



Enhancing Binary Change Detection in Hyperspectral Images Using an Efficient Dimensionality Reduction Technique Within Adversarial Learning


Abstract
1. Introduction
1.1. Traditional vs. Deep Learning Approaches in Hyperspectral Change Detection
1.2. Generative Adversarial Networks in Remote Sensing: Advancements and Applications in Hyperspectral Change Detection
1.3. High-Dimensionality Challenge in Adversarial Learning for Hyperspectral Change Detection
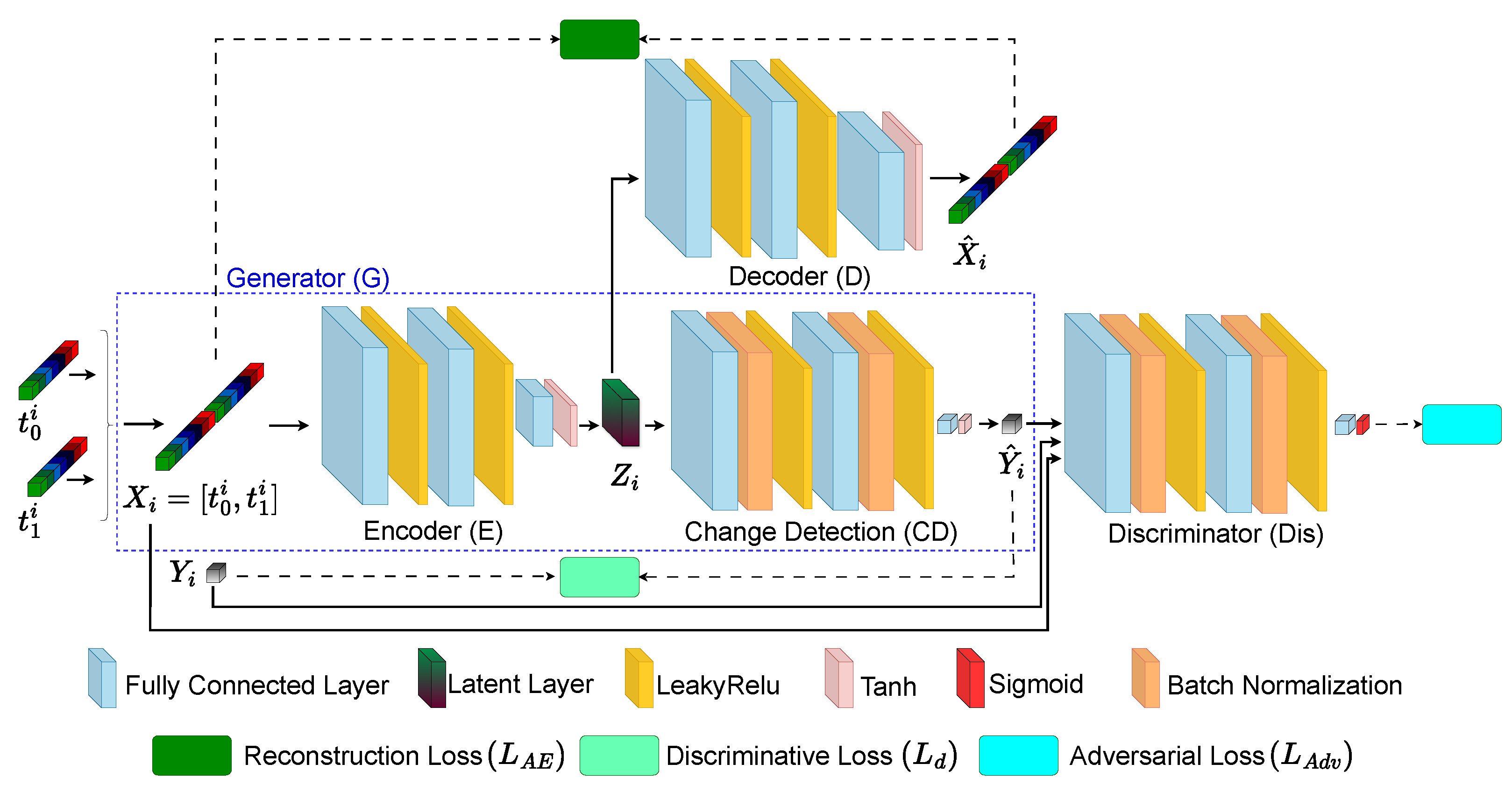
- This study proposes EFC-AdvNet, a novel end-to-end fully connected adversarial network for hyperspectral change detection. This network combines a self-spectral reconstruction (SSR) module with an adversarial change detection (Adv-CD) module to extract relevant spectral features and delineate changes between bitemporal HSIs.
- The proposed EFC-AdvNet employs an innovative joint learning by integrating the SSR module’s autoencoder for dimensionality reduction with the Adv-CD module’s change detection network. This synergy enables the direct generation of accurate change maps.
- In this study, we implement comprehensive training through a unified loss function derived from the concurrent learning of the SSR and Adv-CD modules. The experimental results on three public datasets demonstrate EFC-AdvNet’s superior performance compared with that of state-of-the-art methods.
2. Materials and Methods
2.1. Dataset Description
- Farmland dataset [37]: This dataset, which is also known as the China dataset, comprises bitemporal HSIs captured on 3 May 2006 () and 23 April 2007 (), over farmland in Yuncheng, Jiangsu, China. These images have a size of pixels with 155 spectral bands after the removal of noisy and water-absorbing bands. It primarily focuses on changes in crops and is suitable for surveys related to changes in cultivated land. Pseudo-color images utilizing bands 91, 103, and 123 are depicted in Figure 2a.
- Hermiston dataset [38]: This dataset, which is also known as the USA dataset, originates from an irrigated agricultural area in Hermiston, located in Umatilla County, Oregon, USA. The dataset was collected on two occasions: 1 May 2004 () and 8 May 2007 (). It encompasses a diverse landscape that includes a variety of irrigated fields, a river, and cultivated lands. The dataset images’ dimensions are pixels, and it includes 154 spectral bands. For visualization purposes, pseudo-color images that combine bands 91, 103, and 123 are presented in Figure 2b.
- River dataset [39]: This dataset consists of bitemporal HSIs captured on 3 May 2013 and 31 December 2013, in Jiangsu province, China. This dataset comprises images of pixels with 198 spectral bands after the removal of noisy bands. The primary focus of this dataset is on detecting the disappearance of substances in the river. Pseudo-color images that combine bands 30, 60, and 100 are presented in Figure 2c.
2.2. Methodology
2.2.1. Self-Spectral Reconstruction (SSR)
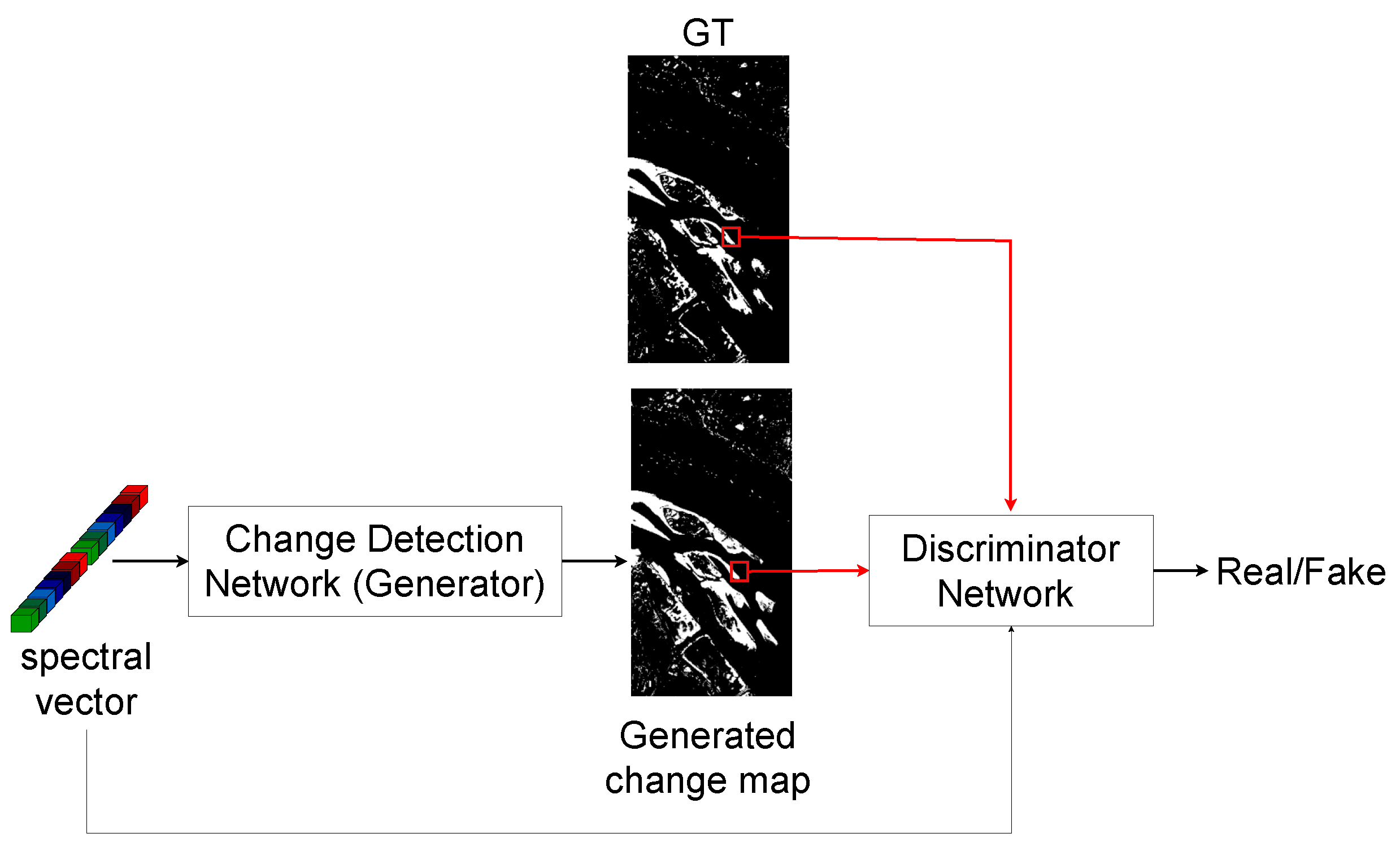
2.2.2. Adversarial Change Detection (Adv-CD) for Hyperspectral Images
2.2.3. Network Architecture
3. Experiments and Results
3.1. Experimental Setup
3.2. Evaluation
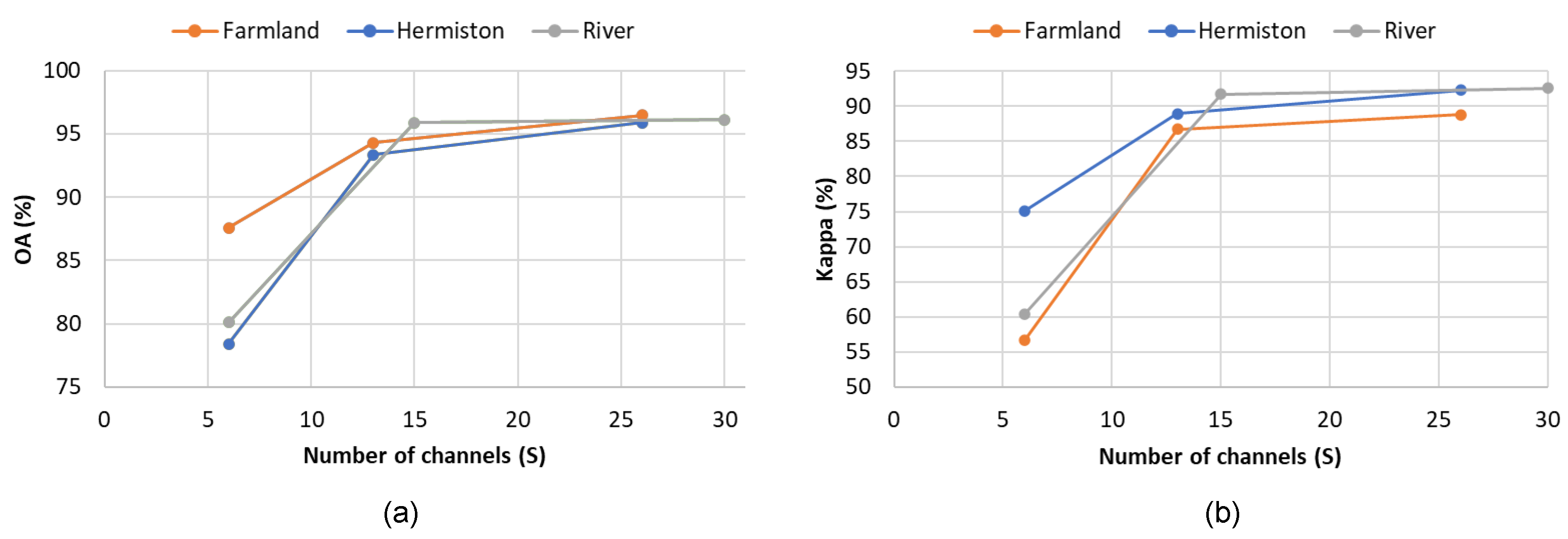
3.3. Tuning the Number of Channels in the Latent Feature Space
3.4. Comparison with State-of-the-Art Change Detection Methods in Hyperspectral Imaging
- Change vector analysis (CVA) [42]: CVA leverages spectral feature vectors from corresponding spatial positions in two images, representing spectral change vectors in polar coordinates with the magnitude and direction. Carvalho et al. introduced the spectral angle mapper (SAM) and spectral correlation mapper (SCM) to enhance the direction calculation in CVA.
- Anomaly change detection (ACD) [13]: ACD employs autoencoders to detect complex spectral differences in multitemporal HSIs. Siamese autoencoder networks construct predictors from different directions to model spectral variations, generating loss maps that highlight anomaly changes while suppressing unchanged pixel differences.
- General end-to-end 2D CNN (GETNET) [39]: GETNET introduces an end-to-end 2D convolutional neural network tailored for hyperspectral change detection tasks. It overcomes data limitations and the underutilization of deep learning features by utilizing a mixed-affinity matrix to capture changed patterns and enhance cross-channel gradient information.
- Self-supervised hyperspectral spatial–spectral feature understanding network (HyperNet) [43]: HyperNet integrates spatial and spectral attention branches to extract discriminative spatial and spectral information independently, and it merges them to generate comprehensive features. Trained using a self-supervised learning framework, HyperNet achieves pixel-level feature learning through similarity comparisons of multitemporal HSIs.
- Spectral–spatial–temporal transformers for hyperspectral image change detection (SST-Former) [11]: The SST-Former encodes each pixel to capture spectral and spatial sequences, employs a spectral transformer encoder for spectral information extraction, and utilizes a spatial transformer encoder for texture information.
- Spectral–temporal transformer for hyperspectral image change detection (STT) [10]: STT processes the HSI CD task from a sequential perspective by concatenating feature embeddings in spectral order, establishing a global spectrum–time-receptive field. Through a multi-head self-attention mechanism, the STT effectively captures spectral–temporal features.
- End-to-end cross-band 2D attention network for hyperspectral change detection (CBANet) [44]: By integrating a cross-band feature extraction module with a 2D spatial–spectral self-attention module, CBANet effectively extracts spectral differences between matching pixels while considering the correlation between adjacent pixels in remote sensing.
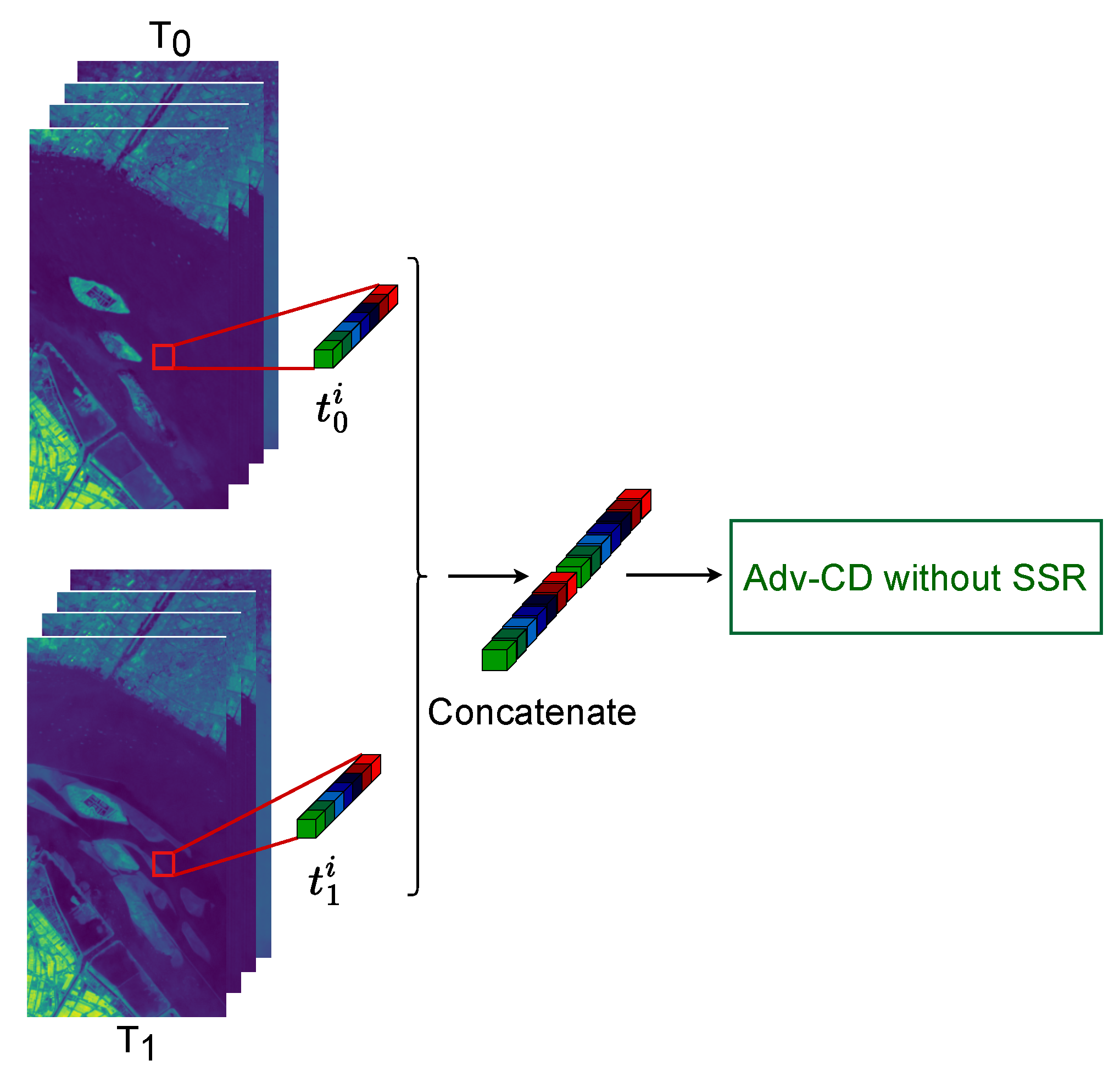
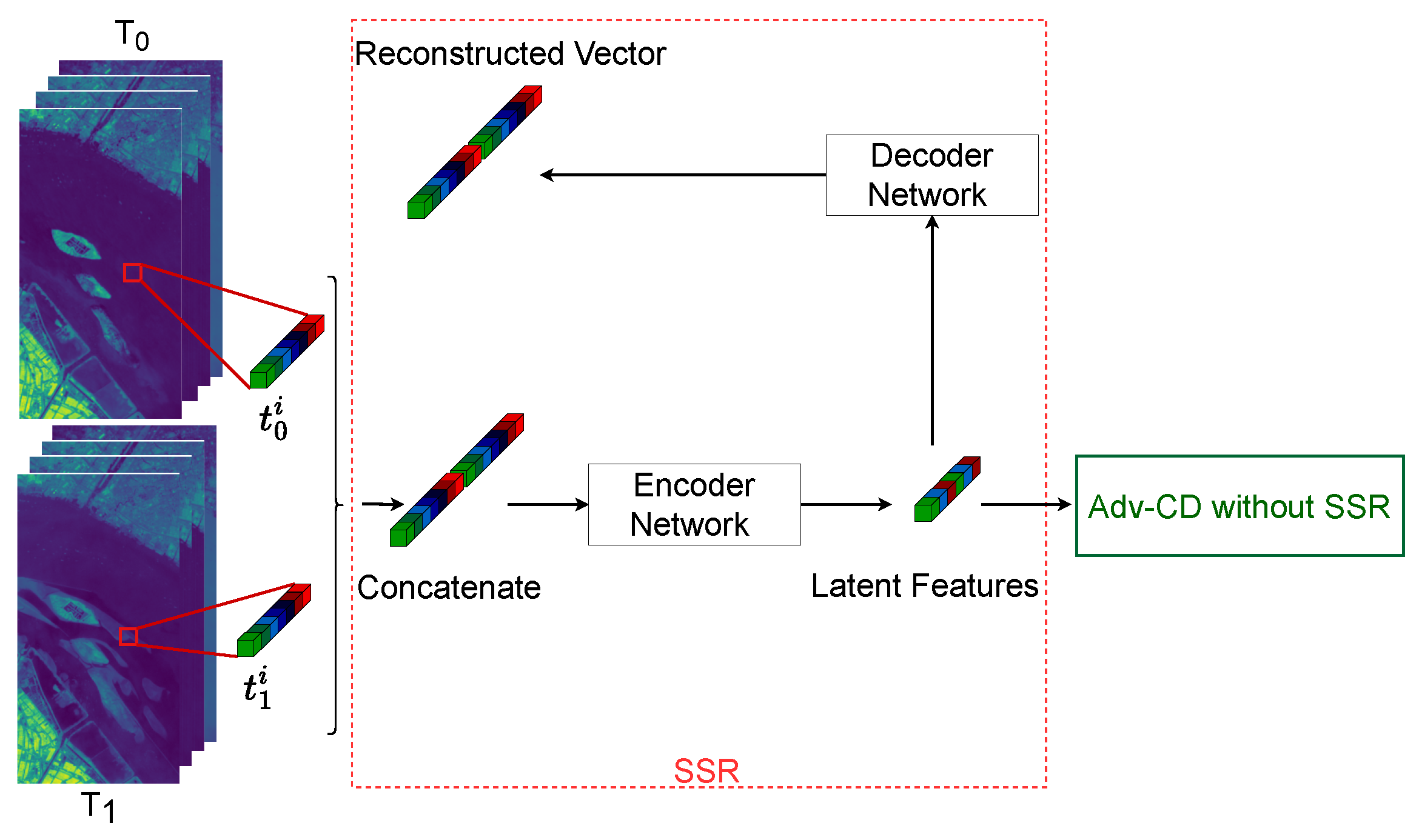
3.5. Ablation Study on the SSR Module
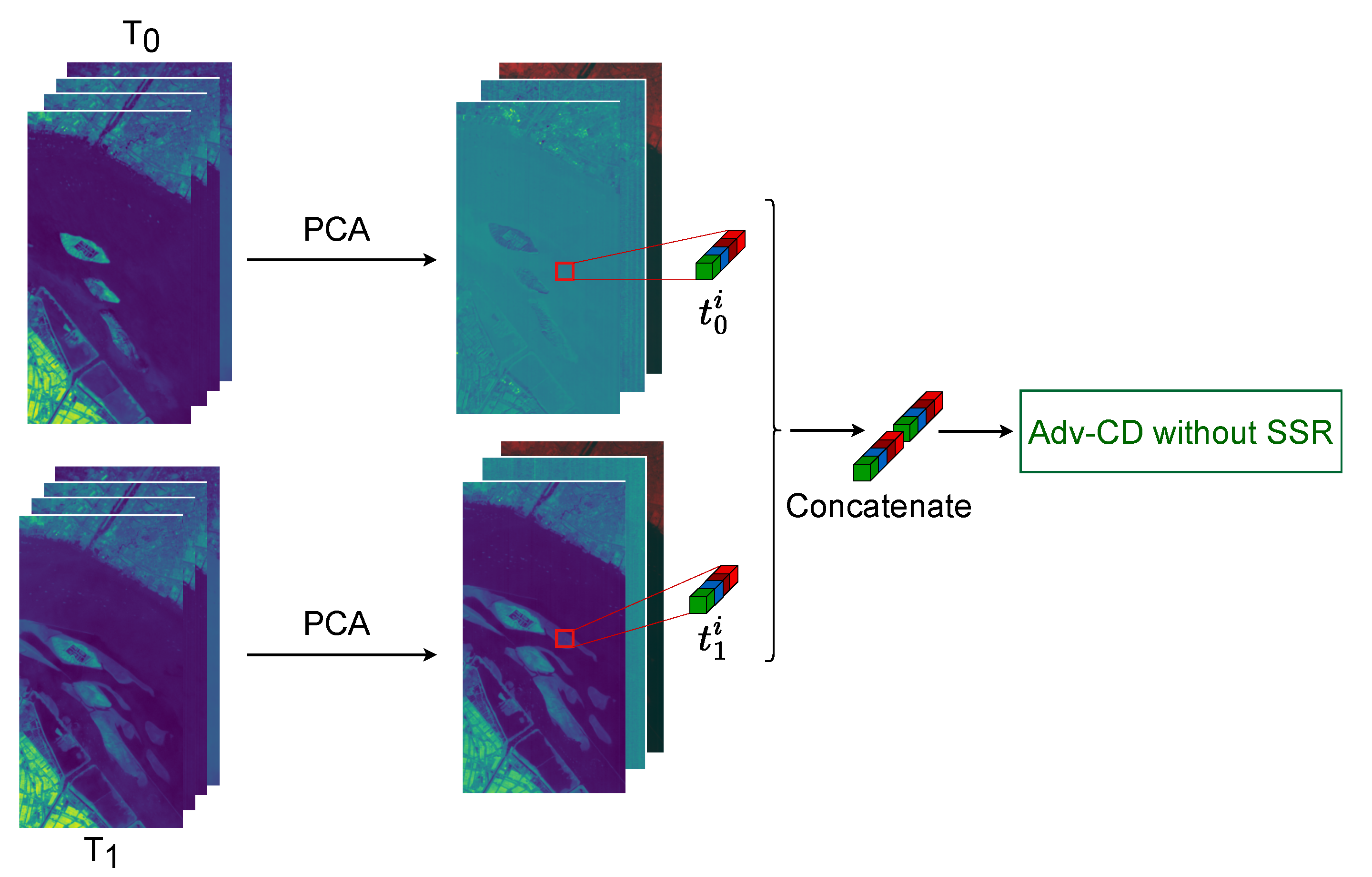
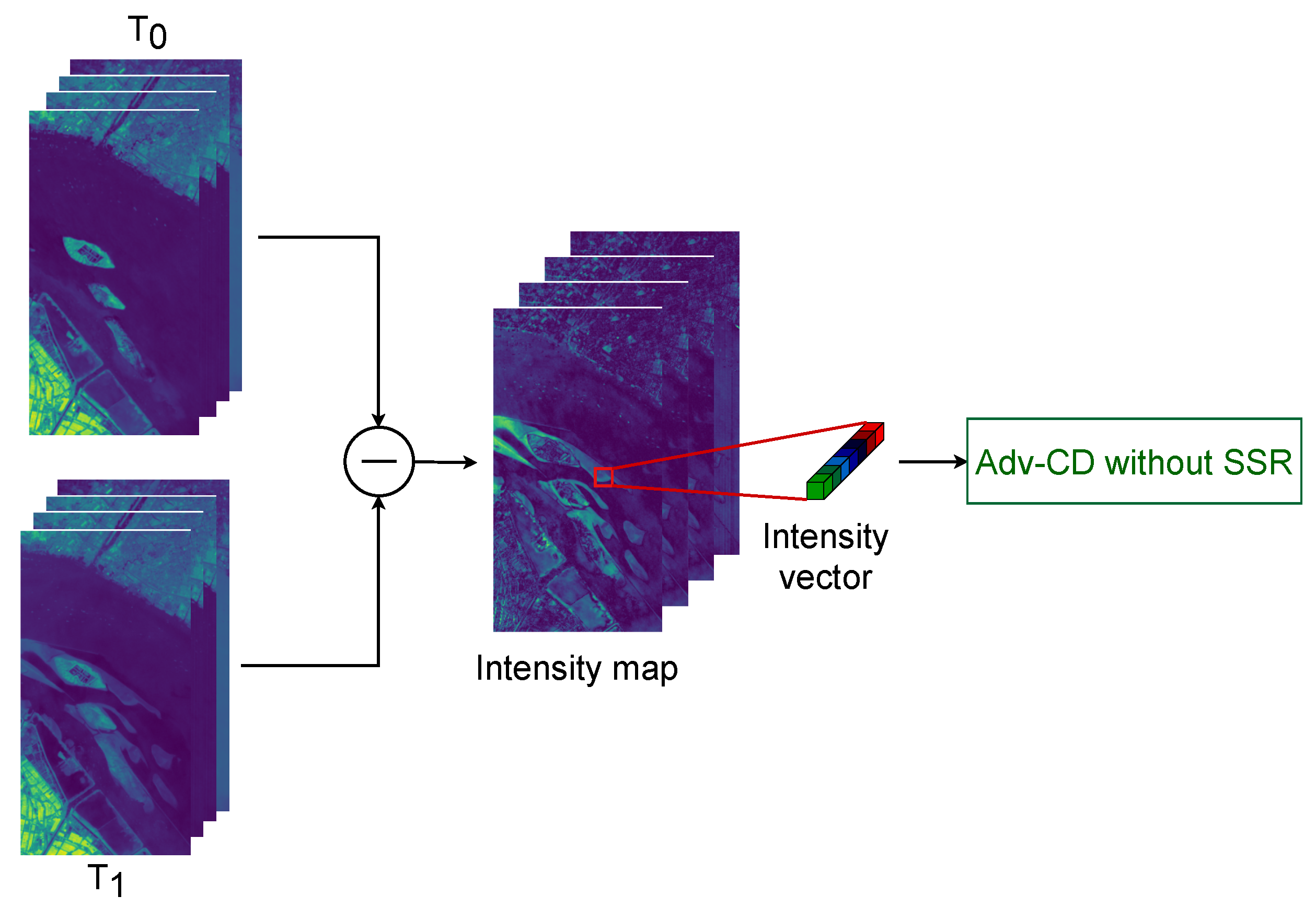
3.6. Comparative Analysis of Various Spectral Representation Methods
4. Discussion
- Feature selection and noise reduction: The encoder part of the SSR module effectively learns compressed representations of the data by encoding the most relevant features while discarding noise and redundant information. This process of dimensionality reduction helps isolate the essential features that are critical for detecting changes in HSIs, thereby improving the ability of the Adv-CD module to focus on significant differences between images.
- Improved generalization: The compressed representation learned by the SSR module can help the change detection model based on adversarial learning generalize better to unseen data by focusing on the underlying patterns and features that are most relevant for change detection. This can enhance EFC-AdvNet’s robustness and its ability to accurately detect changes across different environments and conditions.
- Enhanced learning capability: The resulting latent feature space from the encoder facilitates the learning process of the Adv-CD module by providing a more structured and simplified input space. This led to better convergence during training and improved performance in detecting subtle changes that might be missed in the high-dimensional raw data.
- Complexity: The total number of parameters in our model is approximately 4.45 MB for the River dataset, which has the highest number of channels among the datasets used. This relatively low parameter count indicates that our model is not overly complex. This simplicity enables efficient execution even on systems without dedicated GPU support. Moreover, our method employs a pixel-based approach, where the input is represented as a 1D vector. This design choice further simplifies the computations required, making them less resource-intensive than object-based methods. Object-based approaches often necessitate more complex processing due to their reliance on spatial relationships and larger input sizes, which can increase computational demands. Consequently, our model offers an efficient solution for hyperspectral change detection, making it accessible for a wider range of applications and hardware configurations.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACD | Anomaly Change Detection |
| Adv-CD | Adversarial Change Detection |
| c-GAN | Conditional Generative Adversarial Network |
| CBANet | Cross-Band 2D Attention Network |
| CD | Change Detection |
| CM | Change Map |
| CNN | Convolutional Neural Network |
| CVA | Change Vector Analysis |
| DI | Difference Image |
| DL | Deep Learning |
| EFC-AdvNet | End-to-End Fully Connected Adversarial Network |
| GAN | Generative Adversarial Network |
| GETNET | General End-to-End 2D CNN |
| HSI | Hyperspectral Image |
| HyperNet | Self-Supervised Hyperspectral Spatial-Spectral Feature Understanding Network |
| SSR | Self-Spectral Reconstruction |
| SST-Former | Spectral–Spatial–Temporal Transformers |
| STT | Spectral–Temporal Transformer |
References
- Alegavi, S.; Sedamkar, R. Research Trends in Hyperspectral Imagery Data. Int. J. Comput. Eng. Technol. 2019, 10, 67–73. [Google Scholar] [CrossRef]
- Hasanlou, M.; Seydi, S.T. Hyperspectral Change Detection: An Experimental Comparative Study. Int. J. Remote Sens. 2018, 39, 7029–7083. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Li, Z.; Li, D. A review of multi-class change detection for satellite remote sensing imagery. Geo-Spat. Inf. Sci. 2022, 27, 1–15. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A Theoretical Framework for Unsupervised Change Detection Based on Change Vector Analysis in the Polar Domain. IEEE Trans. Geosci. Remote Sens. 2007, 45, 218–236. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. PCA-based Land-use Change Detection and Analysis Using Multitemporal and Multisensor Satellite Data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi- and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Krinidis, S.; Chatzis, V. A Robust Fuzzy Local Information C-Means Clustering Algorithm. IEEE Trans. Image Process. 2010, 19, 1328–1337. [Google Scholar] [CrossRef]
- Yu, S.; Tao, C.; Zhang, G.; Xuan, Y.; Wang, X. Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks. Appl. Sci. 2024, 14, 6269. [Google Scholar] [CrossRef]
- Shammi, S.A.; Du, Q. Hyperspectral Image Change Detection Using Deep Learning and Band Expansion. In Proceedings of the 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022. [Google Scholar] [CrossRef]
- Li, X.; Ding, J. Spectral-Temporal Transformer for Hyperspectral Image Change Detection. Remote Sens. 2023, 15, 3561. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, D.; Sha, J.; Gao, L.; Liu, L.; Zhang, Y.; Rong, X. Spectral-Spatial-Temporal Transformers for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536814. [Google Scholar] [CrossRef]
- Chakraborty, D.; Ghosh, S.; Ghosh, A.; Ientilucci, E.J. Change Detection in Hyperspectral Images Using Deep Feature Extraction and Active Learning. In Neural Information Processing; Springer Nature: Singapore, 2023; pp. 212–223. [Google Scholar] [CrossRef]
- Hu, M.; Wu, C.; Zhang, L.; Du, B. Hyperspectral Anomaly Change Detection Based on Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3750–3762. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, X.; Ye, X.; Li, B. Dual Generative Adversarial Networks for Merging Ocean Transparency from Satellite Observations. GISci. Remote Sens. 2024, 61, 2356357. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, N.; Wang, B.; Liu, Y.; Zhang, S. Urban Building Extraction from High-resolution Remote Sensing Imagery Based on Multi-scale Recurrent Conditional Generative Adversarial Network. GISci. Remote Sens. 2022, 59, 861–884. [Google Scholar] [CrossRef]
- Liu, M.; Yang, M.; Deng, J.; Cheng, X.; Xie, T.; Deng, P.; Gong, H.; Liu, M.; Wang, X. Feature Equilibrium: An Adversarial Training Method to Improve Representation Learning. Int. J. Comput. Intell. Syst. 2023, 16, 63. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Y.; Luo, L.; Wang, N. CSA-CDGAN: Channel self-attention-based generative adversarial network for change detection of remote sensing images. Neural Comput. Appl. 2022, 34, 21999–22013. [Google Scholar] [CrossRef]
- Yu, W.; Niu, S.; Gao, X.; Liu, K.; Dong, J. Generative Adversarial Networks and Spatial Uncertainty Sample Selection Strategy for Hyperspectral Image Classification. In Proceedings of the Fourteenth International Conference on Graphics and Image Processing (ICGIP 2022), Nanjing, China, 21–23 October 2023. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Su, L.; Sui, Y.; Yuan, Y. An Unmixing-Based Multi-Attention GAN for Unsupervised Hyperspectral and Multispectral Image Fusion. Remote Sens. 2023, 15, 936. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, J.; Lei, J.; Li, Y.; Jia, X. Self-spectral Learning with GAN Based Spectral-Spatial Target Detection for Hyperspectral Image. Neural Netw. 2021, 142, 375–387. [Google Scholar] [CrossRef]
- Gong, M.; Gao, T.; Zhang, M.; Li, W.; Wang, Z.; Li, D. An M-Nary SAR Image Change Detection Based on GAN Architecture Search. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4503718. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Fully Convolutional Change Detection Framework With Generative Adversarial Network for Unsupervised, Weakly Supervised and Regional Supervised Change Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9774–9788. [Google Scholar] [CrossRef]
- Oubara, A.; Wu, F.; Maleki, R.; Ma, B.; Amamra, A.; Yang, G. Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism. ISPRS Int. J. Geo-Inf. 2024, 13, 125. [Google Scholar] [CrossRef]
- Lei, J.; Li, M.; Xie, W.; Li, Y.; Jia, X. Spectral Mapping with Adversarial Learning for Unsupervised Hyperspectral Change Detection. Neurocomputing 2021, 465, 71–83. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Yang, Q.; Tang, J. Adaptive Self-Paced Collaborative and 3-D Adversarial Multitask Network for Semantic Change Detection Using Zhuhai-1 Orbita Hyperspectral Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2777–2788. [Google Scholar] [CrossRef]
- Gong, M.; Niu, X.; Zhang, P.; Li, Z. Generative Adversarial Networks for Change Detection in Multispectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2310–2314. [Google Scholar] [CrossRef]
- Wu, Y.; Bai, Z.; Miao, Q.; Ma, W.; Yang, Y.; Gong, M. A Classified Adversarial Network for Multi-Spectral Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 2098. [Google Scholar] [CrossRef]
- Wang, J.; Chang, C.I. Independent Component Analysis-based Dimensionality Reduction with Applications in Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef]
- Chen, G.; Qian, S.E. Denoising and Dimensionality Reduction of Hyperspectral Imagery Using Wavelet Packets, Neighbour Shrinking and Principal Component Analysis. Int. J. Remote Sens. 2009, 30, 4889–4895. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E.; Bruce, L.M. Locality-Preserving Dimensionality Reduction and Classification for Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1185–1198. [Google Scholar] [CrossRef]
- Cao, F.; Yang, Z.; Hong, X.; Cheng, Y.; Huang, Y.; Lv, J. Supervised Dimensionality Reduction of Hyperspectral Imagery via Local and Global Sparse Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3860–3874. [Google Scholar] [CrossRef]
- Yao, C.; Zheng, L.; Feng, L.; Yang, F.; Guo, Z.; Ma, M. A Collaborative Superpixelwise Autoencoder for Unsupervised Dimension Reduction in Hyperspectral Images. Remote Sens. 2023, 15, 4211. [Google Scholar] [CrossRef]
- Martinez, E.; Jacome, R.; Hernandez-Rojas, A.; Arguello, H. LD-GAN: Low-Dimensional Generative Adversarial Network for Spectral Image Generation with Variance Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Ou, X.; Liu, L.; Tan, S.; Zhang, G.; Li, W.; Tu, B. A Hyperspectral Image Change Detection Framework With Self-Supervised Contrastive Learning Pretrained Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7724–7740. [Google Scholar] [CrossRef]
- Liu, S.; Du, Q.; Tong, X.; Samat, A.; Pan, H.; Ma, X. Band Selection-Based Dimensionality Reduction for Change Detection in Multi-Temporal Hyperspectral Images. Remote Sens. 2017, 9, 1008. [Google Scholar] [CrossRef]
- López-Fandiño, J.; Garea, A.S.; Heras, D.B.; Argüello, F. Stacked Autoencoders for Multiclass Change Detection in Hyperspectral Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1906–1909. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Cao, V.L.; Nicolau, M.; McDermott, J. A Hybrid Autoencoder and Density Estimation Model for Anomaly Detection. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 717–726. [Google Scholar] [CrossRef]
- Carvalho Júnior, O.A.; Guimarães, R.F.; Gillespie, A.R.; Silva, N.C.; Gomes, R.A.T. A New Approach to Change Vector Analysis Using Distance and Similarity Measures. Remote Sens. 2011, 3, 2473–2493. [Google Scholar] [CrossRef]
- Hu, M.; Wu, C.; Zhang, L. HyperNet: Self-Supervised Hyperspectral Spatial-Spectral Feature Understanding Network for Hyperspectral Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5543017. [Google Scholar] [CrossRef]
- Li, Y.; Ren, J.; Yan, Y.; Liu, Q.; Ma, P.; Petrovski, A.; Sun, H. CBANet: An End-to-End Cross-Band 2-D Attention Network for Hyperspectral Change Detection in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5513011. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Pixels | Changed Pixels | Unchanged Pixels | Selected Pixels |
|---|---|---|---|---|
| Farmland | 58,800 | 18,383 | 40,417 | 5800 |
| Hermiston | 73,987 | 16,676 | 57,311 | 7000 |
| River | 111,583 | 9698 | 101,885 | 10,000 |
| Dataset | Number of Channels (S) | ||
|---|---|---|---|
| Farmland (K = 155) | 78.40 | 56.76 | |
| 93.37 | 86.74 | ||
| 95.91 | 88.82 | ||
| Hermiston (K = 154) | 87.57 | 75.12 | |
| 94.32 | 88.92 | ||
| 96.51 | 92.31 | ||
| River (K = 198) | 80.10 | 60.46 | |
| 95.88 | 91.75 | ||
| 96.14 | 92.57 |
| Methods | Farmland | Hemiston | River | |||
|---|---|---|---|---|---|---|
| CVA | 92.43 | 78.08 | 92.21 | 76.67 | 93.87 | 77.93 |
| ACD | 94.23 | 78.55 | 92.72 | 76.70 | 94.29 | 78.67 |
| GETNET | 94.63 | 85.72 | 94.31 | 77.25 | 95.14 | 76.39 |
| HyperNet | 93.98 | 80.01 | 92.66 | 76.93 | 95.59 | 80.46 |
| SST-Former | 95.05 | 87.52 | 95.36 | 90.73 | 95.79 | 91.26 |
| STT | 94.84 | 87.98 | 97.03 | 90.36 | 96.74 | 84.93 |
| CBANet | 95.26 | 88.10 | 96.68 | 91.57 | 97.12 | 85.36 |
| EFC-AdvNet | 95.91 | 88.82 | 96.51 | 92.31 | 96.14 | 92.57 |
| Dataset | Configuration | ||
|---|---|---|---|
| Farmland | Without SSR | 81.46 | 62.89 |
| Separate SSR and Adv-CD | 90.47 | 80.95 | |
| SSR+Adv-CD (EFC-AdvNet) | 95.91 | 88.82 | |
| Hermiston | Without SSR | 71.22 | 42.40 |
| Separate SSR and Adv-CD | 86.08 | 72.17 | |
| SSR+Adv-CD (EFC-AdvNet) | 96.51 | 92.31 | |
| River | Without SSR | 51.16 | 37.98 |
| Separate SSR and Adv-CD | 88.62 | 77.25 | |
| SSR+Adv-CD (EFC-AdvNet) | 96.14 | 92.57 |
| Dataset | Configuration | ||
|---|---|---|---|
| Farmland | PCA+Adv-CD | 72.45 | 44.81 |
| Intensity+Adv-CD | 92.52 | 85.03 | |
| SSR+Adv-CD (EFC-AdvNet) | 95.91 | 88.82 | |
| Hermiston | PCA+Adv-CD | 82.43 | 64.86 |
| Intensity+Adv-CD | 95.14 | 90.27 | |
| SSR+Adv-CD (EFC-AdvNet) | 96.51 | 92.31 | |
| River | PCA+Adv-CD | 77.15 | 54.59 |
| Intensity+Adv-CD | 95.25 | 90.50 | |
| SSR+Adv-CD (EFC-AdvNet) | 96.14 | 92.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oubara, A.; Wu, F.; Qu, G.; Maleki, R.; Yang, G. Enhancing Binary Change Detection in Hyperspectral Images Using an Efficient Dimensionality Reduction Technique Within Adversarial Learning. Remote Sens. 2025, 17, 5. https://doi.org/10.3390/rs17010005
Oubara A, Wu F, Qu G, Maleki R, Yang G. Enhancing Binary Change Detection in Hyperspectral Images Using an Efficient Dimensionality Reduction Technique Within Adversarial Learning. Remote Sensing. 2025; 17(1):5. https://doi.org/10.3390/rs17010005
Chicago/Turabian StyleOubara, Amel, Falin Wu, Guoxin Qu, Reza Maleki, and Gongliu Yang. 2025. "Enhancing Binary Change Detection in Hyperspectral Images Using an Efficient Dimensionality Reduction Technique Within Adversarial Learning" Remote Sensing 17, no. 1: 5. https://doi.org/10.3390/rs17010005
APA StyleOubara, A., Wu, F., Qu, G., Maleki, R., & Yang, G. (2025). Enhancing Binary Change Detection in Hyperspectral Images Using an Efficient Dimensionality Reduction Technique Within Adversarial Learning. Remote Sensing, 17(1), 5. https://doi.org/10.3390/rs17010005