1. Introduction
Radar sensors possess distinct advantages over visible optical sensors, including all-weather, all-time, and long-range detection capabilities, which render them invaluable in various domains such as the national economy and urban planning. These characteristics enable radar systems to perform effective monitoring and analysis even under complex environmental conditions, thus providing critical support for decision-making [
1]. Microwave imaging technology plays a pivotal role in the context of radar automatic target recognition (ATR). The advent of deep learning has significantly advanced the field of ATR by improving recognition performance, exceeding traditional image processing methods in terms of accuracy and detection speed [
2]. However, despite the remarkable progress achieved through deep learning technologies, the internal mechanisms of these models often remain opaque and lack interpretability. This limitation above poses a substantial barrier to the reliable and trustworthy application of radar image target recognition technologies [
3,
4,
5].
Despite the robust representation learning capabilities demonstrated by deep neural networks, most mainstream approaches currently rely primarily on amplitude information for target recognition, often overlooking the significance of prior knowledge [
6]. Incorporating prior knowledge can not only enhance the representational power of features but also improve the interpretability of the model, making the recognition results more reliable and comprehensible. Existing state-of-the-art (SOTA) methods are currently focused on extracting various types of information from radar image data, including scatter point centers, shadow information, phase information, and target size information. Thus, multiple forms of information can be integrated to achieve more discriminative target features using techniques such as feature concatenation. For example, Liu et al. proposed a multiregion and multiscale feature extraction module that effectively extracts scattering center features and fuses these features with image pixel features for recognition, thus improving accuracy and robustness of recognition outcomes [
7]. Furthermore, Zhang et al. integrated the information on target size into the decision-making process through a collaborative decision module, further enhancing the precision of recognition [
8]. Zeng et al. designed an architecture based on a complex value network that effectively merges amplitude and phase information to enhance the feature representation capabilities of the model [
9]. Meanwhile, Choi et al. utilized a domain fusion module to integrate shadow information with the image feature, thus strengthening the model’s ability to recognize targets in complex environments [
10]. These approaches combine prior knowledge with amplitude information, utilizing the fused features for target recognition, which significantly outperforms traditional methods that do not incorporate prior knowledge, especially for the evaluation metrics of accuracy. However, these advanced approaches often require complex image processing, leading to increased computational costs. Furthermore, they typically overlook correlations between different categories during feature fusion, indicating that there is still room for further performance enhancement [
11]. It can be inferred that simplifying the feature extraction and fusion processes while strengthening the modeling of intercategory relationships can improve the efficiency and accuracy of radar image target recognition [
12].
To address the aforementioned issues, we introduced the knowledge of structural attributes into the network for the first time and proposed a coding representation for structural attributes [
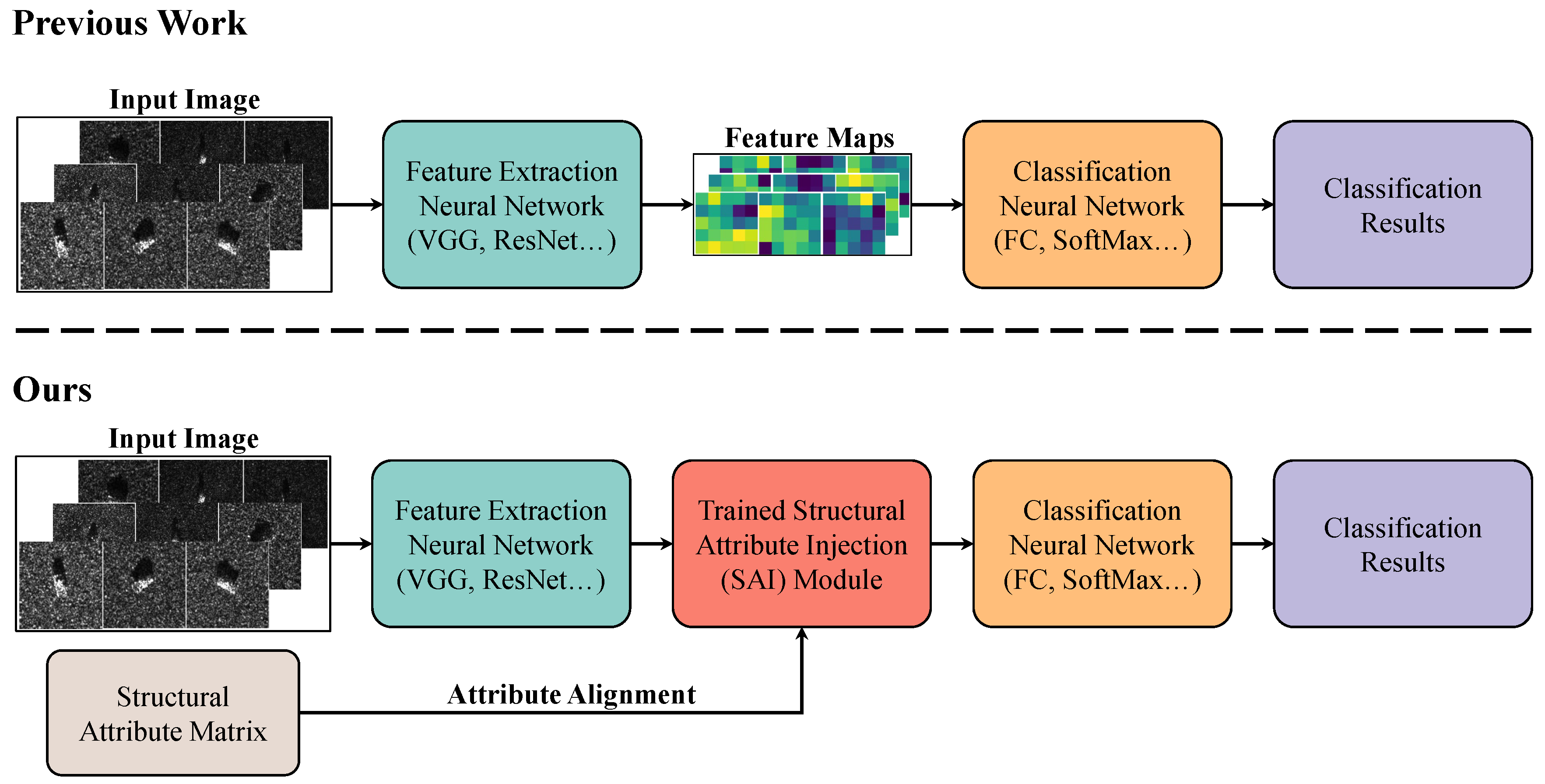
13]. The architectural difference between the proposed approach and the previous radar target recognition network is shown in
Figure 1. It should be noted that our proposed method can align the representation of the structural attributes of the input images with their features by using a higher-dimension trained Structural Attribute Injection module. Structural attributes typically refer to the components of the target object and the characteristics of these components, encompassing both geometric properties and the corresponding functional roles. By integrating this knowledge, we aim to create a more comprehensive understanding of the target’s structure and integrate it into the process of target recognition. Knowledge of structural attributes not only provides essential structural information about the target but also conveys correlations between different categories, facilitating better classification and recognition processes [
14]. Hence, structural attribute knowledge serves as a crucial form of prior knowledge, enabling the model to focus on significant features within the data, which can lead to improved performance on specific tasks [
15]. Furthermore, the approach to leverage structural attributes can enhance interpretability, allowing researchers to gain insights into how the model processes information. Despite the recognized importance of knowledge of structural attributes, research utilizing this framework remains relatively limited [
16]. Therefore, our work not only contributes to the theoretical understanding of structural attributes but also opens new avenues for practical applications in the field.
To effectively integrate structural attribute knowledge into deep learning networks and improve overall performance, we propose a novel Structural Attribute Injection (SAI) module. This module is designed to be inserted between the feature extraction and classification modules of traditional models, facilitating the efficient incorporation of structural attributes. Specifically, the core function of the SAI module is to map the encoded structural attributes to a designated structural space, thereby enabling alignment between sample mappings and structural attributes. This process allows models to acquire representations of structural attributes of targets, resulting in improved accuracy in target recognition tasks. Importantly, the SAI module exhibits strong versatility across the same dataset. As a knowledge injection module, it requires only a single training session, rendering it applicable to all deep learning-based recognition networks on the same dataset. This characteristic significantly streamlines the model’s training process while enhancing its adaptability across various application scenarios. After that, by injecting structural attribute knowledge into the network, the SAI module notably increases recognition accuracy and endows the model with reasoning capabilities. Consequently, even for relatively simple feature extraction networks, the SAI can assist the models in achieving SOTA recognition performance under both sufficient and limited sample conditions.
The main contributions of this paper are as follows:
First, we propose a novel method for constructing target categories based on structural attributes, aimed at establishing a generic structural knowledge of these categories.
Second, we developed a new module named the Structural Attribute Injection (SAI) module, designed to efficiently inject structural knowledge into any image feature extraction network to enhance object recognition performance.
Furthermore, we conducted a comprehensive evaluation of the proposed SAI module using the Moving and Stationary Target Acquisition and Recognition (MSTAR) and Inverse Synthetic Aperture Radar (ISAR) aircraft recognition datasets. The results demonstrate that our approach exhibits superior recognition accuracy and reduced computational costs.
2. Related Work
Unlike traditional visible-light images, radar images reflect and scatter targets in a different manner, exhibiting distinct image characteristics. Although deep learning has been extensively applied to radar image recognition with promising results, a significant number of deep learning algorithms are primarily designed for optical image recognition. Therefore, directly employing these methods for radar image analysis leads to algorithms that utilize only the amplitude information within radar images, thereby neglecting potential physical properties and resulting in reduced recognition accuracy. Moreover, current deep learning models suffer from poor interpretability, which hampers their widespread application in practical scenarios [
17,
18].
To achieve interpretable and highly generalized intelligent recognition methods, it is essential to consider how to integrate physical mechanisms into neural networks, thereby developing physics-informed intelligent target recognition approaches. Given that physical laws possess universality and scientific validity, intelligent methods that incorporate these physical mechanisms will experience significant improvements in generalization capability and interpretability. These approaches essentially lie between traditional methods based on expert knowledge and machine learning methods driven by large datasets, leveraging the advantages of both prior knowledge and experiential learning [
19].
In addition to amplitude information, radar images possess geometric features [
20], polarization characteristics [
21], scattering centers [
22], and complex information [
23]. These features have specific physical meanings in radar images, and leveraging them to enhance optical image processing methods can further improve recognition accuracy. Currently, the main research focuses on radar image recognition, where integrating network features with physical knowledge can enhance network performance and increase its interpretability [
7,
8,
10,
24,
25,
26,
27,
28,
29]. In these studies, phase information is readily available, leading to a significant number of investigations based on complex-valued information. Gleich et al. proposed a complex-valued convolutional neural network to classify synthetic aperture radar image blocks from the TerraSAR-X dataset [
24]. This was achieved by designing complex-valued input layers, complex-valued output layers, and multiple complex-valued hidden layers to integrate complex information. Fan et al. introduced an efficient complex-valued space-scattering separation attention network for PolSAR image classification. This method utilized 3D convolutions to explore features in the spatial and scattering dimensions of PolSAR images, employing complex values as input to better capture phase information [
25]. Ren et al. developed an end-to-end classification method for PolSAR images based on a complex-valued residual attention-enhanced U-Net. This approach combines complex-valued operations to utilize phase information and employs a residual attention module to enhance discriminative features at multiple resolutions [
26]. Zeng et al. proposed a complex-valued multi-stream feature fusion method for SAR target recognition, effectively utilizing the target’s phase information. They first constructed a series of complex-valued operation blocks to facilitate network training in the complex domain [
9].
Scattering centers effectively represent structural information about the target, which enhances the performance of target recognition algorithms. Qin et al. proposed a SAR image ATR method based on a Gaussian mixture model with scattering parameters. By modeling the extracted sets of attributed scattering centers, this method employed a weighted Gaussian quadratic distance to measure similarity, thus achieving the ATR of the SAR image [
27]. Liu et al. introduced a novel end-to-end feature-fusion learning approach, which can represent the SAR target structure with attributed scattering centers located across multiple regions and scales in a physically meaningful way. They fused scattering features with deep features using a weighting coefficient, making the combination of these features more complementary [
7]. Feng et al. proposed a new SAR target classification method that integrates an attributed scattering centers component model with deep learning algorithms. This method first extracted local features of the target using a component model based on attributed scattering centers and then applied an improved fully convolutional network to capture global features of the target. The final classification result was obtained by fusing decisions based on local and global features [
28]. Zhang et al. achieved high-precision recognition of SAR ship targets through the weighted fusion of multiscale scattering features and deep features. The proposed method utilized target fine segmentation to separate the background, constructed local graph structures via the scattering center feature association module, and integrated the scattering features extracted by the multiscale feature enhancement module with multiscale convolutional features from the multi-kernel deep feature extraction module through weighted fusion to achieve comprehensive feature representation [
30]. Zhang et al. used the Harris corner detector to extract key scattering points in SAR images, reflecting the structural characteristics of ships. By generating a topological structure from the spatial relationships between the scattering points, it can address the challenge of recognizing the target of the ship with limited samples [
31]. Li et al. proposed a progressive fusion learning framework that combines structural features from optical and SAR images to achieve complementary information, resulting in high-precision building segmentation [
32]. Zhao et al. introduced an azimuth-sensitive subspace classifier that can map the azimuth dependence of targets to cosine space, enhancing the recognition accuracy of SAR images under few sample conditions [
33]. Huang et al. improved the critical scattering points of aircraft targets by combining spatial coordinate information with deep features. A coordinate attention mechanism improved focus on aircraft positions, and multiscale feature fusion integrates shallow texture information with deep semantic information, increasing the detection accuracy of targets [
34].
In addition, there is limited research focused on integrating domain knowledge, such as geometric properties, size information, and shadow area characteristics. Zhang et al. proposed a polarization fusion network with embedded geometric features. This network utilizes geometric feature embedding to enrich expert knowledge [
8]. Furthermore, Zhang et al. developed a deep neural network enhanced with domain knowledge that considers the azimuth, aspect ratio, and target area of the target for the recognition of SAR vehicles, with the aim of minimizing the overfitting issues caused by limited data [
29]. Choi et al. were the first to successfully integrate target and shadow areas in SAR imagery. This approach represents shadow regions to account for their unique domain-specific properties, introduces a parallelized SAR processing mechanism to allow the network to independently extract features for each conflict pattern, and finally fuses features in a layered manner [
10]. Xiong et al. incorporated directional features to provide the model with prior knowledge of the target’s observation angle. After processing these directional features through a fully connected layer, they were residually fused with the features of the main CNN layers, allowing the model to use angle information during classification [
35].
Currently, knowledge-assisted radar image recognition methods incorporate radar-specific physical knowledge, focusing on feature engineering. The additional prior features provided by physical knowledge are integrated with the features of the image to enhance feature discrimination, resulting in improved recognition accuracy. Knowledge-assisted methods have achieved SOTA recognition performance when sufficient data are available. However, these methods require specialized network designs to effectively process and map data, integrating them with image features to support recognition. Such designs are typically complex, which can increase computational overhead and reduce processing speed.
3. Structural Attributes
In this chapter, we first define structural attributes and clarify their importance in target recognition. In addition, we will outline the general process proposed in this paper for extracting structural attributes from radar images. Next, we will demonstrate how targets with different structural attributes influence the final radar imaging results. Specifically, we analyze specific case studies to highlight the significant impact of various structural characteristics on imaging effectiveness, indicating the essential role of structural characteristics in radar image processing. Finally, we present the vector-encoding modeling method for structural attributes. This approach aims to transform structural attributes into numerical representations, facilitating their input into deep learning models. By employing one-dimensional vector encoding, the network can effectively capture and utilize structural information.
3.1. Structural Attributes Definition
Structural attributes typically refer to the components that constitute a target object, as well as characteristics such as the type, shape, and quantity of these components [
13]. These attributes not only effectively describe the structural features of the target object but also offer an accurate structural characterization of the target categories, revealing correlations between different categories [
14]. However, due to the limitations of coherent imaging systems, directly observing radar images, especially for Synthetic Aperture Radar (SAR) and Inverse Synthetic Aperture Radar (ISAR) images, often complicates the acquisition of an accurate structural description of the target [
36]. To address this issue, we employ text mining techniques to extract structural attributes for target categories. Specifically, we analyze detailed textual descriptions provided for various categories, extracting high-frequency terms from these analyses [
37]. After filtering these terms, we constructed the necessary structural attributes. This method effectively compensates for the shortcomings of direct observation, enabling us to derive structural features of the target from textual data, thus providing richer structural information for subsequent target recognition and classification tasks [
36]. Through this approach, our research not only expands the sources of structural attributes but also establishes a solid foundation for the further injection of structural knowledge.
3.2. Structural Attributes Extraction
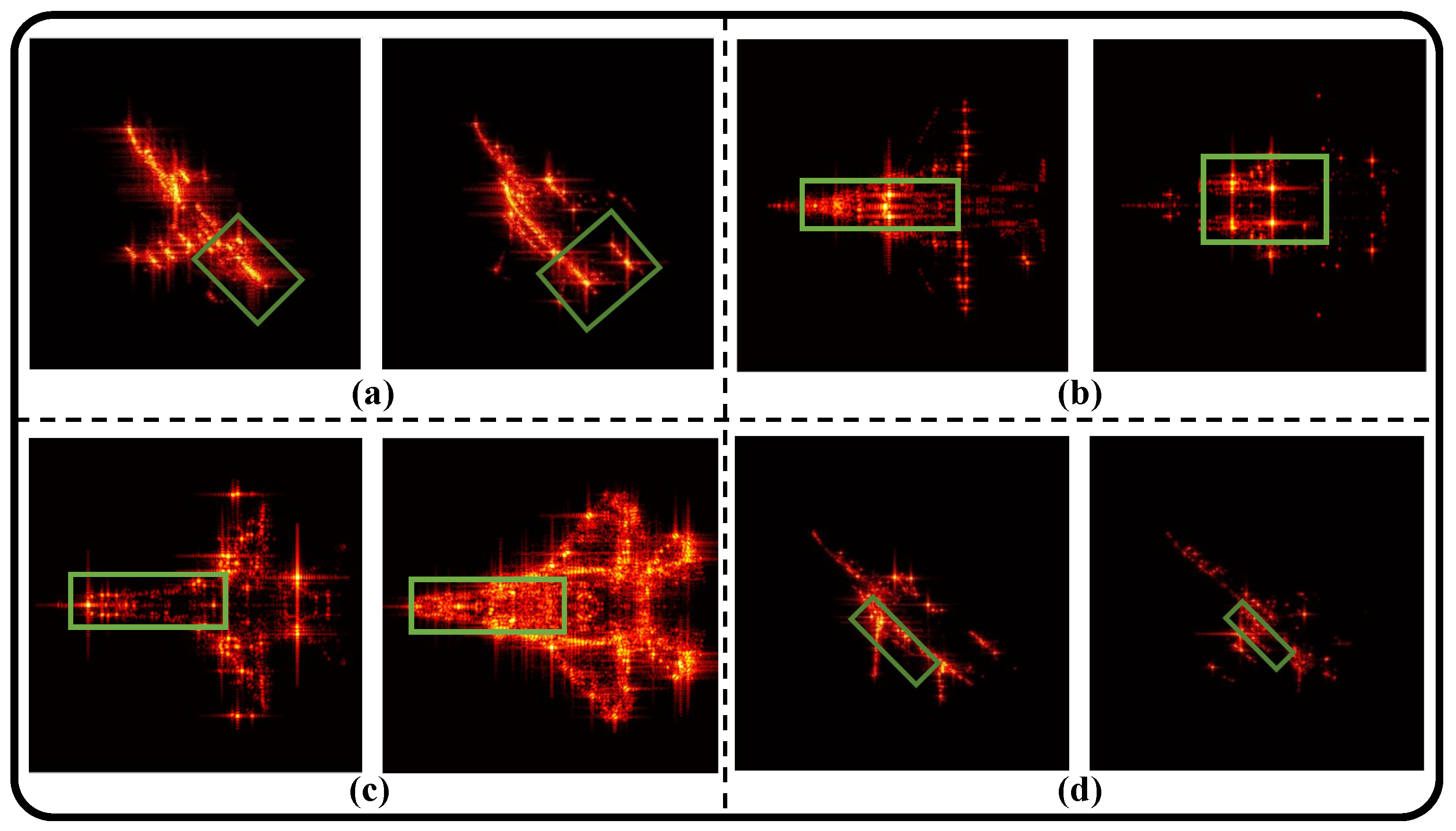
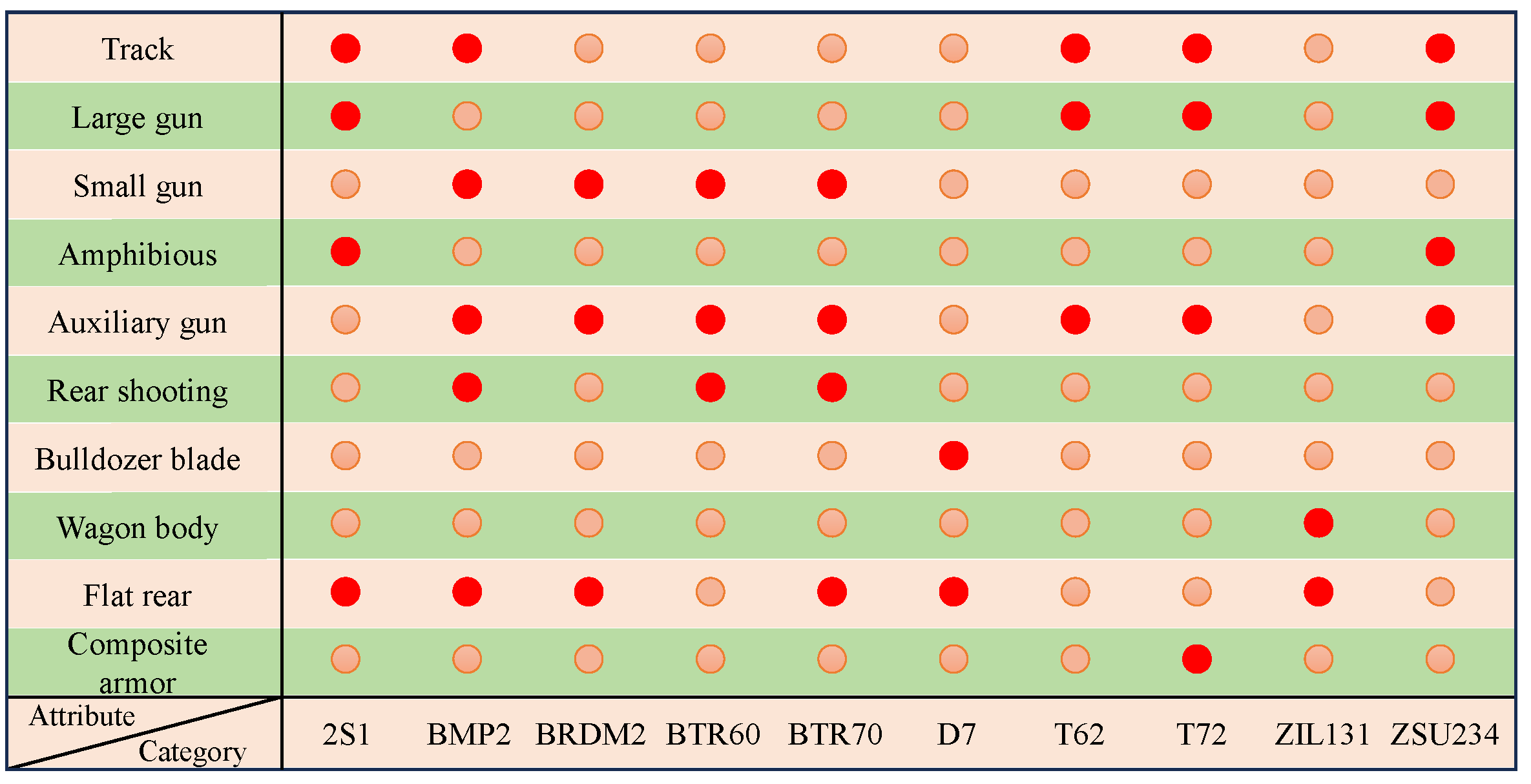
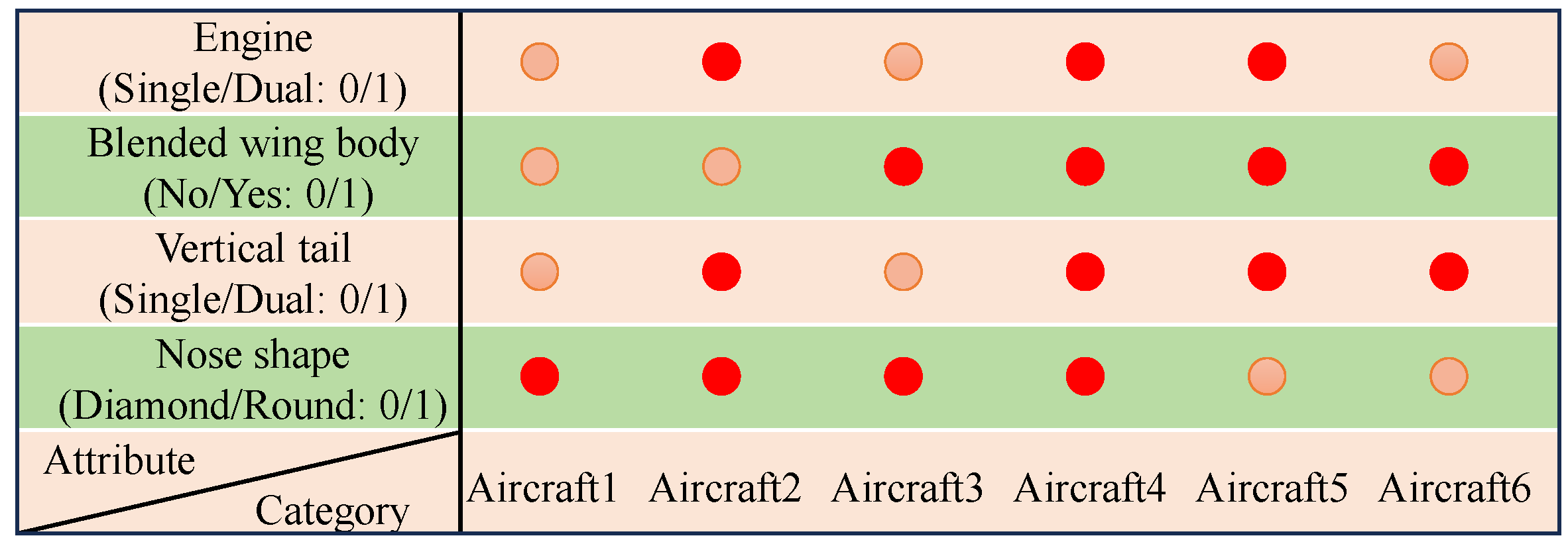
When selecting structural attributes, it is unnecessary to provide a detailed and exhaustive description of every substructure that constitutes the target. Instead, the focus should be on substructures that exhibit good separability, high sensitivity to imaging, and insensitivity to observation angles. As illustrated in
Figure 2 and
Figure 3, the figures demonstrate the impact of specific substructures on the imaging results within the Moving and Stationary Target Acquisition and Recognition (MSTAR) and ISAR aircraft datasets.
The figures above indicate that the presence or absence of these substructures significantly influences the imaging outcomes, which can be clearly observed in the radar images. Furthermore, there are significant differences in structural attributes between the different categories. Therefore, ensuring the separability of structural attribute encoding when selecting substructures is essential. By selecting the satisfactory encoded structural attributes, we can better leverage structural information, thereby optimizing subsequent image processing and recognition workflows.
For example, as shown in
Figure 2, within the MSTAR dataset, the blade structure of the D7 tank, the barrel structure of the T62 tank, and the wheel and track structures of both the T62 tank and the self-propelled 2S1 gun significantly influence the imaging results. Furthermore,
Figure 2d illustrates the shadow effects produced by the obscuration of the gun mount, further emphasizing the importance of substructures in SAR imaging. Similarly, in the ISAR aircraft dataset depicted in
Figure 3, structural attributes such as the vertical tail structure, the number of engines, the shape of the nose, and the application of Blended Wing Body (BWB) technology play crucial roles in the recognition of targets. The use of BWB technology facilitates a smoother connection between the wings and the fuselage, thereby reducing scattering phenomena. In contrast, aircraft lacking this technology exhibit a higher likelihood of secondary scattering at the connection points between the wings and the fuselage, resulting in a significantly increased echo intensity [
38]. The imaging results shown in
Figure 3d clearly illustrate this phenomenon, further validating the critical role of structural attributes in the recognition process.
3.3. Structural Attributes Modeling
To effectively utilize the structural attributes within the algorithm, we model them using one-dimensional vector encoding, transforming the structural attributes into numerical representations suitable for input into the model. This process involves defining the encoding of structural attributes. Specifically, we represent the presence or absence of substructures using binary encoding, as shown in
Figure 4. Each substructure is assigned a specific binary value, where ‘1’ indicates the presence of the substructure, and ‘0’ denotes its absence. This simple yet effective encoding approach not only enhances data processing efficiency but also ensures the accurate transmission of structural attribute information during subsequent model training, helping the model better understand and leverage these attributes [
39]. Therefore, we define
, where
,
C represents the number of categories. Let
A be a binary vector where ‘1’ indicates true (the presence of the structural attribute) and ‘0’ indicates false (the absence of the structural attribute). Using structural attributes to encode the categories, we can establish connections between the different categories, thus facilitating the effective injection of structural attributes into the model.
4. Our Proposed Method
In this section, we introduce our proposed structural attribute injection method specifically designed for radar image recognition tasks. First, we present the Structural Attribute Injection (SAI) module, which consists of two main components: the Attribute-to-Vector (A2V) network and the Attribute Alignment Adapter (Tri-A) module. The former is responsible for structural attribute mapping, and the latter performs structural attribute alignment. We then propose a general target recognition pipeline for SAR images based on structural attribute injection. The pipeline not only integrates the SAI module but also exhibits high flexibility, making it adaptable to any image recognition network. These features underscore the effectiveness and generalizability of the proposed SAI module.
4.1. Structural Attribute Injection Module
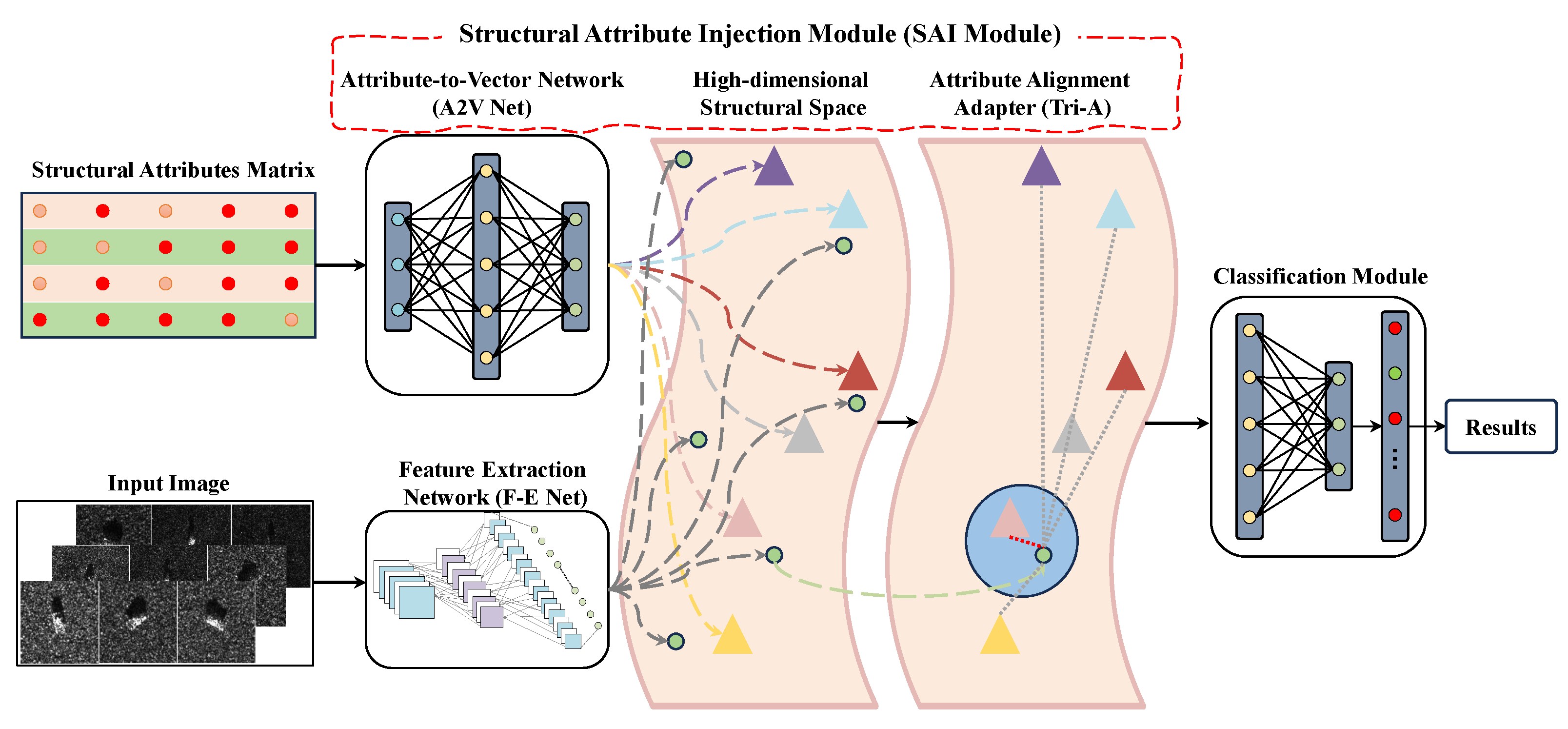
The Structural Attribute Injection (SAI) module consists of an Attribute-to-Vector (A2V) network and an Attribute Alignment Adapter (Tri-A), as illustrated in
Figure 5. The primary function of the A2V network is to map structural attributes into a predefined structural space, thereby creating a high-dimensional representation of these attributes and enabling the network to effectively capture the structural features of the target. The Tri-A aligns the image samples with the nearest structural attribute representations in the structural space, which can help the network to obtain precise attribute representations for the image samples. This method not only enhances the correlation between the samples and their corresponding structural attributes but also ensures the effective transmission of structural information.
As shown in
Figure 5a, the input data consist of two components: the image and its corresponding structural attribute matrix, which is obtained using the structural attribute modeling method introduced in
Section 3.3. First, the image is fed into the feature extraction module, where its features are mapped to a structural space. Simultaneously, the structural attribute matrix is fed into the A2V network, which performs a high-dimensional mapping of the structural attributes, generating a corresponding representation in the structural space. As shown in
Figure 5b, FC refers to fully connected layers, and the subsequent numbers indicate the number of nodes in each layer. M represents the dimensionality of the high-dimensional feature space, while C indicates the number of target categories in the dataset. Through this training, the A2V network embeds low-dimensional structural attributes into a high-dimensional space with enhanced representational capabilities. Next, both the image features and the high-dimensional structural attribute mappings are input into the Tri-A module. In
Figure 5c, the role of the Tri-A module is to match the image features with the closest structural attribute representations in the high-dimensional space. By performing clustering operations in the high-dimensional space, the module outputs the structural attribute representations that correspond to the target category of the input image, ensuring that the category’s structural features are accurately reflected during recognition. Through this alignment, the model can capture the relationships between the image and its structural attributes more accurately. Finally, the aligned results are fed into a classification model to complete the object recognition task.
4.1.1. Attribute-to-Vector Module
Due to the inherent limitations of manually designing and extracting structural attribute features, directly applying the encoding method described in
Section 3.3 to inject structural attributes can only provide a coarse reflection of structural correlations between categories. This rudimentary encoding design may lead to issues during training, particularly caused by unreasonable inter-class distances, which can cause the model’s accuracy curve to fluctuate and become unstable [
40]. To address this issue, we introduce the A2V module. The primary function of the A2V network is to embed the low-dimensional structural attribute encoding into a higher-dimensional structural space. This high-dimensional space allows for a more refined and effective representation of structural attributes, improving separability between categories and improving the model’s learning capability [
41]. By adopting this approach, the representation of structural attributes is significantly improved, ensuring model convergence and stabilizing accuracy during training, ultimately improving overall recognition performance.
The structure of the A2V network is illustrated in
Figure 6, with its core comprising a series of fully connected layers (FC). To effectively map structural attributes from a low-dimensional space to a high-dimensional space, we stack three fully connected layers containing 128, 256, and
V nodes, respectively (layers 1 to 3). Here,
V represents the dimensionality of the high-dimensional space to which the structural attributes are ultimately mapped. Through step-by-step processing across these layers, the A2V network maps the input low-dimensional structural attribute encoding into a more expressive high-dimensional space. The selection of
V requires optimization based on empirical results obtained from parameter tuning. Specifically,
V should strike an appropriate balance between model performance and complexity. If
V is too small, it may lead to insufficient representation of structural attributes, negatively affecting recognition accuracy. Conversely, if
V is too large, it can increase computational costs and model complexity. Therefore, the final selection of
V needs to be fine-tuned through experiments to ensure optimal model performance without excessively burdening computational resources. In this part, layers 1 to 3 are applied for the mapping of structural attributes, and the output of each layer is
, where
,
,
. It should be noted that the output of Layer 3 will be injected into the recognition network as a high-dimensional structural attribute, which can be denoted as
. In addition, Layer4 is a linear classifier that is used to obtain the class probability corresponding to structural attributes, which can be denoted as
, and
C represents the number of categories.
Therefore, the loss function of the proposed A2V network can be expressed as:
where
represents the classification loss, which is designed to ensure that the A2V network can produce structural attribute representations with strong separability between categories after training.
is defined using the cross-entropy loss, which can be denoted as:
where
M is the number of samples for structural attributes,
is the label, and
is the probability that the i-th sample belongs to class c. After that,
represents the distance loss, which is designed to maintain adequate spacing between different categories in the high-dimensional space. Specifically, a minimum distance loss is employed in this context:
where
is a constant coefficient,
and
are the structural attribute codings of the categories mapped from category
i and category
j, respectively.
4.1.2. Attribute Alignment Adapter
The primary function of the Attribute Alignment Adapter (Tri-A) is to match sample features in the high-dimensional structural space with their corresponding structural attributes, thereby achieving effective injection of structural attributes. Specifically, we first use the A2V network to map the structural attributes of all categories to the high-dimensional structural space. Based on these structural attributes, we then construct the cluster centers for the Tri-A module. The structural attributes of each category serve as the center of the cluster for that category in the high-dimensional space, laying the foundation for the subsequent alignment process, which can be denoted as:
Then, the feature extraction module first processes the input image, extracting its features
,
x represents the input samples. These image features are then fed into the Tri-A module, where the system matches them with the cluster centers in the high-dimensional structural space, thus obtaining the representation of the structural attributes corresponding to the category of the sample
x. Moreover, calculate the distance between the extracted image feature and the vectors of structural attributes of each category, which can be defined as:
Finally, determine the corresponding structural attribute of based on the nearest structural attribute, where .
4.2. SAI-Based Target Recognition Pipeline
The proposed general Structural Attribute Injection (SAI) module can effectively integrate structural attribute knowledge into deep learning networks, enhancing radar target recognition. The overall framework of the pipeline is shown in
Figure 7 and consists of three main components: the Feature Extraction Network (F-E Net), the SAI module, and the classification module.
Traditional target recognition networks typically rely solely on feature extraction and classification modules to complete sample recognition tasks. By introducing the SAI module between these two components, we enable the effective integration of structural attributes, improving the model’s understanding of the target’s structural characteristics. The feature extraction module can consist of any neural network used for visual object recognition, with its primary function being to map the input image features into a structural space. For different target categories, we encode structural attributes to provide relational knowledge between categories, helping the model to better distinguish between them. The A2V network within the SAI module is responsible for mapping these structural attributes into a high-dimensional structural space, ensuring tighter integration between structural information and image features. Within the SAI module, the Tri-A component aligns the image samples with the nearest structural attribute representations in the structural space, producing an accurate structural attribute representation for each sample. Finally, the classifier maps these structural attributes to specific sample categories, completing the recognition task. In this way, the SAI module not only improves recognition accuracy but also introduces rich structural knowledge into the network, enhancing its ability to differentiate between target categories.
We first train the A2V network independently, as its training only requires defining the categories and their corresponding structural attributes, without relying on a specific image dataset. This characteristic endows the A2V network with a high degree of generalizability, allowing the proposed SAI module to seamlessly integrate into any image recognition network within the same dataset. Once the A2V network has been trained, the representations
in the structural space are fixed, and we can proceed to train the Feature Extraction Network (F-E Net) using image samples. At this stage, the SAI module introduces two key loss functions for the F-E Net, which are
and
. Among them,
represents the loss of similarity, which is defined using cosine loss:
where
N is the number of input samples,
represents the structural attribute of sample
i obtained by the Tri-A module, and
represents the image feature of sample
i obtained by the F-E Net.
Meanwhile,
represents the distance loss, which can be denoted as:
where
N is the number of input samples;
represents the structural attribute vector of sample
i in high-dimensional space, while
denotes the image feature of sample
i, which is also in high-dimensional space and extracted by the F-E Net.
and
refer to the elements at index
j within these high-dimensional vectors. Finally, the overall loss function of the proposed neural network can be summarized as:
where
is the commonly used classification loss in traditional recognition network frameworks, which is defined as the cross-entropy loss obtained from the classification results and labels. During the training process, we freeze the A2V network parameters. In addition, the classifier parameters are also frozen, as the classifier parameters in the entire pipeline model can directly use the parameters of the fourth layer in A2V without training separately.
5. Results
In this chapter, we provide a detailed description of the experimental setup used to validate the effectiveness of the proposed SAI module, alongside a comprehensive explanation and analysis of its application in radar image recognition. First, we introduce the two datasets used in the experiments and, based on their respective characteristics, design four distinct radar image recognition scenarios to thoroughly assess the performance and adaptability of the SAI module in various tasks. These scenarios encompass different recognition demands and challenges, ensuring the comprehensiveness and credibility of the experimental results. Next, we outline the experimental deployment platform, including specific hardware configurations and hyperparameter settings used in the loss functions during training. By detailing these experimental conditions, we ensure the reproducibility and reliability of the results. Additionally, we establish standards for structural attribute extraction tailored to each dataset, addressing the task’s multidimensional and comprehensive requirements. These standards guarantee consistency and accuracy in the extraction of structural attributes from different datasets. We then designed ablation experiments to evaluate the practical effectiveness of structural attribute extraction and the SAI module in target recognition tasks. By removing or modifying certain components within the module, we systematically assessed the contribution of each part to the overall model performance, further demonstrating the critical role of the SAI module. Finally, we conducted a comparative analysis between the proposed method and existing SOTA approaches. The experimental results show that the proposed method not only achieves a higher recognition accuracy in radar target recognition tasks but also offers significant advantages in computational efficiency. This outcome underscores the potential of the SAI module to enhance recognition performance while reducing model complexity, indicating broad applicability across various scenarios.
5.1. Dataset
We evaluated the proposed method on two datasets.
Dataset (1): We applied the MSTAR (Moving and Stationary Target Acquisition and Recognition) dataset, collected and published by Sandia National Laboratories in the US [
42], which has been widely utilized in the SAR ground target recognition domain. The dataset includes ten types of targets: 2S1, BMP2, BRDM2, BTR60, BTR70, D7, T62, T72, ZIL131, and ZSU234. These targets possess distinct structural features, offering a diverse experimental environment to assess the effectiveness of our SAI module in structure-assisted recognition tasks. It is worth noting that BTR60 and BTR70 are armored vehicles from the same series, and T62 and T72 are tanks from the same series, both of which has extremely high similarity.
Dataset (2): We also used the ISAR aircraft dataset, generated by electromagnetic simulation, which contains ISAR images of 11 different types of aircraft. The dataset covers an elevation angle range from 75° to 105°, with 3° intervals, and an azimuth angle range from 0° to 60°, with 1° intervals. In our experiments, we used a subset of this dataset that includes six structurally similar targets: aircraft1, aircraft2, aircraft3, aircraft4, aircraft5, and aircraft6. This dataset provides an ideal test condition for evaluating the performance of the SAI module in distinguishing structurally similar targets.
After that, we designed four application scenarios under two conditions (ample samples and few shot samples) to comprehensively validate the performance of the SAI module:
Scenario 1: Using Dataset (1), following the SOTA methods [
43,
44,
45], the training set contains 2747 images, and the test set contains 2245 images. This scenario is designed to evaluate the performance of the SAI module under standard conditions with sufficient training data.
Scenario 2: Also using Dataset 1, but only 25 randomly selected images per class are included in the training set, with the remaining images forming the test set. The final training set contains 250 samples, while the test set contains 4742 samples. This scenario tests the performance of the SAI module under few-shot learning conditions.
Scenario 3: Using Dataset 2, for each class, one sample is selected from every 5° interval of the pose angle for the training set, with the remaining samples used for the test set. The training set contains 805 samples, while the test set contains 3221 samples. This scenario assesses the SAI module’s recognition effectiveness when dealing with variations in elevation and azimuth angles.
Scenario 4: Still using Dataset 2, for each class, a sample is selected from every 5° interval around the 90° elevation angle for the training set, while the remaining samples form the test set. The training set consists of only 78 samples, and the test set contains 3948 samples. This scenario further reduces the training sample size to examine the generalizability and stability of the SAI module under extreme few-shot conditions.
By testing the SAI module in these diverse experimental scenarios, we were able to comprehensively evaluate its effectiveness in radar target recognition tasks, particularly in terms of performance under varying data scales, sample scarcity, and target pose variations.
5.2. Implementation Details
In this chapter, all experiments were implemented in a Python 3.7 environment, running on a hardware platform consisting of a Core i7-12700H CPU and a GTX 3070 Ti GPU. We employed the Adam optimizer for parameter optimization, with a batch size of 16 during training and an initial learning rate of 0.0001. For the training of the SAI module, we set the number of epochs to 5 to ensure that the structural attribute encoding can converge quickly and be embedded into the high-dimensional space. For the training of the F-E Net, the number of training epochs varied between the ample-sample and few-shot conditions. In the ample-sample condition, we set the training epoch number to 100 to allow the model to fully learn the association between image features and structural attributes. However, under the few-shot condition, as the algorithm requires more iterations for proper convergence due to the lack of data, we increased the number of training epochs to 200. This adjustment ensures that the model can gradually converge, even with limited data, improving recognition performance in few-shot scenarios. In addition, the hyperparameters of the loss functions are set as follows: for training of the SAI module, = 1, = 1. For the training of F-E Net, = 1, = 3, = 1.
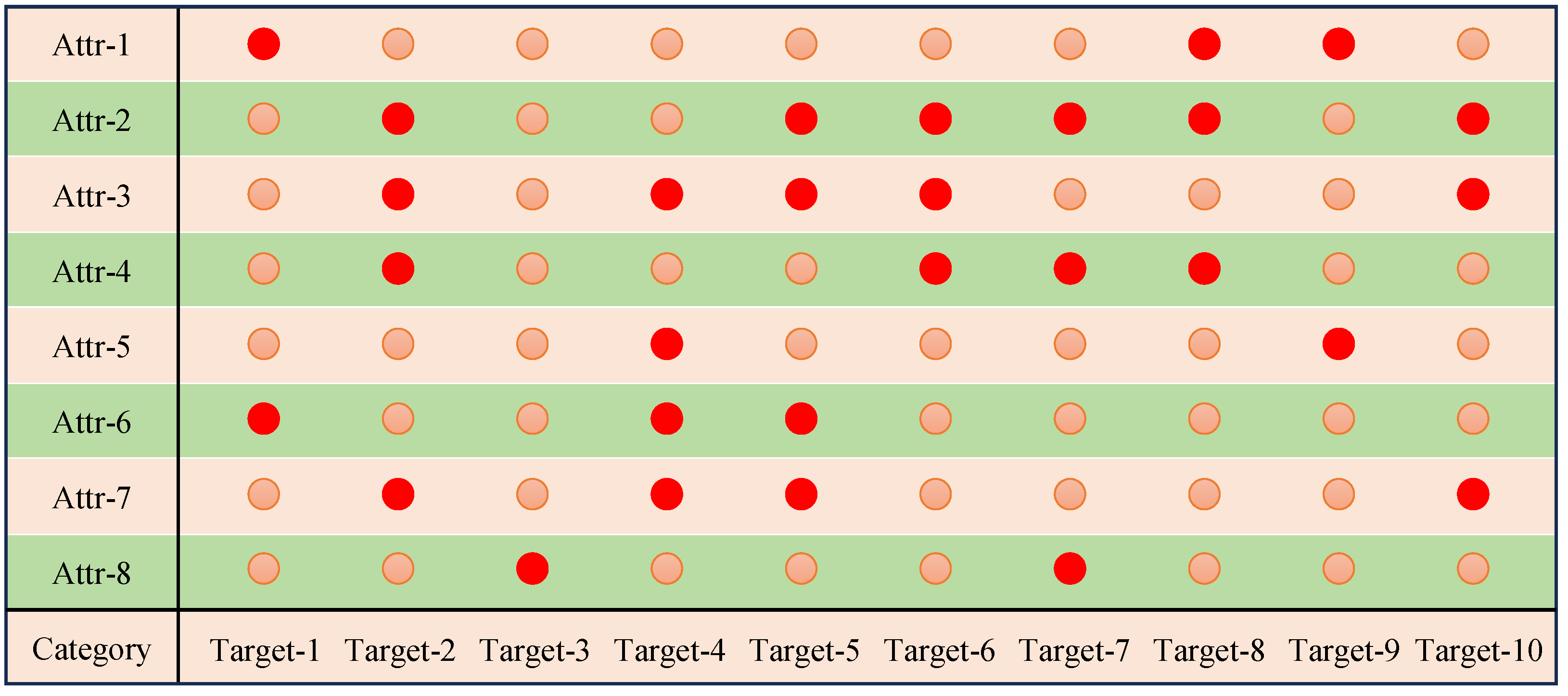
5.3. Structural Attribute Design
Using textual data, we designed structural attributes for each category in Dataset (1) and Dataset (2), encoding these attributes accordingly. The encoding results are shown in
Figure 8 and
Figure 9.
To further enhance the expressiveness of the structural attributes, we utilized the A2V network to map these encodings into a high-dimensional structural space, producing more effective category representations. During this process, we performed multiple rounds of parameter tuning for the mapping dimension V to optimize the performance of the model. Specifically, we used VGG19 as the feature extraction network and experimented with 14 different mapping dimensions V for evaluation.
To ensure result stability, we performed 10 independent experiments for each mapping dimension and used the average accuracy as the selection criterion to determine the optimal dimension. The experimental results are presented in
Table 1, where the optimal mapping dimensions for Dataset (1) and Dataset (2) are denoted as
and
.
As shown in
Table 1, the optimal mapping dimension for Dataset (1)
is 100, while for Dataset (2), the optimal dimension
is 150. Consequently, in subsequent experiments, we set the parameters of the dimensions of the mapping to
and
to ensure that the performance of the model is fully optimized on both datasets.
5.4. Ablation
To validate the effectiveness of the proposed SAI module, we designed ablation experiments to evaluate radar target recognition in four different scenarios, which are shown in
Section 5.1, and the results are shown in
Table 2.
In these experiments, we employed VGG19 [
46], ResNet18 [
47], AlexNet [
48], Vision Transformer (ViT) [
49], RepLKNet [
50], VanillaNet [
51], and RepVGG [
52] as feature extraction modules, with the classification module shown in
Figure 7 used for target recognition. To demonstrate the generalizability of the SAI module, we trained the A2V network only once on each dataset and then applied the resulting structural attribute mappings to all feature extraction networks. This unified training approach ensures that the A2V network adapts to different architectures and scenarios, further validating the SAI module as a general structural attribute injection tool. Specifically, the A2V network used the optimal mapping dimension selected in
Section 5.3 and was trained based on parameters that yielded the best performance in ten independent experiments. For each feature extraction network, we conducted four experimental configurations.
Original architecture (F-E Net + classifier);
Inclusion of structural attributes;
Inclusion of structural attributes and the SAI module;
Inclusion of a randomly generated attribute matrix as a control experiment.
In this setup, random attributes refer to a randomly generated structural attribute matrix, which serves as a baseline to assess the actual contribution of the structural attributes and the SAI module to model performance. By comparing the experimental results of these different configurations, we systematically verified the performance of the SAI module across various feature extraction networks and datasets, indicating the critical role of the SAI module in improving recognition accuracy. The experimental results demonstrate that incorporating structural attributes significantly improves algorithm performance compared to traditional recognition network structures. Across the four experimental scenarios, the recognition accuracy increased by 1.85%, 11.47%, 1.19%, and 9.33%, respectively. This performance improvement is primarily attributed to the ability of structural attributes to capture critical structural information about the target. The integration of structural and image information provides a more comprehensive target representation, effectively enhancing overall algorithm performance. Furthermore, compared to networks that incorporate only structural attributes, the inclusion of the SAI module led to notable improvements in recognition accuracy. In the four scenarios, the accuracy increased by 1.62%, 6.75%, 0.33%, and 5.70%, respectively. Compared to traditional recognition network structures, the accuracy gains with the SAI module were even more significant, reaching 3.48%, 18.22%, 1.52%, and 15.03%, respectively, achieving SOTA performance. These results indicate that the SAI module offers a clear advantage in boosting recognition performance by using structural attributes more effectively. The SAI module reconstructs the structural attributes through the A2V network and utilizes the Tri-A module to output the structural attribute representation for each sample. This process ensures that structural attributes are injected into the network more efficiently, allowing the algorithm to fully take advantage of the combined information from both the structure and image features, thereby improving target recognition performance.
Furthermore, the experiments revealed that networks that incorporate randomly generated attributes exhibited greater variability in performance. Although they performed well in certain cases, the highest accuracy achieved by these networks was comparable to that of traditional network structures and fell short of the performance attained by networks using real structural attributes. In contrast to the substantial improvements brought by structural attributes, the results with random attributes underscore the critical role of genuine structural attributes in target recognition. These findings further reinforce the conclusion that structural attributes significantly enhance recognition accuracy, with the SAI module maximizing this improvement.
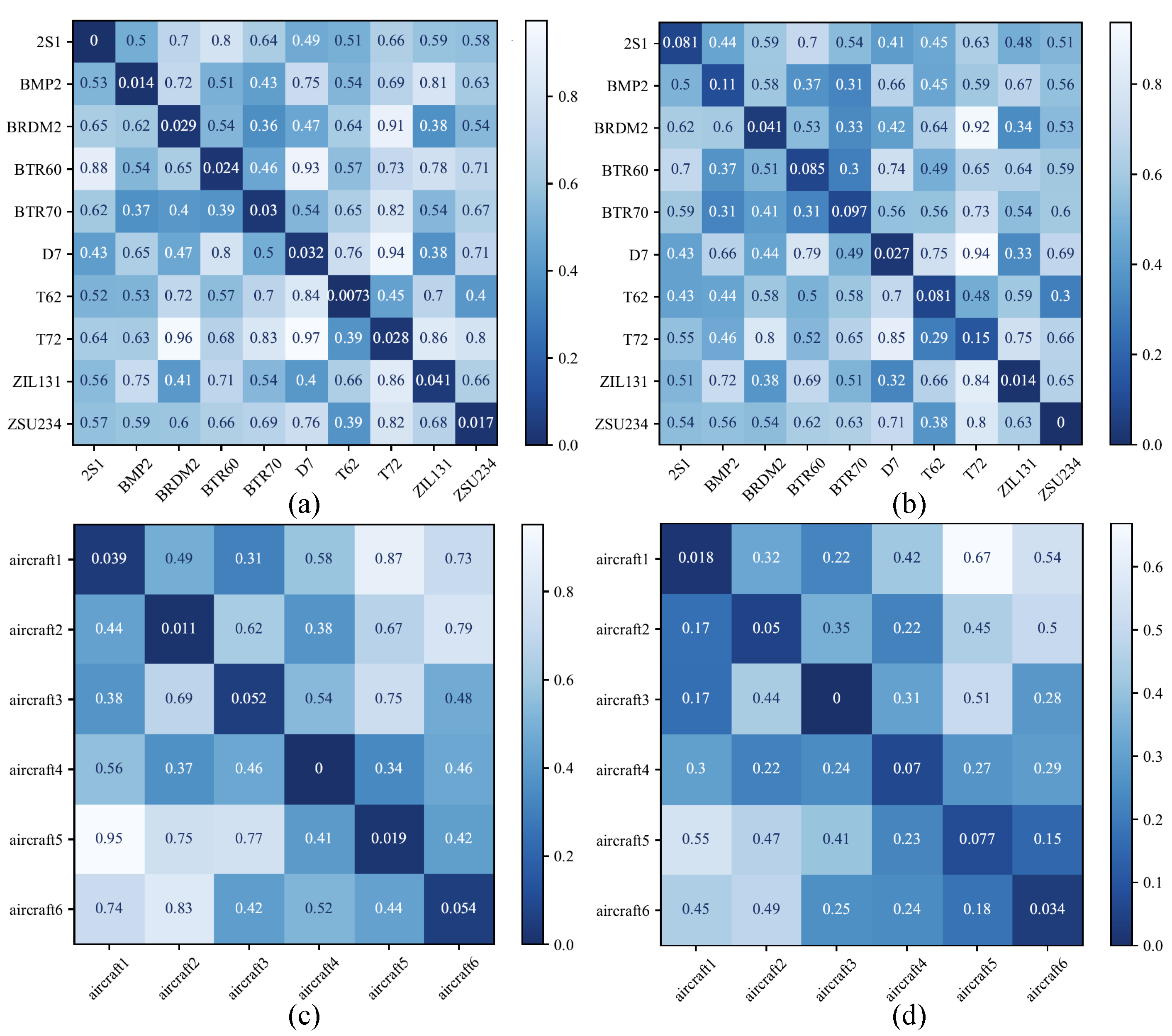
Moreover, the experimental results indicate that our proposed method exhibits a more pronounced improvement in recognition performance under few-shot conditions, demonstrating its higher effectiveness. This is because structural attributes capture the relationships between categories, providing the network with a certain degree of reasoning capability. Through this reasoning, the network can map samples that are difficult to recognize directly to nearby categories with similar structural attributes, thereby achieving more accurate recognition. To further verify the reasoning ability of the network, we calculated the average distance between the test samples and each structural attribute in each scenario, as shown in
Figure 10.
For clarity, different shades of color were used to represent the variations in the distance between the samples and the structural attributes. As evident in
Figure 10, samples cluster near the structural attributes of their corresponding categories, indicating that the network can effectively align the features of the samples with their respective structural attributes. The smaller the distance, the higher the similarity between the sample and the target category. For example, in
Figure 8, the structural attributes of T62 and T72, as well as those of BTR60 and BTR70, are closest to each other, reflecting their actual structural similarities. Similarly, in
Figure 8, aircraft1 and aircraft3, as well as aircraft5 and aircraft6, show closer distances, further validating the effective reasoning ability of the network among structurally similar categories. Based on these observations, we can conclude that the proposed SAI module indeed possesses reasoning capabilities. The module can map uncertain samples to categories with similar structural attributes, resulting in more accurate target recognition. This reasoning ability is particularly critical under few-shot conditions, significantly enhancing the network’s generalization ability and recognition performance when data are limited.
5.5. Computational Resource Analysis
In comparative experiments, we evaluated the performance of the proposed method (using VanillaNet as the feature extraction module) against the latest methods in Scenario 1, as shown in
Table 3. Specifically, we compared the following three methods: SDF-Net (incorporating scattering center information) [
7], MS-CVNet (incorporating phase information) [
9], and PFGFE-Net (incorporating geometric information) [
8]. All comparative experimental results are obtained by reproducing the methods proposed in the literature, with identical experimental implementation details under Scenario 1.
The experimental results are presented in the
Table 3 that demonstrates the accuracy and computational cost of each method. The results reveal that our method demonstrated excellent performance in terms of recognition accuracy. Although the accuracy improvement over the three comparison methods was relatively modest, our method still achieved the highest recognition precision. This indicates that by integrating structural attributes, the proposed SAI module can further enhance target recognition accuracy. In particular, our method exhibited a significant advantage in terms of computational cost. Specifically, compared to the other methods, our approach required less training time and approximately 1/5 of the average parameter count of the comparison networks, while the Floating Point Operations (FLOPs) were only 1/14 of the average for the comparison methods. This demonstrates that our method not only achieves SOTA accuracy levels but also drastically reduces model complexity and resource consumption, highlighting its efficiency and scalability in practical applications. These results underscore that our proposed method can achieve high-precision recognition while significantly lowering computational costs, making it highly efficient. Its low resource demands suggests strong potential for broader application in resource-constrained environments.
6. Discussion
In radar ATR tasks, commonly used methods, such as [
7,
8,
10,
27,
28,
29,
30,
35], employ a deep integration of knowledge-driven and data-driven approaches. These methods use domain knowledge to assist deep networks in completing recognition tasks or leverage physical priors to guide model training, combining expert knowledge with data analysis for more comprehensive decision support, thereby enhancing image recognition accuracy. Our proposed approach differs from these methods in the following two key aspects:
We use structural knowledge, a critical prior, to guide the model’s focus on essential data features, thereby improving its performance on specific tasks. Structural knowledge can help the model target significant features within the data, optimizing performance in complex recognition contexts.
Unlike conventional approaches, which derive scattering centers and angle and dimension information from individual input images with a focus on feature engineering, the extracted prior knowledge and image data undergo separate feature extraction processes, and these features are then integrated. This integration aims to generate more discriminative features from the feature extraction module, leading to higher recognition accuracy. The structural knowledge used in this paper is derived from datasets and textual information, providing not only structural information about the targets but also correlations between classes, thus enabling inferencing capabilities within the model. The information, such as the distribution of scattering centers, is extracted from the input samples, while the structural attributes are additional information that is independent of the input sample; hence, the former is not suitable for zero-shot target recognition, while the latter can be applied. Besides, our approach does not heavily rely on the feature extraction capabilities of F-E Net. As shown by our experimental results, even simple networks like VGG or ResNet can achieve high recognition accuracy with this method.
Our proposed SAI module has been shown to effectively identify target categories, but when materials and appearances are highly similar, our method may not be able to differentiate between real tanks and decoy tanks. In the future, we will further improve the method to combine various reconnaissance techniques, such as monitoring motion characteristics, thermal and infrared signatures, and persistent behavior within the environment, to effectively identify the category and discriminate whether the target is real or not at the same time. In addition, for the classification of aircraft with similar appearances but different engine types, such as jet aircraft and propeller-driven aircraft, the distinct structural characteristics of their engines can serve as distinguishing factors. A trained network is capable of identifying these types based on the features of the engine. Furthermore, propeller-driven aircraft images often exhibit unique micro-movement characteristics, which can be utilized as input for the network and integrated as a criterion for determining target categories. In the future, we will validate these methods following the relevant data collection. In addition, the electromagnetic simulation data that we used may include some view angles that are difficult to achieve under real imaging conditions. In the future, we will validate our proposed method using real measurement data.
In summary, in our future work, we will validate the proposed algorithm not only using simulated data under ideal imaging conditions but also with data obtained from more challenging imaging scenarios, including lower signal-to-noise ratio radar data, lower range-Doppler resolution data, more types of objects, obscuration, difficult and limited aspect angles, lower radar data rates, decoys, targets with camo, jamming, etc. Besides, we will explore zero-shot recognition in future work, enabling target identification solely through descriptive information, which holds significant potential in radar recognition, particularly in reconnaissance tasks.
7. Conclusions
This paper proposes a general Structural Attribute Injection (SAI) module, which is embedded between the feature extraction network and the classification module. The SAI module injects structural attribute knowledge to enhance the network’s recognition process through the Attribute-to-Vector (A2V) network and the Attribute Alignment Adapter (Tri-A). First, the SAI module maps structural attribute encodings into a high-dimensional structural space. Then, the feature extraction network maps the sample features into this space, assisting Tri-A in achieving the structural attribute representation for the sample. Finally, the classification module completes the accurate recognition of the sample. The SAI module improves the network’s ability to understand complex structures by effectively injecting knowledge of inter-class relationships, thereby enhancing recognition performance. We conducted comprehensive experiments on the SAI module under both ample and few-shot training conditions. The results demonstrate a significant increase in the network model’s recognition accuracy after incorporating structural attributes and the SAI module, and the computational resource consumption is less compared to the comparative algorithm. Furthermore, the experiments revealed that our method possesses reasoning capabilities, significantly boosting recognition performance in few-shot scenarios. Using reasoning capability, the network can map difficult-to-recognize samples to nearby categories with similar structures, achieving higher recognition accuracy.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}