
M-SKSNet: Multi-Scale Spatial Kernel Selection for Image Segmentation of Damaged Road Markings


 , ,
, ,
Abstract
1. Introduction
- M-SKSNet (multi-scale spatial kernel selection net): a new image segmentation network that effectively processes various object sizes through combining CNN and transformer architectures with a dynamic kernel.
- CDM data set (Chinese Damaged Road Marking data set): The first extensive data set for Chinese road scenes, enhancing research on road damage detection.
- Detection performance: our approach successfully identifies challenging road markings, showing improved accuracy and robustness on the CDM data set.
2. Related Work
2.1. Damaged Road Marking Data Set
2.2. Road Marking Image Segmentation
2.2.1. Methods Based on Traditional Image Processing
2.2.2. Deep-Learning-Based Methods
- FCN-Based Methods
- 2.
- R-CNN-Based Methods
- 3.
- Transformer-Based Methods
3. Public Damaged Road Marking Data Sets
3.1. Data Processing
3.1.1. Data Acquisition
3.1.2. Manual Curation
3.1.3. Image Refinement
3.2. Data Set Characteristics
- Consideration of geographical distribution heterogeneity, covering roads from various regions of China, including Chongqing, Wuhan, Shanghai, Beijing, and Fuzhou, reflecting the diversity and complexity of Chinese roads.
- Inclusion of various road types, such as ramp entrances, main roads, ramp exits, branches, intersections, etc., covering a wide range of complex road scenes.
- Consideration of sample time differences, including data collection during daytime, evening, and night-time under different lighting conditions.
- Use of the public data set for supplementation and comparison, increasing the scale and quality of the data set.
3.3. Data Set Contributions
- A relatively large-scale road marking damage data set in China: deep learning relies on data, and the generalization performance of models is influenced by the diversity of training data. Considering the low coverage of public road data sets in China and the complexity and diversity of Chinese roads, models trained on existing public data sets perform well in training but poorly in China. Therefore, the application of the CDM data set can supplement the insufficient coverage of Chinese public road data sets and provide important support for the evaluation of deep learning models.
- Higher heterogeneity: the diversity of the data set is key to improving model generalization performance. The CDM data set covers various road types and scenes, providing highly heterogeneous and diverse images. This reflects the characteristics of Chinese roads and provides a benchmark for evaluating the usability and generalization of models.
- Stronger geographical robustness: intra-class diversity helps models recognize more road scenes. The CDM data set covers cities in different geographical regions of China, providing images from various geographical and road backgrounds. This helps improve the robustness and portability of models.
4. Methods
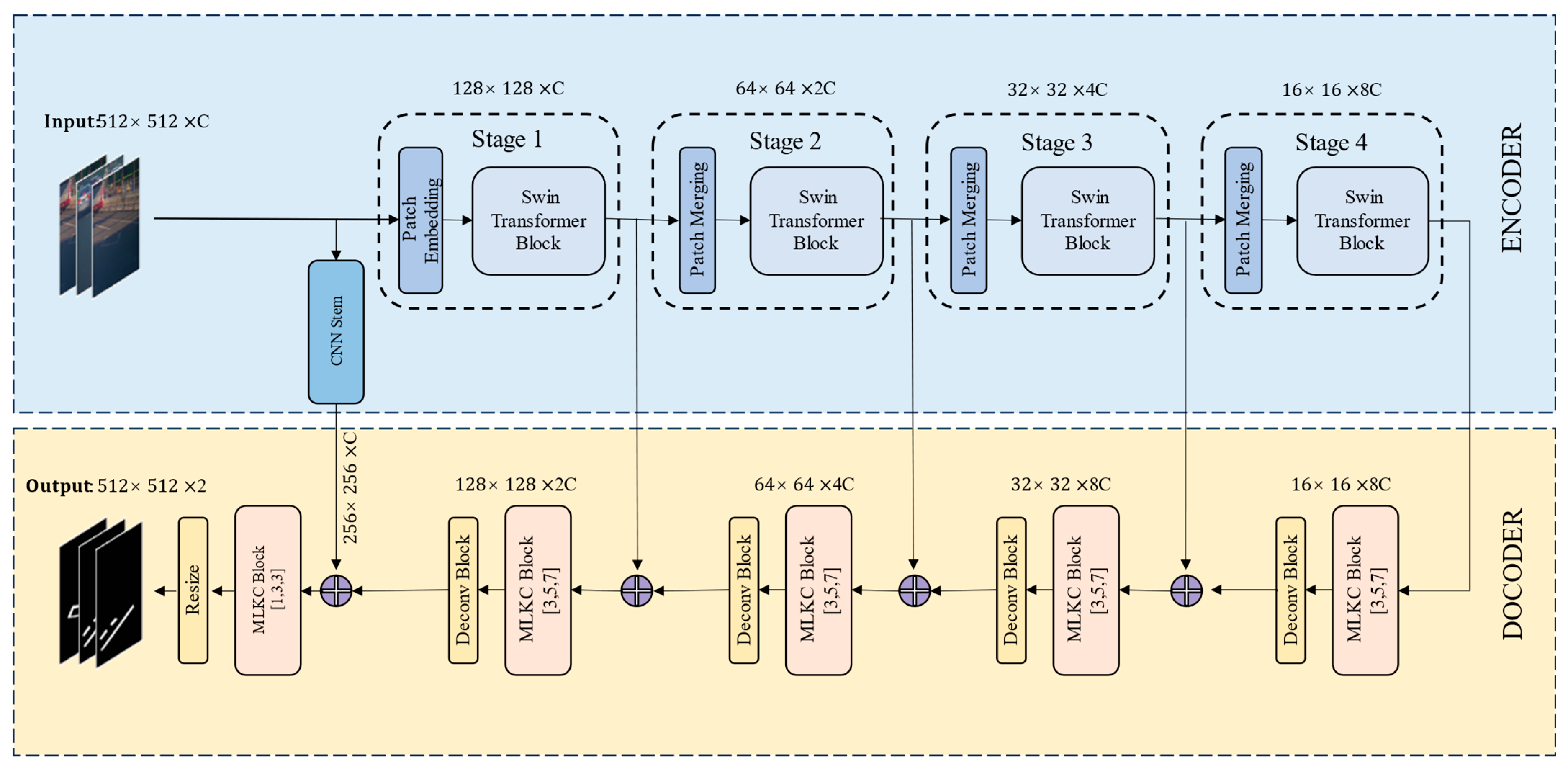
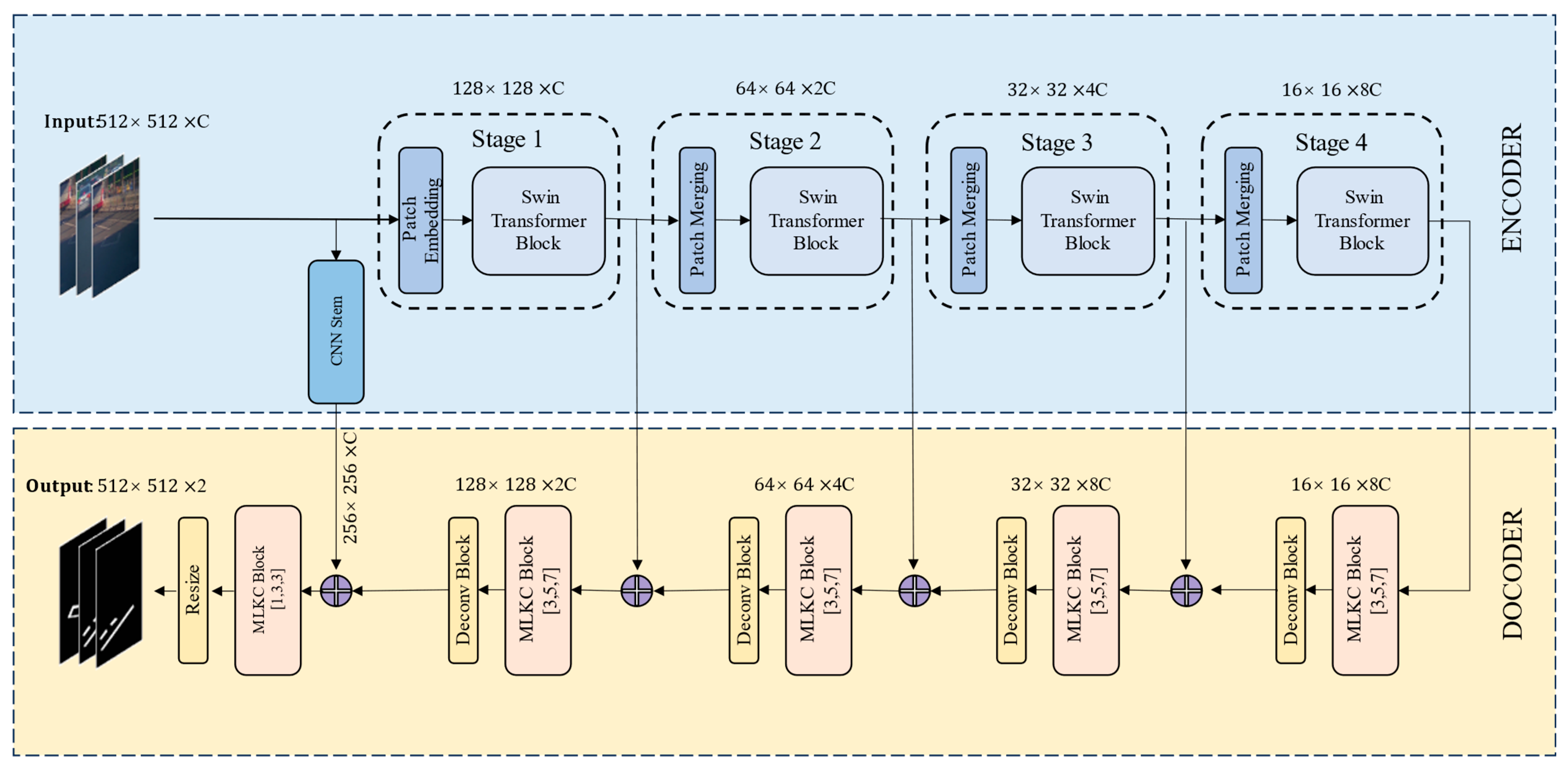
4.1. Model Architecture
4.2. The Transformer (Encoder)
- Patch Embedding: taking the damage marking image with dimensions of H × W × 3 as input, the Swin transformer uses smaller 4 × 4 patches to better capture the details of small-scale objects in image segmentation.
- Transformer Encoder Block: introduces window-based self-attention (WSA) stacked in the proposed model. Notably, the window position is replaced with half the window size, allowing for the gradual construction of global context through effectively integrating information from various windows. This approach enhances the model’s ability to capture broader contextual information for improved performance in various tasks.
- Patch Merging: merges adjacent patches into a larger patch, thereby reducing the resolution of the feature map and increasing the receptive field.
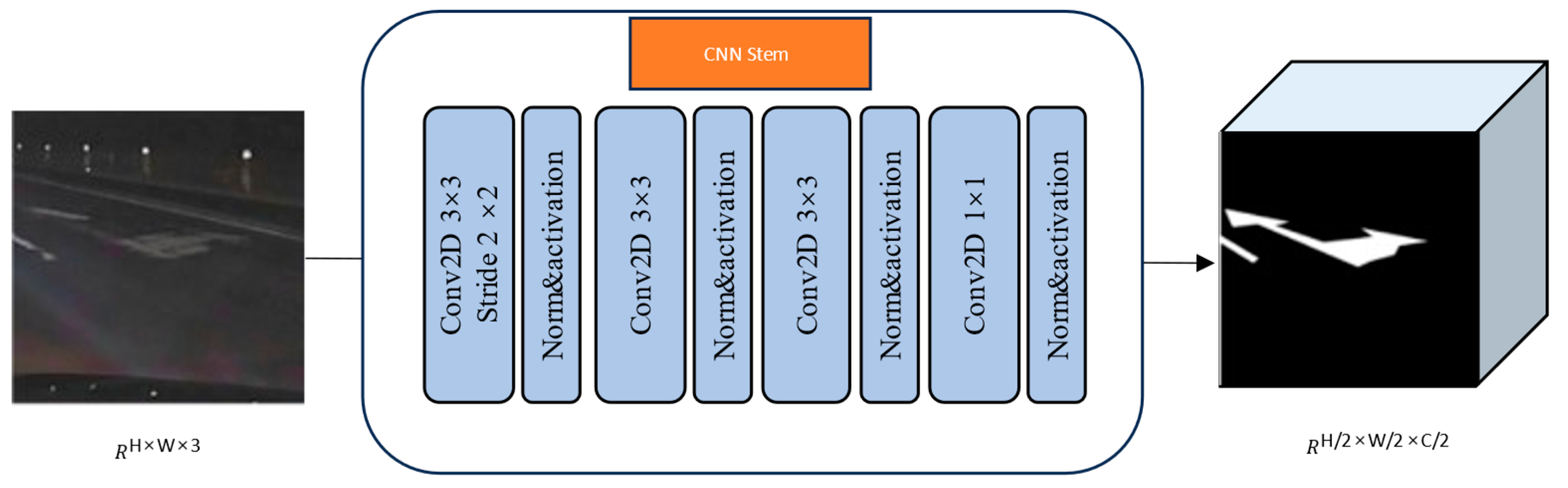
4.3. The CNN Stem
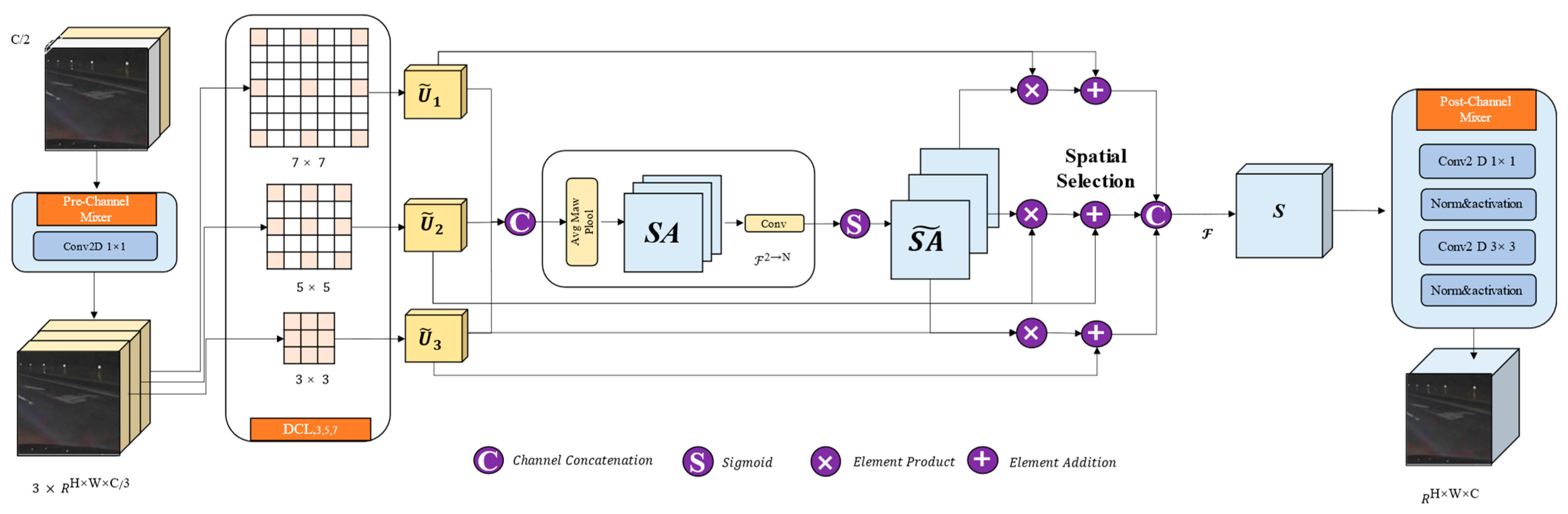
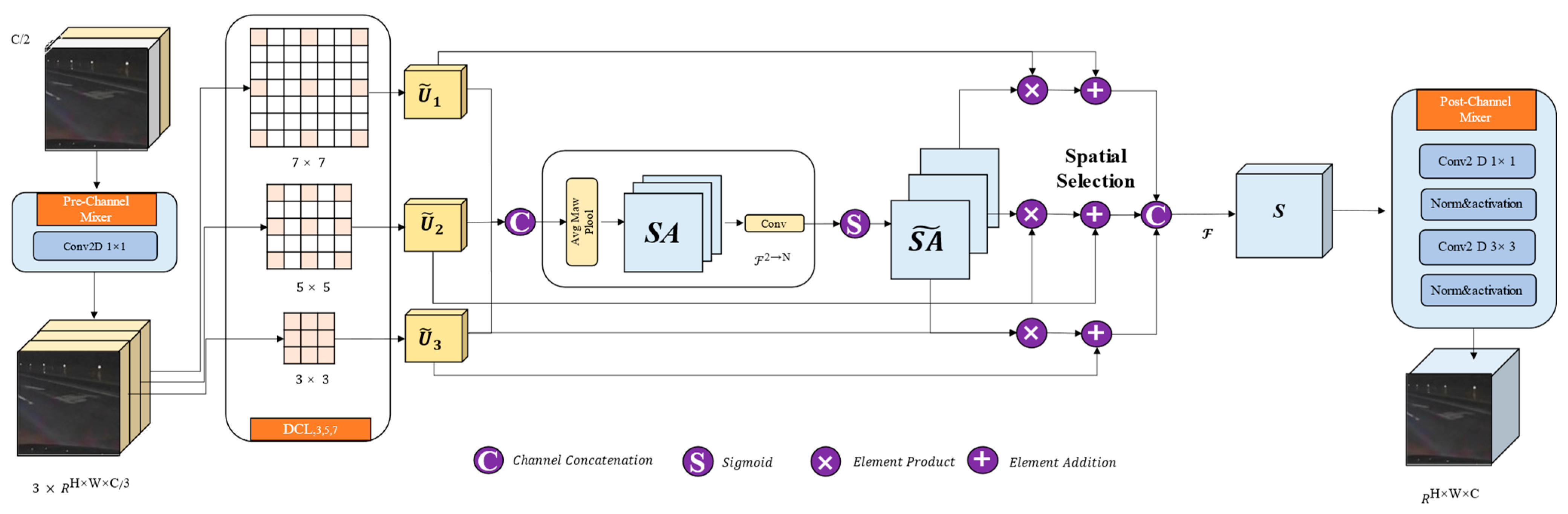
4.4. Multi-Dilated Large Kernel CNN (DECODER)
4.4.1. Pre-Channel Mixer
4.4.2. Dilated Convolutional Layer (DCL)
4.4.3. Spatial Kernel Selection (SKS)
4.4.4. Post-Channel Mixer
4.5. Loss Function
5. Experiment
5.1. Experiment Setting
5.2. Evaluation Metrics
5.3. Experimental Results Analysis
5.3.1. Quantitative Results and Analysis
- Quantitative Analysis of Experimental Results on Different Data Sets
- (1)
- Results of the network performance test on the CDM-P data set
- (2)
- Results of the network performance test on the CDM-H data set
- (3)
- Results of the network performance test on the CDM-C data set
- 2.
- Overall Analysis of Quantitative Experimental Results
5.3.2. Qualitative Results and Analysis
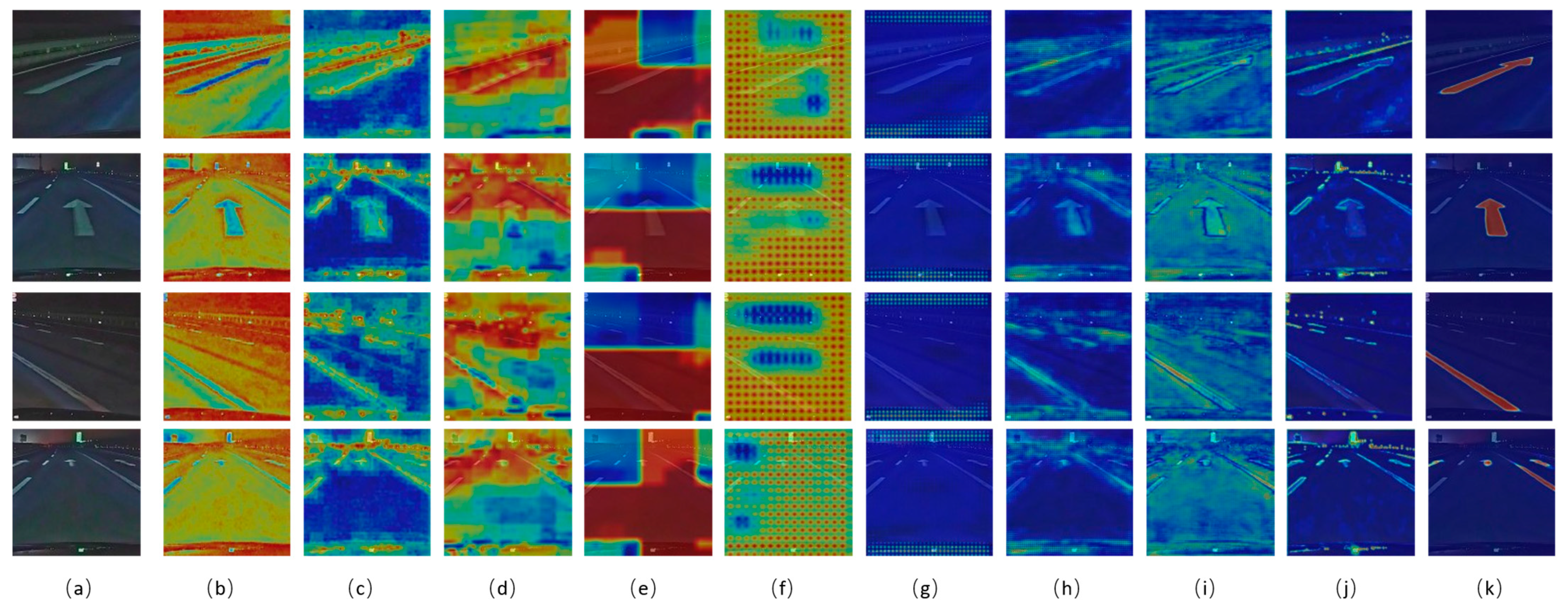
5.4. Feature Map Visualization
5.5. Ablation Study
5.6. Model Complexity Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Morrissett, A.; Abdelwahed, S. A Review of Non-Lane Road Marking Detection and Recognition. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; Wu, P.; Shou, W.; Wang, X.; Chen, M. Vision-Based Pavement Marking Detection and Condition Assessment-A Case Study. Appl. Sci. 2021, 11, 3152. [Google Scholar] [CrossRef]
- Feng, M.Q.; Leung, R.Y. Application of Computer Vision for Estimation of Moving Vehicle Weight. IEEE Sens. J. 2021, 21, 11588–11597. [Google Scholar] [CrossRef]
- Kumar, P.; McElhinney, C.P.; Lewis, P.; McCarthy, T. Automated Road Markings Extraction from Mobile Laser Scanning Data. Int. J. Appl. Earth Obs. Geoinf. 2014, 32, 125–137. [Google Scholar] [CrossRef]
- Chou, C.P.; Hsu, H.H.; Chen, A.C. Automatic Recognition of Worded and Diagrammatic Road Markings Based on Laser Reflectance Information. J. Transp. Eng. Part B Pavements 2020, 146, 04020051. [Google Scholar] [CrossRef]
- Lyu, X.; Li, X.; Dang, D.; Dou, H.; Wang, K.; Lou, A. Unmanned Aerial Vehicle (UAV) Remote Sensing in Grassland Ecosystem Monitoring: A Systematic Review. Remote Sens. 2022, 14, 1096. [Google Scholar] [CrossRef]
- Liu, J.; Liao, X.; Ye, H.; Yue, H.; Wang, Y.; Tan, X.; Wang, D. UAV Swarm Scheduling Method for Remote Sensing Observations during Emergency Scenarios. Remote Sens. 2022, 14, 1406. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Yang, C.; Guo, H. A Method of Image Semantic Segmentation Based on PSPNet. Math. Probl. Eng. 2022. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Zhuang, L.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic Pixel-Level Detection of Vertical Cracks in Asphalt Pavement Based on GPR Investigation and Improved Mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Gupta, A.; Welburn, E.; Watson, S.; Yin, H. CNN-Based Semantic Change Detection in Satellite Imagery. In Artificial Neural Networks and Machine Learning—Icann 2019: Workshop and Special Sessions; Tetko, I.V., Kurkova, V., Karpov, P., Theis, F., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2019; Volume 11731, pp. 669–684. [Google Scholar]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Remote Sensing|Free Full-Text|ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios. Available online: https://www.mdpi.com/2072-4292/15/7/1750 (accessed on 20 March 2024).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Wang, S.; Bai, M.; Mattyus, G.; Chu, H.; Luo, W.; Yang, B.; Liang, J.; Cheverie, J.; Fidler, S.; Urtasun, R. TorontoCity: Seeing the World with a Million Eyes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3028–3036. [Google Scholar] [CrossRef]
- Neuhold, G.; Ollmann, T.; Bulò, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed]
- Jayasinghe, O.; Hemachandra, S.; Anhettigama, D.; Kariyawasam, S.; Rodrigo, R.; Jayasekara, P. CeyMo: See More on Roads—A Novel Benchmark Dataset for Road Marking Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar] [CrossRef]
- Takumi, K.; Watanabe, K.; Ha, Q.; Tejero-De-Pablos, A.; Ushiku, Y.; Harada, T. Multispectral Object Detection for Autonomous Vehicles. In Proceedings of the on Thematic Workshops of ACM Multimedia, New York, NY, USA, 23–27 October 2017; pp. 35–43. [Google Scholar] [CrossRef]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards Real-Time Semantic Segmentation for Autonomous Vehicles with Multi-Spectral Scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar] [CrossRef]
- Schneider, L.; Jasch, M.; Fröhlich, B.; Weber, T.; Franke, U.; Pollefeys, M.; Rätsch, M. Multimodal Neural Networks: RGB-D for Semantic Segmentation and Object Detection. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 98–109. [Google Scholar] [CrossRef]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-Time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar] [CrossRef]
- Uhrig, J.; Rehder, E.; Fröhlich, B.; Franke, U.; Brox, T. Box2Pix: Single-Shot Instance Segmentation by Assigning Pixels to Object Boxes. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 292–299. [Google Scholar] [CrossRef]
- Tian, J.; Yuan, J.; Liu, H. Road Marking Detection Based on Mask R-CNN Instance Segmentation Model. In Proceedings of the 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 10–12 July 2020. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. PATTERN Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Dong, J.; Liu, J.; Wang, N.; Fang, H.; Zhang, J.; Hu, H.; Ma, D. Intelligent Segmentation and Measurement Model for Asphalt Road Cracks Based on Modified Mask R-CNN Algorithm. Cmes-Comput. Model. Eng. Sci. 2021, 128, 541–564. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Belal, M.M.; Sundaram, D.M. Global-Local Attention-Based Butterfly Vision Transformer for Visualization-Based Malware Classification. IEEE Access 2023, 11, 69337–69355. [Google Scholar] [CrossRef]
- Geng, S.; Zhu, Z.; Wang, Z.; Dan, Y.; Li, H. LW-ViT: The Lightweight Vision Transformer Model Applied in Offline Handwritten Chinese Character Recognition. Electronics 2023, 12, 1693. [Google Scholar] [CrossRef]
- Aim, D.; Kim, H.J.; Kim, S.; Ko, B.C. IEEE Shift-ViT: Siamese Vision Transformer Using Shifted Branches. In Proceedings of the 2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; pp. 259–261. [Google Scholar]
- Brandizzi, N.; Fanti, A.; Gallotta, R.; Russo, S.; Iocchi, L.; Nardi, D.; Napoli, C. Unsupervised Pose Estimation by Means of an Innovative Vision Transformer. In Artificial Intelligence and Soft Computing; ICAISC 2022. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; Volume 13589, pp. 3–20. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Remote Sensing|Free Full-Text|MARE: Self-Supervised Multi-Attention REsu-Net for Semantic Segmentation in Remote Sensing. Available online: https://www.mdpi.com/2072-4292/13/16/3275 (accessed on 4 January 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | OA | R | P | F1 | IOU |
|---|---|---|---|---|---|
| M-SKSNet | 99.60 | 84.39 | 90.73 | 86.17 | 75.69 |
| BiSeNet | 99.55 | 79.54 | 88.96 | 83.99 | 72.39 |
| LinkNet | 99.5 | 78.19 | 89.80 | 83.60 | 71.82 |
| EaNet | 99.54 | 76.29 | 91.53 | 83.22 | 71.27 |
| MAResUNet | 99.47 | 73.10 | 89.51 | 80.48 | 67.34 |
| LANet | 99.28 | 65.60 | 82.19 | 72.96 | 57.43 |
| ResNeSt | 99.53 | 77.39 | 89.30 | 82.92 | 70.82 |
| ConvNeXt | 99.45 | 76.02 | 85.36 | 80.42 | 67.25 |
| SegFormer | 99.22 | 57.96 | 84.93 | 68.90 | 52.56 |
| Model | OA | R | P | F1 | IOU |
|---|---|---|---|---|---|
| M-SKSNet | 99.59 | 83.37 | 85.64 | 84.49 | 73.15 |
| BiSeNet | 99.55 | 78.82 | 86.67 | 82.55 | 70.29 |
| LinkNet | 99.56 | 78.47 | 87.85 | 82.90 | 70.79 |
| EaNet | 99.54 | 76.44 | 88.23 | 81.91 | 69.36 |
| MAResUNet | 99.56 | 75.99 | 89.53 | 82.21 | 69.79 |
| LANet | 99.37 | 59.02 | 90.96 | 71.59 | 55.75 |
| ResNeSt | 99.49 | 77.03 | 84.26 | 80.48 | 67.34 |
| ConvNeXt | 99.50 | 74.46 | 86.38 | 79.98 | 66.64 |
| SegFormer | 99.42 | 75.86 | 80.01 | 77.88 | 63.78 |
| Model | OA | R | P | F1 | IOU |
|---|---|---|---|---|---|
| M-SKSNet | 99.08 | 68.35 | 79.98 | 73.71 | 58.37 |
| BiSeNet | 98.99 | 62.66 | 79.13 | 69.94 | 53.77 |
| LinkNet | 98.77 | 55.40 | 72.58 | 62.84 | 45.81 |
| EaNet | 98.88 | 65.90 | 71.91 | 68.77 | 52.41 |
| MAResUNet | 98.76 | 57.43 | 70.96 | 63.48 | 46.50 |
| LANet | 98.59 | 38.39 | 74.42 | 50.65 | 33.91 |
| ResNeSt | 98.99 | 62.51 | 79.11 | 69.84 | 53.65 |
| ConvNeXt | 98.62 | 57.34 | 64.95 | 60.91 | 43.79 |
| SegFormer | 98.63 | 51.27 | 68.15 | 58.52 | 41.36 |
| Method | Baseline | CNN Stem | MLKC | F1 | IOU |
|---|---|---|---|---|---|
| Baseline | √ | 84.98 | 73.88 | ||
| CNN stem | √ | √ | 85.77 | 75.09 | |
| MDC | √ | √ | 85.62 | 74.86 | |
| M-SKSNet | √ | √ | √ | 86.17 | 75.69 |
| Model Name | GFLOPS | Params (MB) | Throughput (FPS) |
|---|---|---|---|
| M-SKSNet | 64.14 | 37.48 | 28.40 |
| BiSeNet | 33.55 | 24.27 | 72.72 |
| EaNet | 18.76 | 34.23 | 78.50 |
| LANet | 9.62 | 11.25 | 198.78 |
| MAResUNet | 25.42 | 16.17 | 61.66 |
| LinkNet | 17.86 | 11.53 | 135.34 |
| ResNeSt | 37.24 | 18.24 | 61.32 |
| ConvNeXt | 71.62 | 46.42 | 30.93 |
| SegFormer | 13.10 | 7.71 | 78.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Liao, X.; Wang, Y.; Zeng, X.; Ren, X.; Yue, H.; Qu, W. M-SKSNet: Multi-Scale Spatial Kernel Selection for Image Segmentation of Damaged Road Markings. Remote Sens. 2024, 16, 1476. https://doi.org/10.3390/rs16091476
Wang J, Liao X, Wang Y, Zeng X, Ren X, Yue H, Qu W. M-SKSNet: Multi-Scale Spatial Kernel Selection for Image Segmentation of Damaged Road Markings. Remote Sensing. 2024; 16(9):1476. https://doi.org/10.3390/rs16091476
Chicago/Turabian StyleWang, Junwei, Xiaohan Liao, Yong Wang, Xiangqiang Zeng, Xiang Ren, Huanyin Yue, and Wenqiu Qu. 2024. "M-SKSNet: Multi-Scale Spatial Kernel Selection for Image Segmentation of Damaged Road Markings" Remote Sensing 16, no. 9: 1476. https://doi.org/10.3390/rs16091476
APA StyleWang, J., Liao, X., Wang, Y., Zeng, X., Ren, X., Yue, H., & Qu, W. (2024). M-SKSNet: Multi-Scale Spatial Kernel Selection for Image Segmentation of Damaged Road Markings. Remote Sensing, 16(9), 1476. https://doi.org/10.3390/rs16091476