
A Deep Learning Localization Method for Acoustic Source via Improved Input Features and Network Structure


Abstract
1. Introduction
- A feature preprocessing scheme is proposed. To improve the localization accuracy, the feature processing step creates the multitime pressure and eigenvector feature (MTPEF). To enhance the localization robustness, the feature augmentation step expands the training datasets in environment parameters and target motion parameters.
- An inception and residual in-series network (IRSNet) is designed. To further improve the localization accuracy, the main module IRS concatenates inception modules and residual modules in the series, and the number of network parameters has been adjusted to account for the acoustic source localization problem.
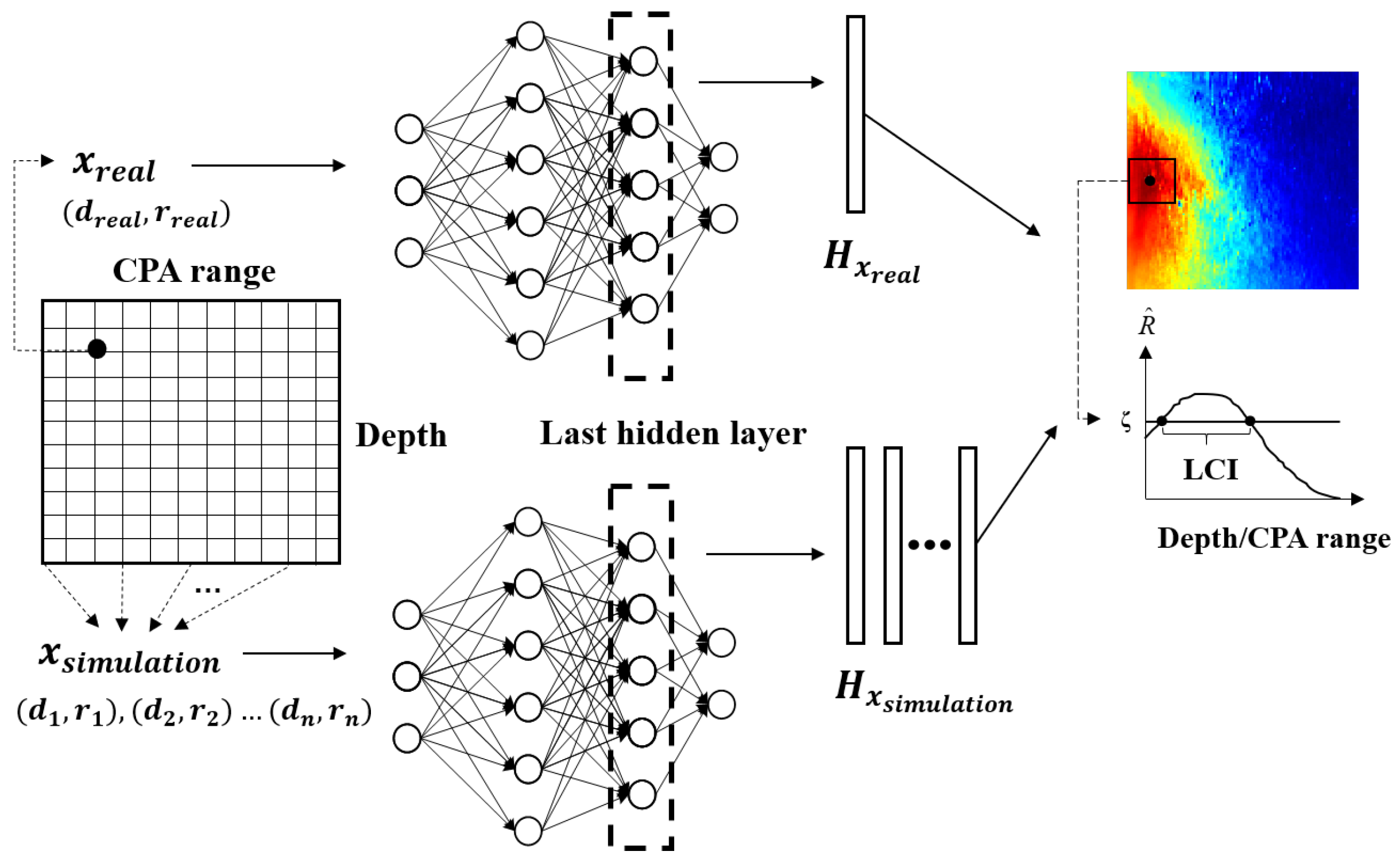
- A visualization method of the network is presented using hidden layer features. To optimize the estimated localization results, the localization confidence interval (LCI) is defined using the visualization method and can obtain the source position interval of high confidence.
2. Materials and Methods
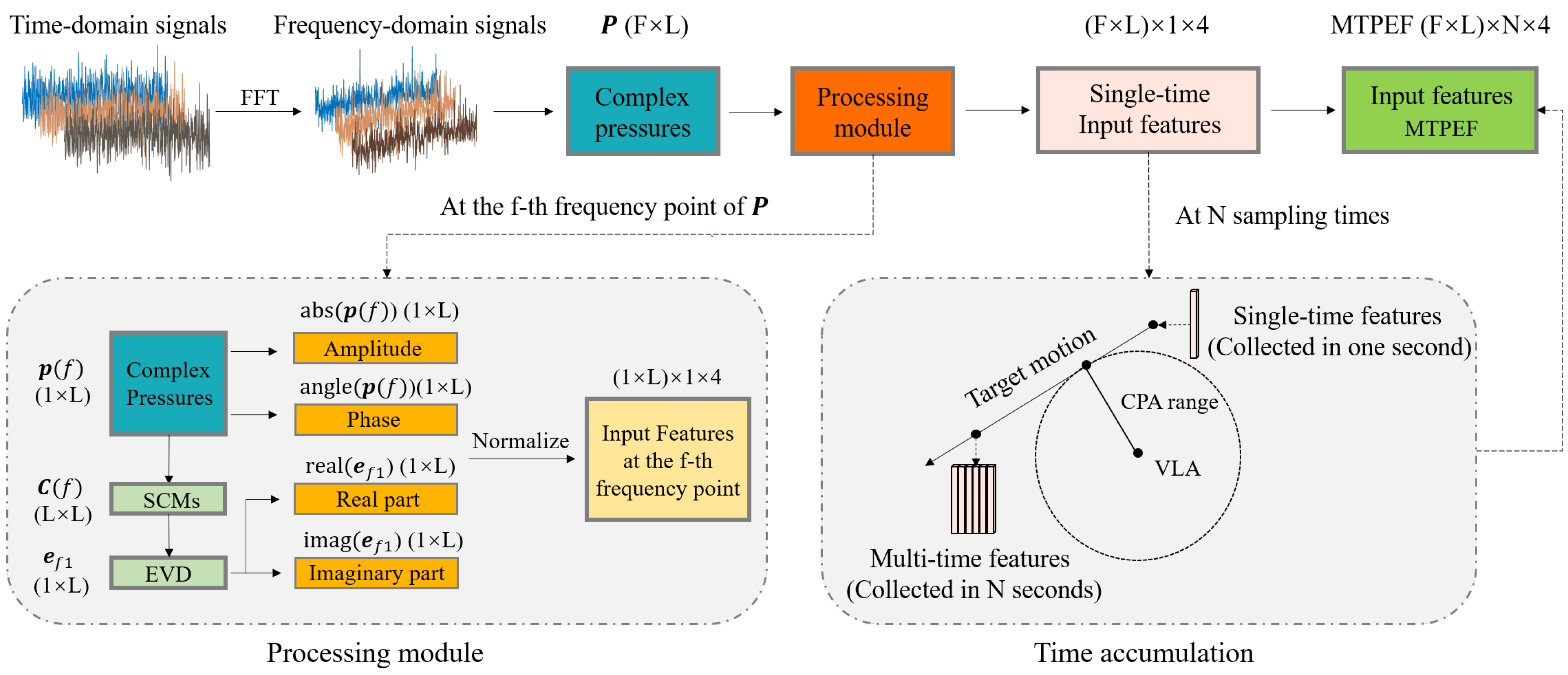
2.1. Features Preprocessing Module Design
2.1.1. Conventional Features
2.1.2. Features Processing
- We used complex pressure and eigenvector features at each sampling time as single-time input features. The complex pressure features are general features without complex preprocessing and retain much of the original information. The eigenvector features are specific features created by the SCMs using eigenvalue decomposition. They consume some original information but can better represent the nonlinear mapping relationship. When using the deep learning model, combining general and specific features often performs better than the features used alone.
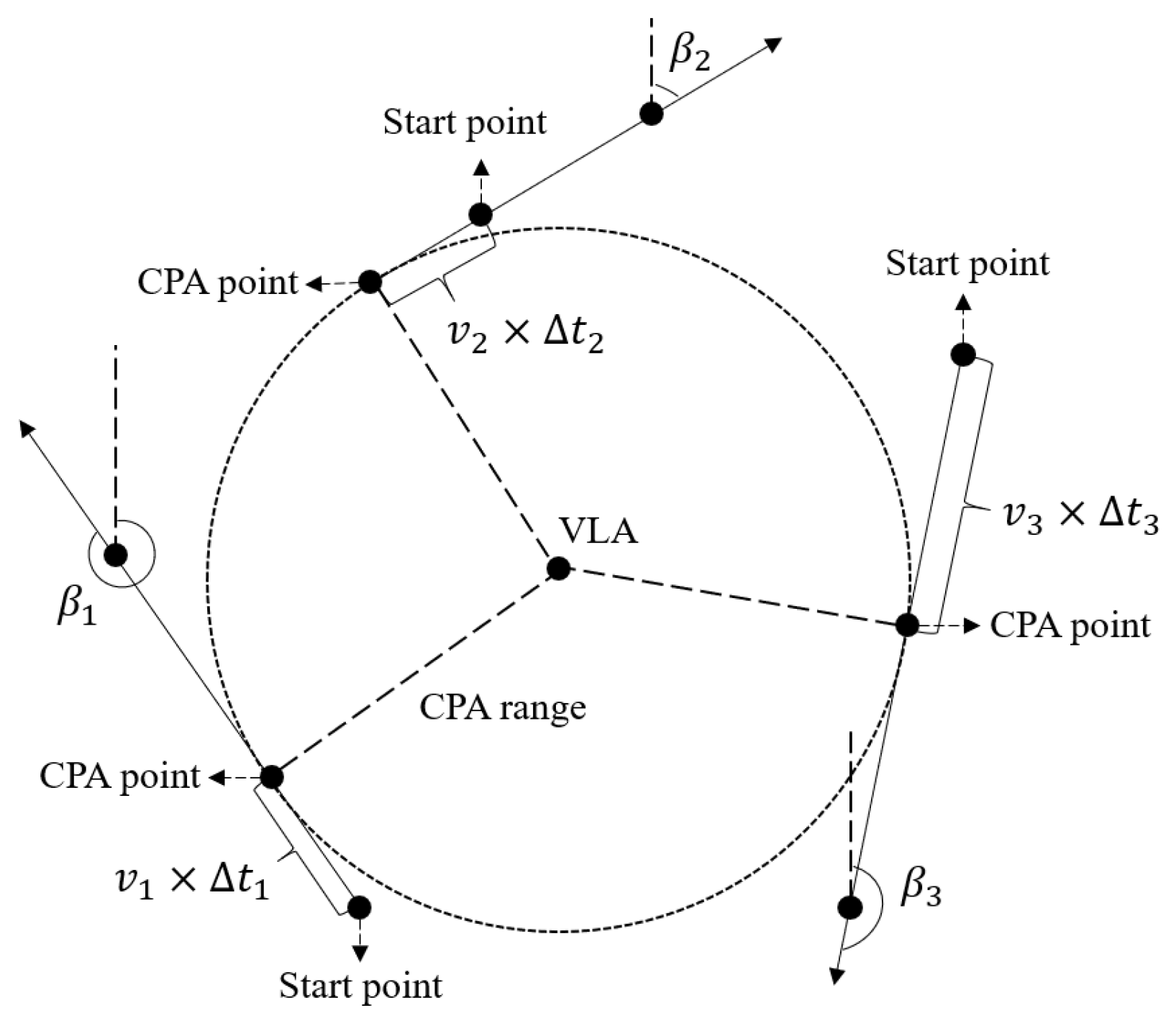
- We extended the single-time features to multitime features. In general, as the source moves for a period of time, the depth can be regarded as a constant, and the distance between the VLA and the source will change. The CPA range is a constant in this process, which can replace the distance. For the depth and the CPA range, the extension of the time domain dimension is equivalent to increasing the original information, and it will make the nonlinear relationship mentioned in Equation (1) more stable to learn.
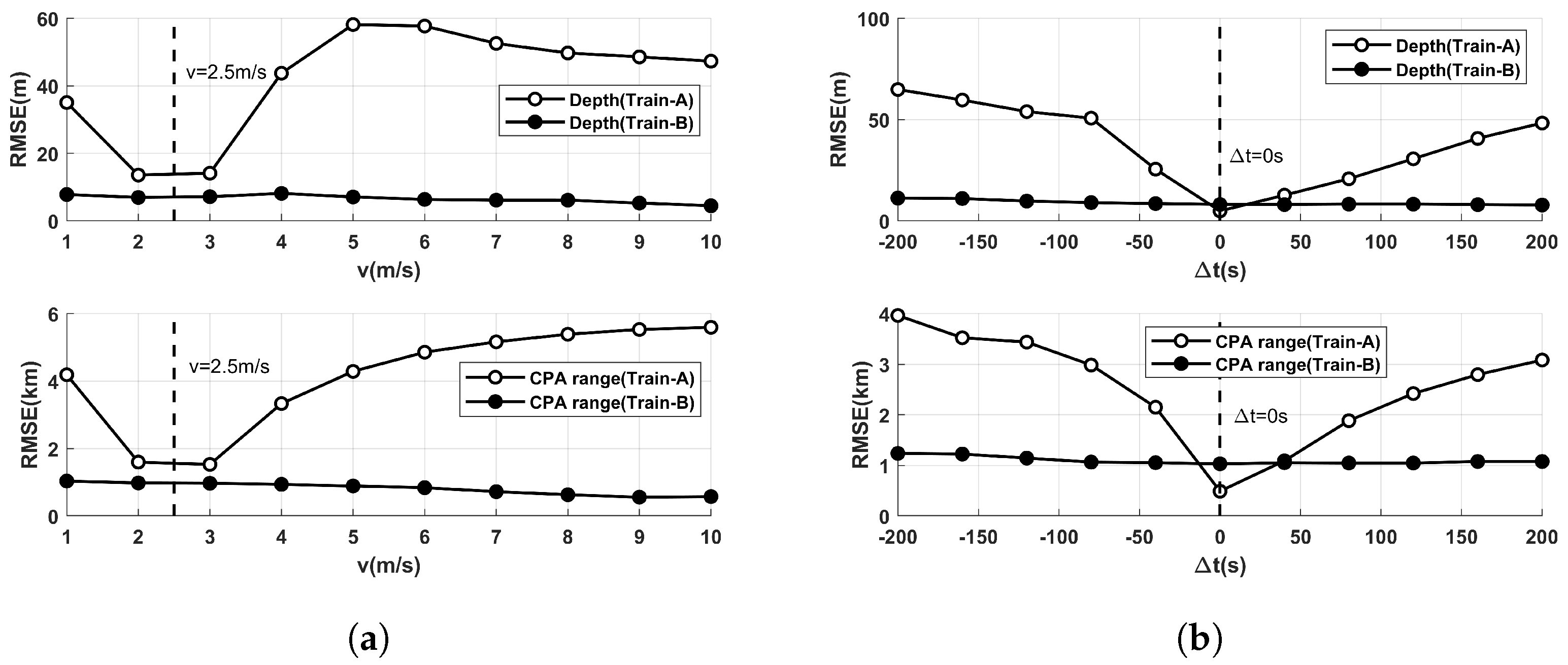
2.1.3. Features Augmentation


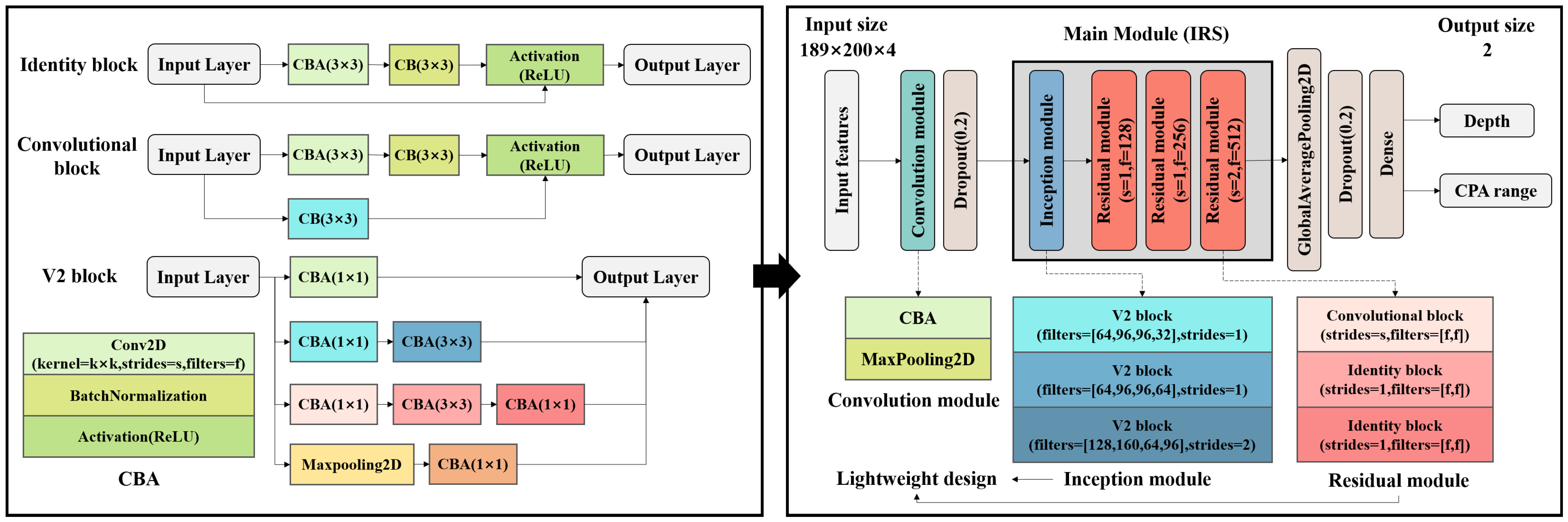
2.2. Deep Learning Network Design
2.2.1. Residual Module and Inception Module
2.2.2. Inception and Residual in Series Network
- The input features designed in Section 2.1 can be considered as image features that contain localization information for a period of time. To improve the understanding of features, the multiscale kernel was used to understand the information of different time and characteristic scales in input features. To prevent the abnormal degradation of network performance when deepening the layers, the structure of the residual module is the most suitable structure for suppressing overfitting.
- The complexity of the deep network structure should be appropriate: being too simple or too complex will affect network performance. To balance localization accuracy and training time, we carried out a lightweight design of the deep network structure and improved the training speed without losing the network localization accuracy.
- The IRS module was designed in series form rather than the nested form in [39]. This is because nested modules are very complex: the amount of training data for underwater acoustic localization problems makes it difficult to make the model converge.
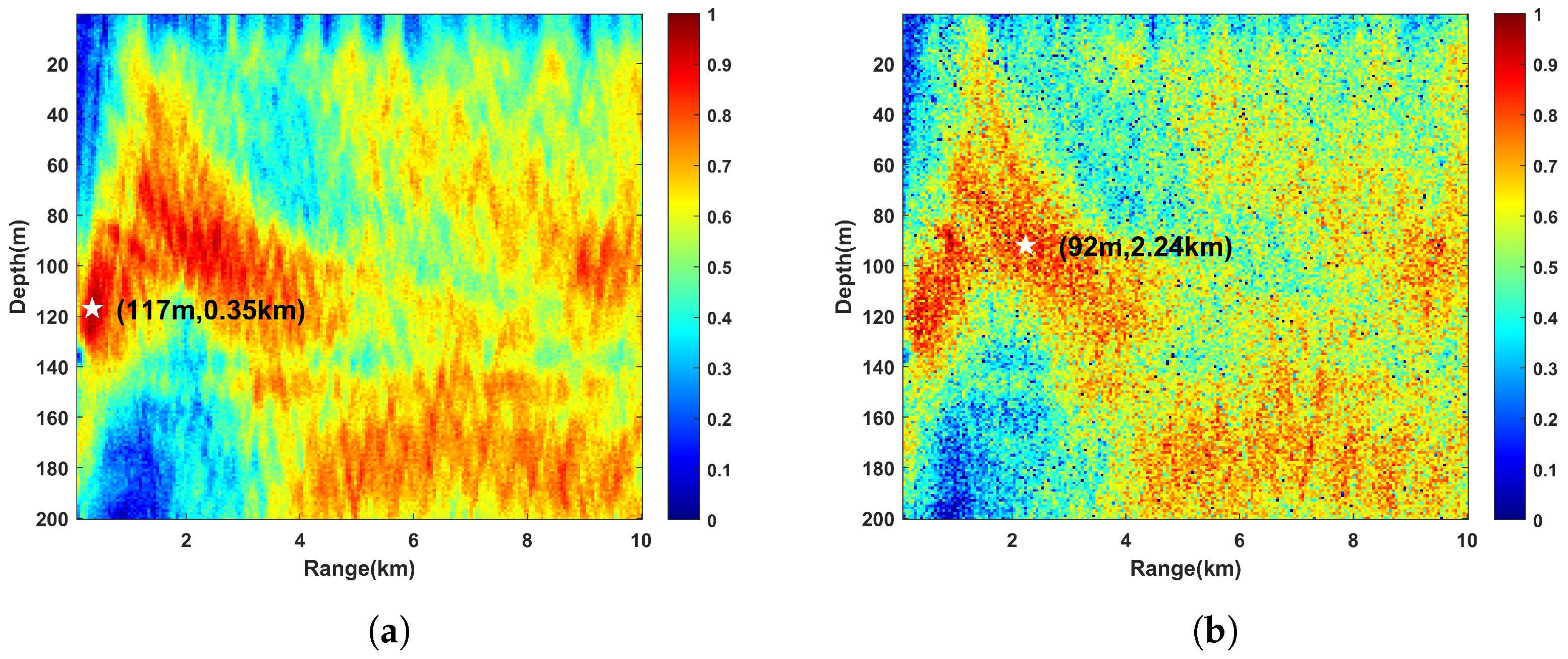
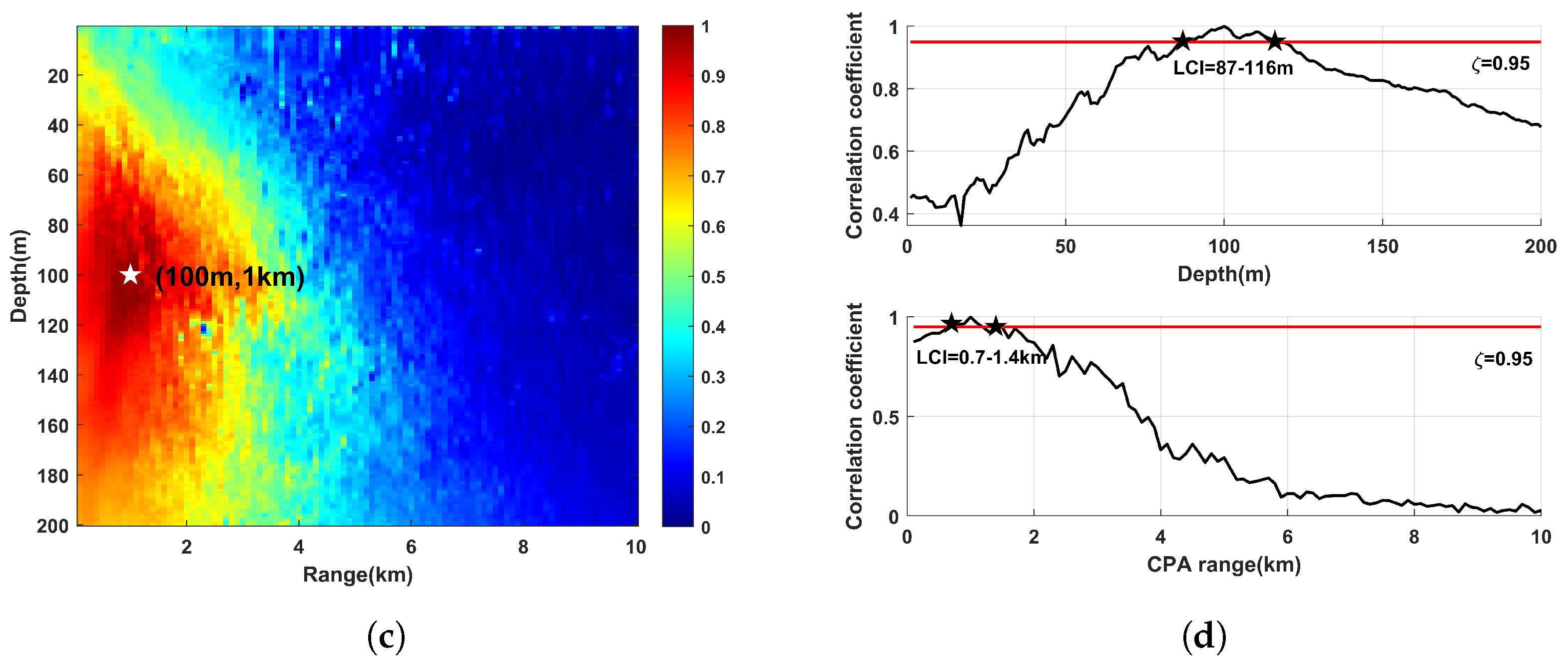
2.2.3. Localization Confidence Interval for Visualization
2.3. Experimental Settings
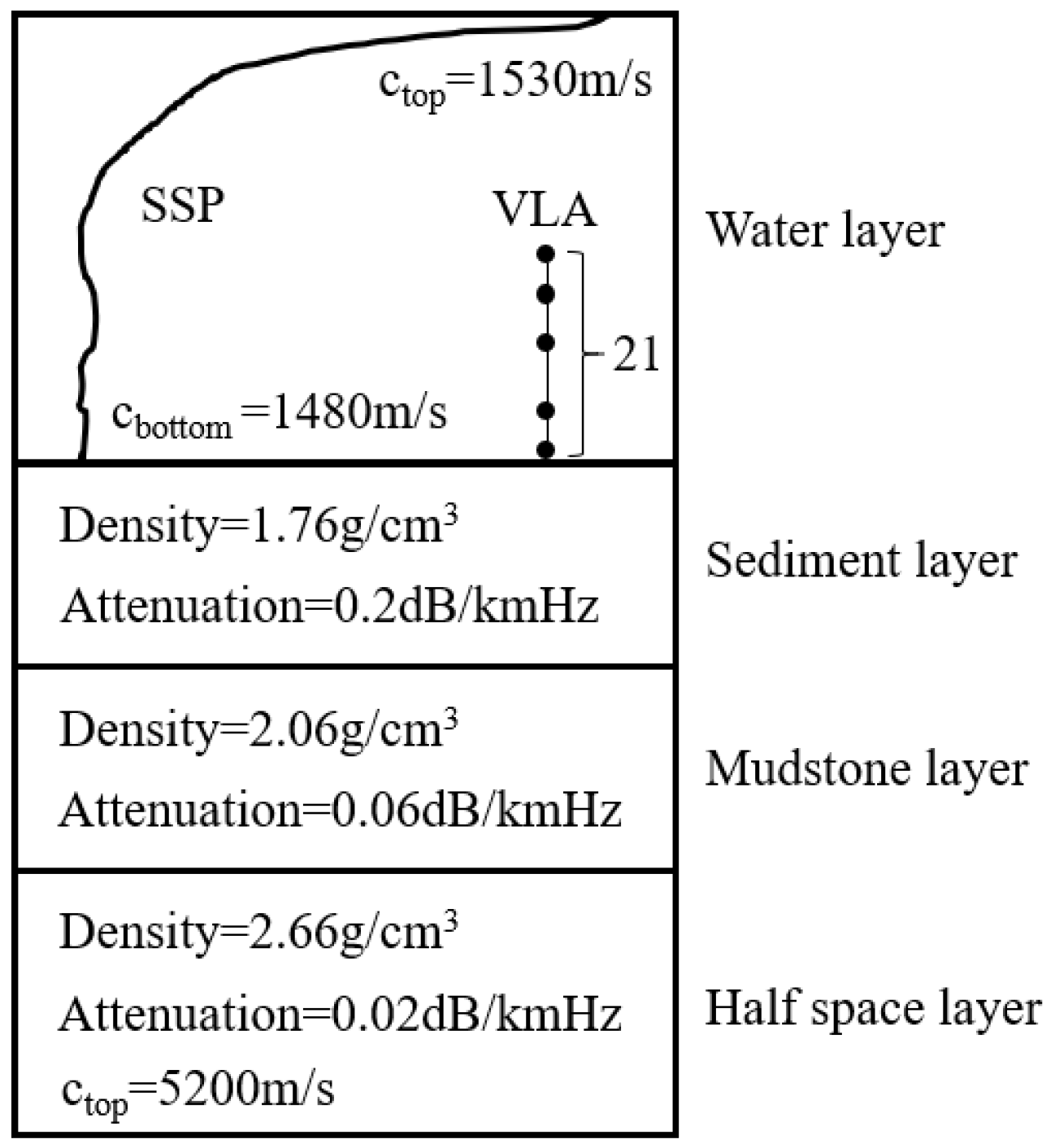
2.3.1. Simulation Datasets
2.3.2. Network Training
2.3.3. Evaluation Metrics
3. Results
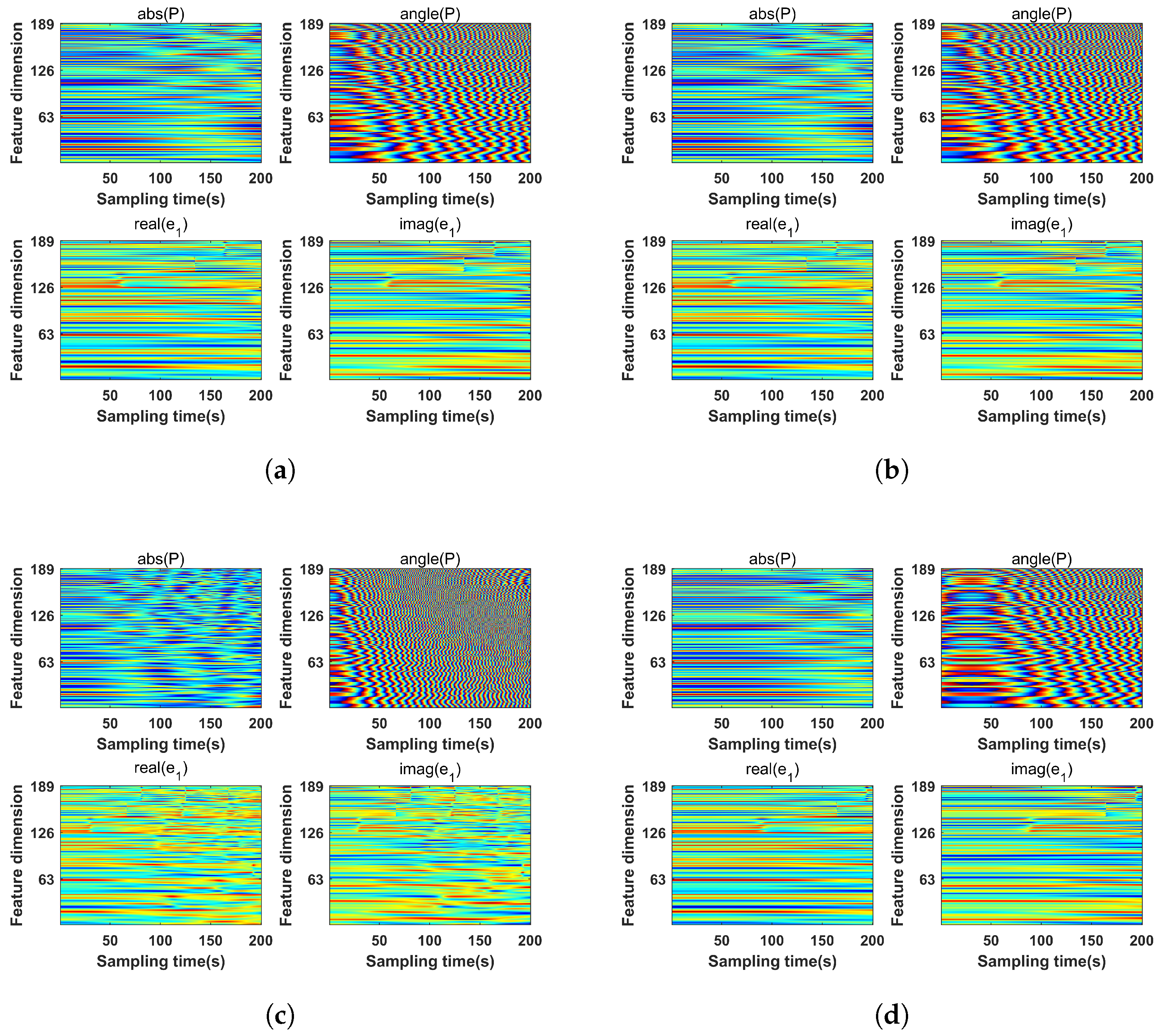
3.1. Different Input Features
3.2. Different Network Structures
- Compared the proposed IRSNet to the network structures that differ only in the main module, the localization accuracy of the IRSNet reached 3.657 m for the depth and 0.523 km for the CPA range. The network with only residual blocks and only inception modules was inferior to that of the IRSNet. The IRS module made the network localization accuracy further improved.
- The localization accuracies of the networks with residual modules and inception modules were generally better than that of the baseline network OriginNet. Deepening the network layers properly can not only improve the localization accuracy but also increase the training time. However, too many parameters can cause an increase in the RMSE, such as the results of the OriginNet with ResNet50 and the OriginNet with a 15 × V2 block. IRSNet has a reasonable number of parameters so that the network will not fall into overfitting. In addition, the lightweight transformation of the network reduces the training time without losing the localization accuracy.
- Compared the OriginNet with Inception-ResNet to the proposed IRSNet, although both structures use residual modules and inception modules together, the localization accuracy difference is huge. It shows that nesting inception modules and residual modules are too complicated and are not suitable structures for underwater acoustic localization. IRSNet connected the two kinds of modules in series and obtained a lower RMSE. In addition, the CNN-MTL [23] and CNN-Selkie3 [41] achieved good results in seabed parameter estimation, but the network structures could not directly transfer to the shallow water source localization because of the changes in input feature dimension and type. Improper network structures have a great influence on localization accuracy.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Structure | Parameter Number | Training Time (min) | (m) | (km) |
|---|---|---|---|---|
| OriginNet (baseline) | 40 | 7.720 | 0.920 | |
| OriginNet with ResNet18 | 73 | 4.647 | 0.755 | |
| OriginNet with ResNet34 | 120 | 3.993 | 0.660 | |
| OriginNet with ResNet50 | 177 | 12.930 | 1.758 | |
| OriginNet with 3 × V2 block | 77 | 4.074 | 0.634 | |
| OriginNet with 10 × V2 block | 153 | 3.721 | 0.668 | |
| OriginNet with 15 × V2 block | 187 | 5.178 | 0.972 | |
| OriginNet with Inception-ResNet | 227 | 21.097 | 2.433 | |
| CNN-Selkie3 | 83 | 17.357 | 2.016 | |
| CNN-MTL | 23 | 14.335 | 1.287 | |
| IRSNet (ours) | 106 | 3.657 | 0.523 |
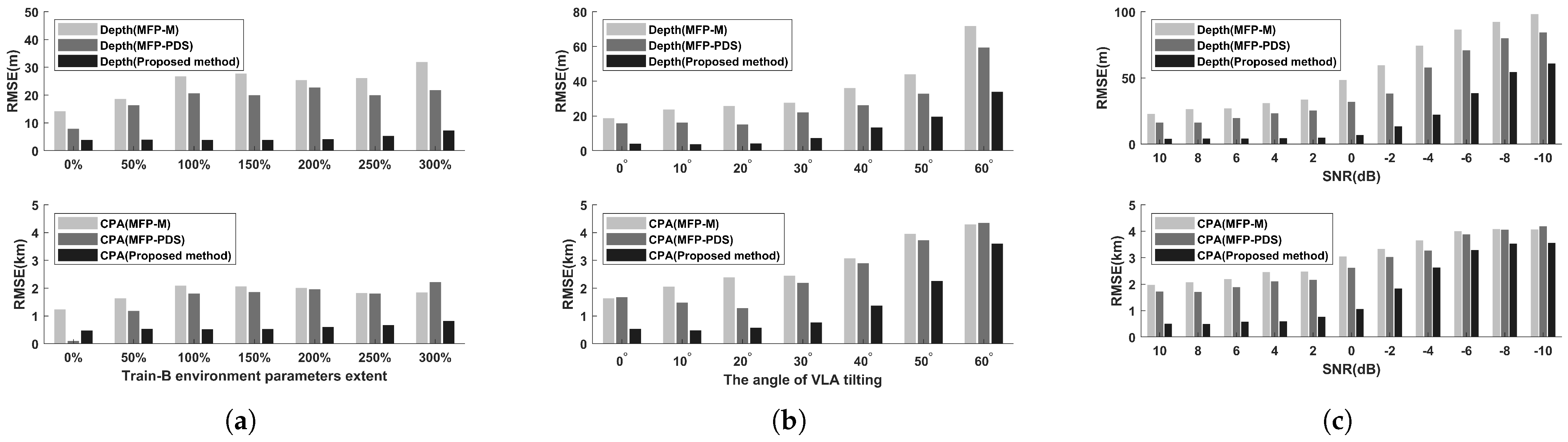
3.3. Comparison with Improved MFP Methods
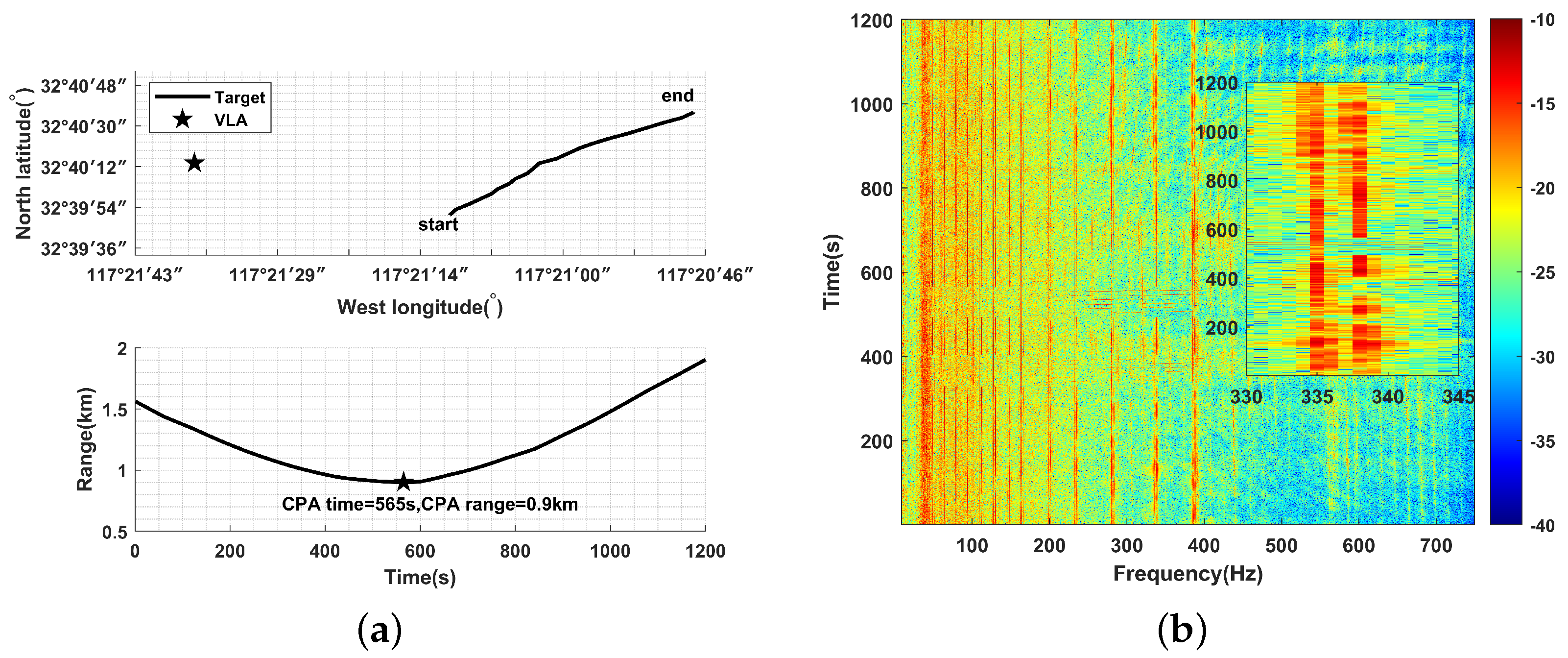
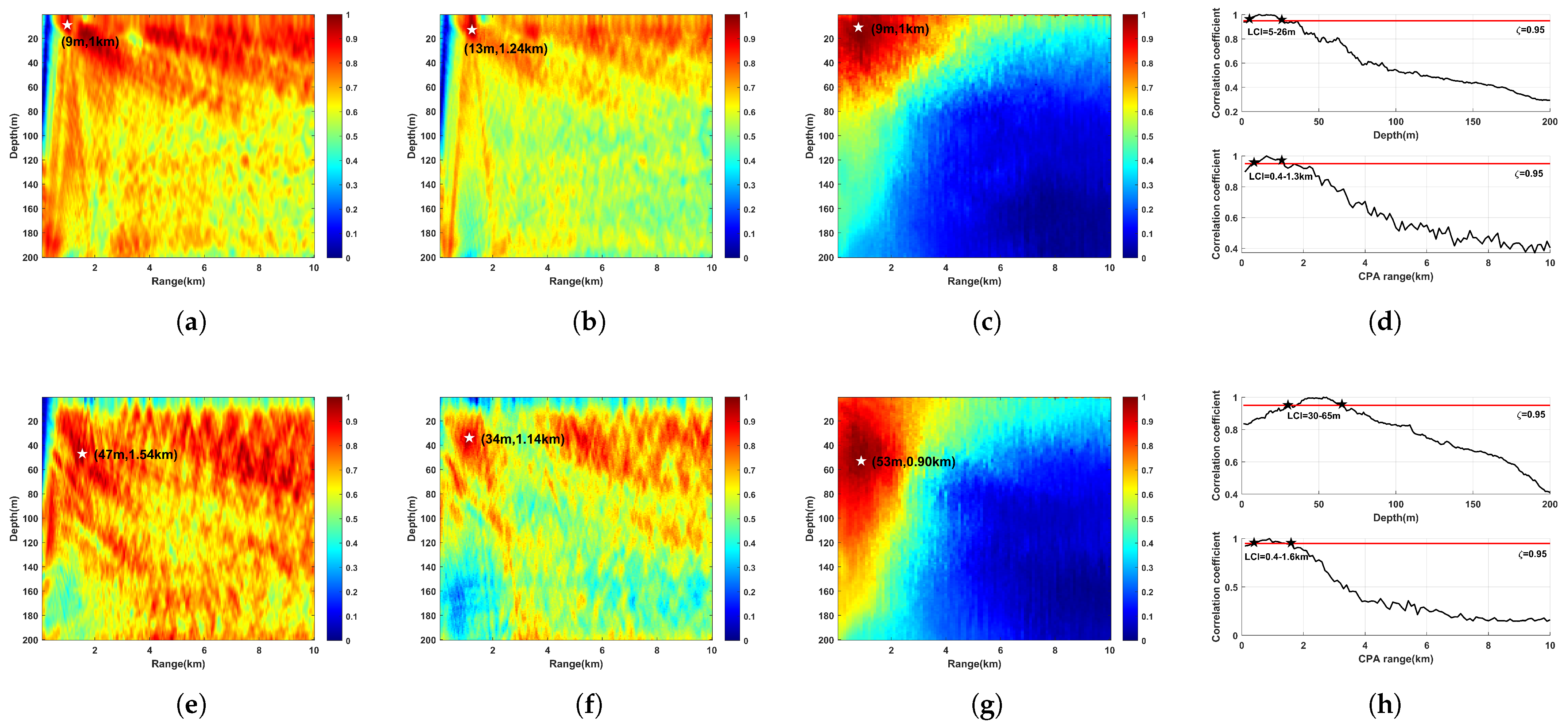
3.4. Evaluation on SWellEx-96 Experiment
| Method | Shallow Source | Deep Source | Running Time | ||
|---|---|---|---|---|---|
| Depth (Error) | CPA Range (Error) | Depth (Error) | CPA Range (Error) | ||
| MFP-M | 9 m (0 m) | 1 km (+0.1 km) | 47 m (−7 m) | 1.54 km (+0.64 km) | 7.2 s |
| MFP-PDS | 13 m (+4 m) | 1.24 km (+0.34 km) | 34 m (−20 m) | 1.14 km (+0.24 km) | 8.9 s |
| Proposed method | 9 m (0 m) | 1 km (0.1 km) | 53 m (−1 m) | 0.90 km (0 km) | 2 s |

4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, T.; Han, G.; Guizani, M.; Yan, L.; Shu, L. Peak Extraction Passive Source Localization Using a Single Hydrophone in Shallow Water. IEEE Trans. Veh. Technol. 2020, 69, 3412–3423. [Google Scholar] [CrossRef]
- Weiss, A.; Arikan, T.; Vishnu, H.; Deane, G.B.; Singer, A.C.; Wornell, G.W. A Semi-Blind Method for Localization of Underwater Acoustic Sources. IEEE Trans. Signal Process. 2022, 70, 3090–3106. [Google Scholar] [CrossRef]
- Le Gall, Y.; Socheleau, F.X.; Bonnel, J. Matched-Field Processing Performance Under the Stochastic and Deterministic Signal Models. IEEE Trans. Signal Process. 2014, 62, 5825–5838. [Google Scholar] [CrossRef]
- Finette, S.; Mignerey, P.C. Stochastic matched-field localization of an acoustic source based on principles of Riemannian geometry. J. Acoust. Soc. Am. 2018, 143, 3628–3638. [Google Scholar] [CrossRef] [PubMed]
- Westwood, E.K. Broadband matched-field source localization. J. Acoust. Soc. Am. 1992, 91, 2777–2789. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Z.; Yan, J.; Peng, Z.; Li, F. Broad-band matched-field source localization in the east China Sea. IEEE J. Ocean. Eng. 2004, 29, 1049–1054. [Google Scholar] [CrossRef]
- Michalopoulou, Z.H.; Pole, A.; Abdi, A. Bayesian coherent and incoherent matched-field localization and detection in the ocean. J. Acoust. Soc. Am. 2019, 146, 4812–4820. [Google Scholar] [CrossRef] [PubMed]
- Virovlyansky, A.L.; Kazarova, A.Y.; Lyubavin, L.Y. Matched Field Processing in Phase Space. IEEE J. Ocean. Eng. 2020, 45, 1583–1593. [Google Scholar] [CrossRef]
- Orris, G.J.; Nicholas, M.; Perkins, J.S. The matched-phase coherent multi-frequency matched-field processor. J. Acoust. Soc. Am. 2000, 107, 2563–2575. [Google Scholar] [CrossRef]
- Chen, T.; Liu, C.; Zakharov, Y.V. Source Localization Using Matched-Phase Matched-Field Processing With Phase Descent Search. IEEE J. Ocean. Eng. 2012, 37, 261–270. [Google Scholar] [CrossRef]
- Yang, T. Data-based matched-mode source localization for a moving source. J. Acoust. Soc. Am. 2014, 135, 1218–1230. [Google Scholar] [CrossRef] [PubMed]
- Virovlyansky, A. Stable components of sound fields in the ocean. J. Acoust. Soc. Am. 2017, 141, 1180–1189. [Google Scholar] [CrossRef] [PubMed]
- Aravindan, S.; Ramachandran, N.; Naidu, P.S. Fast matched field processing. IEEE J. Ocean. Eng. 1993, 18, 1–5. [Google Scholar] [CrossRef][Green Version]
- Sun, Z.; Meng, C.; Cheng, J.; Zhang, Z.; Chang, S. A multi-scale feature pyramid network for detection and instance segmentation of marine ships in SAR images. Remote Sens. 2022, 14, 6312. [Google Scholar] [CrossRef]
- Zhu, X.C.; Zhang, H.; Feng, H.T.; Zhao, D.H.; Zhang, X.J.; Tao, Z. IFAN: An Icosahedral Feature Attention Network for Sound Source Localization. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Li, Y.; Si, Y.; Tong, Z.; He, L.; Zhang, J.; Luo, S.; Gong, Y. MQANet: Multi-Task Quadruple Attention Network of Multi-Object Semantic Segmentation from Remote Sensing Images. Remote Sens. 2022, 14, 6256. [Google Scholar] [CrossRef]
- Bianco, M.J.; Gerstoft, P.; Traer, J.; Ozanich, E.; Roch, M.A.; Gannot, S.; Deledalle, C.A. Machine learning in acoustics: Theory and applications. J. Acoust. Soc. Am. 2019, 146, 3590–3628. [Google Scholar] [CrossRef] [PubMed]
- Michalopoulou, Z.H.; Gerstoft, P.; Kostek, B.; Roch, M.A. Introduction to the special issue on machine learning in acoustics. J. Acoust. Soc. Am. 2021, 150, 3204–3210. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Wang, Y.; Zhang, L.; Chen, B.; Yu, X. Underwater Multitarget Tracking Method Based on Threshold Segmentation. IEEE J. Ocean. Eng. 2023, 48, 1255–1269. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, H. Underwater acoustic source localization using generalized regression neural network. J. Acoust. Soc. Am. 2018, 143, 2321–2331. [Google Scholar] [CrossRef]
- Niu, H.; Reeves, E.; Gerstoft, P. Source localization in an ocean waveguide using supervised machine learning. J. Acoust. Soc. Am. 2017, 142, 1176–1188. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Dong, H.; Salvo Rossi, P.; Landrø, M. Feature selection based on principal component regression for underwater source localization by deep learning. Remote Sens. 2021, 13, 1486. [Google Scholar] [CrossRef]
- Neilsen, T.; Escobar-Amado, C.; Acree, M.; Hodgkiss, W.; Van Komen, D.; Knobles, D.; Badiey, M.; Castro-Correa, J. Learning location and seabed type from a moving mid-frequency source. J. Acoust. Soc. Am. 2021, 149, 692–705. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Jia, Z.; Teng, T.; Ma, C. Robust high-resolution direction-of-arrival estimation method using DenseBlock-based U-net. J. Acoust. Soc. Am. 2022, 151, 3426–3436. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Liu, T.; Wang, Y.; Zhang, G.; Liu, K.; Wang, Y. High-rate underwater acoustic localization based on the decision tree. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4204912. [Google Scholar] [CrossRef]
- Niu, H.; Gong, Z.; Ozanich, E.; Gerstoft, P.; Wang, H.; Li, Z. Deep-learning source localization using multi-frequency magnitude-only data. J. Acoust. Soc. Am. 2019, 146, 211–222. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Xu, J.; Gong, Z.; Wang, H.; Yan, Y. Source localization using deep neural networks in a shallow water environment. J. Acoust. Soc. Am. 2018, 143, 2922–2932. [Google Scholar] [CrossRef]
- Qian, P.; Gan, W.; Niu, H.; Ji, G.; Li, Z.; Li, G. A feature-compressed multi-task learning U-Net for shallow-water source localization in the presence of internal waves. Appl. Acoust. 2023, 211, 109530. [Google Scholar] [CrossRef]
- Wang, W.; Ni, H.; Su, L.; Hu, T.; Ren, Q.; Gerstoft, P.; Ma, L. Deep transfer learning for source ranging: Deep-sea experiment results. J. Acoust. Soc. Am. 2019, 146, EL317–EL322. [Google Scholar] [CrossRef]
- Agrawal, S.; Sharma, D.K. Feature extraction and selection techniques for time series data classification: A comparative analysis. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 23–25 March 2022; pp. 860–865. [Google Scholar]
- Richardson, A.; Nolte, L. A posteriori probability source localization in an uncertain sound speed, deep ocean environment. J. Acoust. Soc. Am. 1991, 89, 2280–2284. [Google Scholar] [CrossRef]
- Schaeffer-Filho, A.; Smith, P.; Mauthe, A.; Hutchison, D.; Yu, Y.; Fry, M. A framework for the design and evaluation of network resilience management. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 401–408. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lu, N.; Li, T.; Ren, X.; Miao, H. A deep learning scheme for motor imagery classification based on restricted Boltzmann machines. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 566–576. [Google Scholar] [CrossRef] [PubMed]
- Saha, A.; Rathore, S.S.; Sharma, S.; Samanta, D. Analyzing the difference between deep learning and machine learning features of EEG signal using clustering techniques. In Proceedings of the 2019 IEEE Region 10 Symposium (TENSYMP), Kolkata, India, 7–9 June 2019; pp. 660–664. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Van Komen, D.F.; Neilsen, T.B.; Mortenson, D.B.; Acree, M.C.; Knobles, D.P.; Badiey, M.; Hodgkiss, W.S. Seabed type and source parameters predictions using ship spectrograms in convolutional neural networks. J. Acoust. Soc. Am. 2021, 149, 1198–1210. [Google Scholar] [CrossRef] [PubMed]









| Environment and Target Motion Parameters | Train-A | Train-B | Validation Dataset |
|---|---|---|---|
| Water layer depth (m) | 220 | 220–240 | 220 |
| Sediment layer depth (m) | 19 | 10–30 | 19 |
| Sound velocity at the top of sediment layer (m/s) | 1550 | 1530–1570 | 1550 |
| Mudstone layer depth (m) | 800 | 780–820 | 800 |
| Sound velocity at the top of mudstone layer (m/s) | 1881 | 1860–1900 | 1881 |
| Source velocity (m/s) | 2.5 | 1–10 | 2.5 |
| Time difference (s) | 0 | (−200)–200 | 0 |
| Features | Element (at Each Frequency Point) | (m) | (km) |
|---|---|---|---|
| PEF | 15.646 | 1.165 | |
| MTPF | 9.385 | 1.001 | |
| MTEF | 8.733 | 1.094 | |
| MTPEF (ours) | 7.722 | 0.921 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, D.; Fu, X.; Teng, T. A Deep Learning Localization Method for Acoustic Source via Improved Input Features and Network Structure. Remote Sens. 2024, 16, 1391. https://doi.org/10.3390/rs16081391
Sun D, Fu X, Teng T. A Deep Learning Localization Method for Acoustic Source via Improved Input Features and Network Structure. Remote Sensing. 2024; 16(8):1391. https://doi.org/10.3390/rs16081391
Chicago/Turabian StyleSun, Dajun, Xiaoying Fu, and Tingting Teng. 2024. "A Deep Learning Localization Method for Acoustic Source via Improved Input Features and Network Structure" Remote Sensing 16, no. 8: 1391. https://doi.org/10.3390/rs16081391
APA StyleSun, D., Fu, X., & Teng, T. (2024). A Deep Learning Localization Method for Acoustic Source via Improved Input Features and Network Structure. Remote Sensing, 16(8), 1391. https://doi.org/10.3390/rs16081391