
A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification


Abstract

1. Introduction
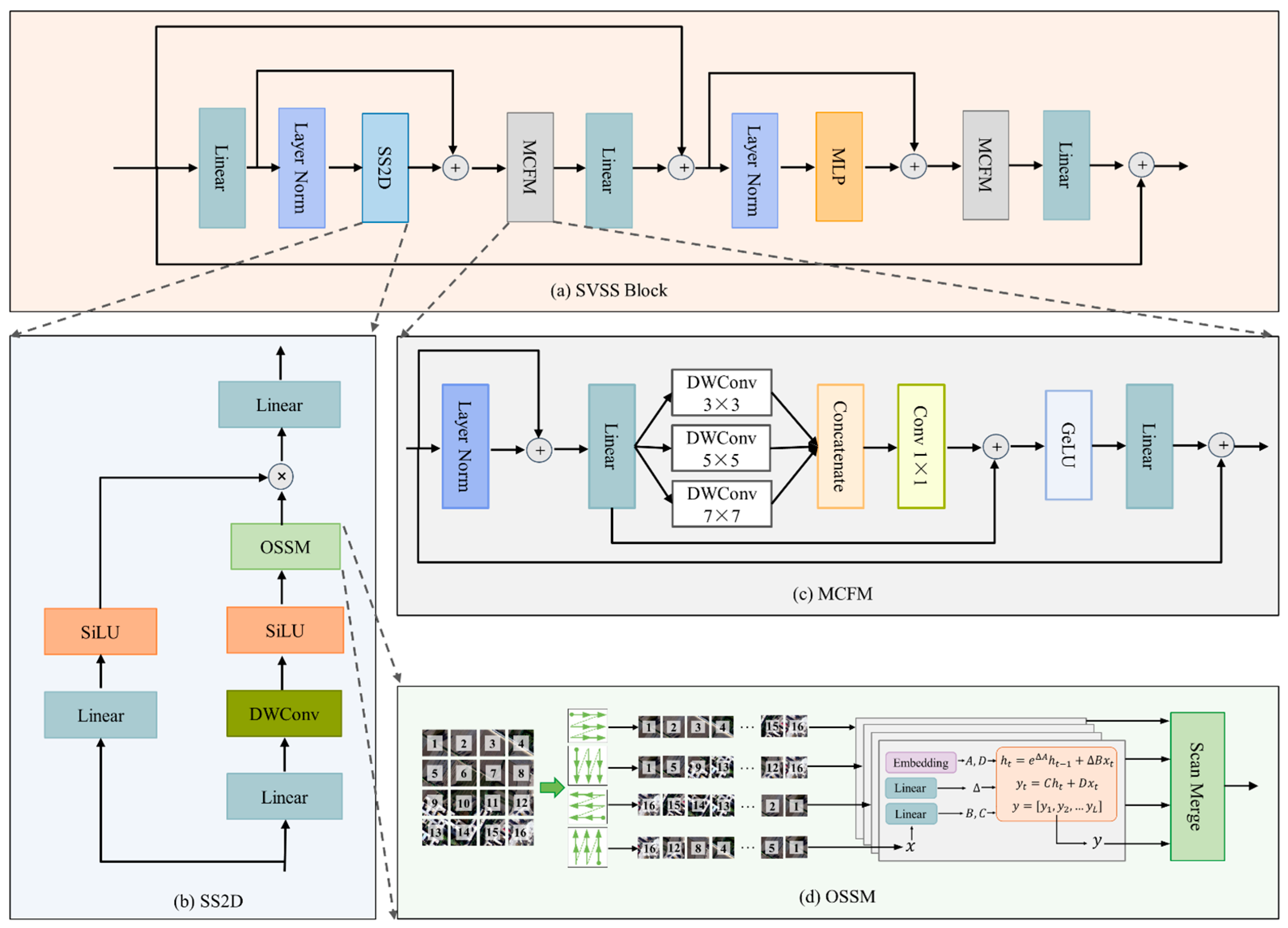
- At the model level, we propose a high-resolution U-shaped mamba (HRUMamba) network to tackle the CI problem. This model employs the existing HRNet as the encoder to extract fine-grained short-range contextual features at multiple scales while preserving detailed information of small targets through feature fusion. The decoder incorporates a newly designed scaled visual state space (SVSS) block, which enhances long-range dependency modeling using the state-of-the-art mamba technique. Within the SVSS block, a novel multi-convolution fusion (MCF) module is proposed, leveraging multiple depthwise convolutions to further enhance inter-class discriminability across different spatial scales. Moreover, we embed three newly proposed attention-based adaptive awareness fusion (AAF) modules into the skip connections to effectively enhance object saliency while mitigating noise interference.
- At the loss function level, we design a novel synthetic loss function consisting of a primary loss and an auxiliary loss. The primary loss, composed of cross-entropy loss and Dice loss, is mainly used to suppress CI problems in semantic segmentation. The auxiliary loss provides additional supervisory signals for the primary loss, thereby improving model performance and convergence speed.
- At the sample dataset optimization level, we affine-transform the minority class samples in the training set by a certain pixel scale threshold to increase the number of minority class samples. Then, the Mosaic data augmentation technique is used in the training stage to increase the data diversity by splicing new images to help the model better learn different scene features.
- In this study, the coefficient of variation (CV) is introduced for the first time as a new metric for multi-class imbalance evaluation. This metric provides a robust and standardized approach for assessing CI in complex multi-class land cover classification scenarios, addressing a critical gap in existing evaluation methods.
2. Related Work
2.1. Model Architecture for Addressing the CI Problem
2.2. Loss Function for Addressing the CI Problem
2.3. Data Optimization Strategies for Addressing the CI Problem
2.4. Indicators for Measuring CI
3. Methodology
3.1. HRUMamba Model
3.1.1. Model’s Encoder–Decoder Framework
3.1.2. HRNet Encoder
3.1.3. Block-Based SVSS Decoder
3.1.4. AAF Module
3.2. Synthetic Loss Function
3.3. CI Indicators
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Datasets and Preparation
4.1.2. Evaluation Indicators
4.1.3. Training Process
4.1.4. The Models Selected for Comparison
4.2. Results of CI-Related Ablation Experiments
4.2.1. Ablation Results of the Key Modules of the HRUMamba Model
4.2.2. Comparison Among Loss Functions
4.2.3. Effect of Data Augmentations
4.3. Comparison of Classification Results
4.3.1. Results Based on Vaihingen Dataset
4.3.2. Results Based on Minqin Dataset
4.3.3. Comparison of Model Efficiency
4.4. Loss Functions
4.5. Comparison of IR and CV
5. Discussion
5.1. Comparison of Models in Dealing with CI Problems
5.2. Importance of the Collaboration with Model, Loss Function, and Sample Dataset to Address the CI Problems
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Megahed, F.M.; Chen, Y.J.; Megahed, A.; Ong, Y.; Altman, N.; Krzywinski, M. The class imbalance problem. Nat. Methods 2021, 18, 1270–1272. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Kang, B.; Hooi, B.; Yan, S.; Feng, J. Deep Long-Tailed Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10795–10816. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, K.; Bellinger, C.; Corizzo, R.; Branco, P.; Krawczyk, B.; Japkowicz, N. The class imbalance problem in deep learning. Mach. Learn. 2024, 113, 4845–4901. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Patel, V.; Bhavsar, H. An Empirical Study of Multi-class Imbalance Learning Algorithms. In Proceedings of ICT Systems and Sustainability: Proceedings of ICT4SD 2022; Springer: Berlin/Heidelberg, Germany; pp. 161–174. [CrossRef]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef]
- Jiang, W.D.; Sun, Y.L.; Lei, L.; Kuang, G.Y.; Ji, K.F. Change detection of multisource remote sensing images: A review. Int. J. Digit. Earth 2024, 17, 2398051. [Google Scholar] [CrossRef]
- Qin, R.J.; Liu, T. A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images-Analysis Unit, Model Scalability and Transferability. Remote Sens. 2022, 14, 646. [Google Scholar] [CrossRef]
- Tang, H.K.; Wang, H.L.; Zhang, X.P. Multi-class change detection of remote sensing images based on class rebalancing. Int. J. Digit. Earth 2022, 15, 1377–1394. [Google Scholar] [CrossRef]
- Ning, X.G.; Zhang, H.C.; Zhang, R.Q.; Huang, X. Multi-stage progressive change detection on high resolution remote sensing imagery. Isprs J. Photogramm. 2024, 207, 231–244. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Zhu, X.X. Enabling country-scale land cover mapping with meter-resolution satellite imagery. ISPRS J. Photogramm. 2023, 196, 178–196. [Google Scholar] [CrossRef]
- Ren, Y.Y.; Zhang, X.F.; Ma, Y.J.; Yang, Q.Y.; Wang, C.J.; Liu, H.L.; Qi, Q. Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sens. 2020, 12, 3547. [Google Scholar] [CrossRef]
- Hu, L.; Zhou, X.; Ruan, J.C.; Li, S.P. ASPP+-LANet: A Multi-Scale Context Extraction Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1036. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4095–4104. [Google Scholar] [CrossRef]
- Kossmann, D.; Wilhelm, T.; Fink, G.A. Towards Tackling Multi-Label Imbalances in Remote Sensing Imagery. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5782–5789. [Google Scholar] [CrossRef]
- Chen, X.; Li, L.Y.; Li, Z.H.; Liu, M.; Li, Q.L.; Qi, H.G.; Ma, D.L.; Wen, Y.; Cao, G.T.; Yu, P.L.H. KD loss: Enhancing discriminability of features with kernel trick for object detection in VHR remote sensing images. Eng. Appl. Artif. Intell. 2024, 129, 107641. [Google Scholar] [CrossRef]
- Tan, J.R.; Li, B.; Lu, X.; Yao, Y.Q.; Yu, F.W.; He, T.; Ouyang, W.L. The Equalization Losses: Gradient-Driven Training for Long-tailed Object Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13876–13892. [Google Scholar] [CrossRef]
- Tan, J.R.; Wang, C.B.; Li, B.Y.; Li, Q.Q.; Ouyang, W.L.; Yin, C.Q.; Yan, J.J. Equalization Loss for Long-Tailed Object Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; pp. 11659–11668. [Google Scholar] [CrossRef]
- Yuan, M.; Ren, D.B.; Feng, Q.S.; Wang, Z.B.; Dong, Y.K.; Lu, F.X.; Wu, X.L. MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 361. [Google Scholar] [CrossRef]
- Hossain, M.S.; Betts, J.M.; Paplinski, A.P. Dual Focal Loss to address class imbalance in semantic segmentation. Neurocomputing 2021, 462, 69–87. [Google Scholar] [CrossRef]
- Quan, Y.H.; Zhong, X.; Feng, W.; Chan, J.C.W.; Li, Q.; Xing, M.D. SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification. Remote Sens. 2021, 13, 464. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Gong, Z.; Duan, L.J.; Xiao, F.J.; Wang, Y.X. MSAug: Multi-Strategy Augmentation for rare classes in semantic segmentation of remote sensing images. Displays 2024, 84, 102779. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Chen, J.F.; Chen, G.; Fang, B.; Wang, J.J.; Wang, L.Z. Class-Aware Domain Adaptation for Coastal Land Cover Mapping Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 11800–11813. [Google Scholar] [CrossRef]
- Shumilo, L.; Okhrimenko, A.; Kussul, N.; Drozd, S.; Shkalikov, O. Generative adversarial network augmentation for solving the training data imbalance problem in crop classification. Remote Sens. Lett. 2023, 14, 1131–1140. [Google Scholar] [CrossRef]
- Leichtle, T.; Geiss, C.; Lakes, T.; Taubenböck, H. Class imbalance in unsupervised change detection—A diagnostic analysis from urban remote sensing. Int. J. Appl. Earth Obs. 2017, 60, 83–98. [Google Scholar] [CrossRef]
- Du, J.; Zhou, Y.H.; Liu, P.; Vong, C.M.; Wang, T.F. Parameter-Free Loss for Class-Imbalanced Deep Learning in Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 3234–3240. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Xiao, A.; Xuan, W.; Wang, J.; Huang, J.; Tao, D.; Lu, S.; Yokoya, N. Foundation models for remote sensing and earth observation: A survey. arXiv 2024, arXiv:2410.16602. [Google Scholar]
- Li, Y.X.; Li, X.; Dai, Y.M.; Hou, Q.B.; Liu, L.; Liu, Y.X.; Cheng, M.M.; Yang, J. LSKNet: A Foundation Lightweight Backbone for Remote Sensing. Int. J. Comput. Vision. 2024, 133, 1410–1431. [Google Scholar] [CrossRef]
- Wei, W.; Cheng, Y.; He, J.F.; Zhu, X.Y. A review of small object detection based on deep learning. Neural Comput. Appl. 2024, 36, 6283–6303. [Google Scholar] [CrossRef]
- Gui, S.X.; Song, S.; Qin, R.J.; Tang, Y. Remote Sensing Object Detection in the Deep Learning Era-A Review. Remote Sens. 2024, 16, 327. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med. Image Comput. Comput. -Assist. Interv. 2015, 9351, 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision–ECCV 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y.; Liu, D.; Mu, Y.D.; Tan, M.K.; Wang, X.G.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Huang, J.F.; Zhang, X.C.; Xin, Q.C.; Sun, Y.; Zhang, P.C. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. Isprs J. Photogramm. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Ma, A.; Wang, J.; Zhong, Y.; Zheng, Z. FactSeg: Foreground Activation-Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, M.M.; Li, W.; Gao, Y.H.; Gui, Y.Y.; Zhang, Y.X. Unbalanced Class Learning Network With Scale-Adaptive Perception for Complicated Scene in Remote Sensing Images Segmentation. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7262–7272. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Xu, R.T.; Wang, C.W.; Zhang, J.G.; Xu, S.B.; Meng, W.L.; Zhang, X.P. RSSFormer: Foreground Saliency Enhancement for Remote Sensing Land-Cover Segmentation. IEEE Trans. Image Process. 2023, 32, 1052–1064. [Google Scholar] [CrossRef]
- Wang, L.B.; Li, R.; Wang, D.Z.; Duan, C.X.; Wang, T.; Meng, X.L. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Y.-B. Rest: An efficient transformer for visual recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 15475–15485. [Google Scholar] [CrossRef]
- Pang, Z.J.; Hu, R.M.; Zhu, W.; Zhu, R.Y.; Liao, Y.X.; Han, X.Y. A Building Extraction Method for High-Resolution Remote Sensing Images with Multiple Attentions and Parallel Encoders Combining Enhanced Spectral Information. Sensors 2024, 24, 1006. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Wang, L.; Li, D.; Dong, S.; Meng, X.; Zhang, X.; Hong, D. PyramidMamba: Rethinking Pyramid Feature Fusion with Selective Space State Model for Semantic Segmentation of Remote Sensing Imagery. arXiv 2024, arXiv:2406.10828. [Google Scholar]
- Chen, P.D.; Ren, Y.R.; Zhang, B.A.; Zhao, Y. Class Imbalance in the Automatic Interpretation of Remote Sensing Images: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2025, 18, 9483–9508. [Google Scholar] [CrossRef]
- Li, J.; Ding, W.; Li, H.; Liu, C. Semantic Segmentation for High-Resolution Aerial Imagery Using Multi-Skip Network and Markov Random Fields. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 12–17. [Google Scholar] [CrossRef]
- Bai, H.W.; Cheng, J.; Su, Y.Z.; Liu, S.Y.; Liu, X. Calibrated Focal Loss for Semantic Labeling of High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 6531–6547. [Google Scholar] [CrossRef]
- Hong, D.F.; Zhang, B.; Li, H.; Li, Y.X.; Yao, J.; Li, C.Y.; Werner, M.; Chanussot, J.; Zipf, A.; Zhu, X.X. Cross-city matters: A multimodal remote sensing benchmark dataset for cross-city semantic segmentation using high-resolution domain adaptation networks. Remote Sens. Environ. 2023, 299, 113856. [Google Scholar] [CrossRef]
- Xu, H.Z.; He, H.J.; Zhang, Y.; Ma, L.F.; Li, J.A.T. A comparative study of loss functions for road segmentation in remotely sensed road datasets. Int. J. Appl. Earth Obs. 2023, 116, 103159. [Google Scholar] [CrossRef]
- Farhadpour, S.; Warner, T.A.; Maxwell, A.E. Selecting and Interpreting Multiclass Loss and Accuracy Assessment Metrics for Classifications with Class Imbalance: Guidance and Best Practices. Remote Sens. 2024, 16, 533. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Q.; Wang, X.F.; Zhang, Q.C.; Kang, M.L.; Jiang, W.X.; Wang, M.Y.; Xu, L.X.; Zhang, C. Hybrid Attention Fusion Embedded in Transformer for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2024, 17, 4421–4435. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, F.K.; Zhao, J.Q.; Yao, R.; Chen, S.L.; Ma, H.P. Spatial-Temporal Based Multihead Self-Attention for Remote Sensing Image Change Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6615–6626. [Google Scholar] [CrossRef]
- Li, G.; Gao, Q.; Yang, M.; Gao, X. Active learning based on similarity level histogram and adaptive-scale sampling for very high resolution image classification. Neural Netw. 2023, 167, 22–35. [Google Scholar] [CrossRef] [PubMed]
- Lu, N.; Li, L.; Qin, J. PV Identifier: Extraction of small-scale distributed photovoltaics in complex environments from high spatial resolution remote sensing images. Appl. Energ. 2024, 365, 123311. [Google Scholar] [CrossRef]
- Chen, C.; Fan, L. Scene segmentation of remotely sensed images with data augmentation using U-net++. In Proceedings of the 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021; pp. 201–205. [Google Scholar] [CrossRef]
- Suo, Z.L.; Zhao, Y.B.; Chen, S.; Hu, Y.L. BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection. Remote Sens. 2022, 14, 5761. [Google Scholar] [CrossRef]
- Chen, B.Y.; Xia, M.; Qian, M.; Huang, J.Q. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, Y.W.; Xue, J.H. Adjusting the imbalance ratio by the dimensionality of imbalanced data. Pattern Recogn. Lett. 2020, 133, 217–223. [Google Scholar] [CrossRef]
- Lu, Y.; Cheung, Y.M.; Tang, Y.Y. Bayes Imbalance Impact Index: A Measure of Class Imbalanced Data Set for Classification Problem. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 3525–3539. [Google Scholar] [CrossRef]
- Liu, Y.C.; Lai, K.W.C. The Performance Index of Convolutional Neural Network-Based Classifiers in Class Imbalance Problem. Pattern Recogn. 2023, 137, 109284. [Google Scholar] [CrossRef]
- Zhao, S.J.; Chen, H.; Zhang, X.L.; Xiao, P.F.; Bai, L.; Ouyang, W.L. RS-Mamba for Large Remote Sensing Image Dense Prediction. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision–ECCV 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.Q.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10553, pp. 240–248. [Google Scholar] [CrossRef]
- Lee, C.Y.; Xie, S.N.; Gallagher, P.W.; Zhang, Z.Y.; Tu, Z.W. Deeply-Supervised Nets. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; Volume 38, pp. 562–570. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298. [Google Scholar] [CrossRef]
- Chen, P.D.; Liu, Y.; Liu, Y.; Ren, Y.R.; Zhang, B.A.; Gao, X.L. High-resolution feature pyramid attention network for high spatial resolution images land-cover classification in arid oasis zones. Int. J. Remote Sens. 2024, 45, 3664–3688. [Google Scholar] [CrossRef]
- Wang, L.B.; Li, R.; Zhang, C.; Fang, S.H.; Duan, C.X.; Meng, X.L.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.Y.; Zhang, C.; Duan, C.X.; Wang, L.B.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6881–6890. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AAFM | MCFM | IoU (%) | mIoU (%) | OA (%) | CV | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low. Veg. | Tree | Car | ||||||
| Baseline | ✘ | ✘ | 92.24 | 92.36 | 73.66 | 82.01 | 81.64 | 84.84 | 93.58 | 0.0492 |
| HRUMamba | ✔ | ✘ | 94.43 | 93.02 | 74.94 | 82.71 | 83.29 | 85.68 | 93.87 | 0.0458 |
| ✘ | ✔ | 94.73 | 93.14 | 74.90 | 82.59 | 83.49 | 85.77 | 93.96 | 0.0464 | |
| ✔ | ✔ | 94.48 | 92.79 | 75.22 | 82.94 | 83.99 | 85.88 | 93.92 | 0.0445 | |
| CM-UNet | - | - | 92.85 | 89.79 | 71.77 | 81.32 | 72.16 | 81.58 | 92.54 | 0.0590 |
| PyramidMamba | - | - | 92.49 | 88.74 | 69.89 | 80.14 | 70.86 | 80.40 | 92.00 | 0.0632 |
| CEL | FL | DL | IoU (%) | mIoU (%) | OA (%) | CV | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low. Veg. | Tree | Car | ||||||
| ✔ | ✘ | ✘ | 94.60 | 93.00 | 74.88 | 82.73 | 81.15 | 85.47 | 93.91 | 0.0467 |
| ✔ | ✔ | ✘ | 94.32 | 92.73 | 75.18 | 82.70 | 82.38 | 85.46 | 93.82 | 0.0453 |
| ✔ | ✘ | ✔ | 94.48 | 92.79 | 75.22 | 82.94 | 83.99 | 85.88 | 93.92 | 0.0445 |
| ✔ | ✔ | ✔ | 94.41 | 92.98 | 74.61 | 82.41 | 84.51 | 85.71 | 93.79 | 0.0463 |
| Auxiliary Loss | IoU (%) | mIoU (%) | OA (%) | CV | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low. Veg. | Tree | Car | ||||
| without | 94.40 | 92.85 | 74.16 | 82.41 | 82.46 | 85.26 | 93.73 | 0.0478 |
| with | 94.48 | 92.79 | 75.22 | 82.94 | 83.99 | 85.88 | 93.92 | 0.0445 |
| Data Augmentation | IoU (%) | mIoU (%) | OA (%) | CV | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low. Veg. | Tree | Car | ||||
| without | 94.01 | 91.97 | 74.82 | 82.75 | 78.14 | 84.34 | 93.56 | 0.0484 |
| with | 94.48 | 92.79 | 75.22 | 82.94 | 83.99 | 85.88 | 93.92 | 0.0445 |
| Models | Backbone | F1 (%) | mF1 (%) | CV | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low. Veg. | Tree | Car | ||||
| FCN | ResNet18 | 95.03 | 92.30 | 80.75 | 88.28 | 66.72 | 84.61 | 0.1201 |
| UNet | - | 96.30 | 93.54 | 82.07 | 88.77 | 85.22 | 89.18 | 0.0585 |
| DeepLabv3+ | ResNet18 | 95.47 | 92.11 | 79.80 | 88.27 | 79.42 | 87.01 | 0.0743 |
| GRRNet | ResNet18 | 95.34 | 92.50 | 80.67 | 88.47 | 79.44 | 87.28 | 0.0722 |
| ASPP+-LANet | - | 96.04 | 93.52 | 81.84 | 88.74 | 77.87 | 87.60 | 0.0783 |
| ABCNet | ResNet18 | 96.47 | 95.12 | 83.88 | 90.15 | 79.95 | 89.11 | 0.0714 |
| Segmenter | ViT-Base | 90.47 | 84.04 | 69.58 | 77.72 | 21.80 | 68.72 | 0.3559 |
| SETR | ViT-Base | 92.76 | 89.29 | 75.68 | 83.02 | 35.09 | 75.17 | 0.2776 |
| Swin Transformer | Swin-Base | 90.94 | 85.93 | 70.10 | 77.45 | 13.29 | 67.54 | 0.4153 |
| BANet | ResT-Base | 96.45 | 95.04 | 83.85 | 89.75 | 86.27 | 90.27 | 0.0539 |
| TransUNet | ResNet18 | 96.51 | 94.34 | 83.98 | 89.98 | 87.15 | 90.39 | 0.0507 |
| MarsNet | ResNet18 | 96.59 | 95.31 | 83.85 | 89.84 | 81.84 | 89.48 | 0.0661 |
| UNetFormer | ResNet18 | 96.51 | 94.59 | 83.81 | 89.90 | 85.12 | 89.99 | 0.0557 |
| CM-UNet | ResNet18 | 96.29 | 94.62 | 83.56 | 89.70 | 83.83 | 89.60 | 0.0590 |
| PyramidMamba | ResNet18 | 96.10 | 94.03 | 82.28 | 88.98 | 82.94 | 88.87 | 0.0632 |
| HRUMamba | HRNet-W64 | 97.16 | 96.26 | 85.86 | 90.67 | 91.30 | 92.25 | 0.0445 |
| Models | Backbone | F1 (%) | mF1 (%) | CV | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Farmland | Garden-land | Woodland | Grassland | Building | Road | Art.stru. | Art.exca. | Bare-land | Water | ||||
| FCN | ResNet18 | 92.05 | 61.68 | 94.80 | 70.88 | 83.28 | 47.54 | 72.16 | 69.68 | 90.89 | 90.22 | 75.88 | 0.1904 |
| UNet | - | 94.51 | 73.43 | 96.09 | 79.54 | 89.82 | 69.75 | 79.44 | 77.10 | 92.67 | 94.44 | 83.59 | 0.1103 |
| DeepLabv3+ | ResNet18 | 92.97 | 65.83 | 95.20 | 74.10 | 85.14 | 59.26 | 72.44 | 69.99 | 91.50 | 92.85 | 78.49 | 0.1556 |
| GRRNet | ResNet18 | 91.60 | 53.40 | 94.44 | 67.54 | 85.04 | 50.79 | 71.02 | 56.84 | 90.61 | 90.96 | 73.47 | 0.2187 |
| ASPP+-LANet | ResNet18 | 95.20 | 80.31 | 96.62 | 83.09 | 87.76 | 66.00 | 79.21 | 80.99 | 93.67 | 94.15 | 84.76 | 0.1067 |
| ABCNet | ResNet18 | 95.25 | 77.83 | 96.60 | 82.44 | 89.21 | 68.30 | 79.17 | 77.27 | 93.69 | 94.65 | 84.42 | 0.1082 |
| Segmenter | ViT-Base | 94.31 | 79.56 | 96.24 | 80.63 | 82.71 | 48.21 | 76.64 | 80.75 | 93.08 | 91.18 | 81.35 | 0.1602 |
| SETR | ViT-Base | 95.41 | 80.62 | 96.69 | 83.58 | 87.71 | 72.08 | 81.26 | 83.16 | 93.59 | 94.65 | 86.01 | 0.0884 |
| Swin Transformer | Swin-Base | 91.78 | 63.62 | 94.71 | 70.73 | 77.11 | 33.41 | 68.16 | 64.48 | 91.04 | 89.54 | 72.78 | 0.2393 |
| BANet | ResT-Base | 95.84 | 80.03 | 96.94 | 85.26 | 90.56 | 74.04 | 82.71 | 84.11 | 93.93 | 95.35 | 87.06 | 0.0841 |
| TransUNet | ResNet18 | 94.13 | 71.13 | 95.91 | 78.16 | 88.61 | 66.45 | 77.63 | 76.03 | 92.50 | 94.31 | 82.28 | 0.1229 |
| MarsNet | ResNet18 | 93.16 | 65.39 | 95.29 | 73.52 | 84.57 | 54.15 | 71.41 | 60.91 | 91.63 | 92.15 | 76.67 | 0.1826 |
| UNetFormer | ResNet18 | 93.68 | 72.00 | 95.43 | 76.04 | 89.07 | 69.30 | 76.96 | 76.50 | 91.65 | 94.38 | 82.29 | 0.1163 |
| CM-UNet | ResNet18 | 93.35 | 69.00 | 95.40 | 75.48 | 89.04 | 69.37 | 77.07 | 76.82 | 91.59 | 94.30 | 81.90 | 0.1209 |
| PyramidMamba | ResNet18 | 90.00 | 46.95 | 93.47 | 63.89 | 82.28 | 52.11 | 68.88 | 0.00 | 89.58 | 91.74 | 65.24 | 0.4088 |
| HRUMamba | HRNet-W64 | 96.28 | 85.65 | 97.22 | 86.51 | 92.85 | 82.75 | 86.36 | 86.69 | 94.60 | 96.65 | 89.88 | 0.0574 |
| Model | Backbone | Memory (MB)↓ | Parameters (M)↓ | FLOPs (G)↓ | Speed (FPS)↑ | mIoU (%)↑ | mF1 (%)↑ |
|---|---|---|---|---|---|---|---|
| ABCNet | ResNet18 | 143.58 | 13.39 | 3.91 | 159.51 | 80.95/74.13 | 89.11/84.42 |
| Segmenter | ViT-Base | 575.2 | 100.41 | 19.84 | 87.28 | 56.84/70.53 | 68.72/81.35 |
| SETR | ViT-Base | 715.44 | 89.20 | 31.17 | 110.56 | 64.06/76.24 | 75.17/86.01 |
| BANet | ResNet18 | 172.22 | 12.73 | 3.26 | 67.71 | 82.63/77.80 | 90.27/87.06 |
| CM-UNet | ResNet18 | 184.31 | 13.55 | 3.17 | 32.47 | 81.54/70.55 | 89.60/81.90 |
| HRUMamba | HRNet-W64 | 1002.19 | 127.13 | 40.00 | 12.08 | 85.88/82.00 | 92.25/89.88 |
| Method | Vaihingen | Minqin | ||
|---|---|---|---|---|
| IR | CV | IR | CV | |
| FCN | 26.5090 | 0.1201 | 396.0737 | 0.1904 |
| UNet | 24.2557 | 0.0585 | 362.7687 | 0.1103 |
| DeepLabv3+ | 27.8198 | 0.0743 | 356.5263 | 0.1556 |
| GRRNet | 21.8609 | 0.0722 | 377.3161 | 0.2187 |
| ASPP+-LANet | 25.2652 | 0.0783 | 338.1965 | 0.1067 |
| ABCNet | 28.7576 | 0.0714 | 359.7662 | 0.1082 |
| Segmenter | 43.3246 | 0.3559 | 377.0061 | 0.1602 |
| SETR | 35.5411 | 0.2776 | 368.5480 | 0.0884 |
| Swin Transformer | 144.7144 | 0.4153 | 428.2575 | 0.2393 |
| BANet | 26.1861 | 0.0539 | 367.1701 | 0.0841 |
| TransUNet | 23.0094 | 0.0507 | 378.8140 | 0.1229 |
| MarsNet | 28.0908 | 0.0661 | 401.5529 | 0.1826 |
| UNetFormer | 25.3069 | 0.0557 | 324.9179 | 0.1163 |
| CM-UNet | 23.6591 | 0.0590 | 339.4628 | 0.1209 |
| PyramidMamba | 24.7307 | 0.0632 | 135.0756 | 0.4088 |
| HRUMamba | 23.9342 | 0.0445 | 312.1325 | 0.0574 |
| Test set benchmark IR values | 21.7113 | 310.3823 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Liu, Y.; Ren, Y.; Zhang, B.; Zhao, Y. A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification. Remote Sens. 2025, 17, 1845. https://doi.org/10.3390/rs17111845
Chen P, Liu Y, Ren Y, Zhang B, Zhao Y. A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification. Remote Sensing. 2025; 17(11):1845. https://doi.org/10.3390/rs17111845
Chicago/Turabian StyleChen, Pengdi, Yong Liu, Yuanrui Ren, Baoan Zhang, and Yuan Zhao. 2025. "A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification" Remote Sensing 17, no. 11: 1845. https://doi.org/10.3390/rs17111845
APA StyleChen, P., Liu, Y., Ren, Y., Zhang, B., & Zhao, Y. (2025). A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification. Remote Sensing, 17(11), 1845. https://doi.org/10.3390/rs17111845