

Research on Radar Target Detection Based on the Electromagnetic Scattering Imaging Algorithm and the YOLO Network


Abstract
1. Introduction
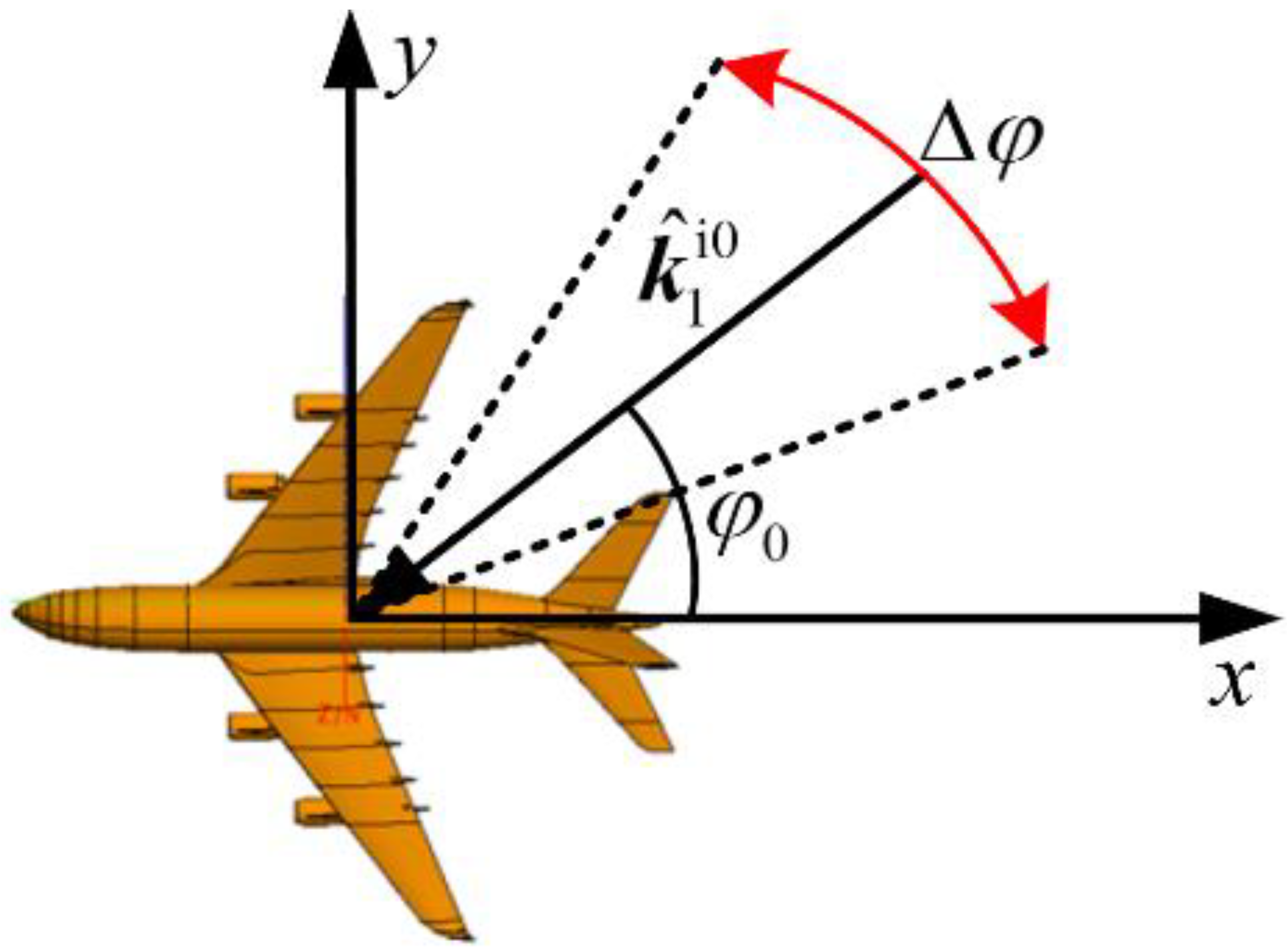
2. Description of the Radar Imaging Method
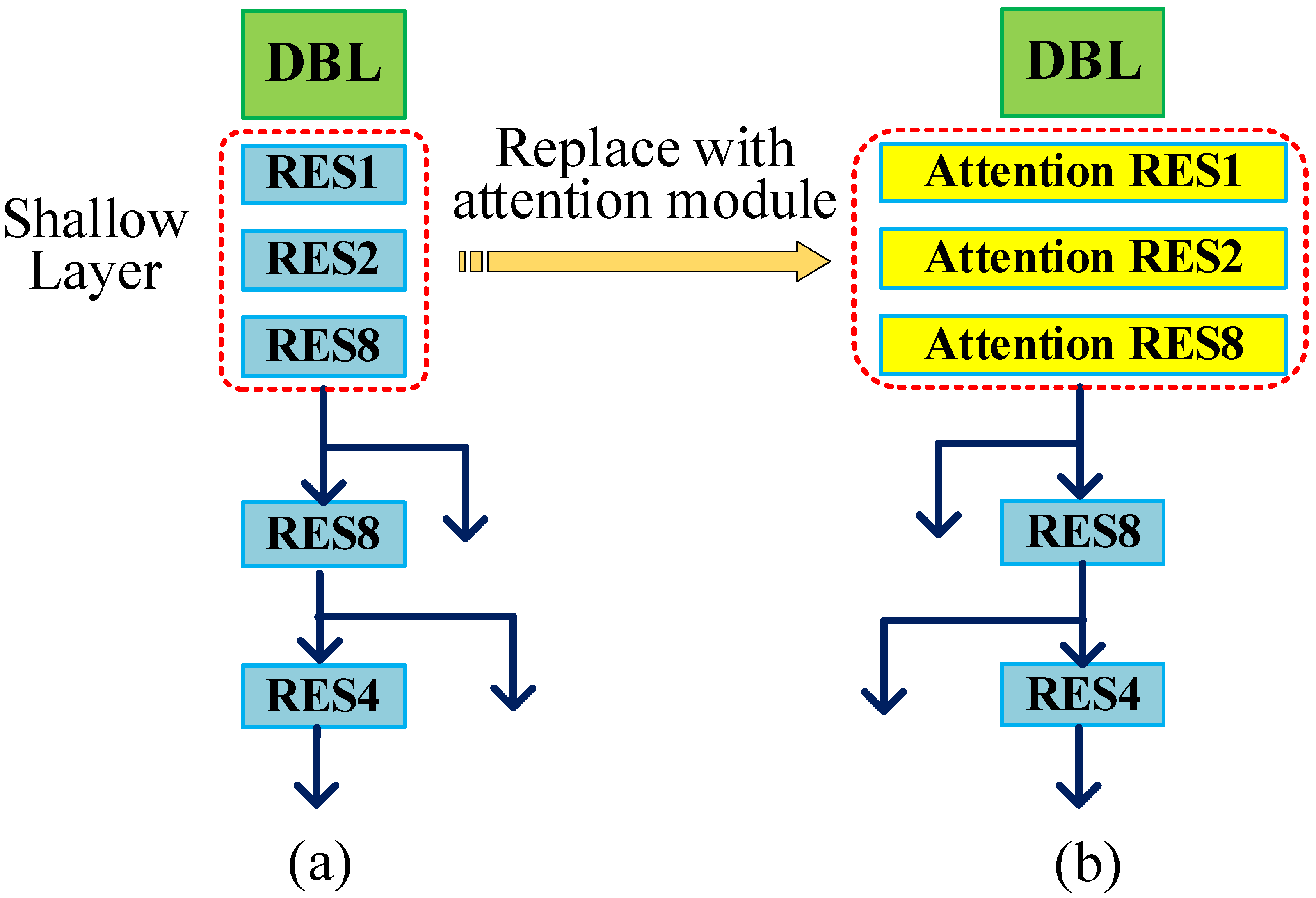
3. Improvement in the YOLOv3 Network
4. Experiments and Analysis
4.1. Accuracy Verification of Imaging Algorithm
4.2. Evaluation of Detection Performance on Simulated Datasets
4.3. Evaluation of Detection Performance on Real Datasets
4.4. Evaluation of Detection Performance on Mixes Datasets
4.5. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Acronym | Full Name |
| TD | time domain |
| YOLO | You Only Look Once |
| ISAR | inverse synthetic aperture radar |
| CNNs | convolutional neural networks |
| SSD | single-shot multi-box detector |
| SE | squeeze-and-excitation |
| CB | convolutional block |
| GO | geometrical optics |
| PO | physical optics |
| FD | frequency domain |
| BN | batch normalization |
| RES | residual |
| FPN | feature pyramid networks |
| MLP | Multilayer Perceptron |
| AP | average precision |
| IoU | Intersection over Union |
| mAP | mean average precision |
| MSTAR | Moving and Stationary Target Acquisition and Recognition |
References
- Lee, S.J.; Lee, M.J.; Kim, K.T.; Bae, J.H. Classification of ISAR Images Using Variable Cross-Range Resolutions. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2291–2303. [Google Scholar] [CrossRef]
- Xue, B.; Tong, N.; Xu, X. DIOD: Fast, Semi-Supervised Deep ISAR Object Detection. IEEE Sens. J. 2019, 19, 1073–1081. [Google Scholar] [CrossRef]
- Guo, G.; Guo, L.; Wang, R. ISAR Image Algorithm Using Time-Domain Scattering Echo Simulated by TDPO Method. IEEE Antennas Wirel. Propag. Lett. 2020, 19, 1331–1335. [Google Scholar] [CrossRef]
- Guo, G.; Guo, L.; Wang, R.; Liu, W.; Li, L. Transient Scattering Echo Simulation and ISAR Imaging for a Composite Target-Ocean Scene Based on the TDSBR Method. Remote Sens. 2022, 14, 1183. [Google Scholar] [CrossRef]
- Xie, P.; Zhang, L.; Du, C.; Wang, X.; Zhong, W. Space Target Attitude Estimation from ISAR Image Sequences with Key Point Extraction Network. IEEE Signal Proc. Let. 2021, 28, 1041–1045. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Y.; Ding, W. A Fast Recognition Method for Space Targets in ISAR Images Based on Local and Global Structural Fusion Features with Lower Dimensions. Int. J. Aerospace Eng. 2020, 2020, 3412582. [Google Scholar] [CrossRef]
- Vatsavayi, V.K.; Kondaveeti, H.K. Efficient ISAR image classification using MECSM representation. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 356–372. [Google Scholar] [CrossRef]
- Pastina, D.; Spina, C. Multi-feature based automatic recognition of ship targets in ISAR. IET Radar Sonar Nav. 2009, 3, 406–423. [Google Scholar] [CrossRef]
- Saidi, M.N.; Daoudi, K.; Khenchaf, A.; Hoeltzener, B.; Aboutajdine, D. Automatic target recognition of aircraft models based on ISAR images. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. IV-685–IV-688. [Google Scholar]
- Saidi, M.N.; Toumi, A.; Khenchaf, A.; Hoeltzener, B.; Aboutajdine, D. Pose estimation for ISAR image classification. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 4620–4623. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012. [Google Scholar]
- Chen, K.; Wang, L.; Zhang, J.; Chen, S.; Zhang, S. Semantic Learning for Analysis of Overlapping LPI Radar Signals. IEEE Trans. Instrum. Meas. 2023, 72, 8501615. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Examples | Time (s) | Similarity |
|---|---|---|
| Figure 8a | 27,457 | 0.97 |
| Figure 9a | 9 | |
| Figure 8b | 27,460 | 0.98 |
| Figure 9b | 9 |
| Networks | T1-AP | T2-AP | T3-AP | mAP |
|---|---|---|---|---|
| YOLOv3 | 0.79 | 0.80 | 0.85 | 0.81 |
| YOLOv3-SE | 0.84 | 0.77 | 0.88 | 0.83 |
| YOLOv3-shallow SE | 0.84 | 0.83 | 0.94 | 0.87 |
| YOLOv3-CB | 0.02 | 0.03 | 0.01 | 0.02 |
| YOLOv3-shallow CB | 0.92 | 0.94 | 0.97 | 0.94 |
| YOLOv3 | YOLOv3-SE | YOLOv3-Shallow SE | YOLOv3-CB | YOLOv3-Shallow CB | |
|---|---|---|---|---|---|
| FPS | 20.3 | 15.3 | 19.6 | 14.2 | 19.1 |
| Networks | T72-AP | 2S1-AP | ZSU-23-4-AP | mAP |
|---|---|---|---|---|
| Faster R-CNN | 0.80 | 0.88 | 0.85 | 0.85 |
| RetinaNet | 0.79 | 0.86 | 0.86 | 0.82 |
| SSD | 0.80 | 0.83 | 0.86 | 0.83 |
| YOLOv3-shallow CB | 0.93 | 0.95 | 0.94 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, G.; Wang, R.; Guo, L. Research on Radar Target Detection Based on the Electromagnetic Scattering Imaging Algorithm and the YOLO Network. Remote Sens. 2024, 16, 3807. https://doi.org/10.3390/rs16203807
Guo G, Wang R, Guo L. Research on Radar Target Detection Based on the Electromagnetic Scattering Imaging Algorithm and the YOLO Network. Remote Sensing. 2024; 16(20):3807. https://doi.org/10.3390/rs16203807
Chicago/Turabian StyleGuo, Guangbin, Rui Wang, and Lixin Guo. 2024. "Research on Radar Target Detection Based on the Electromagnetic Scattering Imaging Algorithm and the YOLO Network" Remote Sensing 16, no. 20: 3807. https://doi.org/10.3390/rs16203807
APA StyleGuo, G., Wang, R., & Guo, L. (2024). Research on Radar Target Detection Based on the Electromagnetic Scattering Imaging Algorithm and the YOLO Network. Remote Sensing, 16(20), 3807. https://doi.org/10.3390/rs16203807