1. Introduction
As a core technology in the field of computer vision, object detection not only enables automatic recognition and localization of objects but also provides a solid foundation for subsequent tasks such as decision analysis and behavior understanding. It is widely applied in various domains including security surveillance, autonomous driving, intelligent manufacturing, search and rescue, significantly enhancing the intelligence level and response speed of these systems [
1]. Traditional object detection methods are limited by manual features and geometric extraction, leading to inefficiency and insufficient accuracy [
2]. With the rise of deep learning, the powerful feature extraction capabilities of multi-layer neural networks has significantly advanced the development of object detection technology [
3,
4].
Deep learning-based object detection algorithms are mainly divided into one-stage and two-stage methods. Two-stage methods divide object detection into candidate region generation and candidate region classification [
5]. Wu et al. [
6] proposed a two-stage method that first uses Binarized Normed Gradients (BING) to obtain candidate regions and then applies Convolutional Neural Networks (CNN) for detection. This research introduced CNN into aircraft detection for the first time. Wu et al. [
7] presented an improved Mask Region-based CNN (R-CNN) model called SCMask R-CNN, which can perform object detection and segmentation in parallel. The improved model increased detection accuracy by 1% to 2%. Zhang et al. [
8] proposed a method that combines GoogLeNet with R-CNN to detect aircraft of various scales in remote sensing images, which can effectively achieve object detection. Liu et al. [
9] combined corner clustering with CNN to propose a new two-stage aircraft target detection method. This method can generate a small number of high-quality candidate regions, reducing the false alarm rate and improving the accuracy and robustness of object detection. Kumar et al. [
1] conducted an in-depth study on the detection performance of Faster R-CNN on military aircraft, exploring the impact of anchor ratios on detection accuracy. These methods have significant advantages in accuracy, but their complex structures require a large amount of computing resources, resulting in slow computation speeds and a lack of global information [
10].
One-stage detectors directly regress the bounding boxes from feature maps, achieving higher efficiency and being more lightweight [
10]. Representative methods include You Only Look Once (YOLO) [
11], Single Shot MultiBox Detector (SSD) [
12]. YOLO algorithm is widely used in aircraft detection due to its concise network architecture and ultra-fast operation speed. It has optimized the trade-off between speed and accuracy in subsequent iterations [
13]. Ji et al. [
14] designed a remote sensing image segmentation algorithm to address the issues of large image size and significant variations in remote sensing images. By combining the yolov5 detector, they performed segmentation before detection on the original images. This method was validated on remote sensing datasets, effectively improving object recognition accuracy. Bhavani et al. [
15] used an improved yolov5 algorithm to enhance object detection accuracy. Aiming at the difficulties and high costs of labeling spaceborne optical remote sensing images, Wang et al. [
16] proposed an end-to-end lightweight aircraft detection framework, A Network Based on Circle Grayscale Characteristics (CGC-NET), which can effectively identify targets with a small number of samples. Cai et al. [
17] proposed a YOLOv8-GD method to address the issues of poor detection accuracy and weak generalization ability in Synthetic Aperture Radar (SAR) images with complex backgrounds, effectively improving the accuracy of aircraft detection in SAR images. Bakirci et al. [
18] utilized the newly released YOLOv9 to detect aircraft targets in satellite images obtained from low-Earth orbit, enhancing airport and aircraft security.
These object detection techniques have achieved remarkable results in single-modality remote sensing images. However, due to the influence of complex environmental factors, it is difficult to accurately detect targets using single-modality (visible light only or infrared only, etc.) remote sensing images [
9,
19]. To this end, researchers have introduced multi-modality image fusion technology into aircraft detection [
8], particularly the fusion of infrared and visible light images, aiming to improve detection accuracy through information complementarity. Several multispectral datasets, such as FLIR [
20], LLVIP [
21], and VEDAI [
22], have also contributed to the advancement of this technology. Adrián [
23] et al. addressing the issue of lighting and other harsh environments at disaster sites limiting vision, proposed an infrared-visible light fusion object detection method based on YOLOv3. This method was applied to detect human and vehicle targets, achieving good performance in search and rescue scenarios. Dong [
24] et al. focusing on the limitation of vehicle detection accuracy using single-modal methods in complex urban environments, innovatively proposed a feature-level infrared and visible light image fusion technique specifically designed to enhance vehicle detection accuracy during both daytime and nighttime. They successfully implemented the practical application of this technique. Due to limitations in datasets, current multi-modality fusion detection primarily focuses on targets such as pedestrians and vehicles, with relatively limited research on aircraft.
In existing multimodal fusion object detection methods, image feature-level fusion methods can be divided into early fusion, mid-fusion, and late fusion according to the fusion stage. Studies have shown that mid-fusion outperforms other fusion methods [
25,
26,
27,
28]. Traditional fusion methods, such as channel concatenation, are simple but have limited in effectiveness. Zhou et al. [
29] proposed a Modality Balance Network (MBNet), which fuse features through Differential Modality-Aware Fusion (DMAF) and an illumination-aware feature alignment module. However, differential methods can only extract differential features between modalities, ignoring other features. Subsequently, various innovative methods have been proposed to enhance feature fusion effects, such as the dual-branch YOLOv3 brightness-weighted fusion network [
30], the self-attention feature fusion module and feature interaction in YOLO-MS [
31], and the fusion module that adaptively adjusts feature weights [
28,
32], as well as the Attention-based Feature Enhancement Fusion Module (AFEFM) that combines differential features with original features through cross-concatenation [
33]. Although these methods have their unique characteristics, they often overlook the value of common information between modalities and mostly focus on local feature information, lacking interaction with distant features. Researchers have then attempted to combine Transformer with CNNs [
19,
34], which improves detection accuracy but significantly increases model complexity, hindering practical deployment [
35]. Fang et al. [
36] achieved efficient multimodal feature fusion with low parameters by distinguishing between common and differential features, but there is still room for improvement in their feature separation method.
Cosine similarity, as an efficient and stable similarity measurement method, boasts fast calculation speed and high resilience to changes in image brightness and contrast [
37]. It has been utilized to calculate the similarity between texts or images [
38]. Liu et al. [
39] applied weighted cosine similarity for image retrieval. Researchers Li et al. [
40,
41,
42] successfully applied the cosine similarity metric to image classification tasks. Yuan et al. [
43] combined cosine similarity calculation with feature redundancy analysis, removing redundant features through cosine transformation. Islam et al. [
44] used cosine similarity to filter similar images in medical imaging. Ahmad et al. [
45] replaced dot product operation in convolutional operations with sharpened cosine similarity calculations, measuring similarities in direction, providing a new perspective for feature extraction. Wang et al. [
46] proposed a target detection network model named YOLO-CS, which ingeniously adopted cosine similarity to replace the traditional dot product operation for measuring the similarity between cross-scale features, thereby facilitating efficient fusion of multi-scale features. Furthermore, cosine similarity was also applied in the construction of the loss function, significantly enhancing the model’s ability to distinguish between backgrounds and targets. Practical applications have demonstrated that the YOLO-CS model exhibits higher accuracy in UAV detection tasks, effectively resolving the original issues.These studies collectively demonstrate the significant application potential of cosine similarity in object detection and image processing. Existing research methods primarily apply cosine similarity in fields such as image classification, retrieval, and similar image filtering. They also propose a new feature extraction approach by using cosine similarity to replace the dot product in convolutional calculations. However, when calculating the similarity between images using cosine similarity, they typically flatten all pixels of the entire image into a one-dimensional vector, or compress image channels and flatten the pixels of cropped or processed sections into one-dimensional vectors for computation. Research that treats an image’s feature channels as a unit and flattens the pixels of a single feature channel into a vector to calculate the similarity between corresponding feature channels of different modalities is relatively scarce.
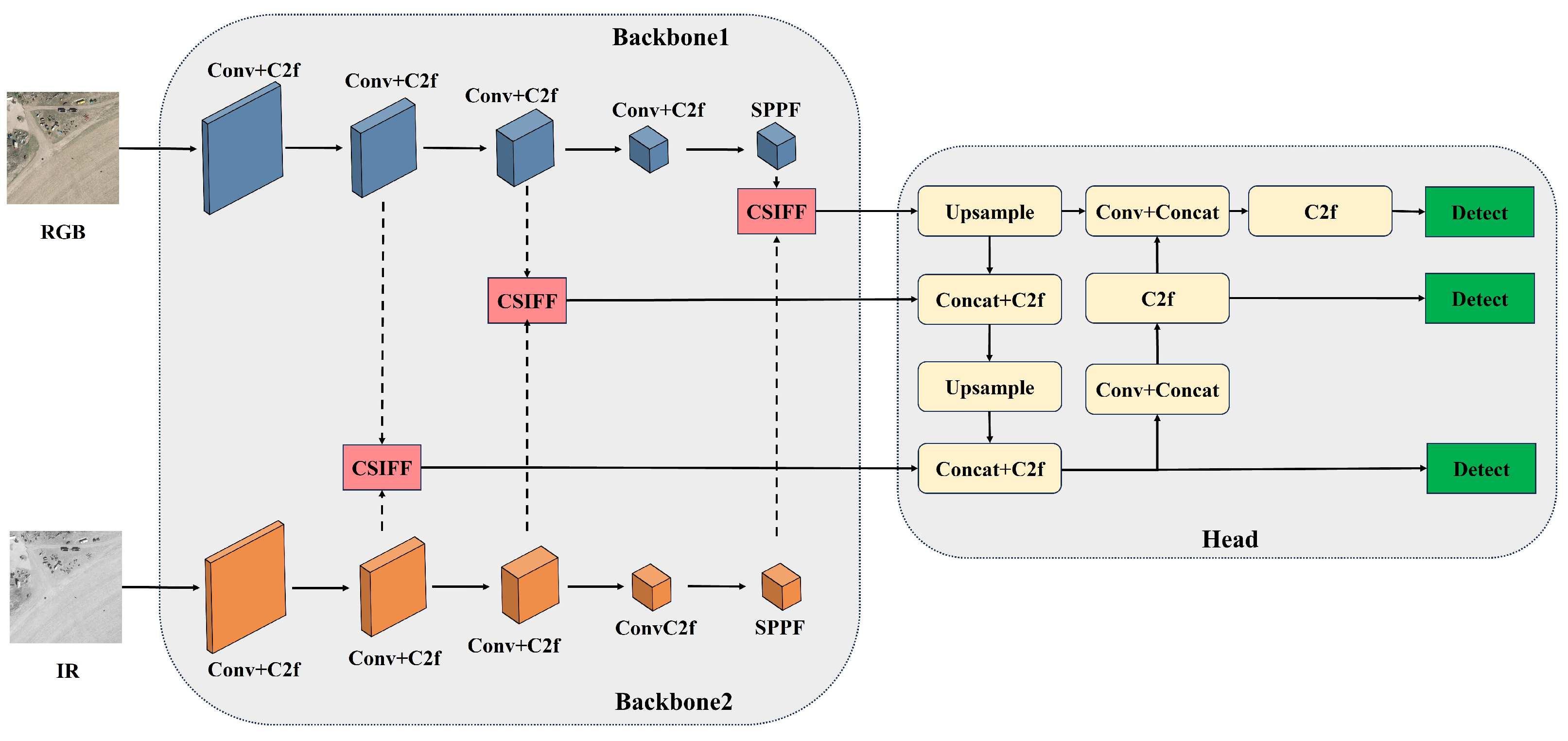
To address the above issues, we innovatively adopt a lightweight dual-branch YOLOv8 architecture, which consists of two parallel backbone networks and a unified head network. These two backbone networks specialize in extracting information from visible and infrared images, respectively, and fuse their outputs before passing them to the head for further detection. To better achieve feature complementarity between visible and infrared modalities, we have devised an efficient feature fusion module called Cosine Similarity-based Image Feature Fusion (CSIFF). CSIFF module initially leverages cosine similarity to decompose features from both modalities into similar and specific features through the Feature Spliting (FS) module. Subsequently, the Similar Feature Processing (SFP) module filters similar features to mitigate redundancy while the Distinct Feature Processing (DFP) module enhancs specific features to preserve their uniqueness. By embedding the CSIFF module into various layers of the dual-branch YOLOv8 backbone to achieve multi-scale feature fusion, constructing an efficient and lightweight Multi-Modality YOLO Fusion Network (MMYFNet) for object detection. This study holds great significance in enhancing the accuracy of object detection.
The main contributions of this paper are as follows:
We designed a dual-branch YOLOv8 architecture, where two parallel backbone networks extract features from visible and infrared modalities, respectively. By ingeniously integrating the CSIFF module into different layers of the backbone, we constructed a novel multi-modal fusion object detection network, MMYFNet.
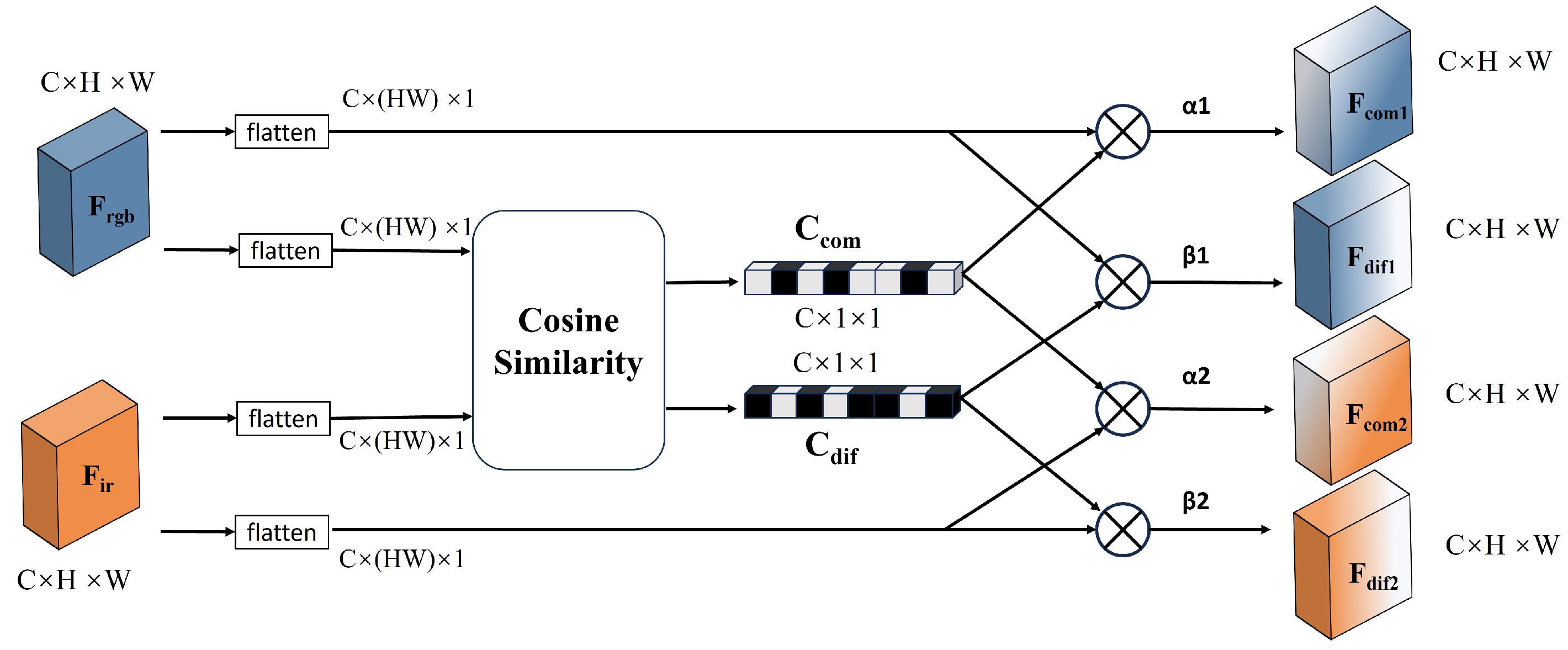
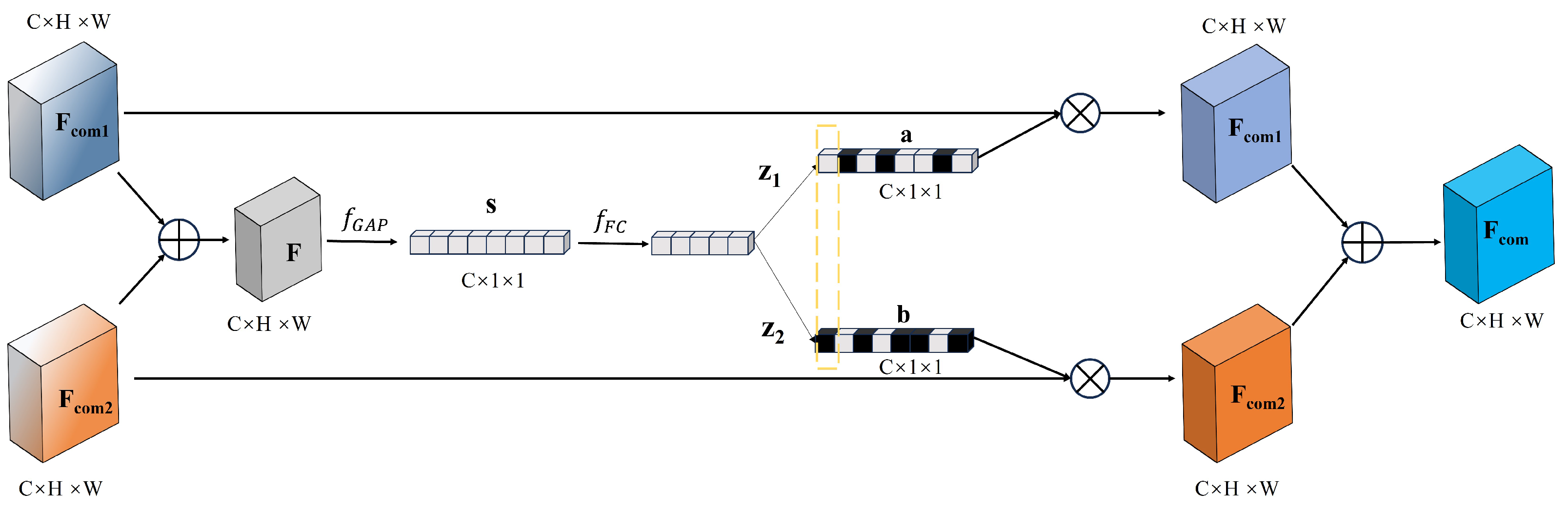
We propose a lightweight feature fusion module, CSIFF, which first precisely partitions features into shared and specific features based on the cosine similarity between corresponding feature channels of different modalities. Subsequently, The DFP module and the SFP module are respectively employed for feature processing operations on distinct features and similar features. Finally, the processed specific and shared features are element-wise added to obtain the fused features.
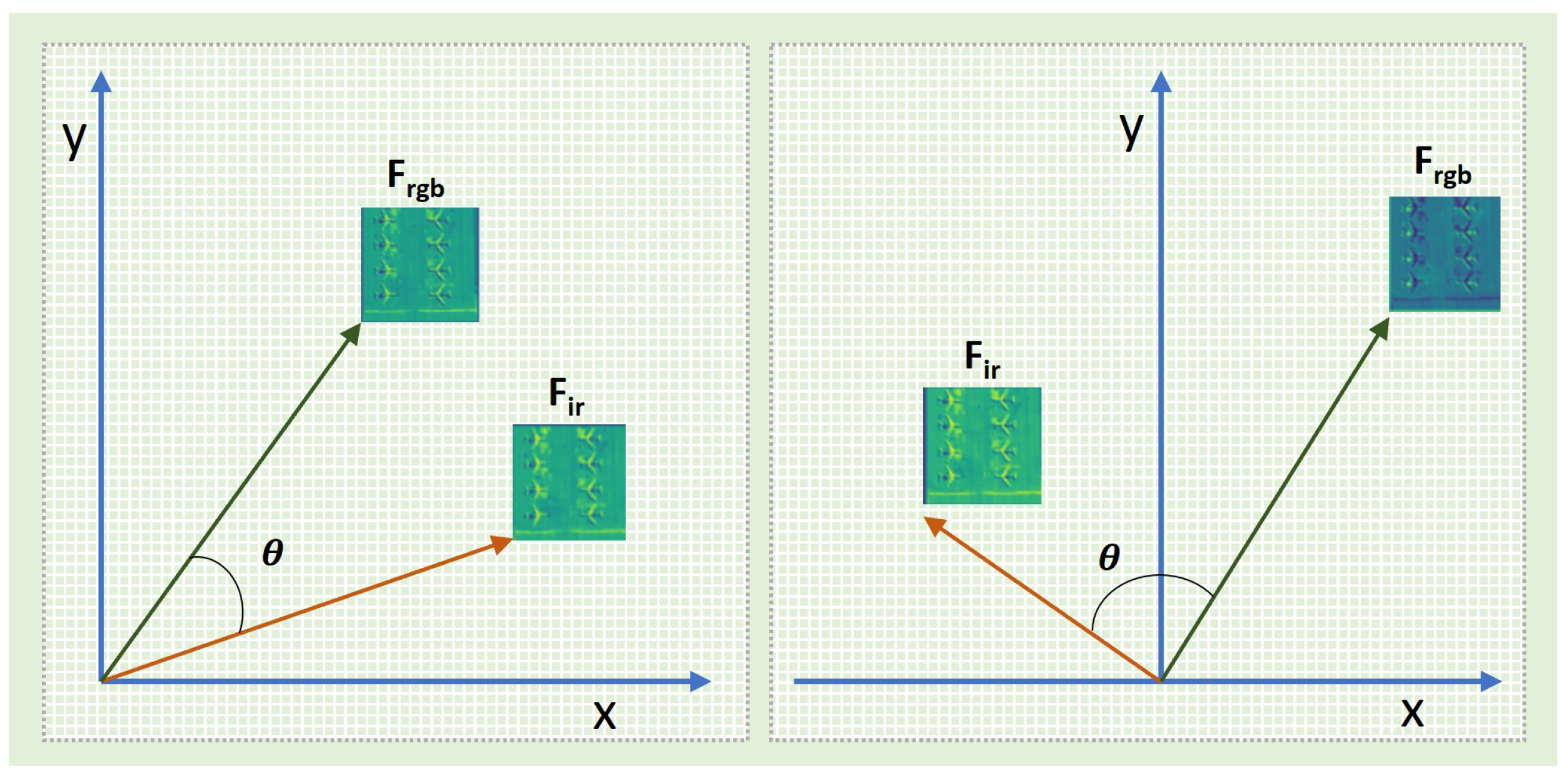
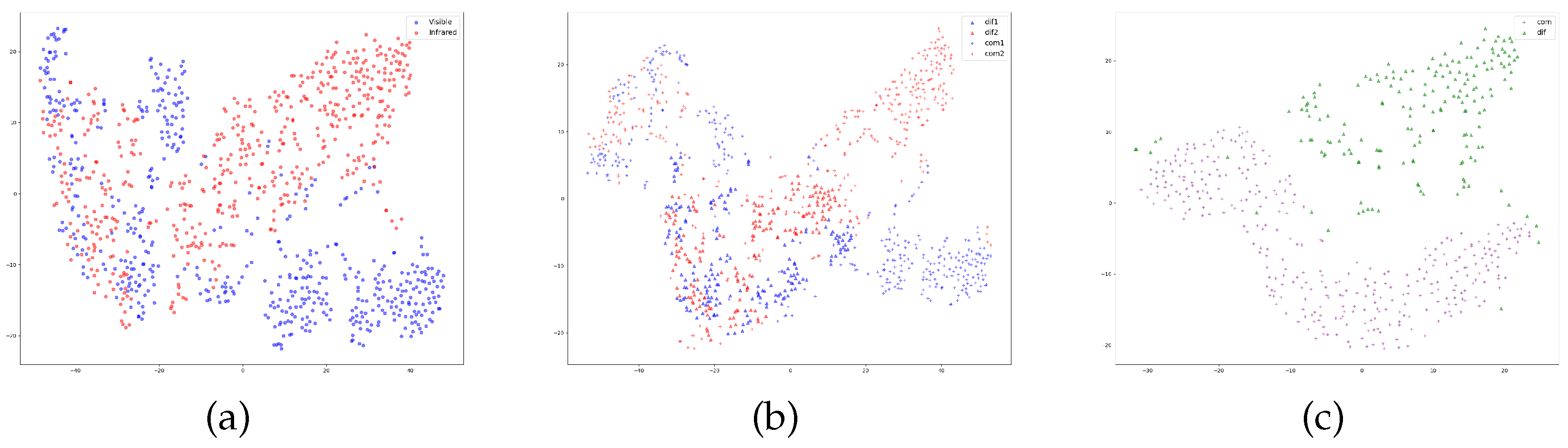
We introduced the FS module, which innovatively applies cosine similarity to compute the similarity between corresponding feature channels of different modalities. Unlike previous applications, it treats each feature channel as a computational unit, flattening all pixels within a single feature channel into a vector for similarity calculation with feature vectors from corresponding channels of different modalities. By adopting this approach, we are able to classify the different feature channels of the same image, distinguishing between similar and dissimilar features, thereby providing more detailed and accurate information for subsequent processing. This new application direction broadens the scope of cosine similarity applications.
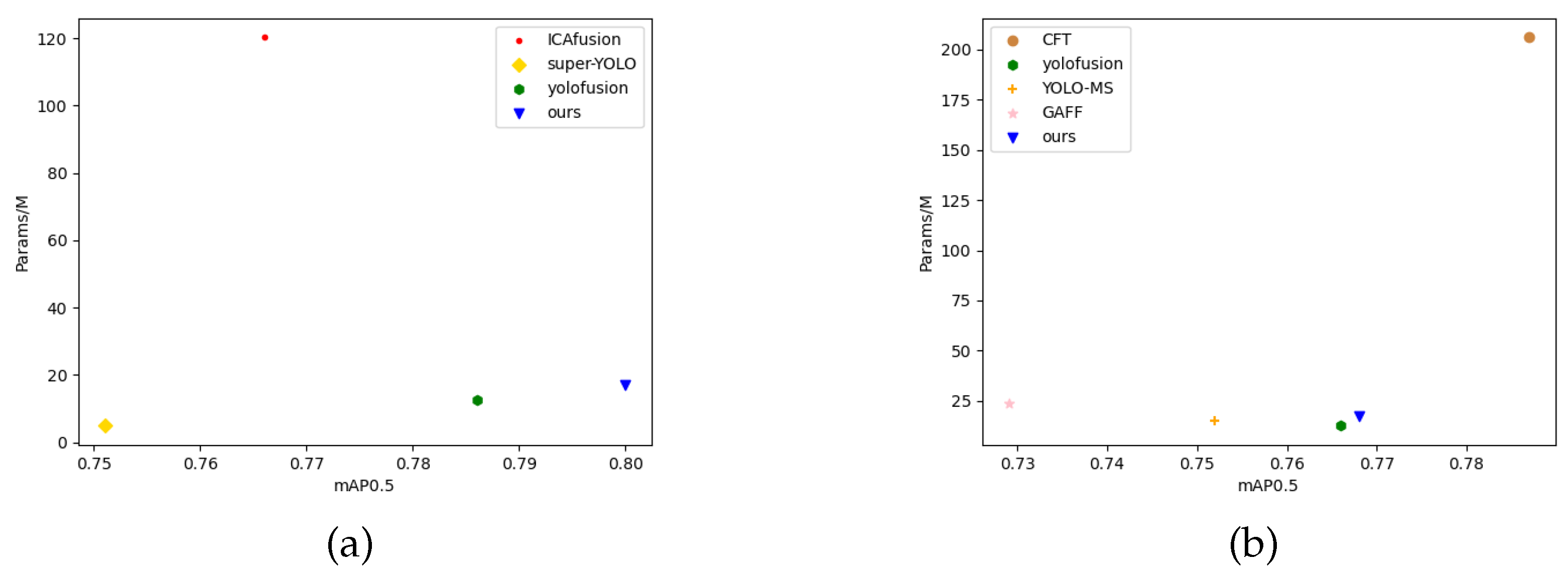
We carried out exhaustive ablation studies and comparative experiments on two public datasets, VEDAI and FLIR, to comprehensively validate the effectiveness of the proposed method. The results indicate that multi-modal feature fusion outperforms single-modal approaches, while the CSIFF module surpasses the existing fusion techniques, achieving a superior balance between parameter efficiency and detection accuracy. Meanwhile, the comparative evaluation results against other state-of-the-art multi-modal fusion detection networks further substantiate the effectiveness of MMYFNet.
The remaining chapters of this paper are organized as follows:
Section 2 introduces the MMYFNet architecture and the implementation details of the CSIFF module;
Section 3 validates the effectiveness of the CSIFF module through comparative experiments and visual analysis; The discussion is provided in
Section 4. In
Section 5, we conclude our paper.
4. Discussion
In complex environments, object detection faces multiple challenges such as illumination variations, occlusions, and severe weather conditions, where single-modality data struggles to comprehensively capture target features, leading to limited detection performance. To address this issue, researchers have introduced infrared and visible image fusion techniques, leveraging information complementarity to enhance detection accuracy. Early approaches focused on differences between modalities through differential methods, followed by the proposal of other feature interaction and fusion modules or networks. However, most of these methods concentrate on differential and local features, neglecting the value of common and long-range information.
Recently, the introduction of Transformers has significantly boosted the performance of fusion-based object detection networks, albeit accompanied by a sharp increase in model complexity. In response to the prevalent issues of high computational complexity and low information utilization in current methods, we propose the CSIFF module and the lightweight dual-branch feature fusion detection network MMYFNet. MMYFNet processes infrared and visible images in parallel through its dual-branch structure, while the CSIFF module significantly improves detection accuracy through feature partitioning, independent processing, and fusion.
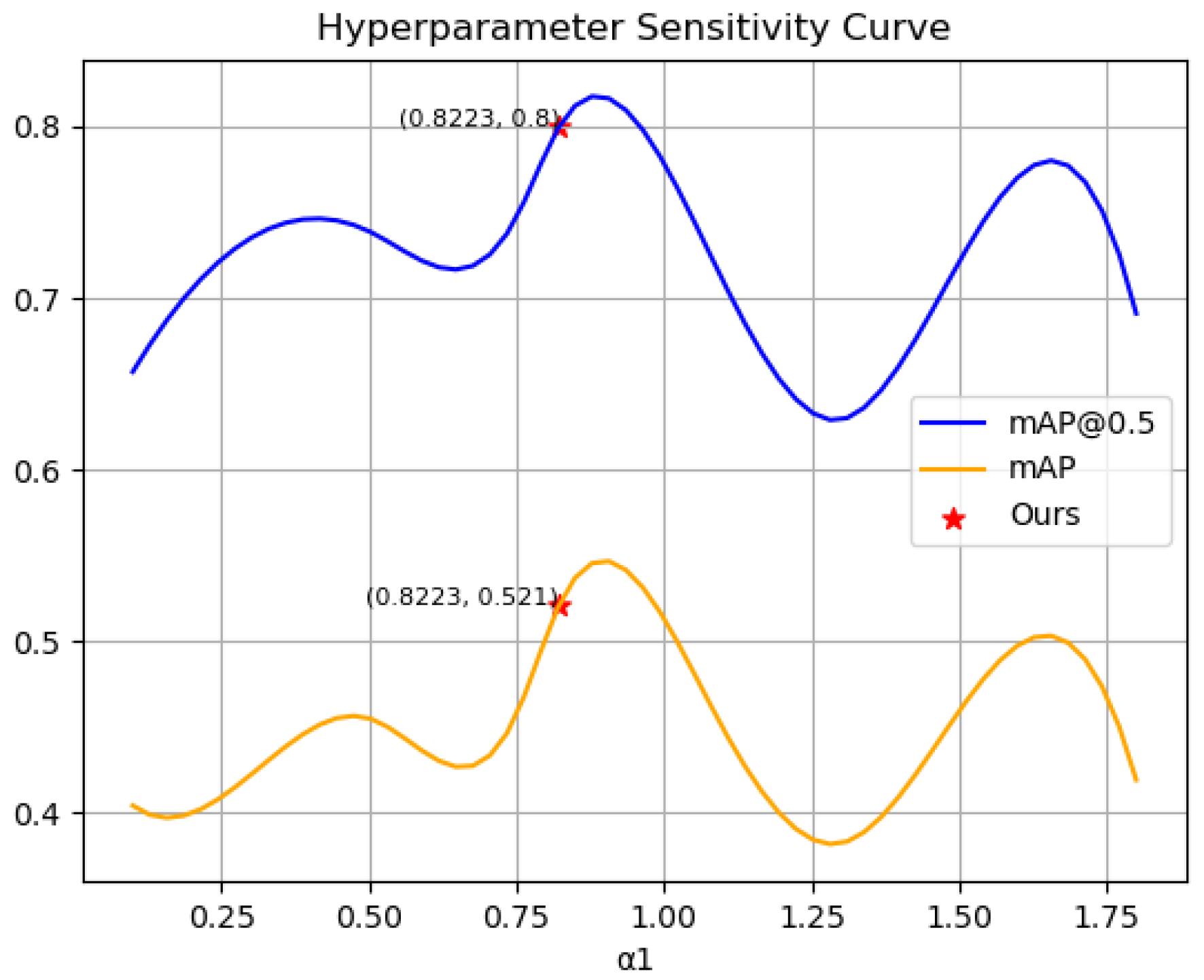
Experimental results demonstrate that MMYFNet surpasses single-modality and baseline models in detection accuracy, and the CSIFF module outperforms other fusion methods. Nevertheless, we also observe that while detection accuracy improves, the introduction of cosine similarity partitioning slightly reduces model computation speed, limiting its potential for real-time applications to some extent. Additionally, our research primarily relies on the VEDAI and FLIR datasets, and the generalization ability of our approach needs further validation on other datasets. Moreover, while our network achieves good detection accuracy in lightweight models, its performance does not yet match that of more complex models incorporating Transformers.
Future research can focus on algorithm optimization to reduce computational complexity while exploring more efficient fusion strategies to fully leverage the complementarity of multi-modal data. Furthermore, applying our method to real-time object detection systems and evaluating its stability and robustness across different scenarios represents a promising direction for exploration.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}