
PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields


Abstract
1. Introduction
- We apply a dual-tree complex wavelet transform-constrained pooling layer to CV-CNN classification from PolSAR images to decrease the level of speckle noise and preserve some structure features (e.g., edges, sharpness) at the pooling layer.
- We integrate a combination of AL and an MRF model-based framework into CV-CWNN for the PolSAR image classification task, which not only obtains the most informative unlabeled training samples based on the output of CV-CWNN, but also achieves spatial local correlation information to improve the classification performance.
- The experimental results on several PolSAR benchmark datasets demonstrate that our proposed ACV-CWNN-MRF PolSAR classification algorithm outperforms other state-of-the-art CNN-based and CV-CNN-based PolSAR algorithms with fewer labeled samples, especially with speckle noise backgrounds.
2. Methods
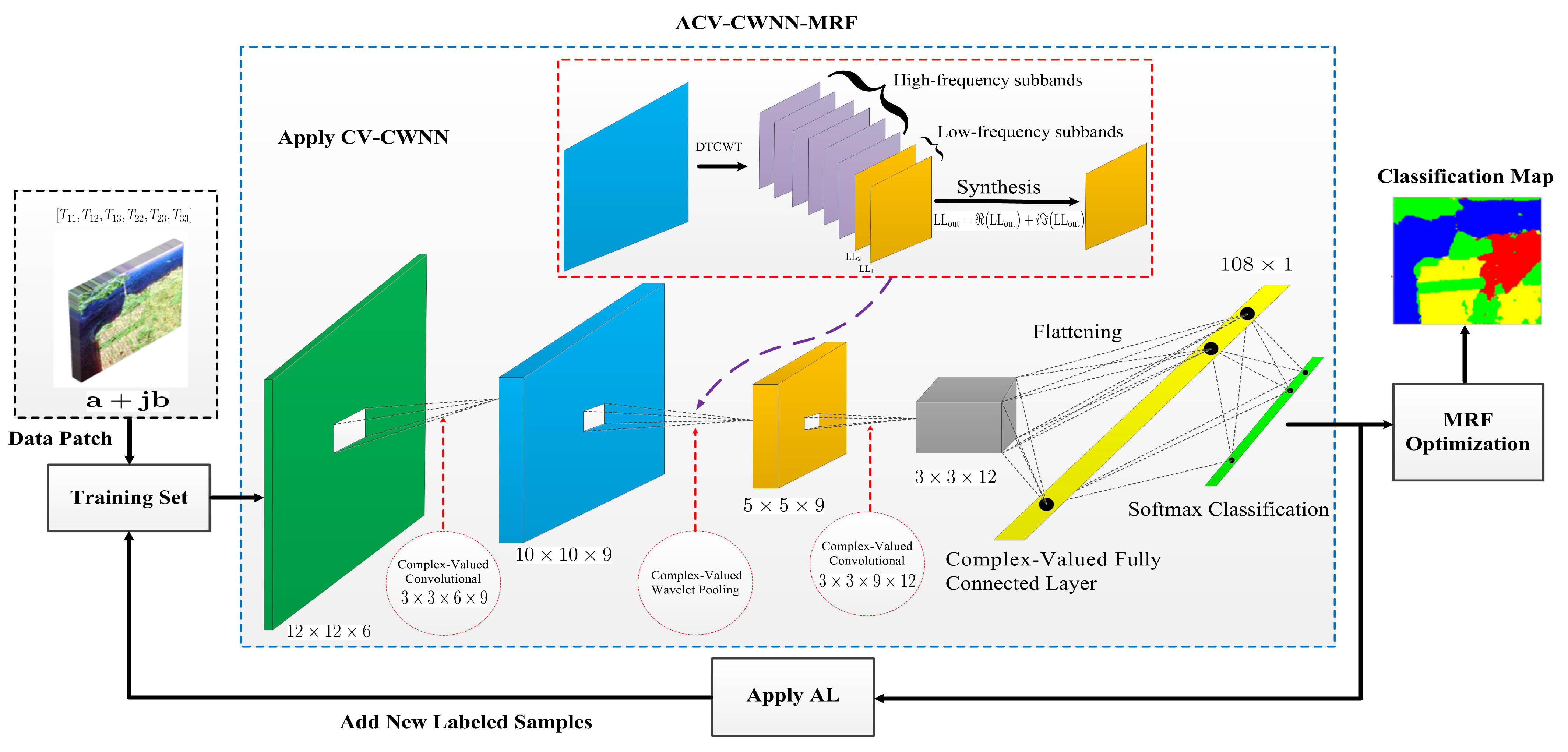
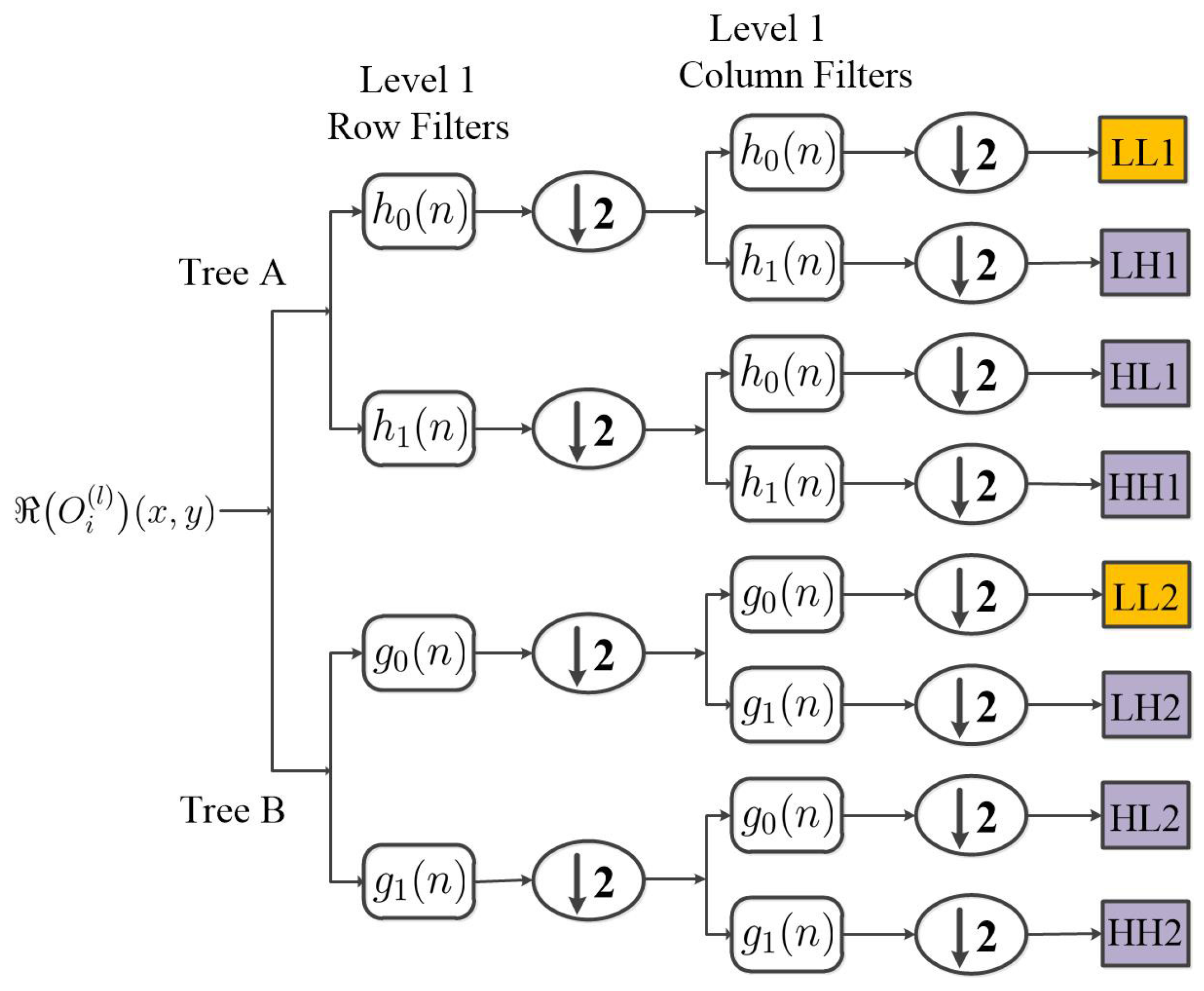
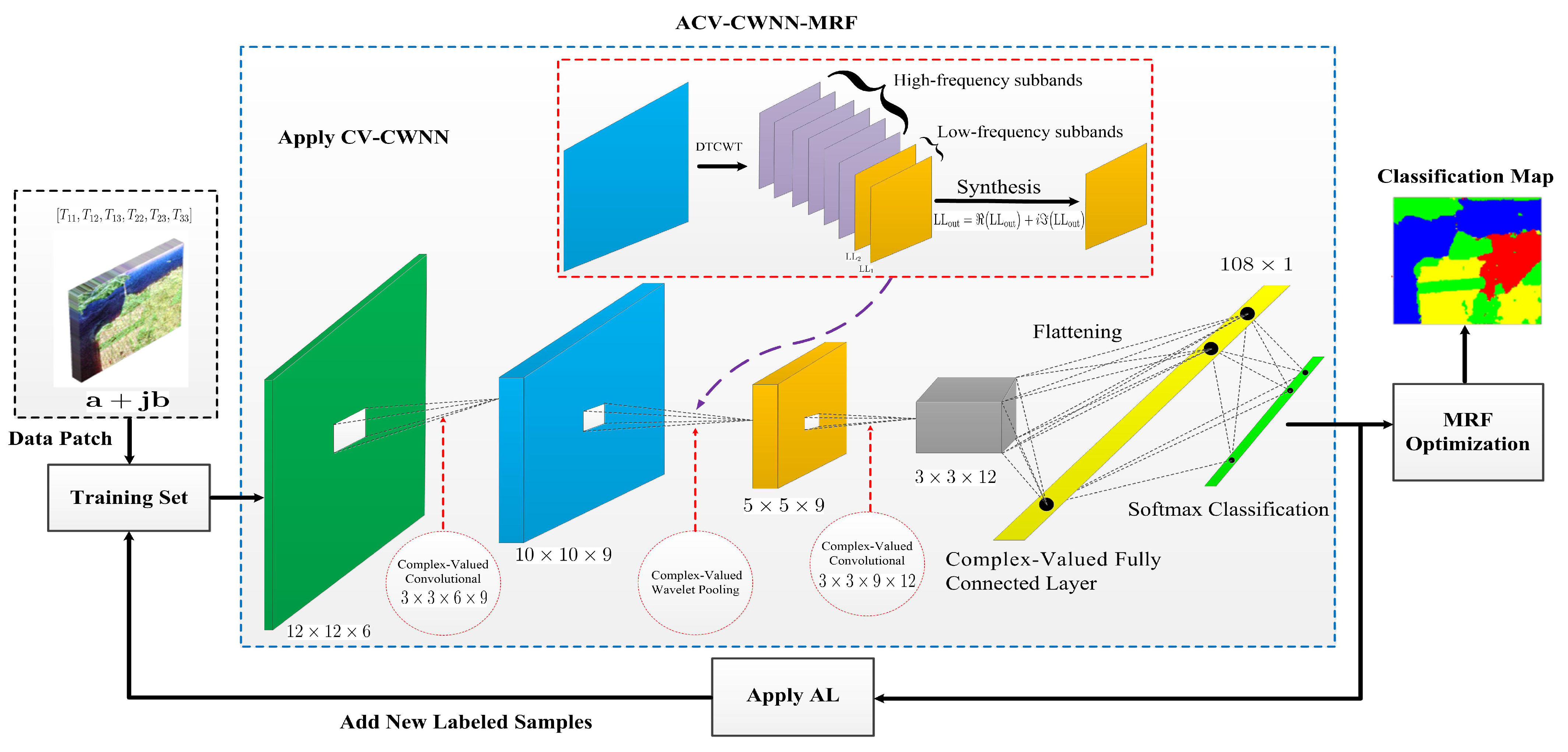
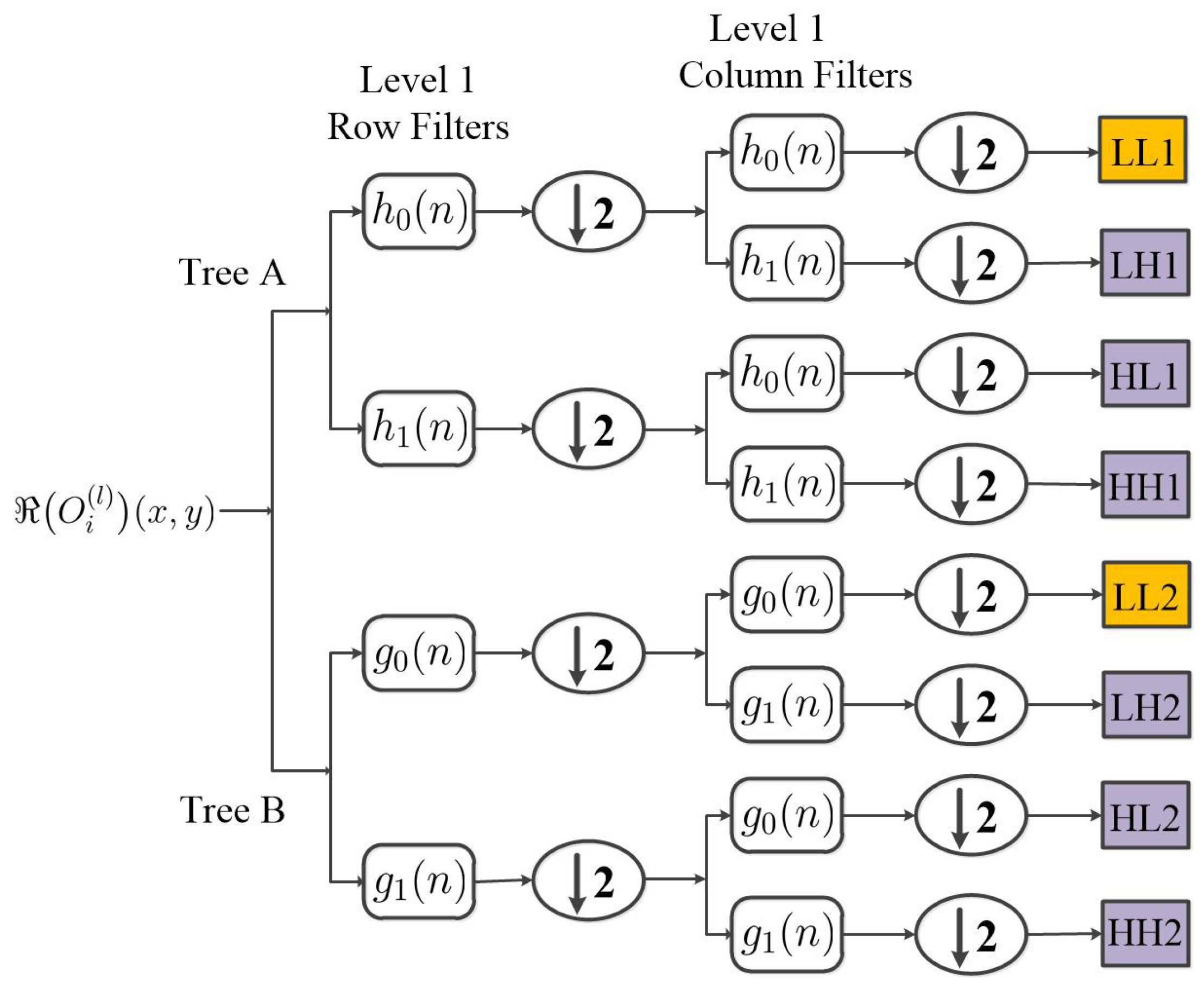
2.1. The Architecture of CV-CWNN
2.2. The Complex-Valued Back-Propagation of CV-CWNN
2.3. AL and MRF-Based CV-CWNN PolSAR Classification
3. PolSAR Data Processing
4. Results
4.1. Parameter Setting
- (1)
- CV-CWNN: The method that is introduced in Section 2.1.
- (2)
- CV-CWNN + BN (CV-CWNN-B): A method that combines the CV-CWNN method and BN strategy.
- (3)
- CV-CWNN + BN + DA (CV-CWNN-BD): A method that incorporates the CV-CWNN-B method with the DA strategy.
- (4)
- CV-CWNN + BN + DA + AL (ACV-CWNN-BD): A method that integrates the AL strategy with the CV-CWNN-BD method.
- (5)
- CV-CWNN + BN + DA + AL +MRF (ACV-CWNN-MRF): A method that integrates the MRF optimization strategy with the ACV-CWNN-BD method.
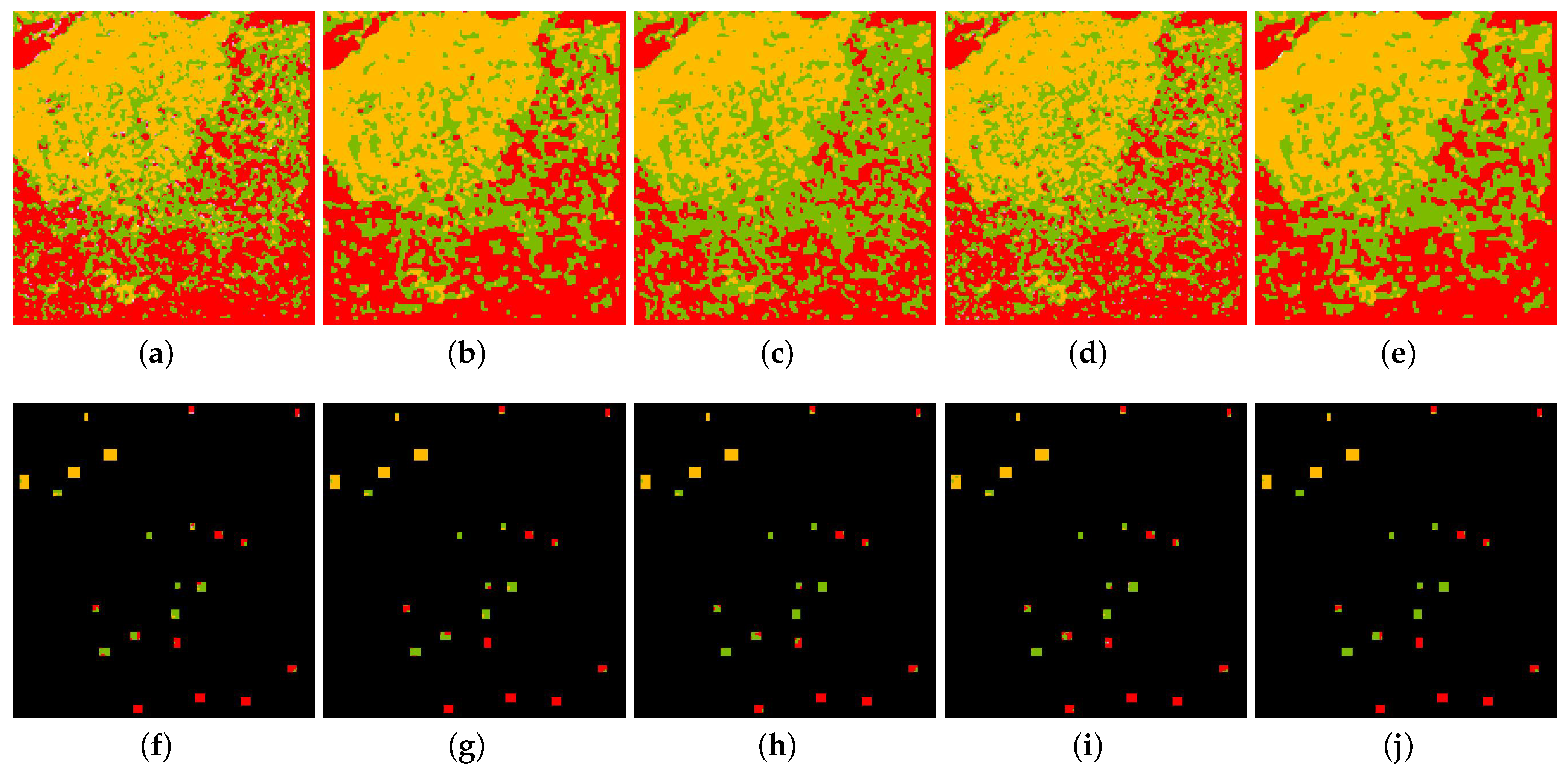
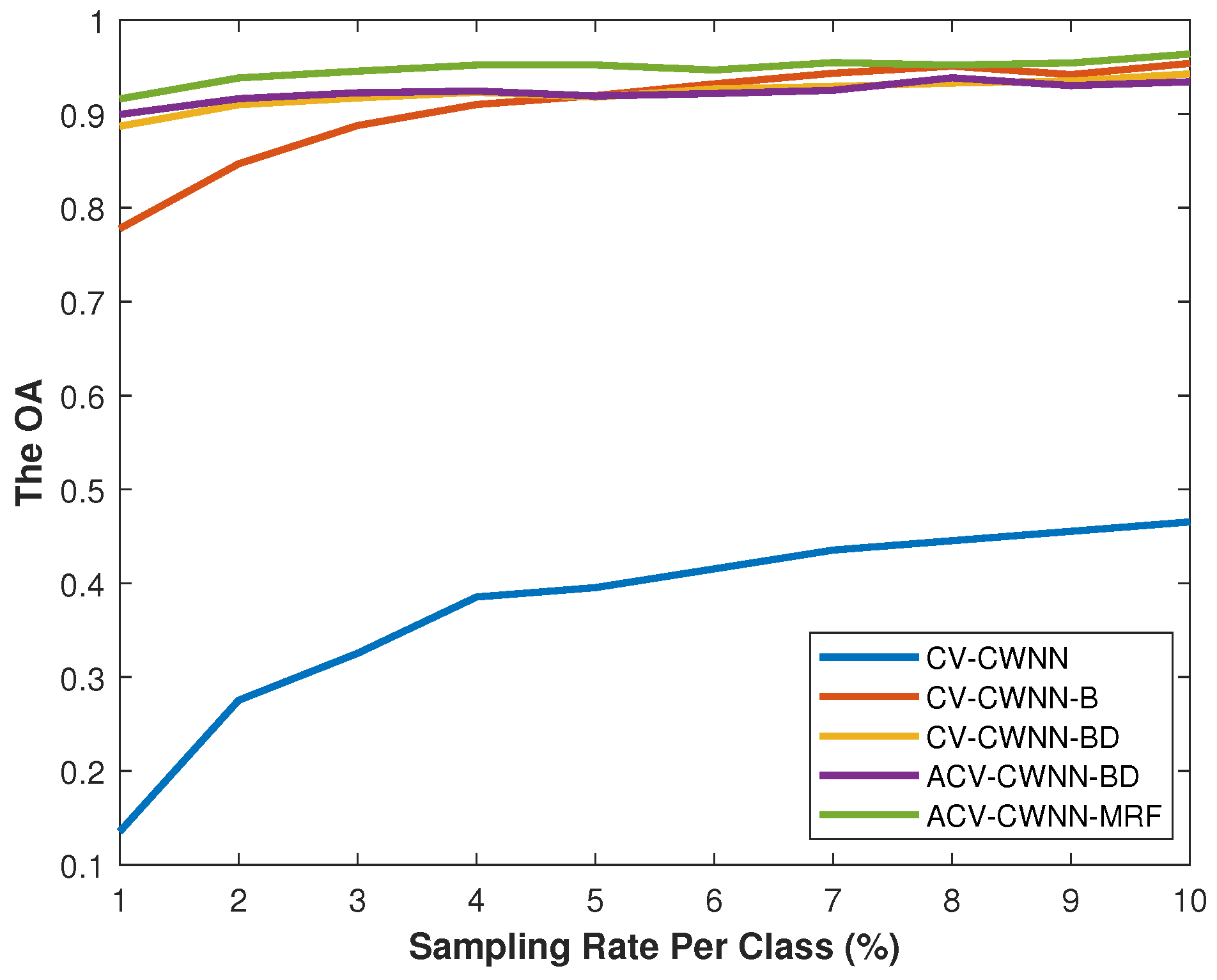
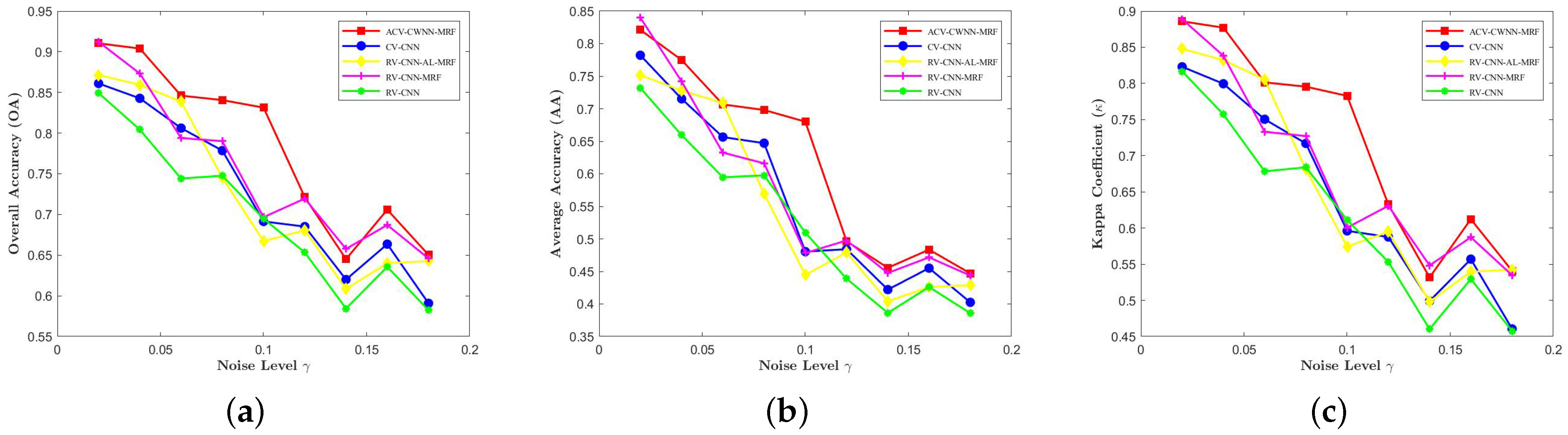
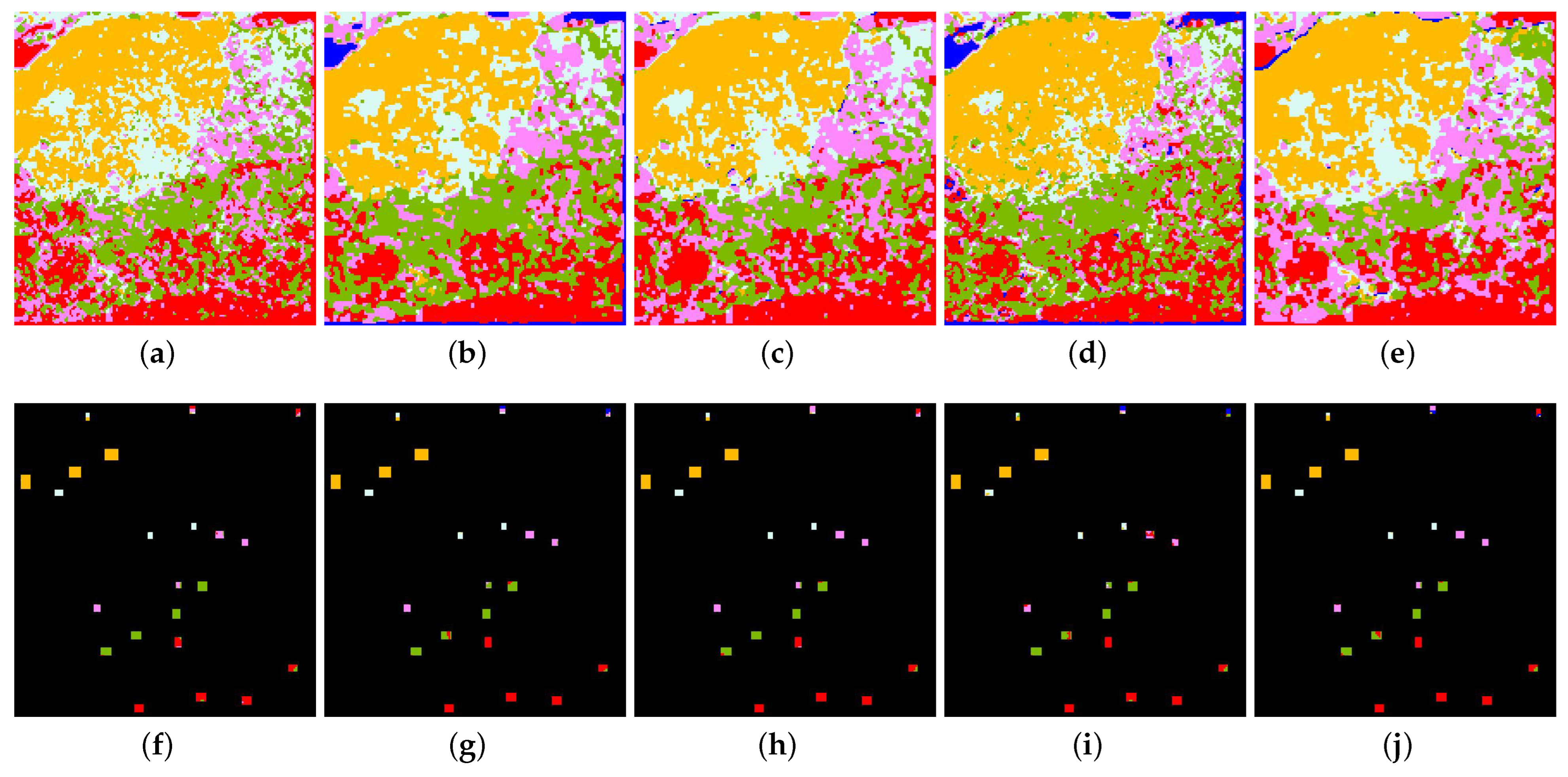
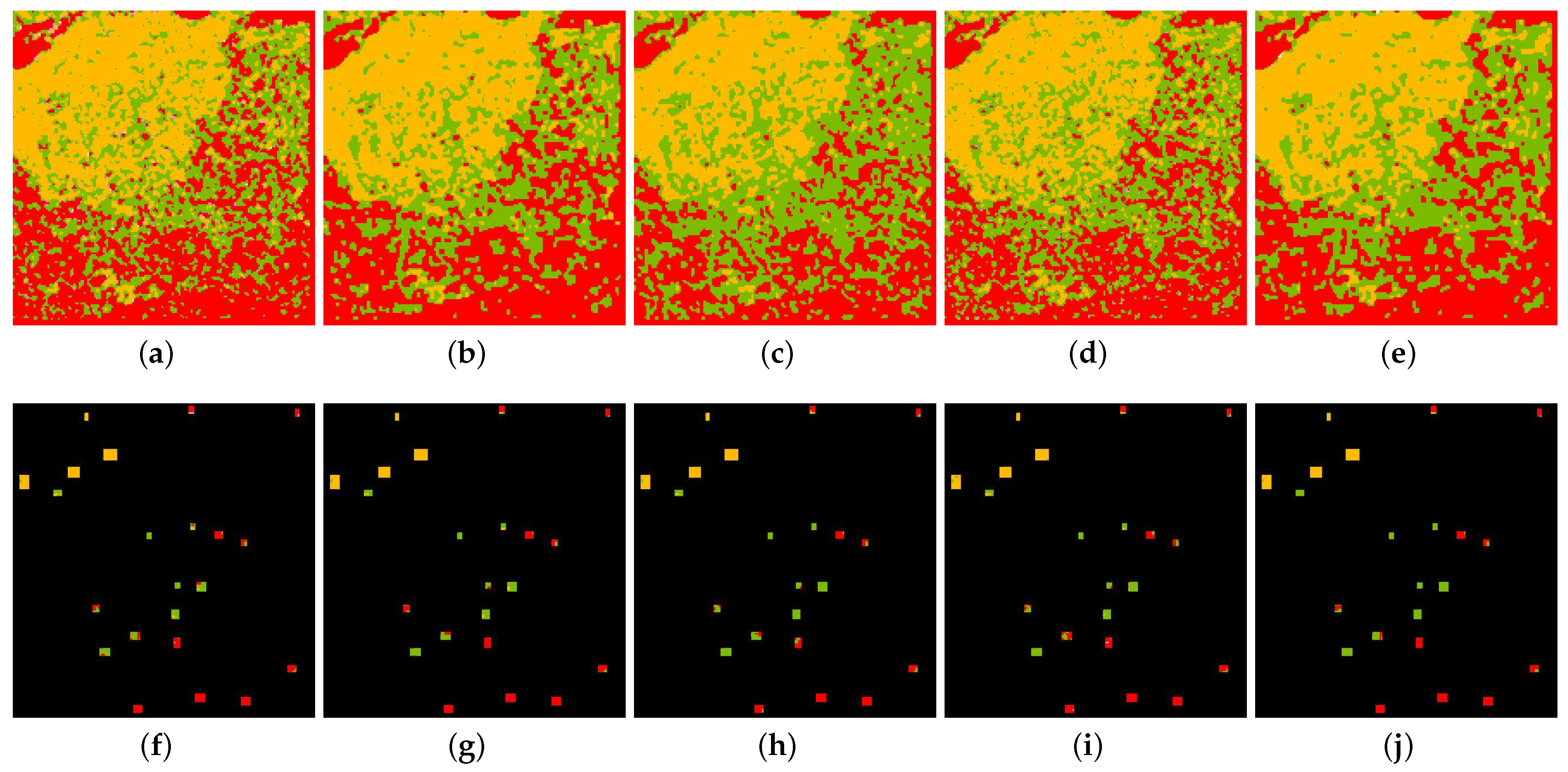
4.2. Effectiveness Verification
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cloude, S. Polarisation: Applications in Remote Sensing; OUP Oxford: Oxford, UK, 2009. [Google Scholar]
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Hänsch, R.; Hellwich, O. Skipping the real world: Classification of PolSAR images without explicit feature extraction. ISPRS J. Photogramm. Remote Sens. 2018, 140, 122–132. [Google Scholar] [CrossRef]
- Durieux, L.; Lagabrielle, E.; Nelson, A. A method for monitoring building construction in urban sprawl areas using object-based analysis of Spot 5 images and existing GIS data. ISPRS J. Photogramm. Remote Sens. 2008, 63, 399–408. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. A multiple conditional random fields ensemble model for urban area detection in remote sensing optical images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3978–3988. [Google Scholar] [CrossRef]
- Besic, N.; Vasile, G.; Chanussot, J.; Stankovic, S. Polarimetric incoherent target decomposition by means of independent component analysis. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1236–1247. [Google Scholar] [CrossRef]
- Doulgeris, A.P.; Anfinsen, S.N.; Eltoft, T. Classification with a non-Gaussian model for PolSAR data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2999–3009. [Google Scholar] [CrossRef]
- Kong, J.; Swartz, A.; Yueh, H.; Novak, L.; Shin, R. Identification of terrain cover using the optimum polarimetric classifier. J. Electromagn. Waves Appl. 1988, 2, 171–194. [Google Scholar]
- Tao, M.; Zhou, F.; Liu, Y.; Zhang, Z. Tensorial independent component analysis-based feature extraction for polarimetric SAR data classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2481–2495. [Google Scholar] [CrossRef]
- Lardeux, C.; Frison, P.L.; Tison, C.; Souyris, J.C.; Stoll, B.; Fruneau, B.; Rudant, J.P. Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4143–4152. [Google Scholar] [CrossRef]
- Ersahin, K.; Cumming, I.G.; Ward, R.K. Segmentation and classification of polarimetric SAR data using spectral graph partitioning. IEEE Trans. Geosci. Remote Sens. 2009, 48, 164–174. [Google Scholar] [CrossRef]
- Bi, H.; Sun, J.; Xu, Z. Unsupervised PolSAR image classification using discriminative clustering. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3531–3544. [Google Scholar] [CrossRef]
- Antropov, O.; Rauste, Y.; Astola, H.; Praks, J.; Häme, T.; Hallikainen, M.T. Land cover and soil type mapping from spaceborne PolSAR data at L-band with probabilistic neural network. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5256–5270. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR image classification based on Wishart DBN and local spatial information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Jiao, L.; Liu, F. Wishart deep stacking network for fast POLSAR image classification. IEEE Trans. Image Process. 2016, 25, 3273–3286. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-valued convolutional neural network and its application in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Bi, H.; Sun, J.; Xu, Z. A graph-based semisupervised deep learning model for PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2116–2132. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Samat, A.; Gamba, P.; Du, P.; Luo, J. Active extreme learning machines for quad-polarimetric SAR imagery classification. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 305–319. [Google Scholar] [CrossRef]
- Liu, W.; Yang, J.; Li, P.; Han, Y.; Zhao, J.; Shi, H. A novel object-based supervised classification method with active learning and random forest for PolSAR imagery. Remote Sens. 2018, 10, 1092. [Google Scholar] [CrossRef]
- Bi, H.; Xu, F.; Wei, Z.; Xue, Y.; Xu, Z. An active deep learning approach for minimally supervised PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9378–9395. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial classification of hyperspectral data using loopy belief propagation and active learning. IEEE Trans. Geosci. Remote Sens. 2012, 51, 844–856. [Google Scholar] [CrossRef]
- Cao, X.; Yao, J.; Xu, Z.; Meng, D. Hyperspectral image classification with convolutional neural network and active learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4604–4616. [Google Scholar] [CrossRef]
- De Silva, D.; Fernando, S.; Piyatilake, I.; Karunarathne, A. Wavelet based edge feature enhancement for convolutional neural networks. In Proceedings of the Eleventh International Conference on Machine Vision (ICMV 2018), Munich, Germany, 1–3 November 2018; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11041, p. 110412R. [Google Scholar]
- Liu, P.; Zhang, H.; Lian, W.; Zuo, W. Multi-level wavelet convolutional neural networks. IEEE Access 2019, 7, 74973–74985. [Google Scholar] [CrossRef]
- Sahito, F.; Zhiwen, P.; Ahmed, J.; Memon, R.A. Wavelet-integrated deep networks for single image super-resolution. Electronics 2019, 8, 553. [Google Scholar] [CrossRef]
- Guberman, N. On complex valued convolutional neural networks. arXiv 2016, arXiv:1602.09046. [Google Scholar]
- Tygert, M.; Bruna, J.; Chintala, S.; LeCun, Y.; Piantino, S.; Szlam, A. A mathematical motivation for complex-valued convolutional networks. Neural Comput. 2016, 28, 815–825. [Google Scholar] [CrossRef]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, S.; Santos, J.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C. Deep Complex Networks. arXiv 2018, arXiv:1705.09792. [Google Scholar]
- Benvenuto, N.; Piazza, F. On the complex backpropagation algorithm. IEEE Trans. Signal Process. 1992, 40, 967–969. [Google Scholar] [CrossRef]
- Lau, M.M.; Lim, K.H.; Gopalai, A.A. Malaysia traffic sign recognition with convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1006–1010. [Google Scholar]
- Kingsbury, N. Complex wavelets for shift invariant analysis and filtering of signals. Appl. Comput. Harmon. Anal. 2001, 10, 234–253. [Google Scholar] [CrossRef]
- Baraniuk, R.; Kingsbury, N.; Selesnick, I. The dual-tree complex wavelet transform-a coherent framework for multiscale signal and image processing. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar]
- Kingsbury, N. Image processing with complex wavelets. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1999, 357, 2543–2560. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- MacKay, D.J. Information-based objective functions for active data selection. Neural Comput. 1992, 4, 590–604. [Google Scholar]
- Luo, T.; Kramer, K.; Goldgof, D.B.; Hall, L.O.; Samson, S.; Remsen, A.; Hopkins, T.; Cohn, D. Active learning to recognize multiple types of plankton. J. Mach. Learn. Res. 2005, 6, 589–613. [Google Scholar]
- Settles, B. Active learning. Synth. Lect. Artif. Intell. Mach. Learn. 2012, 6, 1–114. [Google Scholar]
- Joshi, A.J.; Porikli, F.; Papanikolopoulos, N. Multi-class active learning for image classification. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 2372–2379. [Google Scholar]
- Farag, A.A.; Mohamed, R.M.; El-Baz, A. A unified framework for map estimation in remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1617–1634. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar]
- Kolmogorov, V. Convergent tree-reweighted message passing for energy minimization. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; pp. 182–189. [Google Scholar]
- Yedidia, J.S.; Freeman, W.T.; Weiss, Y. Constructing free-energy approximations and generalized belief propagation algorithms. IEEE Trans. Inf. Theory 2005, 51, 2282–2312. [Google Scholar]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- Xie, H.; Pierce, L.E.; Ulaby, F.T. Statistical properties of logarithmically transformed speckle. IEEE Trans. Geosci. Remote Sens. 2002, 40, 721–727. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CV-CWNN | CV-CWNN-B | CV-CWNN-BD | ACV-CWNN-BD | ACV-CWNN-MRF |
|---|---|---|---|---|---|
| 1st round, 500 samples | 11.52 (2.86) | 17.16 (1.51) | 46.29 (2.12) | 60.74 (2.47) | 61.66 (1.51) |
| 2st round, 550 samples | 12.26 (1.80) | 28.13 (2.91) | 68.85 (1.92) | 70.14 (2.92) | 72.33 (2.14) |
| Class | CV-CWNN | CV-CWNN-B | CV-CWNN-BD | ACV-CWNN-BD | ACV-CWNN-MRF |
|---|---|---|---|---|---|
| 1 | 0 | 99.78 | 99.54 | 99.63 | 99.80 |
| 2 | 0 | 90.83 | 91.27 | 91.54 | 95.39 |
| 3 | 0 | 50.34 | 93.74 | 92.88 | 96.67 |
| 4 | 0 | 99.09 | 98.58 | 96.94 | 97.70 |
| 5 | 99.94 | 99.65 | 99.76 | 99.94 | 99.95 |
| 6 | 0 | 0.15 | 42.34 | 46.47 | 57.50 |
| 7 | 0 | 99.82 | 99.71 | 99.67 | 99.78 |
| 8 | 0 | 0 | 49.71 | 80.90 | 88.60 |
| 9 | 0 | 92.73 | 99.07 | 96.87 | 98.73 |
| 10 | 0 | 0 | 94.05 | 95.40 | 98.19 |
| 11 | 0 | 96.21 | 95.37 | 95.42 | 97.28 |
| 12 | 99.39 | 99.84 | 99.63 | 99.78 | 99.70 |
| 13 | 0 | 71.49 | 88.03 | 82.24 | 87.32 |
| 14 | 0 | 93.69 | 93.33 | 95.97 | 96.40 |
| AA | 14.24 | 70.97 | 88.87 | 90.89 | 93.79 |
| OA | 38.85 | 94.37 | 97.25 | 97.36 | 98.14 |
| 24.19 | 93.35 | 96.75 | 96.89 | 97.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Li, Y. PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields. Remote Sens. 2024, 16, 1094. https://doi.org/10.3390/rs16061094
Liu L, Li Y. PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields. Remote Sensing. 2024; 16(6):1094. https://doi.org/10.3390/rs16061094
Chicago/Turabian StyleLiu, Lu, and Yongxiang Li. 2024. "PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields" Remote Sensing 16, no. 6: 1094. https://doi.org/10.3390/rs16061094
APA StyleLiu, L., & Li, Y. (2024). PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields. Remote Sensing, 16(6), 1094. https://doi.org/10.3390/rs16061094