
DEMNet: A Small Object Detection Method for Tea Leaf Blight in Slightly Blurry UAV Remote Sensing Images


Abstract
1. Introduction
- (1)
- The lightweight HGNetV2 is used as the backbone extraction network, and the dynamic convolution mechanism is introduced to construct the DynamicHGNet network. The dynamic convolution is effectively utilized to adaptively generate convolution kernel weights for input features, which strengthens the feature extraction ability for blurry targets.
- (2)
- A lightweight EMAFPN feature fusion module is utilized to completely use the fusion of low-level and high-level features in order to better collect the detail information of small targets and increase their detection capability.
- (3)
- Construct a CMLAB module that incorporates multi-scale convolution and local window attention mechanism. Aiming at the unclear edges of blurry small targets, the CMLAB module makes up for the semantic lack of blurry edges by fusing contextual features of different scales. The local attention mechanism divides the image into different windows to enhance features, which significantly boosts the recall of leaf blight spot detection.
2. Materials and Methods
2.1. Datasets Preparation
2.1.1. Acquisition of Datasets
2.1.2. Data Preprocessing
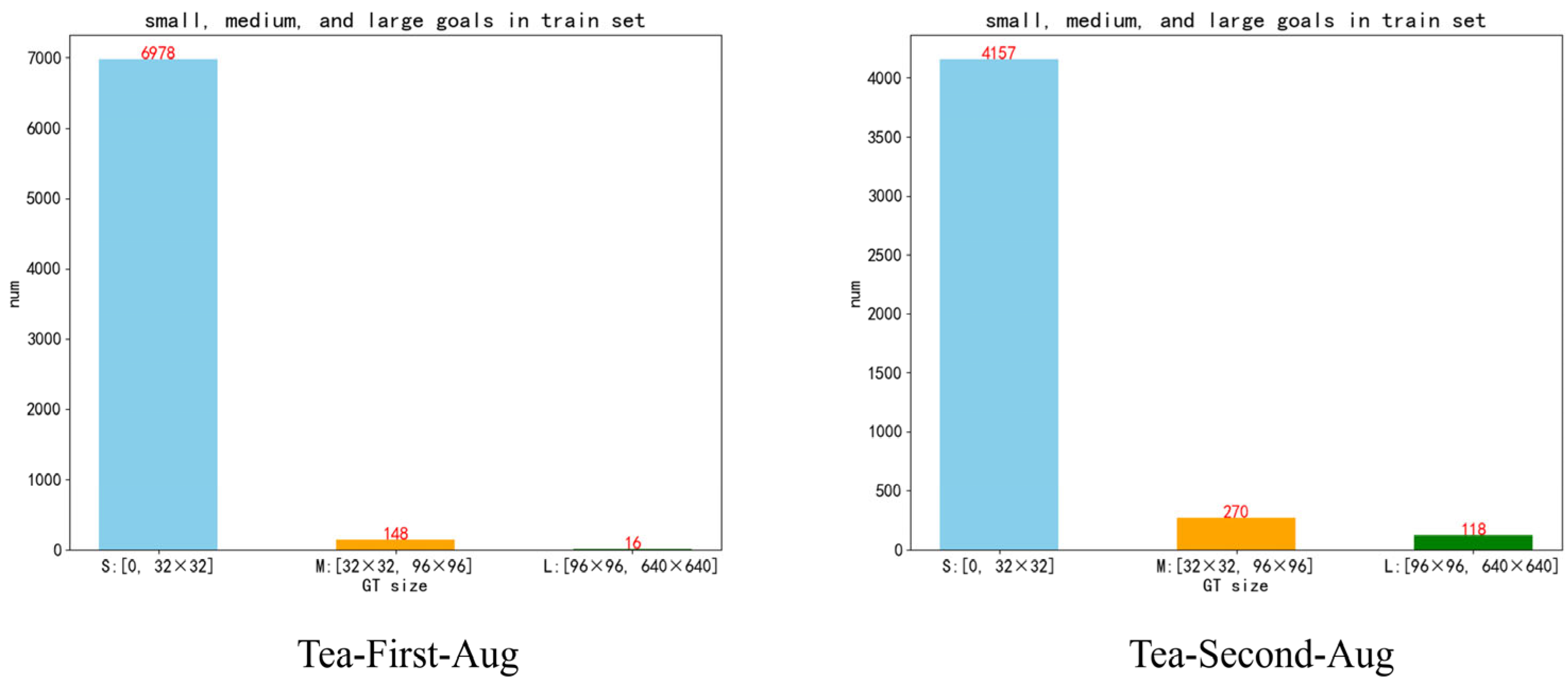
2.1.3. Augmentation of Datasets
2.2. Methodologies
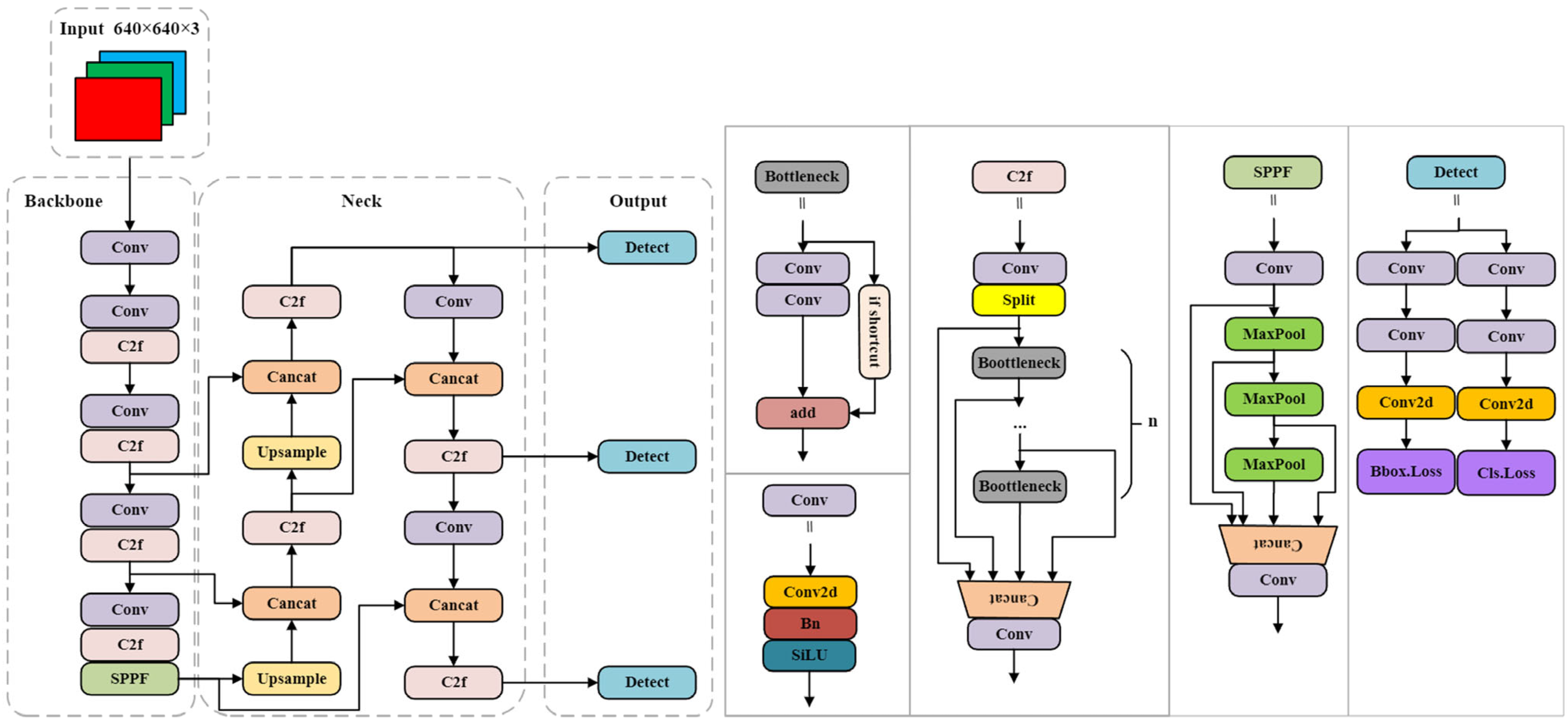
2.2.1. Baseline Model
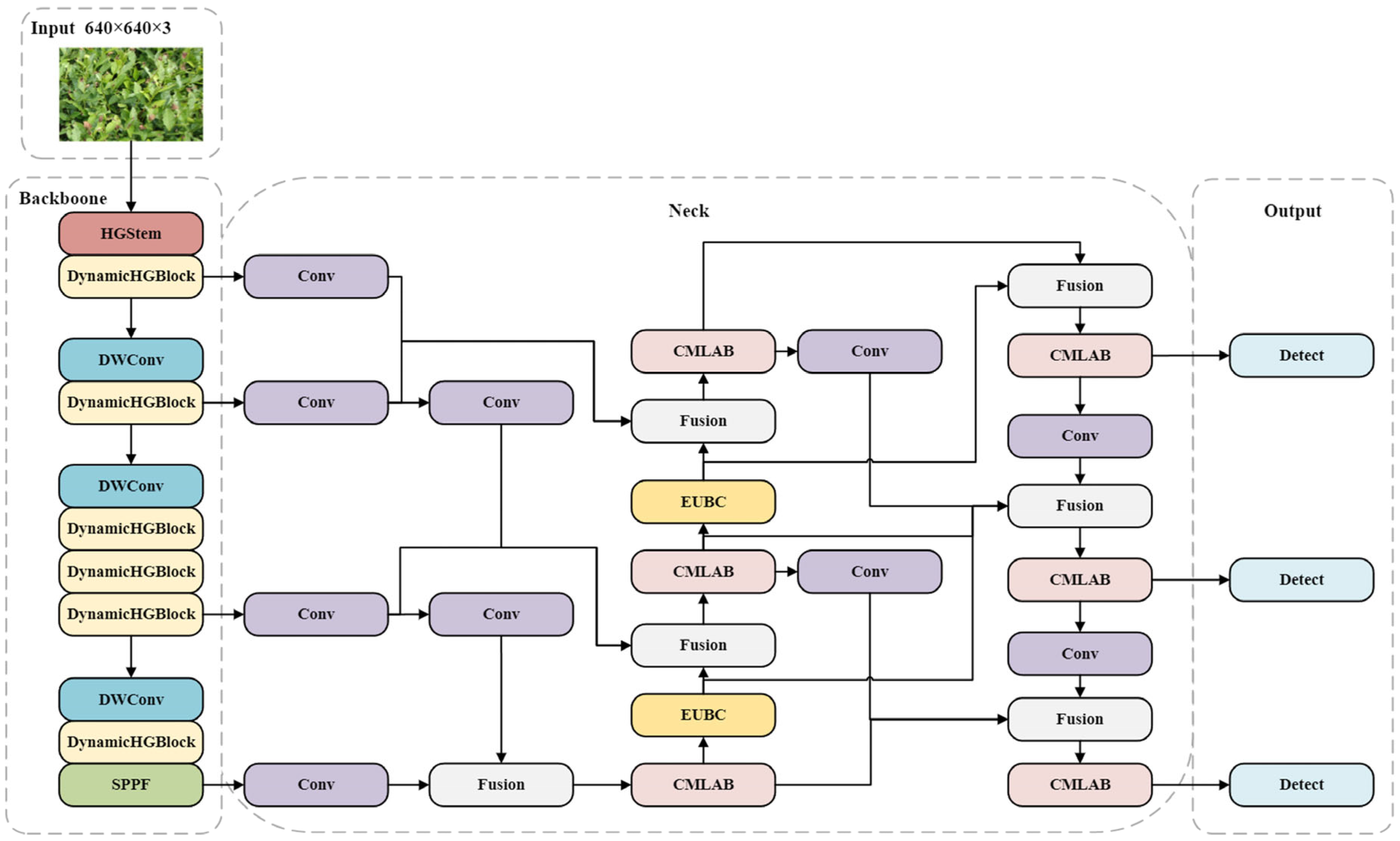
2.2.2. DEMNet Model
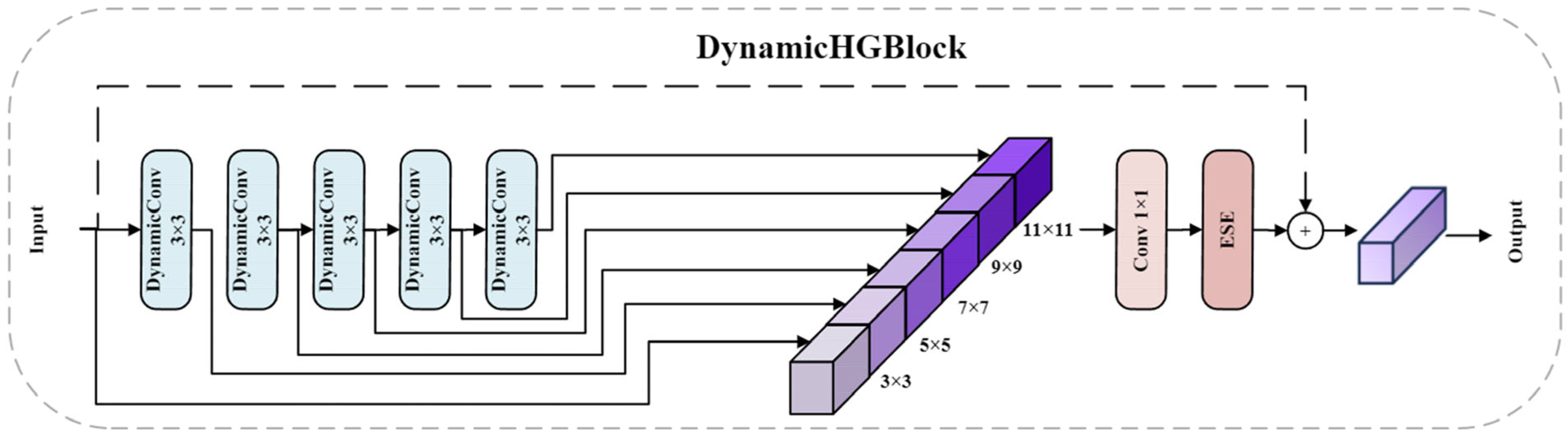
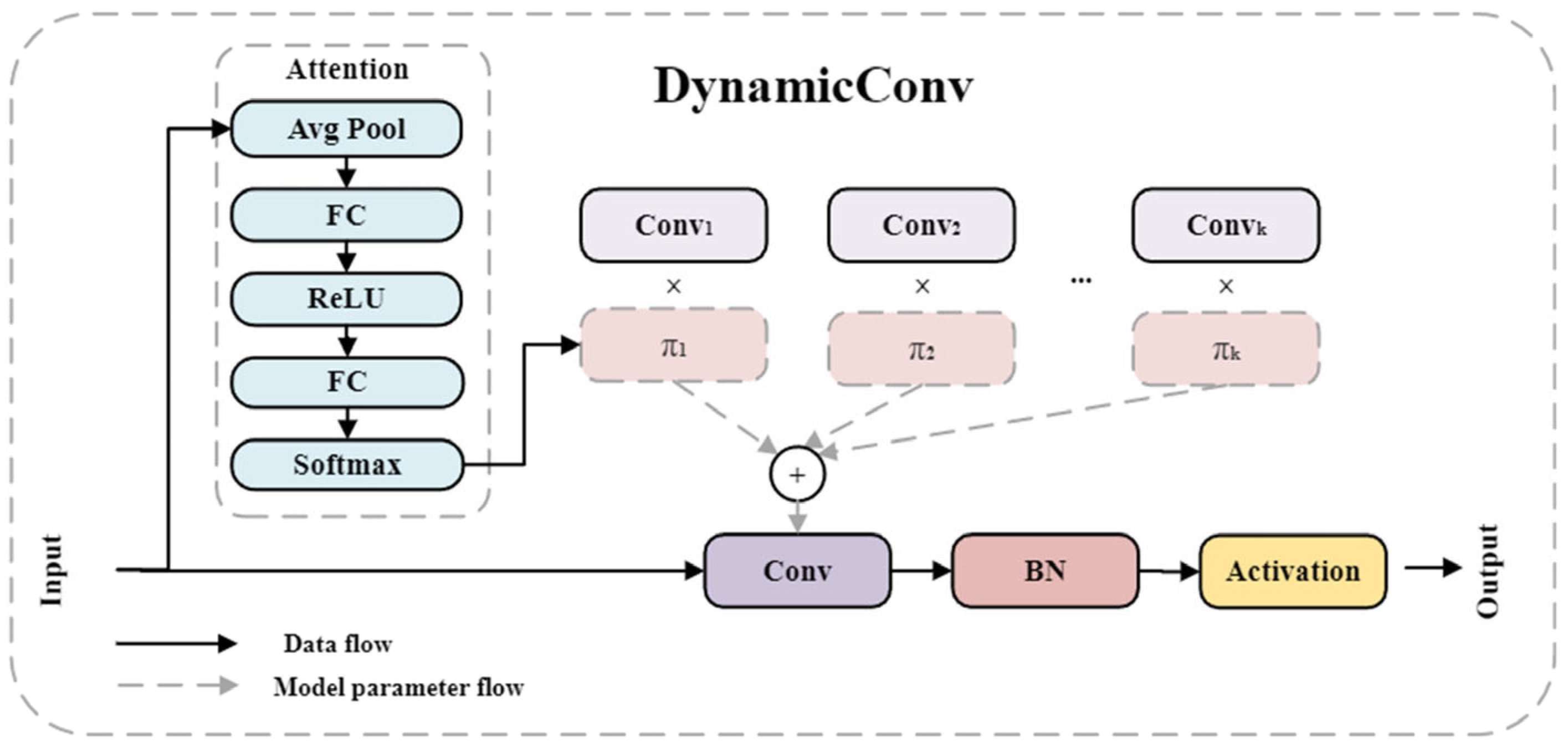
2.2.3. DynamicHGNetV2 Backbone Network
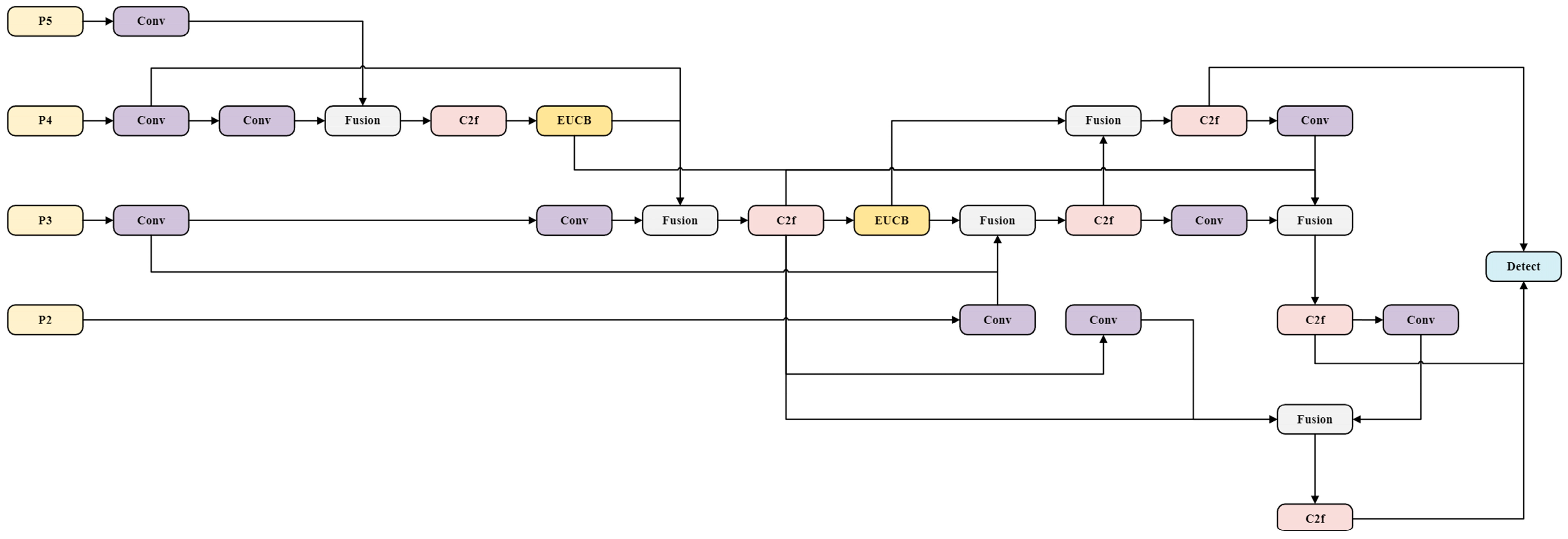
2.2.4. EMAFPN Structure
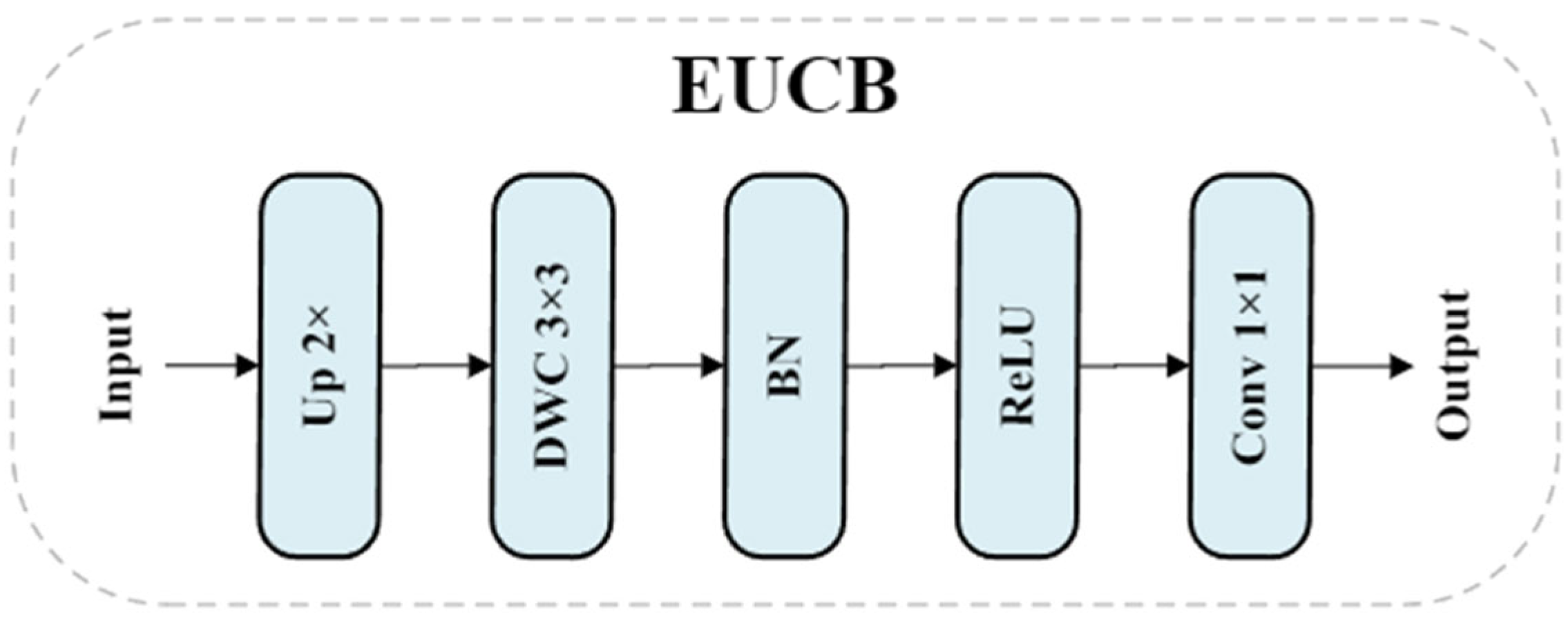
2.2.5. EUCB Module
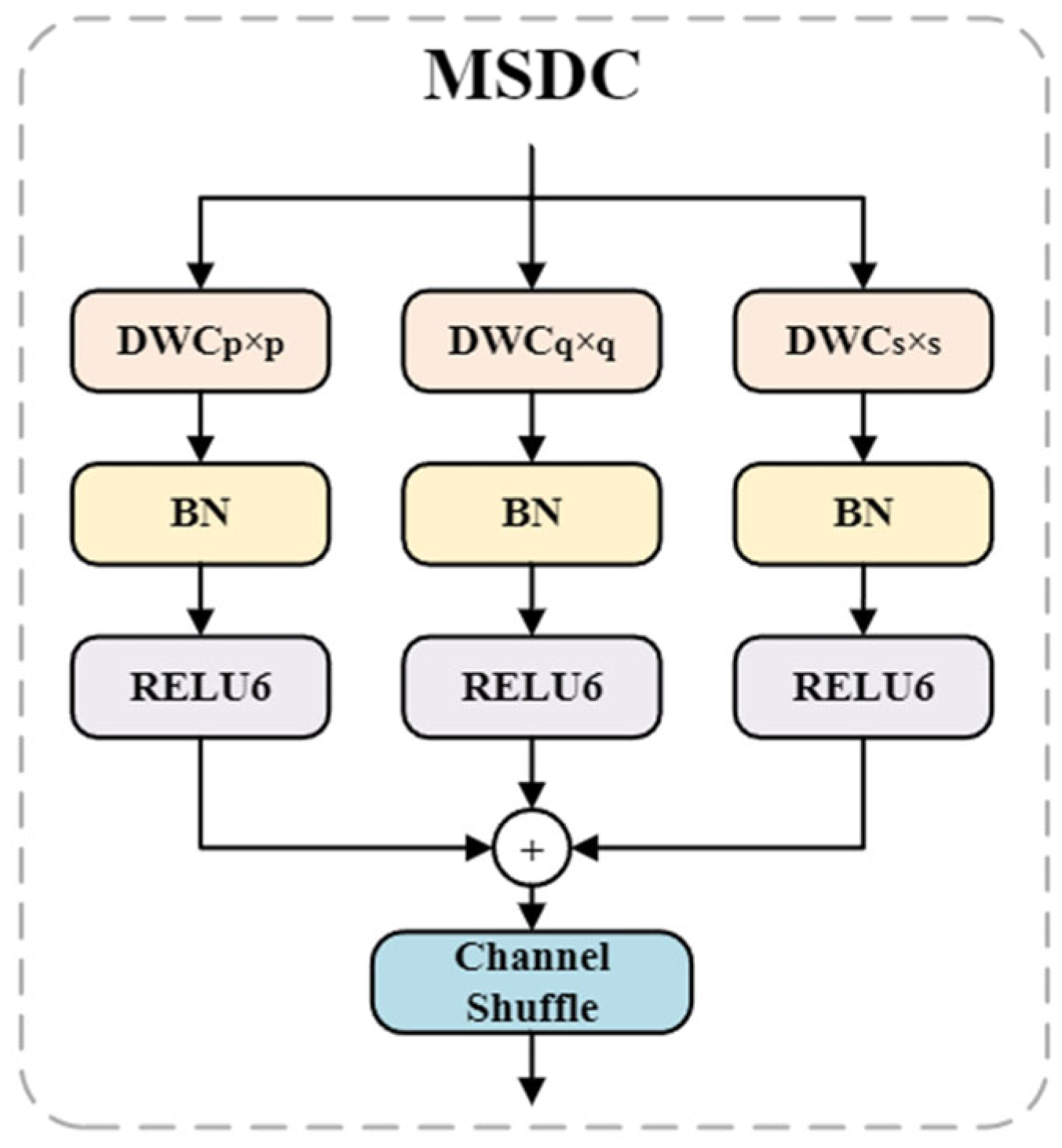
2.2.6. CMLAB Module
2.3. Experimental Setup and Metrics
2.3.1. Experimental Setup
2.3.2. Evaluation Metrics
3. Result
3.1. Ablation Experiment
3.2. Comparative Experiment
3.2.1. Comparative Study on Attention Mechanism
3.2.2. Comparison of Deblurring Methods and DEMNet for Small Object Detection
3.2.3. Comparison of Different Object Detection Models
3.2.4. Comparison Study of Data Augmentation
3.2.5. Generalization Evaluation on Two Datasets
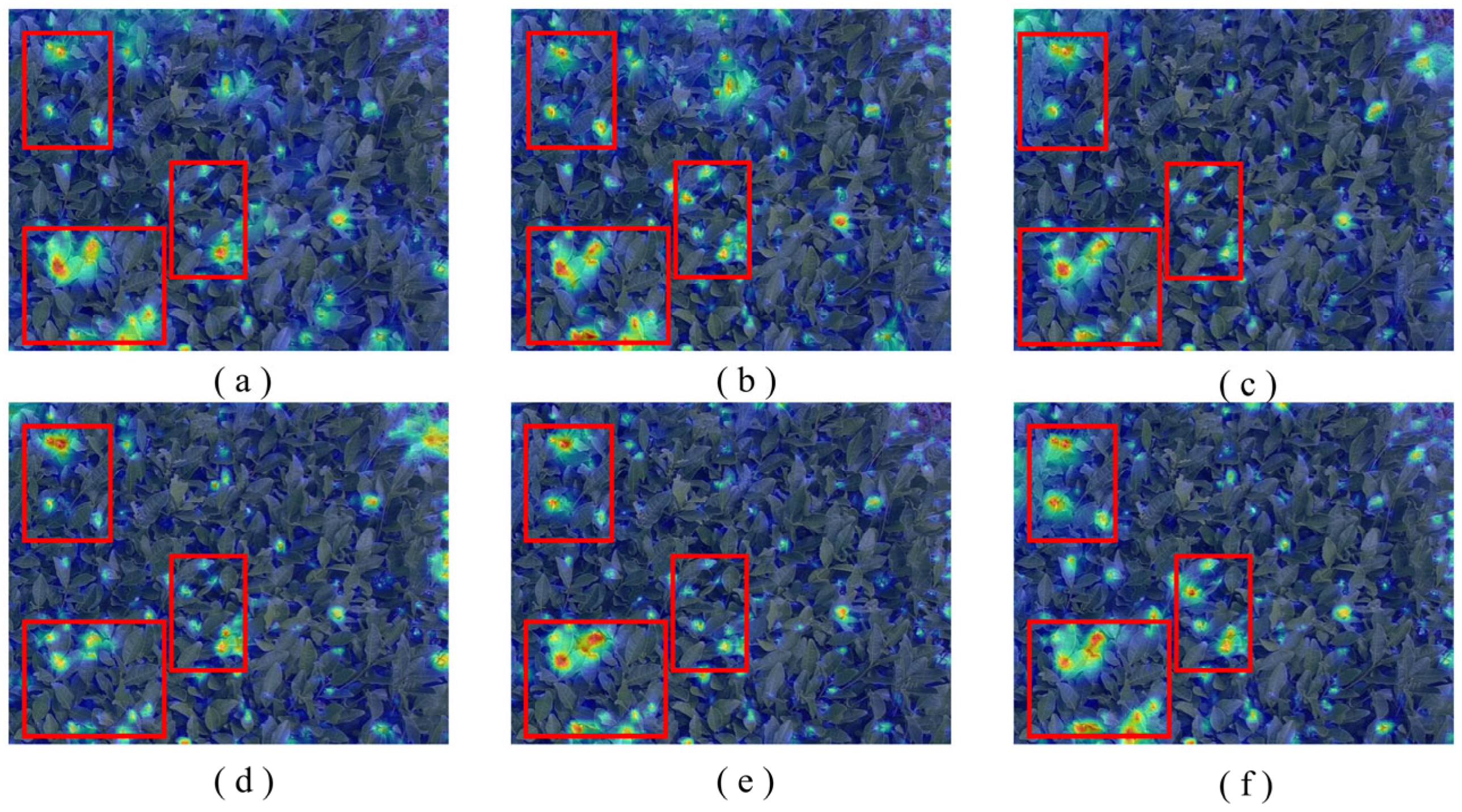
4. Discussion
5. Conclusions
- (1)
- The introduction of the Dynamic Convolution Network, DynamicHGNetV2, significantly enhances the model’s ability to extract features in blurry and degraded target scenarios.
- (2)
- The EMAFPN feature fusion structure improves small target detection, enhances multi-scale detection performance, and reduces computational complexity and parameters.
- (3)
- The traditional C2f module is innovatively modified to form the CMLAB module, improving detection accuracy for edge details and densely distributed small targets while suppressing redundant information.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xia, E.H.; Zhang, H.B.; Sheng, J.; Li, K.; Zhang, Q.J.; Kim, C.; Zhang, Y.; Liu, Y.; Zhu, T.; Li, W.; et al. The tea tree genome provides insights into tea flavor and independent evolution of caffeine biosynthesis. Mol. Plant 2017, 10, 866–877. [Google Scholar] [CrossRef] [PubMed]
- NBS. Tea Production. Available online: https://data.stats.gov.cn/easyquery.htm?cn=C01&zb=A0D0K&sj=2023 (accessed on 21 April 2025).
- Nath, M.; Mitra, P.; Kumar, D. A novel residual learning-based deep learning model integrated with attention mechanism and SVM for identifying tea plant diseases. Int. J. Comput. Appl. 2023, 45, 471–484. [Google Scholar] [CrossRef]
- Gayathri, S.; Wise, D.J.W.; Shamini, P.B.; Muthukumaran, N. Image analysis and detection of tea leaf disease using deep learning. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 398–403. [Google Scholar]
- Ramdan, A.; Heryana, A.; Arisal, A.; Kusumo, R.B.S.; Pardede, H.F. Transfer learning and fine-tuning for deep learning-based tea diseases detection on small datasets. In Proceedings of the International Conference on Radar, Antenna, Microwave, Electronics, Telecommunication (ICRAMET), Tangerang, Indonesia, 18–20 November 2020; pp. 206–211. [Google Scholar]
- Hu, G.; Wang, H.; Zhang, Y.; Wan, M. Detection and severity analysis of tea leaf blight based on deep learning. Comput. Electr. Eng. 2021, 90, 107023. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, R.; Bai, D.; Lin, H. YOLO-tea: A tea disease detection model improved by YOLOv5. Forests 2023, 14, 415. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, H.; Lin, H.; Bai, D. TeaViTNet: Tea disease and pest detection model based on fused multiscale attention. Agronomy 2024, 14, 633. [Google Scholar] [CrossRef]
- Ye, R.; Shao, G.; He, Y.; Gao, Q.; Li, T. YOLOv8-RMDA: Lightweight YOLOv8 network for early detection of small target diseases in tea. Sensors 2024, 24, 2896. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery with Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Ye, W.; Lao, J.; Liu, Y.; Chang, C.-C.; Zhang, Z.; Li, H.; Zhou, H. Pine Pest Detection Using Remote Sensing Satellite Images Combined with a Multi-Scale Attention-UNet Model. Ecol. Inform. 2022, 72, 101906. [Google Scholar] [CrossRef]
- Tetila, E.C.; Machado, B.B.; Astolfi, G.; Belete, N.A.D.; Amorim, W.P.; Roel, A.R.; Pistori, H. Detection and classification of soybean pests using deep learning with UAV images. Comput. Electron. Agric. 2020, 179, 105836. [Google Scholar] [CrossRef]
- Bao, W.; Zhu, Z.; Hu, G.; Zhou, X.; Zhang, D.; Yang, X. UAV remote sensing detection of tea leaf blight based on DDMA-YOLO. Comput. Electron. Agric. 2023, 205, 107637. [Google Scholar] [CrossRef]
- Sayed, M.; Brostow, G. Improved Handling of Motion Blur in Online Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1706–1716. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple Baselines for Image Restoration. In Proceedings of the ECCV, Tel Aviv, Israel, 23–27 October 2022; pp. 17–33. [Google Scholar]
- Genze, N.; Wirth, M.; Schreiner, C.; Ajekwe, R.; Grieb, M.; Grimm, D.G. Improved weed segmentation in UAV imagery of sorghum fields with a combined deblurring segmentation model. Plant Methods 2023, 19, 87. [Google Scholar] [CrossRef] [PubMed]
- Hu, G.; Ye, R.; Wan, M.; Bao, W.; Zhang, Y.; Zeng, W. Detection of Tea Leaf Blight in Low-Resolution UAV Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–18. [Google Scholar] [CrossRef]
- Jobaer, S.; Tang, X.s.; Zhang, Y.; Li, G.; Ahmed, F. A novel knowledge distillation framework for enhancing small object detection in blurry environments with unmanned aerial vehicle-assisted images. Complex Intell. Syst. 2025, 11, 63. [Google Scholar] [CrossRef]
- Bansal, R.; Raj, G.; Choudhury, T. Blur Image Detection Using Laplacian Operator and Open-CV. In Proceedings of the 2016 International Conference System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 25–27 November 2016; pp. 63–67. [Google Scholar]
- Brennan, W. BlurDetection2. Available online: https://github.com/WillBrennan/BlurDetection2 (accessed on 21 April 2025).
- Tzutalin. Labelimg. Available online: https://github.com/HumanSignal/labelImg (accessed on 21 April 2025).
- Jocher, G. Ultralytics YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 April 2025).
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar] [CrossRef]
- Rahman, M.M.; Munir, M.; Marculescu, R. EMCAD: Efficient Multi-Scale Convolutional Attention Decoding for Medical Image Segmentation. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B. MobileNetV4-Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14420–14430. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half instance normalization network for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Jiang, Y.; Lu, L.; Wan, M.; Hu, G.; Zhang, Y. Detection method for tea leaf blight in natural scene images based on lightweight and efficient LC3Net model. J. Plant Dis. Prot. 2024, 131, 209–225. [Google Scholar] [CrossRef]
- Jiang, Y.; Wei, Z.; Hu, G. An efficient detection method for tea leaf blight in UAV remote sensing images under intense lighting conditions based on MLDNet. Comput. Electron. Agric. 2025, 229, 109825. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | P/% | R/% | mAP@0.5/% | Parameters/M | GFLOPs | Model Size/MB |
|---|---|---|---|---|---|---|
| Baseline | 84.2 | 72.1 | 80.3 | 3.0 | 8.1 | 6.3 |
| GhostNet | 82.1 | 72.5 | 80.1 | 3.3 | 6.0 | 7.1 |
| ShuffleNetV2 | 83.0 | 66.2 | 77.0 | 1.7 | 5.0 | 3.7 |
| MobileNetV3 | 79.5 | 68.3 | 77.6 | 2.3 | 5.7 | 5.0 |
| MobileNetV4 | 86.6 | 67.6 | 82.2 | 5.7 | 22.6 | 11.7 |
| MobileVit3 | 78.8 | 75.8 | 81.0 | 3.3 | 10.1 | 7.0 |
| EfficientNet | 74.6 | 71.3 | 77.9 | 2.0 | 5.8 | 4.3 |
| EfficientVit | 78.7 | 73.3 | 78.8 | 4.0 | 9.5 | 8.8 |
| HGNetV2 | 84.6 | 72.9 | 81.9 | 2.3 | 7.0 | 5.0 |
| Methods | P/% | R/% | mAP@0.5/% | Parameters/M | GFLOPs | Model Size/MB |
|---|---|---|---|---|---|---|
| HGBlock | 84.6 | 72.9 | 81.9 | 2.3 | 7.0 | 5.0 |
| DynamicHGBlock | 83.5 | 73.9 | 83.1 | 2.5 | 6.7 | 5.4 |
| Methods | P/% | R/% | mAP@0.5/% | Parameters/M | GFLOPs | Model Size/MB |
|---|---|---|---|---|---|---|
| Add | 83.5 | 74.2 | 82.0 | 2.1 | 7.6 | 4.6 |
| Concat | 80.3 | 76.7 | 81.5 | 2.2 | 7.8 | 4.9 |
| Parameter | Configuration |
|---|---|
| CPU model | Intel Xeon Platinum 8481C v (Intel Corporation, Santa Clara, CA, USA) |
| GPU model | NVIDIA GeForce RTX 4090 D (NVIDIA, Santa Clara, CA, USA) |
| Operating system | Ubuntu 11.4 |
| Deep learning frame | PyTorch 2.0 |
| GPU accelerator | CUDA 11.8 |
| Scripting language | Python 3.8.10 |
| Parameter | Configuration |
|---|---|
| Batch Size | 4 |
| Epochs | 250 |
| Optimizer | SGD |
| momentum | 0.937 |
| Image size | 640 640 |
| Initial learning rate | 0.005 |
| Model | Modules | Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Baseline | Dynamic HGNetV2 | EMAFPN | CMLAB | R | mAP@0.5 | Parameters | GFLOPs | Model Size/MB | |
| 1 | √ | 72.1 | 80.3 | 3.0 | 8.1 | 6.3 | |||
| 2 | √ | √ | 73.9 | 83.1 | 2.5 | 6.7 | 5.4 | ||
| 3 | √ | √ | 72.2 | 82.9 | 2.1 | 7.6 | 4.6 | ||
| 4 | √ | √ | 74.2 | 81.3 | 2.7 | 7.7 | 6.0 | ||
| 5 | √ | √ | √ | 70.4 | 80.3 | 1.7 | 6.3 | 3.8 | |
| 6 | √ | √ | √ | 75.3 | 82.9 | 2.3 | 6.4 | 5.2 | |
| 7 | √ | √ | √ | 74.8 | 81.2 | 2.1 | 7.4 | 5.0 | |
| 8 | √ | √ | √ | √ | 77.8 (+5.7%) | 85.2 (+4.9%) | 1.7 (−43.3%) | 6.1 (−24.7%) | 4.2 (−33.3%) |
| Methods | P/% | R/% | mAP@0.5/% | Parameters/M | GFLOPs | Model Size/MB |
|---|---|---|---|---|---|---|
| No Attention | 85.1 | 75.8 | 82.9 | 1.6 | 5.9 | 3.7 |
| CBAM | 76.2 | 76 | 80.0 | 1.6 | 5.9 | 3.8 |
| TripletAttention | 81.5 | 75.4 | 81.2 | 1.6 | 5.9 | 3.8 |
| SimAM | 80.6 | 72.8 | 81.2 | 1.6 | 5.9 | 3.7 |
| CoordAtt | 79.2 | 73.3 | 79.8 | 1.6 | 5.9 | 3.8 |
| LWA | 82.7 | 77.8 | 85.2 | 1.7 | 6.1 | 4.2 |
| Method | P/% | R/% | mAP@0.5/% | mAP@0.75/% | mAP@0.5:0.95/% | GFLOPs |
|---|---|---|---|---|---|---|
| NAFNet | 74.9 | 73.3 | 78.7 | 19.2 | 31.8 | 130.0 |
| DeblurGANv2 | 80.4 | 75.3 | 82.2 | 17.0 | 32.0 | 43.75 |
| HINet | 82.9 | 74.6 | 79.5 | 18.7 | 32.1 | 341.4 |
| YOLOv8 | 84.2 | 72.1 | 80.3 | 16.5 | 33.3 | 8.1 |
| DEMNet | 82.7 | 77.8 | 85.2 | 19.6 | 34.1 | 6.1 |
| Methods | mAP@0.75/% | mAP@0.5:0.95/% | mAP@0.5/% | Parameters/M | GFLOPs |
|---|---|---|---|---|---|
| Yolov8n (baseline) | 16.5 | 33.3 | 80.3 | 3.0 | 8.1 |
| Yolov5n | 17.9 | 30.4 | 79.8 | 1.7 | 4.1 |
| Yolov5s | 20.2 | 31.9 | 79.7 | 7.0 | 15.8 |
| Yolov10n | 20.1 | 32.1 | 76.1 | 2.2 | 6.6 |
| Yolov11n | 20.0 | 32.5 | 80.5 | 2.5 | 6.3 |
| Yolov11s | 23.4 | 34.1 | 81.4 | 9.0 | 21.3 |
| RTDETR | 18.7 | 30.3 | 77.5 | 31.9 | 103.4 |
| Faster R-CNN | 16.6 | 30.7 | 82.4 | 41.3 | 167.0 |
| RetinaNet | 17.6 | 31.3 | 81.4 | 36.3 | 162.0 |
| DEMNet | 19.6 | 34.1 | 85.2 | 1.7 | 6.1 |
| Dataset | P/% | R/% | mAP@0.5/% | mAP@0.75 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| Tea-First-Original | 73.9 | 73.7 | 76.6 | 15.6 | 28.9 |
| Tea-First-Aug | 82.7 | 77.8 | 85.2 | 19.6 | 34.1 |
| Tea-Second-Original | 48.4 | 46.7 | 48.3 | 6.1 | 17.6 |
| Tea-Second-Aug | 53.4 | 58.7 | 51.0 | 5.1 | 19.0 |
| Dataset | Method | P/% | R/% | mAP@0.5/% | mAP@0.75 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|
| Tea-First-Aug | Yolov8 | 84.2 | 72.1 | 80.3 | 16.5 | 33.3 |
| Tea-First-Aug | DEMNet | 82.7 | 77.8 | 85.2 | 19.6 | 34.1 |
| Tea-SecondAug | YOLOv8 | 47.0 | 49.3 | 46.9 | 5.7 | 16.2 |
| Tea-Second-Aug | DEMNet | 53.4 | 58.7 | 51.0 | 5.1 | 19.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Jing, Y.; Li, H.-D.; Shi, J.; Lin, H. DEMNet: A Small Object Detection Method for Tea Leaf Blight in Slightly Blurry UAV Remote Sensing Images. Remote Sens. 2025, 17, 1967. https://doi.org/10.3390/rs17121967
Gu Y, Jing Y, Li H-D, Shi J, Lin H. DEMNet: A Small Object Detection Method for Tea Leaf Blight in Slightly Blurry UAV Remote Sensing Images. Remote Sensing. 2025; 17(12):1967. https://doi.org/10.3390/rs17121967
Chicago/Turabian StyleGu, Yating, Yuxin Jing, Hao-Dong Li, Juntao Shi, and Haifeng Lin. 2025. "DEMNet: A Small Object Detection Method for Tea Leaf Blight in Slightly Blurry UAV Remote Sensing Images" Remote Sensing 17, no. 12: 1967. https://doi.org/10.3390/rs17121967
APA StyleGu, Y., Jing, Y., Li, H.-D., Shi, J., & Lin, H. (2025). DEMNet: A Small Object Detection Method for Tea Leaf Blight in Slightly Blurry UAV Remote Sensing Images. Remote Sensing, 17(12), 1967. https://doi.org/10.3390/rs17121967