
IEAM: Integrating Edge Enhancement and Attention Mechanism with Multi-Path Complementary Features for Salient Object Detection in Remote Sensing Images

Abstract
1. Introduction
2. Supervised Learning
2.1. Optimization Based on Network Architecture
2.2. Application of Feature Enhancement and Attention Mechanisms
2.3. Innovation and Advantages of IEAM-Net
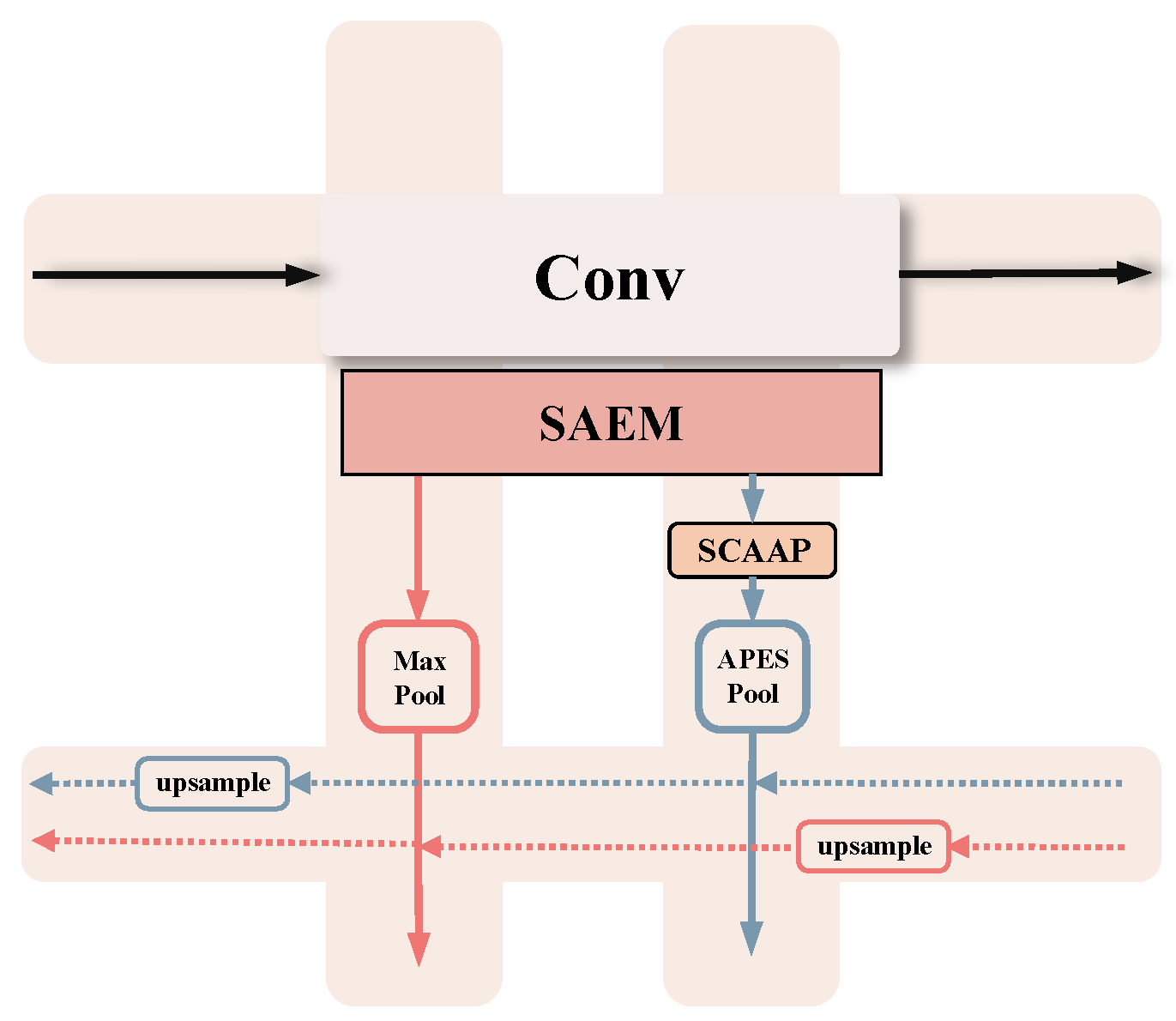
- A convolutional path (left to right) for hierarchical feature extraction;
- A pooling path (top to bottom) combining max and adaptive pooling to adjust receptive fields;
- An up-sampling path (right to left) for reconstructing high-resolution saliency maps.
- SCAAP module and adaptive pooling strategy;IEAM-Net introduces the SCAAP module, which combines adaptive pooling and channel attention to dynamically adjust pooling sizes and focus on salient areas. Unlike traditional pooling methods, this module better handles multi-target and small-object detection, especially in preserving boundaries and saliency.
- Multi-path feature extraction of Tic-Tac-Toe structure;The tic-tac-toe structure is used for grid pooling, which includes a left-to-right convolution path, a top-to-bottom pooling path, and a right-to-left up-sampling path to achieve multi-path feature extraction of Figure 2. Through this multi-level information fusion method, IEAM-Net can capture multi-scale features and improve the detail retention ability of target detection, especially in complex backgrounds and different scale target detection tasks.
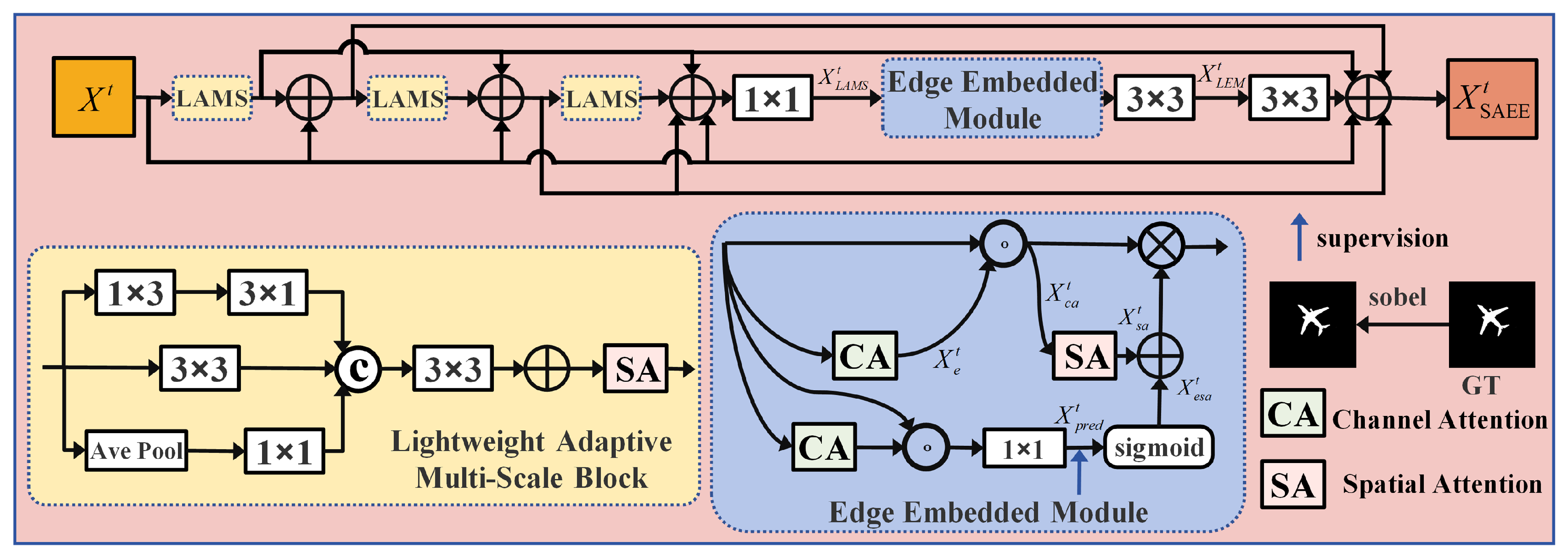
- Enhance edge perception and spatial adaptability.IEAM-Net incorporates two key modules: SAEM (Spatially Adaptive Edge Embedded Module) and the SAG-Model (spatial adaptive guidance module). SAEM enhances edge detection using multi-scale convolution, while the SAG-Model fuses weighted multi-scale features with spatially guided convolution to better focus on key regions. Together, they improve boundary accuracy and spatial feature extraction for salient target detection.
3. Proposed Method
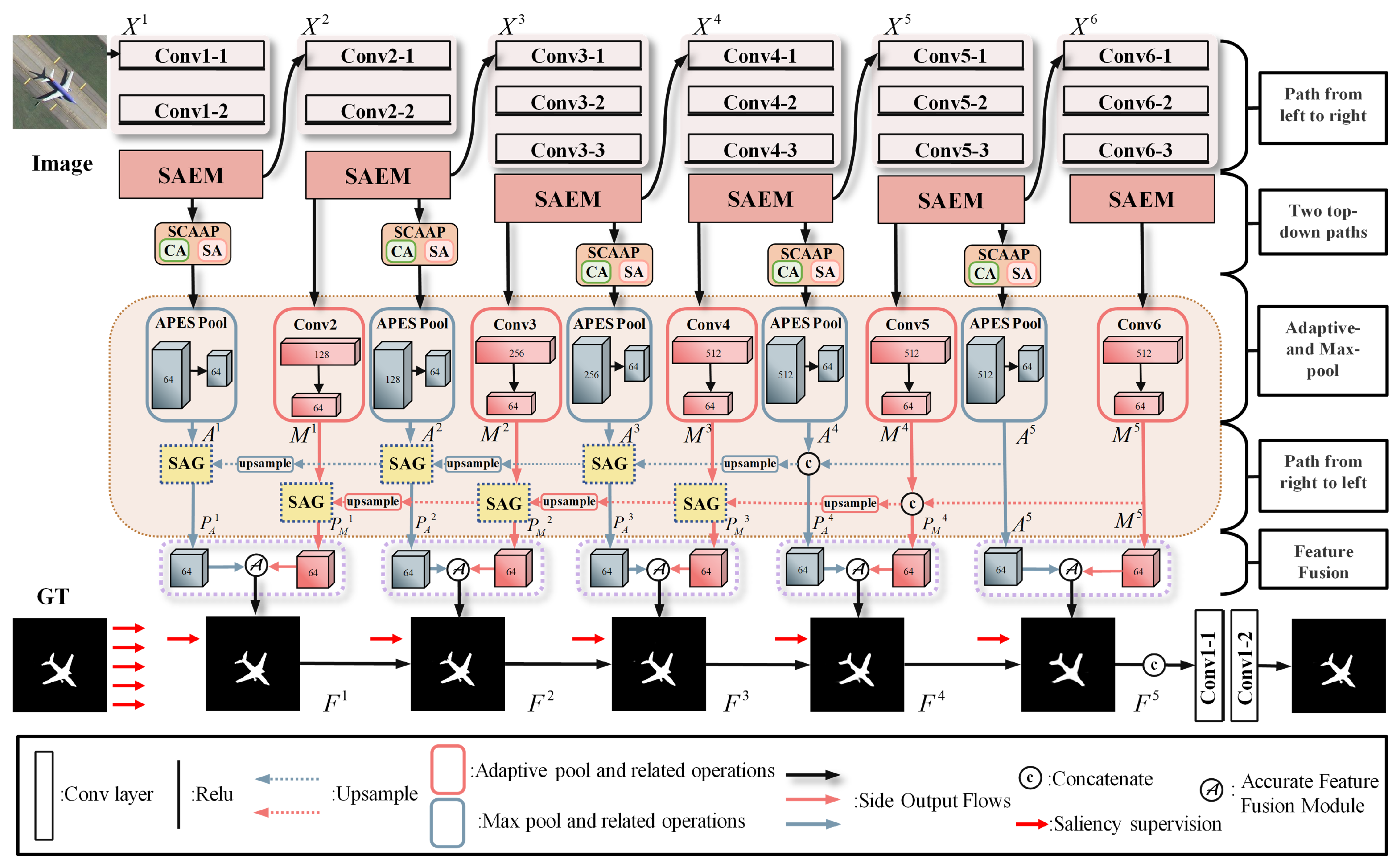
3.1. Network Framework
- Left-to-Right Pathway;The left-to-right pathway, adapted from VGG-16, is used for hierarchical feature extraction through five convolutional blocks (Conv2 to Conv6). Unlike existing approaches, we extract features from the last convolutional layer of each block, instead of pooling, which retains more spatial, channel, and boundary details. The original three fully connected layers of VGG-16 are replaced with three additional convolutional layers (Conv6) to further refine features after Conv5. This results in five multi-scale feature extractions from Conv2-2, Conv3-3, Conv4-3, Conv5-3, and Conv6-3 layers.
- Two Top-Down Paths;
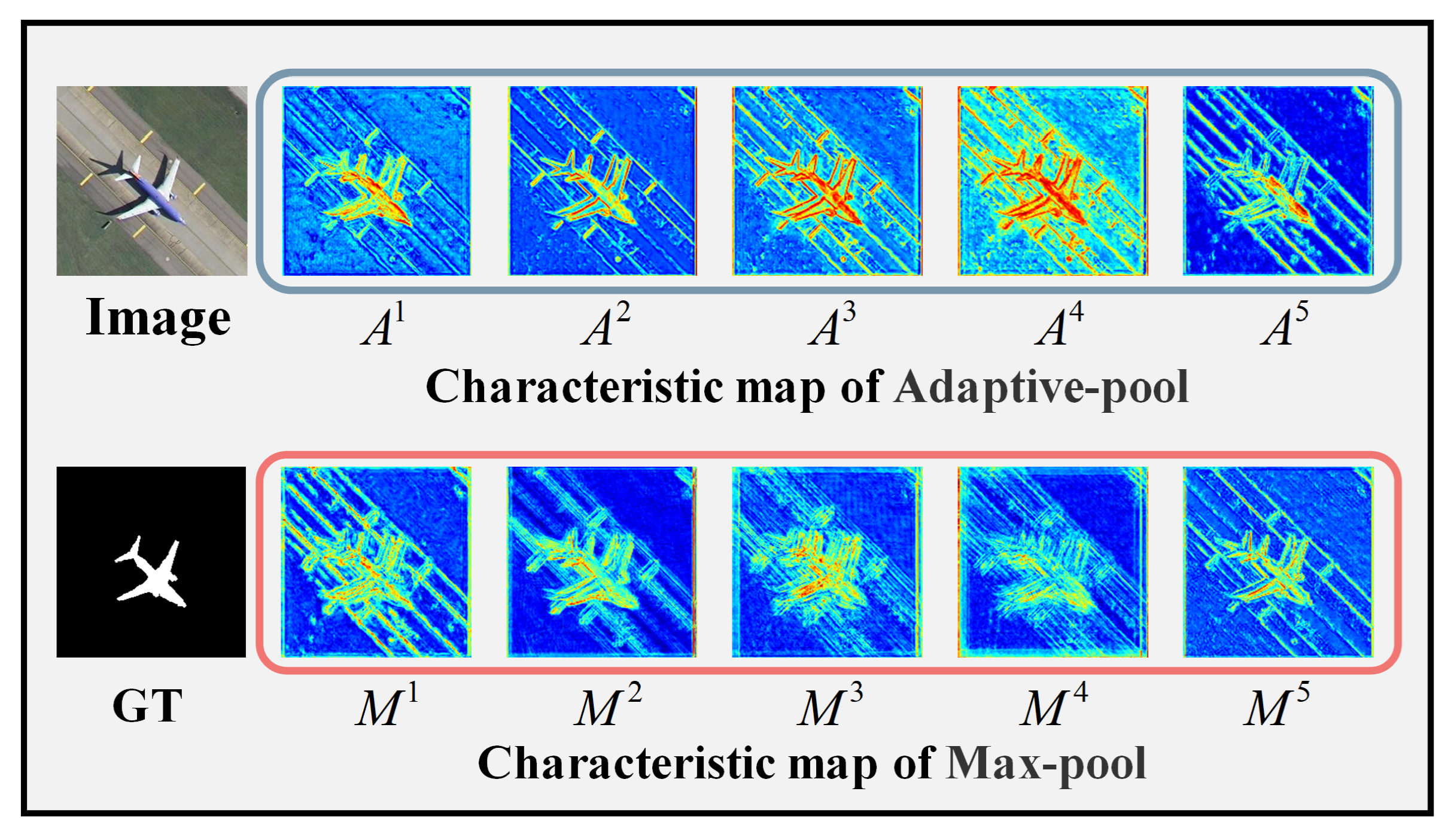
- Max-Pool Path; The max-pool path begins with higher-level features from the Conv2-2, Conv3-3, Conv4-3, Conv5-3, and Conv6-3 layers. It first passes through a max-pooling layer to downsample the features, extracting higher-level semantic information. As the features move down, they are restored to the appropriate size via up-sampling and fused with features adaptively pooled through the SCAAP module. This is followed by a refinement convolutional block for further feature extraction and a channel transformation layer that adjusts feature channels for fusion.
- Adaptive Pool Path; The adaptive pool path starts with features from Conv1-2, Conv2-2, Conv3-3, Conv4-3, and Conv5-3, processed by the SCAAP module. The features undergo spatial and channel attention adjustments before pooling, resulting in feature maps with enhanced representation of the salient target regions. These are then fused with the max-pooling features via up-sampling, concatenation, and convolution, ensuring the combined features accurately represent salient target information.
- Right-to-Left Path.The right-to-left path refines hierarchical features that have undergone adaptive and max pooling via the SCAAP module, followed by up-sampling. The features, denoted as Ai and Mi, pass through two distinct pooling paths—adaptive and max pooling—and are fused via up-sampling and convolution operations to produce the final predictive features.
3.2. Structure and Function of the SAEM Module
3.2.1. LAM (Light Adaptive Multi-Scale Block)
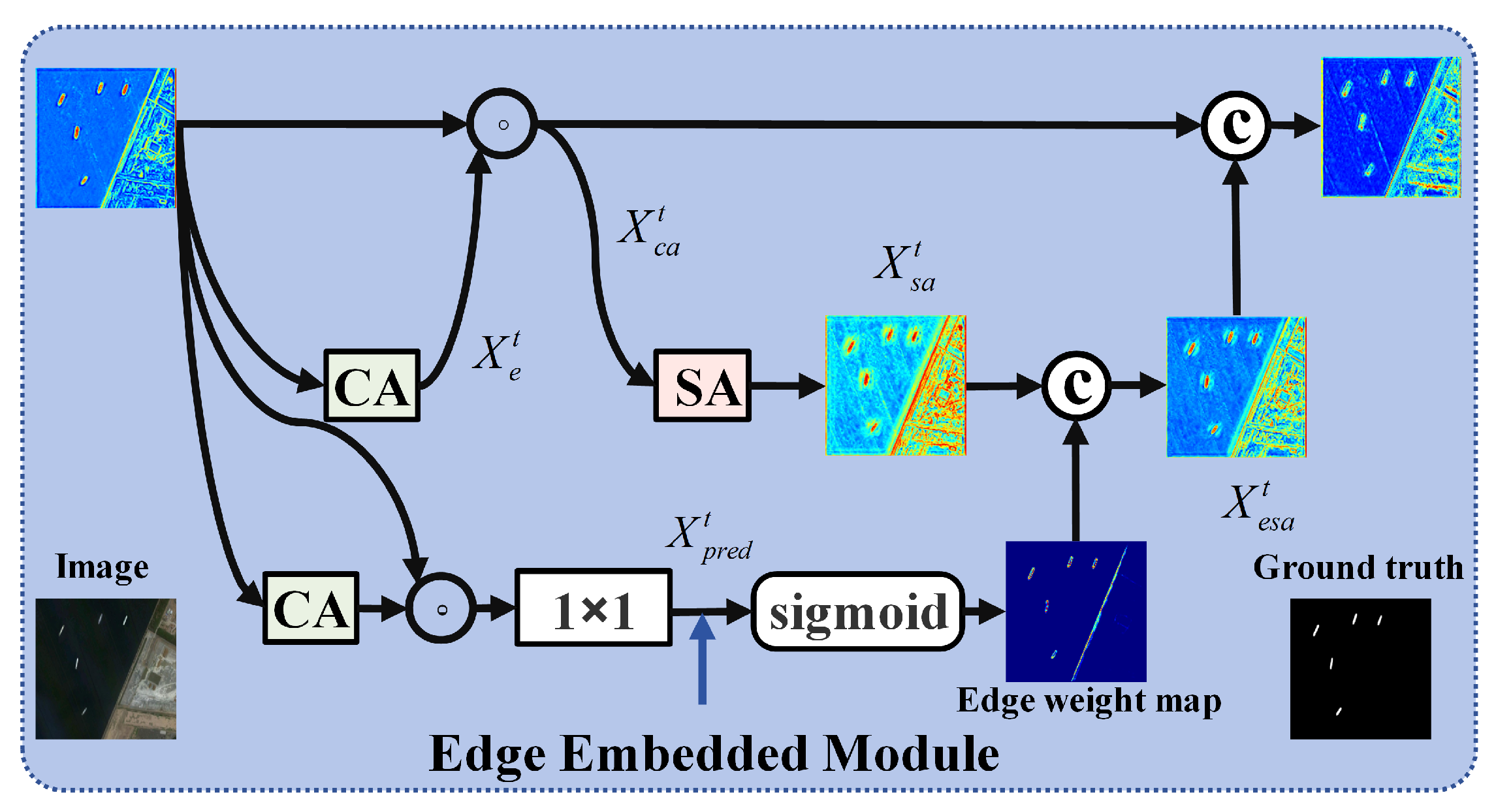
3.2.2. EEM (Edge Embedded Module)
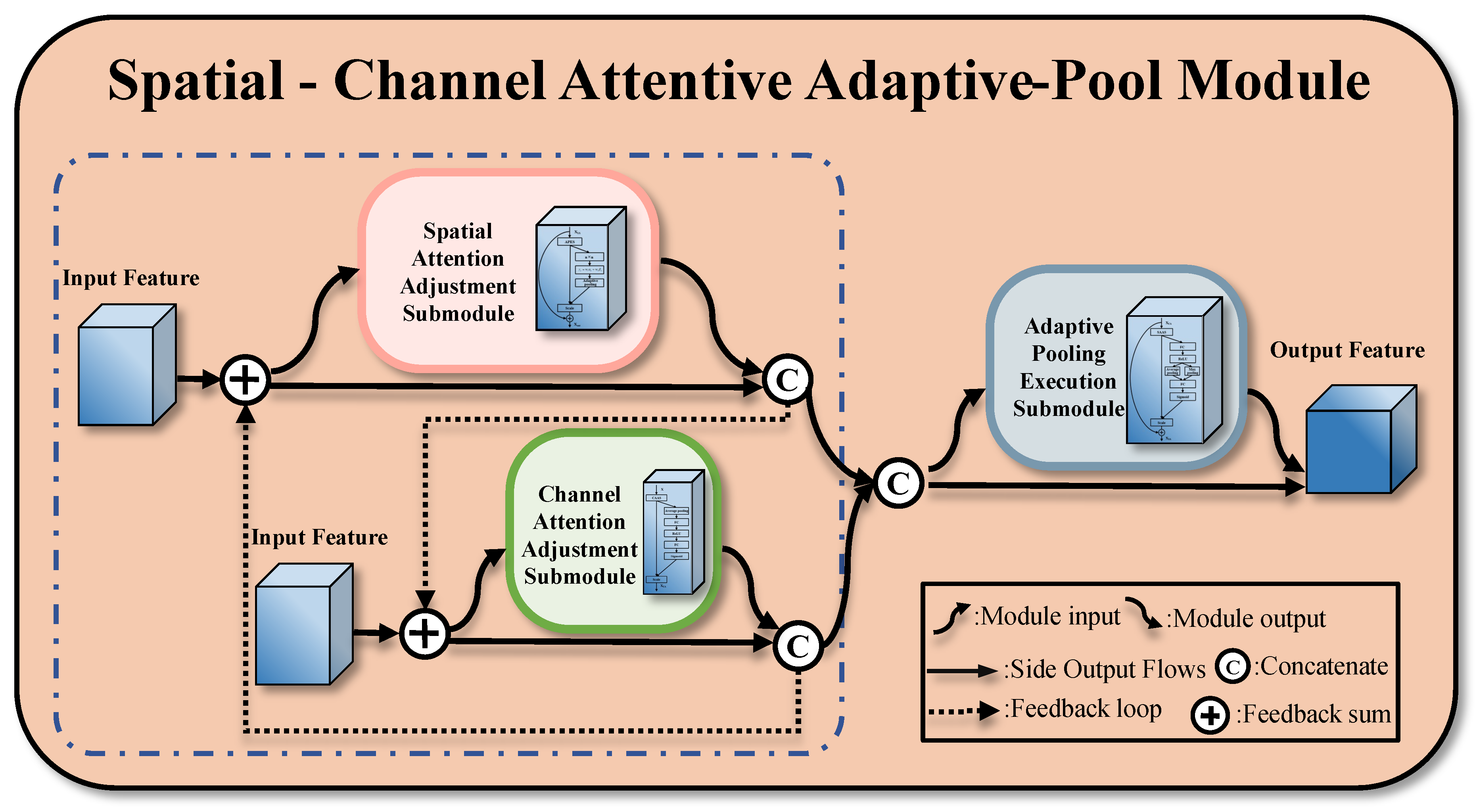
3.3. Spatial-Channel-Attentive Adaptive-Pool
| Algorithm 1: Spatial-Channel Attentive Adaptive Pooling (SCAAP) |
 |
3.3.1. Design Ideas for Two-Way Interaction Mechanisms
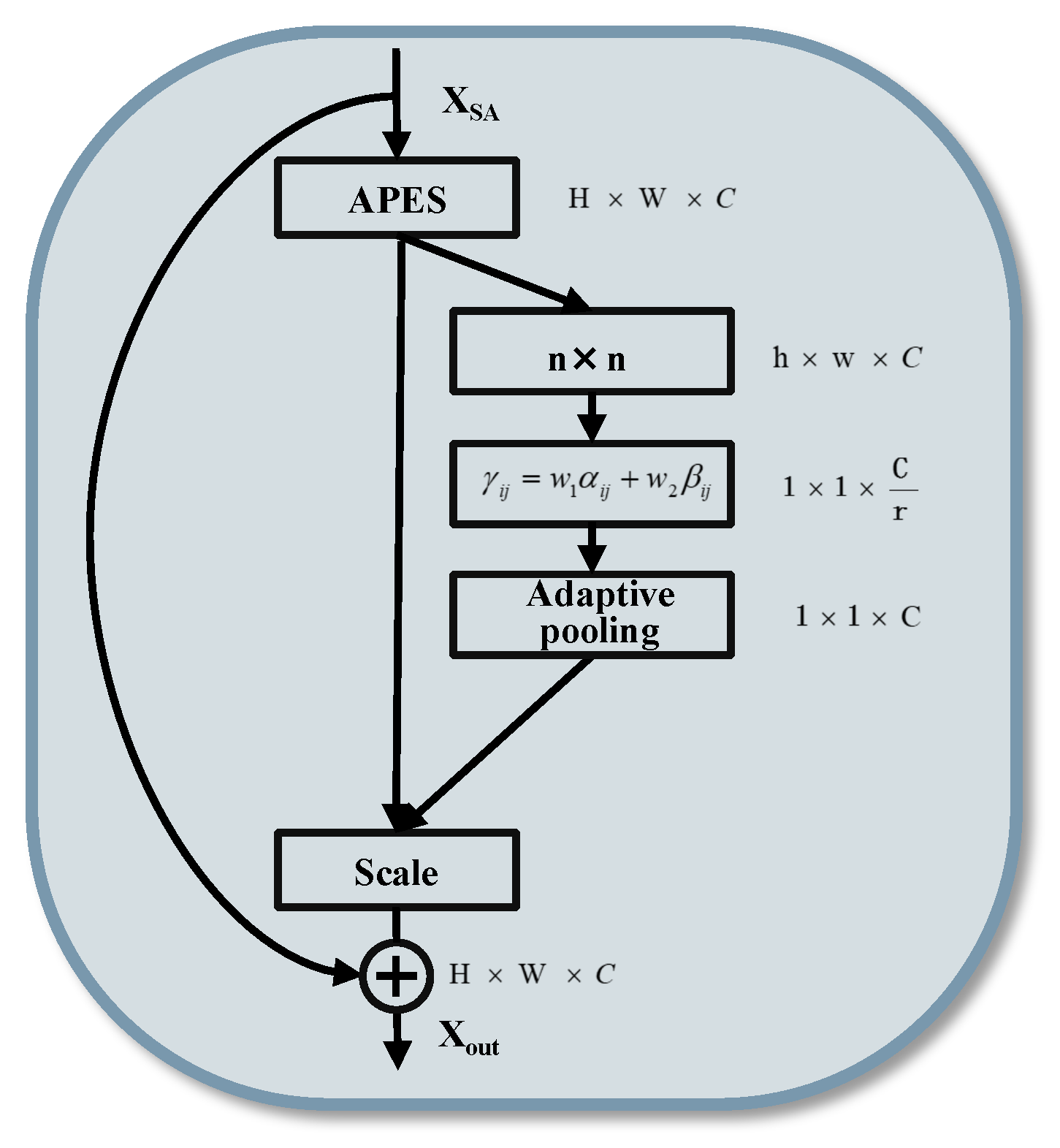
3.3.2. Adaptive Pooling Execution Submodule (APES)
3.4. Structure and Function of the SAG Module
| Algorithm 2: Spatial Adaptive Guidance (SAG) |
 |
3.5. Accurate Feature Fusion Module
3.5.1. Feature Adaptation and Fusion
3.5.2. Feature Compression and Up-Sampling
3.5.3. Deep Supervision Mechanism
4. Experimental Results and Analysis
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison Experiments (With Advanced Methods)
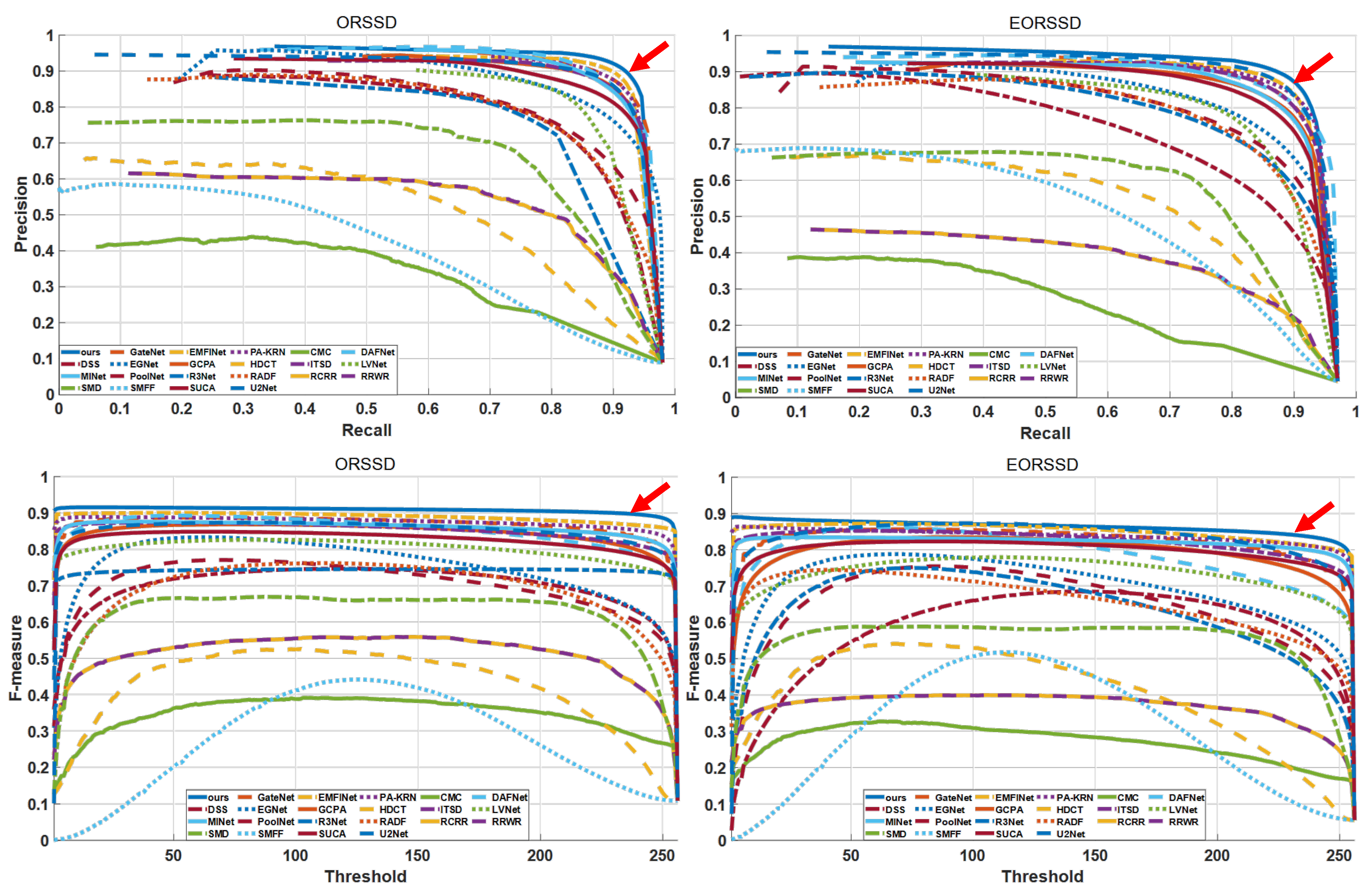
4.2.1. Quantitative Comparison
4.2.2. Comparison of Computational Complexity
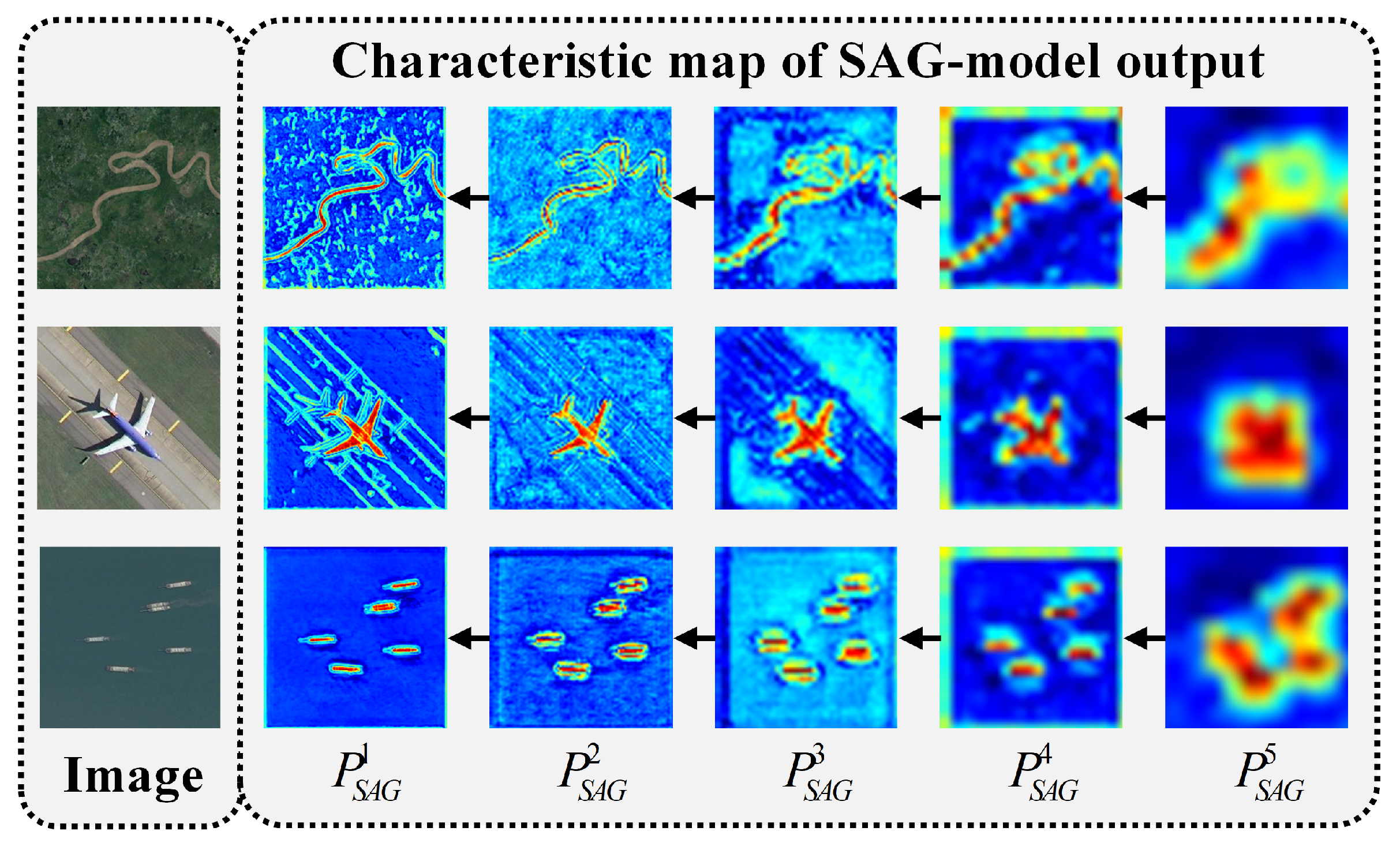
4.2.3. Visual Comparison
4.3. Ablation Experimental Study
4.3.1. SCAAP Component Ablation Experiments
4.3.2. Feature Fusion Module Ablation Experiment
4.3.3. Supervision Mechanism Ablation Experiment
4.3.4. Impact of Backbone Choice
- ResNet-50: a deeper residual CNN known for its strong semantic representation capabilities.
- EfficientNet-B0: a lightweight yet powerful model that utilizes compound scaling to balance depth, width, and resolution.
4.4. Cross-Domain Generalization Evaluation
- iSOD-RS: A large-scale optical remote sensing saliency dataset featuring diverse object categories, complex backgrounds, and varied resolutions.
- WHU-RS19: A scene classification dataset not originally designed for saliency detection but used here for qualitative zero-shot evaluation.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, G.Y.; Liu, Z.; Zhang, X.P.; Lin, W.S. Lightweight Salient Object Detection in Optical Remote-Sensing Images via Semantic Matching and Edge Alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601111. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.M.; Jiang, H.Z.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.G.; Lai, Q.X.; Fu, H.Z.; Shen, J.B.; Ling, H.B.; Yang, R.G. Salient Object Detection in the Deep Learning Era: An In-Depth Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3239–3259. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.P.; Zhang, X.K.; Pun, M.O. RS3Mamba: Visual State Space Model for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6011405. [Google Scholar] [CrossRef]
- Li, X.H.; Xie, L.L.; Wang, C.F.; Miao, J.H.; Shen, H.F.; Zhang, L.P. Boundary-enhanced dual-stream network for semantic segmentation of high-resolution remote sensing images. Giscience Remote Sens. 2024, 61, 2356355. [Google Scholar] [CrossRef]
- Cong, R.M.; Zhang, Y.M.; Fang, L.Y.; Li, J.; Zhao, Y.; Kwong, S. RRNet: Relational Reasoning Network with Parallel Multiscale Attention for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5613311. [Google Scholar] [CrossRef]
- Li, C.Y.; Cong, R.M.; Hou, J.H.; Zhang, S.Y.; Qian, Y.; Kwong, S. Nested Network With Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Zhang, Q.J.; Cong, R.M.; Li, C.Y.; Cheng, M.M.; Fang, Y.M.; Cao, X.C.; Zhao, Y.; Kwong, S. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef]
- Zhang, P.P.; Wang, D.; Lu, H.C.; Wang, H.Y.; Ruan, X. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detectionn. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar] [CrossRef]
- Yang, S.; Jiang, Q.P.; Lin, W.S.; Wang, Y.T. SGDNet: An End-to-End Saliency-Guided Deep Neural Network for No-Reference Image Quality Assessment. In Proceedings of the 27th ACM International Conference on Multimedia (MM), Nice, France, 21–25 October 2019; pp. 1383–1391. [Google Scholar] [CrossRef]
- Deng, Z.J.; Hu, X.W.; Zhu, L.; Xu, X.M.; Qin, J.; Han, G.Q.; Heng, P.A. R3Net: Recurrent Residual Refinement Network for Saliency Detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 684–690. Available online: https://www.ijcai.org/proceedings/2018 (accessed on 13 July 2018).
- Gu, K.; Wang, S.Q.; Yang, H.; Lin, W.S.; Zhai, G.T.; Yang, X.K.; Zhang, W.J. Saliency-Guided Quality Assessment of Screen Content Images. IEEE Trans. Multimed. 2016, 18, 1098–1110. [Google Scholar] [CrossRef]
- Zhang, Q.J.; Zhang, L.B.; Shi, W.Q.; Liu, Y. Airport Extraction via Complementary Saliency Analysis and Saliency-Oriented Active Contour Model. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1085–1089. [Google Scholar] [CrossRef]
- Fang, Y.M.; Chen, Z.Z.; Lin, W.S.; Lin, C.W. Saliency Detection in the Compressed Domain for Adaptive Image Retargeting. IEEE Trans. Image Process. 2012, 21, 3888–3901. [Google Scholar] [CrossRef] [PubMed]
- Ren, J.; Zhu, J. Pyramid Deep Fusion Network for Two-Hand Reconstruction From RGB-D Images. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5843–5855. [Google Scholar] [CrossRef]
- Zhou, X.C.; Liang, F.; Chen, L.H.; Liu, H.J.; Song, Q.Q.; Vivone, G.; Chanussot, J. MeSAM: Multiscale Enhanced Segment Anything Model for Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5623515. [Google Scholar] [CrossRef]
- Zhou, X.F.; Shen, K.Y.; Liu, Z.; Gong, C.; Zhang, J.Y.; Yan, C.G. Edge-Aware Multiscale Feature Integration Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605315. [Google Scholar] [CrossRef]
- Liu, J.J.; Hou, Q.B.; Cheng, M.M.; Feng, J.S.; Jiang, J.M.; Soc, I.C. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3912–3921. [Google Scholar] [CrossRef]
- Zhou, L.; Yang, Z.H.; Zhou, Z.T.; Hu, D.W. Salient Region Detection Using Diffusion Process on a Two-Layer Sparse Graph. IEEE Trans. Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef]
- Sun, L.; Chen, Z.; Wu, Q.M.J.; Zhao, H.; He, W.; Yan, X. AMPNet: Average- and Max-Pool Networks for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4321–4333. [Google Scholar] [CrossRef]
- Yan, Z.Y.; Li, J.X.; Li, X.X.; Zhou, R.X.; Zhang, W.K.; Feng, Y.C.; Diao, W.H.; Fu, K.; Sun, X. RingMo-SAM: A Foundation Model for Segment Anything in Multimodal Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5625716. [Google Scholar] [CrossRef]
- Zhang, X.J.; Li, S.; Tan, Z.Y.; Li, X.H. Enhanced wavelet based spatiotemporal fusion networks using cross-paired remote sensing images. ISPRS J. Photogramm. Remote Sens. 2024, 211, 281–297. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614513. [Google Scholar] [CrossRef]
- Du, Z.S.; Li, X.H.; Miao, J.H.; Huang, Y.Y.; Shen, H.F.; Zhang, L.P. Concatenated Deep-Learning Framework for Multitask Change Detection of Optical and SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 719–731. [Google Scholar] [CrossRef]
- Ding, L.; Zhu, K.; Peng, D.F.; Tang, H.; Yang, K.W.; Bruzzone, L. Adapting Segment Anything Model for Change Detection in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611711. [Google Scholar] [CrossRef]
- Li, G.Y.; Liu, Z.; Shi, R.; Hu, Z.; Wei, W.J.; Wu, Y.; Huang, M.K.; Ling, H.B. Personal Fixations-Based Object Segmentation With Object Localization and Boundary Preservation. IEEE Trans. Image Process. 2021, 30, 1461–1475. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.G.; Shen, J.B.; Xie, J.W.; Cheng, M.M.; Ling, H.B.; Borji, A. Revisiting Video Saliency Prediction in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 220–237. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and balance: A simple gated network for salient object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part II 16; Springer: Cham, Switzerland, 2020; pp. 35–51. [Google Scholar] [CrossRef]
- Zhou, H.J.; Xie, X.H.; Lai, J.H.; Chen, Z.X.; Yang, L.X. Interactive Two-Stream Decoder for Accurate and Fast Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9138–9147. [Google Scholar] [CrossRef]
- Cong, R.M.; Lei, J.J.; Fu, H.Z.; Cheng, M.M.; Lin, W.S.; Huang, Q.M. Review of Visual Saliency Detection with Comprehensive Information. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2941–2959. [Google Scholar] [CrossRef]
- Li, G.Y.; Liu, Z.; Shi, R.; Wei, W.J. Constrained fixation point based segmentation via deep neural network. Neurocomputing 2019, 368, 180–187. [Google Scholar] [CrossRef]
- Chen, K.Y.; Chen, B.W.; Liu, C.Y.; Li, W.Y.; Zou, Z.X.; Shi, Z.W. RSMamba: Remote Sensing Image Classification With State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Zhang, L.B.; Liu, Y.N.; Zhang, J. Saliency detection based on self-adaptive multiple feature fusion for remote sensing images. Int. J. Remote Sens. 2019, 40, 8270–8297. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Xu, Q.Q.; Cong, R.M.; Huang, Q.M. Global Context-Aware Progressive Aggregation Network for Salient Object Detection. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10599–10606. [Google Scholar] [CrossRef]
- Kim, J.; Han, D.; Tai, Y.W.; Kim, J. Salient Region Detection via High-Dimensional Color Transform and Local Spatial Support. IEEE Trans. Image Process. 2016, 25, 9–23. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.C.; Li, C.Y.; Kim, J.; Cai, W.D.; Feng, D.D. Reversion Correction and Regularized Random Walk Ranking for Saliency Detection. IEEE Trans. Image Process. 2018, 27, 1311–1322. [Google Scholar] [CrossRef]
- Peng, H.W.; Li, B.; Ling, H.B.; Hu, W.M.; Xiong, W.H.; Maybank, S.J. Salient Object Detection via Structured Matrix Decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 818–832. [Google Scholar] [CrossRef]
- Li, C.Y.; Yuan, Y.C.; Cai, W.D.; Xia, Y.; Feng, D.D. Robust Saliency Detection via Regularized Random Walks Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2710–2717. [Google Scholar]
- Hou, Q.B.; Cheng, M.M.; Hu, X.W.; Borji, A.; Tu, Z.W.; Torr, P.H.S. Deeply Supervised Salient Object Detection with Short Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.W.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently Aggregating Deep Features for Salient Object Detection. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence/30th Innovative Applications of Artificial Intelligence Conference/8th AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6943–6950. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.F.; Cheng, M.M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8778–8787. [Google Scholar] [CrossRef]
- Xu, B.W.; Liang, H.R.; Liang, R.H.; Chen, P. Locate Globally, Segment Locally: A Progressive Architecture with Knowledge Review Network for Salient Object Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3004–3012. [Google Scholar] [CrossRef]
- Li, J.; Pan, Z.; Liu, Q.; Wang, Z. Stacked U-shape network with channel-wise attention for salient object detection. IEEE Trans. Multimed. 2020, 23, 1397–1409. [Google Scholar] [CrossRef]
- Pang, Y.W.; Zhao, X.Q.; Zhang, L.H.; Lu, H.C. Multi-scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9410–9419. [Google Scholar] [CrossRef]
- Qin, X.B.; Zhang, Z.C.; Huang, C.Y.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Liu, Z.M.; Zhao, D.P.; Shi, Z.W.; Jiang, Z.G. Unsupervised Saliency Model with Color Markov Chain for Oil Tank Detection. Remote Sens. 2019, 11, 1089. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | What It Measures | Practical Interpretation |
|---|---|---|
| Trade-off between precision and recall | Higher score means fewer missed objects and reduced false alarms. Even a 0.005 gain indicates noticeable visual improvement in object completeness and fewer background activations. | |
| S-measure | Structural similarity of prediction vs. GT | Captures how well object shapes and contours are preserved, important for elongated/irregular targets. |
| E-measure | Enhanced alignment of prediction and GT | Measures consistency in spatial and holistic saliency. A higher E-measure implies better edge connectivity and less spatial fragmentation. |
| MAE | Pixel-wise average error | Indicates how “clean” the prediction is—lower values reflect smoother backgrounds and fewer fuzzy edges. |
| IoU | Spatial overlap with ground truth | Reflects how well the predicted and true salient regions match, critical for spatial accuracy. |
| Methods | EORSSD | ORSSD | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RRWR | 0.5994 | 0.3993 | 0.3686 | 0.3344 | 0.6894 | 0.5943 | 0.5639 | 0.1677 | 0.6835 | 0.5590 | 0.5125 | 0.4874 | 0.7649 | 0.7017 | 0.6949 | 0.1324 |
| HDCT | 0.5978 | 0.5407 | 0.4018 | 0.2658 | 0.7861 | 0.6376 | 0.5192 | 0.1088 | 0.6197 | 0.5257 | 0.4235 | 0.3722 | 0.7719 | 0.6495 | 0.6291 | 0.1309 |
| SMD | 0.7106 | 0.5884 | 0.5475 | 0.4081 | 0.7692 | 0.7286 | 0.6416 | 0.0771 | 0.7640 | 0.6692 | 0.6214 | 0.5568 | 0.8230 | 0.7745 | 0.7682 | 0.0715 |
| RCRR | 0.6007 | 0.3995 | 0.3685 | 0.3347 | 0.6882 | 0.5946 | 0.5636 | 0.1644 | 0.6849 | 0.5591 | 0.5126 | 0.4876 | 0.7651 | 0.7021 | 0.6950 | 0.1277 |
| DSS | 0.7868 | 0.6849 | 0.5801 | 0.4597 | 0.9186 | 0.7631 | 0.6933 | 0.0186 | 0.8262 | 0.7467 | 0.6962 | 0.6206 | 0.8860 | 0.8362 | 0.8085 | 0.0363 |
| RADF | 0.8179 | 0.7446 | 0.6582 | 0.4933 | 0.9130 | 0.8567 | 0.7162 | 0.0168 | 0.8259 | 0.7619 | 0.6856 | 0.5730 | 0.9130 | 0.8298 | 0.7678 | 0.0382 |
| R3Net | 0.8184 | 0.7498 | 0.6312 | 0.4165 | 0.9483 | 0.8294 | 0.6462 | 0.0171 | 0.8141 | 0.7456 | 0.7386 | 0.7379 | 0.8913 | 0.8681 | 0.8887 | 0.0399 |
| EGNet | 0.8601 | 0.7880 | 0.6967 | 0.5379 | 0.9570 | 0.8775 | 0.7566 | 0.0120 | 0.8721 | 0.8332 | 0.7500 | 0.6452 | 0.9731 | 0.9013 | 0.8226 | 0.0216 |
| PoolNet | 0.8207 | 0.7545 | 0.6406 | 0.4613 | 0.9292 | 0.8193 | 0.6836 | 0.0210 | 0.8403 | 0.7706 | 0.6999 | 0.6166 | 0.9343 | 0.8650 | 0.8124 | 0.0358 |
| GCPA | 0.8869 | 0.8347 | 0.7905 | 0.6721 | 0.9524 | 0.9167 | 0.8647 | 0.0102 | 0.9026 | 0.8687 | 0.8433 | 0.7861 | 0.9509 | 0.9341 | 0.9205 | 0.0168 |
| ITSD | 0.9050 | 0.8523 | 0.8271 | 0.7421 | 0.9556 | 0.9407 | 0.9103 | 0.0106 | 0.9050 | 0.8735 | 0.8502 | 0.8068 | 0.9601 | 0.9482 | 0.9335 | 0.0165 |
| MINet | 0.9040 | 0.8344 | 0.8174 | 0.7705 | 0.9442 | 0.9346 | 0.9243 | 0.0093 | 0.9040 | 0.8761 | 0.8574 | 0.8251 | 0.9545 | 0.9454 | 0.9423 | 0.0144 |
| GateNet | 0.9114 | 0.8566 | 0.8224 | 0.7109 | 0.9610 | 0.9385 | 0.8909 | 0.0095 | 0.9186 | 0.8871 | 0.8679 | 0.8229 | 0.9664 | 0.9538 | 0.9427 | 0.0137 |
| U2Net | 0.9199 | 0.8732 | 0.8329 | 0.7221 | 0.9649 | 0.9373 | 0.8989 | 0.0076 | 0.9162 | 0.8738 | 0.8492 | 0.8038 | 0.9532 | 0.9387 | 0.9326 | 0.0166 |
| PAKRN | 0.9192 | 0.8639 | 0.8358 | 0.7993 | 0.9616 | 0.9536 | 0.9416 | 0.0104 | 0.9239 | 0.8890 | 0.8727 | 0.8548 | 0.9680 | 0.9620 | 0.9579 | 0.0139 |
| SUCA | 0.8988 | 0.8229 | 0.7949 | 0.7260 | 0.9520 | 0.9277 | 0.9082 | 0.0097 | 0.8989 | 0.8484 | 0.8237 | 0.7748 | 0.9584 | 0.9400 | 0.9194 | 0.0145 |
| CMC | 0.5798 | 0.3268 | 0.2692 | 0.2007 | 0.6803 | 0.5894 | 0.4890 | 0.1057 | 0.6033 | 0.3913 | 0.3454 | 0.3108 | 0.7064 | 0.6417 | 0.5996 | 0.1267 |
| SMFF | 0.5401 | 0.5176 | 0.2992 | 0.2083 | 0.7744 | 0.5197 | 0.5014 | 0.1434 | 0.5312 | 0.4417 | 0.2684 | 0.2496 | 0.7402 | 0.4920 | 0.5676 | 0.1854 |
| LVNet | 0.8630 | 0.7794 | 0.7328 | 0.6284 | 0.9254 | 0.8801 | 0.8445 | 0.0146 | 0.8815 | 0.8263 | 0.7995 | 0.7506 | 0.9456 | 0.9259 | 0.9195 | 0.0207 |
| EMFINet | 0.9290 | 0.8720 | 0.8508 | 0.7984 | 0.9711 | 0.9604 | 0.9501 | 0.0084 | 0.9366 | 0.9002 | 0.9504 | 0.8617 | 0.9737 | 0.9671 | 0.9654 | 0.0109 |
| DAFNet | 0.9166 | 0.8614 | 0.7845 | 0.6427 | 0.9861 | 0.9291 | 0.8446 | 0.0060 | 0.9191 | 0.8928 | 0.8511 | 0.7876 | 0.9771 | 0.9539 | 0.9360 | 0.0113 |
| Ours | 0.9308 | 0.8905 | 0.8473 | 0.8027 | 0.9737 | 0.9625 | 0.9563 | 0.0071 | 0.9421 | 0.9135 | 0.8856 | 0.8947 | 0.9783 | 0.9742 | 0.9663 | 0.0098 |
| Method | Type | FPS ↑ | Params (M) ↓ | FLOPs (G) ↓ | |
|---|---|---|---|---|---|
| RRWR | Traditional | 0.3993 | 5 | – | – |
| UCF | Traditional | 0.4521 | 7 | – | – |
| RBD | Traditional | 0.5010 | 9 | – | – |
| DSS | NSI-CNN | 0.6849 | 22 | 62.2 | 130.8 |
| U2Net | NSI-CNN | 0.7180 | 30 | 44.7 | 98.5 |
| PoolNet | NSI-CNN | 0.7533 | 22 | 68.1 | 150.0 |
| EGNet | NSI-CNN | 0.7880 | 20 | 94.5 | 180.6 |
| CPD | NSI-CNN | 0.7925 | 28 | 47.2 | 104.3 |
| SCRN | NSI-CNN | 0.8010 | 27 | 38.7 | 85.2 |
| MINet | NSI-CNN | 0.8127 | 25 | 60.3 | 145.1 |
| ITSD | NSI-CNN | 0.8194 | 24 | 54.2 | 131.9 |
| F3Net | NSI-CNN | 0.8210 | 25 | 52.0 | 122.4 |
| GCPA | NSI-CNN | 0.8347 | 24 | 86.7 | 291.9 |
| PA-KRN | NSI-CNN | 0.8639 | 18 | 138.3 | 617.7 |
| DAF-Net | RSI-CNN | 0.8614 | 25 | 85.4 | 376.2 |
| DMRA | RSI-CNN | 0.8587 | 20 | 78.1 | 330.5 |
| EMFI-Net | RSI-CNN | 0.8720 | 23 | 107.3 | 487.3 |
| BLNet | RSI-CNN | 0.8704 | 26 | 90.2 | 450.6 |
| RRA-Net | RSI-CNN | 0.8673 | 19 | 95.0 | 420.7 |
| CGANet | RSI-CNN | 0.8735 | 21 | 93.4 | 412.0 |
| BMNet | RSI-CNN | 0.8690 | 24 | 81.3 | 389.6 |
| IEAM-Net (Ours) | RSI-CNN | 0.8905 | 48 | 67.7 | 103.2 |
| No. | Baseline | SAEM | SAG | AP | MP | EORSSD | ORSSD | ||
|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | 0.8632 | 0.9684 | 0.8878 | 0.9608 | ||||
| 2 | ✓ | ✓ | ✓ | 0.8817 | 0.9713 | 0.9043 | 0.9721 | ||
| 3 | ✓ | ✓ | ✓ | 0.8836 | 0.9727 | 0.9066 | 0.9742 | ||
| 4 | ✓ | ✓ | ✓ | 0.8860 | 0.9689 | 0.9086 | 0.9762 | ||
| 5 | ✓ | ✓ | 0.8842 | 0.9713 | 0.9047 | 0.9718 | |||
| 6 | ✓ | ✓ | ✓ | 0.8740 | 0.9623 | 0.9017 | 0.9689 | ||
| 7 | ✓ | ✓ | ✓ | ✓ | 0.8835 | 0.9713 | 0.9126 | 0.9695 | |
| 8 | ✓ | ✓ | ✓ | 0.8872 | 0.9721 | 0.9112 | 0.9723 | ||
| 9 | ✓ | ✓ | ✓ | ✓ | 0.8891 | 0.9702 | 0.9127 | 0.9768 | |
| 10 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.8905 | 0.9737 | 0.9135 | 0.9783 |
| Models | EORSSD | ORSSD | ||
|---|---|---|---|---|
| FFM | 0.8869 | 0.9717 | 0.9118 | 0.9754 |
| EAFFM | 0.8905 | 0.9737 | 0.9135 | 0.9783 |
| Models | EORSSD | ORSSD | ||
|---|---|---|---|---|
| SINGLE SUP | 0.8875 | 0.9720 | 0.9121 | 0.9769 |
| DEEP SUP | 0.8905 | 0.9737 | 0.9135 | 0.9783 |
| Backbone | ↑ | MAE ↓ | FPS ↑ | Params (M) ↓ |
|---|---|---|---|---|
| VGG-16 (default) | 0.8905 | 0.031 | 48 | 67.7 |
| ResNet-50 | 0.9072 | 0.028 | 42 | 85.2 |
| EfficientNet-B0 | 0.8921 | 0.030 | 47 | 59.3 |
| Dataset | ↑ | MAE ↓ | IoU ↑ |
|---|---|---|---|
| ORSSD | 0.8905 | 0.031 | 0.829 |
| EORSSD | 0.8932 | 0.028 | 0.842 |
| iSOD-RS | 0.8511 | 0.041 | 0.774 |
| WHU-RS19 | 0.8073 | 0.057 | 0.701 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Zhang, Z. IEAM: Integrating Edge Enhancement and Attention Mechanism with Multi-Path Complementary Features for Salient Object Detection in Remote Sensing Images. Remote Sens. 2025, 17, 2053. https://doi.org/10.3390/rs17122053
Zhang F, Zhang Z. IEAM: Integrating Edge Enhancement and Attention Mechanism with Multi-Path Complementary Features for Salient Object Detection in Remote Sensing Images. Remote Sensing. 2025; 17(12):2053. https://doi.org/10.3390/rs17122053
Chicago/Turabian StyleZhang, Fubin, and Zichi Zhang. 2025. "IEAM: Integrating Edge Enhancement and Attention Mechanism with Multi-Path Complementary Features for Salient Object Detection in Remote Sensing Images" Remote Sensing 17, no. 12: 2053. https://doi.org/10.3390/rs17122053
APA StyleZhang, F., & Zhang, Z. (2025). IEAM: Integrating Edge Enhancement and Attention Mechanism with Multi-Path Complementary Features for Salient Object Detection in Remote Sensing Images. Remote Sensing, 17(12), 2053. https://doi.org/10.3390/rs17122053