingly, WT-HMFF performs superiorly on the SIRST dataset compared to the IRSTD-1k dataset. This discrepancy stems from the IRSTD-1k’s inclusion of more demanding cases for infrared small target detection, including targets with diverse shapes, lower contrast, and lower signal-to-noise ratio backgrounds with rich clutter and noise. Despite this, our proposed WT-HMFF still outperforms other algorithms. This can be attributed to the WTConv module, which enlarges the receptive field, and the HMFF module, which effectively aggregates multi-scale features across layers.
It should be explained that compared with other methods, the IoU, nIoU, and Pd indexes obtained by the proposed WT-HMFF algorithm are all the best. However, it does not attain the optimal result in the Fa metric. On the IRSTD-1k dataset, SCTransNet achieves the best Fa metric, while on the NUAA-SIRST dataset, IRPuneNet attains the best Fa performance. This can be attributed to their design philosophies. IRPuneNet relies on pruning and sparsity-aware regularization to suppress redundant feature activations, while SCTransNet leverages transformer-based attention mechanisms that enhance global context awareness and help discriminate true targets from background clutter. WT-HMFF integrates both local detailed features and global contextual features, which may also increase the sensitivity to noisy textures. As a result, the Fa metric of WT-HMFF does not reach the optimal level. To address this limitation, future improvements may incorporate attention-based refinement or confidence filtering strategies to reduce Fa while preserving high Pd.
We also plotted the ROC curves for different methods on the IRSTD-1k and SIRST datasets, as shown in Figure 5. It can be observed that the area under the ROC curve (AUC) for our proposed WT-HMFF is larger than that of the other comparison methods, indicating that the behavior of our proposed WT-HMFF is better than the other methods.
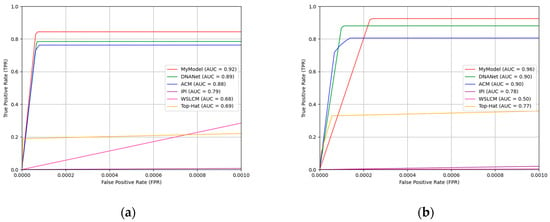
Figure 5.
ROC curves for different methods. (a) ROC curves for different methods on the IRSTD-1k dataset; (b) ROC curves for different methods on the SIRST dataset.
We also compared the computational performance of different approaches, as shown in Table 3. It can be observed that, except for ACM and IRPruneNet, most algorithms are computationally demanding, especially UIUNet and SCTransNet. While IRPruneNet achieves a relatively lower detection accuracy, it has a very low computational cost. In contrast, our proposed WT-HMFF method strikes a good balance between computational efficiency and detection accuracy.
Table 3.
Comparison of computational performance with other deep learning-based methods.
4.4. Visual Results
As shown in Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13, we present the visualization results of different methods on the IRSTD-1k dataset. It can be seen that even under conditions of low contrast and complex backgrounds, our WT-HMFF network can still accurately locate the targets.

Figure 6.
Visual results of different methods in scene 1. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 7.
Visual results of different methods in scene 2. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 8.
Visual results of different methods in scene 3. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 9.
Visual results of different methods in scene 4. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 10.
Visual results of different methods in scene 5. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 11.
Visual results of different methods in scene 6. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 12.
Visual results of different methods in scene 7. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.

Figure 13.
Visual results of different methods in scene 8. (a) Input images from the open IRSTD-1k and SIRST datasets, (b) ground truth, (c–h) results of WSLCM, Top-Hat, IPI, ACM, DNANet, and the proposed WT-HMFF.
To provide a clearer display of the prediction results, we have also plotted the 3D visualization results, as shown in Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20 and Figure 21.
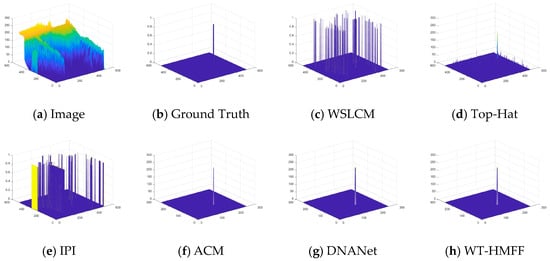
Figure 14.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 1.
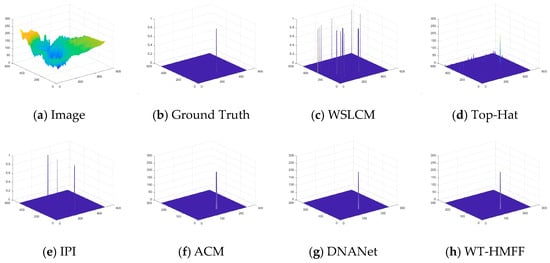
Figure 15.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 2.
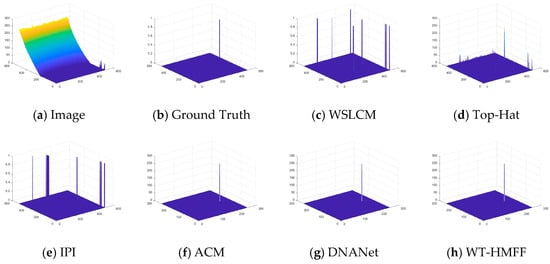
Figure 16.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 3.
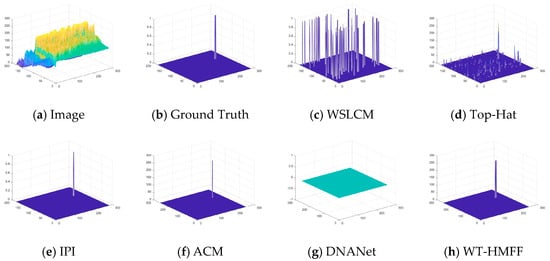
Figure 17.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 4.
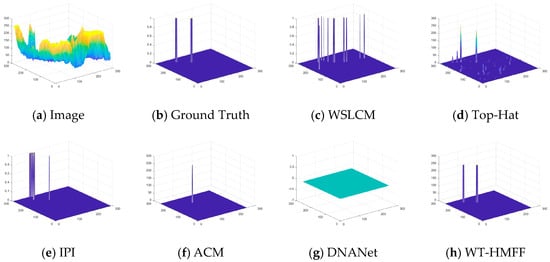
Figure 18.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 5.
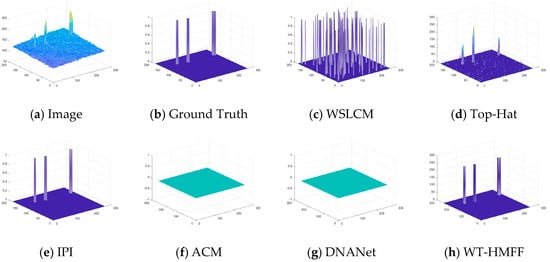
Figure 19.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 6.
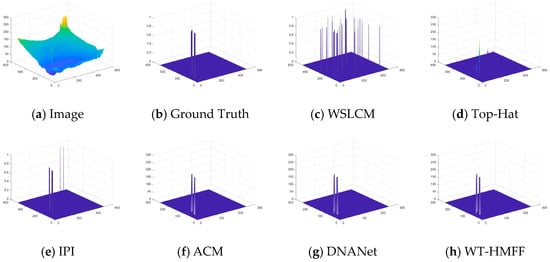
Figure 20.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 7.
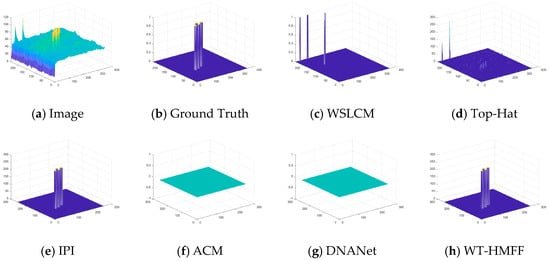
Figure 21.
Three-dimensional visual results of the proposed WT-HMFF and other methods in scene 8.
4.5. Ablation Study
To validate the impact of individual elements within the WT-HMFF network, we conducted several ablation experiments on the SIRST dataset. The findings, summarized in Table 4, highlight the contributions of both the WTConv and the HMFF modules. As shown, each component delivers substantial performance gains over the performance of the baseline network, and their combined use achieves optimal results. These outcomes underscore the critical role each module plays in enhancing overall network efficacy.
Table 4.
Ablation study of the WTConv and HMFF module in (%), (%), Pd (%), Fa ().
4.5.1. Impact of WTConv Decomposition Levels
To compare the effect of different wavelet decomposition levels on the algorithm’s performance in WTConv, experiments were conducted with decomposition levels set to 1, 2, and 3. The experimental results are presented in Table 5.
Table 5.
IoU (%), nIoU (%), Pd (%), and Fa () under different wavelet decomposition levels and wavelet bases.
4.5.2. Impact of Using Different Wavelet Bases in WTConv
To compare the effect of different wavelet bases on the algorithm’s performance, experiments were conducted using the db4 and Haar wavelet bases. The results are also presented in Table 5.
Additionally, as shown in Figure 22, we visualized the evaluation metrics under various wavelet decomposition levels and wavelet bases as bar charts, which offer a clearer, more immediate grasp of the comparative outcomes.
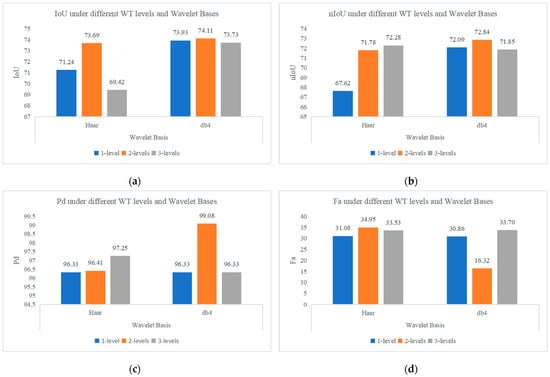
Figure 22.
The evaluation metrics under different wavelet decomposition levels and wavelet bases. (a) IoU (%) under different wavelet decomposition levels and wavelet bases; (b) nIoU (%) under different wavelet decomposition levels and wavelet bases; (c) Pd (%) under different wavelet decomposition levels and wavelet bases; (d) Fa () under different wavelet decomposition levels and wavelet bases.
5. Conclusions
This study introduces an innovative infrared small target detection network, WT-HMFF, designed to overcome the difficulties associated with detecting small, faint targets and the disappearance of target features in deep network layers.
Specifically, the WT-HMFF network comprises two core components: the WTConv and HMFF modules. The former expands the receptive field and captures detailed information. At the same time, the latter achieves an efficient combination of low-level and high-level information, which helps maintain high-resolution feature maps in the network’s deep stages, effectively counteracting the vanishing target feature problem. We conducted extensive experiments on widely recognized IRSTD-1k and SIRST datasets, demonstrating the superiority of the proposed WT-HMFF network in infrared small target detection.
Although WT-HMFF demonstrates a promising performance on several ISTD benchmarks, some limitations still warrant further study. First, the model may misidentify certain noise patterns as targets, resulting in a slightly higher false alarm rate. Second, though WT-HMFF achieves a good trade-off between accuracy and complexity, it has not been explicitly optimized for lightweight deployment. In the next step of work, we plan to explore model compression strategies such as pruning and knowledge distillation. We also intend to investigate the robustness of the model on other infrared datasets.
Author Contributions
Validation, J.H. and Q.D.; formal analysis, S.L.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, S.L., J.H., Q.D., and Z.L.; visualization, S.L.; supervision, Z.L.; project administration, Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China (No. 2024YFB3614400).
Data Availability Statement
The IRSTD-1k dataset supporting this research can be obtained at the following website: https://github.com/RuiZhang97/ISNet (accessed on 20 March 2022). The SIRST dataset supporting this research can be obtained at the following website: https://github.com/YimianDai/sirst (accessed on 10 May 2021).
Acknowledgments
The authors thank Z.M. and D.Y. for providing the open-source data.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Small Infrared Target Detection Based on Weighted Local Difference Measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Thanh, N.T.; Sahli, H.; Hao, D.N. Infrared Thermography for Buried Landmine Detection: Inverse Problem Setting. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3987–4004. [Google Scholar] [CrossRef]
- Deng, L.; Chen, Q.; He, Y.; Sui, X.; Liu, Q.; Hu, L. Fire Detection with Infrared Images Using Cascaded Neural Network. J. Algorithms Comput. Technol. 2019, 13, 1748302619895433. [Google Scholar] [CrossRef]
- Teutsch, M.; Krüger, W. Classification of Small Boats in Infrared Images for Maritime Surveillance. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar]
- Pan, P.; Wang, H.; Wang, C.; Nie, C. ABC: Attention with Bilinear Correlation for Infrared Small Target Detection. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 2381–2386. [Google Scholar]
- Deshpande, S.D.; Er, M.H.; Ronda, V.; Chan, P. Max-Mean and Max-Median Filters for Detection of Small-Targets. In Proceedings of the SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO, USA, 18–23 July 1999. [Google Scholar]
- Bai, X.; Zhou, F. Analysis of New Top-Hat Transformation and the Application for Infrared Dim Small Target Detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, X.; Wang, M. Background Suppression Algorithm for Infrared Images Based on Robinson Guard Filter. In Proceedings of the 2017 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017; pp. 250–254. [Google Scholar]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint L2,1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Kim, S.; Yang, Y.; Lee, J.; Park, Y. Small Target Detection Utilizing Robust Methods of the Human Visual System for IRST. J. Infrared Milli Terahz Waves 2009, 30, 994–1011. [Google Scholar] [CrossRef]
- Bo, Y.; Wu, Y.; Wang, X. A Novel Attention-Enhanced Network for Image Super-Resolution. Eng. Appl. Artif. Intell. 2024, 130, 107709. [Google Scholar] [CrossRef]
- Liu, S.; Chen, P.; Woźniak, M. Image Enhancement-Based Detection with Small Infrared Targets. Remote Sens. 2022, 14, 3232. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual Conference, Waikoloa, HI, USA, 5–9 January 2021; pp. 949–958. [Google Scholar]
- Zhao, B.; Wang, C.; Fu, Q.; Han, Z. A Novel Pattern for Infrared Small Target Detection with Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4481–4492. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Zhang, M.; Bai, H.; Zhang, J.; Zhang, R.; Wang, C.; Guo, J.; Gao, X. RKformer: Runge-Kutta Transformer with Random-Connection Attention for Infrared Small Target Detection. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1730–1738. [Google Scholar]
- Yang, H.; Mu, T.; Dong, Z.; Zhang, Z.; Wang, B.; Ke, W.; Yang, Q.; He, Z. PBT: Progressive Background-Aware Transformer for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5004513. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5002013. [Google Scholar] [CrossRef]
- Chen, T.; Tan, Z.; Chu, Q.; Wu, Y.; Liu, B.; Yu, N. TCI-Former: Thermal Conduction-Inspired Transformer for Infrared Small Target Detection. Proc. AAAI Conf. Artif. Intell. 2024, 38, 1201–1209. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. arXiv 2024, arXiv:2407.05848. [Google Scholar]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust Infrared Small Target Detection Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7000805. [Google Scholar] [CrossRef]
- Wu, S.; Xiao, C.; Wang, L.; Wang, Y.; Yang, J.; An, W. RepISD-Net: Learning Efficient Infrared Small-Target Detection Network via Structural Re-Parameterization. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622712. [Google Scholar] [CrossRef]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-Shaped Convolution and Scale-Based Dynamic Loss for Infrared Small Target Detection. arXiv 2024, arXiv:2412.16986. [Google Scholar] [CrossRef]
- Liu, S.; Qiao, B.; Li, S.; Wang, Y.; Dang, L. Patch Spatial Attention Networks for Semantic Token Transformer in Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5003014. [Google Scholar] [CrossRef]
- Chen, T.; Ye, Z.; Tan, Z.; Gong, T.; Wu, Y.; Chu, Q.; Liu, B.; Yu, N.; Ye, J. MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small-Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 3992–4003. [Google Scholar]
- Zhang, M.; Wang, Y.; Guo, J.; Li, Y.; Gao, X.; Zhang, J. IRSAM: Advancing Segment Anything Model for Infrared Small Target Detection. In Proceedings of the Computer Vision—ECCV 2024: 18th European Conference, Milan, Italy, 29 September–4 October 2024; Proceedings, Part LXVII.. Springer: Berlin/Heidelberg, Germany, 2024; pp. 233–249. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31×31: Revisiting Large Kernel Design in CNNs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11965. [Google Scholar]
- Liu, S.; Chen, T.; Chen, X.; Chen, X.; Xiao, Q.; Wu, B.; Kärkkäinen, T.; Pechenizkiy, M.; Mocanu, D.; Wang, Z. More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 Using Sparsity. arXiv 2023, arXiv:2207.03620. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-Level Wavelet-CNN for Image Restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 886–88609. [Google Scholar]
- Fujieda, S.; Takayama, K.; Hachisuka, T. Wavelet Convolutional Neural Networks. arXiv 2018, arXiv:1805.08620. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wu, Y.-H.; Liu, Y.; Zhan, X.; Cheng, M.-M. P2T: Pyramid Pooling Transformer for Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12760–12771. [Google Scholar] [CrossRef]
- Kolahi, S.G.; Chaharsooghi, S.K.; Khatibi, T.; Bozorgpour, A.; Azad, R.; Heidari, M.; Hacihaliloglu, I.; Merhof, D. MSA^2Net: Multi-Scale Adaptive Attention-Guided Network for Medical Image Segmentation. arXiv 2024, arXiv:2407.21640. [Google Scholar]
- Xie, L.; Li, C.; Wang, Z.; Zhang, X.; Chen, B.; Shen, Q.; Wu, Z. SHISRCNet: Super-Resolution and Classification Network for Low-Resolution Breast Cancer Histopathology Image. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2023; Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda-Mahmood, T., Taylor, R., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023; Volume 14224, pp. 23–32. ISBN 978-3-031-43903-2. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zhang, M.; Yang, H.; Guo, J.; Li, Y.; Gao, X.; Zhang, J. IRPruneDet: Efficient Infrared Small Target Detection via Wavelet Structure-Regularized Soft Channel Pruning. AAAI 2024, 38, 7224–7232. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Yuan, S.; Qin, H.; Yan, X.; Akhtar, N.; Mian, A. SCTransNet: Spatial-Channel Cross Transformer Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5002615. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, R.; Zheng, B.; Wang, H.; FU, Y. Infrared Small Target Detection with Scale and Location Sensitivity. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 17490–17499. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).