
GLUENet: An Efficient Network for Remote Sensing Image Dehazing with Gated Linear Units and Efficient Channel Attention




Abstract
1. Introduction
- We developed GLUENet, an encoder–decoder remote sensing image dehazing network, with less model complexity and computational effort, achieving superior results.
- We construct basic convolutional blocks (GLUE blocks) using gated linear units and efficient channel attention while using depth-separable convolutional layers to aggregate spatial information and efficiently transform features.
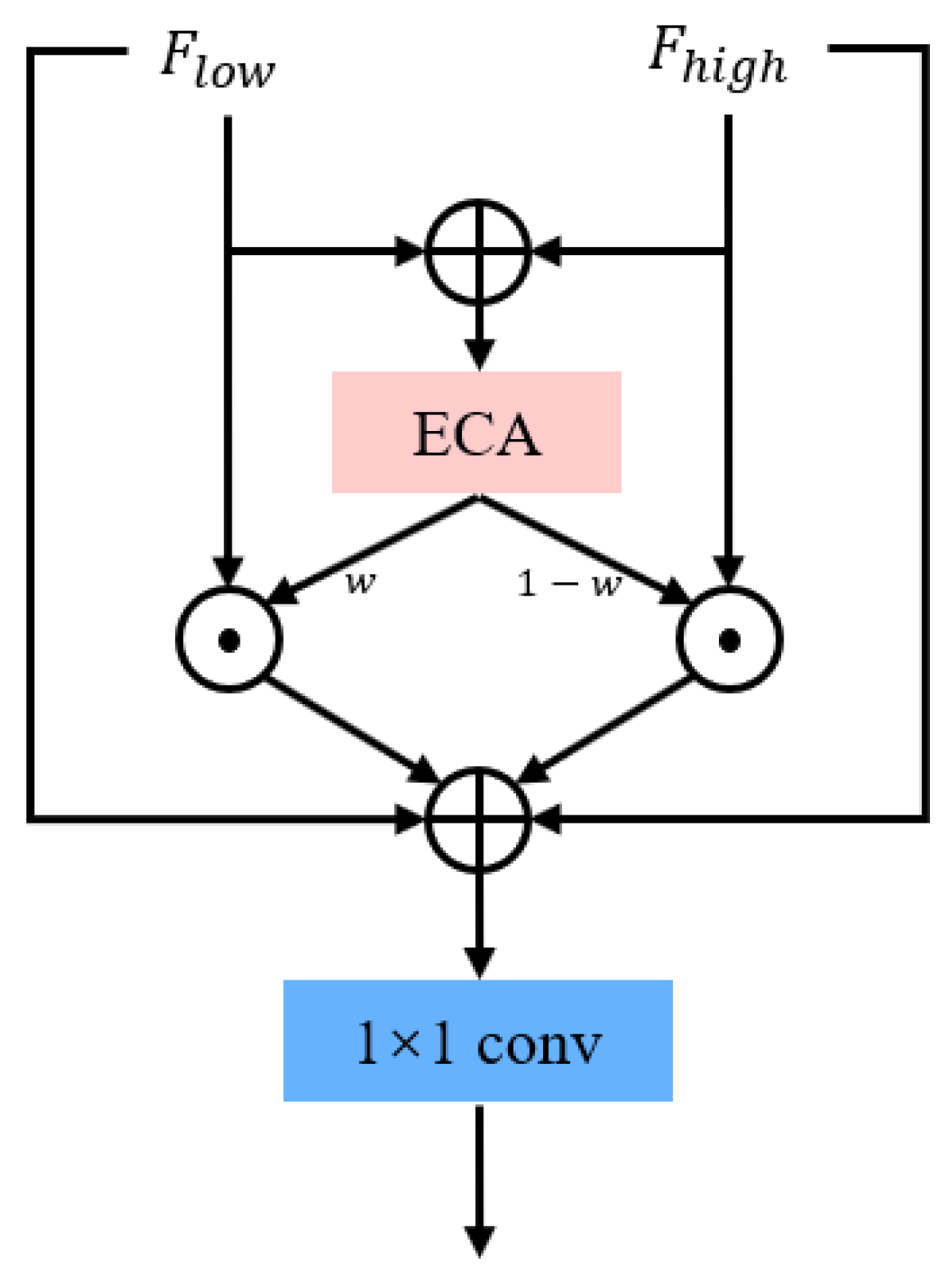
- We proposed an attention-guided fusion block based on efficient channel attention (ECA Fusion), integrating information from different stages in both encoding and decoding to enhance the dehazing effect.
- We created a real remote sensing image haze-clear dataset using Sentinel-2 satellite remote sensing images.
2. Related Work
2.1. Image Dehaze
2.2. Gated Linear Units
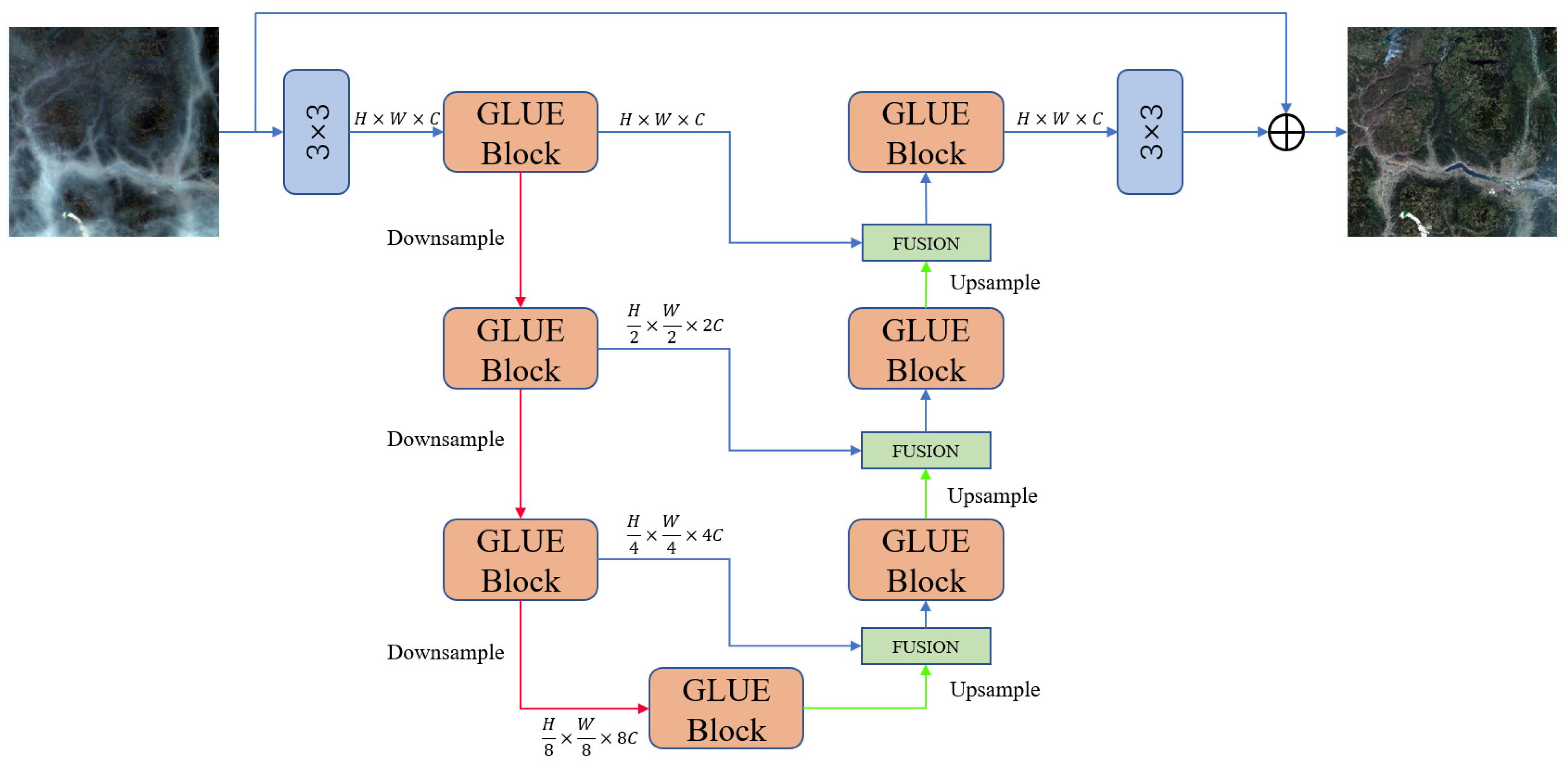
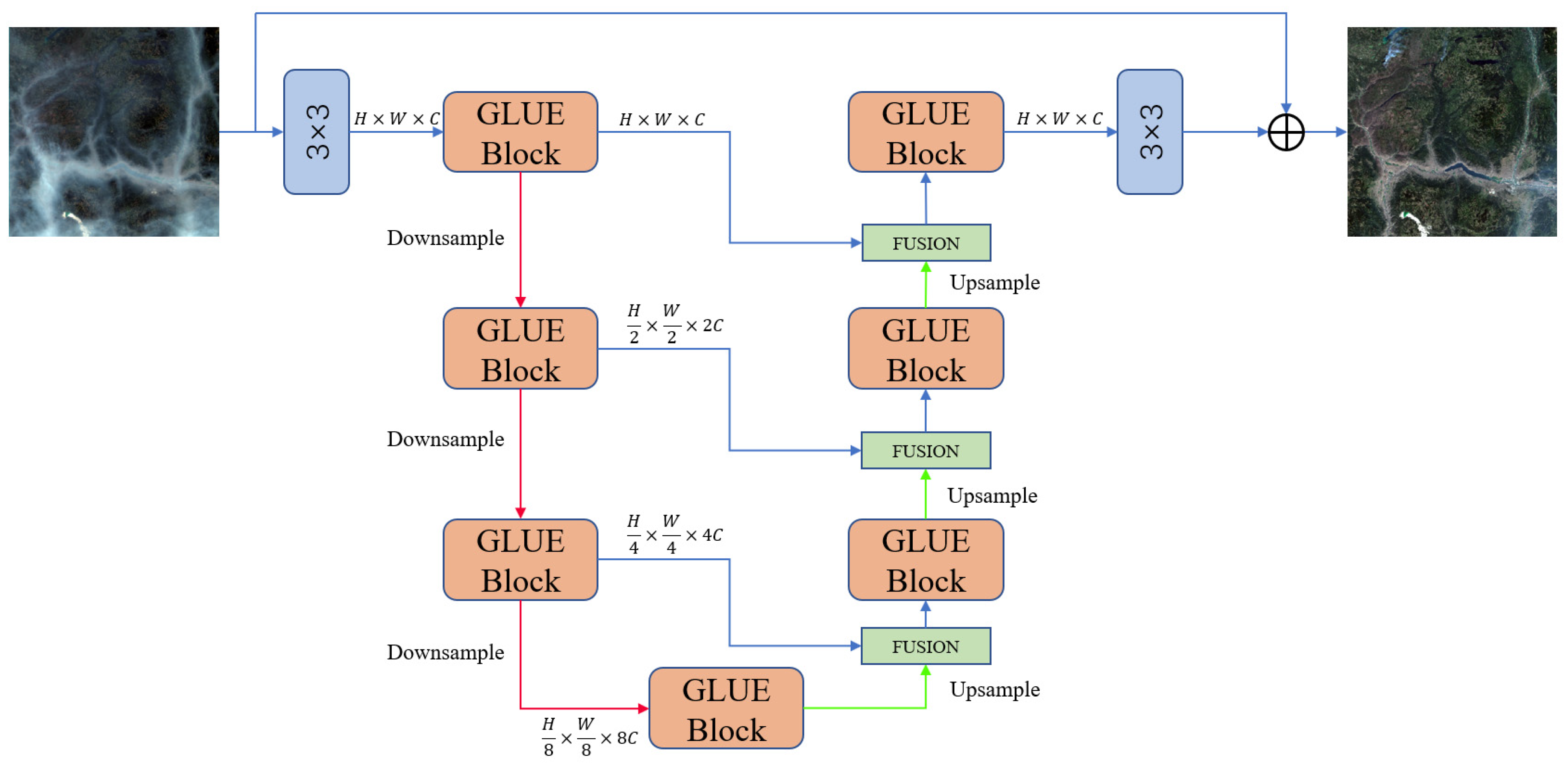
3. Proposed Method
3.1. Network Architecture
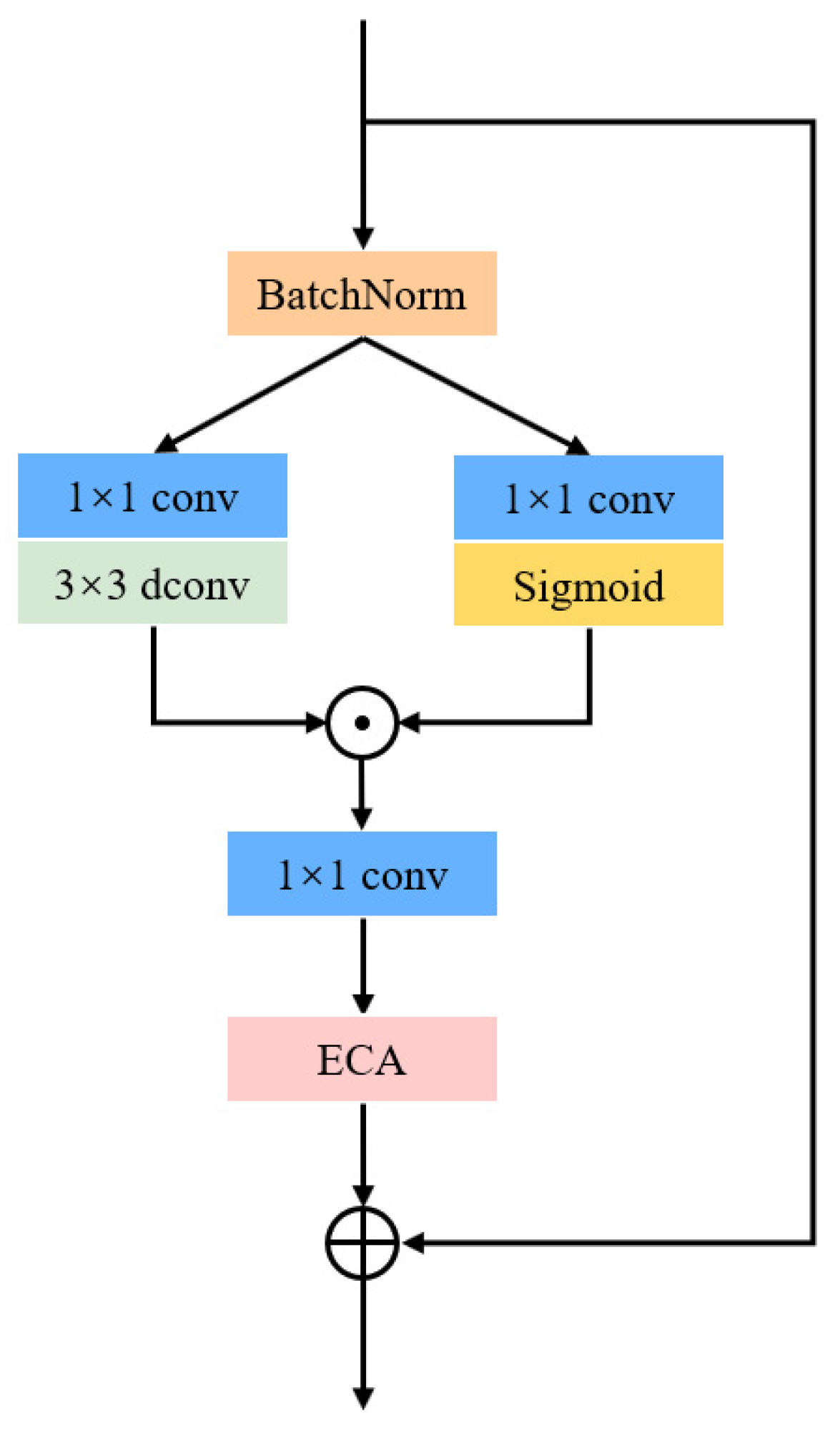
3.2. GLUE Block
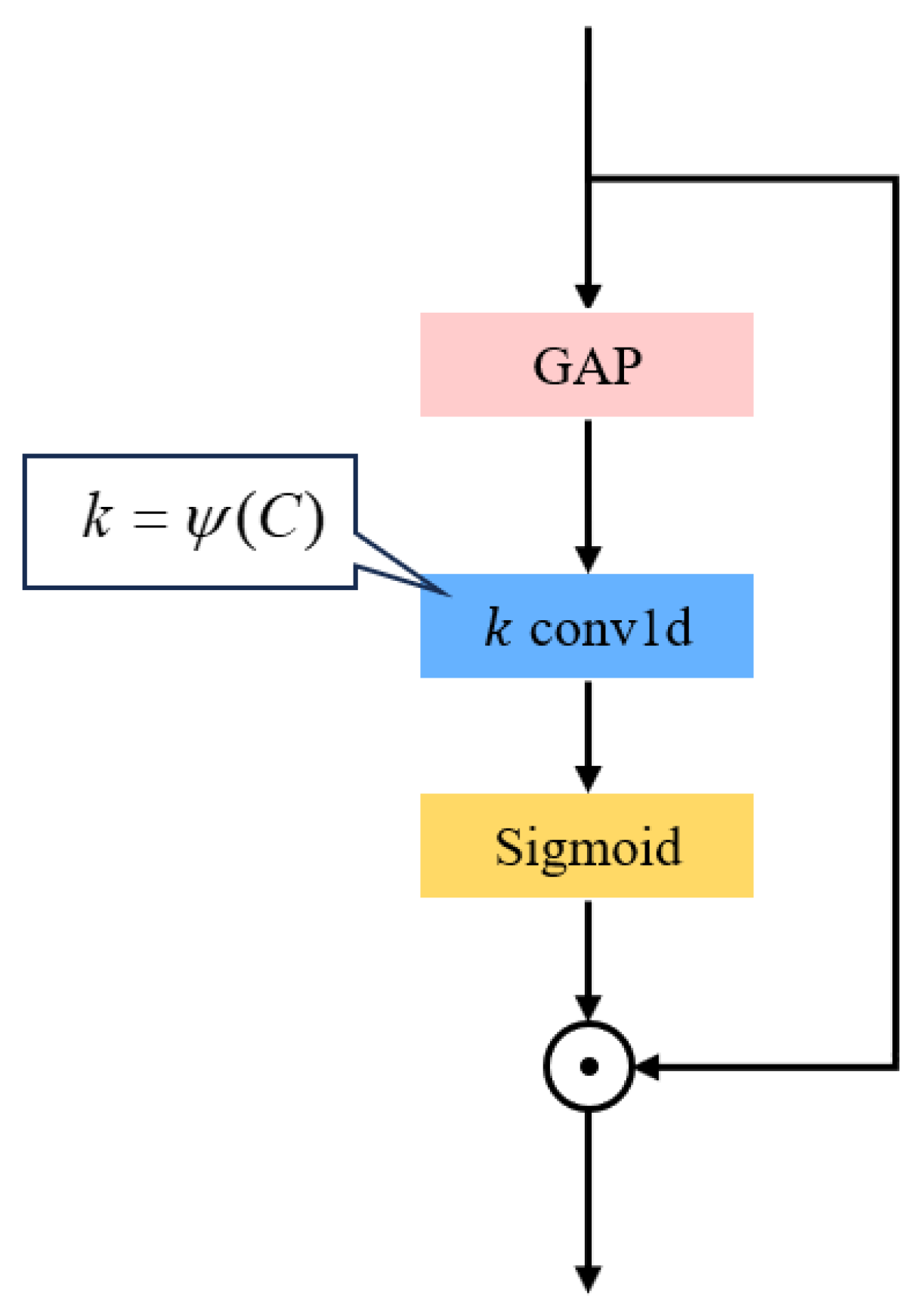
3.3. Efficient Channel Attention
3.4. Attention-Guided Fusion
4. Experimental Results
4.1. Dataset Generation
4.2. Experimental Settings
4.2.1. Datasets
4.2.2. Implementation Details
4.2.3. Evaluation Metric and Benchmark Methods
4.3. Quantitative Evaluations
4.3.1. Quantitative Evaluations on RSHaze Dataset
4.3.2. Quantitative Evaluations on RRSH Dataset
4.4. Qualitative Comparisons
4.4.1. Qualitative Comparisons on RSHaze Dataset
4.4.2. Qualitative Comparisons on RRSH Dataset
4.4.3. Qualitative Comparisons on Real Remote Sensing Images
4.5. Ablation Analysis
4.5.1. Effectiveness of GLUE Block
4.5.2. Effectiveness of ECA Fusion
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kotaridis, I.; Lazaridou, M. Remote Sensing Image Segmentation Advances: A Meta-Analysis. ISPRS J. Photogramm. Remote Sens. 2021, 173, 309–322. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A Survey on Deep Learning-Based Change Detection from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Berman, D.; Treibitz, T.; Avidan, S. Non-Local Image Dehazing. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1674–1682. [Google Scholar]
- Makarau, A.; Richter, R.; Muller, R.; Reinartz, P. Haze Detection and Removal in Remotely Sensed Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5895–5905. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4780–4788. [Google Scholar]
- Li, Y.; Chen, X. A Coarse-to-Fine Two-Stage Attentive Network for Haze Removal of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1751–1755. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. AAAI 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision Transformers for Single Image Dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple Baselines for Image Restoration. In Computer Vision—ECCV 2022; Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2022; Volume 13667, pp. 17–33. ISBN 978-3-031-20070-0. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5718–5729. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Nayar, S.K.; Narasimhan, S.G. Vision in Bad Weather. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 820–827. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Removing Weather Effects from Monochrome Images. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE Computer Society: Washington, DC, USA, 2001; Volume 2, pp. II-186–II-193. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9992–10002. [Google Scholar]
- Guo, J.; Yang, J.; Yue, H.; Tan, H.; Hou, C.; Li, K. RSDehazeNet: Dehazing Network with Channel Refinement for Multispectral Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2535–2549. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Q.; Feng, H.; Xu, Z.; Chen, Y. Nonuniformly Dehaze Network for Visible Remote Sensing Images. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 21–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 446–455. [Google Scholar]
- Li, S.; Zhou, Y.; Xiang, W. M2SCN: Multi-Model Self-Correcting Network for Satellite Remote Sensing Single-Image Dehazing. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Kulkarni, A.; Murala, S. Aerial Image Dehazing with Attentive Deformable Transformers. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6294–6303. [Google Scholar]
- He, Y.; Li, C.; Li, X. Remote Sensing Image Dehazing Using Heterogeneous Atmospheric Light Prior. IEEE Access 2023, 11, 18805–18820. [Google Scholar] [CrossRef]
- He, Y.; Li, C.; Bai, T. Remote Sensing Image Haze Removal Based on Superpixel. Remote Sens. 2023, 15, 4680. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, L.; Shen, Y.; Zhou, Y. RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing. IEEE Trans. Image Process. 2021, 30, 3391–3404. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, X.; Fan, Z.; Li, P.; Dai, L.; Kong, C.; Zheng, Z.; Huang, Y.; Li, Y. Unpaired Deep Image Dehazing Using Contrastive Disentanglement Learning. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2022; Volume 13677, pp. 632–648. ISBN 978-3-031-19789-5. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR—Proceedings of Machine Learning Research: Cambridge, MA, USA, 2017; Volume 70, pp. 933–941. [Google Scholar]
- Shazeer, N. GLU Variants Improve Transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MAXIM: Multi-Axis MLP for Image Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5769–5780. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Bai, H.; Pan, J.; Xiang, X.; Tang, J. Self-Guided Image Dehazing Using Progressive Feature Fusion. IEEE Trans. Image Process. 2022, 31, 1217–1229. [Google Scholar] [CrossRef] [PubMed]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset Of Georeferenced Multi-Spectral Sentinel-1/2 Imagery For Deep Learning And Data Fusion. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W7, 153–160. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Hu, Z.; Li, Z.; Wang, Y.; Molinier, M. Deep Learning Based Thin Cloud Removal Fusing Vegetation Red Edge and Short Wave Infrared Spectral Information for Sentinel-2A Imagery. Remote Sens. 2021, 13, 157. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the International Conference on Learning Representations, Touloun, France, 24–26 April 2017. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale Structural Similarity for Image Quality Assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 1398–1402. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. arXiv 2018, arXiv:1811.08747. [Google Scholar]
- Copernicus Browser. Available online: https://browser.dataspace.copernicus.eu/ (accessed on 29 February 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | RSHaze | Overhead | |||||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | FSIM | MS-SSIM | #Param (M) | MACs (G) | Latency (ms) | |
| DCP | 17.81 | 0.729 | 0.808 | 0.702 | - | - | - |
| AOD-Net | 26.67 | 0.858 | 0.888 | 0.840 | 0.002 | 0.115 | 14.67 |
| GCANet | 34.05 | 0.952 | 0.965 | 0.962 | 0.702 | 18.47 | 127.98 |
| FCFT-Net | 36.33 | 0.963 | 0.970 | 0.969 | 0.159 | 10 | 119.60 |
| DehazeFormer-B | 39.87 | 0.971 | 0.979 | 0.980 | 2.514 | 25.79 | 714.02 |
| GLUENet (ours) | 38.98 | 0.973 | 0.977 | 0.978 | 1.44 | 4.62 | 123.13 |
| Methods | RRSH | Overhead | |||||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | FSIM | MS-SSIM | #Param (M) | MACs (G) | Latency (ms) | |
| DCP | 18.77 | 0.723 | 0.862 | 0.820 | - | - | - |
| AOD-Net | 27.11 | 0.853 | 0.886 | 0.863 | 0.002 | 0.115 | 14.67 |
| GCANet | 27.61 | 0.888 | 0.913 | 0.901 | 0.702 | 18.47 | 127.98 |
| FCFT-Net | 32.31 | 0.925 | 0.927 | 0.920 | 0.159 | 10 | 119.60 |
| DehazeFormer-B | 33.26 | 0.925 | 0.935 | 0.931 | 2.514 | 25.79 | 714.02 |
| GLUENet(ours) | 33.57 | 0.938 | 0.938 | 0.934 | 1.44 | 4.62 | 123.13 |
| Setting | RSHaze | RRSH | Overhead | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | #Param (M) | MACs (G) | |
| plainnet | 37.62 | 0.969 | 32.98 | 0.933 | 1.42 | 4.60 |
| +glu | 37.67 | 0.970 | 33.16 | 0.935 | 1.42 | 4.38 |
| +glu+eca | 38.95 | 0.973 | 33.55 | 0.938 | 1.42 | 4.41 |
| +glu+efusion | 38.76 | 0.972 | 33.48 | 0.937 | 1.44 | 4.51 |
| +glu+eca+efusion | 38.98 | 0.973 | 33.57 | 0.938 | 1.44 | 4.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, J.; Wang, X.; Li, Y.; Zhang, X.; Zhang, B.; Gade, M. GLUENet: An Efficient Network for Remote Sensing Image Dehazing with Gated Linear Units and Efficient Channel Attention. Remote Sens. 2024, 16, 1450. https://doi.org/10.3390/rs16081450
Fang J, Wang X, Li Y, Zhang X, Zhang B, Gade M. GLUENet: An Efficient Network for Remote Sensing Image Dehazing with Gated Linear Units and Efficient Channel Attention. Remote Sensing. 2024; 16(8):1450. https://doi.org/10.3390/rs16081450
Chicago/Turabian StyleFang, Jiahao, Xing Wang, Yujie Li, Xuefeng Zhang, Bingxian Zhang, and Martin Gade. 2024. "GLUENet: An Efficient Network for Remote Sensing Image Dehazing with Gated Linear Units and Efficient Channel Attention" Remote Sensing 16, no. 8: 1450. https://doi.org/10.3390/rs16081450
APA StyleFang, J., Wang, X., Li, Y., Zhang, X., Zhang, B., & Gade, M. (2024). GLUENet: An Efficient Network for Remote Sensing Image Dehazing with Gated Linear Units and Efficient Channel Attention. Remote Sensing, 16(8), 1450. https://doi.org/10.3390/rs16081450