GAT-Enhanced YOLOv8_L with Dilated Encoder for Multi-Scale Space Object Detection

 ,
,
Abstract
1. Introduction
- Abandon the original Feature Pyramid Network (FPN) structure, propose an adaptive fusion strategy based on multi-level features of backbone network, enhance the expression ability of multi-scale targets through upsampling and feature stacking, and reconstruct FPN.
- By introducing GAT, we propose a novel space image object detection algorithm to address the limitations of convolutional neural networks, combining their respective strengths to enhance overall detection performance.
- The Dilated Encoder network is introduced to cover different scale targets by differentiating receptive fields.
- This study establishes a novel spacecraft imagery dataset specifically designed to advance object detection algorithms in orbital environments. Through systematic validation on the dataset, we quantitatively verify the functional significance of each technical component and its contribution to performance enhancement.
2. Related Works
2.1. YOLOv8 Object Detection Algorithm
2.2. YOLOF Object Detection Algorithm
2.3. Graph Neural Network
2.4. Attention Mechanism
2.5. Space Object Dataset
3. Methods
3.1. Framework Solution of Improved YOLOv8_L
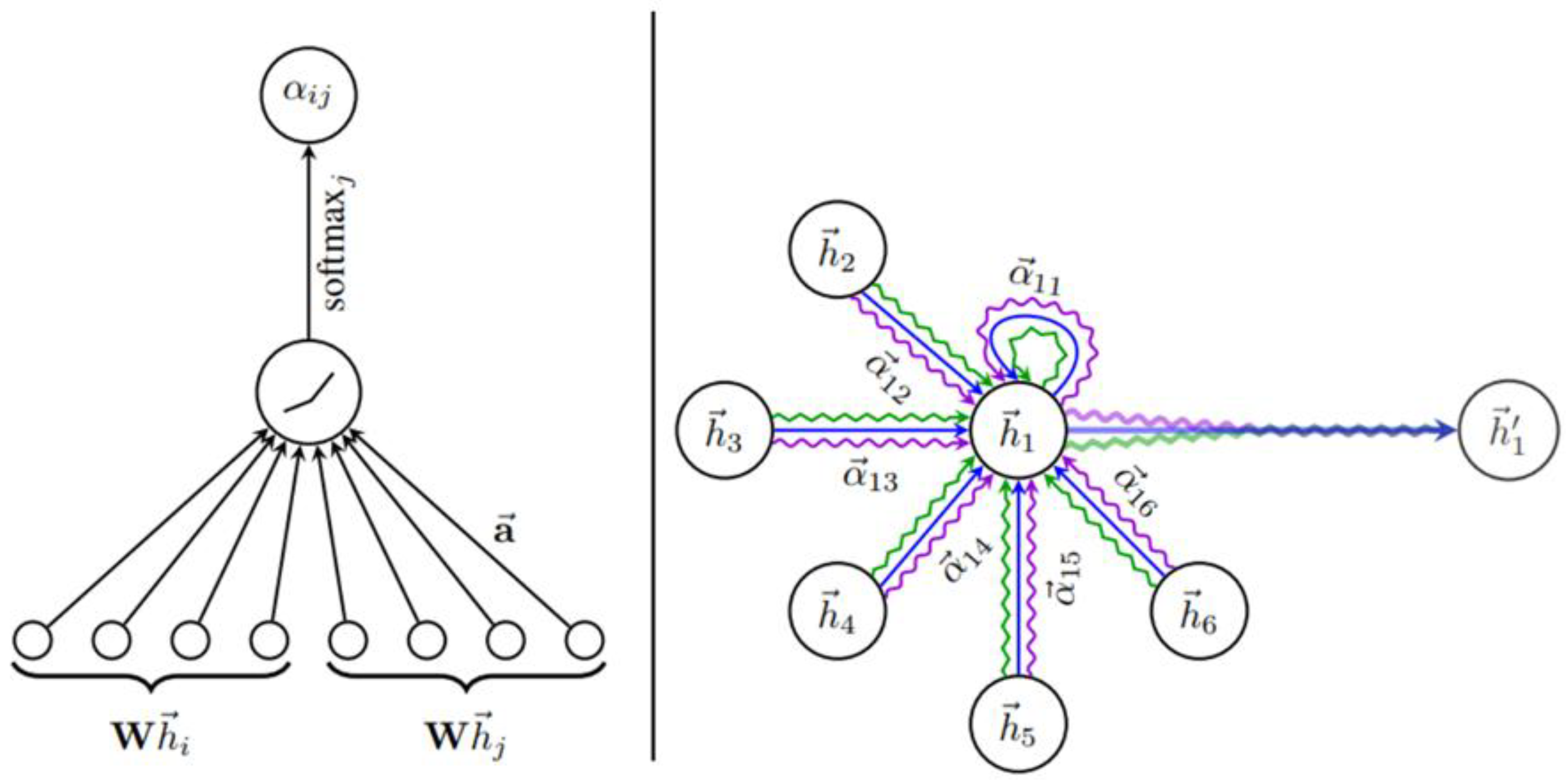
3.2. Graph Attention Network
3.3. Dilated Encoder Network
3.4. Improvement of FPN in YOLOv8_L
3.5. Improvement in YOLOHead Network in YOLOv8_L
3.6. Construct Space Object Dataset
- We consider the production of satellite model dataset under strong light interference, and some of the renderings are shown in Figure 7a–c.
- A satellite model dataset is made from different angles and scales. The partial renderings are shown in Figure 7d–f.
- Considering the imaging effect of the satellite model in a dark light environment, some of the renderings are shown in Figure 7g–i.
4. Experiments
4.1. Datasets
4.2. Experimental Parameter Configuration
- NVIDIA GeForce RTX4090 GPU with CUDA 11.6.
- OS: Windows 10 Pro 64-bit.
- Deep Learning Framework: PyTorch 1.13.1.
- Language: Python 3.10.
- IDE: Jupyter.
- Epochs: 100.
- Batch Size: 8.
- Learning Rate: 0.01.
- Optimizer: SGD.
4.3. Evaluation Indicators
5. Results and Discussion
5.1. Contrastive Experiments Results on the VOC2007 + 2012 Dataset
5.2. Visual Experiment Results on the Space Object Dataset
5.3. Contrastive Experiments Results on the Space Object Dataset
5.4. Ablation Experiment Results on the Space Object Dataset
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.P.; Deng, C.W.; Deng, Z.Y. A Diverse Space Target Dataset With Multidebris and Realistic On-Orbit Environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9102–9114. [Google Scholar] [CrossRef]
- Ai, H.; Zhang, H.F.; Ren, L.; Feng, J.; Geng, S.N. Detection and Recognition of Spatial Non-Cooperative Objects Based on Improved YOLOX_L. Electronics 2022, 11, 3433. [Google Scholar] [CrossRef]
- Shan, M.H.; Guo, J.; Gill, E. Review and comparison of active space debris capturing and removal methods. Prog. Aerosp. Sci. 2016, 80, 18–32. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Z.; Ai, X.; Wu, Q.; Liu, X.; Cheng, J. A Novel Method for PolISAR Interpretation of Space Target Structure Based on Component Decomposition and Coherent Feature Extraction. Remote Sens. 2025, 17, 1079. [Google Scholar] [CrossRef]
- Su, H.; You, Y.; Liu, S. Multi-Oriented Enhancement Branch and Context-Aware Module for Few-Shot Oriented Object Detection in Remote Sensing Images. Remote Sens. 2023, 15, 3544. [Google Scholar] [CrossRef]
- Wu, W.; Cui, S.; Zhang, P.; Dong, S.; He, Q. Development of intelligent processing technology of space remote sensing. Space Int. 2024, 59–64. [Google Scholar]
- Wang, Z.; Hu, Y.; Yang, J.; Zhou, G.; Liu, F.; Liu, Y. A ContrastiveAugmented Memory Network for Anti-UAV Tracking in TIR Videos. Remote Sens. 2024, 16, 4775. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.Q.; Han, J.W. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Yang, L.; Wang, H.; Zeng, Y.; Liu, W.; Wang, R.; Deng, B. Detection of Parabolic Antennas in Satellite Inverse Synthetic Aperture Radar Images Using Component Prior and Improved-YOLOv8 Network in Terahertz Regime. Remote Sens. 2025, 17, 604. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics/yolov5: v4.0—nn.SiLU Activations, Weights & Biases logging, PyTorch Hub integration. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 January 2023).
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Jocher, G.C.A.; Qiu, J. YOLO by Ultralytics. DB/OL. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. arXiv 2022, arXiv:2201.12329. [Google Scholar] [CrossRef]
- Wu, T.; Yang, X.; Song, B.; Wang, N.; Yang, D. T-SCNN: A Two-Stage Convolutional Neural Network for Space Target Recognition. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Xiang, Y.; Xi, J.; Cong, M.; Yang, Y.; Ren, C.; Han, L. Space debris detection with fast grid-based learning. In Proceedings of the 2020 IEEE 3rd International Conference of Safe Production and Informatization (IICSPI), Chongqing, China, 28–30 November 2020; pp. 205–209. [Google Scholar]
- Wang, G.; Lei, N.; Liu, H. Improved-YOLOv3 network for object detection in simulated Space Solar Power Systems images. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar]
- Jia, P.; Liu, Q.; Sun, Y.Y. Detection and Classification of Astronomical Targets with Deep Neural Networks in Wide-field Small Aperture Telescopes. Astron. J. 2020, 159, 212. [Google Scholar] [CrossRef]
- AlDahoul, N.; Karim, H.A.; De Castro, A.; Tan, M.J.T. Localization and classification of space objects using EfficientDet detector for space situational awareness. Sci. Rep. 2022, 12, 1–19. [Google Scholar] [CrossRef]
- Mahendrakar, T.; White, R.T.; Wilde, M.; Tiwari, M. SpaceYOLO: A Human-Inspired Model for Real-time, On-board Spacecraft Feature Detection. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2023. [Google Scholar]
- Tang, Q.; Li, X.W.; Xie, M.L.; Zhen, J.L. Intelligent Space Object Detection Driven by Data from Space Objects. Appl. Sci. 2024, 14, 333. [Google Scholar] [CrossRef]
- Massimi, F.; Ferrara, P.; Petrucci, R.; Benedetto, F. Deep learning-based space debris detection for space situational awareness: A feasib ility study applied to the radar processing. IET Radar Sonar Navig. 2024, 18, 635–648. [Google Scholar] [CrossRef]
- Guo, X.J.; Chen, T.; Liu, J.C.; Liu, Y.; An, Q.C. Dim Space Target Detection via Convolutional Neural Network in Single Optical Image. IEEE Access 2022, 10, 52306–52318. [Google Scholar] [CrossRef]
- Jiang, Y.X.; Tang, Y.J.; Ying, C.C. Finding a Needle in a Haystack: Faint and Small Space Object Detection in 16-Bit Astronomical Images Using a Deep Learning-Based Approach. Electronics 2023, 12, 4820. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE Transactions on Pattern Analysis & Machine Intelligence, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, P.; Sun, W.; Xu, J.; Liao, L.; Cao, Y.; Han, Y. Improving plant miRNA-target prediction with self-supervised k-mer embedding and spectral graph convolutional neural network. PeerJ 2024, 12, e17396. [Google Scholar] [CrossRef]
- Velikovi, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference On Learning Representations, New Orleans, LA, USA, 6 May 2019. [Google Scholar]
- Tang, G.; Yang, L.; Zhang, L.; Cao, W.; Meng, L.; He, H.; Kuang, H.; Yang, F.; Wang, H. An attention-based automatic vulnerability detection approach with GGNN. Int. J. Mach. Learn. Cybern. 2023, 14, 3113–3127. [Google Scholar] [CrossRef]
- Cai, H.; Wang, Y.; Liu, L.; Zhu, S.; Chen, M. DAGNN: Deep Autoencoder-Based Graph Neural Network for Local Anomaly Detection. In Proceedings of the 2024 6th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 10–12 May 2024. [Google Scholar]
- Wang, Y.; Xiao, H.; Ma, C.; Zhang, Z.; Cui, X.; Xu, A. On-board detection of rail corrugation using improved convolutional block attention mechanism. Eng. Appl. Artif. Intell. 2025, 146, 110349. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G.; Albanie, S. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zheng, S.; Jiang, L.; Yang, Q.; Zhao, Y.; Wang, Z. GS-orthogonalization OMP method for space target detection via bistatic space-based radar. Chin. J. Aeronaut. 2024, 37, 333–351. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, R.; Yu, S. Deep Neural Network closed-loop with raw data for optical resident space object detection. Res. Astron. Astrophys. 2024, 24, 95–103. [Google Scholar] [CrossRef]
- Agrawal, S.; Sharma, A.; Bhatnagar, C.; Chauhan, D.S. Modelling and Analysis of Emitter Geolocation using Satellite Tool Kit. Def. Sci. J. 2020, 70, 440–447. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, H.; Ji, M.; Lu, T.; Zhang, C.; Yu, Y. Lightweight multi-scale feature fusion enhancement algorithm for spatial noncooperative small target detection. J. Beijing Univ. Aeronaut. Astronaut. 2024, 1–12. [Google Scholar] [CrossRef]
- Hoang, D.A.; Chen, B.; Chin, T.J. A Spacecraft Dataset for Detection, Segmentation and Parts Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision, Nashville, TN, USA, 11–15 June 2025. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv.2010.04159. [Google Scholar] [CrossRef]
- Li, F.; Zhang, H.; Zhang, N.L. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 2239–2251. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision/% | Recall/% | mAP50/% | mAP50-95/% | FPS | GFLOPs | Params/M |
|---|---|---|---|---|---|---|---|
| YOLOv5_L | 0.728 | 0.684 | 0.711 | 0.594 | 207 | 109.1 | 46.5 |
| YOLOv6_L | 0.811 | 0.717 | 0.802 | 0.624 | 153 | 391.2 | 110.9 |
| YOLOv7 | 0.794 | 0.733 | 0.797 | 0.562 | 185 | 105.4 | 37.29 |
| YOLOv8_L | 0.823 | 0.761 | 0.839 | 0.669 | 227 | 165.7 | 43.62 |
| OURS | 0.844 | 0.782 | 0.861 | 0.680 | 248 | 150.8 | 36.57 |
| YOLOv9_C | 0.833 | 0.791 | 0.850 | 0.680 | 250 | 103.8 | 25.54 |
| YOLOv10_L | 0.825 | 0.762 | 0.840 | 0.657 | 250 | 127.4 | 25.79 |
| Model | mAP50/% | GFLOPs | Params/M |
|---|---|---|---|
| Cascade R-CNN | 0.854 | 77.52 | 68.93 |
| RepPoints | 0.865 | 35.62 | 36.61 |
| DETR | 0.723 | 86 | 41 |
| Deformable DETR | 0.765 | 173 | 40 |
| DN-DETR | 0.772 | 94 | 44 |
| OURS | 0.861 | 150.8 | 36.57 |
| Model | Precision/% | Recall/% | mAP50/% | mAP50-95/% | FPS | GFLOPs | Params/M |
|---|---|---|---|---|---|---|---|
| YOLOv5_L | 0.931 | 0.932 | 0.927 | 0.45 | 207 | 109.1 | 46.5 |
| YOLOv6_L | 0.92 | 0.839 | 0.924 | 0.455 | 153 | 391.2 | 110.9 |
| YOLOv7 | 0.937 | 0.938 | 0.959 | 0.486 | 185 | 105.4 | 37.29 |
| YOLOv8_L | 0.939 | 0.927 | 0.951 | 0.501 | 227 | 165.7 | 43.62 |
| OURS | 0.948 | 0.939 | 0.972 | 0.516 | 248 | 150.8 | 36.57 |
| YOLOv9_C | 0.927 | 0.929 | 0.961 | 0.517 | 250 | 103.8 | 25.54 |
| YOLOv10_L | 0.941 | 0.923 | 0.961 | 0.491 | 250 | 127.4 | 25.79 |
| Model | mAP50/% | FPS | Params/M |
|---|---|---|---|
| YOLOv8_L | 0.951 | 227 | 43.62 |
| YOLOv8_L + GAT | 0.962 | 226 | 43.83 |
| YOLOv8_L + Dilated Encoder Network | 0.958 | 224 | 43.72 |
| YOLOv8_L + GAT + Dilated Encoder Network | 0.973 | 221 | 43.83 |
| YOLOv8_L_Backbone + Improved FPN + GAT + Dilated Encoder Network | 0.961 | 245 | 36.54 |
| YOLOv8_L_Backbone + Improved FPN + GAT + Dilated Encoder Network + Attention mechanism | 0.972 | 248 | 36.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Ai, H.; Xue, D.; He, Z.; Zhu, H.; Liu, D.; Cao, J.; Mei, C. GAT-Enhanced YOLOv8_L with Dilated Encoder for Multi-Scale Space Object Detection. Remote Sens. 2025, 17, 2119. https://doi.org/10.3390/rs17132119
Zhang H, Ai H, Xue D, He Z, Zhu H, Liu D, Cao J, Mei C. GAT-Enhanced YOLOv8_L with Dilated Encoder for Multi-Scale Space Object Detection. Remote Sensing. 2025; 17(13):2119. https://doi.org/10.3390/rs17132119
Chicago/Turabian StyleZhang, Haifeng, Han Ai, Donglin Xue, Zeyu He, Haoran Zhu, Delian Liu, Jianzhong Cao, and Chao Mei. 2025. "GAT-Enhanced YOLOv8_L with Dilated Encoder for Multi-Scale Space Object Detection" Remote Sensing 17, no. 13: 2119. https://doi.org/10.3390/rs17132119
APA StyleZhang, H., Ai, H., Xue, D., He, Z., Zhu, H., Liu, D., Cao, J., & Mei, C. (2025). GAT-Enhanced YOLOv8_L with Dilated Encoder for Multi-Scale Space Object Detection. Remote Sensing, 17(13), 2119. https://doi.org/10.3390/rs17132119