3.1. RS-FeatFuseNet
As shown in
Figure 2, YOLOv8’s backbone section serves as the main network for feature extraction. The neck section is in charge of fusing and optimizing the features extracted by the backbone while also playing a dual role in feature extraction and enhancement. The head section utilizes the feature information extracted in the preceding steps to predict the class and location of objects.
We made three main enhancements to the YOLOv8 model. First of all, we introduced the ESHA module before the large detection head. The large detection head typically handles larger-scale objects, and introducing this module at this stage helps the model better understand semantic information in the images, enhancing its perception of global information. We replaced Conv module in the C2f part of the neck section with the Parallel Feature Enhancement Module (PFEM) to create a new C2f, enhancing feature extraction and fusion capabilities. Additionally, we improved the loss function to make the model pay more attention to objects that are harder to detect, thus increasing the detection accuracy.
Table 1 shows the structure of our RS-FeatFuseNet. The ‘Index’ is used to uniquely identify each layer in the neural network structure, providing a clear identification of the network’s hierarchical layout. The ‘Module’ indicates the specific module employed by each layer, aiding in understanding the function and purpose of each layer. ‘From’ displays the input source for each layer, where −1 signifies that the layer directly receives the output from the previous layer. N is used to denote the number of repeated modules. The ‘Argvs’ column contains lists of different parameters with specific meanings depending on each module type: ‘Conv’ layers include the input channel number, output channel number, kernel size, and stride. Only the fourth item of the ‘C2f’ layer is different from that of the ‘Conv’ layer, and it represents whether bias is used (‘True’ indicates the use of bias); SPPF layers include the input channel number, output channel number, and pool size; ‘Upsample’ layers include ‘None’ (it indicates no additional input is required), the upsampling factor, and the upsampling method (e.g., ‘nearest’); ‘Concat’ layers comprise a list of connected layer indices; the ‘Improved_C2f’ layer is the same as the ‘C2f’ layer except that the former does not have the fourth item; ‘ESHA’ layers include the input channel number and output channel number; ‘Detect’ layers include lists of input feature map indices and output channel numbers. ‘Parameters’ represent the number of parameters for each layer.
3.2. Efficient Multi-Scales and Multi-Head Attention
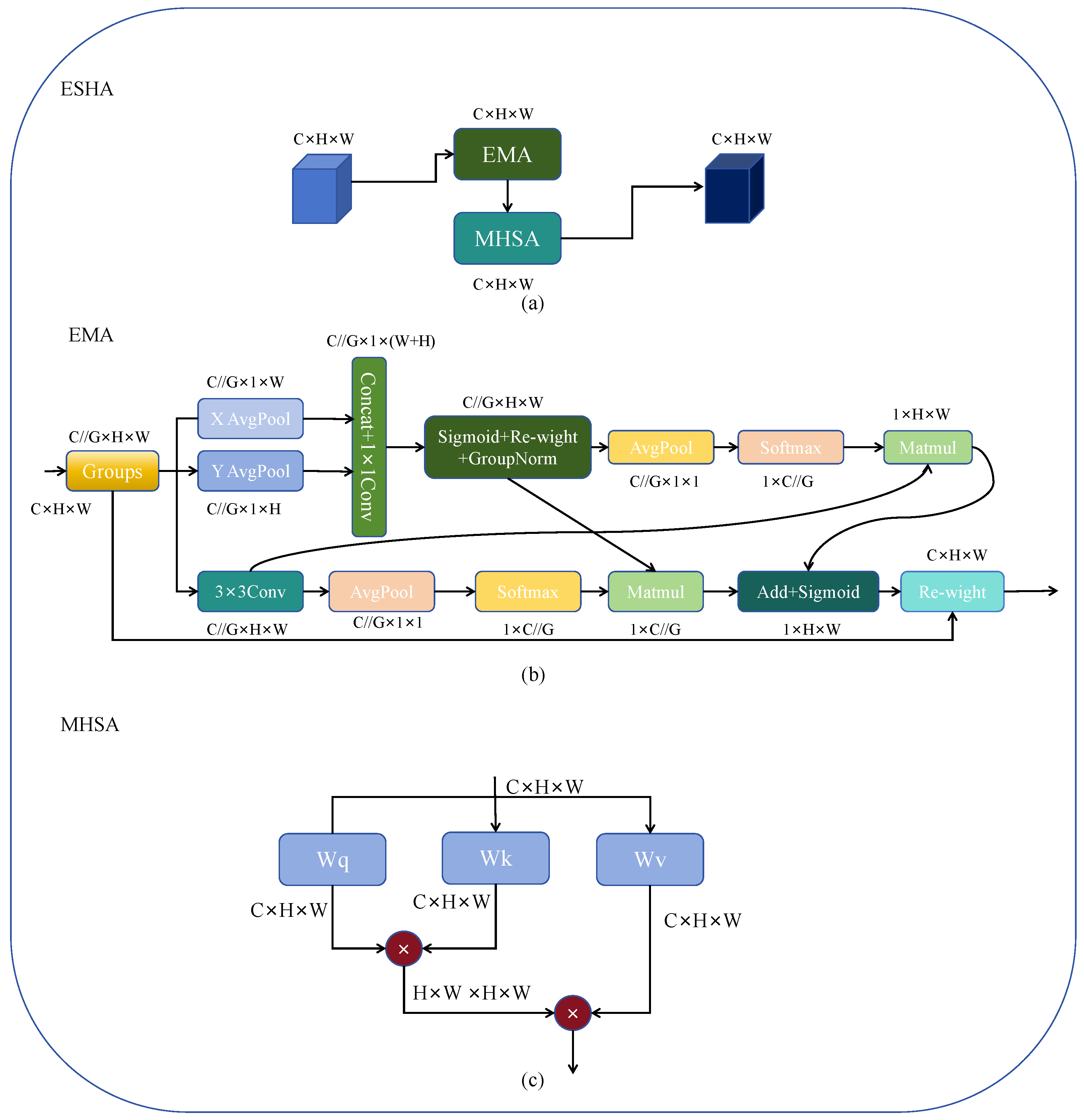
Remote sensing images often contain complex backgrounds and varied scales. Compared to natural images, a remote sensing image demands more detailed information to exclude noise interference and concurrently requires a larger receptive field to assist in detection. A detector relying solely on a CNN architecture would struggle to extract global information effectively due to the constraints of kernel size. To address this issue, we developed the ESHA module, as illustrated in
Figure 3a. The module employs Efficient Multi-Scale Attention Module with Cross-Spatial Learning (EMA) [
8] as a cross-space multi-scale attention mechanism for initial local multi-scale attention extraction. The cross-spatial learning and multi-scale attention in the EMA module enable it to achieve good detection performance of different scales. It then integrates an enhanced MHSA to extract global features.
The structure of EMA is depicted in
Figure 3b. EMA processes input feature maps using
and
branches in parallel. The
branch conducts global average pooling along the horizontal and vertical dimensions, which is followed by ‘Concat’ and channel adjustment through
. The output is subjected to non-linear transformation using the ‘Sigmoid’ and channel fusion via Re-weight to facilitate information exchange between these two
branches. On the other hand, the
branch employs
‘Conv’ to facilitate local cross-channel interactions, thereby expanding the feature space. Subsequently, the re-weighted results from the
branch are subjected to GroupNorm, and the output conducts global average pooling and is processed through the ‘Softmax’ with the output of the
branch. The processed outputs of the
and
branches and the original
and
branches are subjected to ‘Matmul’ to achieve cross-space learning and fusion. Additionally, the branches of different scales excel in detecting objects of varied scales. By applying attention maps to the input features, the module ultimately achieves cross-space multi-scale feature attention extraction. Combining the two outputs further enhances feature information, followed by fitting through the ‘Sigmoid’, and ultimately re-weighting via the re-weight function to achieve cross-space multi-scale attention feature extraction.
After the EMA module, we added an MHSA to capture contextual information around the targets, aiding the model in further understanding the relationship between targets and backgrounds. In complex scenarios, MHSA can model spatial relationships between targets, assisting the model in better comprehending interactions and positional relationships among targets. It also possesses a degree of adaptability and flexibility, allowing for dynamic adjustments based on the characteristics of different scenes and targets, thereby accommodating detection requirements in diverse scenarios. Unlike the MHSA in the Transformer, since the position is already encoded in the EMA module, we delete the position information and remove the layer norm, dropout and Gelu operations in the MHSA in order to minimize computational demands.
We employ the feature map directly as input for self-attention, eliminating the embedding operation. The simplified multi-head self-attention module is depicted in
Figure 3c.
Its formula is represented by Equation (
1).
where
x represents input features, while
Q,
K, and
V denote the linear transformations of
x.
signifies the grouping operation,
h represents the number of attention heads, and
,
, and
refer to the
Q,
K,
V values of the
ith attention head. The term
denotes the softmax function, and
denotes the concatenation operation.
represents the feature dimension of
. The martix
symbolizes the output transformation matrix for mapping linear vectors back to the feature space.
represents the ultimate result or final output.
3.3. Parallel Feature Enhance Module
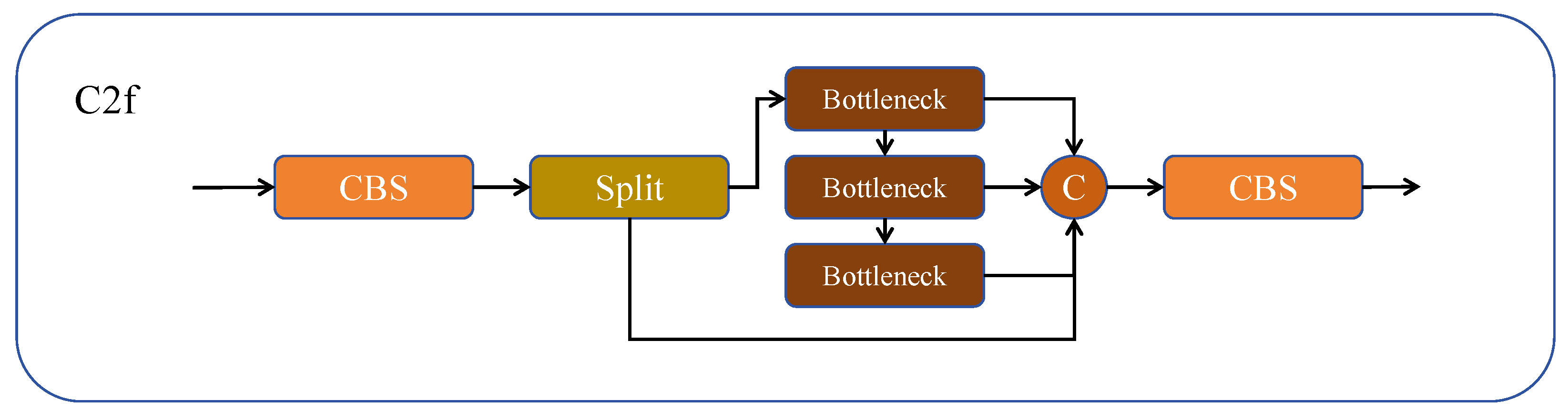
Remote sensing objects are typically smaller in scale and may have fewer distinguishable features. This necessitates more effective feature extraction and fusion modules to ensure accurate detection in remote sensing applications. While the C2f module functions as a critical feature fusion element within YOLOv8, specifically crafted to amalgamate feature maps from different scales, it may not suffice for detecting small objects in remote sensing images due to its limitations in feature extraction.
Figure 4 illustrates the C2f structure of YOLOv8. The input feature map is transformed via the initial CBS, generating an intermediate feature map. Subsequently, this map is then split into two parts: one part is inputted into a series of consecutive bottleneck modules for processing, while the other part of the feature map is concatenated in the Concat module, forming a fused feature map. The concatenated feature map then undergoes processing through the second convolutional layer to obtain the ultimate output feature map.
We have primarily improved the bottleneck section in C2f. As illustrated in
Figure 5a, we substituted the first part of the bottleneck with the Parallel Feature Enhancement Module (PFEM). The detailed structure of the PFEM is shown in
Figure 5b. This design enables the network to extract diverse and rich features from different paths simultaneously. By integrating and enhancing features through operations like ‘Sigmoid’ for feature integration and adjustment, coupled with the ‘SiLU’ for refinement and enhancement, the network effectively captures and represents critical information in the data. This process enhances the network’s feature representation capability and learning effectiveness, leading to improved object recognition and localization in object detection tasks. Initially, 1 × 1 convolutions and 3 × 3 convolutions are employed to extract two different scales and complexities of information from the original features. The original features are then subjected to average pooling, max pooling operations, and the ‘Sigmoid’ function to learn feature importance. The output is multiplied with the original features to enhance the features. Subsequently, different levels of feature information are fused to acquire a more diverse third feature representation. The three types of features are element-wise added to achieve fusion of different kinds of features, enhancing feature diversity and representational capacity. Finally, the integrated features undergo non-linear transformation via the ‘SiLU’ activation function to enhance their representational capacity. Equation (
2) demonstrates the calculation process of the PFEM.
where
x represents the input,
represents the
convolution; similarly,
represents the
convolution.
represent the global average pooling, and the
denotes global maximum pooling operations. The
activation function is used for processing.
is the final output.
3.4. Loss Function
The training process involves comparing ground truth with predicted results and optimizing them by adjusting the network parameters through gradient backpropagation. The loss function of YOLOv8 consists of two parts: classification loss and regression loss.
To determine the detected category and produce the confidence output, the classification loss function utilizes VFL loss. For multiple classifications, the formula is Equation (
3).
i represents the ith detection object, varying from 1 to N, where N stands for the total number of detection objects. M indicates the number of categories. takes binary values of 0 or 1, with 1 indicating the true category of sample i as c and 0 otherwise. represents the predicted probability that observation sample i belongs to category c.
In regression scenarios, the regression loss is employed to measure the degree of intersection between bounding boxes. This measure usually involves comparing the regression of boxes by comparing the ratio of the object box to the predicted box.
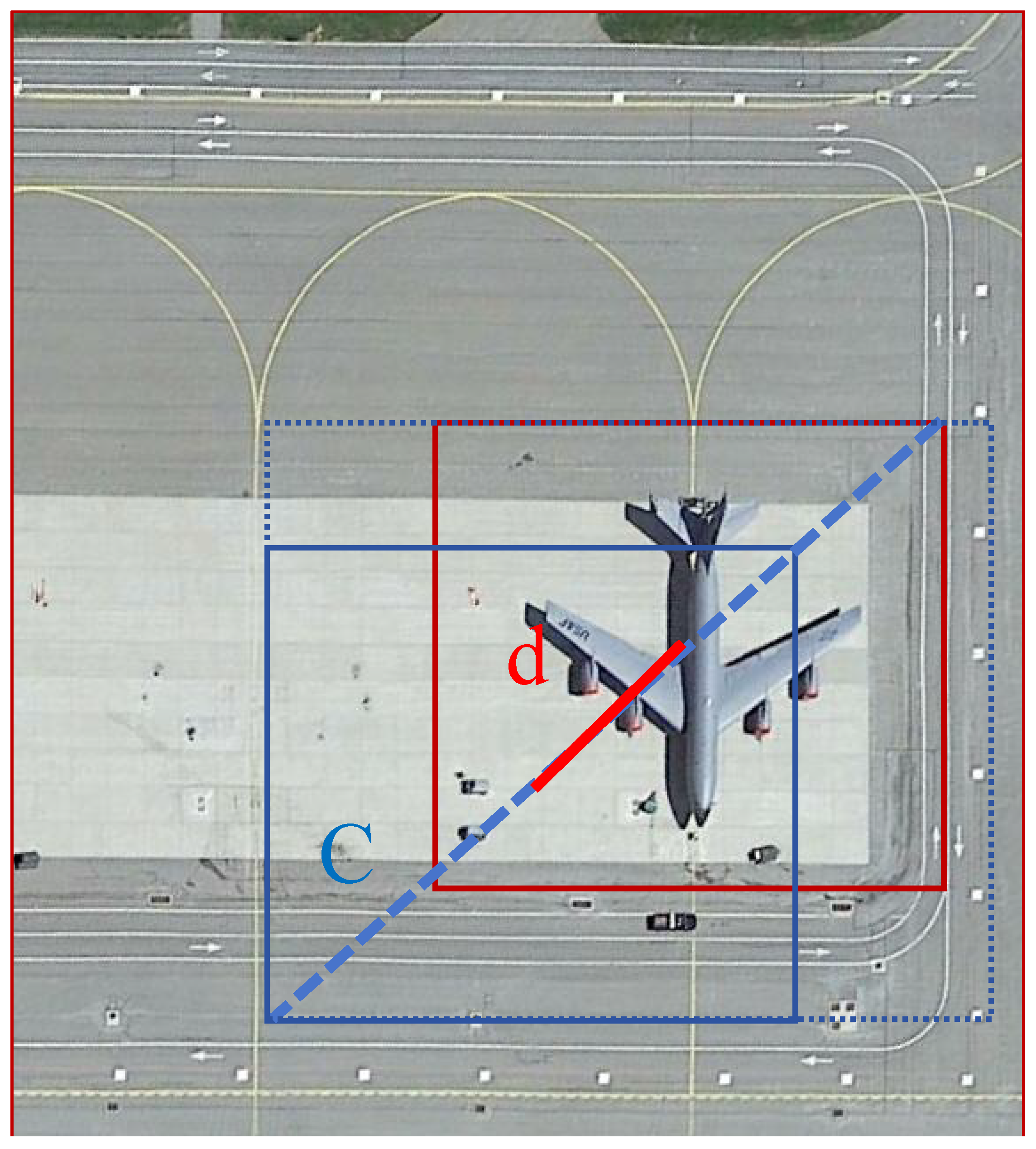
The principle of IoU is depicted in
Figure 6 to visually illustrate this concept.
In contrast to IoU,
additionally incorporates the distance between the centroids of the actual and predicted boxes (denoted as ‘d’) and the diagonal distance between the minimum enclosing rectangles of the two boxes (indicated as ‘c’ in
Figure 7).
For instance, in scenarios where two boxes exhibit no overlap, resulting in an IoU value of 0, a traditional IoU may hinder backpropagation. serves as an effective solution to this challenge by considering additional spatial information, thereby facilitating robust optimization even in cases of non-overlapping boxes.
The specific formula for
is Equation (
4):
The Complete Intersection over Union () formula assesses the similarity between two bounding boxes. It comprises the Intersection over Union () term, representing the overlap between these boxes, adjusted by the term , where denotes the Euclidean distance between the centers of the predicted bounding box b and the ground truth bounding box , and c denotes the diagonal length of the bounding boxes. Additionally, is employed to assess aspect ratio’s consistency between the predicted bounding box dimensions w and h and the ground truth dimensions and . The coefficient modulates the influence of the aspect ratio term relative to the term within the computation.
However, a notable issue with
is its limited ability to effectively balance the difficulty levels of samples within detection boxes. Therefore, we introduce
to enhance
.
represents an enhanced variant the cross-entropy loss function, which is designed to hadle class imbalances in binary classification problems, with its formulation illustrated in Equation (
5).
In this loss function, represents the function tailored to mitigate class imbalance challenges, where y signifies the true label of a sample, p denotes the model’s predicted probability for that class, and acts as a parameter modulating the impact of the focusing mechanism. The terms and dynamically adjust the loss computation by de-emphasizing well-classified instances and amplifying the contribution of challenging samples, thus enhancing the model’s focus on harder-to-classify examples.
FocalL1 loss is inspired by the concept of but is tailored to address imbalances in regression tasks. In the domin of object detection, we regard the disparity between high and low-quality samples as a significant factor affecting model convergence. In object detection scenarios, a majority of predicted boxes derived from anchor points exhibit relatively low with the ground truth, categorizing them as low-quality samples. Training on these low-quality samples can result in significant fluctuations in loss. FocalL1 aims to solve the class imbalance issue between high and low-quality samples.
In this study, By introducing the idea of
, we use the adjustment factor gamma to adjust the loss weights, and thus obtain a new loss function named
, which is represented as Equation (
6).
The formula combines the metrics and . By raising the value of to the power of and multiplying it with , the formula adjusts the weight of to be influenced by , providing a more nuanced assessment of the similarity between two bounding boxes in object detection tasks. The parameter serves as a tuning factor that controls the influence of the and metric. A higher value of will amplify the effect of on the final metric, while a lower value will reduce its impact. This formulation helps to more comprehensively consider two different evaluation metrics when evaluating the performance of object detection algorithms.



 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}