
Blind Infrared Remote-Sensing Image Deblurring Algorithm via Edge Composite-Gradient Feature Prior and Detail Maintenance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. Methods Based on Optimization
2.2. Methods Based on Deep Learning
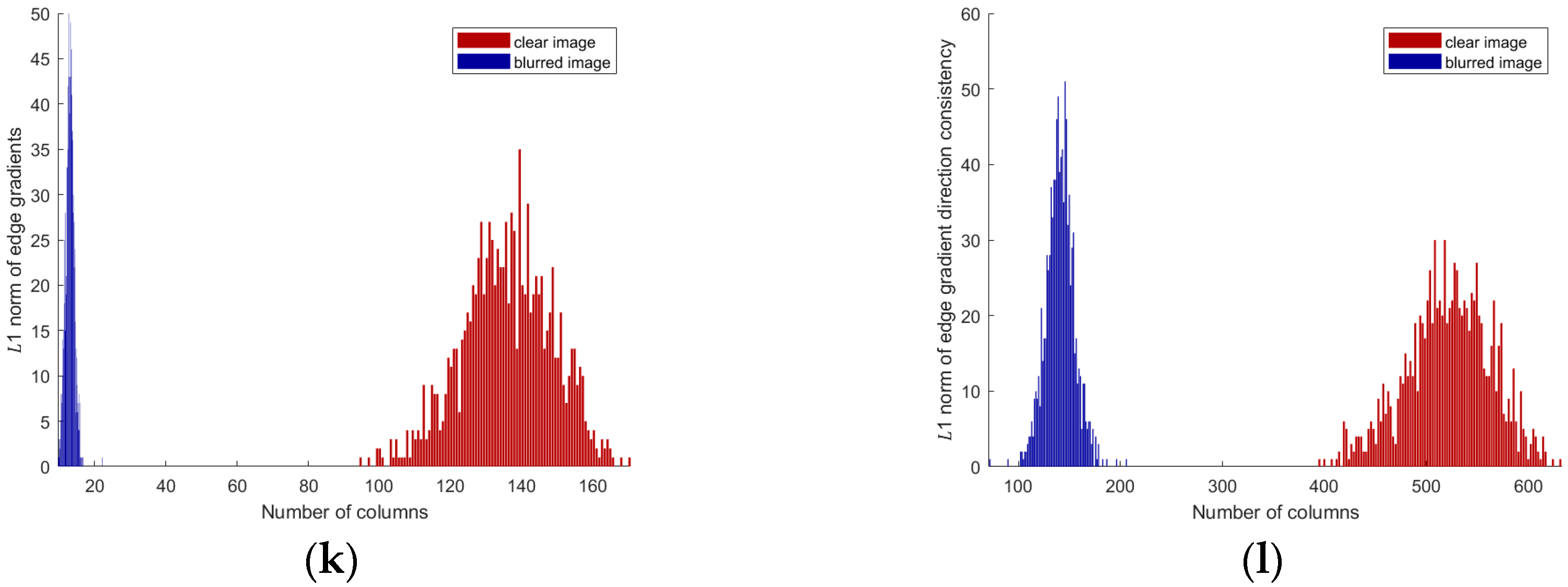
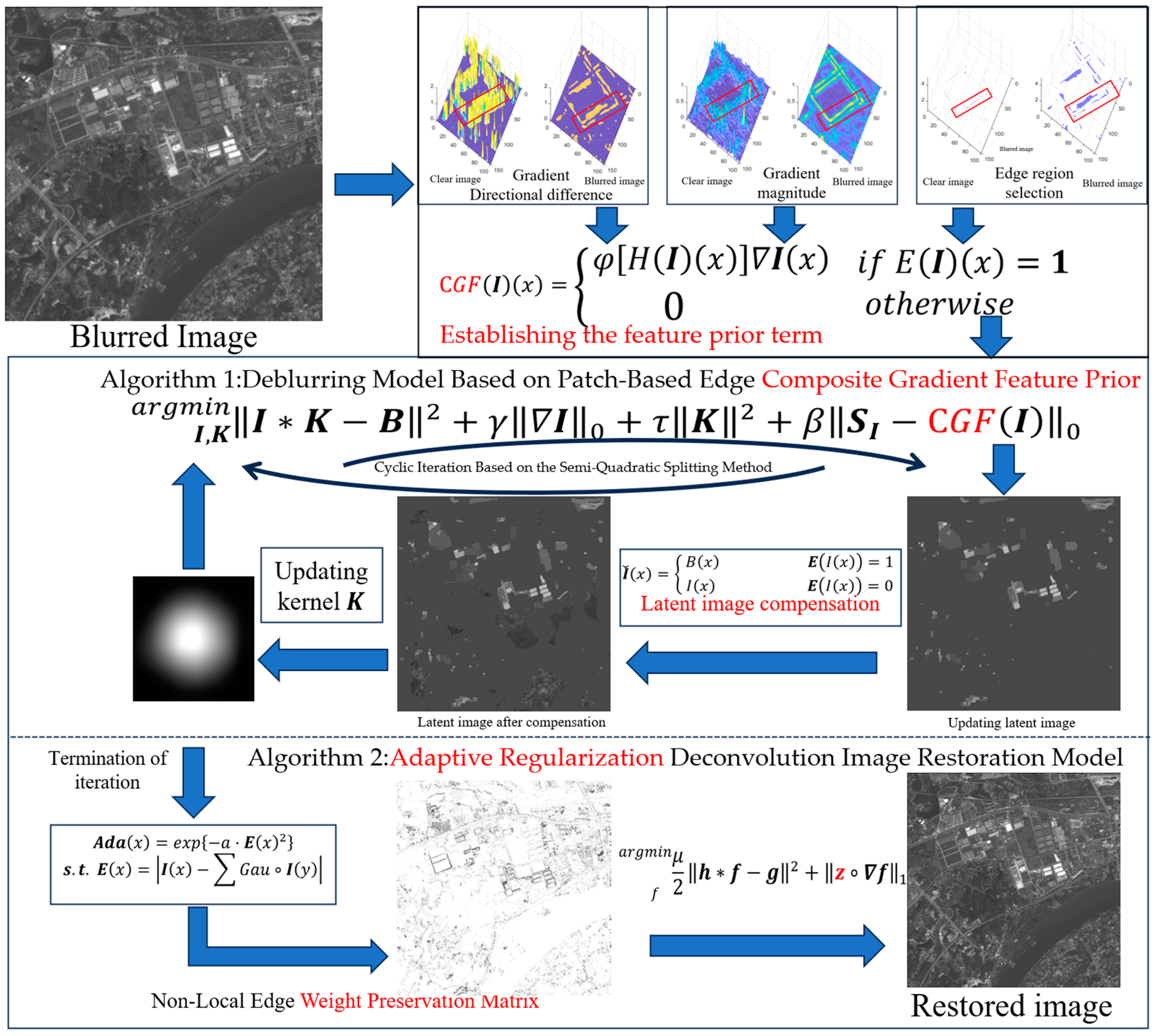
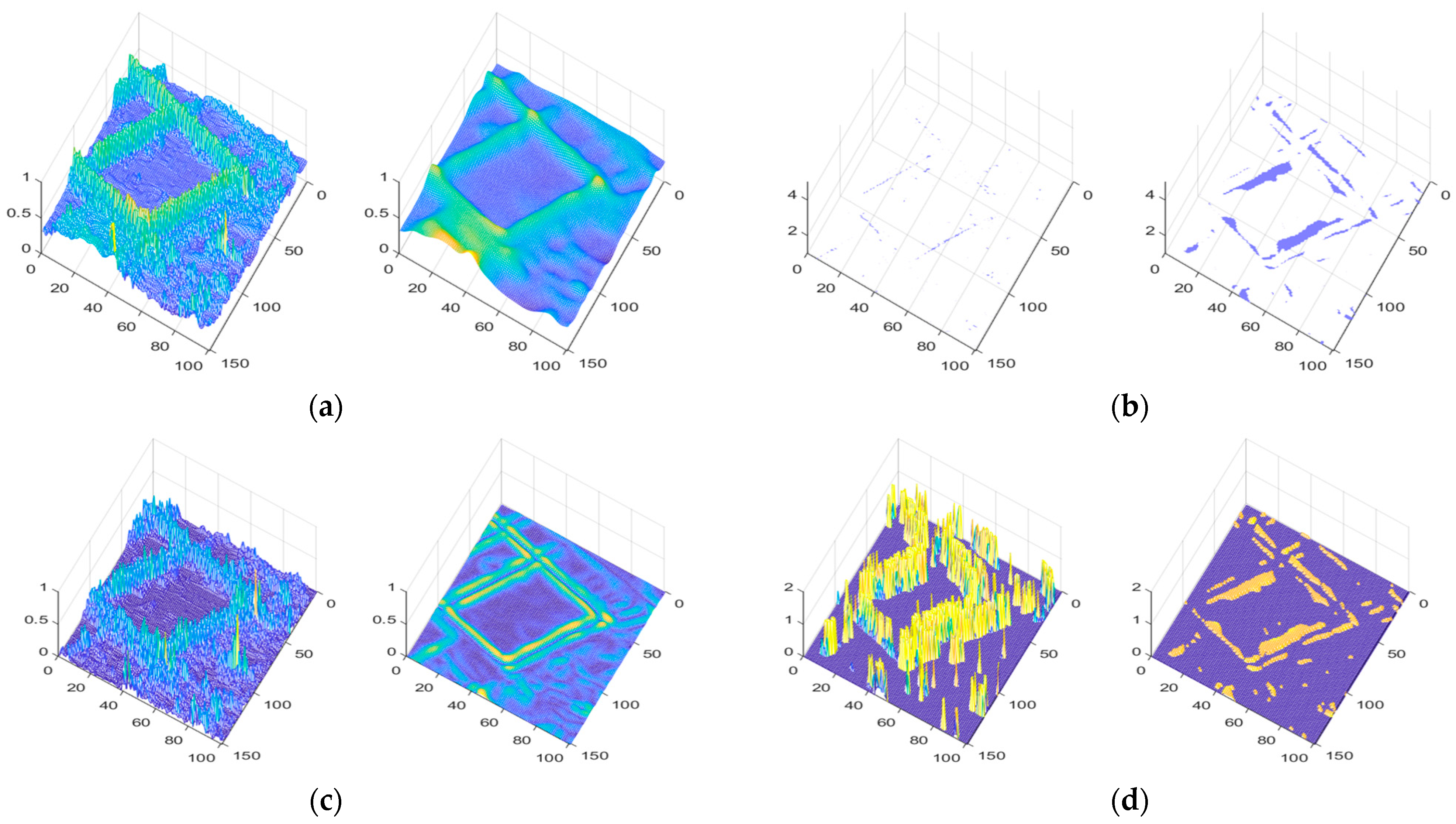
- Novel Edge-Region Detection Method: we propose a new method for detecting edge regions that significantly improves the accuracy of edge localization in blurred images. Unlike existing methods that rely primarily on traditional gradient-based techniques, our method uses a more robust approach based on comparing the gradient magnitude of a central pixel with that of surrounding neighborhood patches. This enables us to effectively identify edge regions, especially in blurred images where traditional methods may struggle. The method places a particular emphasis on aggregating edge regions, allowing for the sufficient detection of both sharp and smoothed edges that may have been affected by blur. This approach is designed to be particularly applicable in real-world scenarios such as infrared imaging, where edges are often blurred but still essential for interpretation.
- Gradient Fusion () Prior Term: based on the edge detection method, we introduce a prior term within the MAP framework, which incorporates the gradient fusion features of image edges. The prior term is specifically designed to exploit the sparse nature of sharp-edge regions in clear images. This sparsity helps alleviate the ill-posed nature of optimization problems typically encountered in image restoration tasks. Notably, the proposed method outperforms existing edge-preserving techniques by providing a more accurate and efficient way to handle blurred regions without over-smoothing important edge details.
- Effective Blur Kernel Estimation with Structural Compensation: in the blur kernel estimation process, we incorporate grayscale values from pixels within the detected edge regions of the blurred image into the intermediate latent image. This approach compensates for subtle structural details lost during the blurring process, ensuring that the final latent image retains more accurate structural information. By preserving edge features more effectively, our method improves the overall accuracy of blur kernel estimation. Moreover, we introduce a weight preservation matrix through nonlinear mapping in the TV model, which preserves critical image details, demonstrating the robustness of our approach. The real-world applicability of this method is evident in its ability to handle complex image structures while delivering high-quality restoration results.
3. Mechanism and Supporting Proof
4. The Blind Deconvolution Model and Optimization
4.1. Patch-Based Edge Composite-Gradient Feature Prior and Deblurring Model
4.2. Implementation of Prior, Mathematically
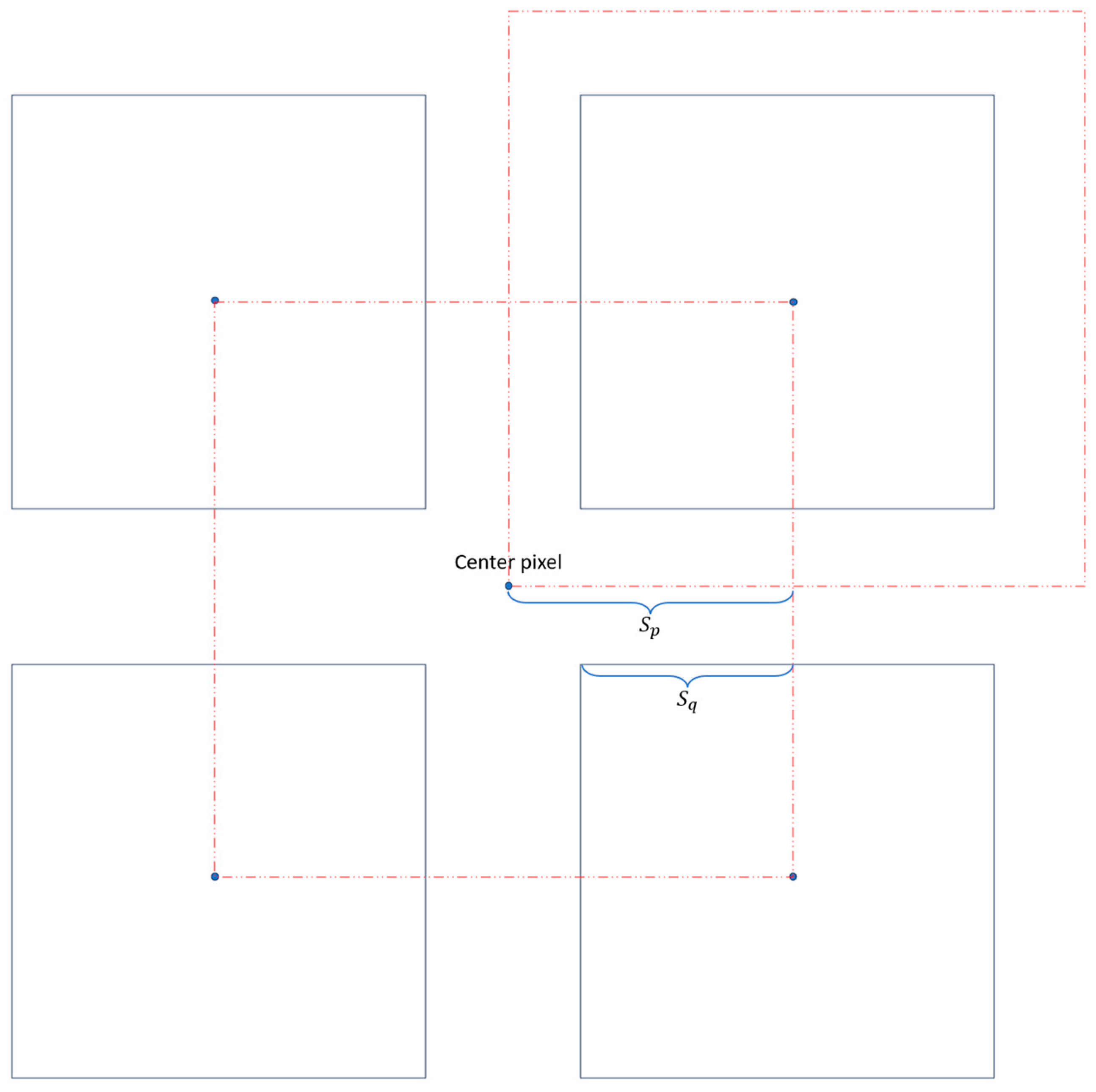
4.2.1. Edge Region Selection Operator
- If , then
- If , then (Max())=
4.2.2. Quantification of Gradient Direction Differences in Edge Regions
- The chosen mapping function, , is a non-negative and increasing function;
- The function is designed to have small increments at the two ends and larger increments in the middle;
- and . Among them, and are the minimum and maximum values of the Gradient Direction Difference Matrix , respectively.
4.2.3. The Implementation of the Calculation of Prior Term
4.3. Model and Optimization
4.3.1. Optimization of Intermediate Latent Image
| Algorithm 1 Calculate intermediate latent Image |
| Input: blurred image , blur kernel For i = 1:5 do Compute matrix using (25). Compute matrix using (28). For i = j:4 do Compute matrix using (38). . repeat Compute matrix using (37). . until End for End for Output: Intermediate latent Image . |
4.3.2. Estimating Blur Kernel
4.3.3. Restore Clear Image by Adaptive Regularization Model
| Algorithm 2 Estimating blur kernel and restore clear Image |
| Input: blurred Image , Intermediate latent Image Initialize from the previous layer of the pyramid. While i < maxiter do Estimate according to (45) Compensation of detail through (43) End While Set parameters (default = 2) and (default = 0.7). Initialize , while not converging, do 1. Solve the -subproblem (49) using (50). 2. Solve the -subproblem (51) using (52). 3. Update the weight matrix using (53). if then break end if break Output: Clear image . |
5. Numerical Experiments
5.1. Experimental Scheme
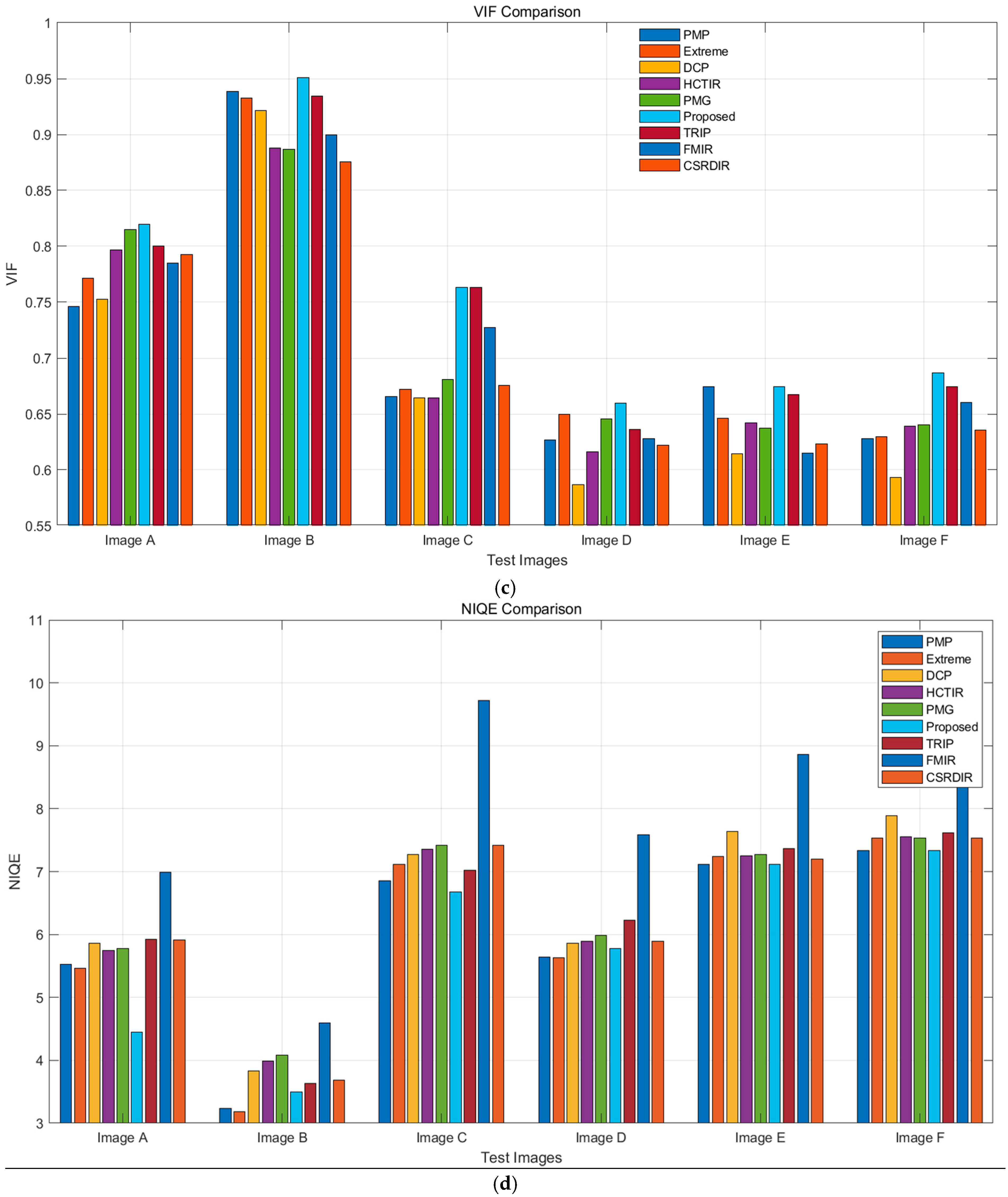
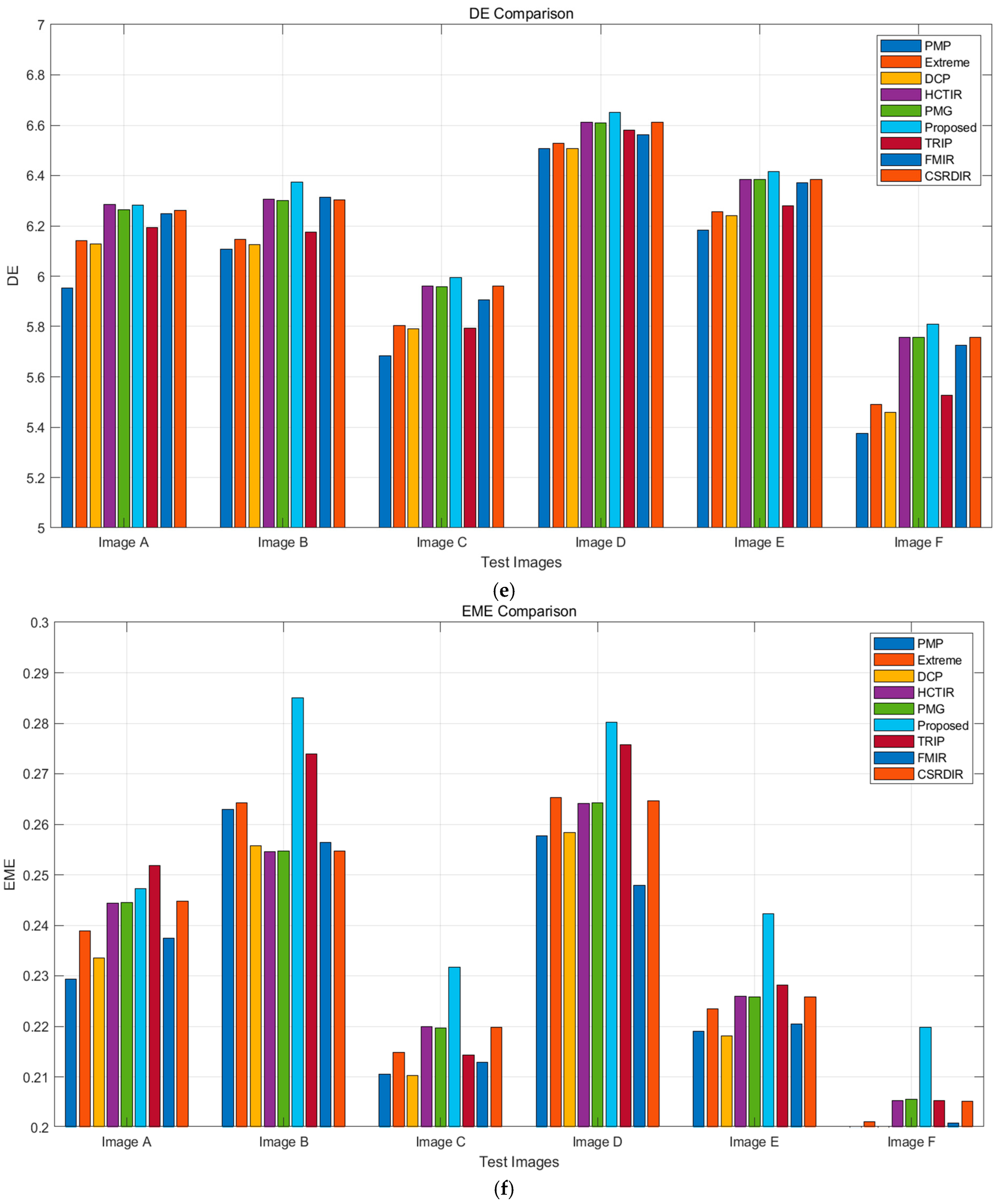
5.2. Results and Discussion
6. Analysis and Discussion
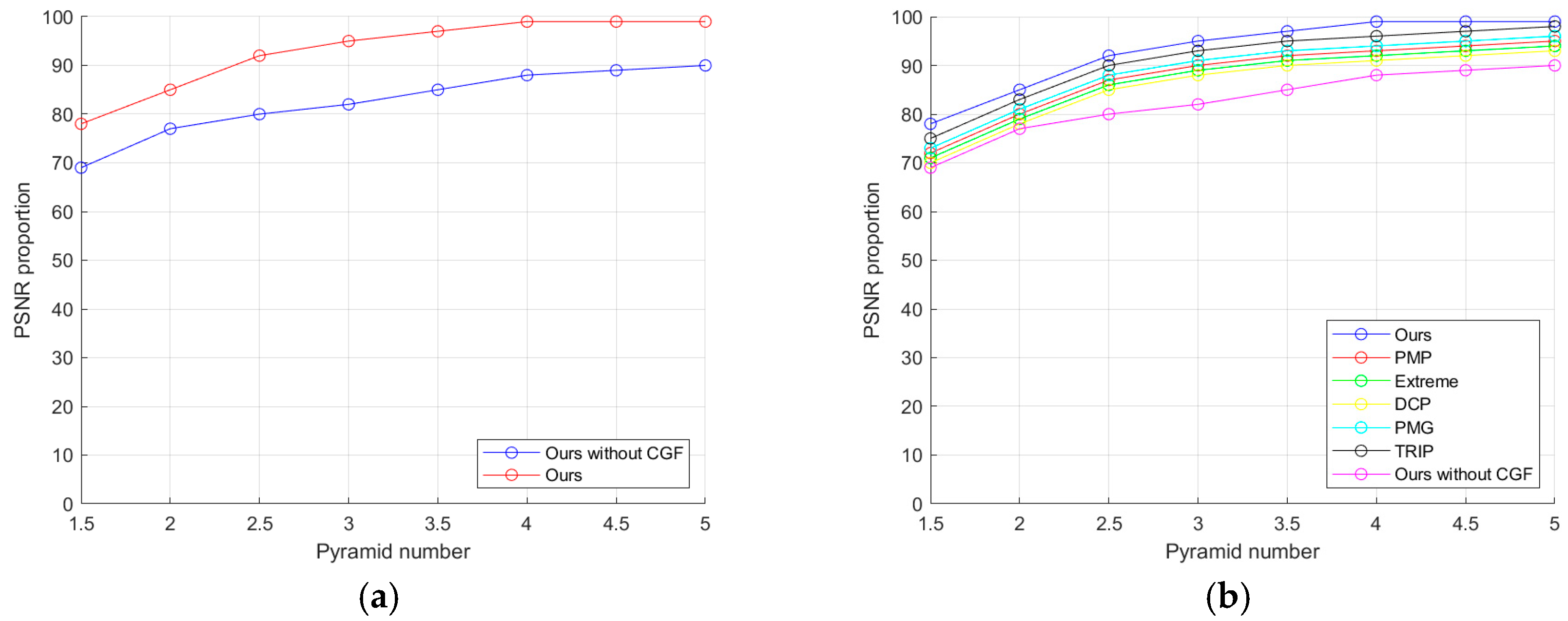
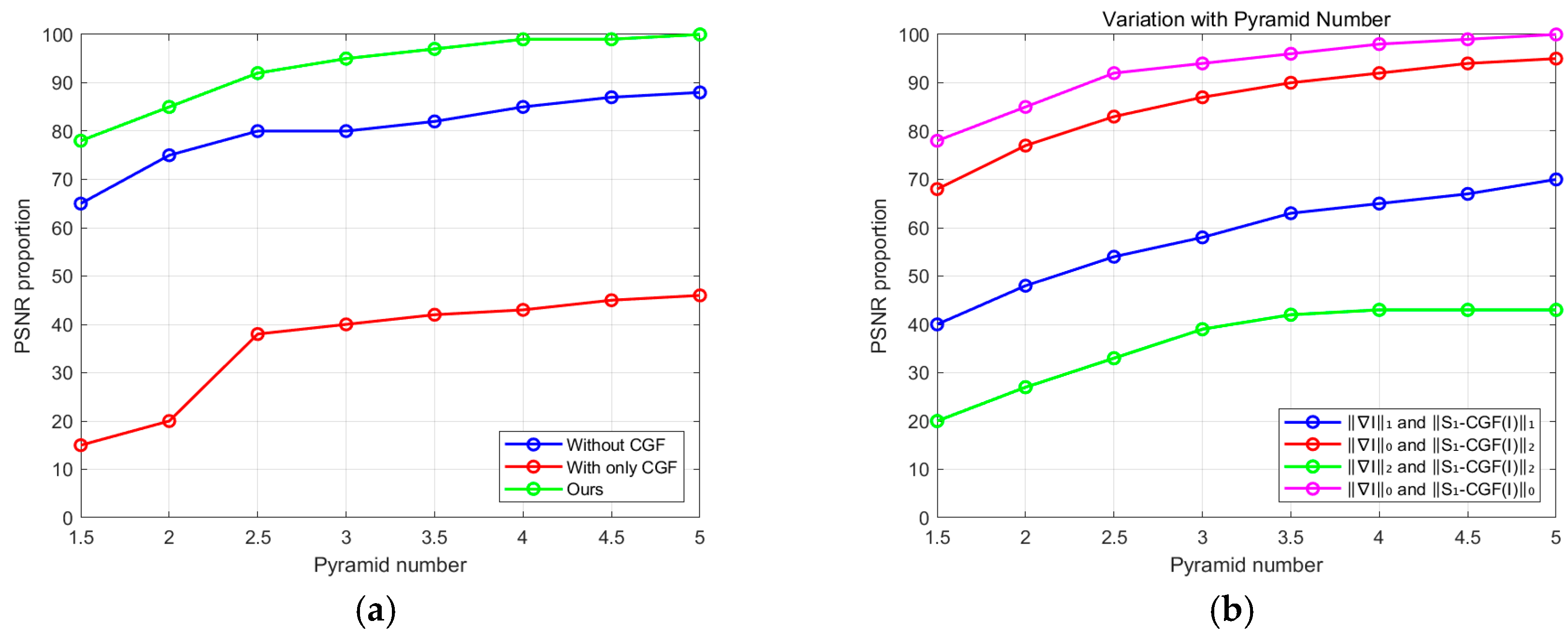
6.1. Effectiveness of Prior
6.2. Comparison with Other L0 Regularization Methods
6.3. Sparsity Constraints on the Prior
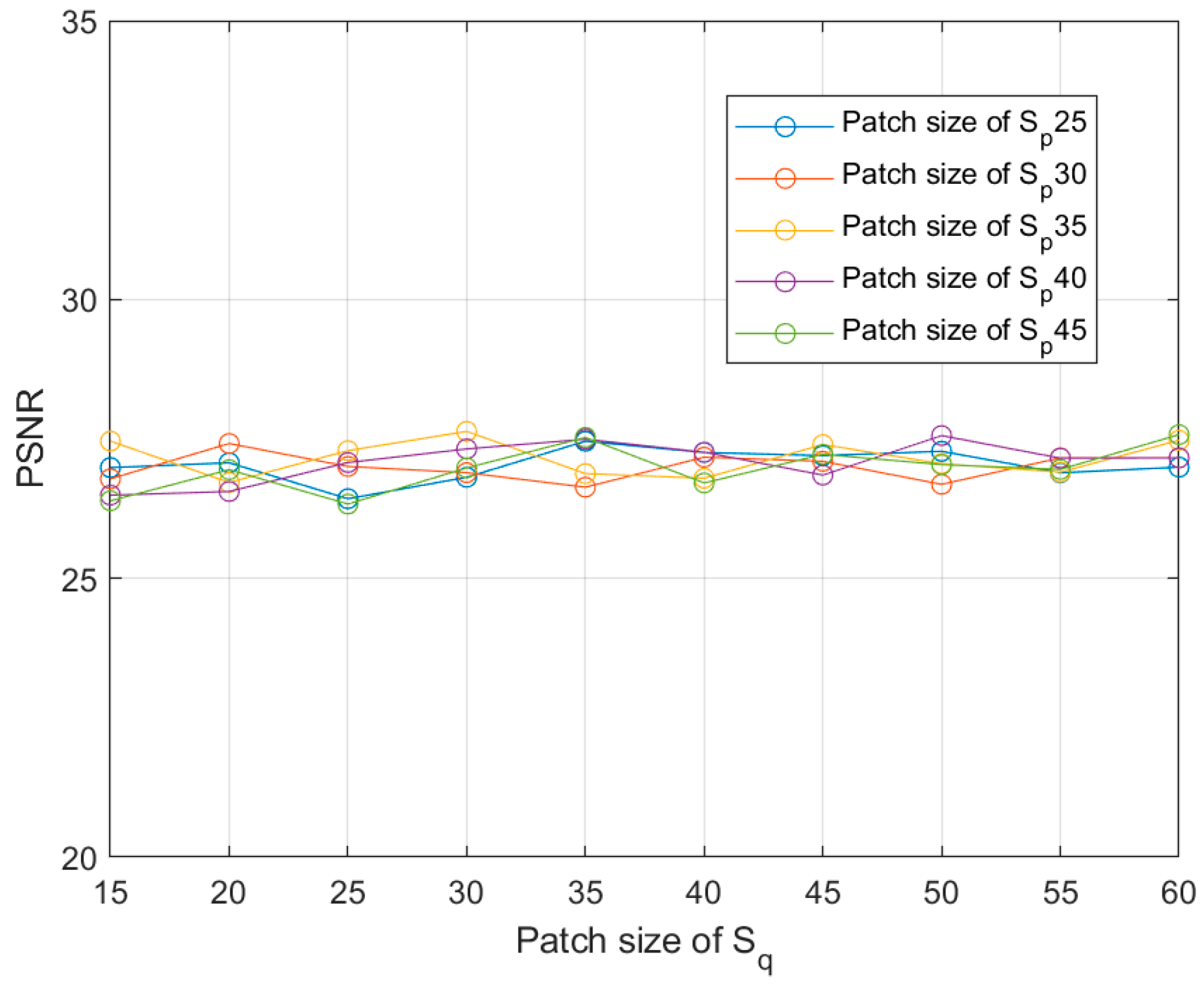
6.4. Effect of Patch Size
6.5. Effect of Adaptive Weights for TV Model
6.6. Analysis of the Parameters
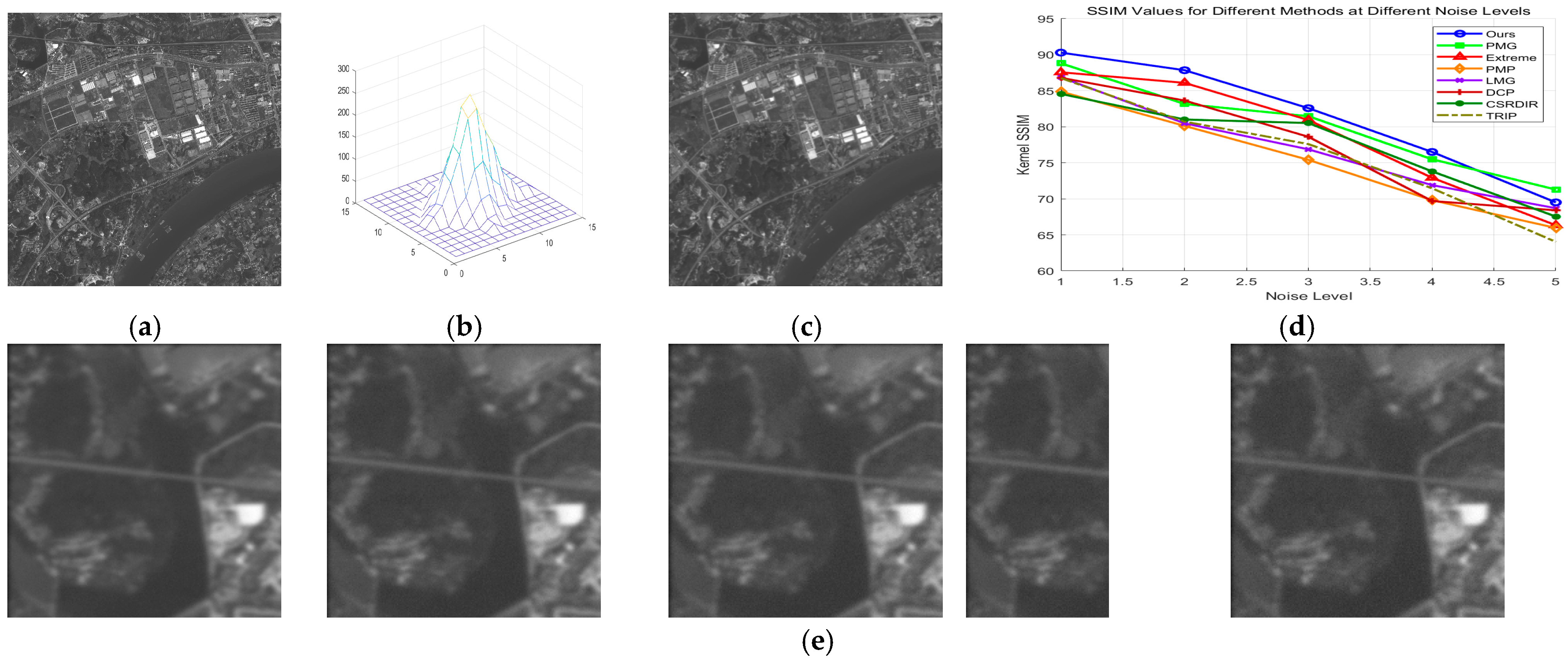
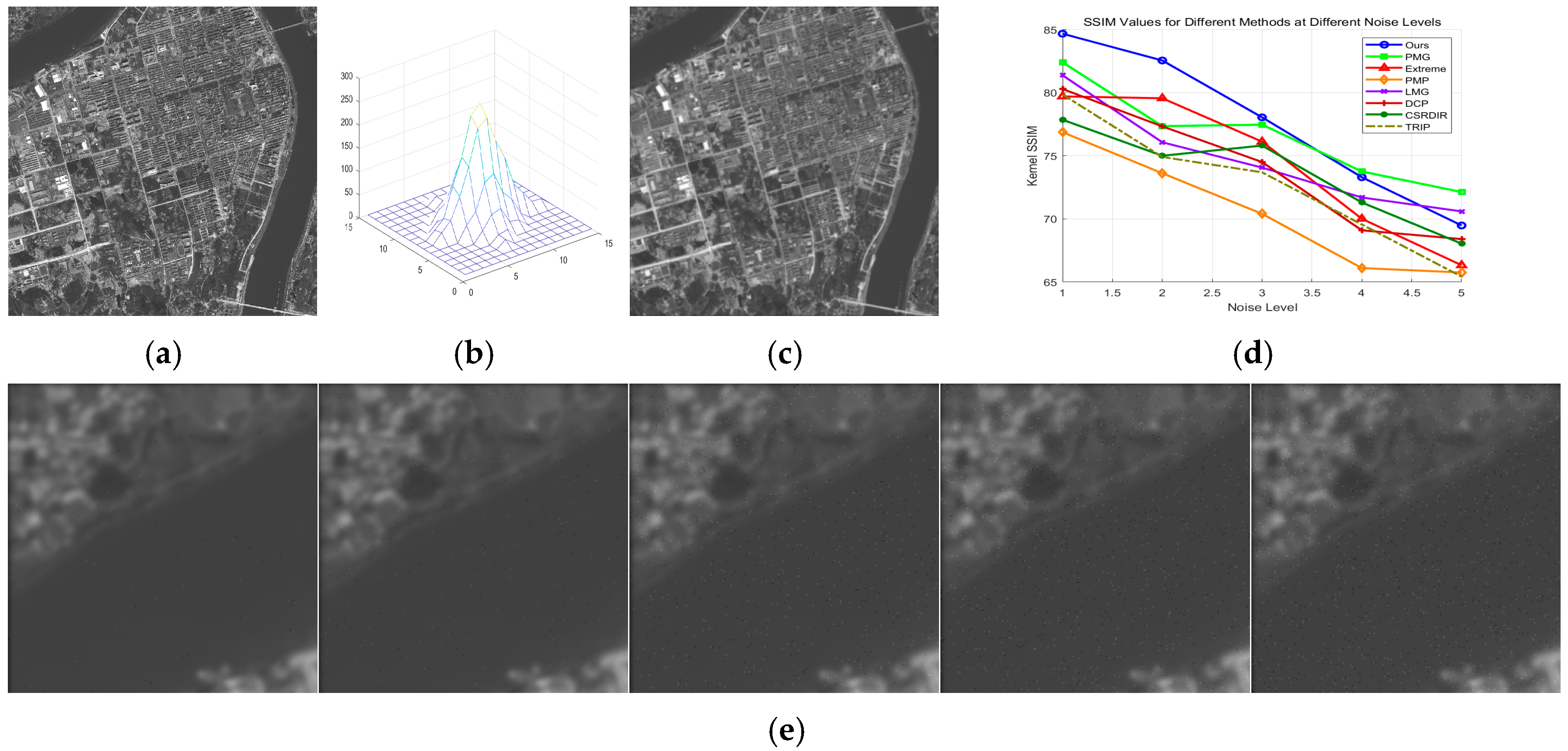
6.7. Noise Robustness Testing
6.7.1. Gaussian Noise Robustness Testing
6.7.2. Salt-and-Pepper Noise Robustness Testing
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Torres Gil, L.K.; Valdelamar Martínez, D.; Saba, M.J.A. The widespread use of remote sensing in asbestos, vegetation, oil and gas, and geology applications. Atmosphere 2023, 14, 172. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C.J.R.S. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.J.I.G.; et al. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef]
- Cao, Q.; Yu, G.; Qiao, Z. Application and recent progress of inland water monitoring using remote sensing techniques. Environ. Monit. Assess. 2023, 195, 125. [Google Scholar] [CrossRef]
- Müller, R. Calibration and verification of remote sensing instruments and observations. Remote Sens. 2014, 6, 5692–5695. [Google Scholar] [CrossRef]
- Ali, M.A.; Eltohamy, F.; Abd-Elrazek, A.; Hanafy, M.E. Assessment of micro-vibrations effect on the quality of remote sensing satellites images. Int. J. Image Data Fusion 2023, 14, 243–260. [Google Scholar] [CrossRef]
- Serief, C.J.O.; Technology, L. Estimate of the effect of micro-vibration on the performance of the Algerian satellite (Alsat-1B) imager. Opt. Laser Technol. 2017, 96, 147–152. [Google Scholar] [CrossRef]
- Yuan, Y.; Cai, Y.; Eyyuboğlu, H.T.; Baykal, Y.; Chen, J. Propagation factor of partially coherent flat-topped beam array in free space and turbulent atmosphere. Opt. Lasers Eng. 2012, 50, 752–759. [Google Scholar] [CrossRef]
- Zoran, D.; Weiss, Y. From learning models of natural image patches to whole image restoration. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 479–486. [Google Scholar]
- Yang, H.; Su, X.; Chen, S. Blind image deconvolution algorithm based on sparse optimization with an adaptive blur kernel estimation. Appl. Sci. 2020, 10, 2437. [Google Scholar] [CrossRef]
- Whyte, O.; Sivic, J.; Zisserman, A. Deblurring shaken and partially saturated images. Int. J. Comput. Vis. 2014, 110, 185–201. [Google Scholar] [CrossRef]
- Ren, M.; Delbracio, M.; Talebi, H.; Gerig, G.; Milanfar, P. Multiscale structure guided diffusion for image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 10721–10733. [Google Scholar]
- Oliveira, J.P.; Bioucas-Dias, J.M.; Figueiredo, M.A. Adaptive total variation image deblurring: A majorization–minimization approach. Signal Process. 2009, 89, 1683–1693. [Google Scholar] [CrossRef]
- Cho, S.; Wang, J.; Lee, S. Handling outliers in non-blind image deconvolution. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 495–502. [Google Scholar]
- Carbajal, G.; Vitoria, P.; Lezama, J.; Musé, P. Blind motion deblurring with pixel-wise Kernel estimation via Kernel prediction networks. IEEE Trans. Comput. Imaging 2023, 9, 928–943. [Google Scholar] [CrossRef]
- Rasti, B.; Chang, Y.; Dalsasso, E.; Denis, L.; Ghamisi, P. Image restoration for remote sensing: Overview and toolbox. IEEE Geosci. Remote Sens. Mag. 2021, 10, 201–230. [Google Scholar] [CrossRef]
- Quan, Y.; Wu, Z.; Ji, H.J. Gaussian kernel mixture network for single image defocus deblurring. Adv. Neural Inf. Process. Syst. 2021, 34, 20812–20824. [Google Scholar]
- Lee, J.; Son, H.; Rim, J.; Cho, S.; Lee, S. Iterative filter adaptive network for single image defocus deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2034–2042. [Google Scholar]
- Barman, T.; Deka, B. A Deep Learning-based Joint Image Super-resolution and Deblurring Framework. IEEE Trans. Artif. Intell. 2024, 5, 3160–3173. [Google Scholar] [CrossRef]
- Shruthi, C.M.; Anirudh, V.R.; Rao, P.B.; Shankar, B.S.; Pandey, A. Deep Learning based Automated Image Deblurring. In Proceedings of the E3S Web of Conferences, Tamilnadu, India, 22–23 November 2023; p. 01052. [Google Scholar]
- Wei, X.-X.; Zhang, L.; Huang, H. High-quality blind defocus deblurring of multispectral images with optics and gradient prior. Opt. Express 2020, 28, 10683–10704. [Google Scholar] [CrossRef]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. In Proceedings of the SIGGRAPH06: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Boston, MA, USA, 30 July–3 August 2006; pp. 787–794. [Google Scholar]
- Shan, Q.; Jia, J.; Agarwala, A. High-quality motion deblurring from a single image. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Understanding and evaluating blind deconvolution algorithms. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1964–1971. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Efficient marginal likelihood optimization in blind deconvolution. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2657–2664. [Google Scholar]
- Krishnan, D.; Tay, T.; Fergus, R. Blind deconvolution using a normalized sparsity measure. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 233–240. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Pan, J.; Su, Z. Fast ℓ0-Regularized Kernel Estimation for Robust Motion Deblurring. IEEE Signal Process. Lett. 2013, 20, 841–844. [Google Scholar]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.-H. Deblurring text images via L0-regularized intensity and gradient prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2901–2908. [Google Scholar]
- Li, J.; Lu, W. Blind image motion deblurring with L0-regularized priors. J. Vis. Commun. Image Represent. 2016, 40, 14–23. [Google Scholar] [CrossRef]
- Xu, L.; Jia, J. Two-phase kernel estimation for robust motion deblurring. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Proceedings, Part I 11. pp. 157–170. [Google Scholar]
- Pan, J.; Liu, R.; Su, Z.; Gu, X. Kernel estimation from salient structure for robust motion deblurring. Signal Process. Image Commun. 2013, 28, 1156–1170. [Google Scholar] [CrossRef]
- Cho, S.; Lee, S. Fast motion deblurring. In Proceedings of the SIGGRAPH09: Special Interest Group on Computer Graphics and Interactive Techniques Conference, New Orleans, LA, USA, 3–7 August 2009; pp. 1–8. [Google Scholar]
- Joshi, N.; Szeliski, R.; Kriegman, D.J. PSF estimation using sharp edge prediction. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sun, L.; Cho, S.; Wang, J.; Hays, J. Edge-based blur kernel estimation using patch priors. In Proceedings of the IEEE International Conference on Computational Photography (ICCP), Cambridge, MA, USA, 19–21 April 2013; pp. 1–8. [Google Scholar]
- Michaeli, T.; Irani, M. Blind deblurring using internal patch recurrence. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part III 13. pp. 783–798. [Google Scholar]
- Ren, W.; Cao, X.; Pan, J.; Guo, X.; Zuo, W.; Yang, M.-H. Image deblurring via enhanced low-rank prior. IEEE Trans. Image Process. 2016, 25, 3426–3437. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Pan, J.; Su, Z. Blur kernel estimation via salient edges and low rank prior for blind image deblurring. Signal Process. Image Commun. 2017, 58, 134–145. [Google Scholar] [CrossRef]
- Tang, Y.; Xue, Y.; Chen, Y.; Zhou, L. Blind deblurring with sparse representation via external patch priors. Digit. Signal Process. 2018, 78, 322–331. [Google Scholar] [CrossRef]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.-H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Yan, Y.; Ren, W.; Guo, Y.; Wang, R.; Cao, X. Image deblurring via extreme channels prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4003–4011. [Google Scholar]
- Wen, F.; Ying, R.; Liu, Y.; Liu, P.; Truong, T.-K. A simple local minimal intensity prior and an improved algorithm for blind image deblurring. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2923–2937. [Google Scholar] [CrossRef]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind image deblurring with local maximum gradient prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1742–1750. [Google Scholar]
- Hsieh, P.-W.; Shao, P.-C. Blind image deblurring based on the sparsity of patch minimum information. Pattern Recognit. 2021, 109, 107597. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, H.; Li, Z. Fast blind deconvolution using a deeper sparse patch-wise maximum gradient prior. Signal Process. Image Commun. 2021, 90, 116050. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, X.; Li, L.; Hu, T.; Fansheng, C. A combined stripe noise removal and deblurring recovering method for thermal infrared remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Gong, D.; Tan, M.; Zhang, Y.; Van Den Hengel, A.; Shi, Q. Self-paced kernel estimation for robust blind image deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1661–1670. [Google Scholar]
- Dong, J.; Pan, J.; Su, Z.; Yang, M.-H. Blind image deblurring with outlier handling. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2478–2486. [Google Scholar]
- Hu, Z.; Cho, S.; Wang, J.; Yang, M.-H. Deblurring low-light images with light streaks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3382–3389. [Google Scholar]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.-H. Deblurring face images with exemplars. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VII 13. pp. 47–62. [Google Scholar]
- Jiang, X.; Yao, H.; Zhao, S. Text image deblurring via two-tone prior. Neurocomputing 2017, 242, 1–14. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to deblur. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1439–1451. [Google Scholar] [CrossRef]
- Chakrabarti, A. A neural approach to blind motion deblurring. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. pp. 221–235. [Google Scholar]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.-H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Li, L.; Pan, J.; Lai, W.-S.; Gao, C.; Sang, N.; Yang, M.-H. Blind image deblurring via deep discriminative priors. Int. J. Comput. Vis. 2019, 127, 1025–1043. [Google Scholar] [CrossRef]
- Chen, M.; Quan, Y.; Xu, Y.; Ji, H. Self-supervised blind image deconvolution via deep generative ensemble learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 634–647. [Google Scholar] [CrossRef]
- Quan, Y.; Yao, X.; Ji, H. Single image defocus deblurring via implicit neural inverse kernels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12600–12610. [Google Scholar]
- Yi, S.; Li, L.; Liu, X.; Li, J.; Chen, L. HCTIRdeblur: A hybrid convolution-transformer network for single infrared image deblurring. Infrared Phys. Technol. 2023, 131, 104640. [Google Scholar] [CrossRef]
- Young, W.H. On the multiplication of successions of Fourier constants. Proc. R. Soc. London. Ser. A Contain. Pap. A Math. Phys. Character 1912, 87, 331–339. [Google Scholar]
- Zhou, X.; Zhang, J.; Li, M.; Su, X.; Chen, F. Thermal infrared spectrometer on-orbit defocus assessment based on blind image blur kernel estimation. Infrared Phys. Technol. 2023, 130, 104538. [Google Scholar] [CrossRef]
- Yang, L.; Yang, J.; Yang, K. Adaptive detection for infrared small target under sea-sky complex background. Electron. Lett. 2004, 40, 1. [Google Scholar] [CrossRef]
- Chen, B.-H.; Wu, Y.-L.; Shi, L.-F. A fast image contrast enhancement algorithm using entropy-preserving mapping prior. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 38–49. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Y.; Zhang, L.; Zhang, Z.; Li, Y. Image deblurring using tri-segment intensity prior. Neurocomputing 2020, 398, 265–279. [Google Scholar] [CrossRef]
- Varghese, N.; Mohan, M.R.; Rajagopalan, A.N. Fast motion-deblurring of IR images. IEEE Signal Process. Lett. 2022, 29, 459–463. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, M.H. Good regions to deblur. Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012, Proceedings, Part V.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 59–72. [Google Scholar]
















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Li, M.; Nie, T.; Han, C.; Huang, L. Blind Infrared Remote-Sensing Image Deblurring Algorithm via Edge Composite-Gradient Feature Prior and Detail Maintenance. Remote Sens. 2024, 16, 4697. https://doi.org/10.3390/rs16244697
Zhao X, Li M, Nie T, Han C, Huang L. Blind Infrared Remote-Sensing Image Deblurring Algorithm via Edge Composite-Gradient Feature Prior and Detail Maintenance. Remote Sensing. 2024; 16(24):4697. https://doi.org/10.3390/rs16244697
Chicago/Turabian StyleZhao, Xiaohang, Mingxuan Li, Ting Nie, Chengshan Han, and Liang Huang. 2024. "Blind Infrared Remote-Sensing Image Deblurring Algorithm via Edge Composite-Gradient Feature Prior and Detail Maintenance" Remote Sensing 16, no. 24: 4697. https://doi.org/10.3390/rs16244697
APA StyleZhao, X., Li, M., Nie, T., Han, C., & Huang, L. (2024). Blind Infrared Remote-Sensing Image Deblurring Algorithm via Edge Composite-Gradient Feature Prior and Detail Maintenance. Remote Sensing, 16(24), 4697. https://doi.org/10.3390/rs16244697