
A Lightweight Remote-Sensing Image-Change Detection Algorithm Based on Asymmetric Convolution and Attention Coupling



Abstract
1. Introduction
- (1)
- The Siamese network and attention mechanism: The twin CNN of Zhan et al. [21] learned the similarities and differences between cells through weighted contrast loss and performed well in aerial image detection. The multi-path attention residual block proposed by Zhang et al. [22] realizes the differentiated processing of multi-scale features through the channel-attention mechanism, and effectively copes with the interference of light changes and vegetation seasons.
- (2)
- Multimodal and multi-scale fusion: Wang et al. [23] improved the registration accuracy of hyperspectral images by generating hybrid affine matrices. The spectral–spatial joint learning network of Zhang et al. [24] synchronously extracts multi-dimensional features through the twin structure, which significantly enhances the representation ability of change information.
- (3)
- Lightweight and edge deployment: Although deep models significantly improve detection accuracy, the high computational complexity of mainstream methods (such as SNUNet, 175.76 G FLOPs) limits their application in resource-constrained scenarios such as drones and edge devices. Lightweight designs such as the MobileNet variant [25] reduce the amount of computation, but the accuracy of small target detection is reduced due to an insufficient receptive field [26].
- The introduction of lightweight residual convolution blocks reduces parameter complexity and computational complexity, while ensuring the effective extraction and transfer of features, which significantly compresses the calculation cost of the model.
- The multi-scale spatial-attention module enables the network to pay attention to features of different scales, enhancing its ability to capture change information from objects of varying sizes in remote sensing imagery.
- The proposed feature difference enhancement module further highlights the features of the changed regions through the enhanced processing of feature differences of remote-sensing images at distinct phases, leading to more accurate localization and identification of the changed regions.
- Quantitative and qualitative experiments on three datasets demonstrate that our proposed ABLRCNet effectively balances computational resources and detection accuracy.
2. Methodology and Materials
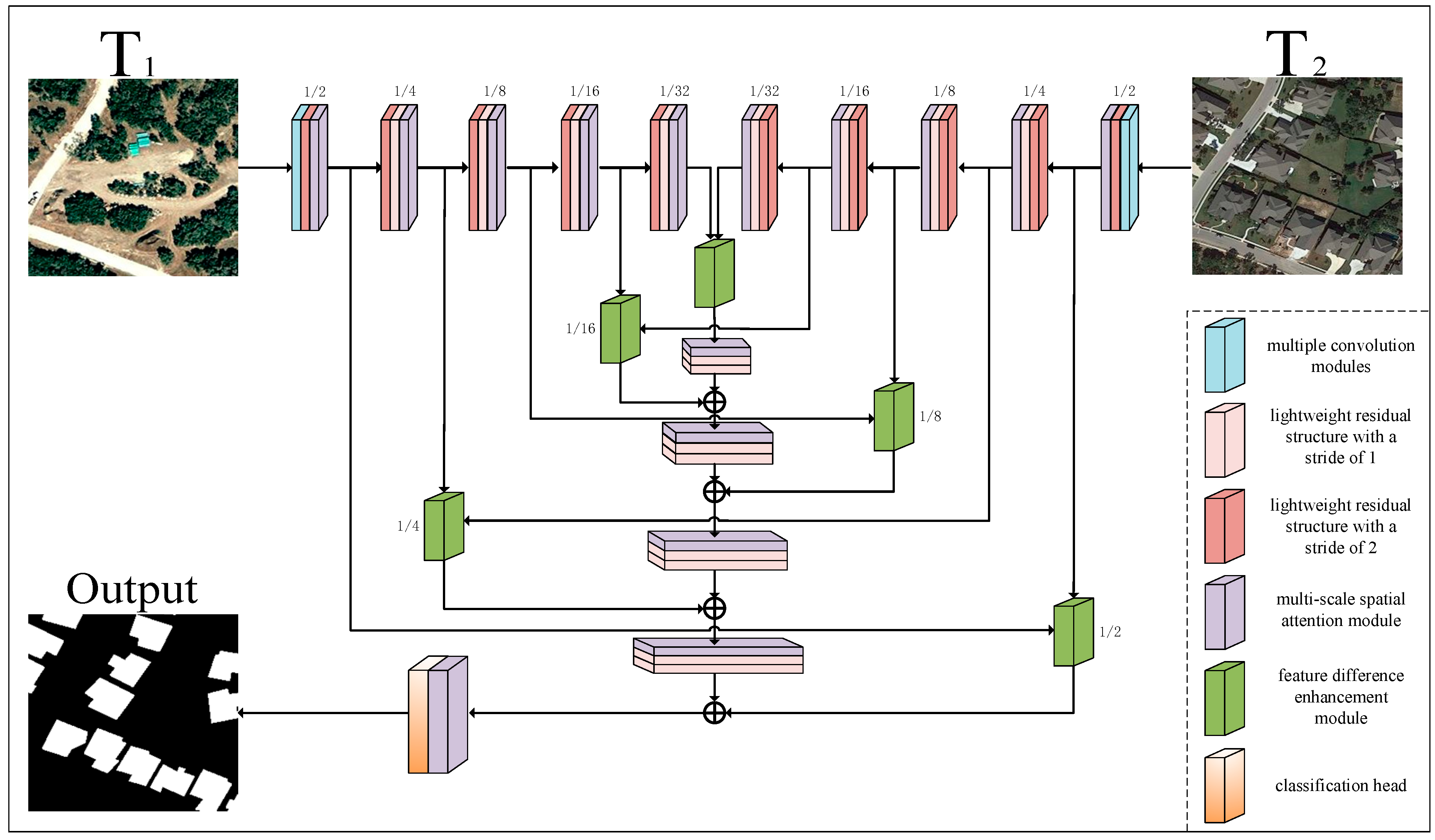
2.1. Network Architecture
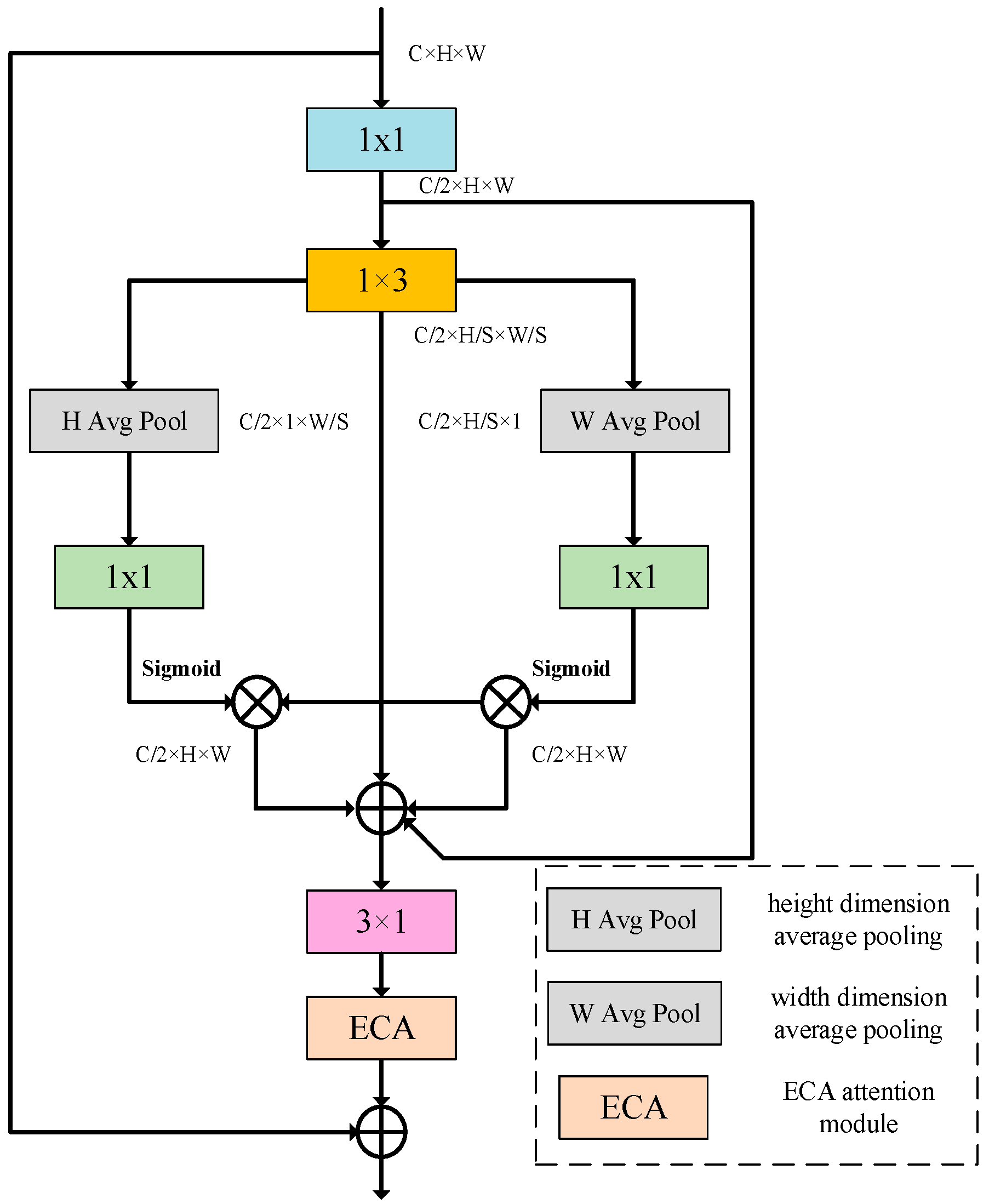
2.2. Lightweight Residual Convolution Blocks (LRCBs)
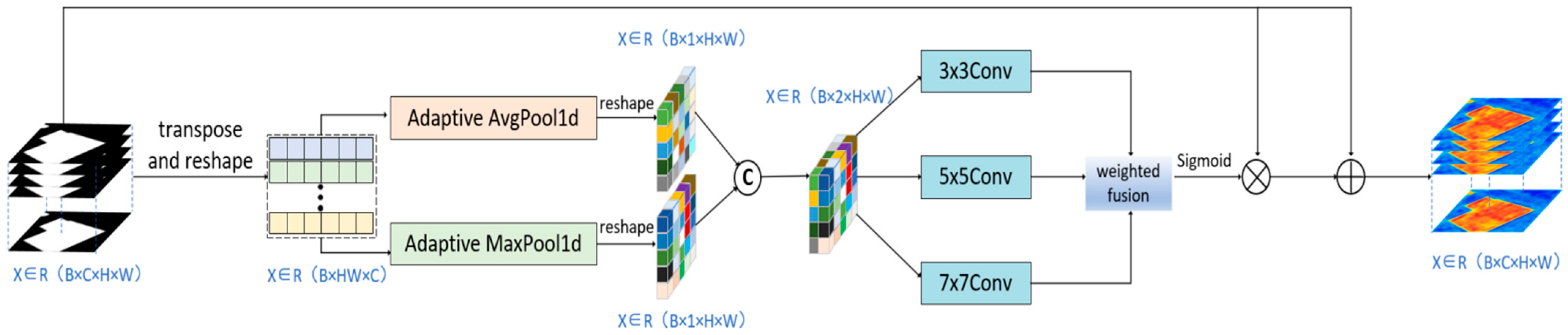
2.3. Multi-Scale Spatial-Attention Module (MSAM)
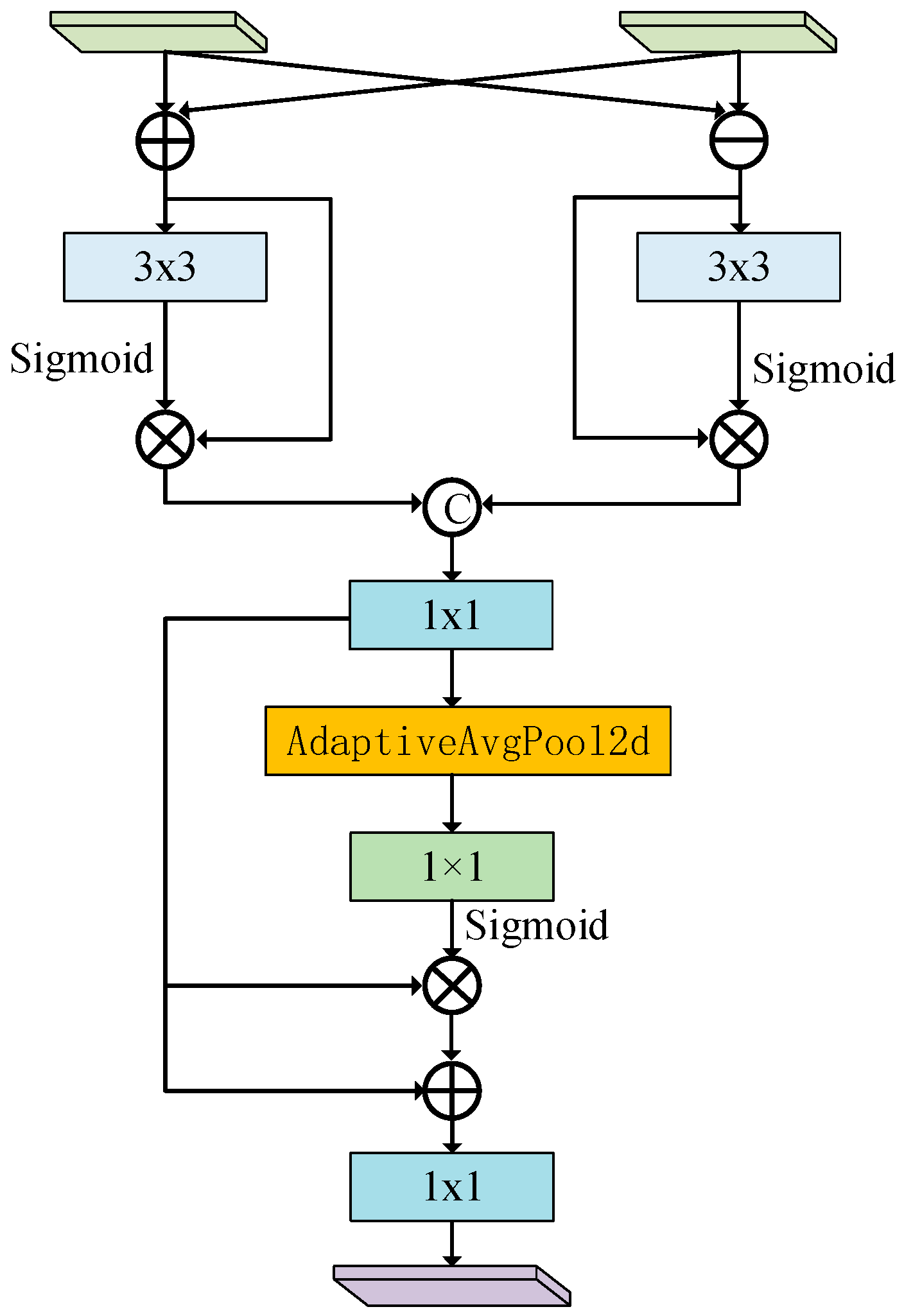
2.4. Feature-Difference Enhancement Module (FDEM)
2.5. Dataset Materials
2.5.1. BTCDD Dataset
2.5.2. LEVIR-CD Dataset
2.5.3. BCDD Dataset
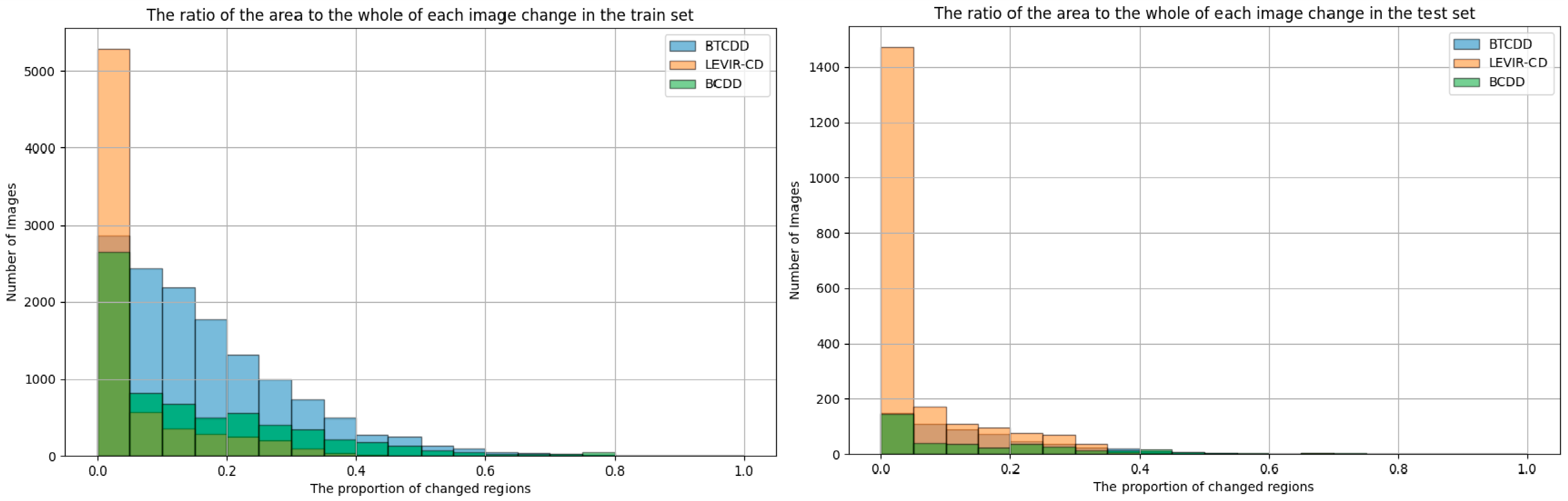
2.5.4. Data Analysis
2.6. Performance Evaluation Metrics
3. Experimental
3.1. Experimental Environment
3.2. Network Module Ablation Experiment
3.3. Ablation Experiment of the Feature-Difference Enhancement Module
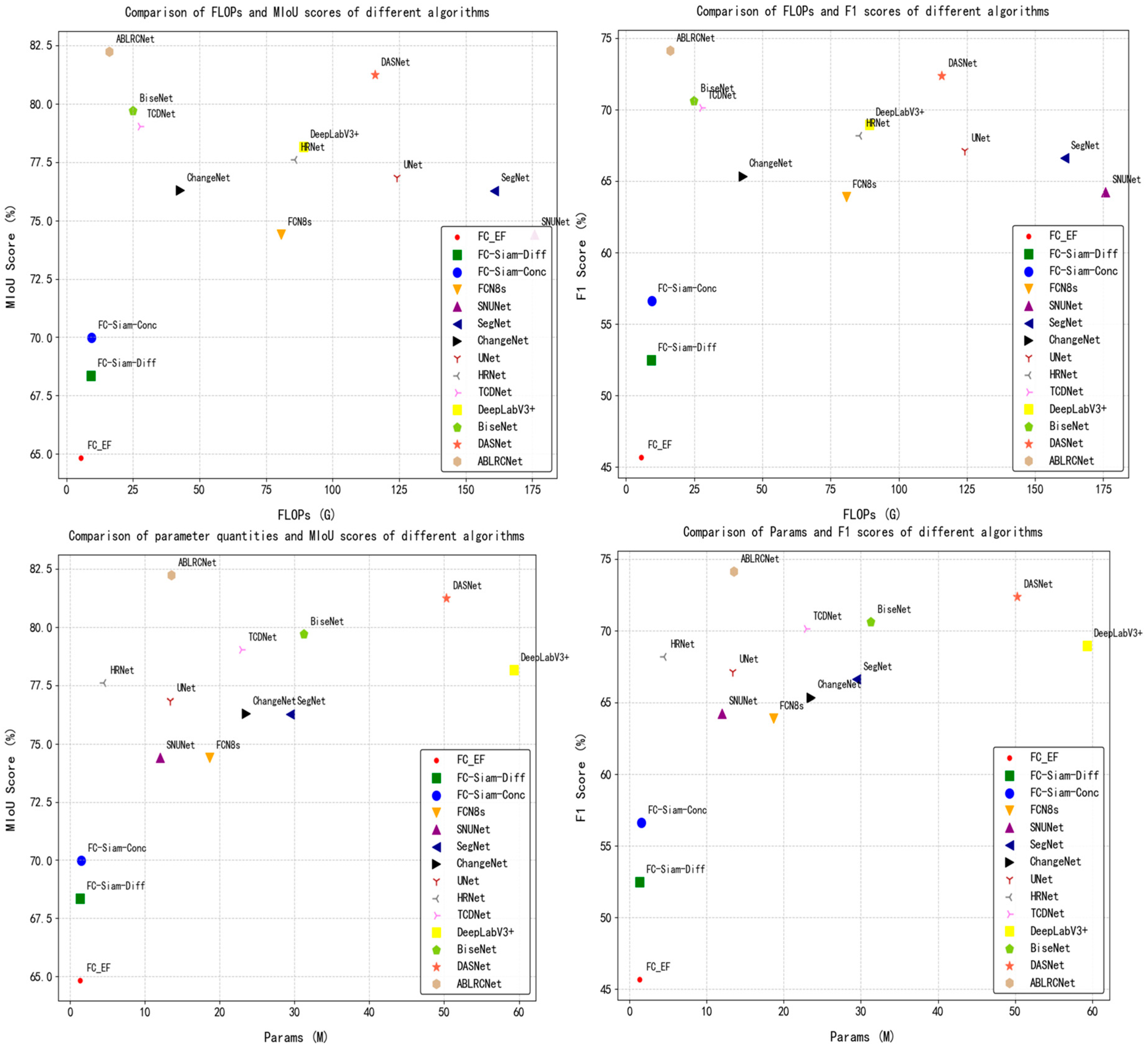
3.4. Comparative Experiments on BTCDD Dataset
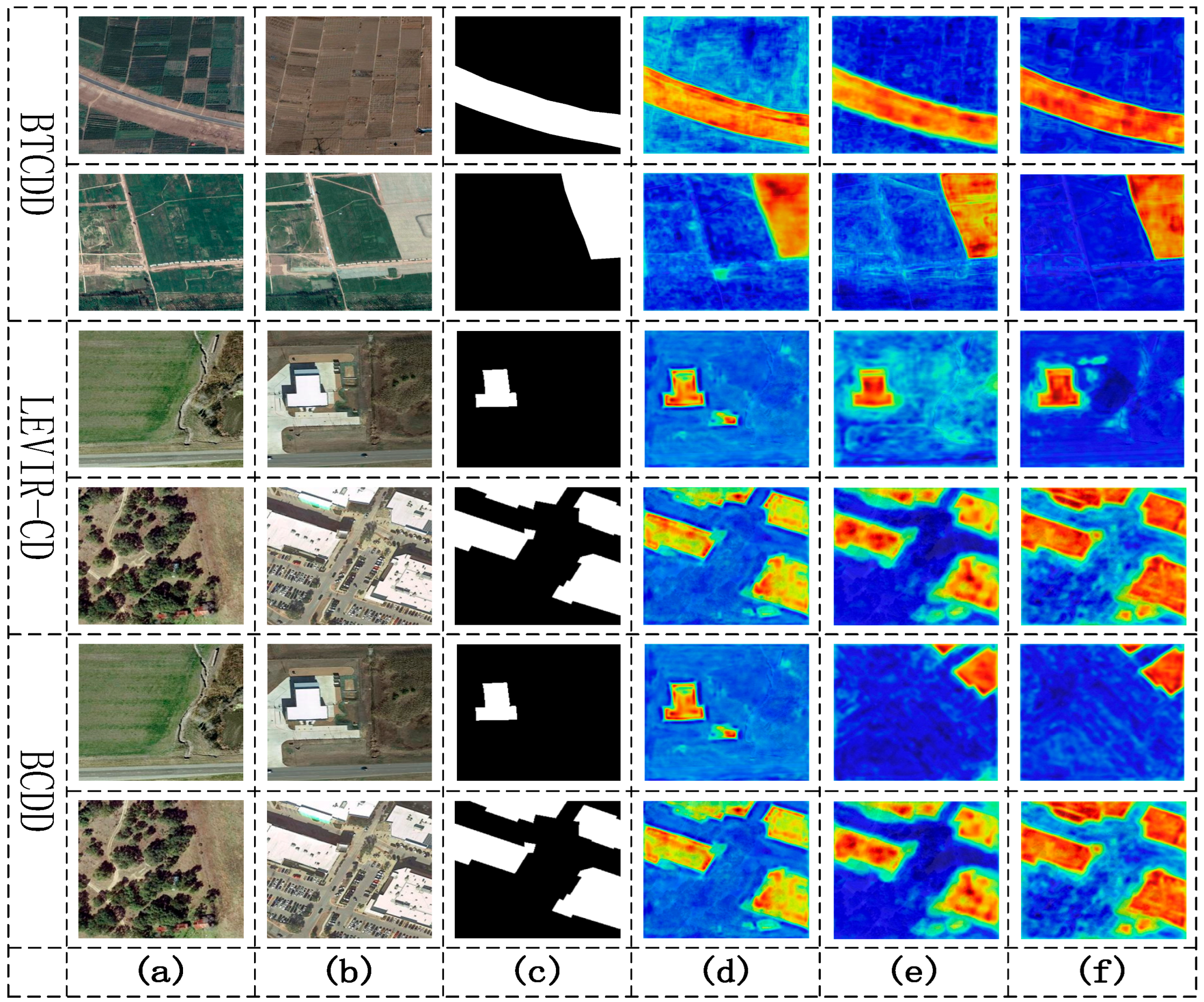
3.5. Generalization Experiments on the LEVIR-CD and BCDD Datasets
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LRCB | lightweight residual convolution block |
| MSAM | multi-scale spatial-attention module |
| FDEM | feature-difference enhancement module |
| SAR | synthetic aperture radar |
| ECA | efficient channel attention |
| SAM | spatial-attention module |
| GCP | ground control point |
References
- Liu, Y.; Wu, L.Z. Geological Disaster Recognition on Optical Remote Sensing Images Using Deep Learning. Procedia Comput. Sci. 2016, 91, 566–575. [Google Scholar] [CrossRef]
- Chughtai, A.H.; Abbasi, H.; Karas, I.R. A review on change detection method and accuracy assessment for land use land cover. Remote Sens. Appl. Soc. Environ. 2021, 22, 100482. [Google Scholar] [CrossRef]
- Cheng, P.; Xia, M.; Wang, D.; Lin, H.; Zhao, Z. Transformer Self-Attention Change Detection Network with Frozen Parameters. Appl. Sci. 2025, 15, 3349. [Google Scholar] [CrossRef]
- Tison, C.; Nicolas, J.-M.; Tupin, F.; Maitre, H. A new statistical model for Markovian classification of urban areas in high-resolution SAR images. IEEE Trans. Geosci. Remote. Sens. 2004, 42, 2046–2057. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A deep multitask learning framework coupling semantic segmentation and fully convolutional LSTM networks for urban change detection. IEEE Trans. Geosci. Remote. Sens. 2021, 59, 7651–7668. [Google Scholar] [CrossRef]
- Zhu, T.; Zhao, Z.; Xia, M.; Huang, J.; Weng, L.; Hu, K.; Lin, H.; Zhao, W. FTA-Net: Frequency-Temporal-Aware Network for Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2025, 18, 3448–3460. [Google Scholar] [CrossRef]
- Isaienkov, K.; Yushchuk, M.; Khramtsov, V.; Seliverstov, O. Deep learning for regular change detection in Ukrainian forest ecosystem with sentinel-2. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 364–376. [Google Scholar] [CrossRef]
- Zhan, Z.; Ren, H.; Xia, M.; Lin, H.; Wang, X.; Li, X. AMFNet: Attention-guided multi-scale fusion network for bi-temporal change detection in remote sensing images. Remote. Sens. 2024, 16, 1765. [Google Scholar] [CrossRef]
- Sublime, J.; Kalinicheva, E. Automatic post-disaster damage mapping using deep-learning techniques for change detection: Case study of the Tohoku tsunami. Remote. Sens. 2019, 11, 1123. [Google Scholar] [CrossRef]
- Ke, L.; Lin, Y.; Zeng, Z.; Zhang, L.; Meng, L. Adaptive Change Detection With Significance Test. IEEE Access 2018, 6, 27442–27450. [Google Scholar] [CrossRef]
- Rignot, E.J.M.; Van Zyl, J.J. Change detection techniques for ERS-1 SAR data. IEEE Trans. Geosci. Remote Sens. 1993, 31, 896–906. [Google Scholar] [CrossRef]
- Zhuang, H.; Deng, K.; Fan, H.; Yu, M. Strategies Combining Spectral Angle Mapper and Change Vector Analysis to Unsupervised Change Detection in Multispectral Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 681–685. [Google Scholar] [CrossRef]
- Li, Y.; Weng, L.; Xia, M.; Hu, K.; Lin, H. Multi-scale fusion siamese network based on three-branch attention mechanism for high-resolution remote sensing image change detection. Remote Sens. 2024, 16, 1665. [Google Scholar] [CrossRef]
- Lefebvre, A.; Corpetti, T.; Hubertmoy, L. Object-Oriented Approach and Texture Analysis for Change Detection in Very High Resolution Images. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. 1005–1013. [Google Scholar]
- Juan, S.U. A Change Detection Algorithm for Man-made Objects Based on Multi-temporal Remote Sensing Images. Acta Autom. Sin. 2008, 34, 13–19. [Google Scholar]
- Benedek, C.; Sziranyi, T. Change Detection in Optical Aerial Images by a Multilayer Conditional Mixed Markov Model. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3416–3430. [Google Scholar] [CrossRef]
- Wang, W.; Liu, C.; Liu, G.; Wang, X. CF-GCN: Graph convolutional network for change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5607013. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional Siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Ding, A.; Zhang, Q.; Zhou, X.; Dai, B. Automatic recognition of landslide based on CNN and texture change detection. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 444–448. [Google Scholar]
- Hou, B.; Wang, Y.; Liu, Q. Change detection based on deep features and low rank. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2418–2422. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change detection based on deep siamese convolutional network for optical aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Zhang, X.; Li, W.; Gao, C.; Yang, Y.; Chang, K. Hyperspectral pathology image classification using dimension-driven multi-path attention residual network. Expert Syst. Appl. 2023, 230, 120615. [Google Scholar] [CrossRef]
- Wang, F.; Wu, Y.; Zhang, Q.; Zhang, P.; Li, M.; Lu, Y. Unsupervised Change Detection on SAR Images Using Triplet Markov Field Model. IEEE Geosci. Remote Sens. Lett. 2013, 10, 697–701. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, X. The spectral-spatial joint learning for change detection in multispectral imagery. Remote Sens. 2019, 11, 240. [Google Scholar] [CrossRef]
- Ye, X.; Zhang, W.; Li, Y.; Luo, W. Mobilenetv3-yolov4-sonar: Object detection model based on lightweight network for forward-looking sonar image. In Proceedings of the OCEANS 2021: San Diego–Porto, Virtual, 20–23 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Chen, Z.; Ji, H.; Zhang, Y.; Liu, W.; Zhu, Z. Hybrid receptive field network for small object detection on drone view. Chin. J. Aeronaut. 2025, 38, 103127. [Google Scholar] [CrossRef]
- Lei, T.; Wang, J.; Ning, H.; Wang, X.; Xue, D.; Wang, Q.; Nandi, A.K. Difference enhancement and spatial–spectral nonlocal network for change detection in VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4507013. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Jiang, S.; Lin, H.; Ren, H.; Hu, Z.; Weng, L.; Xia, M. Mdanet: A high-resolution city change detection network based on difference and attention mechanisms under multi-scale feature fusion. Remote Sens. 2024, 16, 1387. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4063–4067. [Google Scholar]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Miao, L.; Li, X.; Zhou, X.; Yao, L.; Deng, Y.; Hang, T.; Zhou, Y.; Yang, H. SNUNet3+: A full-scale connected Siamese network and a dataset for cultivated land change detection in high-resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 62, 4400818. [Google Scholar] [CrossRef]
- Ji, D.; Gao, S.; Tao, M.; Lu, H.; Zhao, F. Changenet: Multi-temporal asymmetric change detection dataset. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2725–2729. [Google Scholar]
- Qian, J.; Xia, M.; Zhang, Y.; Liu, J.; Xu, Y. Tcdnet: Trilateral change detection network for google earth image. Remote Sens. 2020, 12, 2669. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Wang, L.; Zomaya, A.Y. Remote sensing change detection via temporal feature interaction and guided refinement. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5628711. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Fully convolutional change detection framework with generative adversarial network for unsupervised, weakly supervised and regional supervised change detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9774–9788. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Wu, Z.; Chen, Y.; Zhou, W.; Wei, M. Fine-Grained High-Resolution Remote Sensing Image Change Detection by SAM-UNet Change Detection Model. Remote Sens. 2024, 16, 3620. [Google Scholar] [CrossRef]
- Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241.
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A survey on deep learning-based change detection from high-resolution remote sensing images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Li, Y. The research on landslide detection in remote sensing images based on improved DeepLabv3+ method. Sci. Rep. 2025, 15, 7957. [Google Scholar] [CrossRef]
- Wang, Z.; Gu, G.; Xia, M.; Weng, L.; Hu, K. Bitemporal attention sharing network for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10368–10379. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| — | Stage | Output Size | Network 1 | Network 2 | — | Stage | Output Size | — |
|---|---|---|---|---|---|---|---|---|
| Encoder | D1 | 1/2 | [3 × 3, 32] × 3 [LRCB, 32, 2] [MSAM] | Weight Sharing | Decoder | U1 | 1/16 | [MSAM] [LRCB, 256, 1] [LRCB, 256, 1] |
| D2 | 1/4 | [LRCB, 64, 2] [LRCB, 64, 1] [MSAM] | U2 | 1/8 | [MSAM] [LRCB, 128, 1] [LRCB, 128, 1] | |||
| D3 | 1/8 | [LRCB, 128, 2] [LRCB, 128, 1] [MSAM] | U3 | 1/4 | [MSAM] [LRCB, 64, 1] [LRCB, 64, 1] | |||
| D4 | 1/16 | [LRCB, 256, 2] [LRCB, 256, 1] [MSAM] | U4 | 1/2 | [MSAM] [LRCB, 32, 1] [LRCB, 32, 1] | |||
| D5 | 1/32 | [LRCB, 512, 2] [LRCB, 512, 1] [MSAM] | Prediction | 1 | [MSAM] [1 × 1, 2] [Upsample] |
| Methods | Parameters |
|---|---|
| random rotation | −10 to 10° |
| translation | −20 to 20° |
| HSV saturation | −50 to 50% |
| random horizontal flip | 50% |
| random vertical flip | 50% |
| Dataset | Changed Pixels | Unchanged Pixels | Proportion | |
|---|---|---|---|---|
| BTCDD | train | 589,780,588 | 2,996,349,332 | 0.196 |
| val | 31,424,441 | 117,997,639 | 0.266 | |
| test | 21,277,278 | 128,144,802 | 0.166 | |
| total | 642,482,307 | 3,242,491,773 | 0.198 | |
| LEVIR-CD | train | 21,412,971 | 445,203,349 | 0.048 |
| val | 3,668,682 | 63,440,147 | 0.058 | |
| test | 6,837,404 | 127,380,324 | 0.054 | |
| total | 31,919,057 | 636,023,820 | 0.050 | |
| BCDD | train | 65,215,450 | 373,613,606 | 0.174 |
| val | 4,132,500 | 20,181,356 | 0.205 | |
| test | 3,751,149 | 20,562,707 | 0.182 | |
| total | 73,099,099 | 414,357,669 | 0.176 | |
| Method | LRCB | LRCB + SAM | LRCB + MSAM | LRCB + MSAM + FDEM | |
|---|---|---|---|---|---|
| Dataset | |||||
| BTCDD | OA (%) | 94.84 | 94.87 | 95.1 | 95.55 |
| RC (%) | 70.48 | 72.24 | 74.28 | 73.87 | |
| PR (%) | 77.15 | 75.25 | 76.36 | 77.79 | |
| F1 (%) | 71.76 | 72.3 | 73.66 | 74.14 | |
| MIoU (%) | 80.21 | 80.94 | 81.52 | 82.24 | |
| LEVIR-CD | OA (%) | 97.69 | 97.98 | 98.08 | 98.19 |
| RC (%) | 77.32 | 78.17 | 78.21 | 78.46 | |
| PR (%) | 79.56 | 81.74 | 82.18 | 83.25 | |
| F1 (%) | 77.64 | 79.32 | 79.87 | 80.19 | |
| MIoU (%) | 82.96 | 84.24 | 84.85 | 85.41 | |
| BCDD | OA (%) | 96.57 | 96.73 | 96.98 | 97.12 |
| RC (%) | 75.28 | 75.62 | 75.97 | 76.68 | |
| PR (%) | 74.24 | 74.68 | 75.12 | 75.3 | |
| F1 (%) | 72.83 | 73.21 | 73.52 | 74.01 | |
| MIoU (%) | 80.14 | 81.2 | 81.32 | 82.74 |
| Method | Processing Time (ms/Image) | Parameters (M) | FLOPs (G) |
|---|---|---|---|
| LRCB | 0.041 | 7.12 | 9.88 |
| LRCB + SAM | 0.042 | 7.13 | 9.91 |
| LRCB + MSAM | 0.048 | 9.04 | 12.91 |
| LRCB + MSAM + FDEM | 0.051 | 13.57 | 16.13 |
| Method | ABLRCNet (+−, c) | ABLRCNet (+c, −) | ABLRCNet (−c, +) | |
|---|---|---|---|---|
| Dataset | ||||
| BTCDD | OA(%) | 95.55 | 95.21 | 94.82 |
| RC(%) | 73.87 | 74.27 | 73.64 | |
| PR(%) | 77.79 | 77.56 | 76.91 | |
| F1(%) | 74.14 | 73.82 | 73.65 | |
| MIoU(%) | 82.24 | 82.02 | 81.91 | |
| LEVIR-CD | OA(%) | 98.19 | 98.08 | 98.02 |
| RC(%) | 78.46 | 78.84 | 78.36 | |
| PR(%) | 83.25 | 82.94 | 82.87 | |
| F1(%) | 80.19 | 80.06 | 79.97 | |
| MIoU(%) | 85.41 | 85.29 | 84.96 | |
| BCDD | OA(%) | 97.12 | 96.94 | 96.53 |
| RC(%) | 76.68 | 76.53 | 76.31 | |
| PR(%) | 75.3 | 74.84 | 74.62 | |
| F1(%) | 74.01 | 73.71 | 73.62 | |
| MIoU(%) | 82.74 | 82.42 | 82.13 |
| Method | OA (%) | RC (%) | PR (%) | F1 (%) | MioU (%) | FLOPs (G) | Params (M) | Time (ms) |
|---|---|---|---|---|---|---|---|---|
| FC_EF | 90.32 | 40.4 | 69.3 | 45.67 | 64.83 | 5.52 | 1.35 | 14.372 |
| FC-Siam-Diff | 91.55 | 46.56 | 73.30 | 52.46 | 68.36 | 9.29 | 1.35 | 16.258 |
| FC-Siam-Conc | 91.51 | 53.79 | 69.21 | 56.62 | 69.97 | 9.34 | 1.55 | 12.994 |
| FCN8s | 92.93 | 64.44 | 67.41 | 63.91 | 74.41 | 80.68 | 18.65 | 9.09 |
| SNUNet | 92.98 | 64.02 | 69.24 | 64.22 | 74.41 | 175.76 | 12.03 | 0.017 |
| SegNet | 93.75 | 64.38 | 72.75 | 66.62 | 76.28 | 160.72 | 29.45 | 10.526 |
| ChangeNet | 94.02 | 61.08 | 75.24 | 65.35 | 76.29 | 42.73 | 23.52 | 28.897 |
| UNet | 93.89 | 65.11 | 73.53 | 67.15 | 76.86 | 124.21 | 13.4 | 9.893 |
| HRNet | 94.10 | 66.80 | 74.21 | 68.18 | 77.61 | 85.62 | 4.49 | 33.243 |
| TCDNet | 94.38 | 68.24 | 77.22 | 70.11 | 79.03 | 27.56 | 22.91 | 20.005 |
| DeepLabV3+ | 94.39 | 67.63 | 74.62 | 68.92 | 78.17 | 89.15 | 59.35 | 32.932 |
| BiseNet | 94.81 | 67.86 | 77.6 | 70.59 | 79.71 | 24.87 | 31.26 | 14.696 |
| DASNet | 95.08 | 69.12 | 79.42 | 72.35 | 81.23 | 115.79 | 50.27 | 23.142 |
| ABLRCNet | 95.55 | 73.87 | 77.79 | 74.14 | 82.24 | 16.13 | 13.57 | 0.051 |
| Dataset | LEVIR-CD (%) | BCDD (%) | Performance Evaluation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | OA | RC | PR | F1 | MIoU | OA | RC | PR | F1 | MIoU | FLOPs (G) | Params (M) | |
| FC_EF | 97.73 | 77.08 | 77.43 | 75.75 | 82.54 | 95.77 | 65.83 | 70.04 | 65.13 | 77.14 | 1.19 | 1.35 | |
| FC-Siam-Diff | 97.99 | 78.15 | 80.74 | 78.60 | 84.24 | 94.06 | 71.99 | 63.97 | 64.61 | 75.41 | 2.32 | 1.35 | |
| FC-Siam-Conc | 97.96 | 81.09 | 80.73 | 79.59 | 84.56 | 91.93 | 76.55 | 58.06 | 62.05 | 72.31 | 2.33 | 1.55 | |
| FCN8s | 98.11 | 79.29 | 82.18 | 79.71 | 84.96 | 96.89 | 74.22 | 66.74 | 65.78 | 77.82 | 20.17 | 18.65 | |
| SNUNet | 98.16 | 82.44 | 82.21 | 81.13 | 85.58 | 96.01 | 77.38 | 69.86 | 70.45 | 79.47 | 43.94 | 12.03 | |
| SegNet | 97.91 | 78.18 | 79.93 | 77.52 | 83.53 | 96.58 | 76.42 | 77.83 | 74.45 | 81.63 | 40.18 | 29.45 | |
| ChangeNet | 97.59 | 79.57 | 76.30 | 76.51 | 82.47 | 95.39 | 73.52 | 66.77 | 67.02 | 77.56 | 10.68 | 23.52 | |
| UNet | 98.31 | 80.27 | 83.20 | 80.53 | 85.84 | 96.43 | 71.43 | 73.67 | 74.56 | 82.42 | 31.05 | 13.4 | |
| HRNet | 98.13 | 78.37 | 82.17 | 79.14 | 84.78 | 96.62 | 73.34 | 75.45 | 71.53 | 81.32 | 21.4 | 4.49 | |
| TCDNet | 97.66 | 77.24 | 79.36 | 77.26 | 82.93 | 96.97 | 74.83 | 75.47 | 73.12 | 81.79 | 6.89 | 22.91 | |
| BiseNet | 97.75 | 77.75 | 79.97 | 77.91 | 83.38 | 97.26 | 75.14 | 74.61 | 73.17 | 82.11 | 6.22 | 31.26 | |
| DeepLabV3+ | 98.07 | 80.08 | 82.13 | 80.12 | 85.06 | 97.31 | 74.41 | 75.68 | 73.31 | 82.16 | 22.29 | 59.35 | |
| DASNet | 97.88 | 80.24 | 80.85 | 78.56 | 84.72 | 96.15 | 72.23 | 74.36 | 71.24 | 80.72 | 28.95 | 50.27 | |
| ABLRCNet | 98.19 | 78.46 | 83.25 | 80.19 | 85.41 | 97.12 | 76.68 | 75.3 | 74.01 | 82.74 | 4.03 | 13.57 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, E.; Li, Y.; Lin, H.; Xia, M. A Lightweight Remote-Sensing Image-Change Detection Algorithm Based on Asymmetric Convolution and Attention Coupling. Remote Sens. 2025, 17, 2226. https://doi.org/10.3390/rs17132226
Zhang E, Li Y, Lin H, Xia M. A Lightweight Remote-Sensing Image-Change Detection Algorithm Based on Asymmetric Convolution and Attention Coupling. Remote Sensing. 2025; 17(13):2226. https://doi.org/10.3390/rs17132226
Chicago/Turabian StyleZhang, Enze, Yan Li, Haifeng Lin, and Min Xia. 2025. "A Lightweight Remote-Sensing Image-Change Detection Algorithm Based on Asymmetric Convolution and Attention Coupling" Remote Sensing 17, no. 13: 2226. https://doi.org/10.3390/rs17132226
APA StyleZhang, E., Li, Y., Lin, H., & Xia, M. (2025). A Lightweight Remote-Sensing Image-Change Detection Algorithm Based on Asymmetric Convolution and Attention Coupling. Remote Sensing, 17(13), 2226. https://doi.org/10.3390/rs17132226