



Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing


Abstract
1. Introduction
- To better learn semantic structure information in spectral satellite images with non-homogeneous haze, we propose a hybrid CNN–Transformer architecture, in which a hierarchical semantic guidance (HSG) module is introduced to synergetically aggregate local structure features and non-local semantic information.
- To fully consider the inconsistent attenuation, we present a cross-layer fusion (CLF) module, which is significantly better than traditional skip connection for integrating cross-layer features and reinforcing the attention to the spatial regions and feature channels with more serious attenuation.
- We establish a hierarchical semantic-guided contextual structure-aware network (SCSNet), which can effectively restore hazy-free images from non-homogeneous hazy satellite ones. Our SCSNet achieves nontrivial performance on three challenging SID datasets.
2. Related Work
2.1. Prior-Based Methods
2.2. Deep Learning-Based Methods
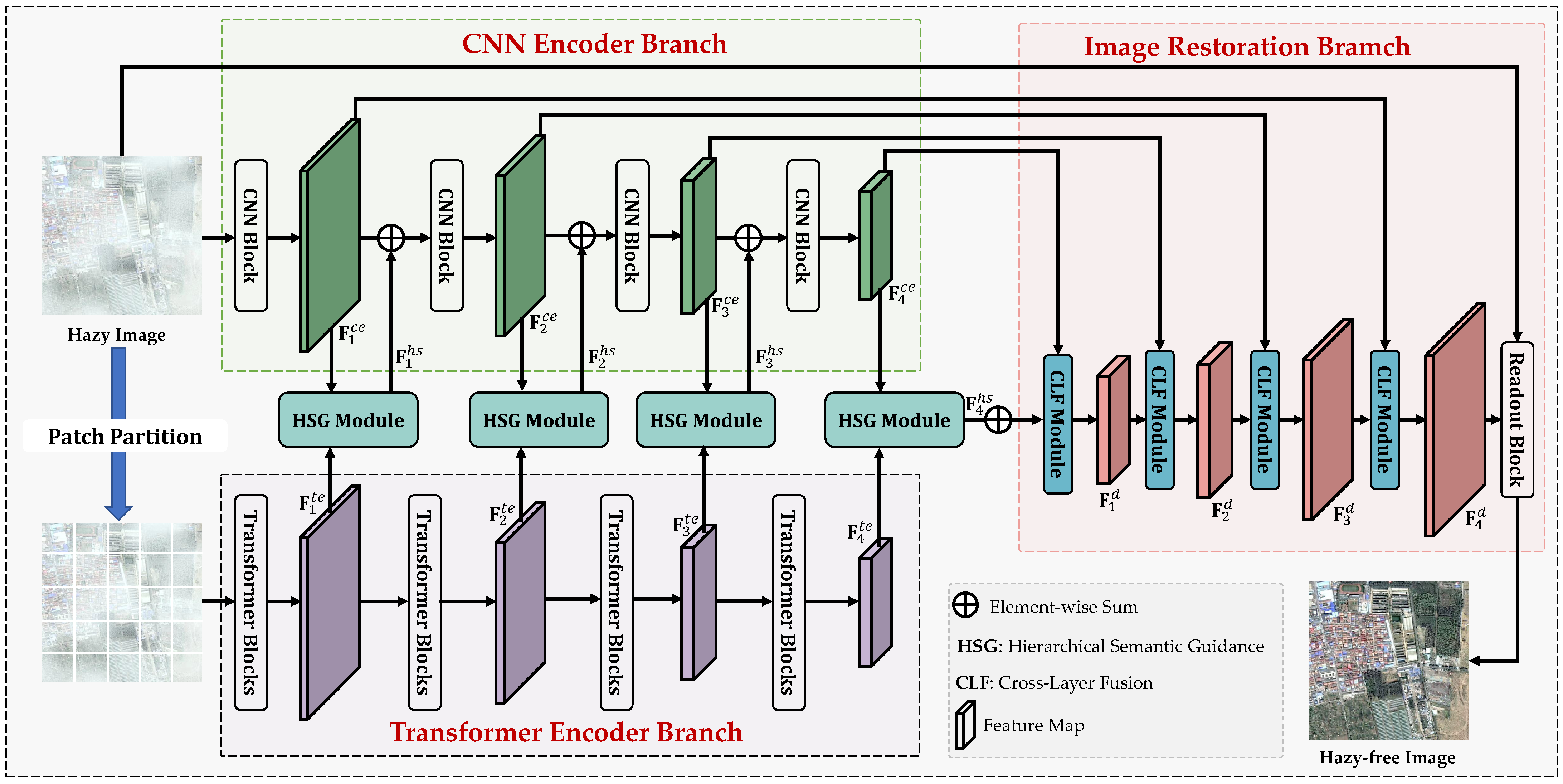
3. The Proposed Method
3.1. Image Encoders
3.1.1. CNN Encoder Branch
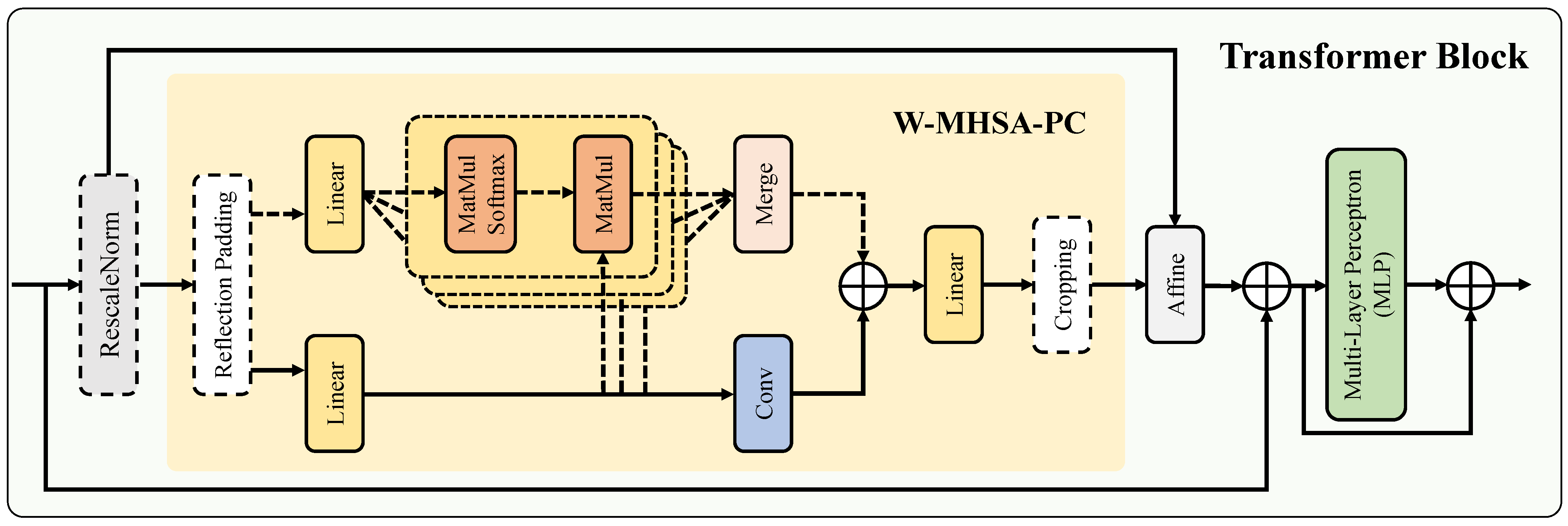
3.1.2. Transformer Encoder Branch
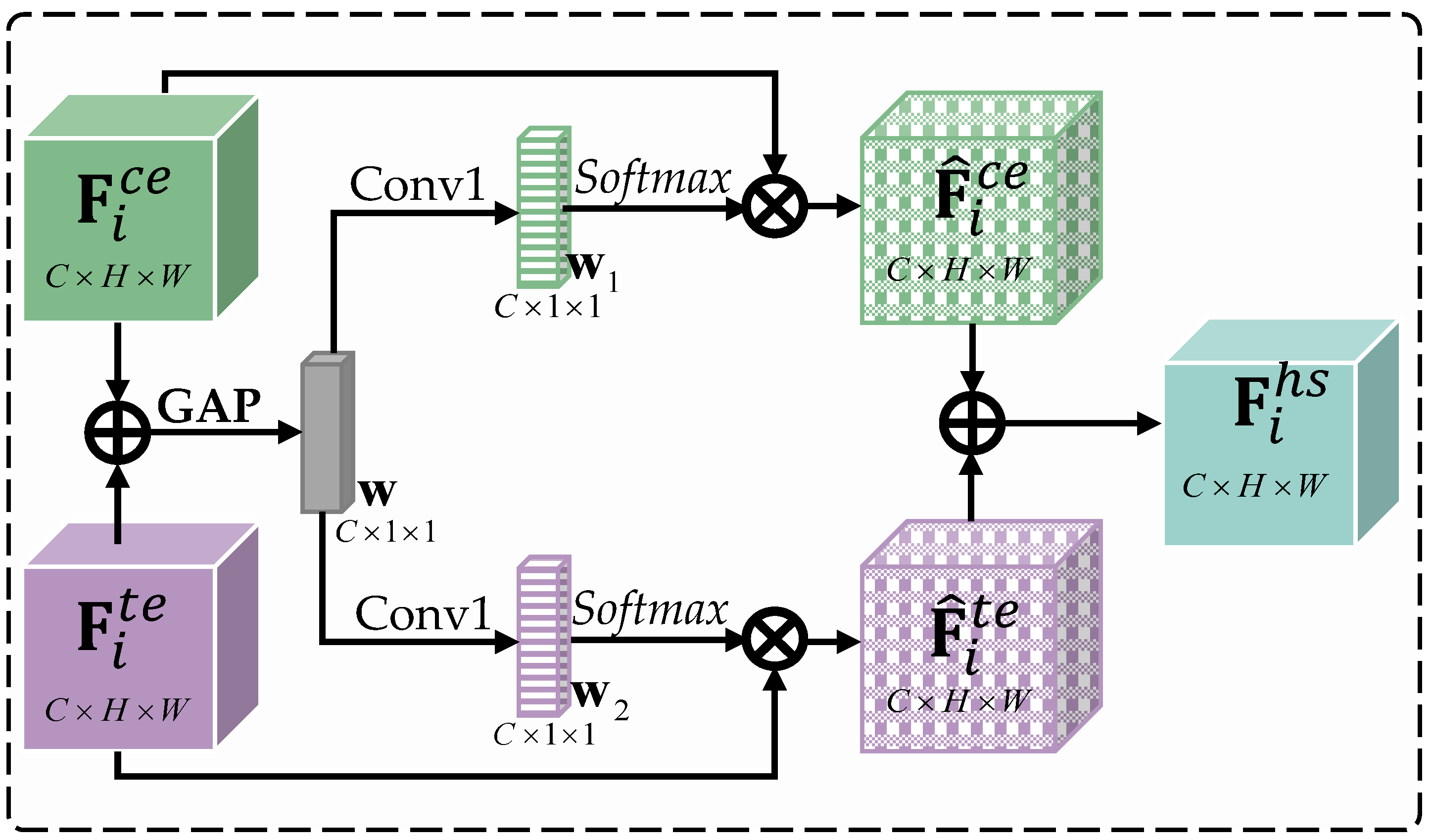
3.2. Hierarchical Semantic Guidance Module
- (1)
- Coarse-guidance: First, the local structure features and non-local semantic features are combined using the concatenation operation and compressed via channel reduction by:where is the coarse-guidance feature, denotes the convolutional layer with batch normalization for channel reduction, and represents the concatenation operation. Then, we use global average pooling on the spatial dimension of the coarse-guidance to compute the channel-wise descriptor. Finally, we use two parallel 1 × 1 convolution layers to process the channel-wise descriptor, obtaining and , which enhance the interaction between local structure features and non-local semantic features.
- (2)
- Fine-guidance: We apply the softmax function to and generating attention activations, which are leveraged to adaptively re-calibrate the local structure features and the non-local semantic features . Finally, the hierarchical semantic guidance feature obtained after the fine-graining is:
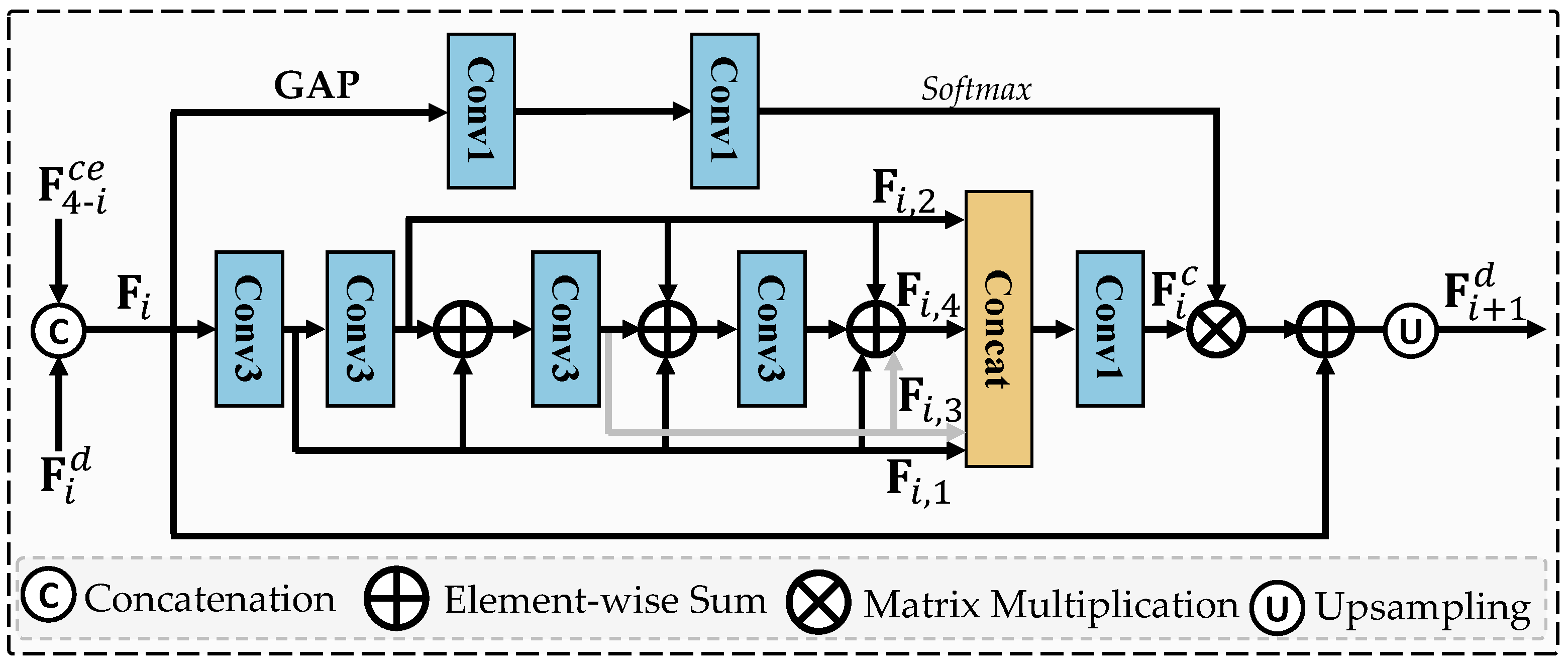
3.3. Image Restoration
3.4. Loss Function
4. Experiment and Results
4.1. Datasets
- (1)
- SateHaze1k: The SateHaze1k dataset [41] consists of 1200 pairs of hazy images, corresponding clear images, and SAR images. The dataset has three levels of haze, covering thin, medium, and thick haze, each with 400 pairs, which is beneficial for evaluating the robustness of the proposed method. Following the previous work [41], we divided the training, validation, and testing data ratio into 8:1:1 for each level of haze. In addition, in order to better evaluate the dehazing effect in real situations, we mixed the data of the three different haze levels together.
- (2)
- RS-Haze: The RS-Haze dataset [8] is a challenging and representative large-scale image dehazing dataset consisting of 51,300 paired images, of which 51,030 are for training and 270 are for testing. The dataset covers a variety of scenes and haze intensities, including urban, forest, beach, and mountain scenes.
- (3)
- RSID: The RSID dataset [1] offers a collection of 1000 image pairs, each consisting of a hazy and haze-free counterpart. Following the previous work [42], we randomly selected 900 of these pairs. The remaining 100 pairs were reserved as a distinct test set to assess the model’s ability to generalize to unknown data.
4.2. Implementation Details and Evaluation Metrics
4.3. Comparison with State-of-the-Arts
4.4. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chi, K.; Yuan, Y.; Wang, Q. Trinity-Net: Gradient-Guided Swin Transformer-based Remote Sensing Image Dehazing and Beyond. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Sun, H.; Luo, Z.; Ren, D.; Hu, W.; Du, B.; Yang, W.; Wan, J.; Zhang, L. Partial Siamese with Multiscale Bi-codec Networks for Remote Sensing Image Haze Removal. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Zheng, X.; Sun, H.; Lu, X.; Xie, W. Rotation-invariant attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 4251–4265. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Li, C.; Bai, T. Remote Sensing Image Haze Removal Based on Superpixel. Remote. Sens. 2023, 15, 4680. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, X.; Lu, X.; Sun, B. Unsupervised change detection by cross-resolution difference learning. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, J.; Wu, Y.; Wang, S.; Zhang, J.; Chen, X.; Li, Y.; Li, X.; Wang, L. A Dehazing Method for Remote Sensing Image Under Nonuniform Hazy Weather Based on Deep Learning Network. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Dong, W.; Wang, C.; Sun, H.; Teng, Y.; Liu, H.; Zhang, Y.; Zhang, K.; Li, X.; Xu, X. End-to-End Detail-Enhanced Dehazing Network for Remote Sensing Images. Remote. Sens. 2024, 16, 225. [Google Scholar] [CrossRef]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Peng, Y.T.; Lu, Z.; Cheng, F.C.; Zheng, Y.; Huang, S.C. Image haze removal using airlight white correction, local light filter, and aerial perspective prior. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1385–1395. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Bie, Y.; Yang, S.; Huang, Y. Single Remote Sensing Image Dehazing using Gaussian and Physics-Guided Process. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X. A coarse-to-fine two-stage attentive network for haze removal of remote sensing images. IEEE Geosci. Remote. Sens. Lett. 2020, 18, 1751–1755. [Google Scholar] [CrossRef]
- Kulkarni, A.; Murala, S. Aerial Image Dehazing With Attentive Deformable Transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6305–6314. [Google Scholar]
- Ning, J.; Zhou, Y.; Liao, X.; Duo, B. Single Remote Sensing Image Dehazing Using Robust Light-Dark Prior. Remote. Sens. 2023, 15, 938. [Google Scholar] [CrossRef]
- Wei, J.; Wu, Y.; Chen, L.; Yang, K.; Lian, R. Zero-shot remote sensing image dehazing based on a re-degradation haze imaging model. Remote. Sens. 2022, 14, 5737. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Huang, Y.; Chen, X. Single Remote Sensing Image Dehazing Using a Dual-Step Cascaded Residual Dense Network. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AL, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3852–3856. [Google Scholar]
- Frants, V.; Agaian, S.; Panetta, K. QCNN-H: Single-image dehazing using quaternion neural networks. IEEE Trans. Cybern. 2023, 53, 5448–5458. [Google Scholar] [CrossRef] [PubMed]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Air-light estimation using haze-lines. In Proceedings of the 2017 IEEE International Conference on Computational Photography (ICCP), Stanford, CA, USA, 12–14 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–9. [Google Scholar]
- Bui, T.M.; Kim, W. Single image dehazing using color ellipsoid prior. IEEE Trans. Image Process. 2017, 27, 999–1009. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Zhao, D.; Yan, Y.; Kwong, S.; Chen, J.; Duan, L.Y. IDeRs: Iterative dehazing method for single remote sensing image. Inf. Sci. 2019, 489, 50–62. [Google Scholar] [CrossRef]
- Zhao, D.; Xu, L.; Yan, Y.; Chen, J.; Duan, L.Y. Multi-scale Optimal Fusion model for single image dehazing. Signal Process. Image Commun. 2019, 74, 253–265. [Google Scholar] [CrossRef]
- Gu, Z.; Zhan, Z.; Yuan, Q.; Yan, L. Single remote sensing image dehazing using a prior-based dense attentive network. Remote. Sens. 2019, 11, 3008. [Google Scholar] [CrossRef]
- Sun, H.; Li, B.; Dan, Z.; Hu, W.; Du, B.; Yang, W.; Wan, J. Multi-level Feature Interaction and Efficient Non-Local Information Enhanced Channel Attention for image dehazing. Neural Netw. 2023, 163, 10–27. [Google Scholar] [CrossRef] [PubMed]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Qiu, Y.; Zhang, K.; Wang, C.; Luo, W.; Li, H.; Jin, Z. MB-TaylorFormer: Multi-branch efficient transformer expanded by Taylor formula for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12802–12813. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jiang, H.; Lu, N.; Yao, L.; Zhang, X. Single image dehazing for visible remote sensing based on tagged haze thickness maps. Remote. Sens. Lett. 2018, 9, 627–635. [Google Scholar] [CrossRef]
- Jiang, B.; Chen, G.; Wang, J.; Ma, H.; Wang, L.; Wang, Y.; Chen, X. Deep dehazing network for remote sensing image with non-uniform haze. Remote. Sens. 2021, 13, 4443. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Dai, L.; Kong, C. Hybrid high-resolution learning for single remote sensing satellite image Dehazing. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, S.; Zhou, Y.; Xiang, W. M2SCN: Multi-Model Self-Correcting Network for Satellite Remote Sensing Single-Image Dehazing. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Huang, Y.; Xiong, S. Remote sensing image dehazing using adaptive region-based diffusion models. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In Proceedings of the IEEE/CVF winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Wen, Y.; Gao, T.; Zhang, J.; Li, Z.; Chen, T. Encoder-free Multi-axis Physics-aware Fusion Network for Remote Sensing Image Dehazing. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–15. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Ullah, H.; Muhammad, K.; Irfan, M.; Anwar, S.; Sajjad, M.; Imran, A.S.; de Albuquerque, V.H.C. Light-DehazeNet: A novel lightweight CNN architecture for single image dehazing. IEEE Trans. Image Process. 2021, 30, 8968–8982. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Thin Fog | Moderate Fog | Thick Fog | Mixed Fog | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| DCP [10] | 19.1183 | 0.8518 | 19.8384 | 0.8812 | 16.793 | 0.7701 | 18.5833 | 0.8344 |
| CEP [26] | 13.5997 | 0.7222 | 14.2122 | 0.7270 | 16.0824 | 0.7762 | 14.6950 | 0.7512 |
| MOF [29] | 15.3891 | 0.7291 | 14.7418 | 0.6256 | 16.2495 | 0.6767 | 15.5146 | 0.6859 |
| AOD-Net [13] | 19.0548 | 0.7777 | 19.4211 | 0.7015 | 16.4672 | 0.7123 | 17.4859 | 0.6332 |
| Light-DehazeNet [44] | 18.4868 | 0.8658 | 18.3918 | 0.8825 | 16.7662 | 0.7697 | 17.8132 | 0.8352 |
| FFA-Net [14] | 20.141 | 0.8582 | 22.5586 | 0.9132 | 19.1255 | 0.7976 | 21.2873 | 0.8663 |
| Restormer [21] | 20.9829 | 0.8686 | 23.1574 | 0.9036 | 19.6984 | 0.7739 | 20.7892 | 0.8379 |
| DehazeFormer [8] | 21.9274 | 0.8843 | 24.4407 | 0.9268 | 20.2133 | 0.8049 | 22.0066 | 0.8659 |
| DCRD-Net [22] | 20.8473 | 0.8767 | 23.3119 | 0.9225 | 19.725 | 0.8121 | 21.7468 | 0.8812 |
| FCTF-Net [17] | 18.3262 | 0.8369 | 20.9057 | 0.8553 | 17.2551 | 0.6922 | 19.5883 | 0.8434 |
| SCSNet | 26.1460 | 0.9415 | 28.3501 | 0.9566 | 24.6542 | 0.9015 | 25.1759 | 0.9223 |
| Methods | RS-Haze | RSID | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| DCP [10] | 18.1003 | 0.6704 | 17.3256 | 0.7927 |
| CEP [26] | 15.9097 | 0.5772 | 14.2375 | 0.7034 |
| MOF [29] | 16.1608 | 0.5628 | 14.2375 | 0.7034 |
| AOD-Net [13] | 23.9677 | 0.7207 | 18.7037 | 0.7424 |
| Light-DehazeNet [44] | 25.5965 | 0.8209 | 17.9279 | 0.8414 |
| FFA-Net [14] | 29.1932 | 0.8846 | 21.2876 | 0.9042 |
| Restormer [21] | 25.6700 | 0.7563 | 11.7240 | 0.5971 |
| DehazeFormer [8] | 29.3419 | 0.8730 | 22.6859 | 0.9118 |
| DCRD-Net [22] | 29.6780 | 0.8878 | 22.1643 | 0.8926 |
| FCTF-Net [17] | 29.6240 | 0.8958 | 20.2556 | 0.8397 |
| SCSNet | 32.2504 | 0.9271 | 25.3821 | 0.9585 |
| Datasets | Ablated Components | Baselines | PSNR | SSIM |
|---|---|---|---|---|
| SateHaze1k | Feature Encoding | w/plain ConvE | 22.0216 | 0.8954 |
| CNN Encoder Branch | w/CNN Encoder Branch | 21.1281 | 0.8647 | |
| Transformer Encoder Branch | w/Transformer Encoder Branch | 20.6172 | 0.8470 | |
| HSG | w/o HSG | 21.6719 | 0.8927 | |
| CLF | w/add | 23.5234 | 0.9026 | |
| Full model (SCSNet) | — | 25.1759 | 0.9223 | |
| RS-Haze | Feature Encoding | w/plain ConvE | 30.4251 | 0.9126 |
| CNN Encoder Branch | w/CNN Encoder Branch | 29.0637 | 0.8813 | |
| Transformer Encoder Branch | w/Transformer Encoder Branch | 28.5183 | 0.8729 | |
| HSG | w/o HSG | 29.4806 | 0.9081 | |
| CLF | w/add | 31.6208 | 0.9217 | |
| Full model (SCSNet) | — | 35.2504 | 0.9471 | |
| RSID | Feature Encoding | w/plain ConvE | 23.7316 | 0.9218 |
| CNN Encoder Branch | w/CNN Encoder Branch | 22.8219 | 0.9075 | |
| Transformer Encoder Branch | w/Transformer Encoder Branch | 22.5311 | 0.8962 | |
| HSG | w/o HSG | 23.2430 | 0.9168 | |
| CLF | w/add | 24.0257 | 0.9349 | |
| Full model (SCSNet) | — | 25.3821 | 0.9585 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Cao, J.; Wang, H.; Dong, S.; Ning, H. Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing. Remote Sens. 2024, 16, 1525. https://doi.org/10.3390/rs16091525
Yang L, Cao J, Wang H, Dong S, Ning H. Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing. Remote Sensing. 2024; 16(9):1525. https://doi.org/10.3390/rs16091525
Chicago/Turabian StyleYang, Lei, Jianzhong Cao, Hua Wang, Sen Dong, and Hailong Ning. 2024. "Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing" Remote Sensing 16, no. 9: 1525. https://doi.org/10.3390/rs16091525
APA StyleYang, L., Cao, J., Wang, H., Dong, S., & Ning, H. (2024). Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing. Remote Sensing, 16(9), 1525. https://doi.org/10.3390/rs16091525