
Gravity-Aided Navigation Underwater Positioning Confidence Study Based on Bayesian Estimation of the Interquartile Range Method


Abstract

1. Introduction
- (1)
- An interquartile range (IQR) processing method combined with Bayesian estimation of the mean square difference (MSD) correlation is developed to select candidate matching points with an independent confidence assessment;
- (2)
- A dynamic confidence evaluation framework is established by integrating spatial distribution and probabilistic weight distributions of candidate points, enabling robust matching even in the presence of outliers;
- (3)
- The proposed method is validated using multiple sets of measured data, demonstrating its effectiveness in improving gravity-matching accuracy and reliability for long-duration underwater navigation.
2. Matching Algorithm and Confidence Calculation
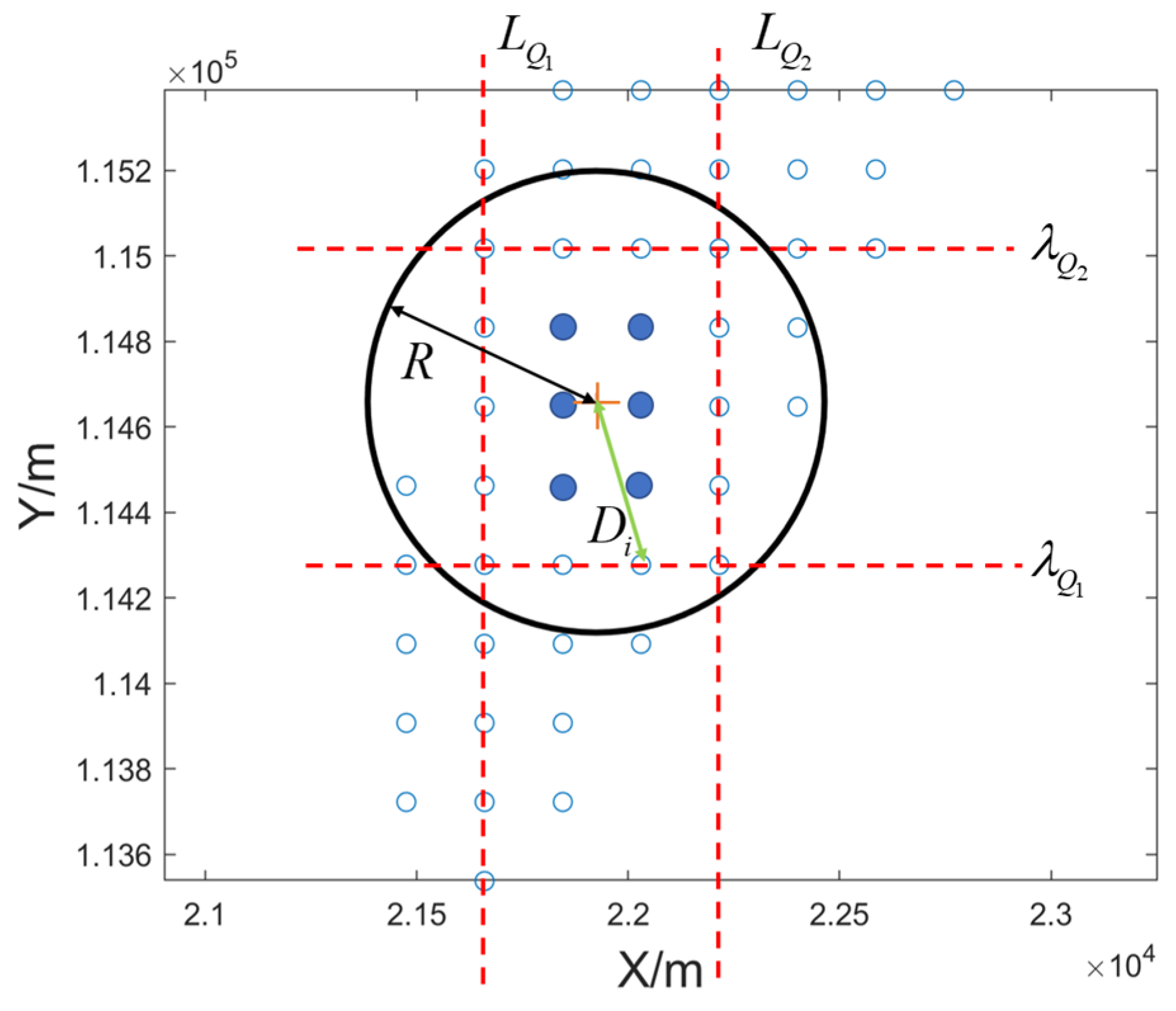
2.1. Interquartile Range Screening of To-Be-Matched Points
2.2. Confidence Analysis of the Matching Results
- (1)
- The prior probability of a point is given by Equation (1);
- (2)
- Extrapolation of the posterior probability of each point is given by Equation (9);
- (3)
- The core point coordinates and posterior probabilities determine the final match, as given by Equation (15);
- (4)
- The point within the range circle and its weight relative to the overall point weight share are given by Equation (20).
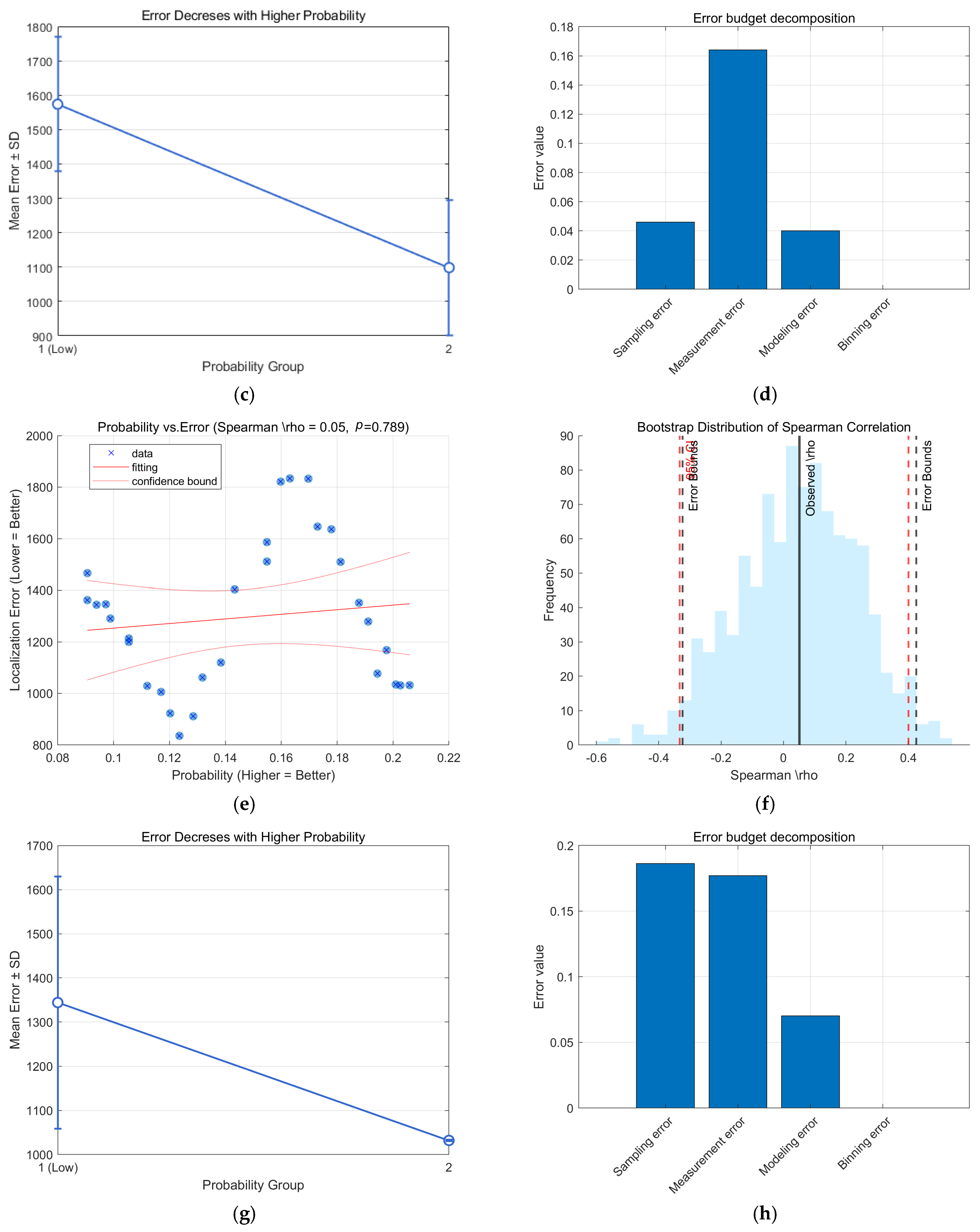
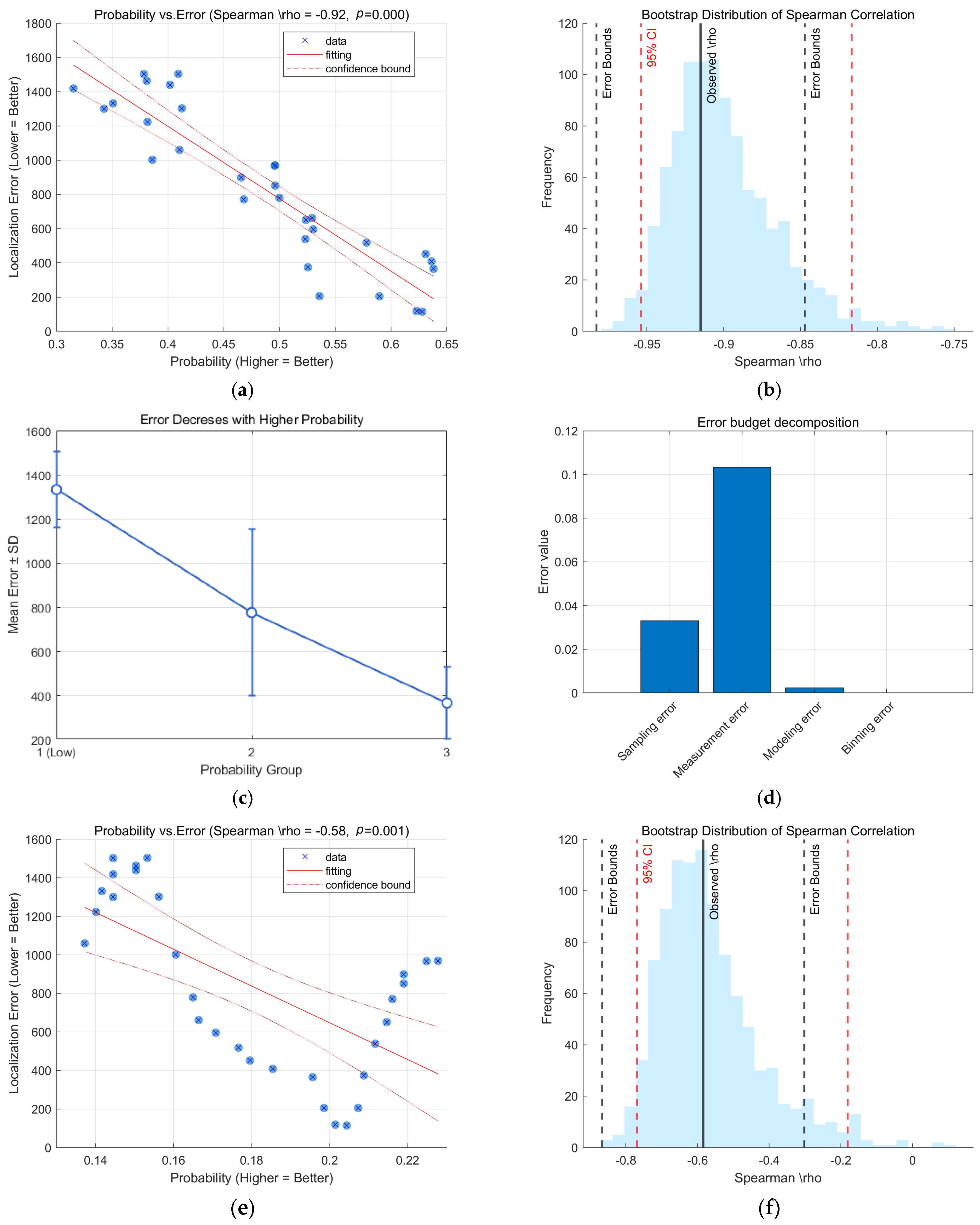
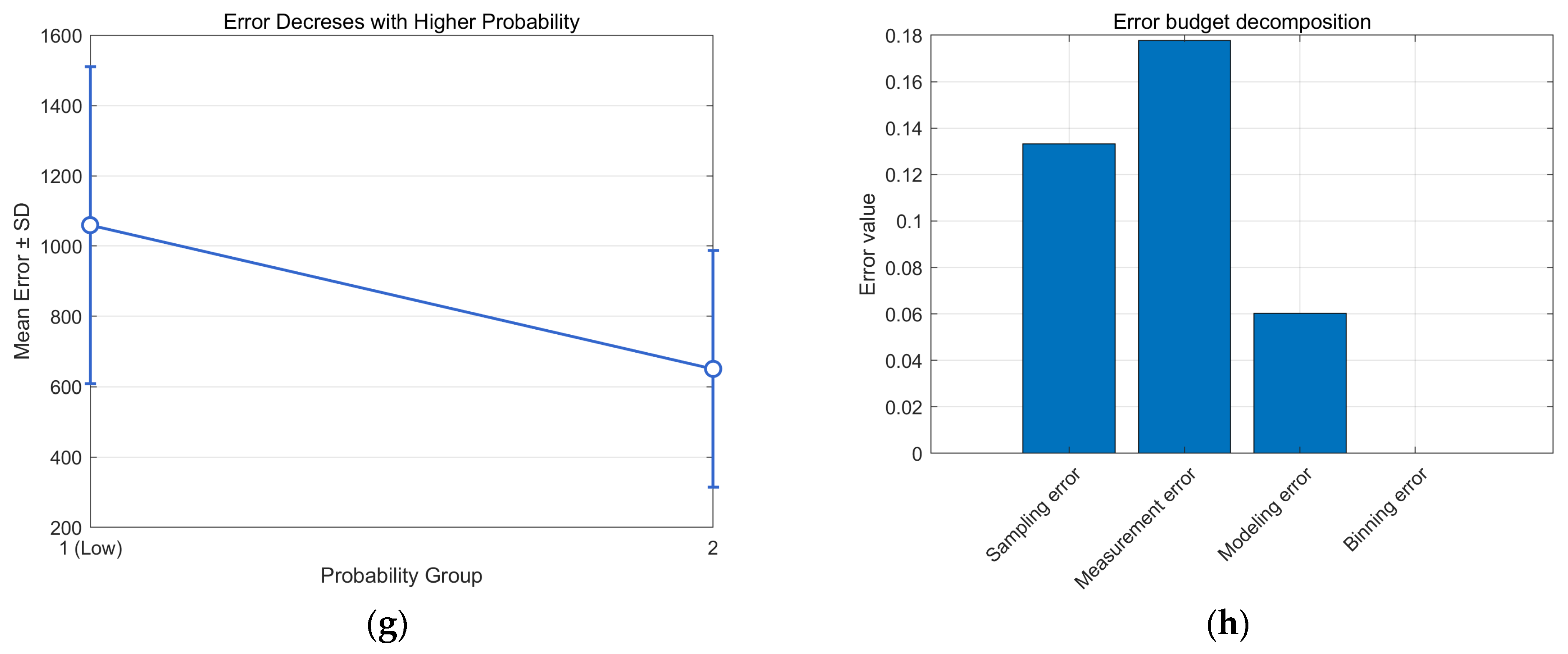
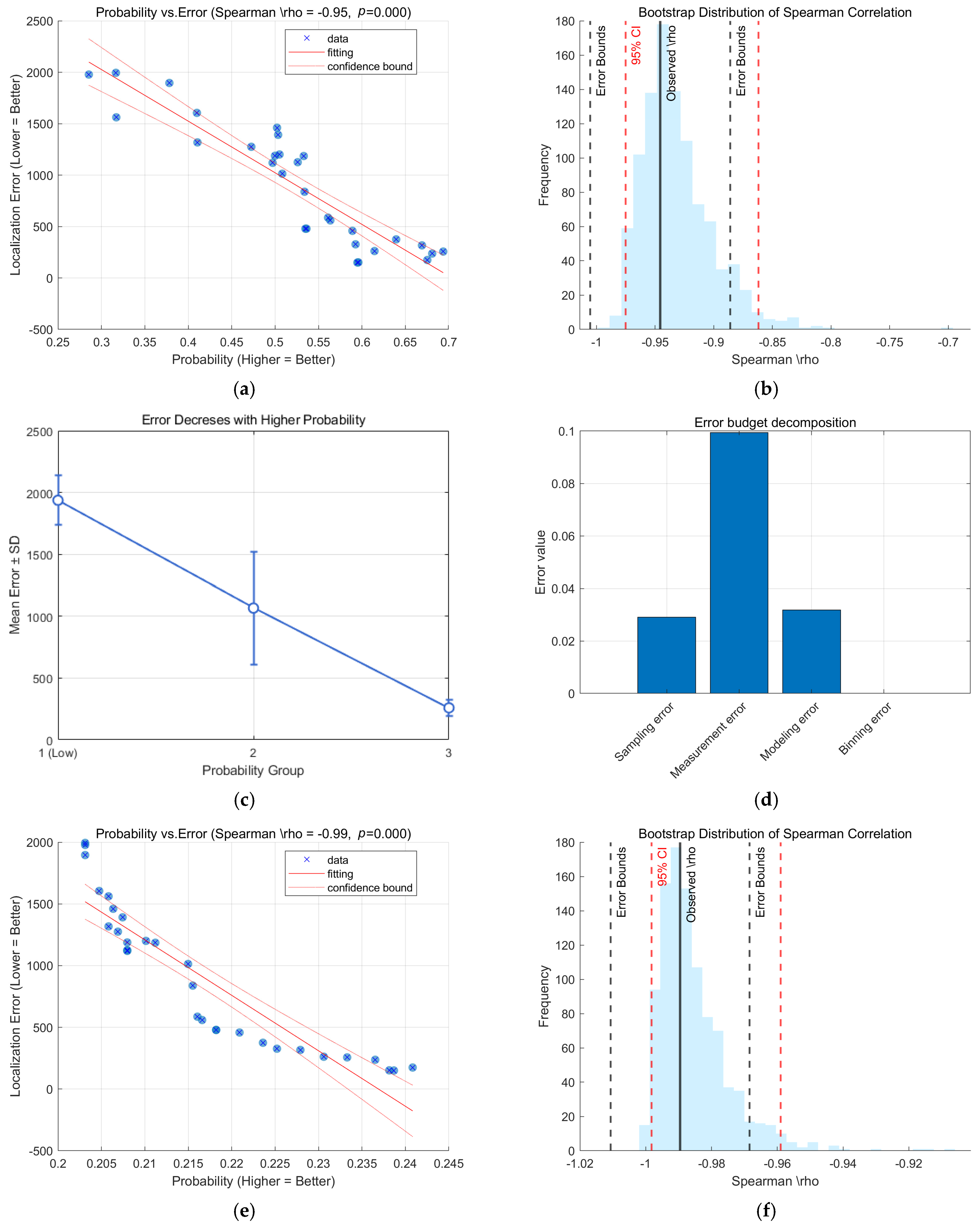
3. Confidence Testing
3.1. Relevance Calculation
3.2. Hypothesis Testing
- (1)
- Resampling: samples are taken from the original data with putbacks and repeated times to obtain ;
- (2)
- Calculate the 95% confidence intervals: ;
- (3)
- If does not contain 0, reject .
3.3. Trend Analysis of Split-Box
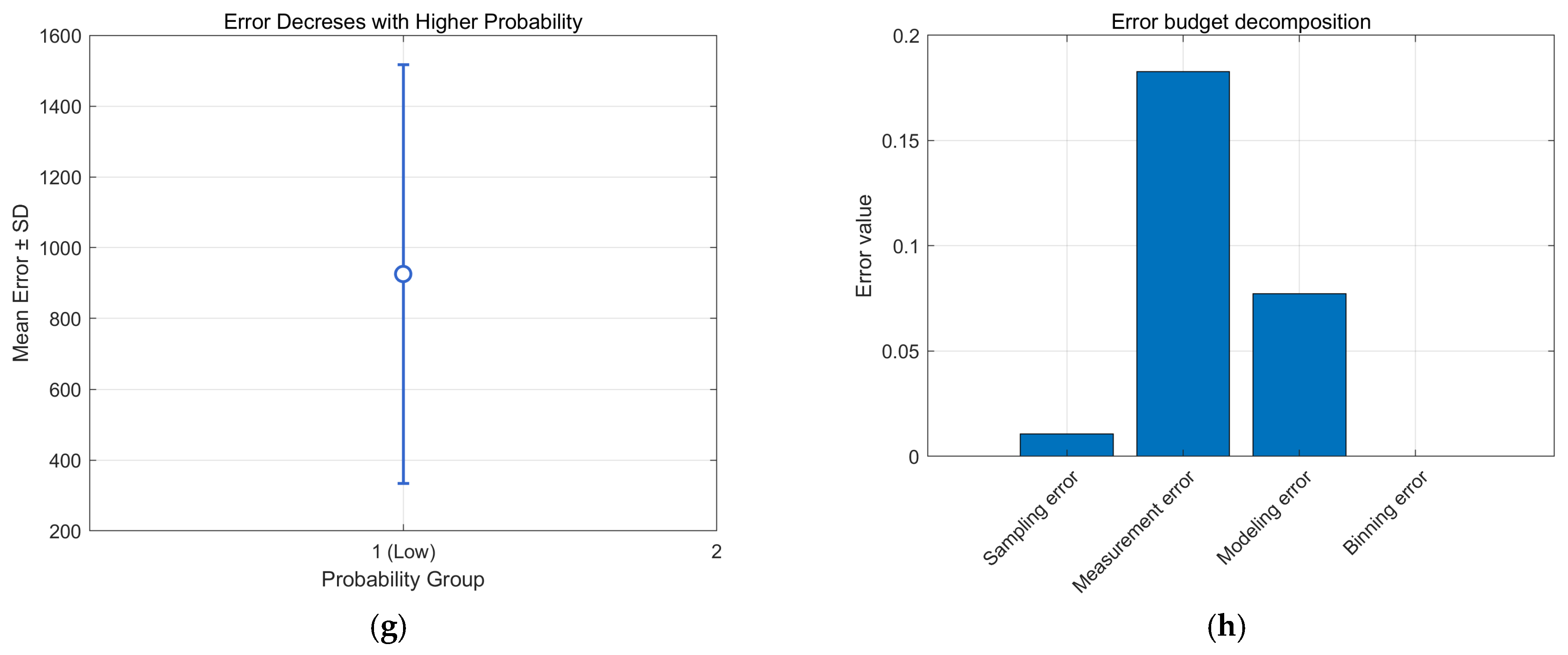
3.4. Error Bounds and Error Budget
- (1)
- The median Spearman correlation coefficient is extracted from the bootstrap sample as a point estimate;
- (2)
- Its standard deviation is calculated as a benchmark for the error boundaries;
- (3)
- The error bound is defined as the point estimate ± k × SD, where k is chosen according to the confidence level (e.g., 95% corresponds to 1.96). SD is the standard deviation
4. Experimental Results
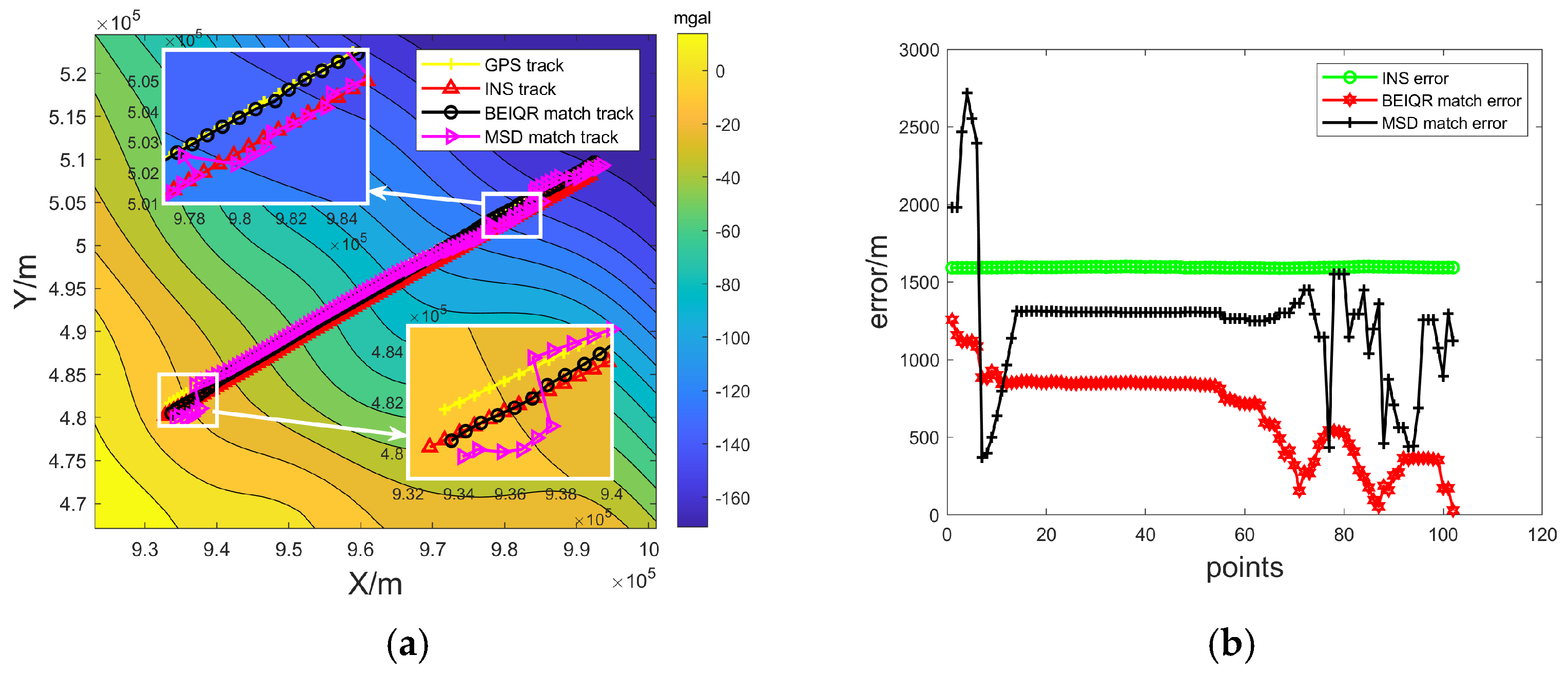
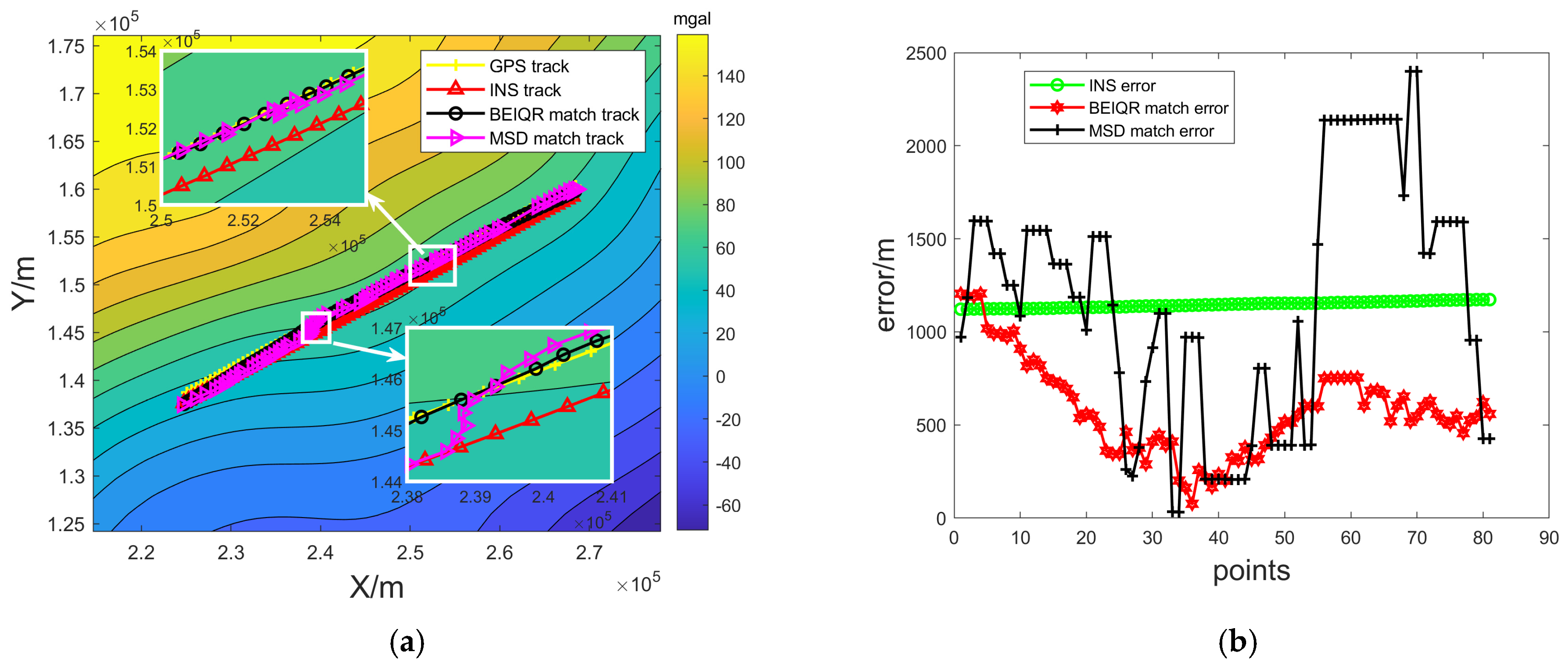
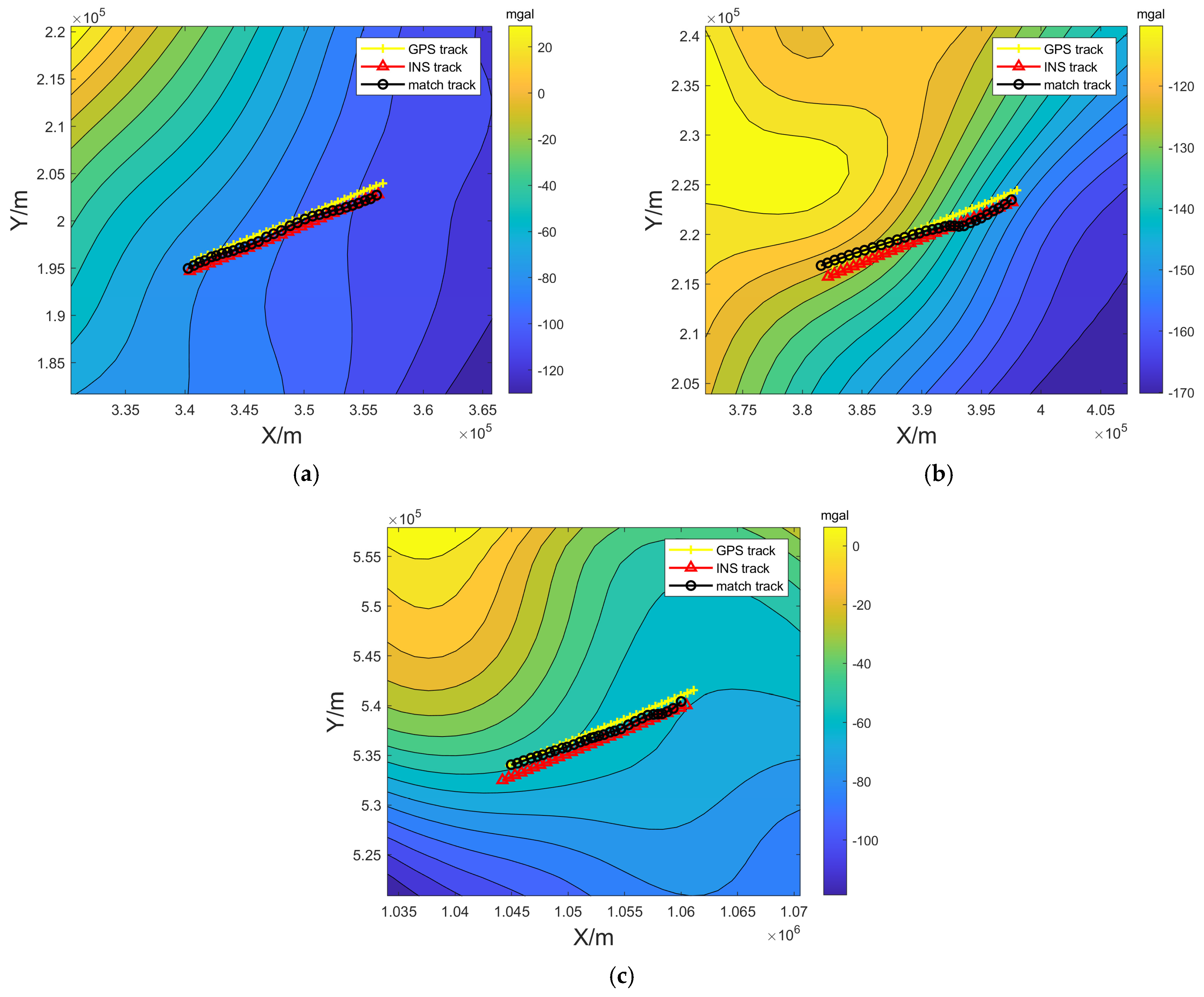
4.1. Experiments to Verify the Effectiveness of the Matching Algorithm
4.2. Experiments to Verify the Validity of the Confidence Level
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, B.; Wei, S.; Lu, J.; Wang, J.; Su, G. Fast Self-Alignment Technology for Hybrid Inertial Navigation Systems Based on a New Two-Position Analytic Method. IEEE Trans. Ind. Electron. 2020, 67, 3226–3235. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, W.; Li, Z.; Xu, A.; Zhu, H. Improving Matching Accuracy of Underwater Gravity Matching Navigation Based on Iterative Optimal Annulus Point Method with a Novel Grid Topology. Remote Sens. 2021, 13, 4616. [Google Scholar] [CrossRef]
- Jia, Y.; Li, S.; Qin, Y.; Cheng, R. Error Analysis and Compensation of MEMS Rotation Modulation Inertial Navigation System. IEEE Sens. J. 2018, 18, 2023–2030. [Google Scholar] [CrossRef]
- Ma, T.; Ding, S.; Li, Y.; Fan, J. A Review of Terrain Aided Navigation for Underwater Vehicles. Ocean Eng. 2023, 281, 114779. [Google Scholar] [CrossRef]
- Xiong, C.; Wu, L.; Liu, S.; Mao, G.; Wu, P.; Ji, B.; Bao, L.; Wang, Y. A Novel Eötvös Correction Method Based on Passive Velocity Compensated INS. IEEE Trans. Instrum. Meas. 2025, 74, 1–12. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, W.; Li, Z. Optimizing Matching Area for Underwater Gravity-Aided Inertial Navigation Based on the Convolution Slop Parameter-Support Vector Machine Combined Method. Remote Sens. 2021, 13, 3940. [Google Scholar] [CrossRef]
- Zhao, S.; Xiao, X.; Pang, X.; Wang, Y.; Deng, Z. Gravity Matching Algorithm Based on Backtracking for Small Range Adaptation Area. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, Y.; Wang, M.; Wu, J.; Zhang, Y. A Computationally Efficient Outlier-Robust Cubature Kalman Filter for Underwater Gravity Matching Navigation. IEEE Trans. Instrum. Meas. 2022, 71, 1–18. [Google Scholar] [CrossRef]
- Zou, J.; Cai, T. Improved Particle Swarm Optimization Screening Iterative Algorithm in Gravity Matching Navigation. IEEE Sens. J. 2022, 22, 20866–20876. [Google Scholar] [CrossRef]
- Mao, N.; Li, A.; Xu, J.; Li, F.; Qin, F.; He, H.; Li, J.; Zhu, B. Adaptive Gravity-Aided Inertial Navigation Based on Characteristic Analysis of Marine Gravity Anomaly From Satellite Altimetry. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Zhao, S.; Xiao, X.; Deng, Z.; Shi, L. Gravity Matching Algorithm Based on Correlation Filter. IEEE Sens. J. 2023, 23, 2618–2629. [Google Scholar] [CrossRef]
- Zhao, X.; Zheng, W.; Xu, K.; Zhang, H. Optimizing the Matching Area for Underwater Gravity Matching Navigation Based on a New Gravity Field Feature Parameters Selection Method. Remote Sens. 2024, 16, 2202. [Google Scholar] [CrossRef]
- Wang, B.; Zhu, Y.; Deng, Z.; Fu, M. The Gravity Matching Area Selection Criteria for Underwater Gravity-Aided Navigation Application Based on the Comprehensive Characteristic Parameter. IEEE/ASME Trans. Mechatron. 2016, 21, 2935–2943. [Google Scholar] [CrossRef]
- Wang, B.; Li, T.; Deng, Z.; Fu, M. Wavelet Transform Based Morphological Matching Area Selection for Underwater Gravity Gradient-Aided Navigation. IEEE Trans. Veh. Technol. 2023, 72, 3015–3024. [Google Scholar] [CrossRef]
- Wang, C.; Wang, B.; Deng, Z.; Fu, M. A Delaunay Triangulation-Based Matching Area Selection Algorithm for Underwater Gravity-Aided Inertial Navigation. IEEE/ASME Trans. Mechatron. 2021, 26, 908–917. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, G.; Zhao, J. The Study on the TERCOM Mismatch Diagnostic Based on Detecting the Extreme Value of Similarity. In Proceedings of the 2011 Second International Conference on Mechanic Automation and Control Engineering, Inner Mongolia, China, 15–17 July 2011; pp. 4623–4626. [Google Scholar]
- Zhao, S.; Zheng, W.; Li, Z.; Zhu, H.; Xu, A. Improving Matching Efficiency and Out-of-Domain Positioning Reliability of Underwater Gravity Matching Navigation Based on a Novel Domain-Center Adaptive-Transfer Matching Method. IEEE Trans. Instrum. Meas. 2023, 72, 1–11. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, W.; Li, Z.; Zhu, H.; Xu, A. Improving Matching Efficiency and Out-of-Domain Reliability of Underwater Gravity Matching Navigation Based on a Novel Soft-Margin Local Semicircular-Domain Re-Searching Model. Remote Sens. 2022, 14, 2129. [Google Scholar] [CrossRef]
- Han, Y.; Wang, B.; Deng, Z.; Wang, S.; Fu, M. A Mismatch Diagnostic Method for TERCOM-Based Underwater Gravity-Aided Navigation. IEEE Sens. J. 2017, 17, 2880–2888. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, W.; Li, Z.; Zhu, H.; Xu, A. A Novel Cross-Line Adaptive Domain Matching Algorithm for Underwater Gravity Aided Navigation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Gao, S.; Cai, T. A Confidence Assessment Method for Positioning Errors in Gravity-Aided Navigation. In Proceedings of the 2023 International Conference on Ocean Studies (ICOS), Vladivostok, Russia, 3–6 October 2023; pp. 007–010. [Google Scholar]
- Han, Y.; Wang, B.; Deng, Z.; Fu, M. An Improved TERCOM-Based Algorithm for Gravity-Aided Navigation. IEEE Sens. J. 2016, 16, 2537–2544. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, B.; Bi, R. A Mismatch Correction Method Based on Two-Way Strategies of Spatial Vector Feature. In Proceedings of the 2024 IEEE 18th International Conference on Control & Automation (ICCA), Reykjavík, Iceland, 18–21 June 2024; pp. 573–578. [Google Scholar]
- Yang, Y.; Wang, K. Mismatching Judgment Using PDAF in ICCP Algorithm. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 4, pp. 172–176. [Google Scholar]
- Li, Z.; Zheng, W.; Wu, F. Improving the Reliability of Underwater Gravity Matching Navigation Based on a Priori Recursive Iterative Least Squares Mismatching Correction Method. IEEE Access 2020, 8, 8648–8657. [Google Scholar] [CrossRef]
- Yoo, Y.M.; Lee, W.H.; Lee, S.M.; Park, C.G.; Kwon, J.H. Improvement of TERCOM Aided Inertial Navigation System by Velocity Correction. In Proceedings of the 2012 IEEE/ION Position, Location and Navigation Symposium, Myrtle Beach, SC, USA, 23–26 April 2012; pp. 1082–1087. [Google Scholar]
- Wang, B.; Cai, T.; Fang, K. Observation-Differenced Point Mass Filter in Gravity-Aided Inertial Navigation. IEEE/ASME Trans. Mechatron. 2024, 29, 1601–1606. [Google Scholar] [CrossRef]
- Yurong, H.; Bo, W.; Zhihong, D.; Mengyin, F. Point Mass Filter Based Matching Algorithm in Gravity Aided Underwater Navigation. J. Syst. Eng. Electron. 2018, 29, 152–159. [Google Scholar] [CrossRef]
- Sandwell, D.T.; Mueller, R.D.; Smith, W.H.F.; Garcia, E.; Francis, R. New Global Marine Gravity Model from CryoSat-2 and Jason-1 Reveals Buried Tectonic Structure. Science 2014, 346, 65–67. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Measuring Equipment Parameters | |
|---|---|
| Parameter | Value |
| Gyro constant drift | |
| Gyro random error | |
| Accelerometer zero bias | 10 µg |
| Accelerometer random drift | |
| Experiment | Variance | Information Entropy | Correlation Coefficient | Degree of Relevance | Confidence Interval | ||
|---|---|---|---|---|---|---|---|
| BEIQRC | KTERCOMC | BEIQRC | KTERCOMC | ||||
| 1 | 1033.43 | 7.1843 | −0.0076 | −0.90 | 0.05 | [−0.76, −0.95] | [0.32, 0.40] |
| 2 | 358.68 | 7.6207 | −0.1537 | −0.92 | −0.58 | [−0.81, −0.95] | [−0.24, −0.75] |
| 3 | 681.03 | 7.2725 | 0.2254 | −0.95 | −0.99 | [−0.85, −0.97] | [−0.96, −0.99] |
| 4 | 2562.93 | 7.5286 | 0.6596 | −0.93 | −0.97 | [−0.83, −0.95] | [−0.88, −0.99] |
| 5 | 13.03 | 7.3913 | −0.4203 | −0.92 | −0.81 | [−0.82, −0.96] | [−0.62, −0.92] |
| 6 | 58.74 | 7.6711 | −0.2576 | −0.91 | 0.66 | [−0.77, −0.97] | [0.26, 0.84] |
|
Sampling Error | Measurement Error | Modeling Error |
Binning Error | Total Error | ||
|---|---|---|---|---|---|---|
| 1 | 0.04596 | 0.16408 | 0.04008 | 0 | 0.17505 | |
| BEIQRC | 2 | 0.03300 | 0.10337 | 0.00234 | 0 | 0.10854 |
| 3 | 0.02902 | 0.09939 | 0.03177 | 0 | 0.10831 | |
| 1 | 0.18619 | 0.17713 | 0.07029 | 0 | 0.26643 | |
| KTERCOMC | 2 | 0.13328 | 0.17763 | 0.06016 | 0 | 0.23008 |
| 3 | 0.01066 | 0.18277 | 0.07719 | 0 | 0.19869 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Cai, T.; Zhao, S. Gravity-Aided Navigation Underwater Positioning Confidence Study Based on Bayesian Estimation of the Interquartile Range Method. Remote Sens. 2025, 17, 2137. https://doi.org/10.3390/rs17132137
Zou J, Cai T, Zhao S. Gravity-Aided Navigation Underwater Positioning Confidence Study Based on Bayesian Estimation of the Interquartile Range Method. Remote Sensing. 2025; 17(13):2137. https://doi.org/10.3390/rs17132137
Chicago/Turabian StyleZou, Jiasheng, Tijing Cai, and Shiliang Zhao. 2025. "Gravity-Aided Navigation Underwater Positioning Confidence Study Based on Bayesian Estimation of the Interquartile Range Method" Remote Sensing 17, no. 13: 2137. https://doi.org/10.3390/rs17132137
APA StyleZou, J., Cai, T., & Zhao, S. (2025). Gravity-Aided Navigation Underwater Positioning Confidence Study Based on Bayesian Estimation of the Interquartile Range Method. Remote Sensing, 17(13), 2137. https://doi.org/10.3390/rs17132137