1. Introduction
Polarimetric synthetic aperture radar (PolSAR) has drawn significant attention because it can operate all day and night. A polarization scattering matrix can provide rich feature information that is widely used in land cover classification. In the field of PolSAR image classification, various unsupervised, semi-supervised, and supervised methods have been proposed. A large number of accurately labeled data are necessary in supervised classification methods. Unsupervised learning only uses the similarity relationships between samples to train models without labeled data. PolSAR images often do not have sufficient accurately labeled samples. The accurately labeled samples require significant manpower and time. Therefore, people are increasingly concerned about unsupervised methods.
Recently, many unsupervised methods have been proposed.The maximum likelihood classification [
1] has been widely used and developed. This method proposed a new distance metric derived based on the complex Wishart distribution [
2]. Pottier et al. [
3] proposed a method using
to initialize the iterative Wishart classifier. Cao et al. [
4] referred to this idea and used
to initialize the Wishart classifier. Lee et al. [
5] also proposed a robust classification method to maintain the uniform scattering mechanisms of various classes. Freeman decomposition [
6] and the Wishart classifier are combined in this method. In [
7], a new spectral clustering method was proposed based on the Wishart-derived distance metric to construct a similarity matrix. Additionally, spectral clustering was popular due to its excellent performance and its well-defined framework. Song et al. [
8] proposed a spectral clustering affinity matrix that was easy to process and saved memory, reducing the enormous computational resources required for clustering on large-sized PolSAR images. Yang et al. [
9] proposed that kernel fuzzy C-means achieved better clustering results for PolSAR images. In [
10], Yang et al. utilized the divergence of analytic information theory to construct an affinity matrix and proposed a kernel fuzzy similarity measurement method based on the membership distribution using the fuzzy C-means method. This method performed well in the spectral clustering of PolSAR images. However, traditional unsupervised clustering methods still suffer from the problem of category boundaries not matching the true distribution of the data.
Deep learning has been further developed. More and more unsupervised deep learning methods have been proposed in the field of PolSAR image classification. The deep cluster [
11] used k-means to calculate pseudo-labels and trained deep neural networks for supervision. Haeusser et al. [
12] proposed an associated deep clustering framework that did not use the clustering model with the feature maps extracted by the network. This framework directly utilized deep neural networks for clustering. Ji et al. [
13] proposed deep subspace clustering networks (DSCs) that combined deep learning with subspace clustering. Compared with traditional autoencoders, DSCs added a sub-representation layer for low-dimensional feature space. Song et al. [
14] introduced DSCs to generative adversarial networks (GANs) and proposed deep adversarial subspace clustering (DASC), which performed impressively on real-world data with complex subspaces. However, these deep learning methods have not yet effectively integrated traditional clustering techniques, and they have not implemented robust semantic filtering mechanisms to enhance classification accuracy. Feature post-processing and clustering mechanisms outside the network make these clustering methods more cumbersome [
15]. In [
15], invasive information clustering (IIC) was proposed, which involved slight modifications to the convolutional neural network (CNN) by maximizing the objective function with mutual information and building a two-headed CNN architecture. Unsupervised learning has great research value. A deep belief network (DBN) [
16] was applied to PolSAR image classification [
17]. The DBN is a classic deep learning probabilistic generative network composed of multiple stacked restricted Boltzmann machines (RBMs) [
18]. The superpixel segmentation algorithm was introduced to the autoencoder (AE) network to extract the neighborhood information of PolSAR images through the unsupervised learning of polarization features [
19]. Based on the AE, overcomplete sparse features were extracted from hidden layers, and a stacked sparse autoencoder (SSAE) network was proposed to improve the accuracy of unsupervised classification further [
20]. Then, the SSAE added adaptive non-local spatial information to obtain robust polarization features [
21]. These methods can effectively learn the deep features of polarimetric data. Bi et al. combined polarimetric image decomposition with deep convolutional networks within a principled framework, introducing a new unsupervised learning classification method [
22]. Wang et al. [
23] proposed a model known as rotation-domain deep mutual information (RDDMI) that operates on a convolutional long short-term memory (ConvLSTM) network. RDDMI combined the deep mutual information of IIC with deep comprehensive correlation mining (DCCM) [
24]. The performance of unsupervised PolSAR image classification has been elevated to a better level. Zuo et al. proposed deep similarity clustering (DSC). This newest model combined an unsupervised feature extraction pipeline with a Wishart distance metric and a deep clustering pipeline with a feature similarity metric. Moreover, the regularization combined two parts to maintain the clarity of edges and the semantic continuity of image content [
25]. The DSC has achieved very good unsupervised classification results. Deep learning has made significant progress in the field of unsupervised PolSAR image classification. The potential applications of the results generated through unsupervised learning deserve further exploration. Unsupervised learning, as a powerful tool, can help us identify potential structures and patterns in a dataset during the initial analysis stage. At present, few methods further analyze the results of unsupervised classification of PolSAR images. In the maps of the unsupervised classification of PolSAR images, there are a large number of high-confidence samples that have not been fully utilized. These high-confidence samples can be transformed into high-confidence pseudo-labels and effectively applied in supervised or semi-supervised learning frameworks to make the result of PolSAR image classification more accurate.
Semi-supervised learning can still demonstrate good performance with only a small number of labeled samples. Therefore, the pseudo-labels generated through unsupervised learning are particularly suitable for semi-supervised learning methods. The classic two-stage training paradigm is simple yet efficient in semi-supervised learning methods. For example, the residual network (ResNet) [
26], visual transformer (ViT) [
27], and Swin transformer (Swin-T) [
28] are typically pre-trained on large-scale datasets in a supervised manner, and then a small number of labeled samples are used to fine-tune the pre-trained model. Currently, pseudo-labeling [
29] and consistency regularization [
30] are used in the joint learning paradigm to label samples directly. MixMatch [
31] made full use of this idea to generate pseudo-labels by sharpening the average of multiple strongly augmented views. The MixUp trick was used in MixMatch to augment pseudo-labels [
32]. ReMixMatch [
33] introduced weakly augmented views to generate pseudo-labels and used an alignment strategy to encourage pseudo-labels to align with the edge distribution of labeled samples. Fixmatch [
34] adopted a simpler approach, as it retained the model but used only high-confidence pseudo-labels. It greatly simplified the idea of augmenting the anchoring in consistency regularization and produced better results. These methods used labeled samples to train semantic classifiers and treated the predicted results as pseudo-labels of unlabeled samples. However, models often fit overconfident but incorrect pseudo-labels, leading to inaccurate results when simply using pseudo-labels. To solve this problem, similarity matching (SimMatch) [
35] optimizes the process of generating pseudo-labels in Fixmatch, taking both semantic and instance similarity into account. SimMatch guided the better propagation of the two similarities by a memory buffer. SimMatch achieved outstanding performance in semi-supervised classification. The smooth integration of the high-confidence samples contained in unsupervised learning classifications into semi-supervised learning frameworks deserves further study. Benefiting from the excellent performance of semi-supervised learning methods, the performance of unsupervised classification can be further improved. The high-confidence samples from unsupervised classification maps of PolSAR images, naturally, can be used as pseudo-labels. By utilizing the advantages of both high-confidence pseudo-labels and advanced semi-supervised classification algorithms, unsupervised PolSAR image classification performance can be further improved.
This study proposes a high-confidence unsupervised pseudo-label learning classification framework for PolSAR images based on representative points of superpixels. The framework segments a PolSAR image through simple linear iterative clustering (SLIC) [
36] and extracts the geometric centers of the superpixels as representative points. Then, the generated maps of an advanced unsupervised classification method, RDDMI, are combined with the representative points as high-confidence pseudo-labels. Finally, the pseudo-labels with high confidence are used as supervision for the excellent semi-supervised algorithm SimMatch to train and obtain the final classification results.
The following are the main contributions of this study: (1) This study proposes a novel unsupervised PolSAR image classification framework called superpixel pseudo-label similarity matching (SP-SIM) based on the extraction of high-confidence pseudo-labels through superpixels. (2) This study utilizes classification maps from an advanced unsupervised classification algorithm, RDDMI, as pseudo-labels. Superpixels are used as the basic processing unit to obtain pseudo-labels with high confidence quickly. (3) This study introduces the semi-supervised algorithm SimMatch, which has excellent performance. In this framework, semantic and instance pseudo-labels can propagate to each other and achieve more intrinsic feature matching. It also uses high-confidence pseudo-labels as supervision for learning, making full use of the feature information of pseudo-labels. The high-confidence pseudo-labels with SimMatch obtain excellent classification results.
The results were extensively evaluated through experiments on three real PolSAR images and compared with those of other advanced unsupervised classification algorithms for PolSAR images. The accuracy reached the optimal level, verifying the effectiveness and superiority of SP-SIM.
2. Methods
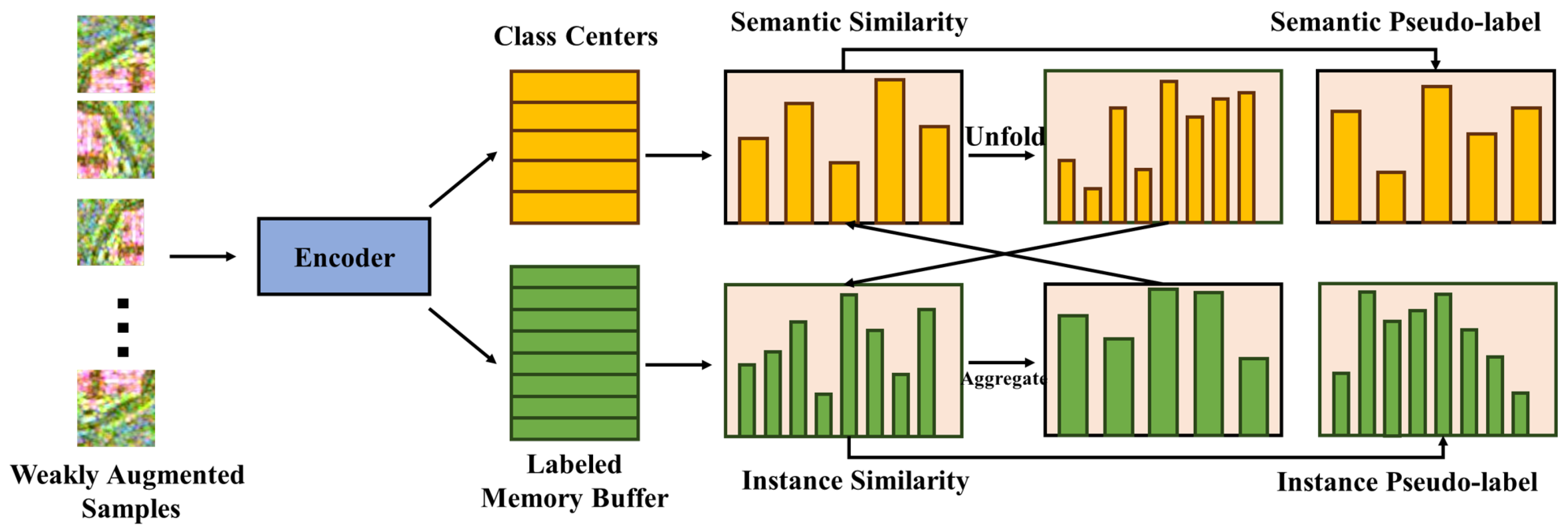
Figure 1 illustrates the five parts of the proposed framework. The first part shows the steps in the generation of representative points of superpixels. The second part shows the preliminary generation of maps by the unsupervised learning algorithm RDDMI. The third part shows how to use representative points of superpixels to improve the confidence of the maps. The three parts mentioned above constitute the method of how high-confidence pseudo-labels are generated. The fourth part is the semi-supervised algorithm SimMatch. SimMatch uses high-confidence pseudo-labels as supervision to generate pseudo-labels from unlabeled samples. Two types of losses are calculated. The fifth part is a typical use of high-confidence pseudo-labels as supervision to generate supervised predictions. In this part, the pseudo-labels and features are also stored in the memory buffer of the fourth part.
The first part presents the selection of representative points of superpixels using SLIC. The pixels in a PolSAR Pauli pseudo-color image are grouped according to the similarity of their color, brightness, and other characteristics. The generated superpixels are compact and neat like cells, and the neighborhood features are relatively easy to express. SLIC outperforms other superpixel segmentation methods in terms of contour preservation, running speed, and the compactness of the generated superpixels.
In the second part, the unsupervised learning algorithm RDDMI is used to generate preliminary pseudo-label maps. For each pixel in the PolSAR image, paired data x and are used as inputs for deep mutual information learning. The RDDMI generates preliminary unsupervised classification maps for the creation of pseudo-labels.
In the third part, this study refers to the contour of each superpixel to find its approximate maximum inscribed rectangle and geometric center. The shape of a single superpixel contour may be irregular, resulting in the inscribed rectangle being too small and the central representative point being inaccurate. Therefore, a certain number of contour pixels are allowed to exist in the inscribed rectangle in this process. The points corresponding to the central representative points in the maps generated by RDDMI are selected as pseudo-labels with high confidence.
In the fourth part, high-confidence pseudo-labels are used as supervision through the excellent semi-supervised algorithm SimMatch. SimMatch first uses weakly augmented views to generate semantic and instance pseudo-labels and calculates their similarity through the class center and label embedding. Then, these two similarities are fused through expansion and aggregation operations. The strongly augmented view is used to generate predictions and feature similarities. The semantic pseudo-labels and instance pseudo-labels have instance pseudo-labels and semantic pseudo-labels, respectively. Finally, the unsupervised loss and input loss are calculated by the predictions and similarities.
The fifth part is the process of calculating the supervision loss. The high-confidence pseudo-labels mentioned above are used as supervision. “Labels” and feature embeddings of high-confidence pseudo-label samples are stored in a labeled memory buffer.
Figure 1 shows the entire process of the algorithm proposed in this paper. First, RDDMI unsupervised learning classification is used to obtain primary pseudo-labels that contain pseudo-supervision information. Second, the PolSAR image is segmented by SLIC, and the geometric centers of the approximate maximum inscribed rectangles of superpixels are calculated. The centers are combined with the primary pseudo-label to extract high-confidence pseudo-labels. Third, the pseudo-labels are used for classification tasks through the semi-supervised algorithm SimMatch. In SimMatch, the memory buffer stores the features obtained from high-confidence pseudo-labels and performs similarity matching with the prediction results of unlabeled data to obtain more accurate results. Finally, SimMatch uses supervised loss
, unsupervised loss
, and consistency regularization loss
to jointly form the overall loss function. The generalization ability and the performance of the model are guaranteed.
2.1. Method of Obtaining Pseudo-Labels
The method of obtaining pseudo-labels mainly includes three parts: (1) Using the RDDMI algorithm to generate pseudo-labels with low confidence; (2) using the SLIC algorithm to segment PolSAR images and calculate the representative points of each superpixel; (3) combining representative points of superpixels with low-confidence maps to extract high-confidence pseudo-labels.
2.1.1. RDDMI
The RDDMI algorithm represents a significant advancement in the realm of unsupervised learning for PolSAR image classification. In RDDMI, an end-to-end convolutional long short-term memory (ConvLSTM) network was used. The data processing workflow is simplified. The deep mutual information associated with various polarization directions (POAs) in the rotation domain of the polarization coherence matrix is effectively learned. RDDMI has good classification accuracy and rapid processing capabilities, allowing for the swift generation of accurate pseudo-labels for subsequent analysis. ConvLSTM has taken the place of LSTM’s [
38] fully connected gate layers with convolutional layers, enabling it to process sequence data with spatial information.
The architecture of the RDDMI network initiates with two ConvLSTM layers to extract rotational-domain features from the inputs. Next, three convolutional layers, three max-pooling layers, and two fully connected layers are applied to further refine and learn deep features. The network culminates in a softmax layer to output a one-hot vector, with the argmax function being employed to calculate the class of the sample [
23].
As shown in Equation (
1), the loss function includes pseudo-label loss, pseudo-graph loss, and two mutual losses based on the predicted features of
x and
information losses. RDDMI first introduces pseudo-label supervised loss, pseudo-graph supervised loss, and triple mutual information loss into DCCM [
23]. The similarity matrix between samples is calculated using the predictive properties of the network. The shallow features output by the first max-pooling layer and the deep features output by the second fully connected layer are used to calculate the mutual loss of triples.
2.1.2. Representative Points of Superpixels
Superpixels are a group of pixels that are combined based on similar colors or low-level features. In the unsupervised classification of PolSAR images, there are common phenomena of blurred boundaries and inaccurate boundary classifications. This will affect the overall classification accuracy and lead to low overall confidence in pseudo-labels. Reference superpixel segmentation overcomes speckle noise by extracting color features. The PolSAR image is divided into several superpixels with similar color features using superpixel segmentation. The geometric center point of each superpixel is used as an accurate and representative pseudo-label point. This approach abandons a large amount of boundary information that is highly likely to be erroneous, increasing the confidence of pseudo-labels. Therefore, there is an urgent need for an accurate and fast superpixel segmentation method. In existing methods, the superpixels generated by SLIC have precise boundary adhesion and uniform regularity. SLIC requires very few parameters to be set, and by default, only the number of pre-segmented superpixels needs to be set. Therefore, this study uses SLIC to quickly segment PolSAR images into many superpixels. Then, the approximate maximum inscribed rectangle of each superpixel is calculated. This rectangle allows an appropriate number of pixels on the superpixel outline inside the rectangle to ensure that it is centered, and the largest rectangle is calculated. At this point, the center point of the rectangle can also be considered as the center point of the superpixel, which is representative. Finally, the representative points are combined with the maps generated by the RDDMI mentioned above to form a high-confidence pseudo-label.
2.2. Framework of SimMatch Semi-Supervised Learning
The extracted pseudo-labels have high confidence, but the quantity is limited. The situation at this point is similar to semi-supervised learning. A small amount of labels are used in semi-supervised learning, so a semi-supervised learning algorithm is needed to complete the remaining processing work. In [
39], SimMatch was used to detect changes in PolSAR images, and the effect was significant. SimMatch is a suitable semi-supervised image classification algorithm with good performance under limited label conditions. This is a way to propagate pseudo-labels’ information to each other, and it uses the label memory buffer to achieve the isomorphic transformation of two types of similarity. SimMatch solves the problems of model overfitting and improves the reliability of the model. SimMatch effectively utilizes the idea of combining consistency regularization with pseudo-labels in FixMatch [
34]. This section will first review consistency regularization and pseudo-labels and then introduce the innovation of SimMatch, which allows pseudo-label information to mutually propagate.
Firstly, the image classification problem can be defined as there being a set of labeled samples and unlabeled samples , where is the label of sample . Data augmentation is often used to improve the generalization ability of models. The weakly augmented function and strongly augmented function are defined as and .
2.2.1. Two Methods in Semi-Supervision
Consistency regularization is frequently used in semi-supervised learning. Consistency regularization was first proposed in [
40], and it requires ensuring that the same image still has similar prediction results under different perturbations. In the models in [
41], the loss function is used for unlabeled samples as follows:
Here, is the predicted classification result of input x, and both and are random. SimMatch uses cross-entropy loss instead of square loss.
Pseudo-labeling is also commonly used in semi-supervised learning. Pseudo-labels are obtained from the model itself. Specifically, during supervised training, the prediction with a maximum class probability higher than the threshold
is retained. This prediction is used as the pseudo-label of the unlabeled sample. It can be expressed by the following loss function:
where
. FixMatch applies
to the prediction to generate an effective one-hot prediction. Differently, in SimMatch, a distribution alignment strategy
[
33] is adopted to balance the distribution of pseudo-labels, and
is directly used as the pseudo-label to calculate the cross-entropy between the strongly augmented sample predictions
:
2.2.2. Instance Similarity
SimMatch encourages the similarity distributions of strongly and weakly augmented views to align closely. A nonlinear head
representing
h maps to a feature embedding
is assumed. The augmented anchoring and the embeddings can be denoted by
(the weakly augmented views) and
(the strongly augmented views), respectively. For the
embeddings of various weakly augmented samples
, the similarity with
and the
-th instance are calculated by a similarity function
. This is represented by the dot product between
and the normalized vector
. Then, the generated similarity is processed through a softmax layer. In the generated similarity distribution,
is used as a temperature parameter to adjust the sharpness of the distribution:
The sim
is used to calculate the similarity between strongly augmented views
and
to obtain the similarity distribution:
2.2.3. Label Information Dissemination
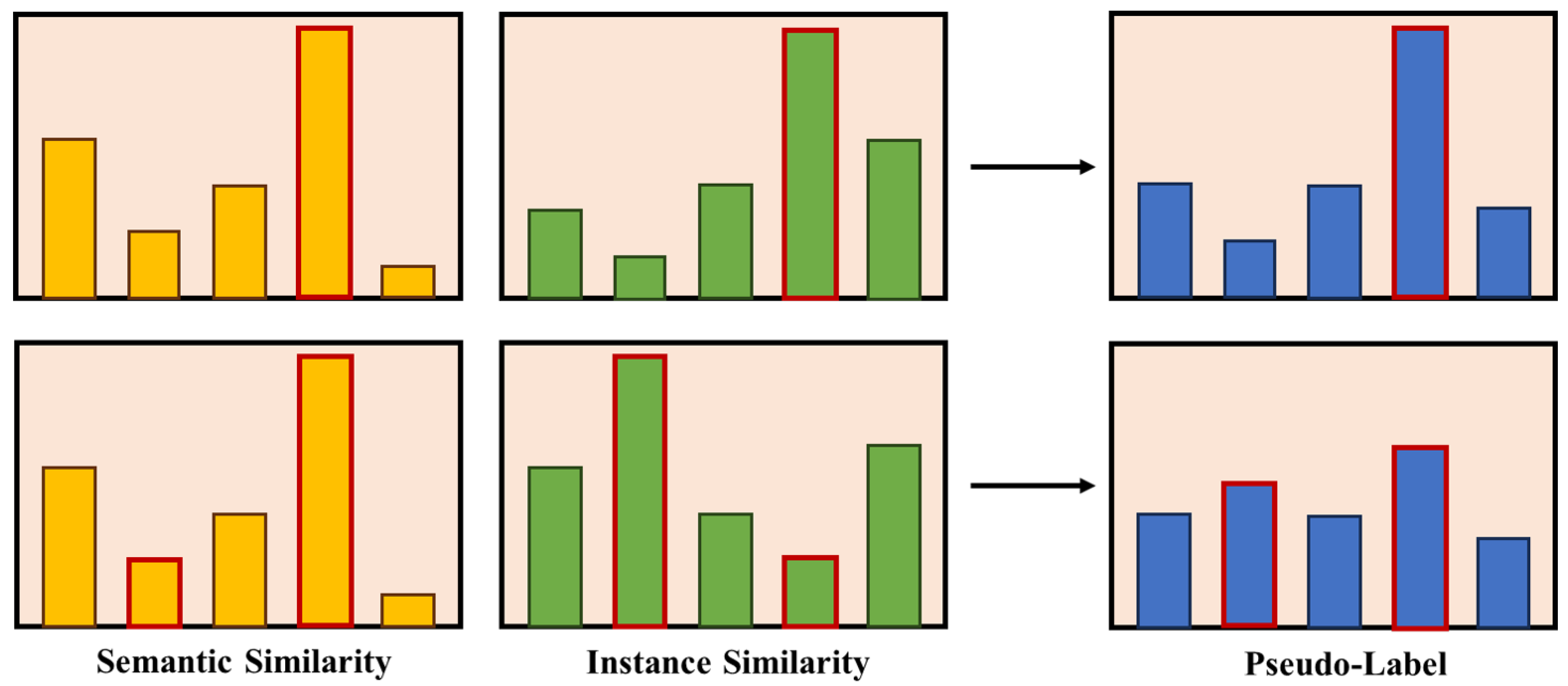
The SimMatch framework also considers instance-level consistency regularization. The use of entirely unsupervised instance pseudo-labels, denoted as
, leads to a considerable waste of label information. To address this issue, SimMatch utilizes labeled information at the instance level. The interaction between semantic and instance similarity is enhanced, thereby improving the result of the generated pseudo-labels. The labeled memory buffer saves all labeled samples, as shown in
Figure 2. Each
in Equations (
5) and (
6) can be associated with a specific class. The vectors in
are regarded as center class references when the labeled samples stored in the memory buffer can be viewed as the same class.
is semantic similarity and
is instance similarity. Both of them are computed by using weakly augmented samples. It should be noted that the value of
L is typically much smaller than that of
K because each class requires at least one sample. Subsequently,
is calibrated by expanding
(referred to as
). Aligning the semantic similarities embedded within labels leads to the following results:
In Equation (
7),
can return the basic truth class. The
indicates the label of the
jth element in the memory buffer and represents the
ith class. Then, the calibrated instance pseudo-labels are regenerated by scaling
through
and can be expressed as
The old labels
will be updated to the pseudo-labels
of the instance. At the same time,
q will be aggregated into an L-dimensional space. The instance similarity is combined with the semantic similarity, represented as
. Then, the instance similarity is summed to achieve the sharing of the same ground-truth labels:
The semantic pseudo-labels will be updated by using
to smooth
:
In Equation (
10),
is the hyperparameter that controls the instance information and semantic weight. The pseudo-label
p will contain semantic-level information and
q will contain instance-level information. Similarly, the old value,
, will be replaced with the adjusted semantic pseudo-label. If the two are not close, the histogram will be flatter. As shown in
Figure 3, if these two similarities are very close, it means that the predictions of the two similarities’ distributions are consistent, and the histogram will be sharp.
2.2.4. Memory Buffer
SimMatch stores ground-truth labels and feature embeddings of labeled samples in a memory buffer. Specifically, it delineates a label memory buffer, denoted as
, and a feature memory buffer, referred to as
, where
D represents the embedding size and
N represents the amounts of labeled samples. For the label memory buffer, each label only stores one scalar. Aggregation and unfolding operations are implemented through functions provided by a deep learning library [
35]. Given the variance in buffer sizes, SimMatch employs two distinct implementations. When
N is large, the memory buffer is represented as
and
using the student–teacher framework [
42]. The labeled samples and strongly augmented samples are directed to
, while weakly augmented samples are input into
to generate pseudo-labels. The updating process for
is as follows:
When
N is small, a time integration strategy [
43] is used to smooth the feature embeddings, and this can be defined as
In this case, the same encoder will receive all samples.
2.3. Loss
In SimMatch, the feature information
of weakly augmented labeled samples
is extracted by encoder
of the convolutional neural network. The fully connected prediction head
is used to calculate the semantic similarity
and the supervised classification loss as follows:
Applying the weakly augmented function
and the strongly augmented function
to unlabeled samples to obtain weakly augmented samples
and strongly augmented samples
,
is a distribution alignment method used to balance the distribution of pseudo-labels [
33]. Then, it is necessary to keep the moving average of
constant and use
to adjust the current
[
44].
is used directly as pseudo-labels. The cross-entropy between
(pseudo-label) and
(semantic-similarity) is used to define unsupervised loss:
By minimizing the difference between
and
, consistency regularization can be achieved, and this is represented by the cross-entropy as
The overall loss function of SimMatch is:
3. Experiment
To validate the feasibility of the proposed method, multiple comparative experiments were conducted on three PolSAR datasets. Four PolSAR image classification methods, which were the classic unsupervised method, the Wishart cluster, the deep learning-based method RDDMI, and the traditional supervised random forest (RF) method, were used to compare with the proposed method. The supervised training of Random Forest (RF) uses 25,000 randomly selected labeled samples for each PolSAR datum. During this process, the input data are 15 × 15 neighborhood window data, which is the same size as the neighborhood window used in the proposed method. At the same time, the same normalization method is used for data processing to ensure data consistency.
The experimental results were evaluated using the overall accuracy (OA), kappa, precision, recall, and F1 score.
The proportion of overall correct predictions is calculated by OA. The kappa was used for unbalanced samples. The precision reflects the proportion of samples belonging to a certain class among the samples predicted as that class by the model. Recall is defined as the proportion of samples that are correctly identified by the model as belonging to a certain class. The F1 score is used to comprehensively measure the precision and recall of the model.
3.1. Datasets
This section introduces three real PolSAR image data. The data details are shown in the
Table 1.
3.1.1. RADARSAT-2 Flevoland Dataset
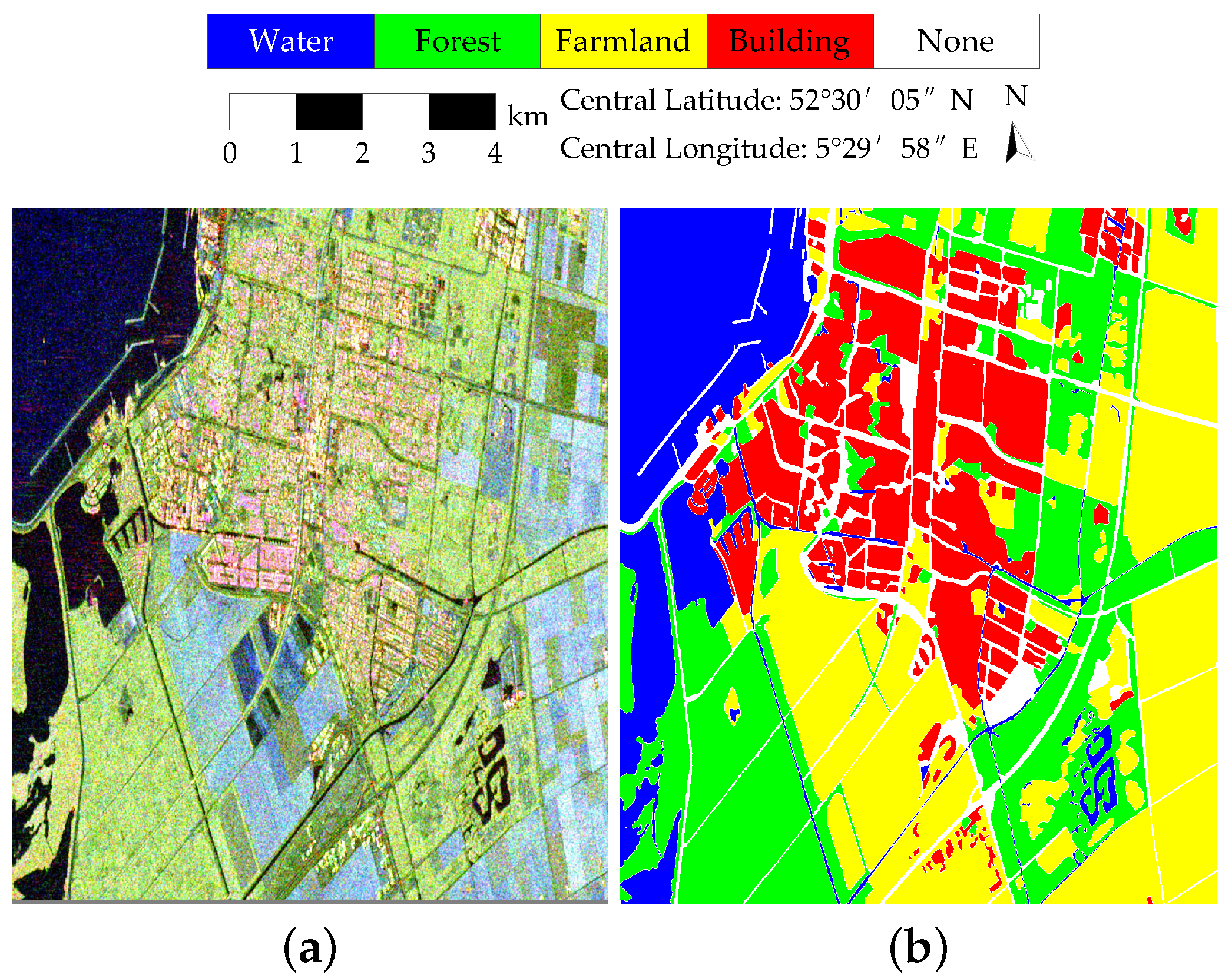
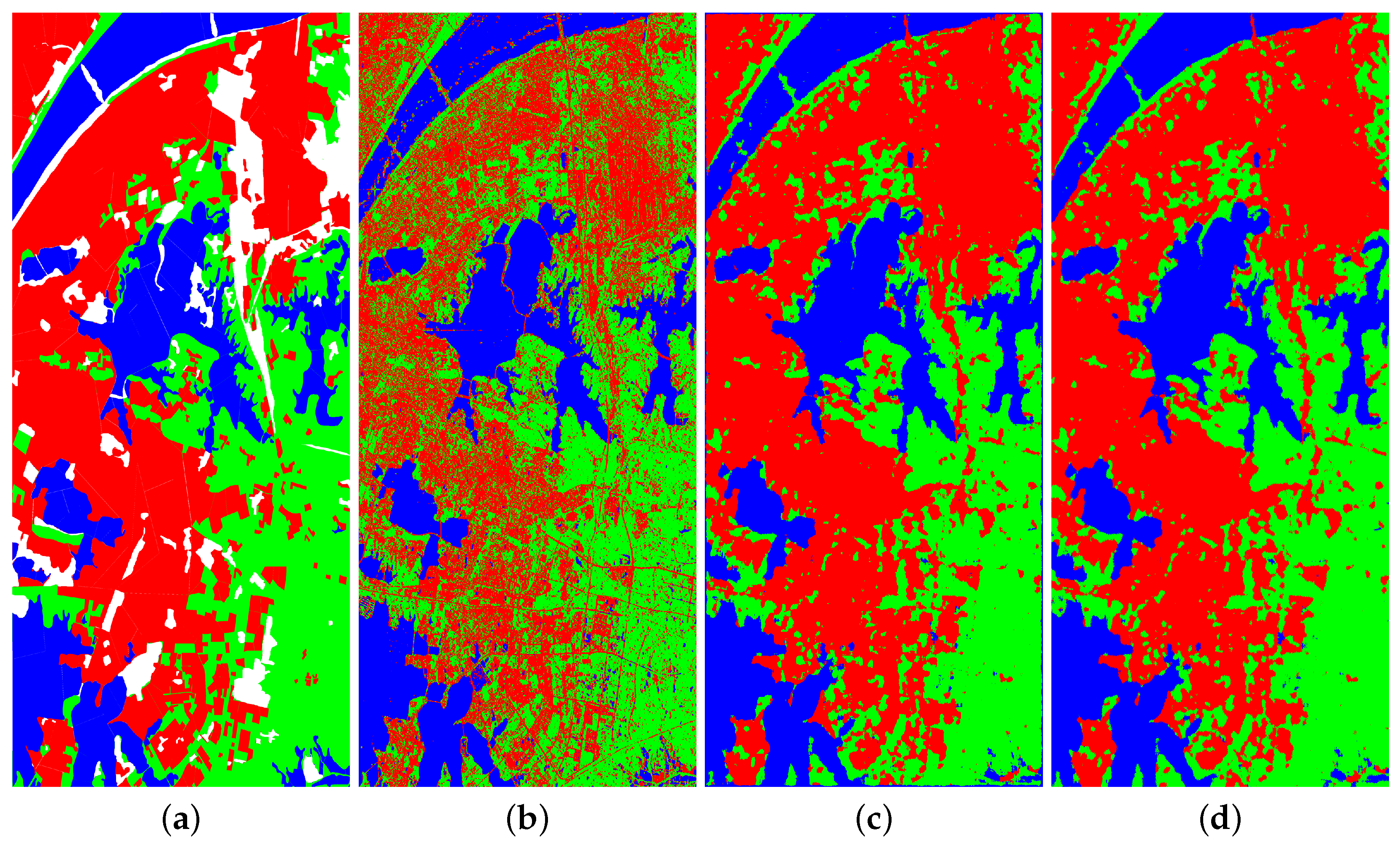
In the field of PolSAR image classification, the RADARSAT-2 (RS-2) Flevoland dataset is widely used. This dataset has an image size of 1400 × 1200 pixels and a spatial resolution of 12 × 8 m. It covers the Flevoland region of the Netherlands and has four land cover categories: farmland, water, forests, and buildings. The Pauli pseudo-color image and the corresponding ground-truth map of the RS-2 Flevoland dataset are shown in
Figure 4.
3.1.2. RADARSAT-2 Wuhan Dataset
The RS-2 Wuhan dataset covers the scene of Wuhan and was obtained using the RADARSAT-2 C-band PolSAR system in the fine quad-pol mode. The image size is 5500 × 2400 pixels. The spatial resolution is 12 × 8 m. It contains three land cover categories: water, forest, and buildings. This dataset has highly dense buildings with different orientations, which increases the difficulty of clustering. The Pauli pseudo-color image and the corresponding ground-truth map of the RS-2 Wuhan dataset are shown in
Figure 5.
3.1.3. AIRSAR Flevoland Dataset
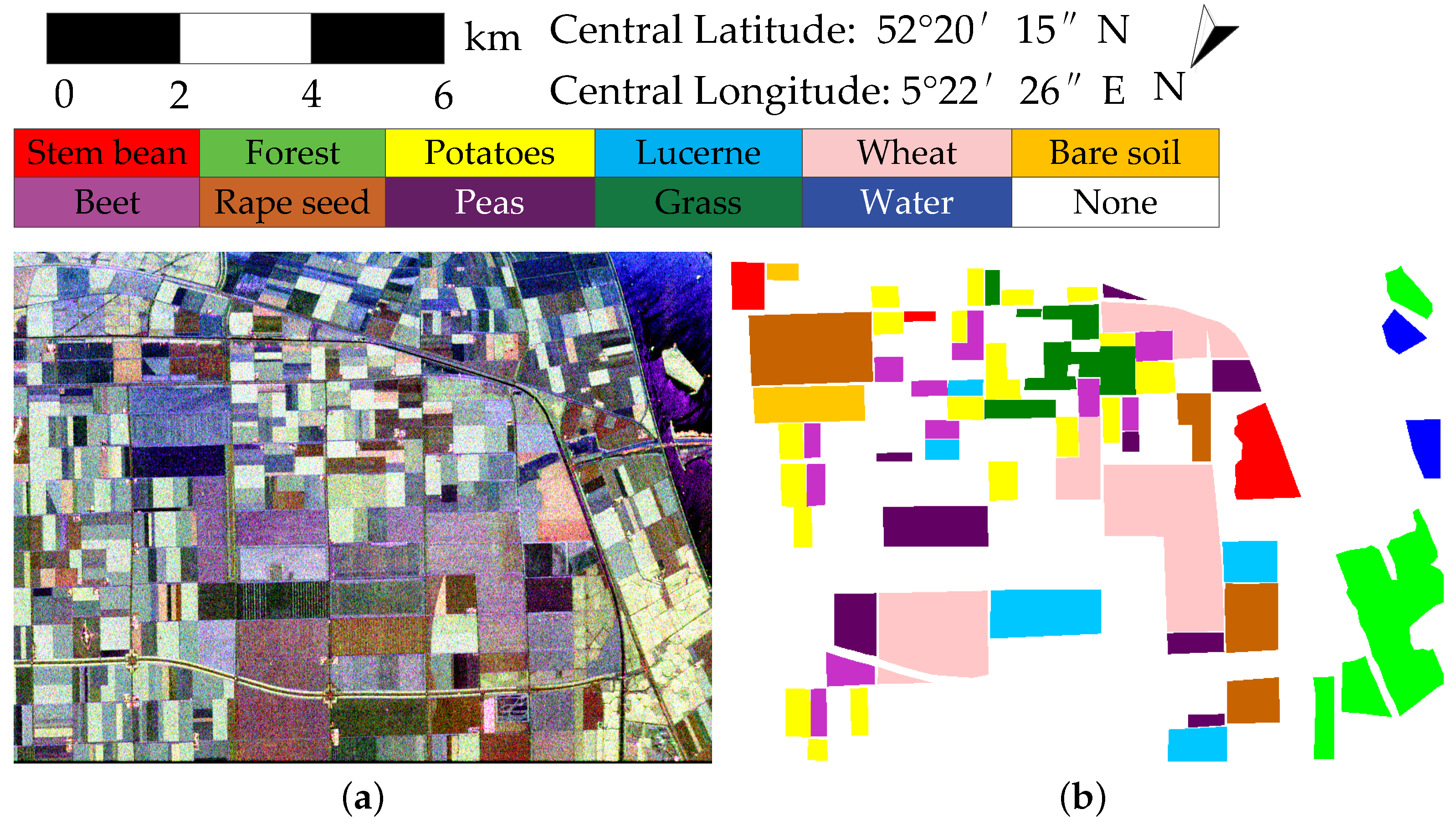
The AIRSAR Flevoland dataset contains four-look fully polarimetric images and was acquired by the NASA/JPL AIRSAR L-band system. This dataset also covers the scene of Flevoland, the Netherlands. The image size is 750 × 1024 pixels. The spatial resolution is 6 × 12 m. It contains 11 types of land cover, including forests, wheat, and 9 other types. The Pauli pseudo-color image and the corresponding ground-truth map of the AIRSAR Flevoland dataset are shown in
Figure 6.
3.2. Results
3.2.1. Results on the RS-2 Flevoland Dataset
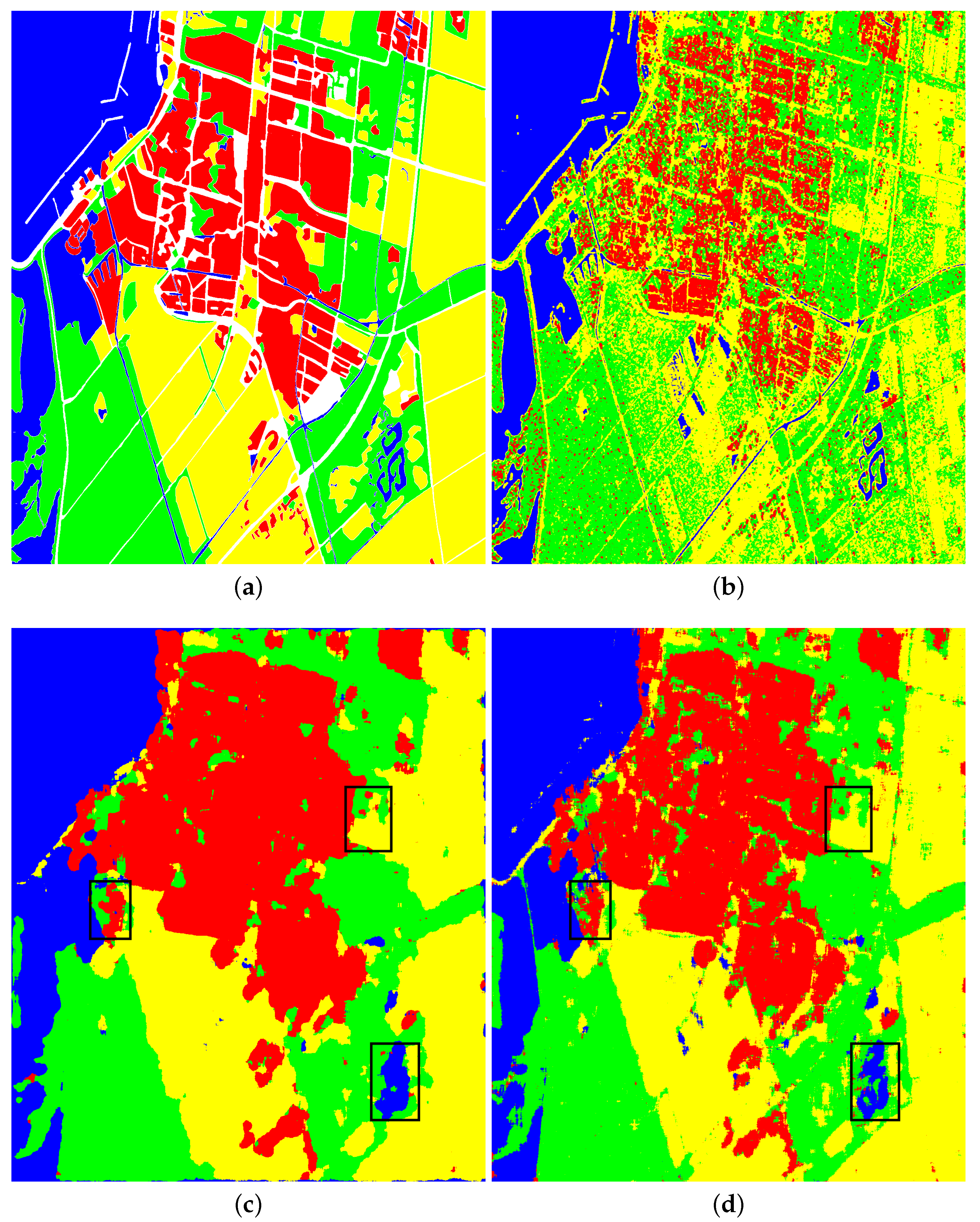
The classification results on the RS-2 Flevoland dataset are shown in
Figure 7 and
Table 2. The RS-2 Flevoland dataset contains forest and farmland types embedded in building types, and farmland types have different backscattering properties, which poses difficulties for accurate classification. Wishart performed poorly on this dataset, and a large number of buildings and farmlands were identified as forests. RDDMI showed great classification performance and improved the OA to 87.86%. However, the pixels on the boundaries were not precisely classified. The proposed SP-SIM was superior to the above methods. In particular, the boundary pixels were finely classified, as shown in the black boxes in
Figure 7c,d. The building and water types were all well classified. The boundaries of farmlands were also much better than those of RDDMI. Compared with RDDMI, the accuracies of the proposed method for water, forest, and farmland were increased by 0.61%, 4.17%, and 2.62%, respectively. Finally, the OA of the SP-SIM increased by 1.70%. Meanwhile, the OA of the SP-SIM was 1.46% higher than that of supervised RF. Moreover, the precision, recall, and F1 score are all higher than those of other methods, including RF. The above analysis demonstrates the obvious performance improvement and proves that the proposed framework is efficient for unsupervised PolSAR image classification.
3.2.2. Results on the RS-2 Wuhan Dataset
In the RS-2 Wuhan dataset, there is a large number of buildings with different orientations, which exhibit different features in PolSAR images. It is difficult to accurately distinguish building types through unsupervised methods.
Figure 8 shows the classification maps, and
Table 3 displays the quantitative results. RDDMI achieved very good results on this dataset, with impressive accuracy in identifying buildings. The results of the traditional Wishart cluster were not good. The OA of SP-SIM was 0.99% higher than that of RDDMI and close to that of the supervised RF method. The accuracies for all land cover types were better than those of RDDMI. The precision, recall and F1 score are all higher than those of the other methods. The experiment demonstrated the effectiveness of the proposed method on PolSAR images.
3.2.3. Results on the AIRSAR Flevoland Dataset
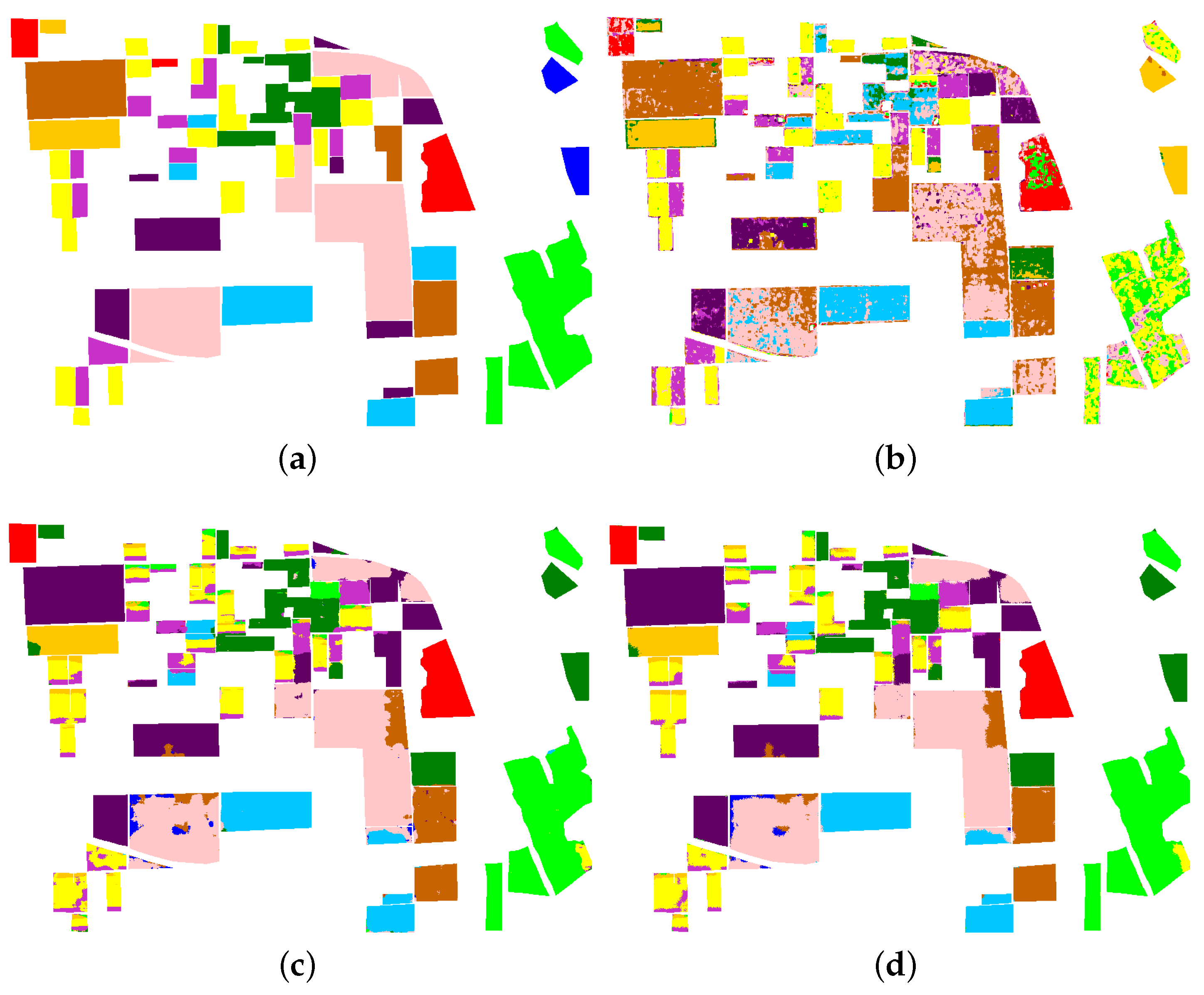
The AIRSAR Flevoland dataset has up to 11 categories, and the polarization properties of each category are also very complicated, which is undoubtedly a huge challenge for unsupervised classification. The backscattering properties of some land cover types have similarities in this dataset. In addition, there may be large differences in the polarization matrices observed for the same land cover type. As shown in
Figure 9, the properties of water are similar to those of other categories, which will greatly affect the classification performance. The RF method can overcome these interpretation ambiguity problems to a certain extent by supervising the information. However, the unsupervised method makes it difficult to overcome this problem of interpretation ambiguity without supervised information, so the classification performance is poor. Moreover, this dataset contains many unlabeled areas; we only used labeled areas to evaluate the results.
In
Figure 10 and
Table 4, it can be seen that Wishart could not make accurate judgments on categories with similar polarization characteristics, and RDDMI achieved better results. All methods cannot accurately classify water. This is because the backscattering properties of water are similar to those of other categories. The proposed method had a certain improvement based on RDDMI, and the OA was increased by 0.80%. Other indicators also reached an excellent level. The experiment showed that although the proposed framework was able to improve the unsupervised PolSAR classification performance, it also had its limitations. The maps of RDDMI will affect the performance of the proposed method. If the results of RDDMI are poor, the performance of the proposed method will be limited.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}