






A Single Data Extraction Algorithm for Oblique Photographic Data Based on the U-Net

 ,
,  ,
,
Abstract
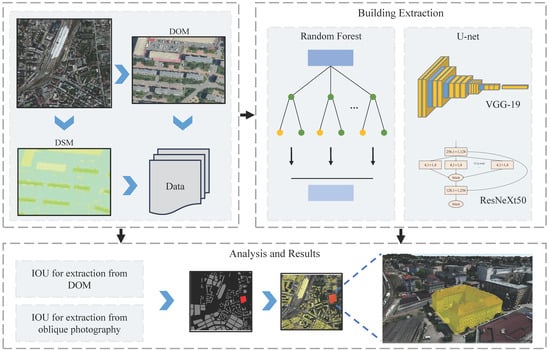
1. Introduction
2. Literature Review
2.1. Evolution of Three-Dimensional Reconstruction and Extraction
2.2. Advancements in Remote Sensing Technology for 3D Data Acquisition
2.3. Applications of 3D Reconstruction and Extraction and RS AI Algorithms across Various Fields
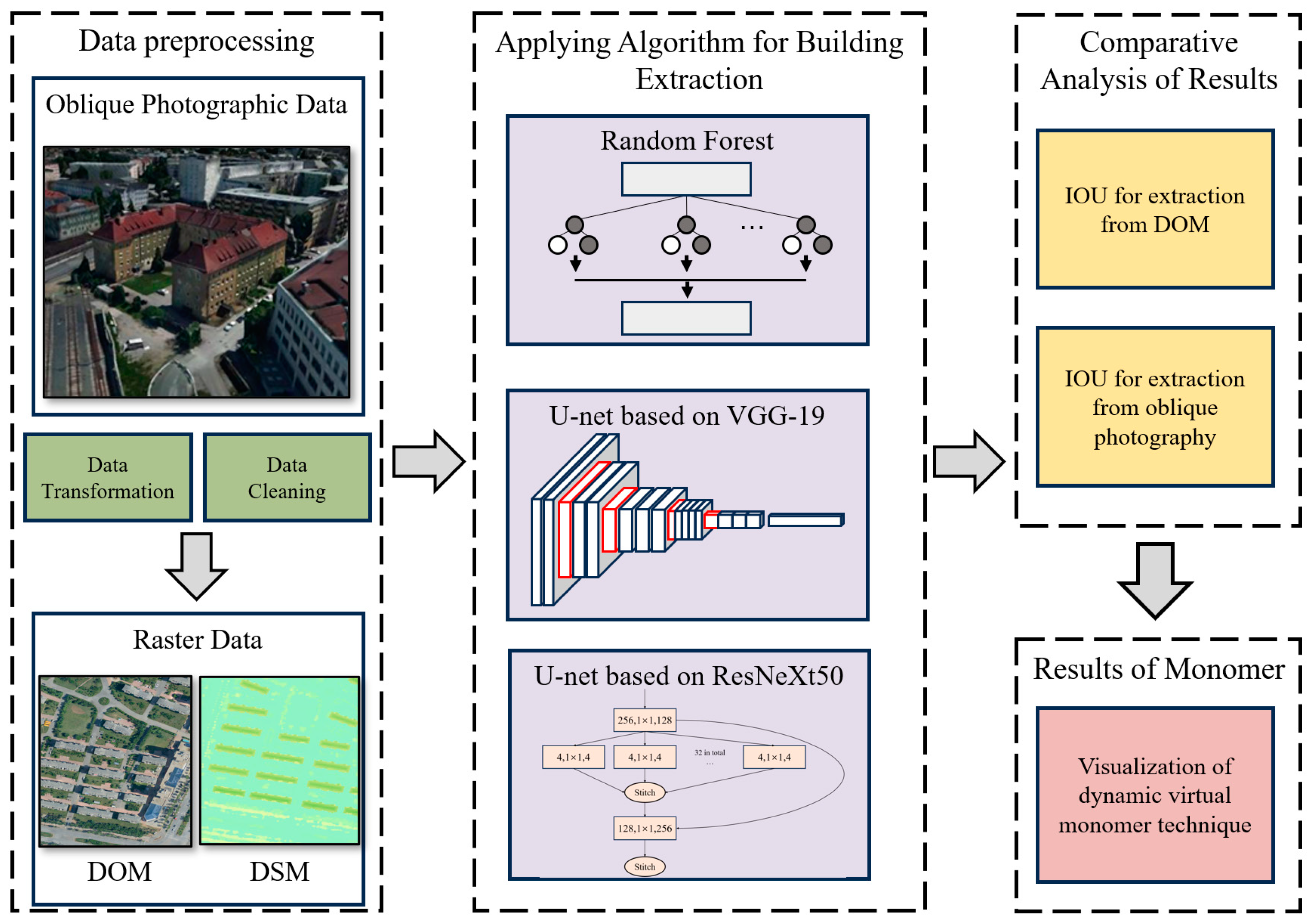
3. Materials and Methods
3.1. Study Area
3.2. Deep Convolution Neural Network for Automatic Acquisition of the Polygonal Underside of a Building
3.2.1. Oblique Photographic Data Preprocessing
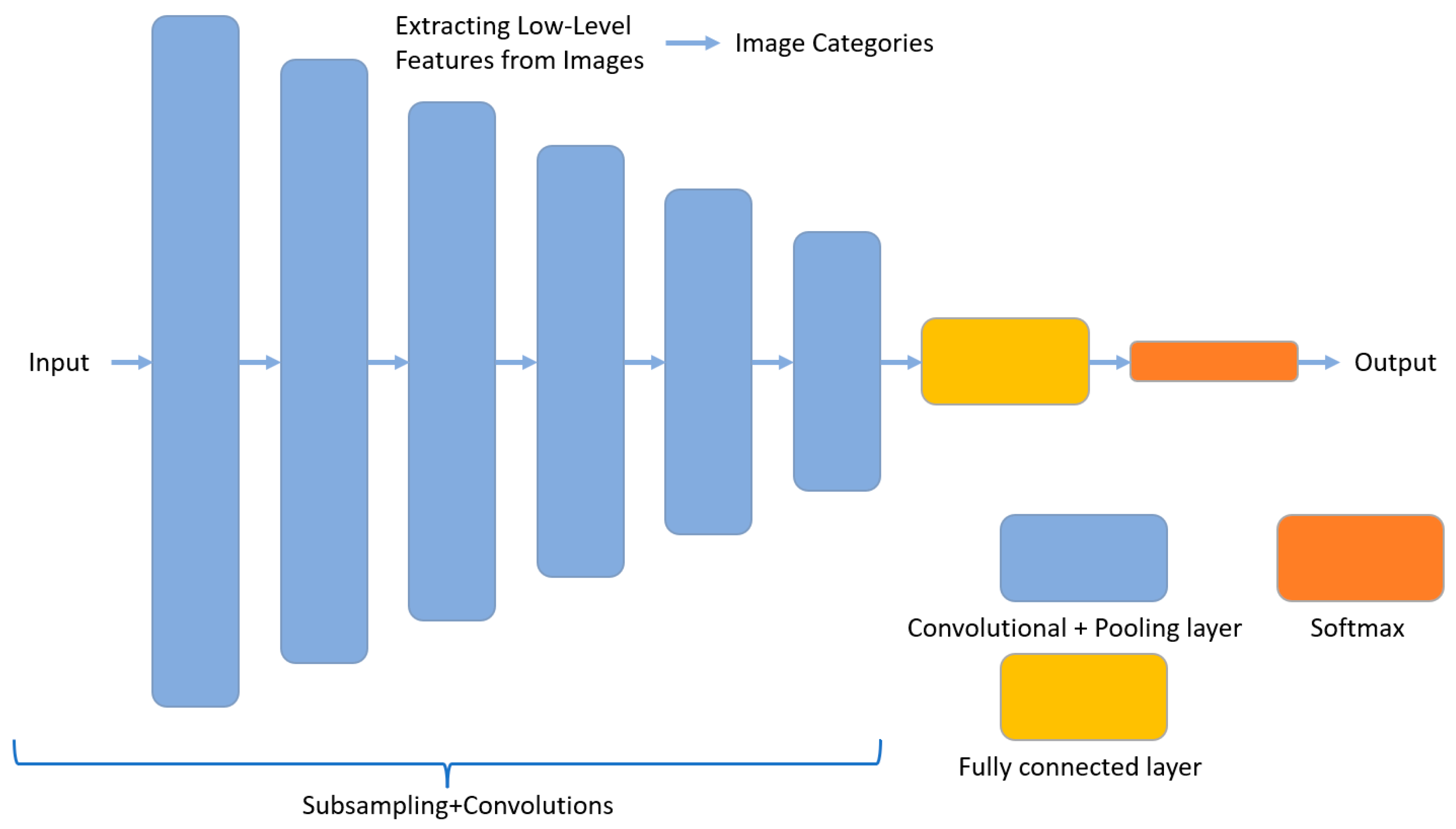
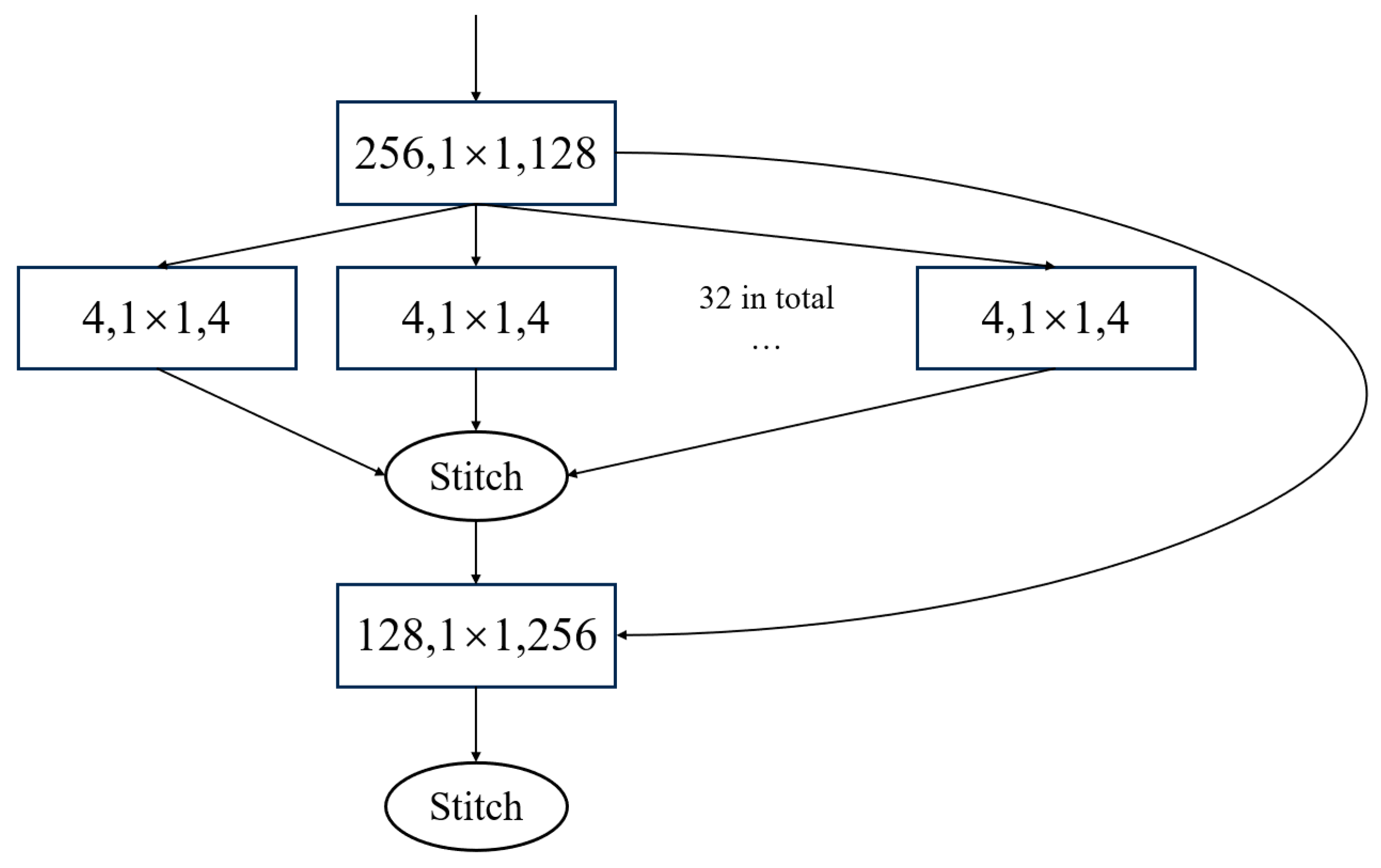
3.2.2. Convolutional Neural Network
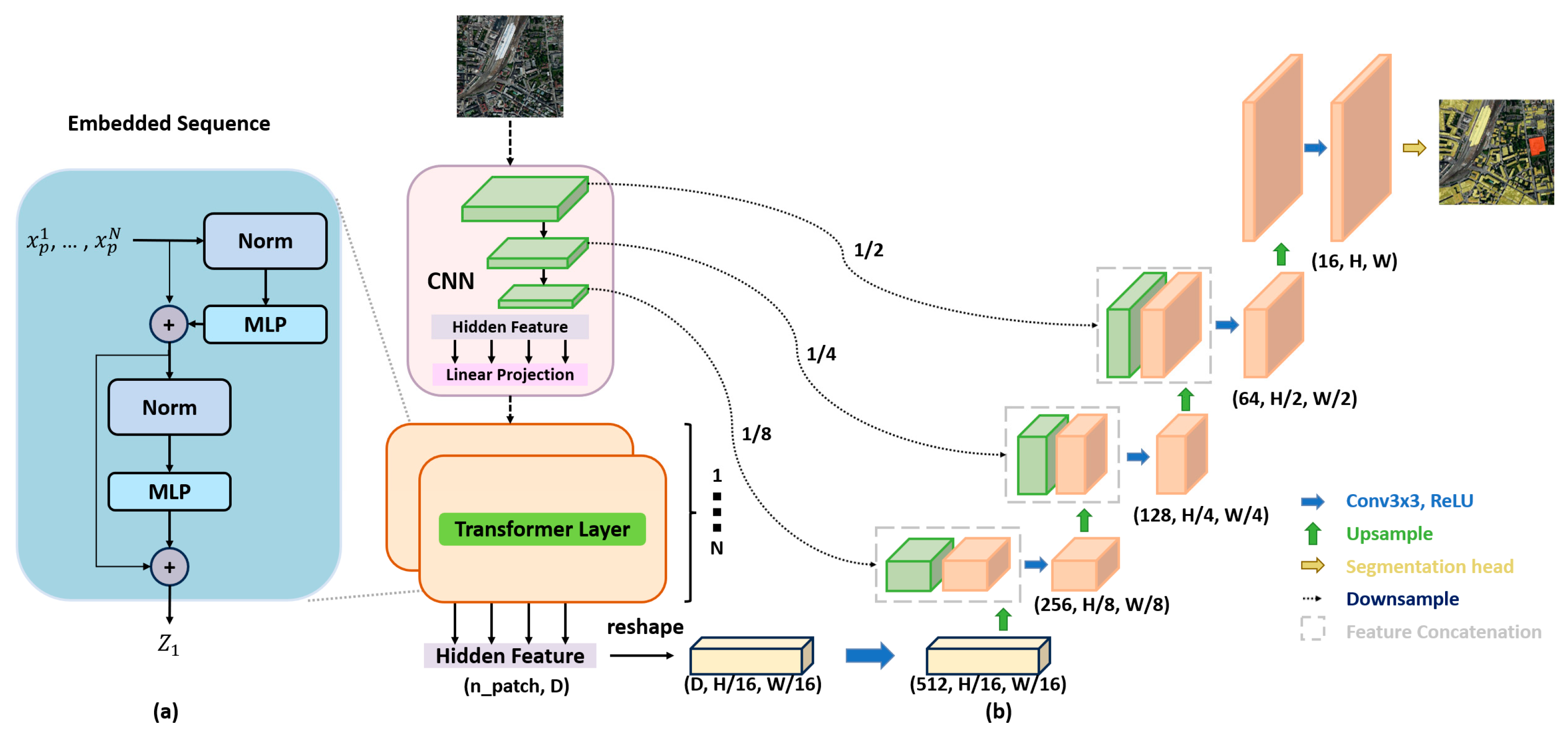
3.2.3. Loss Function
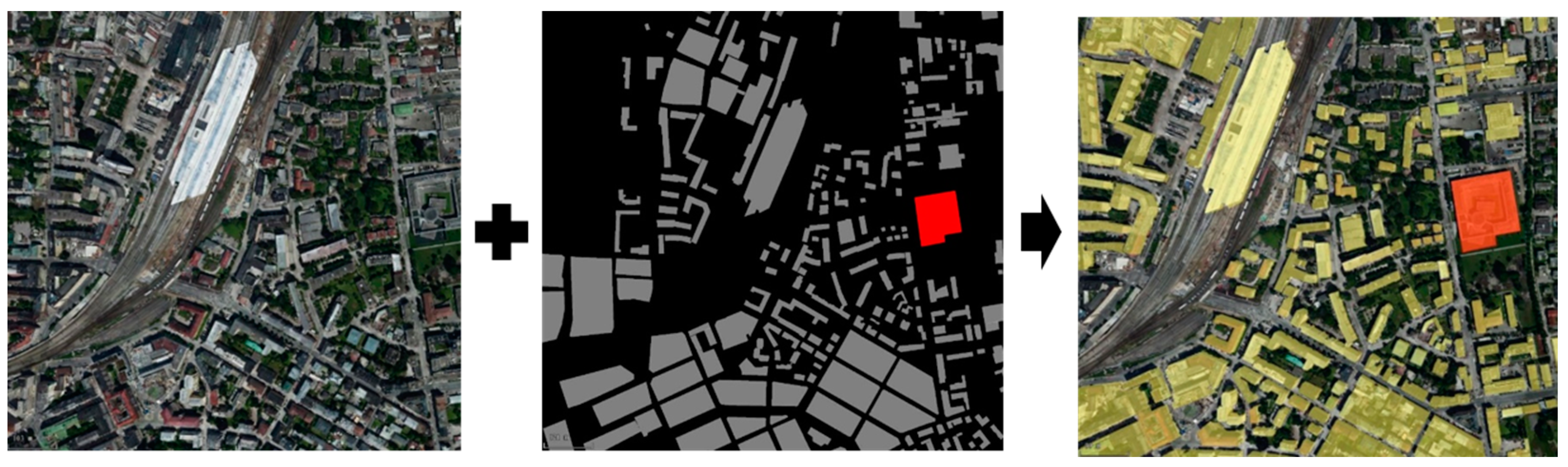
3.3. Oblique Photographic Dynamic Virtual Method of Building Monomer Construction
4. Results
4.1. The Comparision of Building Extraction Method
4.2. Visualization of Dynamic Virtual Building Monomer Construction
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Suveg, I.; Vosselman, G. Reconstruction of 3D building models from aerial images and maps. ISPRS J. Photogramm. Remote Sens. 2004, 58, 202–224. [Google Scholar] [CrossRef]
- Yin, X.; Wonka, P.; Razdan, A. Generating 3D Building Models from Architectural Drawings: A Survey. IEEE Comput. Graph. Appl. 2009, 29, 20–30. [Google Scholar] [CrossRef] [PubMed]
- El-Mekawy, M.; Östman, A.; Hijazi, I. A Unified Building Model for 3D Urban GIS. ISPRS Int. J. Geo-Inf. 2012, 1, 120–145. [Google Scholar] [CrossRef]
- Danilina, N.; Slepnev, M.; Chebotarev, S. Smart city: Automatic reconstruction of 3D building models to support urban development and planning. MATEC Web Conf. 2018, 251, 03047. [Google Scholar] [CrossRef]
- Schrotter, G.; Hürzeler, C. The Digital Twin of the City of Zurich for Urban Planning. J. Photogramm. Remote Sens. Geoinf. Sci. 2020, 88, 99–112. [Google Scholar] [CrossRef]
- Baarimah, A.O.; Alaloul, W.S.; Liew, M.S.; Kartika, W.; Al-Sharafi, M.A.; Musarat, M.A.; Alawag, A.M.; Qureshi, A.H. A Bibliometric Analysis and Review of Building Information Modelling for Post-Disaster Reconstruction. Sustainability 2022, 14, 393. [Google Scholar] [CrossRef]
- Li, Q.; Shi, Y.; Huang, X.; Zhu, X.X. Building Footprint Generation by Integrating Convolution Neural Network with Feature Pairwise Conditional Random Field (FPCRF). IEEE Trans. Geosci. Remote Sens. 2020, 58, 7502–7519. [Google Scholar] [CrossRef]
- Cha, H.S.; Kim, J. A study on 3D/BIM-based on-site performance measurement system for building construction. J. Asian Archit. Build. Eng. 2020, 19, 574–585. [Google Scholar] [CrossRef]
- Song, G. The dilemma and way out of 3D GIS. China Surv. Mapp. 2010, 1, 32–39. [Google Scholar]
- Ahmed, R.; Mahmud, K.H.; Tuya, J.H. A GIS-based mathematical approach for generating 3d terrain model from high-resolution UAV imageries. J. Geovi. Spat. Anal. 2021, 5, 24. [Google Scholar] [CrossRef]
- Zhou, L.; Yuan, B.; Hu, F.N.; Wei, C.Z.; Dang, X.W.; Sun, D.Q. Understanding the effects of 2D/3D urban morphology on land surface temperature based on local climate zones. Build. Environ. 2022, 208, 108578. [Google Scholar] [CrossRef]
- Zhang, C.; Fan, H.; Kong, G. VGI3D: An interactive and low-cost solution for 3D building modelling from street-level VGI images. J. Geovi. Spat. Anal. 2021, 5, 18. [Google Scholar] [CrossRef]
- Li, D.; Xiao, X.; Guo, B.; Jiang, W.; Shi, Y. Oblique Image Based Automatic Aerotriangulation and Its Application in 3D City Model Reconstruction. Geomat. Inf. Sci. Wuhan Univ. 2016, 41, 711–721. [Google Scholar] [CrossRef]
- Song, G.; Zhong, E.; Wu, Z.; Li, S.; Cai, W.; Wang, S. Four Key Technologies of the Next Generation GIS Platform. J. Geomat. 2019, 44, 1–8. [Google Scholar] [CrossRef]
- Feng, Z.; Li, M.; Yang, Y.; Li, N. Research and Practice on Key Technologies of New Generation 3D GIS. Geomat. Spat. Inf. Technol. 2017, 40, 85–87. [Google Scholar] [CrossRef]
- Meng, C.; Song, Y.; Ji, J.; Jia, Z.; Zhou, Z.; Gao, P.; Liu, S. Automatic classification of rural building characteristics using deep learning methods on oblique photography. Build. Simul. 2022, 15, 1161–1174. [Google Scholar] [CrossRef]
- Xu, W.; Zeng, Y.; Yin, C. 3D City Reconstruction: A Novel Method for Semantic Segmentation and Building Monomer Construction Using Oblique Photography. Appl. Sci. 2023, 13, 8795. [Google Scholar] [CrossRef]
- Ma, X.Y.; Zhang, X.P.; Shi, L. Research on the Algorithm of Building Object Boundary Extraction Based on Oblique Photographic Model. In Proceedings of the IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018. [Google Scholar] [CrossRef]
- Cheng, H. A Monolithic Approach to BIM with UAV Remote Sensing Tilt Imagery; Beijing University of Architecture: Beijing, China, 2018. [Google Scholar]
- Yang, C. Building Extraction and Parametric 3D Reconstruction Based on Tilt Images; Xi’an University of Science and Technology: Xi’an, China, 2016. [Google Scholar]
- Zhao, L.; Wang, H.; Guo, Z.; Guan, J. A study of classification of point clouds generated by oblique imagery based on random forest. Eng. Surv. Mapp. 2018, 27, 16–21. [Google Scholar] [CrossRef]
- Yao, J.; Cao, X.Y.; Hong, D.F.; Wu, X.; Meng, D.Y.; Chanussot, J.; Xu, Z.B. Semi-Active Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5537915. [Google Scholar] [CrossRef]
- Xin, W.; Hong, D.F.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5517010. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; Volume 25, pp. 1097–1105. [Google Scholar] [CrossRef]
- Gao, F.; Huang, T.; Sun, J.; Wang, J.; Hussain, A.; Yang, E. A New Algorithm for SAR Image Target Recognition Based on an Improved Deep Convolutional Neural Network. Cogn. Comput. 2019, 11, 809–824. [Google Scholar] [CrossRef]
- Yuan, D.; Fan, N.; He, Z. Learning target-focusing convolutional regression model for visual object tracking. Knowl.-Based Syst. 2020, 194, 105526. [Google Scholar] [CrossRef]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding Deep Learning Techniques for Image Segmentation. ACM Comput. Surv. 2019, 52, 73. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Swalpa, K.R.; Purbayan, K.; Hong, D.F.; Xin, W.; Antonio, P.; Chanussot, J. Revisiting Deep Hyperspectral Feature Extraction Networks via Gradient Centralized Convolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5516619. [Google Scholar] [CrossRef]
- Behnood, R.; Hong, D.F.; Hang, R.L.; Ghamisi, P.; Kang, X.D.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Hong, D.F.; Gao, L.R.; Wu, X.; Yao, J.; Zhang, B. Revisiting Graph Convolutional Networks with Mini-Batch Sampling for Hyperspectral Image Classification. In Proceedings of the 2021 11th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 14–16 January 2021. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crops Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Sportouche, H.; Tupin, F.; Denise, L. Extraction and Three-Dimensional Reconstruction of Isolated Buildings in Urban Scenes from High-Resolution Optical and SAR Spaceborne Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3932–3946. [Google Scholar] [CrossRef]
- Sui, H.G.; Liu, C.X.; Huang, L.H.; Hua, L. Application of Remote Sensing Technology in Earthquake-Induced Building Damage Detection. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 1008–1019. [Google Scholar] [CrossRef]
- Wang, S.B.; Li, M.X.; Li, H.R. Research on obstacle detection of transmission line corridor based on 3D laser radar technology. Electron. Technol. 2019, 32, 81–84. [Google Scholar] [CrossRef]
- Manthira, S.M.; Misra, I.; Kaur, R.; Darji, N.P.; Ramakrishnan, R. Kernel Based Learning Approach for Satellite Image Classification Using Support Vector Machine. In Proceedings of the 2011 IEEE Recent Advances in Intelligent Computational Systems, Trivandrum, India, 22–24 September 2011. [Google Scholar] [CrossRef]
- Sun, Y.; Du, Y. Big data and sustainable cities: Applications of new and emerging forms of geospatial data in urban studies. Open Geospat. Data Softw. Stand. 2017, 2, 24. [Google Scholar] [CrossRef]
- Goebbels, S. 3D reconstruction of bridges from airborne laser scanning data and cadastral footprints. J. Geovis. Spat. Anal. 2021, 5, 10. [Google Scholar] [CrossRef]
- Zhu, J.P.; Zhao, H.L.; Yang, H.T. Disparity map generation technology based on convolutional neural network. J. Comput. Appl. 2018, 38, 255. [Google Scholar] [CrossRef]
- Liu, X.L.; Zhao, X.S.; Lu, F.; Sun, W.B. A GA-SVM based model for throwing rate prediction in the open-pit cast blasting. J. China Coal Soc. 2012, 37, 1999–2005. [Google Scholar] [CrossRef]
- Li, X.Z. Construction Research and Application Practice of 3D High Precision Map-Take 5G + Intelligent Transportation Field as an Example. Mod. Inf. Technol. 2021, 5, 57–61. [Google Scholar] [CrossRef]
- Luo, H.T. Research on Safety Monitoring and Evaluation of Urban Rail Transit Based on “BIM+GIS”. Railw. Investig. 2021, 47, 33–36+47. [Google Scholar] [CrossRef]
- Alcaraz, C.; Lopez, J. Digital Twin: A Comprehensive Survey of Security Threats. IEEE Commun. Surv. Tutor. 2022, 24, 1475–1503. [Google Scholar] [CrossRef]
- Zhu, R.S.; Li, S.; Sun, Y.Z.; Cao, Y.Y.; Sun, K.; Guo, Y.X.; Jiang, B.F.; Wang, X.Y.; Li, Y.; Zhang, Z.G.; et al. Research advances and prospects of crop 3D reconstruction technology. Smart Agric. 2021, 3, 94. [Google Scholar] [CrossRef]
- Gan, L.L.; Li, J.; Jing, N. Hybrid organization and visualization of the DSM combined with 3D building model. In Proceedings of the 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 566–571. [Google Scholar] [CrossRef]
- Ma, R. Building Model Reconstruction from LiDAR Data and Aerial Photographs; The Ohio State University: Columbus, OH, USA, 2005. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Kim, P.; Kim, P. Convolutional neural network. In MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Apress: Berkeley, CA, USA, 2017; pp. 121–147. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Huang, Z.C.; Chanussot, J. Infrared Small Object Detection Using Deep Interactive U-Net. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517805. [Google Scholar] [CrossRef]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; p. 26. [Google Scholar] [CrossRef]
- Benali, A.A.; Amrouch, M. Convolutional neural networks backbones for object detection. In Proceedings of the Image and Signal Processing: 9th International Conference, ICISP 2020, Marrakesh, Morocco, 4–6 June 2020. [Google Scholar] [CrossRef]
- Habib, N.; Hasan, M.M.; Reza, M.M.; Rahman, M.M. Ensemble of CheXNet and VGG-19 feature extractor with random forest classifier for pediatric pneumonia detection. SN Comput. Sci. 2020, 1, 359. [Google Scholar] [CrossRef] [PubMed]
- Mateen, M.; Wen, J.; Nasrullah; Song, S.; Huang, Z. Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry 2018, 11, 1. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representions, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.Y.; Ren, S.Q. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Zwartjes, P.; Yoo, J. First break picking with deep learning–evaluation of network architectures. Geophys. Prospect. 2022, 70, 318–342. [Google Scholar] [CrossRef]
- Wang, E.; Wang, D. Using U-Net to Detect Buildings in Satellite Images. J. Comput. Commun. 2022, 10, 132–138. [Google Scholar] [CrossRef]
- Xu, J.J.; Zhang, H.; Tang, C.S.; Cheng, Q.; Liu, B.; Shi, B. Automatic soil desiccation crack recognition using deep learning. Geotechnique 2022, 72, 337–349. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the Fourth International Conference on 3D Vision(3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar] [CrossRef]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Dstl Satellite Imagery Feature Detection. Available online: https://www.kaggle.com/competitions/dstl-satellite-imagery-feature-detection (accessed on 5 February 2023).
- Vharkate, M.N.; Musande, V.B. Fusion based feature extraction and optimal feature selection in remote sensing image retrieval. Multimed. Tools Appl. 2022, 81, 31787–31814. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Pleiss, G.; Maaten, L.V.D.; Weinberger, K.Q. Convolutional networks with dense connectivity. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8704–8716. [Google Scholar] [CrossRef] [PubMed]
- Song, G.; Zhong, E.; Zhou, Q.; Feng, Z. Research and Practice on General 3D Field Data Model in GIS. J. Geomat. 2020, 45, 1–7. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, X.; Lin, L.; Lu, H.; Jiang, Y.; Zhang, N.; Wang, W.; Yue, J.; Li, Z. A Single Data Extraction Algorithm for Oblique Photographic Data Based on the U-Net. Remote Sens. 2024, 16, 979. https://doi.org/10.3390/rs16060979
Wang S, Li X, Lin L, Lu H, Jiang Y, Zhang N, Wang W, Yue J, Li Z. A Single Data Extraction Algorithm for Oblique Photographic Data Based on the U-Net. Remote Sensing. 2024; 16(6):979. https://doi.org/10.3390/rs16060979
Chicago/Turabian StyleWang, Shaohua, Xiao Li, Liming Lin, Hao Lu, Ying Jiang, Ning Zhang, Wenda Wang, Jianwei Yue, and Ziqiong Li. 2024. "A Single Data Extraction Algorithm for Oblique Photographic Data Based on the U-Net" Remote Sensing 16, no. 6: 979. https://doi.org/10.3390/rs16060979
APA StyleWang, S., Li, X., Lin, L., Lu, H., Jiang, Y., Zhang, N., Wang, W., Yue, J., & Li, Z. (2024). A Single Data Extraction Algorithm for Oblique Photographic Data Based on the U-Net. Remote Sensing, 16(6), 979. https://doi.org/10.3390/rs16060979