1. Introduction
The Landsat satellite series provides the longest record of land observations from space, and the >10 million images sensed since 1972 are archived and processed by the United States Geological Survey (USGS) into radiometrically calibrated, geolocated, and atmospherically corrected images [
1]. The most recently processed Collection 2 Landsat data sensed by the Thematic Mapper (TM) (Landsat 4 and 5), Enhanced Thematic Mapper Plus (ETM+) (Landsat 7), Operational Land Imager (OLI), and Thermal Infrared Sensor (TIRS) (Landsat 8 and 9) instruments are provided with cloud and shadow masks so that contaminated pixels may be discarded prior to analysis [
2]. Accurate cloud and shadow classification is challenging, particularly over cold and highly reflective surfaces, or over dark surfaces, that are spectrally similar to clouds and shadows, respectively [
3,
4,
5,
6]. The need for improved Landsat cloud detection in the next Landsat collection has been recognized [
2]. In this paper, we present research to develop improved cloud and cloud shadow masking suitable for global application to Landsat OLI data using a recent deep learning attention model.
The Landsat sensors were not designed for cloud property investigations and lack the appropriate spectral bands and sensor design found on dedicated cloud and atmospheric satellite remote sensing systems [
7,
8,
9,
10]. Consequently, physically based cloud and cloud shadow detection algorithms have not been developed for Landsat, and instead, algorithms have used supervised classification or empirical spectral test-based approaches. Clouds are dynamic with considerable spatial, seasonal, and diurnal variation; have variable morphology, water vapor content, and height; and often co-exist at different altitudes [
11,
12,
13]. Consequently, conventional supervised classification algorithms that are applied to individual Landsat pixels, using classifiers such as decision trees [
14,
15,
16], artificial neural networks [
16,
17], and random forests [
18,
19], are challenging to train in a globally representative manner and apply to provide globally reliable results. A number of empirical cloud detection algorithms have been developed that apply spectral tests to individual Landsat pixels [
20,
21,
22,
23,
24]. Cloud shadow detection algorithms have also been developed and typically first require a cloud mask and use the sun-cloud-sensor geometry with an assumed or approximately estimated cloud height (based on brightness temperature for Landsat sensors with thermal bands) to locate potentially shaded areas, followed by spectral tests to refine the locations of shadow pixels [
25,
26,
27,
28]. In addition, algorithms using time series images have also been developed by assuming that cloud changes more rapidly than land surface [
4,
6,
29,
30]). The Landsat cloud and cloud shadow masks are generated using a version of the empirical Fmask cloud and cloud shadow detection algorithms [
2].
In the last decade, a number of deep learning algorithms using convolutional neural networks have been developed for Landsat cloud and cloud shadow detection (summarized in
Appendix A). Rather than be applied to individual pixels, they are applied to square image subsets, termed patches, and the spatial relationships within the patch provide additional information for cloud and shadow detection. The trained network is applied to image patches translated across the image to classify each patch center pixel. Fully convolutional networks (FCN) [
31] classify all the patch pixels, rather than the center pixel, and most recent Landsat cloud/shadow deep learning architectures use some form of FCN [
32,
33]. In particular, the U-Net model has been adopted because it preserves spatial detail by using skip connections between low-level and high-level features [
34]. For example, [
32,
33,
35,
36,
37,
38] used U-Net for cloud detection, although other architectures such as SegNET [
39] and DeepLab [
40] have also been used. Most models are implemented with patch spatial dimensions varying from 86 × 86 to 512 × 512 30 m pixels and using the OLI visible and short wavelength bands. Of the deep learning algorithms summarized in
Appendix A, only a minority also used the TIRS bands. Deep learning algorithms that detect clouds and shadows separately have been developed [
41,
42] although this may result in the incorrect detection of both cloud and cloud shadows at the same pixel location. All the Landsat deep learning algorithms summarized in
Appendix A were trained and evaluated using publicly available annotated datasets derived by visual interpretation of 185 × 180 km Landsat images [
22] or image spatial subsets [
17].
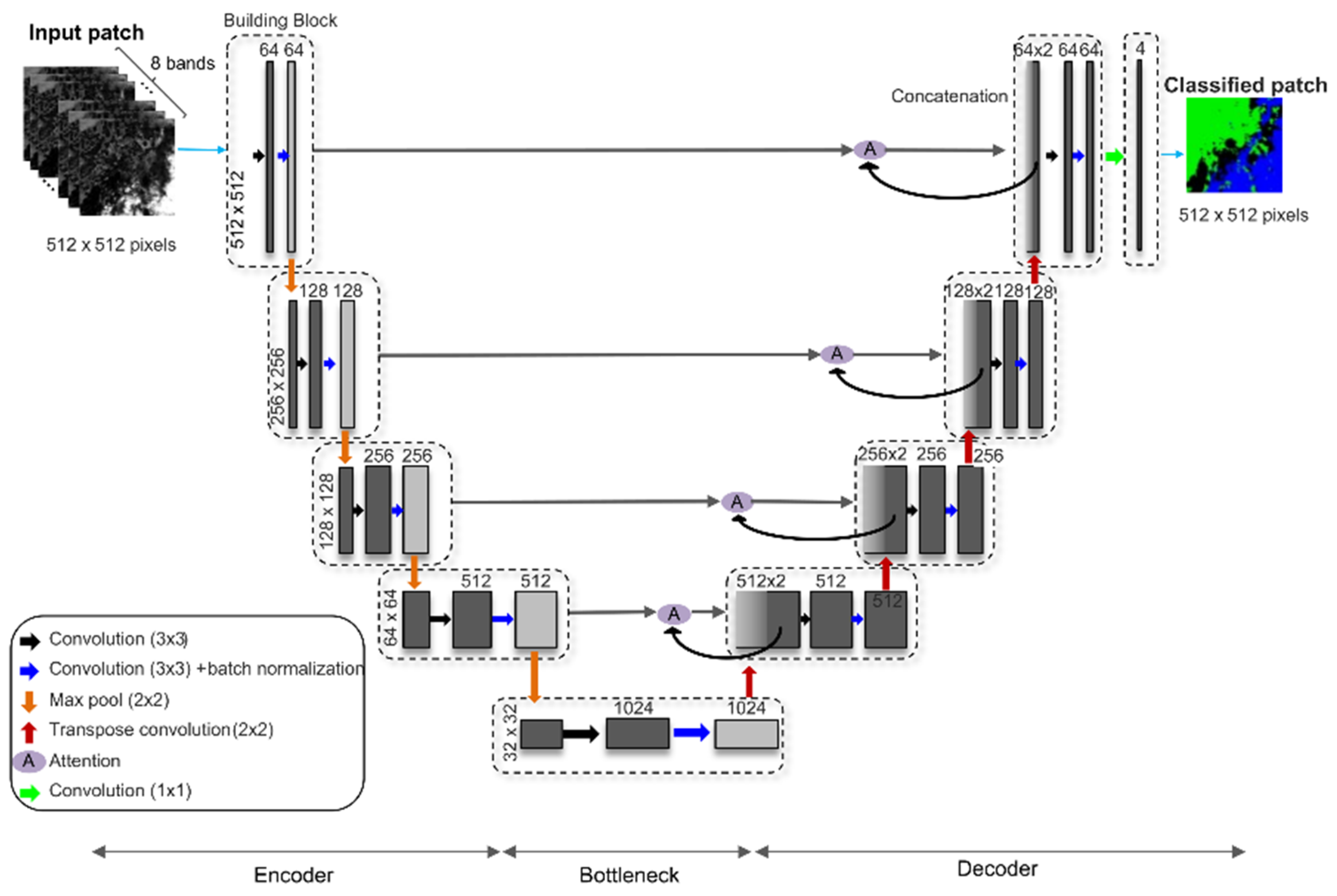
We present a new Landsat 8/9 OLI cloud and cloud shadow masking algorithm that classifies pixels as either clear, thin cloud, cloud, or cloud shadow. The algorithm is called the Learning Attention Network Algorithm (LANA) and is designed for application to OLI imagery acquired over global land surfaces, including snow and coastal/inland water. The LANA is a form of U-Net with an additional attention mechanism that reduces small receptive field (a small local spatial window around a patch pixel that determines the feature values for the pixel) issues. The issues often present in convolution-based deep learning structures are that the feature values for a pixel location in a two-dimensional feature map (derived by a convolutional layer) may be determined by only a small local spatial window around the pixel [
43,
44]. The attention mechanism was developed to capture long-range structure among pixels [
45,
46] in image classification, which was inspired by the attention success in machine translation each word generation needs to attend to all the input words in the to-be-translated sentence to address the grammar difference [
47,
48]. This may be helpful for detection of cloud shadows that always occur to the west of clouds in Landsat imagery because the sun is in the East for the majority of global land areas except at very high latitudes due to the Landsat morning overpass time [
49]. The offsets can be quite large relative to 30 m pixel dimensions. For example, shadows will be offset from clouds by 3.76 km and 6.92 km, considering a cloud with a global average 4.0 km cloud top height [
11] and solar zenith angles of 43.23° and 60°, respectively. The global annual mean Landsat solar zenith angle is 43.23° and a 60° solar zenith angle is typically experienced in Landsat imagery at mid-latitudes in the winter [
49]. The attention mechanism may also be helpful for cloud detection in images with non-random cloud distributions. A customized loss function was also used in the LANA implementation to increase the influence of minority classes in the model training that can be missed by machine learning models [
50,
51].
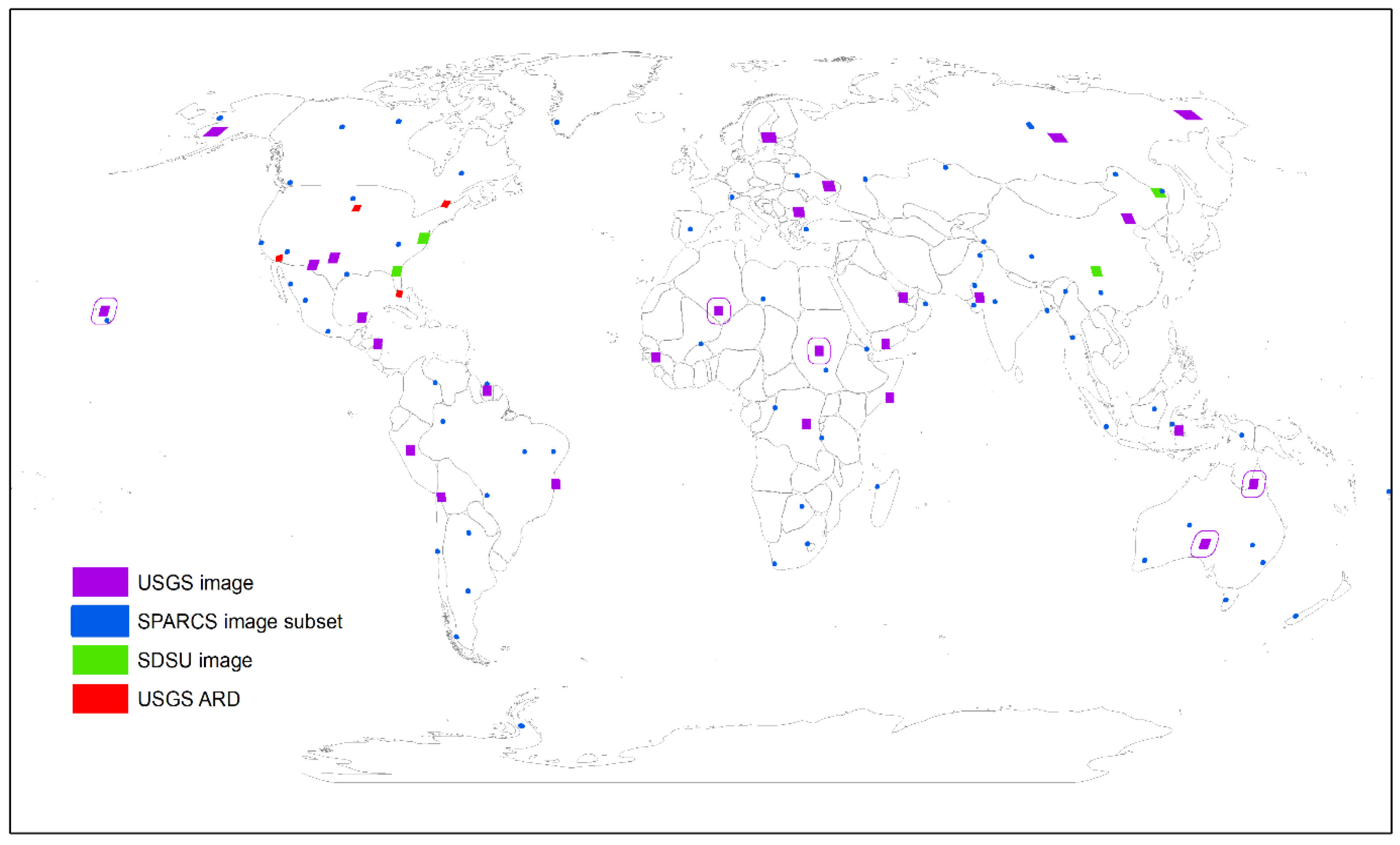
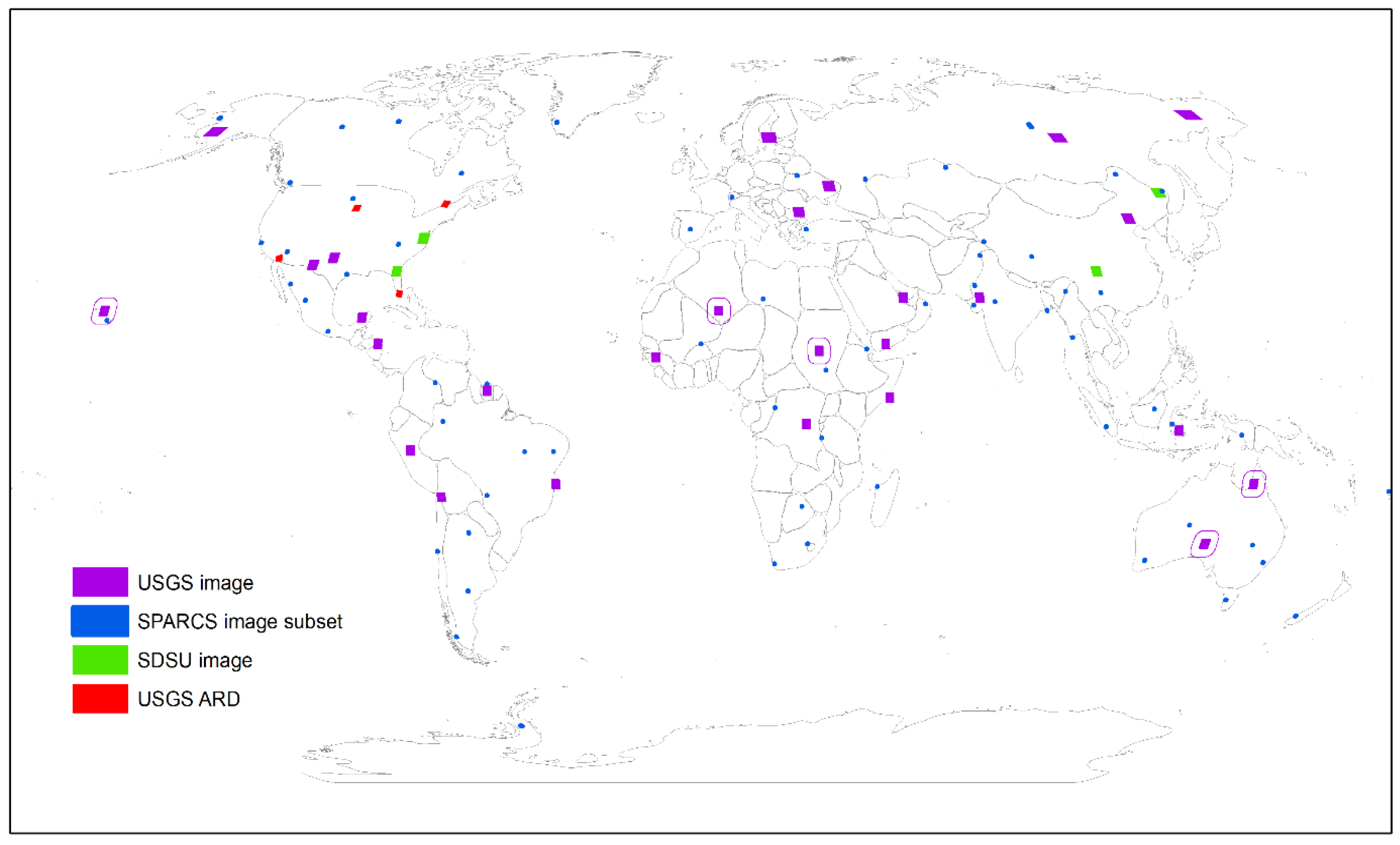
The LANA was trained using Landsat 8 OLI top of atmosphere (TOA) reflectance and associated cloud/shadow state annotations drawn from a pool of 100 datasets composed of (i) 27 Landsat 8 images annotated by USGS personnel [
52], (ii) 69 1000 × 1000 Landsat 8 image subsets annotated by the Spatial Procedures for Automated Removal of Cloud and Shadow (SPARCS) project [
17], and (iii) 4 Landsat 8 images that we annotated to capture image conditions underrepresented in the USGS and SPARCS datasets. Overall and class-specific accuracy statistics were derived from a single confusion matrix populated with the five selected datasets from the 100 datasets. For comparative purposes, the classification accuracies provided by a conventional U-Net model [
36], referred to here as U-Net Wieland, were also assessed. The U-Net Wieland model was considered as its authors have publicly released their trained model, mitigating potential implementation biases that may arise from re-training other published models. This is a real issue, as deep learning model performance is sensitive to the implementation and hyper-parameter settings [
53,
54]. The accuracy of the Fmask cloud/shadow mask provided with the Landsat 8 data was quantified, considering the same evaluation data as a benchmark.
In addition to cloud and cloud shadow accuracy assessment, the results of the three algorithms (LANA, U-Net Wieland, and Fmask) were compared considering a year of Landsat 8 OLI data acquired over four 5000 × 5000 30 m Landsat Analysis Ready Data (ARD) tiles [
55]. The geographic coordinates of each Landsat ARD tile pixel are fixed, and no additional geometric alignment steps are necessary prior to multi-temporal analysis using the ARD. Qualitative visual comparisons were undertaken, and summary statistics of the number of cloud and shadow masked observations over the year for the algorithms were compared. The temporal smoothness of the cloud and shadow-masked ARD surface reflectance time series was quantified to provide insights into the relative prevalence of undetected clouds and cloud shadows.
The paper is structured as follows. First, the Landsat 8 training and evaluation data are described (
Section 2). Then, the methods, including the LANA algorithm, accuracy assessment, and the algorithm time-series comparison, are described (
Section 3). This is followed by the results (
Section 4) reporting the LANA training and parameter optimization, accuracy assessment, and algorithm comparisons. The paper concludes with a discussion of LANA and its merits over the two other cloud and cloud shadow masking algorithms.
5. Discussion and Conclusions
Landsat cloud and cloud shadow detection has a long heritage based on the application of empirical spectral tests to single image pixels, including the Fmask algorithm that is used to generate the cloud/shadow mask provided with the standard Landsat products [
2]. Cloud and cloud shadow detection is challenging, particularly for thin clouds and cloud shadows that can be spectrally indistinguishable from clear land and water surfaces, respectively. Recently, deep convolutional neural network models have been developed for Landsat Operational Land Imager (OLI) cloud and cloud shadow detection (
Appendix A). They take advantage of both spectral and spatial contextual information and are trained and applied to image patches rather than to single pixels. The convolutional operation typically uses small spatial dimension convolution kernels that may not model spatial dependence between thin cloud and cloud pixels or between cloud and cloud shadow pixels that occur across the image patch. This study presented the learning attention network algorithm (LANA) that uses the conventional U-Net deep learning architecture with a spatial attention mechanism to capture information further from each patch pixel. The LANA includes a customized loss function to increase the influence of the cloud shadow and thin cloud minority classes using weights defined by the relative class presence in the model training. The LANA classifies each pixel in 512 × 512 30 m pixel patches as cloud, thin cloud, cloud shadow, or clear, and was trained using 100 annotated Landsat 8 OLI datasets, including 27 USGS 185 × 185 km images (of which we refined eight to improve the annotations), 69 SPARCS image subsets, and four images that we annotated to augment the USGS and SPARCS training.
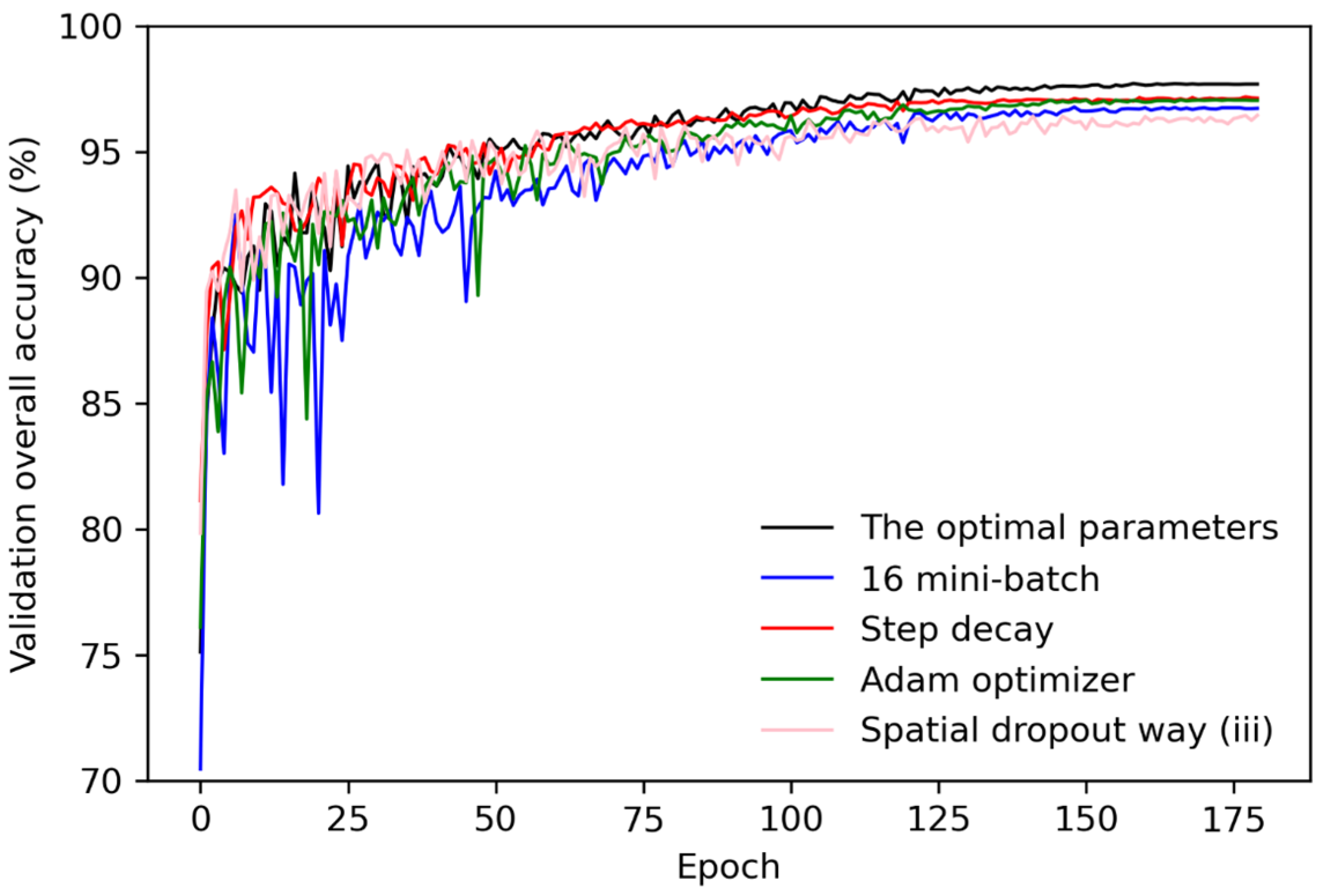
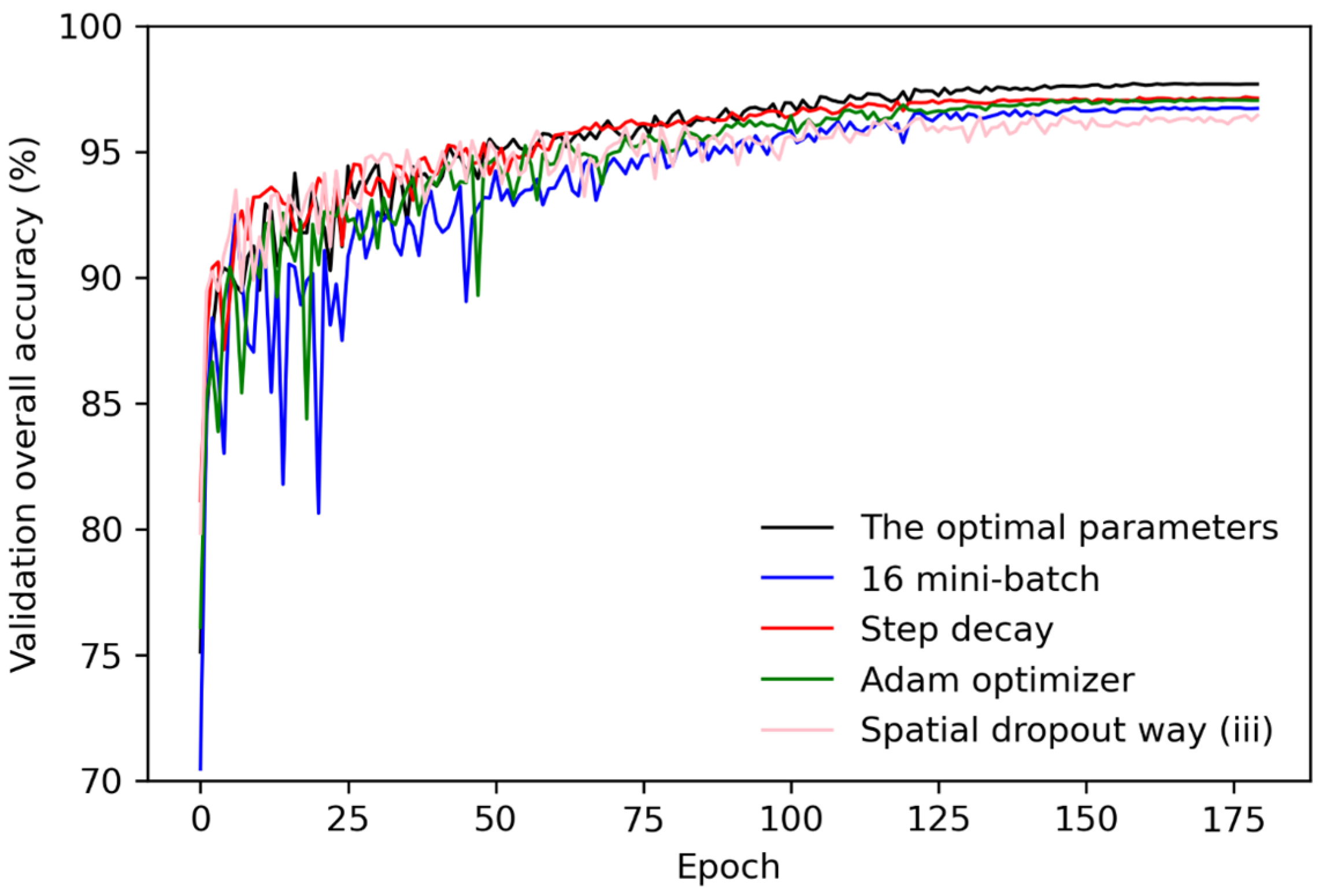
It is well established that deep learning results can vary considerably, regardless of the training data used, depending on the deep learning model structure and the parameterization [
53,
105]. The optimal LANA structure and parameterization presented in this study was found by undertaking a sensitivity analysis considering different feature map sizes and optimizers, as well as a range of learning rates, mini-batch sizes, and spatial dropout implementations. The final LANA structure used (
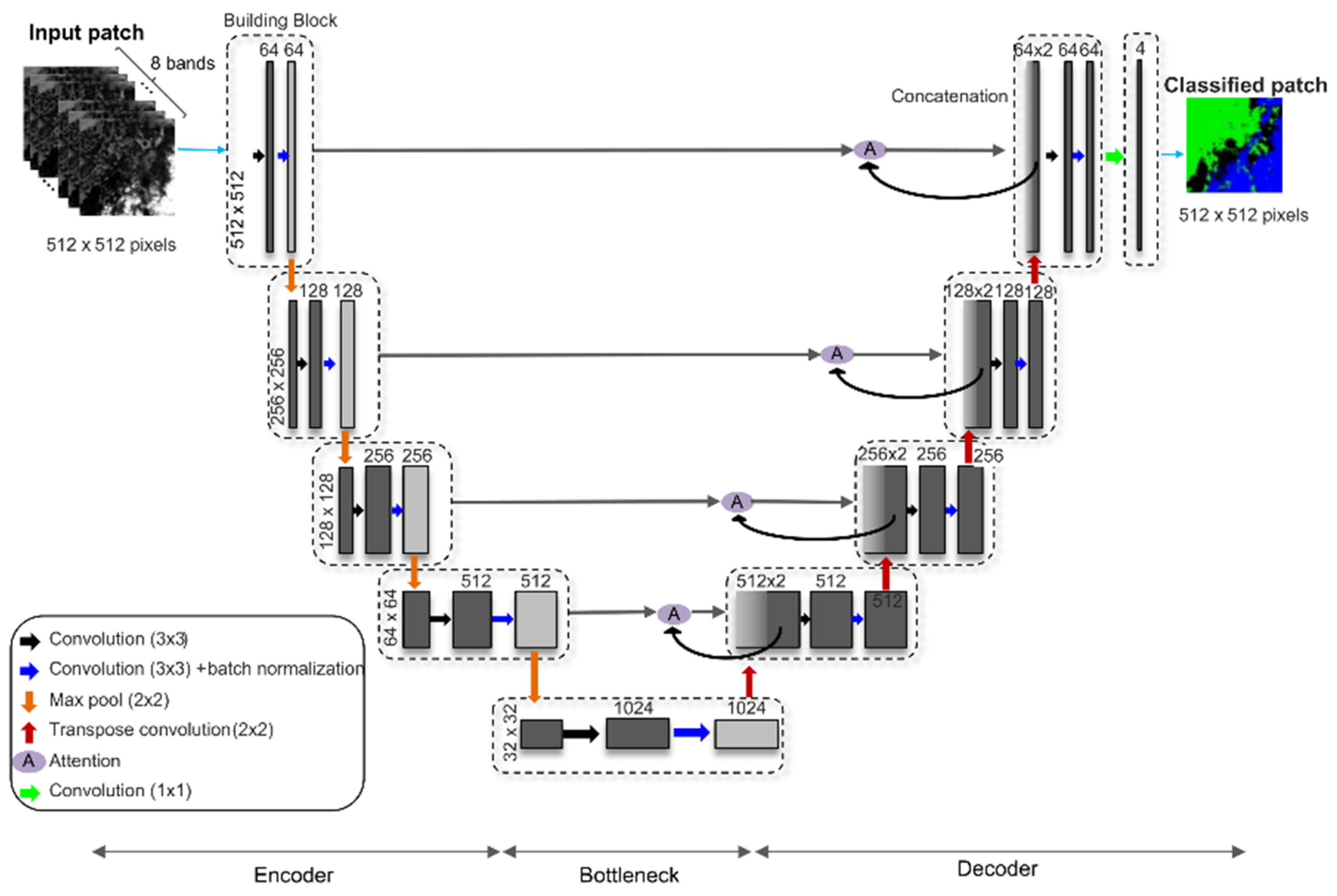
Figure 3) was composed of 64, 128, 256, and 512 feature maps in four encoder convolution blocks (31,309,552 learnable coefficients) with an attention mechanism applied to the encoder feature maps when they were copied to the decoder side in the skip connections. The LANA was trained using 16,861 512 × 512 30 m pixel annotated patches, and the final implementation used a mini-batch size of 64 patches, a 0.0005 initial learning rate with a cosine learning rate decay strategy, the RMSProp optimizer algorithm, and spatial dropout applied to the last convolutional layer and to all the decoder layers before the transpose convolutions.
The LANA classification results were compared with the Fmask results available in the Landsat products and, in addition, with the results of the U-Net Wieland model that was developed and trained by [
36]. The LANA classifies 30 m pixels into four classes (cloud, thin cloud, cloud shadow, and clear) and had a 77.91% overall classification accuracy, with class-specific accuracy increasing sequentially from thin cloud (F1-score 0.4104) to cloud shadow (0.5753), cloud (0.8139), and clear (0.8902) classes (
Table 3). The very low F1-score of the thin cloud and shadow classes highlights the difficulty in detecting reliably thin clouds and cloud shadows due to the considerable spatial and spectral variability of these classes, which is evident in the 500 × 500 pixel subsets illustrated in
Section 4.3.
The LANA, Fmask, and U-Net Wieland algorithms have different class legends, and, in order to provide meaningful intercomparison, the three algorithm classification results were harmonized to the same three classes, i.e., cloud, cloud shadow, and clear (
Section 3.4). Considering the three classes, the LANA model had the highest (88.84%) overall accuracy, followed by Fmask (85.91%), and then U-Net Wieland (85.19%) (
Table 4). The LANA had the highest F1-score accuracies for the three classes, which were >0.89 (clear), >0.91 (cloud), and >0.57 (cloud shadow). The Fmask and U-Net Wieland algorithm F1-score accuracies were lower for all three classes, particularly for cloud (Fmask 0.90, U-Net Wieland 0.88) and cloud shadow (Fmask 0.45, U-Net Wieland 0.52).
In addition to the accuracy assessment, a time-series evaluation was undertaken by applying each algorithm to a year of Collection 2 Landsat 8 OLI reflectance at four 5000 × 5000 30 m pixel CONUS ARD tiles. The ARD tiles encompassed different land surfaces and degrees of cloudiness and did not spatially coincide with the training data. At each ARD tile pixel, the temporal smoothness (TSI
λ) of the annual surface reflectance time series, considering only observations classified as “clear”, was quantified to provide insights into the prevalence of undetected clouds and cloud shadows, including sub-pixel clouds and shadows. The percentage of tile pixel observations classified as “clear” was similar for the three algorithms and so the algorithm TSI
λ values could be meaningfully compared. The LANA had the smallest tile-averaged TSI
λ values for 20 of the 24 (four tiles and six OLI bands/tile) TSI
λ comparisons, and the U-Net Wieland had marginally smaller values than the LANA for the remaining four comparisons. The Fmask had the greatest tile-averaged TSI
λ values for all bands for three of the ARD tiles, and for the other ARD tile (over Mexico/US that was the least cloudy), the Fmask had the greatest tile-averaged TSI
λ values for three of the six bands considered. The TSI
λ results indicate that the LANA had the lowest prevalence of undetected clouds and cloud shadows, whereas the Fmask had the greatest prevalence. This was also reflected in the class specific accuracy results. Among the three algorithms, the LANA had the smallest cloud and cloud shadow omission errors with 93.79% and 65.62% producer’s accuracies, respectively, whereas the Fmask had the greatest cloud omission error (86.57% producer’s accuracy) and the second greatest cloud shadow omission error (60.67% producer’s accuracy) (
Table 3). The U-Net Wieland had the greatest cloud shadow omission error (50.88% producer’s accuracy). The U-Net Wieland had 89.31% cloud producer’s accuracy.
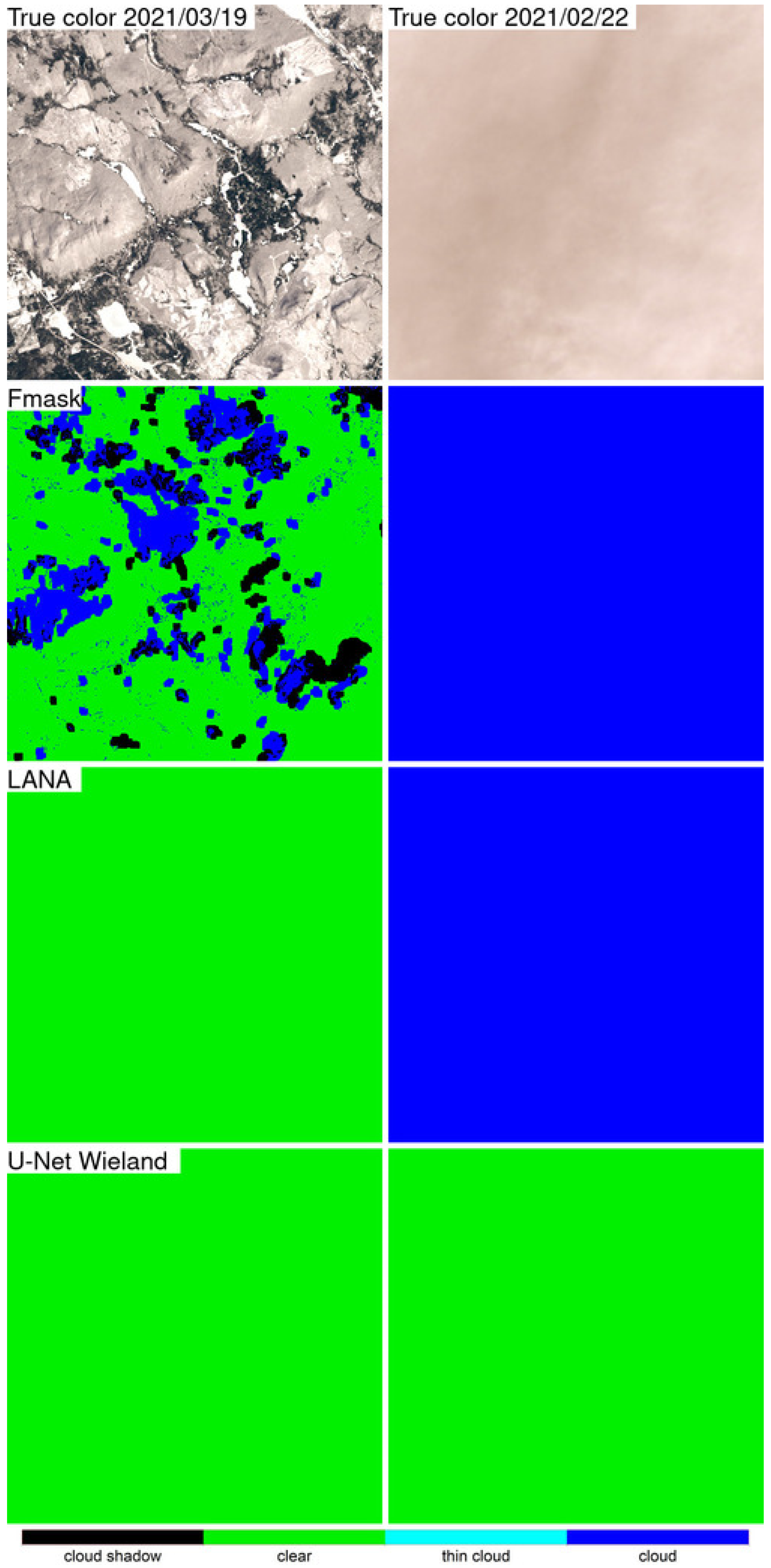
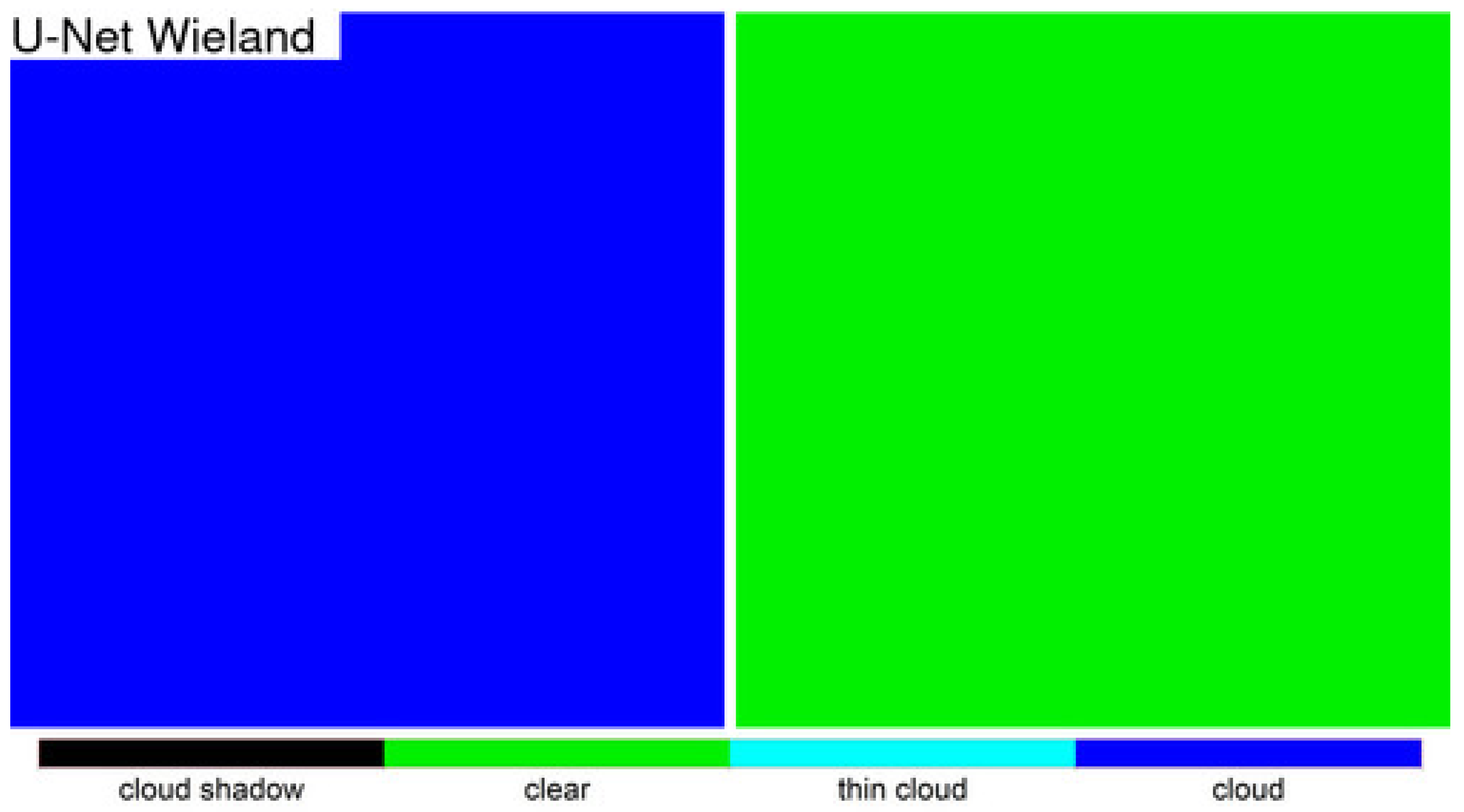
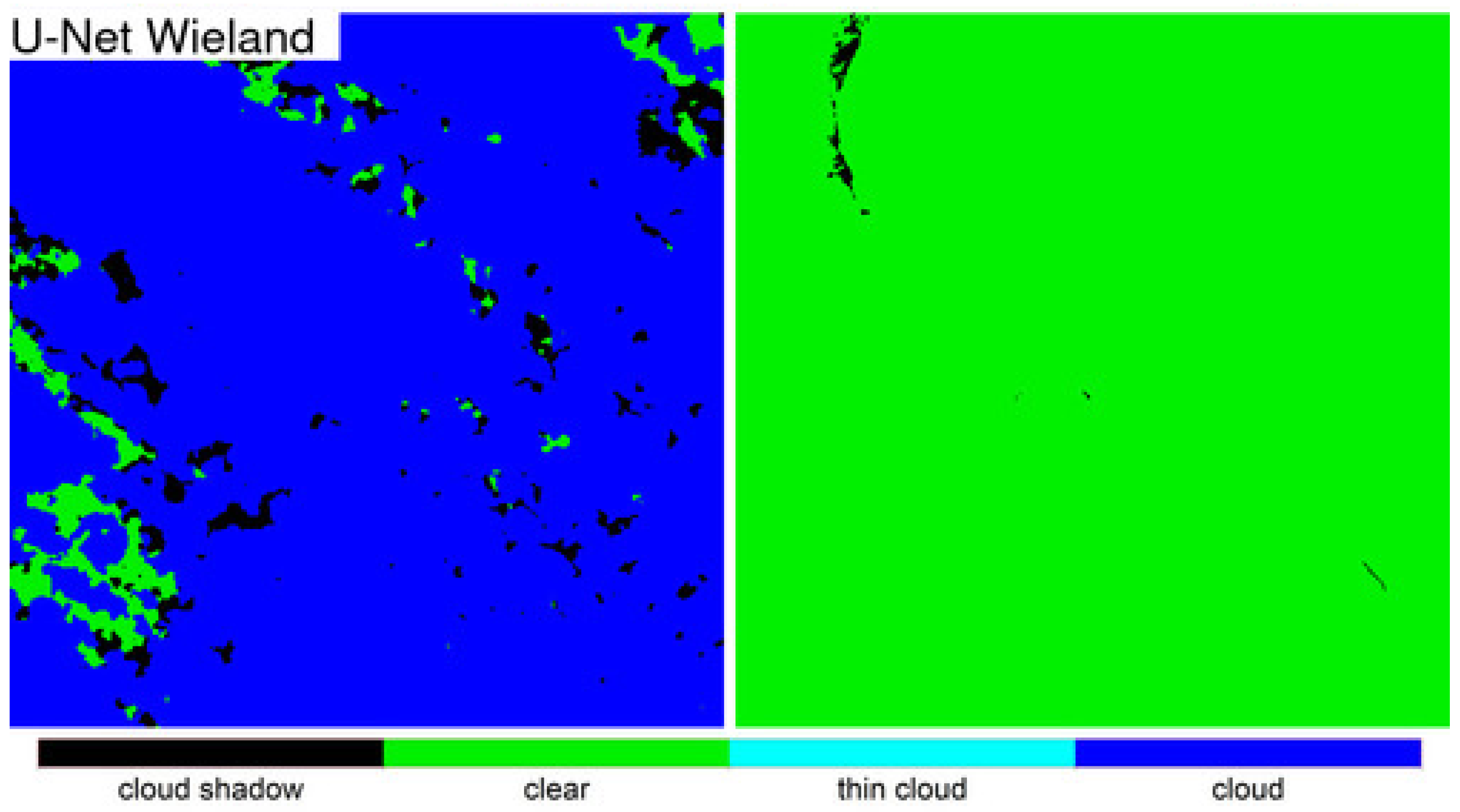
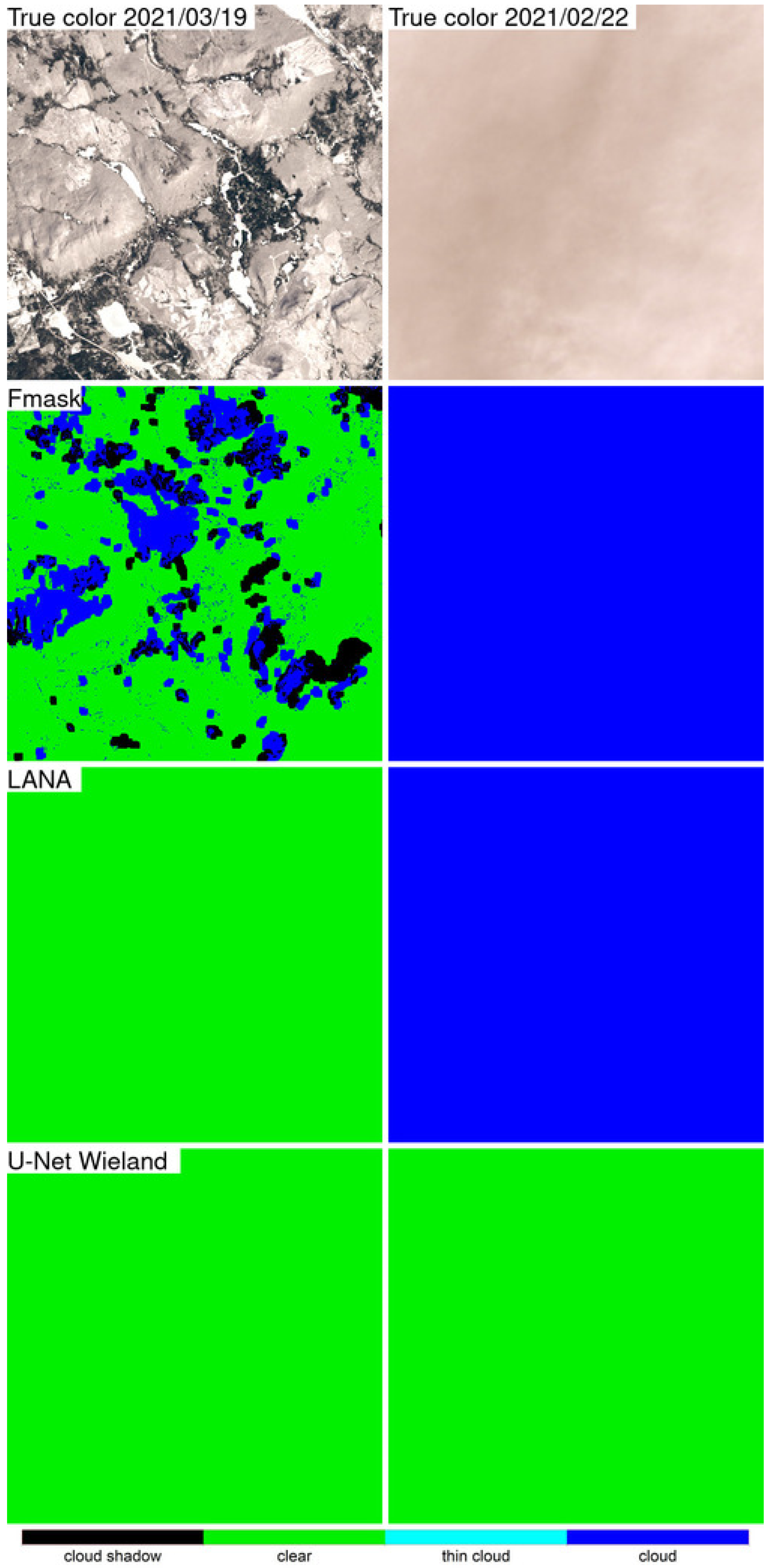
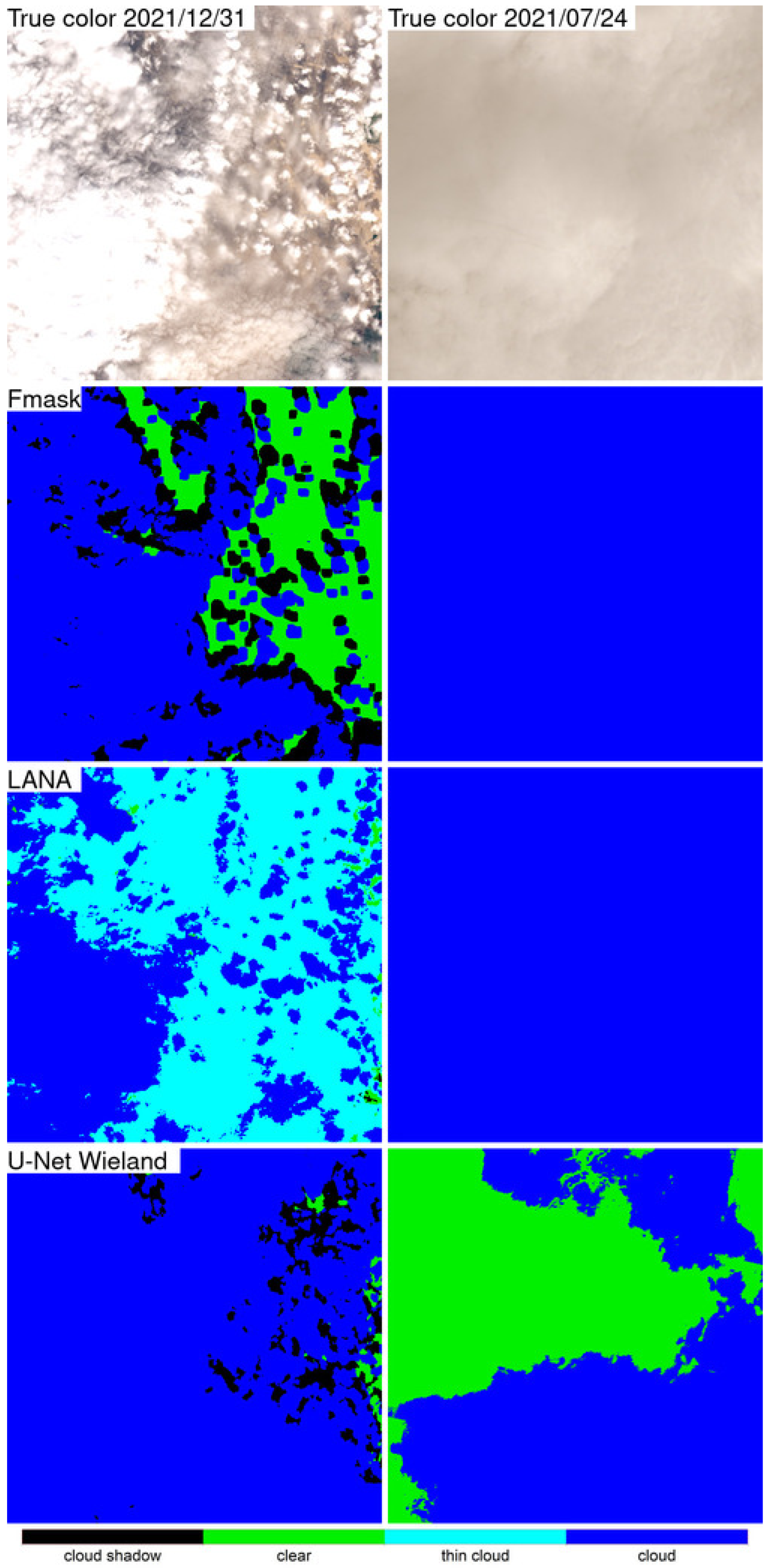
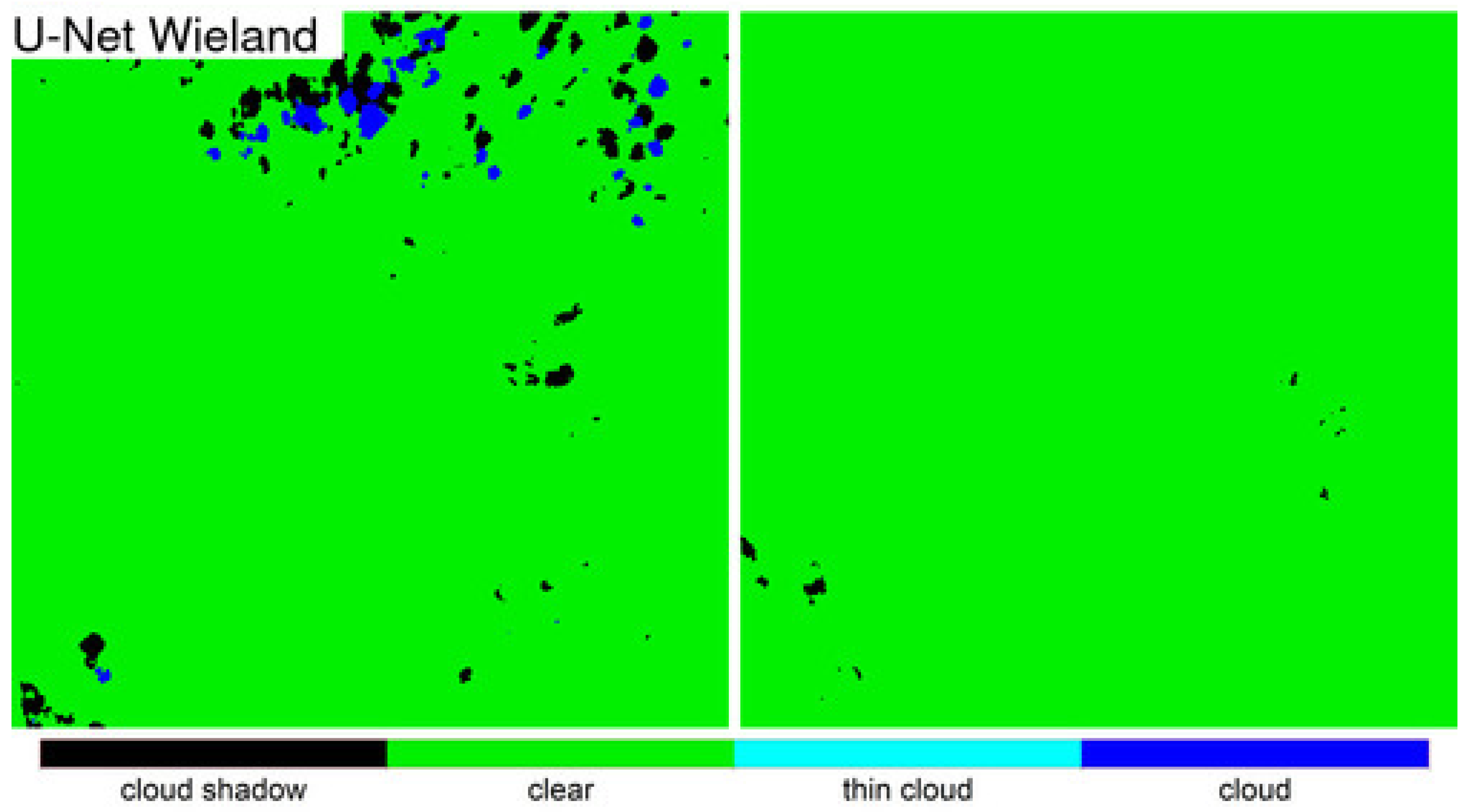
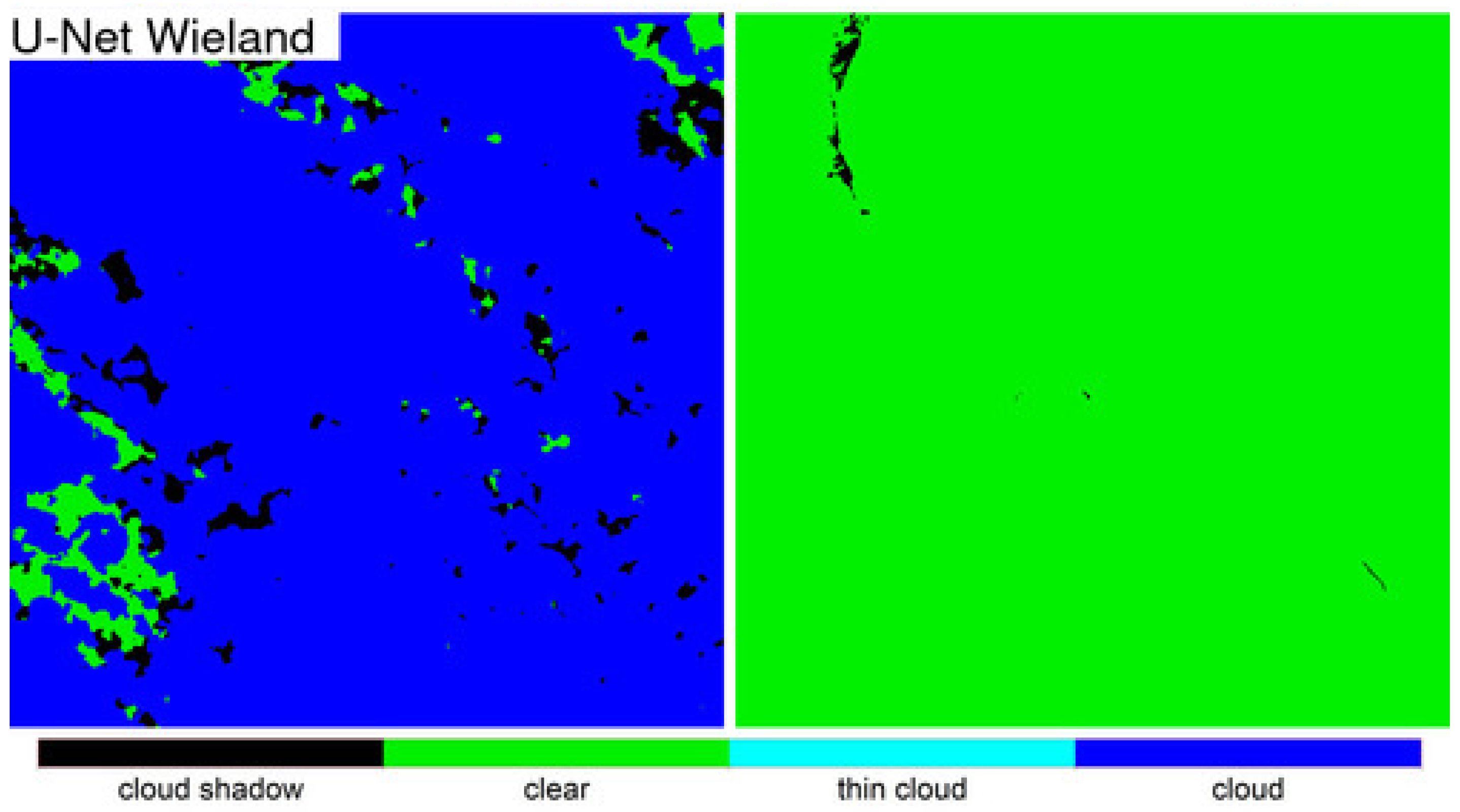
Detailed 500 × 500 30 m pixel ARD tile pixel subsets of the three algorithm classification results were compared qualitatively with the OLI reflectance for two dates selected based on the most different classification results between the LANA and each of the other two algorithms. The qualitative results were broadly consistent with the class specific accuracy assessment findings. The LANA algorithm typically performed better than Fmask and U-Net Wieland. Notably, the U-Net Wieland often failed to detect cloud and cloud shadows, and the Fmask occasionally missed obvious clouds and aggressively detected cloud shadows, which is reflected by it having the greatest cloud shadow commission error (36.30% user’s accuracy). These detailed visual assessments, and the ARD tile counts of annual “clear” observations, reinforce the need for cloud algorithm quality assessment. Formal accuracy assessment relies on a limited sample of validation data that may not adequately capture artefacts in the classification results, such as the Fmask stripe between successive Landsat images acquired in the same orbit and the U-Net Weiland cloud commission errors over bright desert, evident in
Figure 9 and
Figure 12, respectively.
The results presented in this study demonstrate that the LANA provides more reliable and accurate cloud and cloud shadow classification than the other algorithms. The Fmask and U-Net Wieland overall classification accuracies reported in this study are lower than those reported by the original algorithm publications. This is for several reasons. The U-Net Wieland authors reported a 91.0% accuracy for five classes (cloud shadow, cloud, water, land, and snow/ice), however, they used training and evaluation patches selected from the same images [
36]. The Fmask Collection 1 overall accuracy was reported as 89.0% for three classes (cloud, cloud shadow, and clear) [
21], and for Collection 2, it was reported as 85.1% [
22]. The reported Fmask Collection 2 overall accuracy is close to the 85.91% Fmask accuracy reported in this study. Notably, however, we found that the 32 USGS annotated Landsat 8 OLI images used by [
21] to validate the Collection 2 Fmask included images with missing cloud shadow annotations, and five images had visually indistinguishable cloud and snow areas that were unlikely to have been annotated perfectly. This underscores the need for high-quality annotation data that, ideally, should be derived at a higher resolution than the cloud/shadow results, as clouds and shadows occur at the sub-pixel level. International benchmarking and algorithm inter-comparison exercises, such as the Cloud Mask Intercomparison eXercise (CMIX) [
106], are encouraged to generate annotated datasets that can be used for accuracy assessment and to investigate other ways of assessing cloud/shadow algorithms, although obtaining contemporaneous higher spatial resolution cloud/shadow information is challenging.
The LANA was implemented using the eight Landsat 8 OLI 30 m reflective bands and will also work for Landsat 9, which has the same reflective wavelength OLI bands and was launched successfully, after a short delay, in September 2021 [
2]. The Landsat thermal bands were not used, even though clouds are often colder than land surfaces [
107,
108]. We found that including the two Landsat 8 thermal bands did not improve the LANA classification accuracy. This is likely because the emitted thermal radiance across a patch can vary rapidly due to factors, including the solar irradiance history, the surface type (e.g., specific heat capacity), wetness (rain and dew), and wind, which control latent and sensible heat fluxes. Further, cloud top temperatures can vary considerably, including with respect to cloud height, cloud optical depth, and ambient atmospheric temperature [
109,
110]. We also found that dropping the shorter wavelength OLI blue bands that are highly sensitive to aerosol scattering and that are difficult to reliably atmospherically correct [
93,
111] did not, like for other recent Landsat 8 OLI studies [
67], significantly change the LANA classification accuracy.
Finally, we note that the LANA could be applied to other satellite sensors. The older Landsat sensor series have different spectral bands and spectral response functions [
112], potentially complicating transfer learning approaches that have been developed for other Landsat deep learning applications [
33,
100]. In particular, the Landsat Multispectral Scanner (MSS) onboard Landsat 1–3 carried no blue or SWIR bands and had a coarser resolution [
113,
114], and research using the LANA for MSS cloud and cloud shadow masking is recommended. For reliable application to MSS, and to other sensor data, the LANA model should preferably be retrained. For example, the Sentinel-2 MultiSpectral Instrument (MSI) has similar but different spectral bands to the Landsat 8/9 OLI [
115], and we note that Sentinel-2 cloud annotations are available [
116,
117], but no such datasets exist for MSS, and improved MSS cloud and cloud shadow masking is considered a future priority for the next Landsat collection [
2].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}