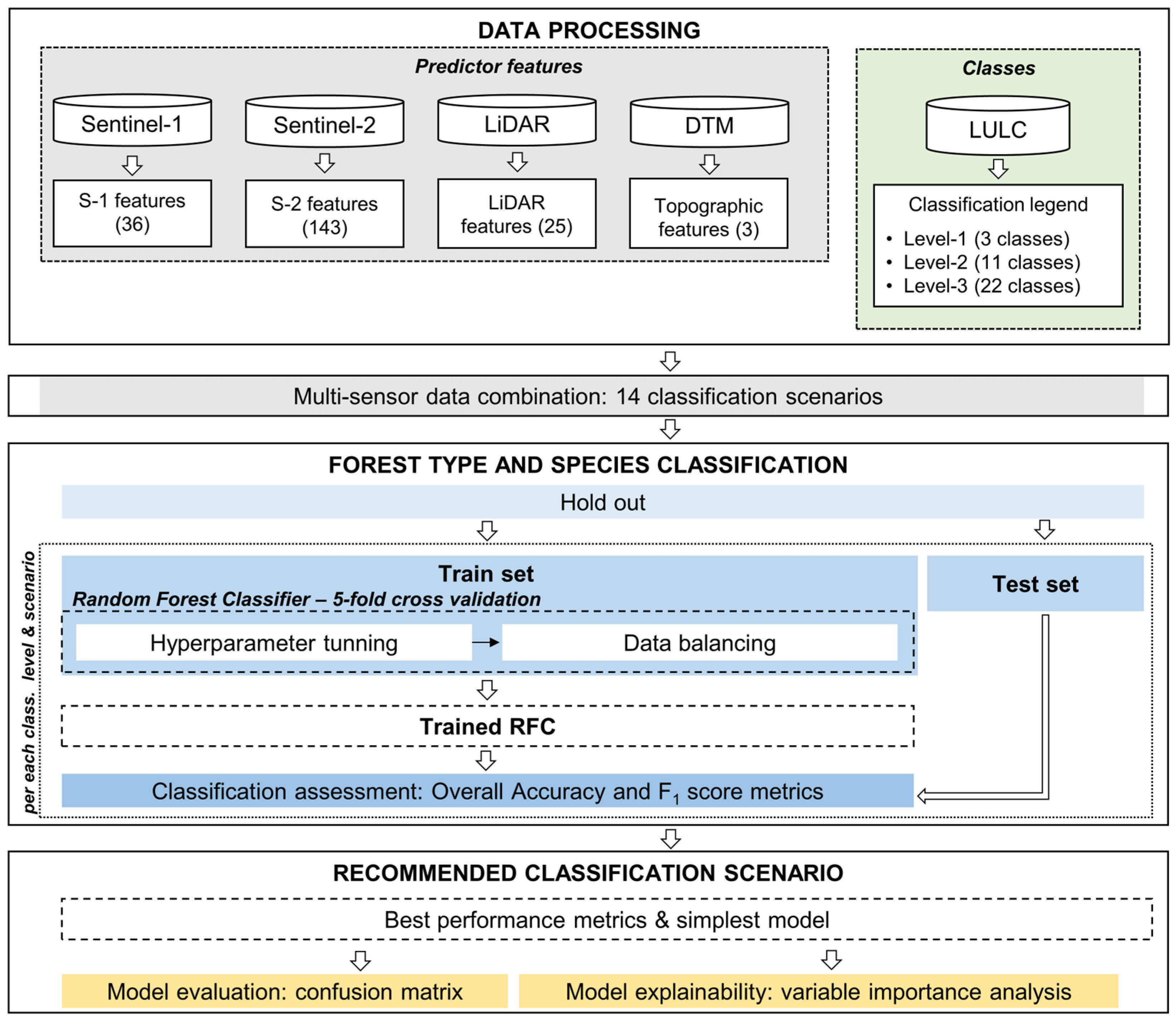
4.1. Descriptive Analysis
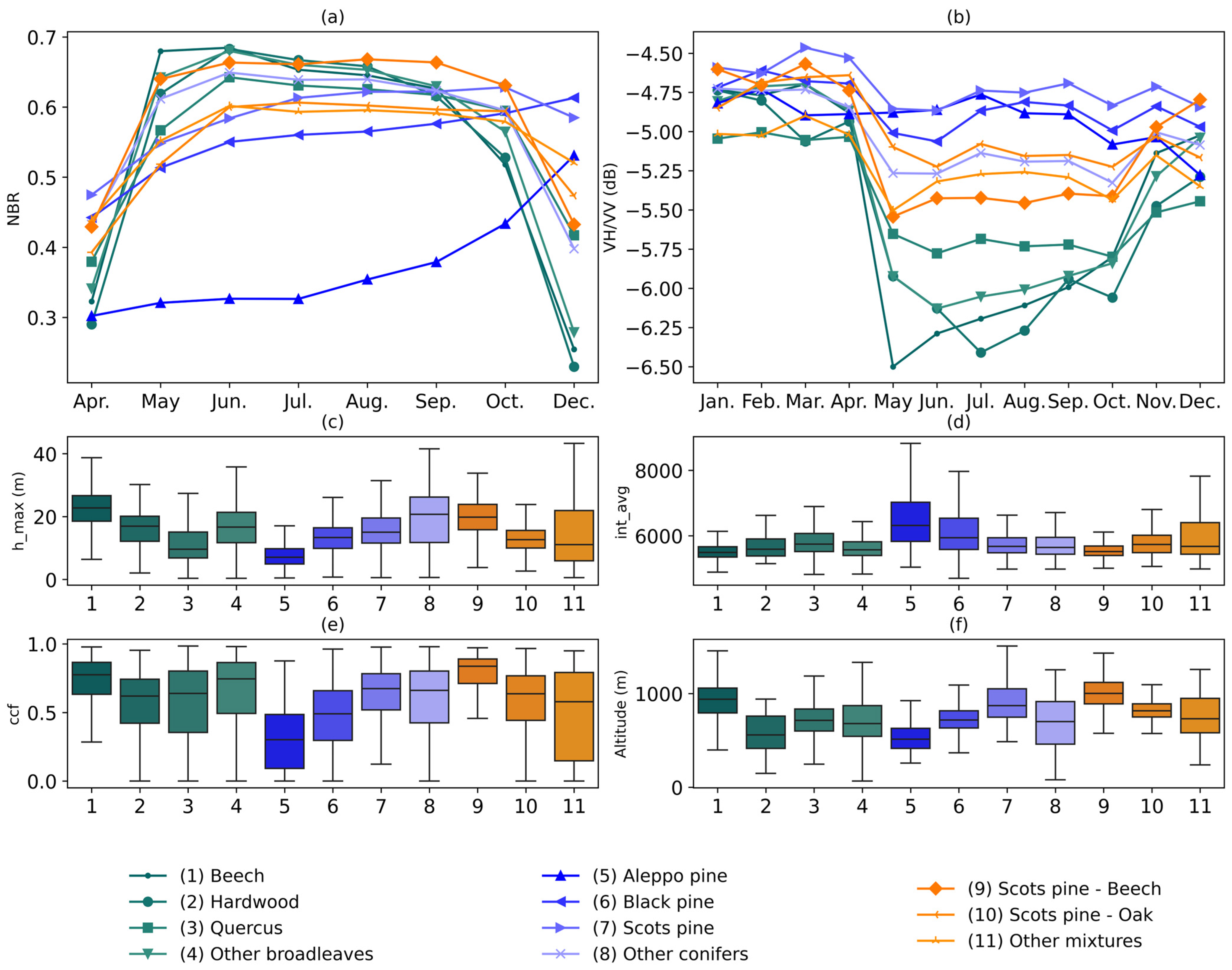
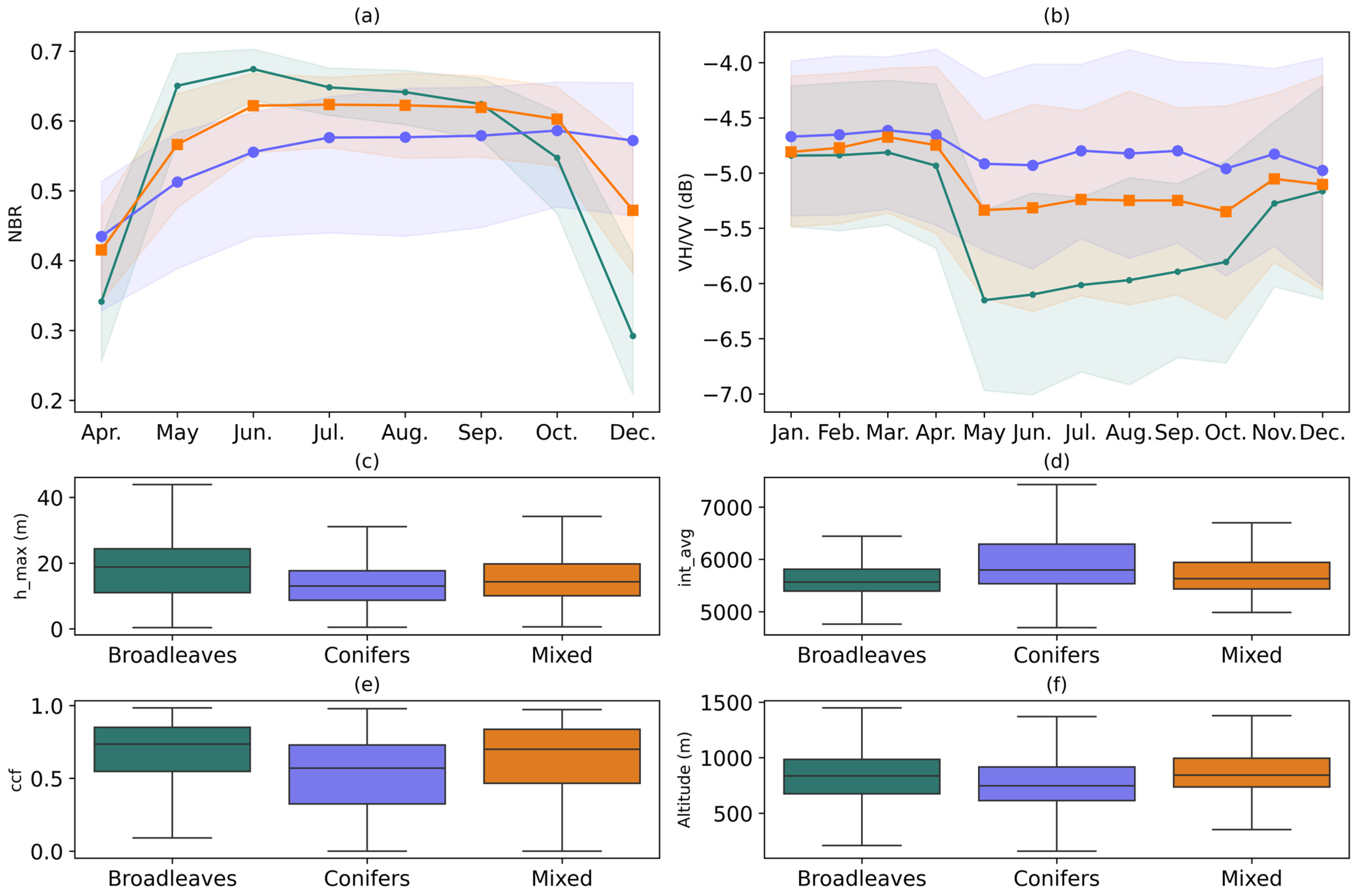
The median time series of broadleaves, conifers, and mixed forests for the S-2 NBR and the S-1 VH/VV ratio, as well as the boxplots of some selected LiDAR metrics (maximum height, average intensity, and canopy cover fraction), and the altitude are plotted in
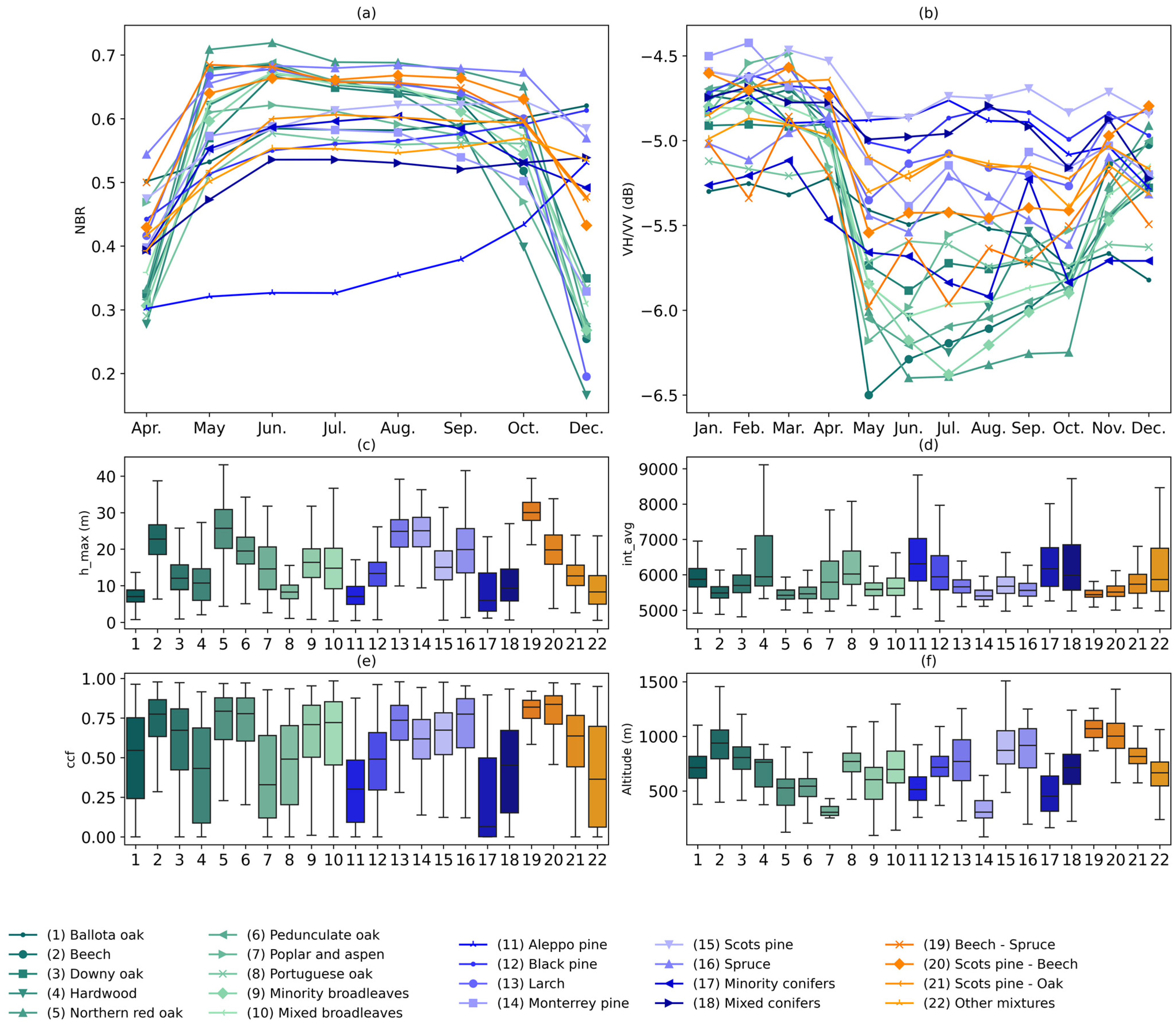
Figure 3. Results for levels 2 and 3 are given in
Appendix A (
Figure A1 and
Figure A2).
The values of NBR (
Figure 3a) for broadleaves exhibited an increase in spring, followed by a decline from summer onwards, reaching the lowest values in December. In contrast, conifers showed a rather flat trend, with a slight increase in NBR during spring, but an almost flat trend from summer to autumn. Mixed forests had an intermediate NBR trend, positioned between conifers and broadleaves. The month of December exhibited the greatest difference between the three classes. The variability of the NBR was found to be the highest for conifers, although differences were not significant.
The time series of S-1 features spanned from January to December (e.g., VH/VV in
Figure 3b), thus enabling a more detailed multitemporal analysis than S-2. During the winter months of January to March, broadleaves, conifers, and mixed forests exhibited very similar VH/VV values, maintaining an almost constant value until the onset of spring. Beginning in April, VH/VV showed a sharp decline in broadleaves, reaching its minimum in May, and subsequently taking an upward trend from June to October (summer). Finally, broadleaves showed an increase in VH/VV in November, coinciding with the leaf fall. Conversely, conifers exhibited a relatively constant VH/VV trend, with minor fluctuations observed in May and October. Mixed forests showed again an intermediate behavior indicative of the mixture of coniferous and broadleaves. The largest differences between forest types in VH/VV occurred during the late spring and summer months.
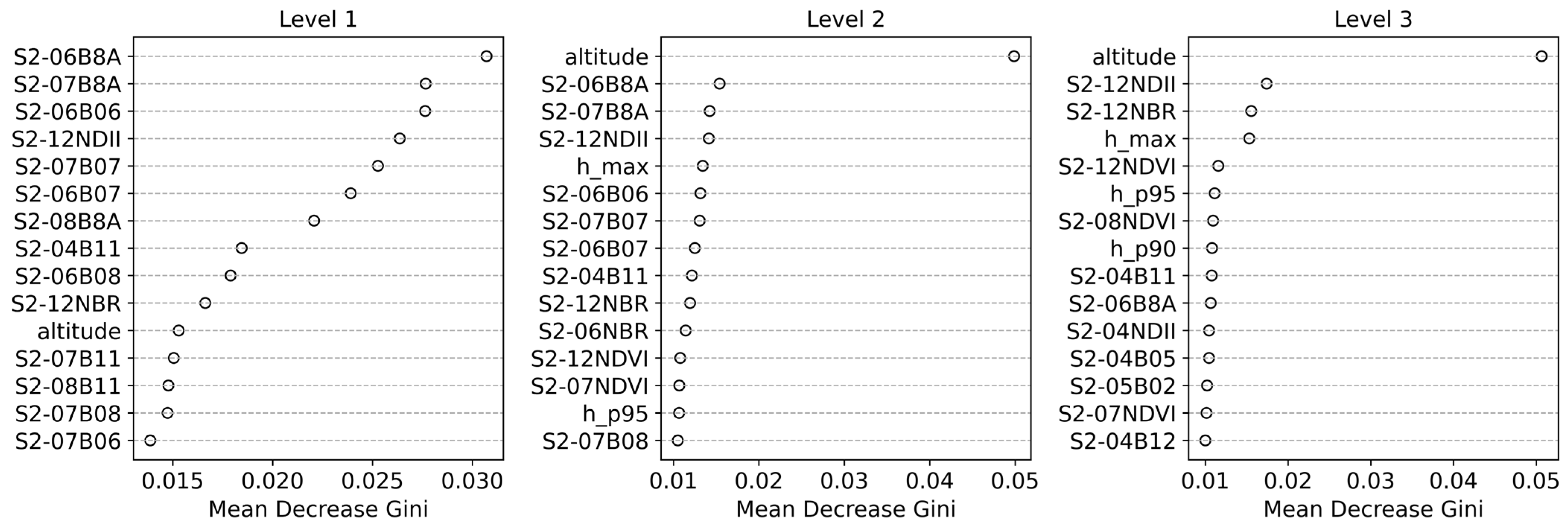
The distribution of the LiDAR metrics (
Figure 3c–e) and the altitude (
Figure 3f) demonstrated a substantial overlap between the three classes at level 1. The maximum height (h_max,
Figure 3c) and canopy cover fraction (ccf,
Figure 3d) were found to be slightly higher for broadleaves, while the average intensity was slightly higher for conifers. The distribution of forest types in terms of altitude was found to be quite similar. However, more detailed classification levels (levels 2 and 3) showed specific behaviors for certain species in the LiDAR metrics and topographic features (
Figure A1 and
Figure A2). Monospecific classes (e.g., Beech and Black pine) had the smallest interquartile range (IQR) compared to more heterogeneous classes (e.g., Quercus and other conifers). Furthermore, substantial differences were also observed among the broadleaved classes and among the conifer classes, due to the specificities of each species. Additionally, mixed forest classes exhibited different values depending on the monospecific classes intervening in the mixture (
Figure A1 and
Figure A2) (e.g., similar altitude data distributions for Beech and Scots pine-Beech classes).
4.2. Classification Results
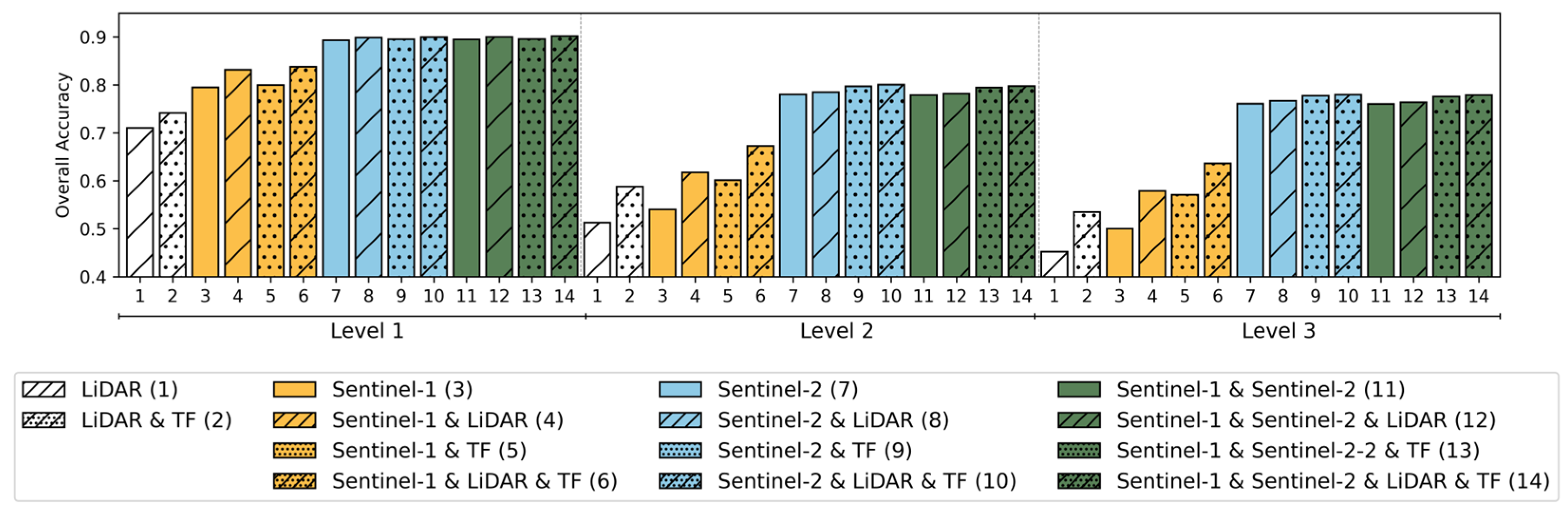
Figure 4 shows the OA values obtained with the test dataset for the different classification models. In all cases, the OA obtained for each particular model decreased as the classification level became more specific, with this decrease being more pronounced when moving from level 1 to level 2 than from level 2 to level 3. In addition, the three levels showed analogous patterns with regard to the classification scenarios. On the one hand, the scenarios including S-2 (scenarios 7–14) yielded the highest OA, followed by those including S-1 (scenarios 3–6) and LiDAR (1–2). On the other hand, the incorporation of topographic variables enhanced the OA in the majority of cases. However, the OA gain brought by these topographic variables was less pronounced at level 1 than at levels 2 and 3. The incorporation of LiDAR metrics to S-1 and/or S-2 scenarios led to an enhancement in OA in all cases, with greater enhancements for S-1 than for S-2.
For level 1, scenarios 8, 10, 12, and 14 displayed the highest OA values (~0.90), while, for levels 2 and 3, scenarios 9, 10, and 14 performed the best (~0.80 for level 2 and ~0.79 for level 3). It is worth noting that the classification scenario based solely on S-2 data (7) already achieved high OA values, with only slight improvements when other datasets were incorporated (scenarios 8–14).
For a better understanding of the classification results, the F
1 score values of each class are presented in
Figure 5,
Figure 6 and
Figure 7. Generally, it was observed that the benefits of combining input data were more significant for more complex classification levels (2 and 3). For level 1 (
Figure 5), broadleaves achieved the lowest error in all scenarios, with F
1 scores ranging from 0.80 to 0.95, followed by conifers (F
1 of 0.62–0.88) and mixed forests (F
1 of 0.13–0.33). The difference in F
1 values between broadleaves and conifers was higher in the first six scenarios. Notably, scenarios based on S-2 (7 to 14) yielded the highest accuracies, with remarkable F
1 values for both broadleaves and conifers. Interestingly, the combination of S-1 and S-2 (scenarios 11 to 14) did not yield any enhancements in comparison to those based on S-2 alone (scenarios 7 to 10). In fact, the results obtained for broadleaves and conifer forests remained unchanged after adding S-1, whereas the mixed class obtained an even poorer F
1 score. Indeed, the mixed class achieved very low F
1 scores in classifications based on S-1 data (scenarios 3 to 6). However, quite good results were obtained with S-1 for broadleaves and conifer forests, especially when incorporating the LiDAR metrics (scenario 4) and, to a lesser extent, the topographic variables (scenario 6), reaching F
1 scores of 0.90 and 0.80 for broadleaves and conifers, respectively.
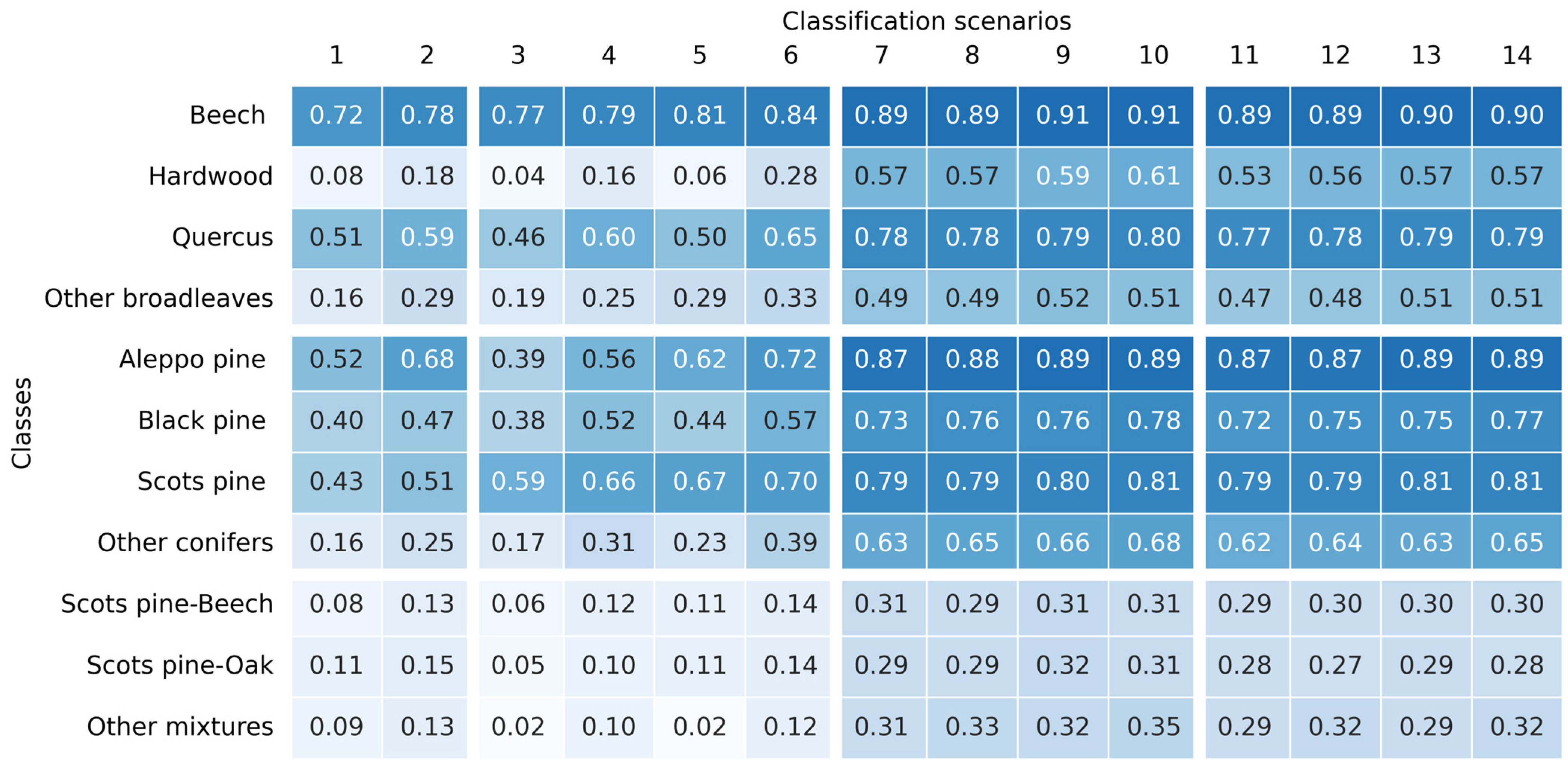
In level 2 (
Figure 6), the species achieving the highest F
1 scores were Beech, Aleppo pine, Scots pine, Quercus, and Black pine across most of the classification scenarios. Indeed, the models demonstrated a superior performance when classifying homogeneous classes, as opposed to heterogeneous classes (e.g., hardwood, other conifers, and other mixtures). In a manner analogous to the results observed for level 1, the incorporation of S-2 bands in the classifications led to an enhancement in the accuracy of these heterogeneous and mixed classes. Furthermore, scenarios based on S-2 (from 7 to 10) outperformed those combining S-1 and S-2 (from 11 to 14) across nearly all classes. Beech was the only species achieving an F
1 score greater than 0.70 using only LiDAR and topographic variables as model inputs (scenarios 1 and 2). In the other scenarios, the incorporation of LiDAR and/or topographic variables had a positive effect on the classification results. In some classes, LiDAR exhibited a greater impact than topographic variables (e.g., Hardwood and Quercus), while in other classes the reverse was observed (e.g., Aleppo pine). However, for the majority of species (e.g., Beech and Scots pine), there was a minimal difference in the results, especially when F
1 scores were already high (>0.70). Finally, it is worth noting that, while scenarios based on S-2 and S-1 and S-2 achieved the highest accuracies for most classes, scenario 6 (S-1) also yielded high accuracies for specific species, such as Beech (0.84), Aleppo pine (0.72), and Scots pine (0.70).
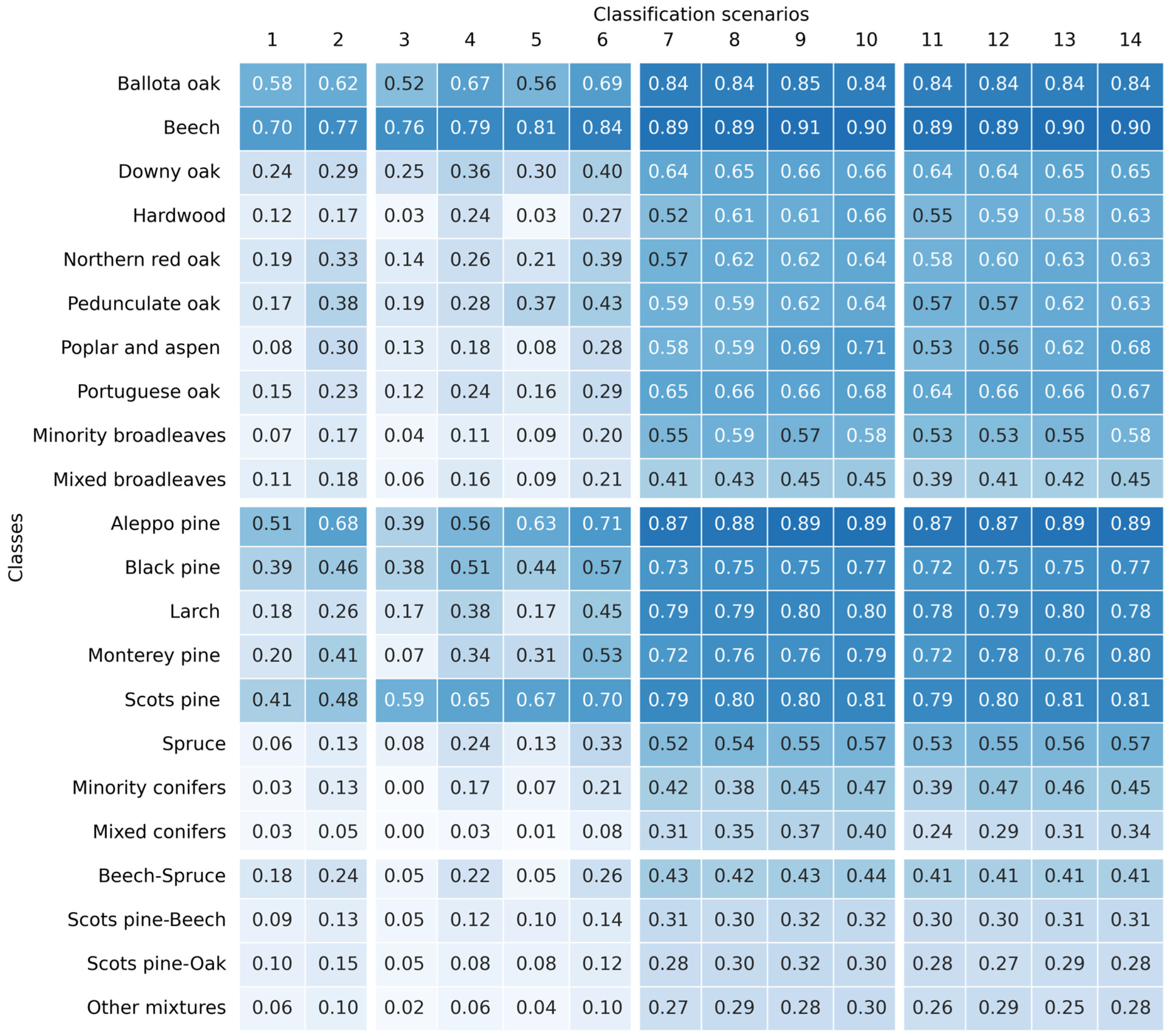
Finally, for classification level 3 (
Figure 7), Beech, Aleppo pine, Scots pine, and Black pine classes maintained mostly the same F
1 scores achieved for level 2, being again the best classified species. Additionally, Ballota oak, Larch, and Monterey pine demonstrated noteworthy performances, achieving high F
1 scores. Conversely, Northern red, Pedunculate and Portuguese oak, and Spruce were identified as the most challenging monospecific classes. Nevertheless, the performance of mixed and heterogeneous classes was again the poorest.
At level 3, in an analogous manner to level 2, most classes obtained higher accuracies when using S-2 as input (scenarios 7–14), in comparison to S-1 or LiDAR (scenarios 1–6), with most notable examples being Hardwood, Larch and Monterey pine, followed by Downy and Portuguese oaks, Black pine and Spruce. The contribution of S-2 bands was also remarkable for mixed and heterogeneous classes, which obtained modest performances, but in any case, much higher than with S-1 or LiDAR. As for level 2, the addition of LiDAR and topographic variables to the classification models based on S-1 and/or S-2 generally leads to enhanced F1 scores. In general, similar improvements were obtained when adding either LiDAR or topographic data, but in some cases, topographic features appeared to be more determinant (e.g., Poplar and aspen), and in some others, LiDAR (e.g., Hardwood, Black and Monterey pines, and Beech-spruce mixtures).
For most level 3 classes, scenarios incorporating S-2 data yielded the highest F1 scores. However, it should be noted that certain classes exhibited already remarkable F1 values even in the absence of this data. In scenario 2 (LiDAR and topographic data), Beech and Aleppo pine exhibited adequate results, achieving F1 scores of 0.77 and 0.68, respectively. These performances were further enhanced when S-1 data was integrated in scenario 6, with Beech attaining an F1 score of 0.84 and Aleppo pine 0.71. Scots pine also obtained promising results in this scenario, with an F1 score of 0.70.
The findings indicate that scenarios 9, 10, and 14 yielded the most favorable results for the three classification levels. Scenario 9 (S-2) presented high performance metrics with a lower number of input variables than scenario 10 (S-2 and topographic features). However, certain classes, such as Hardwood or Monterey pine, exhibited a substantial enhancement in their classification metrics in scenarios 10 and 14 (all input datasets). Regarding model complexity, classification scenario 10 was simpler than scenario 14. Consequently, the classification model selected as the one achieving the best compromise in terms of accuracy and model complexity was scenario 10. This model was thus recommended, and it was further evaluated in the next sections.
4.3. Recommended Classification Scenario
This section comments on the confusion matrices obtained with the recommended classification model (scenario 10), across all three levels, to evaluate the confusion between classes. At level 1 (
Table 5), the mixed class had the highest level of confusion, with only 32% (PA) of the test samples being correctly classified. Misclassified samples were confused with both conifers and broadleaves, although a higher degree of confusion was observed with conifers. In contrast, 94% of broadleaves and 89% of conifer test samples were correctly classified. Some confusion between broadleaves and conifers occurred. However, it had a minimal impact on the results. Approximately 3.3% of broadleaves were misclassified as conifers, while 6.8% of conifers were incorrectly classified as broadleaves.
Regarding the confusion matrix obtained at level 2 (
Table 6), the most important species had little confusion. For instance, 90% (PA) of the Beech test samples (class 1 in
Table 6) were correctly classified, 4% were misclassified as other broadleaves, 2% as Quercus, and 2% as Scots pine–Beech mixed forests. Conversely, within the 18,990 samples classified as Beech, 3% were actually other broadleaves, and 4% were Quercus. Similarly, 92% of the Aleppo pine test samples were correct, with only a few errors with Quercus and Black pine. Concerning Scots pine, 80% of its samples were correct, and confusion occurred with Quercus (6%), Black pine (4%), and mixed classes like Scots pine-Beech and Scots pine-Oak (3%).
Looking at the mixed classes (
Table 6), it was noteworthy that only 26% (UA) of the samples assigned to the Scots pine-Beech class really belonged to it. However, the confusion occurred with the monospecific classes intervening in the mix (Beech and Scots pine). Similar results were observed for the Scots pine-Oak mixed class.
At level 3 (
Table 7), similar results were observed, with the main monospecific classes being correctly classified, and most of the confusion occurring in heterogeneous and mixed classes. For broadleaves, Beech and Ballota Oak test samples were correctly classified in 89% of the cases, with only a minor confusion with Mixed broadleaves and Downy oak, and in the case of Ballota Oak also with some conifers (Aleppo and Scots pines). The most challenging broadleaves categories were the heterogeneous ones, specifically the hardwood class, with only 53% of its samples being correctly identified, and a large confusion with Beech, Downy oak, Mixed broadleaves, and Black pine. Interestingly, 87% (UA) of the samples assigned to Hardwood were correct. While half of the minority broadleaves samples were correctly classified, with the rest being mostly confused with other broadleaves (10%), beech (2%), and downy oak (3%).
Regarding conifers, Aleppo pine maintained 92% of correctly classified test samples, consistent with the results at level 2, and with only a few errors with Black pine and Ballota oak. Scots pine also obtained successful results with 80% of samples correctly classified, and the main confusions were with the mixed classes where this species participated. It was also noteworthy that nearly 11% of samples misclassified as Black pine belonged to the Scots pine category. Less frequent conifers like Larch or Monterey pine were, in general, correctly classified. In contrast, Spruce showed both poor PA and UA results, with only 59% of its samples correctly assigned, and notable confusion with Scots pine, Scots pine-Beech, and Beech classes. Minority and mixed conifers showed the worst results, with a substantial proportion of their samples wrongly assigned to Aleppo pine and, to a lesser extent, to other conifer species.
Finally, regarding mixed classes, in accordance with the already commented F
1 scores (
Figure 7), results were less successful, but the confusion matrix (
Table 7) showed that confusion mostly occurred with the monospecific classes intervening in the mix. For instance, the Beech–Spruce class was mostly confused with the Beech and Spruce classes, and the same occurred with Scots pine–Beech and Scots pine–Oak classes.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}