
A Category–Pose Jointly Guided ISAR Image Key Part Recognition Network for Space Targets


Abstract
1. Introduction
2. Methods
2.1. ISAR Imaging Mechanism
2.2. Fine-Grained Category Training Paradigm
2.3. Network Architecture
2.3.1. Multi-Scale Feature Extraction Blocks
2.3.2. Satellite Category and Pose Classification Heads
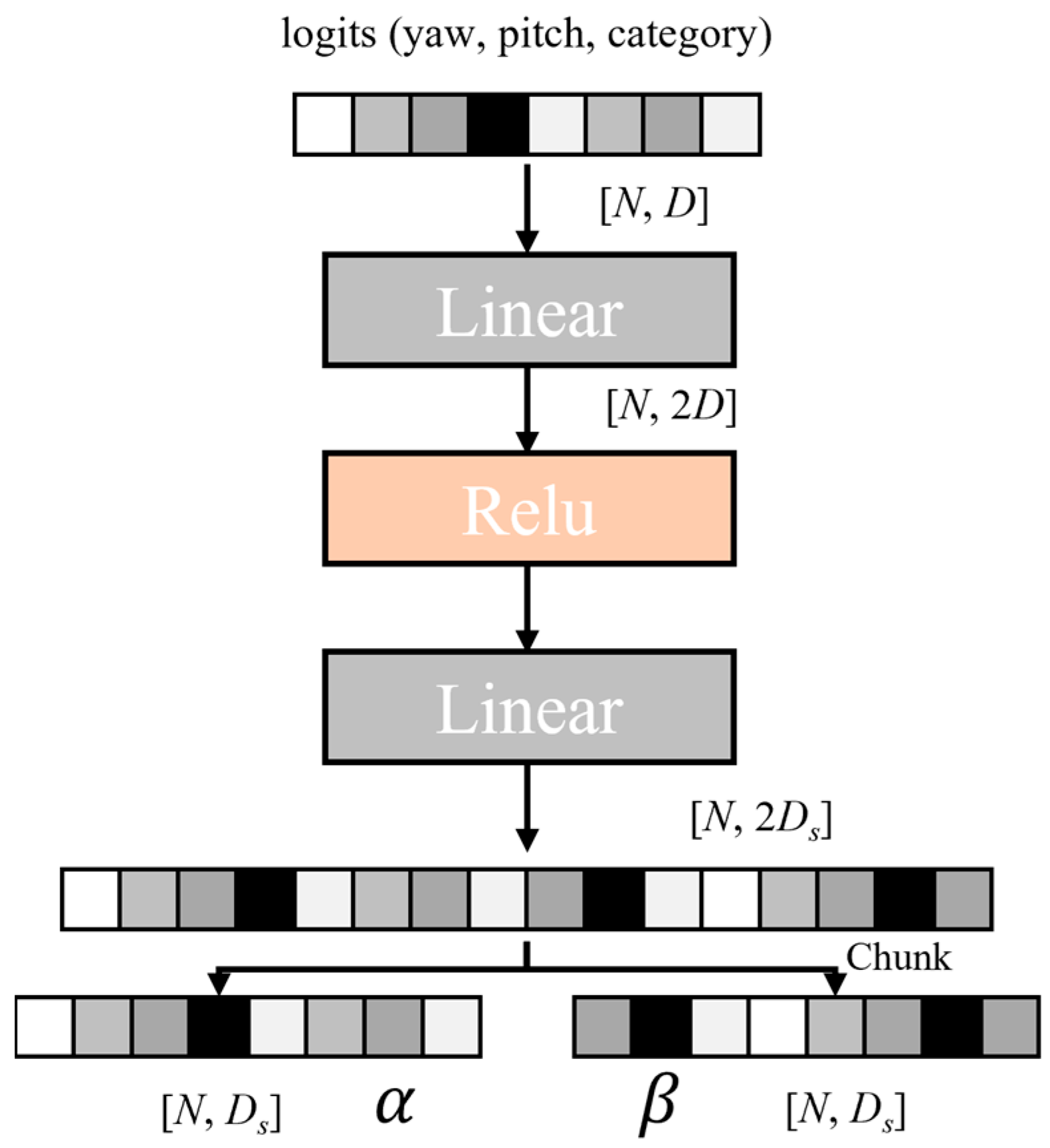
2.3.3. Category–Pose Guidance Module
2.3.4. Semantic Decoding Layer
2.4. Loss Function
3. Experiment and Discussion
3.1. Implementation Details
3.2. Experimental Configuration
3.3. Performance Analysis
3.4. Discussion on Category and Pose Prediction
3.5. Ablation Experiment
3.6. Discussion on the Limitations and Future Work
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ISAR | Inverse Synthetic Aperture Radar |
| PCA | Principal Component Analysis |
| CPGM | Category–Pose Guidance Module |
| LOS | Line-of-Sight |
| GT | Ground Truth |
| CNN | Convolutional Neural Network |
| FFN | Feed-Forward Network |
| MLP | Multi-Layer Perceptron |
| ALOS | Advanced Land Observing Satellite |
| KH | KeyHole |
| GSSAP | Geosynchronous Space Situational Awareness Program |
References
- Camp, W.W.; Mayhan, J.T.; O’Donnell, R.M. Wideband radar for ballistic missile defense and range-doppler imaging of satellites. Linc. Lab. J. 2000, 12, 267–280. [Google Scholar]
- Bai, X.; Yang, M.; Chen, B.; Zhou, F. REMI: Few-shot isar target classification via robust embedding and manifold inference. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 6000–6013. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Jiang, L.; Li, M.; Ren, X.; Wang, Z. Slow-spinning spacecraft cross-range scaling and attitude estimation based on sequential isar images. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7469–7485. [Google Scholar] [CrossRef]
- Fan, L.; Wang, H.; Yang, Q.; Deng, B. High-quality airborne terahertz video SAR imaging based on echo-driven robust motion compensation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 2001817. [Google Scholar] [CrossRef]
- Kou, P.; Qiu, X.; Liu, Y.; Zhao, D.; Li, W.; Zhang, S. ISAR image segmentation for space target based on contrastive learning and nl-unet. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3506105. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Fan, L.; Yang, Q.; Wang, H.; Qin, Y.; Deng, B. Sequential ground moving target imaging based on hybrid ViSAR-ISAR image formation in terahertz Band. IEEE Trans. Circuits Syst. Video Technol. 2025. early access. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, X.; Yuan, H.; Li, W.; Ding, H.; Wu, S.; Zhang, W.; Li, Y.; Chen, K.; Loy, C.C. Omg-seg: Is one model good enough for all segmentation? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Chen, L.-C. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, Z.H.; Wang, Z.; Jiang, L.B. Components segmentation algorithm for space target ISAR image based on clean. In Proceedings of the 2017 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Ningbo, China, 9–12 July 2017. [Google Scholar]
- Coe, M.; Jones, G.; Gashinova, M.; Cherniakov, M.; Martorella, M.; Alconcel, L.N.; Marchetti, E. Segmentation and Classification of Sub-THz ISAR Imagery. In Proceedings of the 2024 International Radar Symposium (IRS), Rennes, France, 21–25 October 2024. [Google Scholar]
- Wang, J.; Du, L.; Li, Y.; Lyu, G.; Chen, B. Attitude and size estimation of satellite targets based on isar image interpretation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5109015. [Google Scholar] [CrossRef]
- Li, C.; Zhu, W.; Qu, W.; Ma, F.; Wang, R. Component recognition of ISAR targets via multimodal feature fusion. Chin. J. Aeronaut. 2025, 38, 103122. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Y.; Lu, W.; Fang, Y.; He, J. An isar image component recognition method based on semantic segmentation and mask matching. Sensors 2023, 23, 7955. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Yang, C.; Shi, Z.; Wang, K.; Li, Y. Satellite Component Segmentation Based on Symmetry Loss and Edge Perception. In Proceedings of the 2024 IEEE 17th International Conference on Signal Processing (ICSP), Suzhou, China, 16–18 December 2024. [Google Scholar]
- Zhong, F.; Gao, F.; Liu, T.; Wang, J.; Sun, J.; Zhou, H. Scattering Characteristics Guided Network for ISAR Space Target Component Segmentation. IEEE Geosci. Remote Sens. Lett. 2025, 22, 4009505. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. Segformer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Hao, S.; Zhou, Y.; Guo, Y. A Brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Fcn | Lraspp | Deeplab_v3 | U-Net | ConvNeXt | MobileViT | Segformer | Ours |
|---|---|---|---|---|---|---|---|---|
| MPA | 73.3 | 60.9 | 82.4 | 76.0 | 82.9 | 78.3 | 88.2 | 94.3 |
| MIOU | 62.4 | 51.5 | 59.7 | 73.1 | 77.3 | 75.6 | 82.0 | 89.2 |
| Metric | W/o Pose | W/o Category | Ours |
|---|---|---|---|
| MPA | 93.8 | 87.4 | 94.3 |
| MIOU | 88.9 | 83.5 | 89.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Wang, H.; Fan, L.; Li, S. A Category–Pose Jointly Guided ISAR Image Key Part Recognition Network for Space Targets. Remote Sens. 2025, 17, 2218. https://doi.org/10.3390/rs17132218
Yang Q, Wang H, Fan L, Li S. A Category–Pose Jointly Guided ISAR Image Key Part Recognition Network for Space Targets. Remote Sensing. 2025; 17(13):2218. https://doi.org/10.3390/rs17132218
Chicago/Turabian StyleYang, Qi, Hongqiang Wang, Lei Fan, and Shuangxun Li. 2025. "A Category–Pose Jointly Guided ISAR Image Key Part Recognition Network for Space Targets" Remote Sensing 17, no. 13: 2218. https://doi.org/10.3390/rs17132218
APA StyleYang, Q., Wang, H., Fan, L., & Li, S. (2025). A Category–Pose Jointly Guided ISAR Image Key Part Recognition Network for Space Targets. Remote Sensing, 17(13), 2218. https://doi.org/10.3390/rs17132218