
Fusion of Single and Integral Multispectral Aerial Images


Abstract
1. Introduction
- (1)
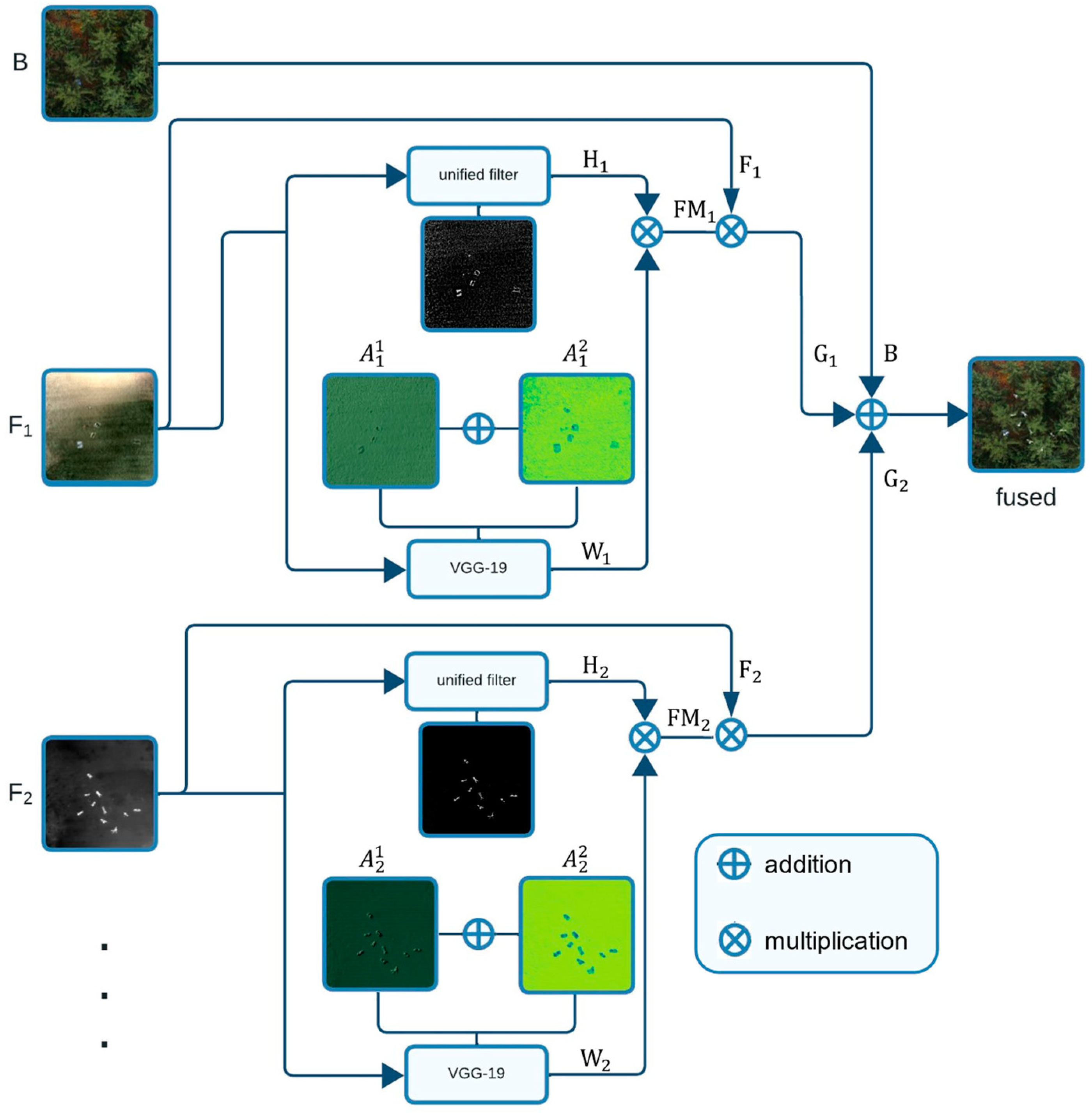
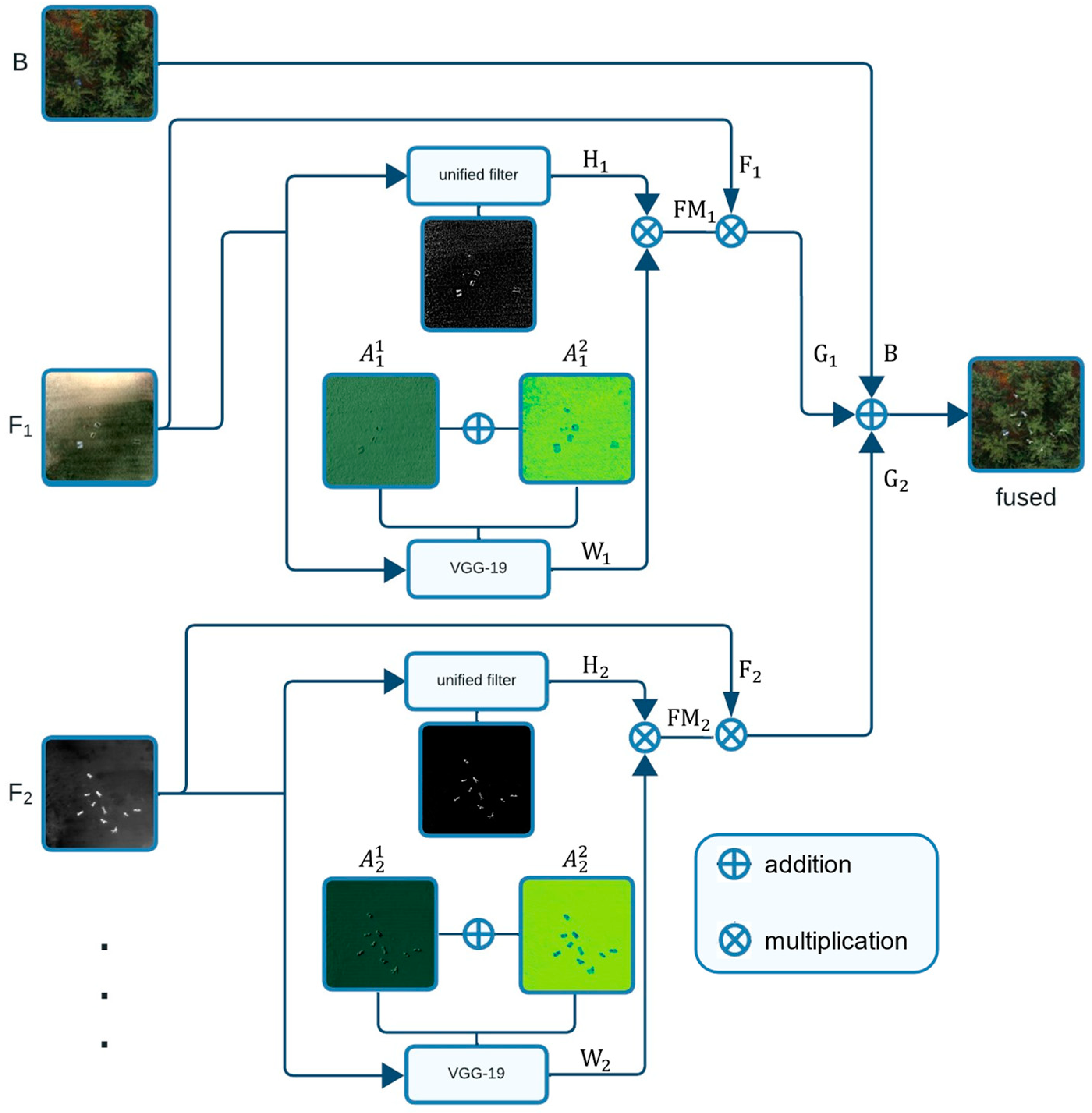
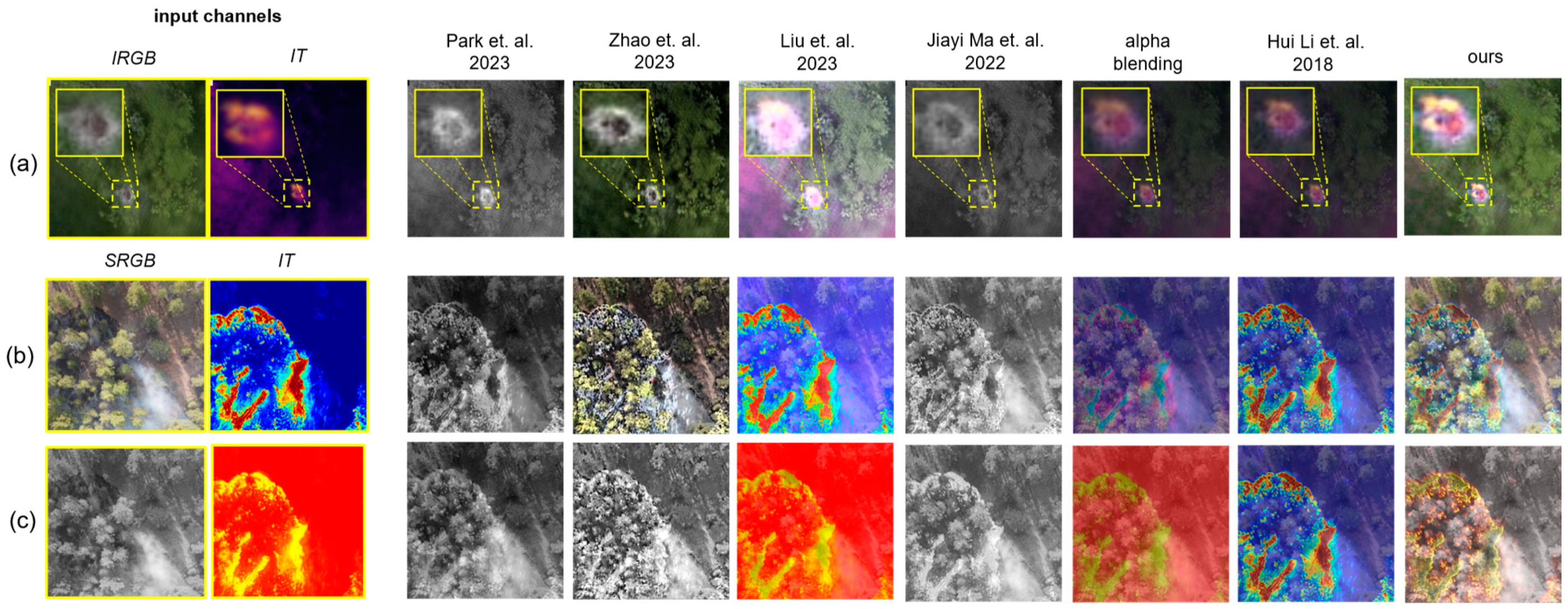
- We present the first fusion approach for multispectral aerial images that combines the most salient features from conventional aerial images and integral images which result from synthetic aperture sensing. While the first contains the environment’s spatial references for orientation, the latter contains features of unoccluded targets that would normally be hidden by dense vegetation. Our model does not require manually tuned parameters, can be extended to an arbitrary number and arbitrary combinations of spectral channels, and is reconfigurable for addressing different use cases. This method is explained in Section 2.
- (2)
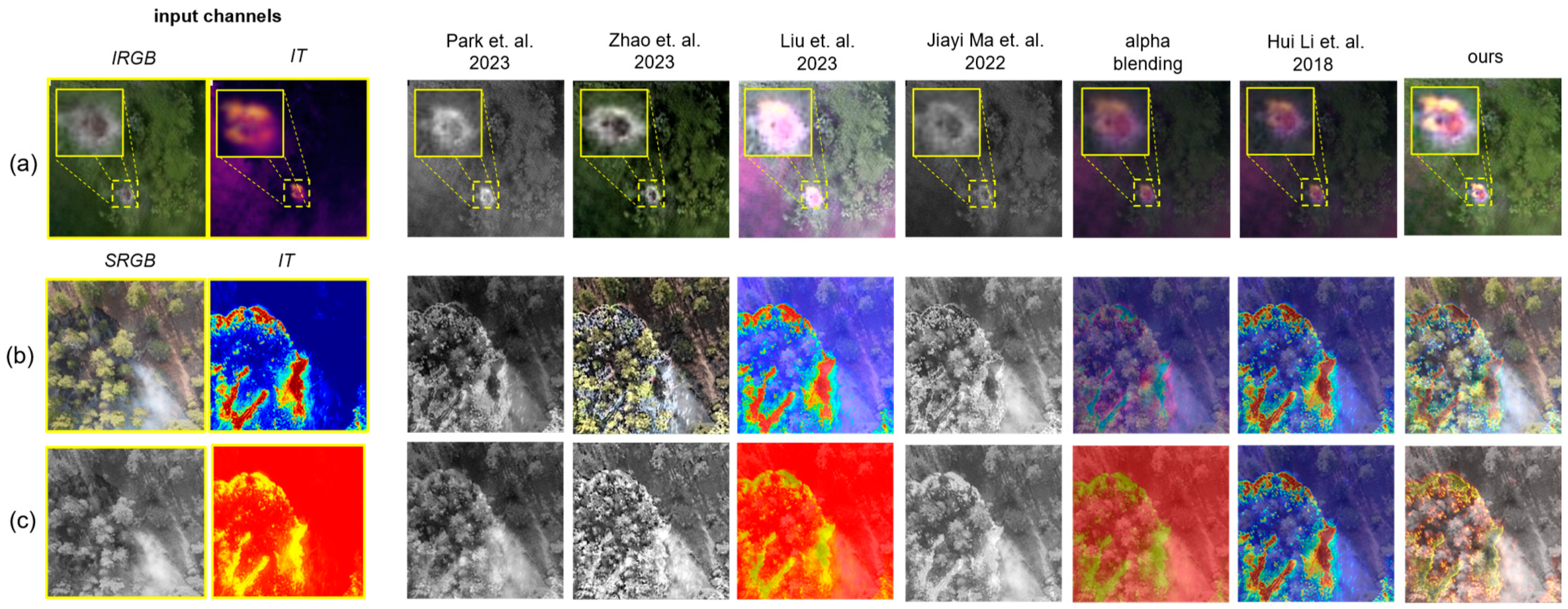
- Our method outperforms state-of-the-art two-channel and multi-channel fusion approaches visually and quantitatively in common metrics, such as mutual information, visual information fidelity, and peak signal-to-noise ratio. We demonstrate results for various use cases, such as search and rescue, wildfire detection, and wildlife observation. These results are presented in Section 3.
2. Materials and Methods
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kurmi, I.; Schedl, D.C.; Bimber, O. Airborne Optical Sectioning. J. Imaging 2018, 4, 102. [Google Scholar] [CrossRef]
- Schedl, D.C.; Kurmi, I.; Bimber, O. Airborne Optical Sectioning for Nesting Observation. Sci. Rep. 2020, 10, 7254. [Google Scholar] [CrossRef] [PubMed]
- Schedl, D.C.; Kurmi, I.; Bimber, O. Search and Rescue with Airborne Optical Sectioning. Nat. Mach. Intell. 2020, 2, 783–790. [Google Scholar] [CrossRef]
- Schedl, D.C.; Kurmi, I.; Bimber, O. An Autonomous Drone for Search and Rescue in Forests Using Airborne Optical Sectioning. Sci. Robot. 2021, 6, eabg1188. [Google Scholar] [CrossRef] [PubMed]
- Nathan, R.J.A.A.; Kurmi, I.; Bimber, O. Drone Swarm Strategy for the Detection and Tracking of Occluded Targets in Complex Environments. Nat. Commun. Eng. 2023, 2, 55. [Google Scholar] [CrossRef]
- Vivone, G. Multispectral and Hyperspectral Image Fusion in Remote Sensing: A Survey. Inf. Fusion 2023, 89, 405–417. [Google Scholar] [CrossRef]
- Li, S.; Yang, B.; Hu, J. Performance Comparison of Different Multi-Resolution Transforms for Image Fusion. Inf. Fusion 2011, 12, 74–84. [Google Scholar] [CrossRef]
- Cao, L.; Jin, L.; Tao, H.; Li, G.; Zhuang, Z.; Zhang, Y. Multi-Focus Image Fusion Based on Spatial Frequency in Discrete Cosine Transform Domain. IEEE Signal Process. Lett. 2015, 22, 220–224. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and Visible Image Fusion Based on Target-Enhanced Multiscale Transform Decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Awad, M.; Elliethy, A.; Aly, H.A. Adaptive Near-Infrared and Visible Fusion for Fast Image Enhancement. IEEE Trans. Comput. Imag. 2020, 6, 408–418. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. Multi-Focus Image Fusion Using Dictionary Learning and Low-Rank Representation. In Proceedings of the Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 675–686. [Google Scholar]
- Li, H.; Wu, X.-J.; Kittler, J. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. Infrared and Visible Image Fusion Using a Deep Learning Framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Jian, L.; Yang, X.; Liu, Z.; Jeon, G.; Gao, M.; Chisholm, D. SEDRFuse: A Symmetric Encoder–Decoder With Residual Block Network for Infrared and Visible Image Fusion. IEEE Trans. Instrum. and Meas. 2020, 70, 5002215. [Google Scholar] [CrossRef]
- Zhao, W.; Xie, S.; Zhao, F.; He, Y.; Lu, H. MetaFusion: Infrared and Visible Image Fusion via Meta-Feature Embedding From Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13955–13965. [Google Scholar]
- Li, H.; Wu, X.-J.; Kittler, J. RFN-Nest: An End-to-End Residual Fusion Network for Infrared and Visible Images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification Saliency-Based Rule for Visible and Infrared Image Fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Park, S.; Vien, A.G.; Lee, C. Cross-Modal Transformers for Infrared and Visible Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 770–785. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-Domain Long-Range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; Luo, Z.; Fan, X. CoCoNet: Coupled Contrastive Learning Network with Multi-Level Feature Ensemble for Multi-Modality Image Fusion. Int. J. Comput. Vis. 2023, 1–28. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A Generative Adversarial Network for Infrared and Visible Image Fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, J.; Tian, X.; Ma, J. GAN-FM: Infrared and Visible Image Fusion Using GAN With Full-Scale Skip Connection and Dual Markovian Discriminators. IEEE Trans. Comput. Imaging 2021, 7, 1134–1147. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image Fusion With Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hopkins, B.; O’Neill, L.; Afghah, F.; Razi, A.; Rowell, E.; Watts, A.; Fule, P.; Coen, J. FLAME 2: Fire Detection and Modeling: Aerial Multi-Spectral Image Dataset. IEEE Dataport 2022. Available online: https://ieee-dataport.org/open-access/flame-2-fire-detection-and-modeling-aerial-multi-spectral-image-dataset (accessed on 6 December 2023).
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-Aware Dual Adversarial Learning and a Multi-Scenario Multi-Modality Benchmark To Fuse Infrared and Visible for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Toet, A. The TNO Multiband Image Data Collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Sankaran, P.G.; Sunoj, S.M.; Nair, N.U. Kullback–Leibler Divergence: A Quantile Approach. Stat. Probab. Lett. 2016, 111, 72–79. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A New Image Fusion Performance Metric Based on Visual Information Fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Victor Ikechukwu, A.; Murali, S.; Deepu, R.; Shivamurthy, R.C. ResNet-50 vs VGG-19 vs Training from Scratch: A Comparative Analysis of the Segmentation and Classification of Pneumonia from Chest X-ray Images. Glob. Transit. Proc. 2021, 2, 375–381. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VIF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| Park et al. [19] | 0.936 | 0.675 | 0.879 | 0.667 | 0.718 | 0.940 | 0.998 | 0.452 | 0.600 | 0.762 |
| Zhao et al. [16] | 0.849 | 0.563 | 0.628 | 0.638 | 0.550 | 0.899 | 0.849 | 0.428 | 0.473 | 0.653 |
| Liu et al. [21] | 0.892 | 0.701 | 0.698 | 0.689 | 0.530 | 0.770 | 1.015 | 0.427 | 0.235 | 0.662 |
| Jiayi Ma et al. [20] | 0.898 | 0.129 | 0.912 | 0.175 | 0.692 | 0.624 | 0.884 | 0.539 | 0.119 | 0.552 |
| ours | 1.069 | 1.002 | 1.024 | 0.774 | 0.849 | 1.072 | 1.047 | 0.635 | 0.742 | 0.912 |
| MI | ||||||||||
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| Park et al. [19] | 0.547 | 0.505 | 1.266 | 0.831 | 1.016 | 0.420 | 0.525 | 0.739 | 0.937 | 0.754 |
| Zhao et al. [16] | 0.796 | 0.388 | 1.119 | 0.708 | 1.161 | 0.901 | 0.514 | 0.584 | 0.637 | 0.756 |
| Liu et al. [21] | 0.643 | 0.552 | 1.444 | 0.606 | 1.194 | 0.634 | 0.605 | 1.023 | 0.750 | 0.828 |
| Jiayi Ma et al. [20] | 0.597 | 0.063 | 1.832 | 0.424 | 1.022 | 0.422 | 0.846 | 0.935 | 0.371 | 0.724 |
| ours | 1.207 | 1.444 | 1.843 | 1.121 | 1.346 | 1.094 | 1.526 | 1.210 | 1.281 | 1.341 |
| PSNR | ||||||||||
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| Park et al. [19] | 20.942 | 20.509 | 17.915 | 19.475 | 13.723 | 12.849 | 20.336 | 11.250 | 12.455 | 16.606 |
| Zhao et al. [16] | 24.642 | 19.808 | 16.912 | 21.904 | 15.049 | 16.819 | 19.792 | 10.728 | 10.921 | 17.397 |
| Liu et al. [21] | 20.923 | 18.110 | 12.495 | 21.100 | 14.298 | 16.004 | 19.258 | 12.111 | 7.084 | 15.709 |
| Jiayi Ma et al. [20] | 24.791 | 18.304 | 20.792 | 20.989 | 14.460 | 14.051 | 19.535 | 12.003 | 10.791 | 17.301 |
| ours | 26.503 | 23.523 | 21.899 | 26.850 | 16.514 | 18.865 | 25.501 | 12.917 | 12.861 | 20.603 |
| VIF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| alpha blending | 0.623 | 0.685 | 0.779 | 0.579 | 0.447 | 0.422 | 0.616 | 0.434 | 0.524 | 0.568 |
| Hui Li et al. [13] | 0.732 | 0.797 | 0.803 | 0.627 | 0.515 | 0.434 | 0.637 | 0.462 | 0.562 | 0.619 |
| ours | 1.068 | 1.040 | 1.023 | 0.774 | 0.863 | 1.088 | 1.047 | 0.635 | 0.742 | 0.920 |
| MI | ||||||||||
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| alpha blending | 1.006 | 1.230 | 1.231 | 0.909 | 0.877 | 1.134 | 0.699 | 0.828 | 1.245 | 1.018 |
| Hui Li et al. [13] | 1.020 | 1.245 | 1.228 | 0.904 | 1.190 | 1.102 | 0.675 | 0.939 | 1.189 | 1.055 |
| ours | 1.149 | 1.940 | 1.837 | 1.121 | 1.419 | 1.173 | 1.526 | 1.210 | 1.281 | 1.406 |
| PSNR | ||||||||||
| (Figure 4a) | (Figure 4b) | (Figure 4c) | (Figure 4d) | (Figure 4e) | (Figure 4f) | (Figure 5a) | (Figure 5b) | (Figure 5c) | AVG | |
| alpha blending | 18.827 | 21.461 | 18.138 | 24.832 | 15.227 | 14.938 | 20.080 | 11.032 | 11.068 | 17.289 |
| Hui Li et al. [13] | 16.307 | 19.291 | 18.131 | 24.800 | 14.130 | 14.930 | 19.987 | 9.511 | 9.112 | 16.244 |
| ours | 20.581 | 22.068 | 21.350 | 26.850 | 16.695 | 16.904 | 25.501 | 12.917 | 12.861 | 19.525 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Youssef, M.; Bimber, O. Fusion of Single and Integral Multispectral Aerial Images. Remote Sens. 2024, 16, 673. https://doi.org/10.3390/rs16040673
Youssef M, Bimber O. Fusion of Single and Integral Multispectral Aerial Images. Remote Sensing. 2024; 16(4):673. https://doi.org/10.3390/rs16040673
Chicago/Turabian StyleYoussef, Mohamed, and Oliver Bimber. 2024. "Fusion of Single and Integral Multispectral Aerial Images" Remote Sensing 16, no. 4: 673. https://doi.org/10.3390/rs16040673
APA StyleYoussef, M., & Bimber, O. (2024). Fusion of Single and Integral Multispectral Aerial Images. Remote Sensing, 16(4), 673. https://doi.org/10.3390/rs16040673