
High-Precision Heterogeneous Satellite Image Manipulation Localization: Feature Point Rules and Semantic Similarity Measurement

Abstract
1. Introduction
2. Related Works
2.1. IML on Satellite Images
2.2. Heterogeneous Satellite Image Manipulation Localization
2.3. Image Consistency Measurement and Evaluation
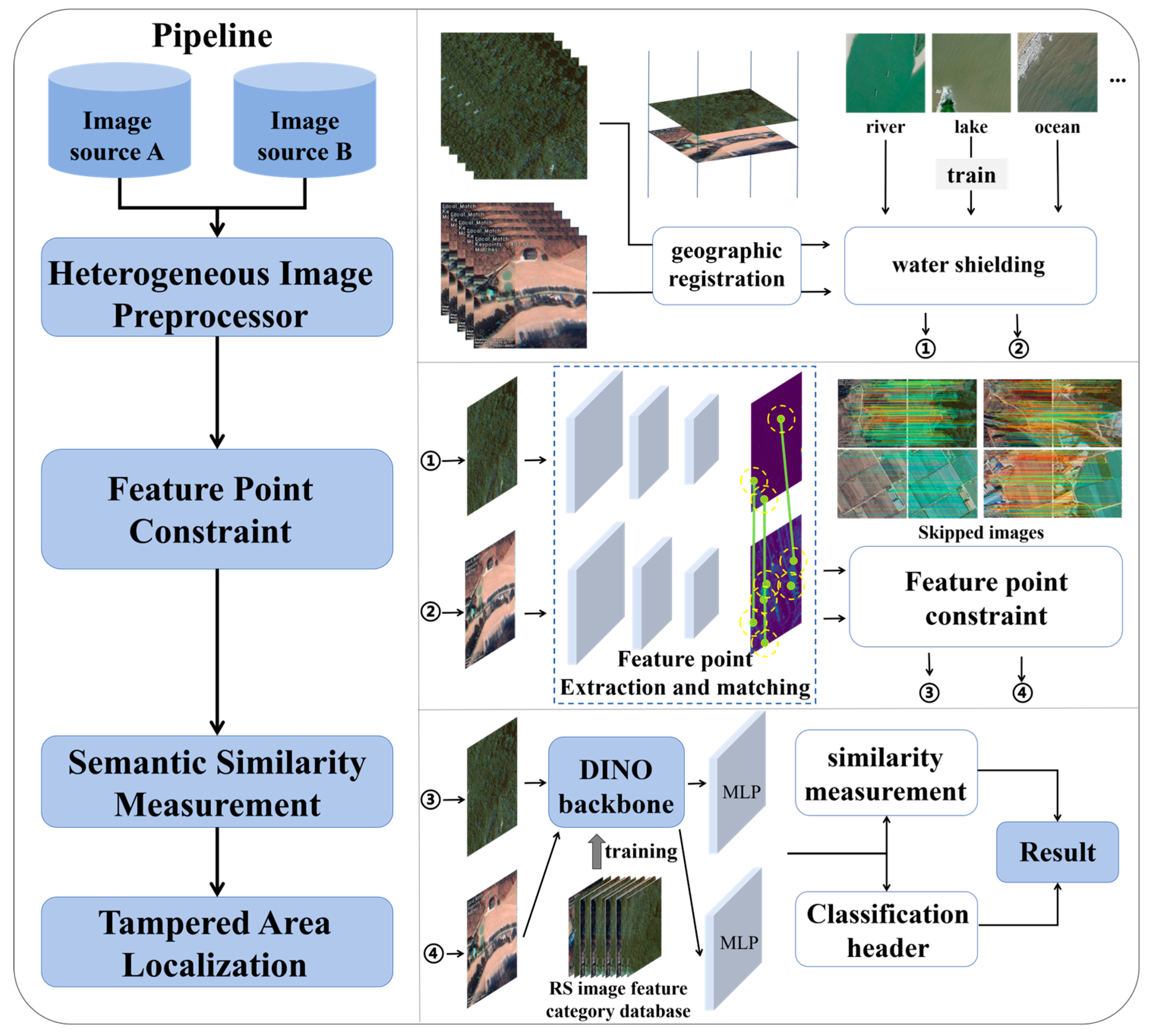
3. Methods
3.1. Heterogeneous Image Preprocessor
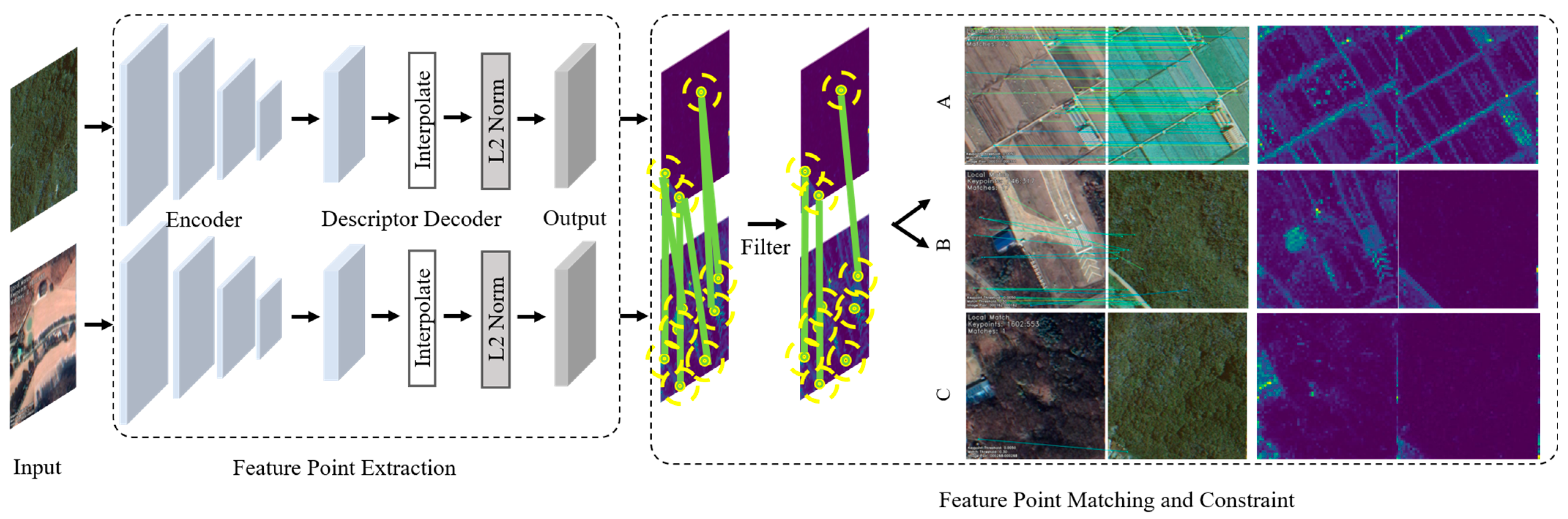
3.2. Feature Point Constraint Module
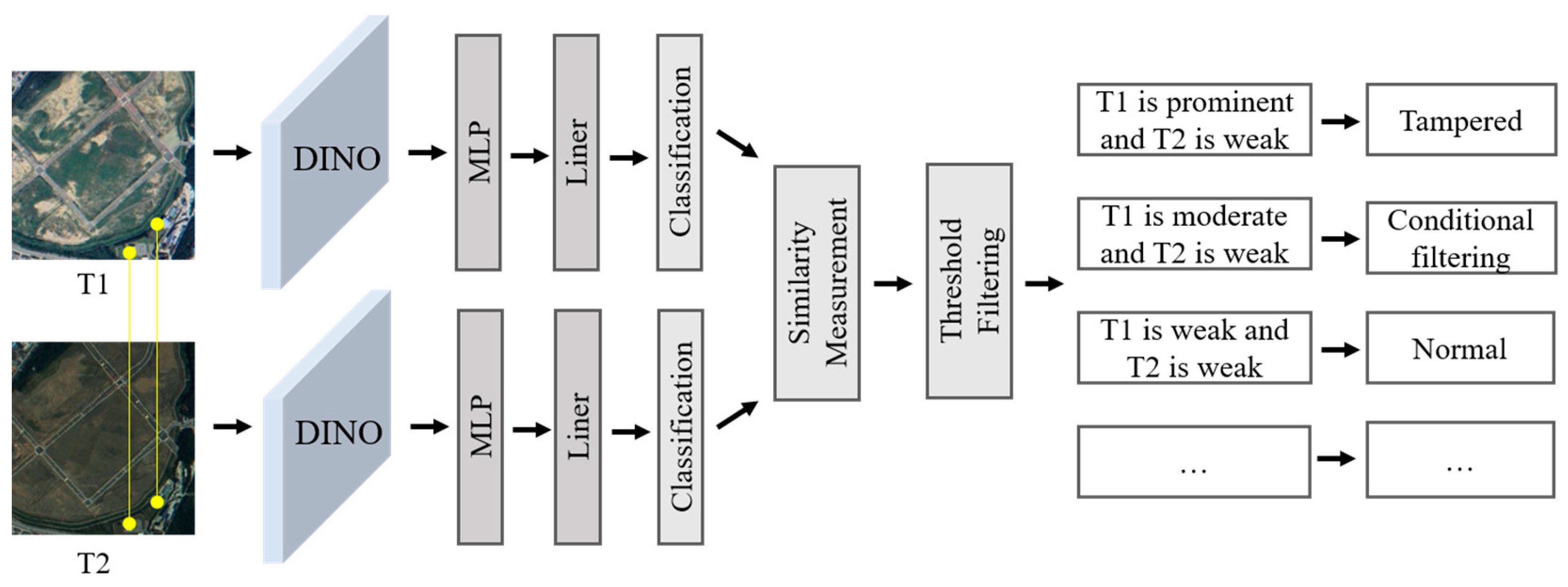
3.3. Semantic Similarity Measurement
4. Experiments
4.1. Dataset
4.2. Ablation Experiment of Semantic Similarity Measurement Module
4.3. Comparative Analysis
4.4. Visualization
4.5. Parameter Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, G.; Li, J.; Nie, P. Tracking the History of Urban Expansion in Guangzhou (China) during 1665–2017: Evidence from Historical Maps and Remote Sensing Images. Land Use Policy 2022, 112, 105773. [Google Scholar] [CrossRef]
- Basu, T.; Das, A.; Pereira, P. Exploring the Drivers of Urban Expansion in a Medium-Class Urban Agglomeration in India Using the Remote Sensing Techniques and Geographically Weighted Models. Geogr. Sustain. 2023, 4, 150–160. [Google Scholar] [CrossRef]
- Qiu, C.; Zhang, X.; Tong, X.; Guan, N.; Yi, X.; Yang, K.; Zhu, J.; Yu, A. Few-Shot Remote Sensing Image Scene Classification: Recent Advances, New Baselines, and Future Trends. ISPRS J. Photogramm. Remote Sens. 2024, 209, 368–382. [Google Scholar] [CrossRef]
- Li, X.; Wen, C.; Hu, Y.; Zhou, N. RS-CLIP: Zero Shot Remote Sensing Scene Classification via Contrastive Vision-Language Supervision. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103497. [Google Scholar] [CrossRef]
- Wang, J.; Li, W.; Zhang, M.; Tao, R.; Chanussot, J. Remote-Sensing Scene Classification via Multistage Self-Guided Separation Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615312. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Benediktsson, J.A.; Falco, N. Land Cover Change Detection Techniques: Very-High-Resolution Optical Images: A Review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 44–63. [Google Scholar] [CrossRef]
- Das, S.; Angadi, D.P. Land Use Land Cover Change Detection and Monitoring of Urban Growth Using Remote Sensing and GIS Techniques: A Micro-Level Study. GeoJournal 2022, 87, 2101–2123. [Google Scholar] [CrossRef]
- Lv, Z.; Zhong, P.; Wang, W.; You, Z.; Benediktsson, J.A.; Shi, C. Novel Piecewise Distance Based on Adaptive Region Key-Points Extraction for LCCD With VHR Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607709. [Google Scholar] [CrossRef]
- Edwards, J. NGA’s Todd Myers: China Uses GAN Technique to Tamper With Earth Images 2019. Available online: https://executivegov.com/2019/04/ngas-todd-myers-china-uses-gan-technique-to-tamper-with-earth-images (accessed on 1 April 2019).
- Ma, X.; Du, B.; Jiang, Z.; Hammadi, A.Y.A.; Zhou, J. IML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer. arXiv 2023, arXiv:2307.14863. [Google Scholar] [CrossRef]
- Horvath, J. Manipulation Detection and Localization for Satellite Imagery. Ph.D. Thesis, Purdue University Graduate School, West Lafayette, IN, USA, 2022. [Google Scholar]
- Bartusiak, E.R.; Yarlagadda, S.K.; Güera, D.; Bestagini, P.; Tubaro, S.; Zhu, F.M.; Delp, E.J. Splicing Detection and Localization in Satellite Imagery Using Conditional GANs. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 91–96. [Google Scholar]
- Montserrat, D.M.; Horváth, J.; Yarlagadda, S.K.; Zhu, F.; Delp, E.J. Generative Autoregressive Ensembles for Satellite Imagery Manipulation Detection 2020. In Proceedings of the 12th IEEE International Workshop on Information Forensics and Security (WIFS), New York, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Horváth, J.; Montserrat, D.M.; Hao, H.; Delp, E.J. Manipulation Detection in Satellite Images Using Deep Belief Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2832–2840. [Google Scholar]
- Horváth, J.; Baireddy, S.; Hao, H.; Montserrat, D.M.; Delp, E.J. Manipulation Detection in Satellite Images Using Vision Transformer. arXiv 2021, arXiv:2105.06373. [Google Scholar] [CrossRef]
- Horváth, J.; Montserrat, D.M.; Delp, E.J.; Horváth, J. Nested Attention U-Net: A Splicing Detection Method for Satellite Images. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges; Del Bimbo, A., Cucchiara, R., Sclaroff, S., Farinella, G.M., Mei, T., Bertini, M., Escalante, H.J., Vezzani, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 516–529. [Google Scholar]
- Horváth, J.; Xiang, Z.; Cannas, E.D.; Bestagini, P.; Tubaro, S.; Iii, E.J.D. Sat U-Net: A Fusion Based Method for Forensic Splicing Localization in Satellite Images. In Proceedings Volume, Multimodal Image Exploitation and Learning 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12100, p. 1210002. [Google Scholar]
- Ho, A.T.S.; Zhu, X.; Woon, W.M. A Semi-Fragile Pinned Sine Transform Watermarking System for Content Authentication of Satellite Images. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, 2005—IGARSS ’05, Seoul, Republic of Korea, 29 July 2005; Volume 2, p. 4. [Google Scholar]
- Yarlagadda, S.K.; Güera, D.; Bestagini, P.; Zhu, F.M.; Tubaro, S.; Delp, E.J. Satellite Image Forgery Detection and Localization Using GAN and One-Class Classifier. arXiv 2018, arXiv:1802.04881. [Google Scholar] [CrossRef]
- Horvath, J.; Guera, D.; Kalyan Yarlagadda, S.; Bestagini, P.; Maggie Zhu, F.; Tubaro, S.; Delp, E.J. Anomaly-Based Manipulation Detection in Satellite Images. Networks 2019, 29, 62–71. [Google Scholar]
- Klaric, M.N.; Claywell, B.C.; Scott, G.J.; Hudson, N.J.; Sjahputera, O.; Li, Y.; Barratt, S.T.; Keller, J.M.; Davis, C.H. GeoCDX: An Automated Change Detection and Exploitation System for High-Resolution Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2067–2086. [Google Scholar] [CrossRef]
- Han, Y.; Bovolo, F.; Bruzzone, L. An Approach to Fine Coregistration Between Very High Resolution Multispectral Images Based on Registration Noise Distribution. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6650–6662. [Google Scholar] [CrossRef]
- Bergamasco, L.; Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised Change Detection Using Convolutional-Autoencoder Multiresolution Features. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408119. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.; Liu, X. UTRNet: An Unsupervised Time-Distance-Guided Convolutional Recurrent Network for Change Detection in Irregularly Collected Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410516. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change Detection on Remote Sensing Images Using Dual-Branch Multilevel Intertemporal Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4401015. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, Z.; Feng, J.; Liu, L.; Jiao, L. Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sens. 2023, 15, 842. [Google Scholar] [CrossRef]
- Hao, M.; Yang, C.; Lin, H.; Zou, L.; Liu, S.; Zhang, H. Bi-Temporal Change Detection of High-Resolution Images by Referencing Time Series Medium-Resolution Images. Int. J. Remote Sens. 2023, 44, 3333–3357. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A Hierarchical Attention Network for Change Detection with Bitemporal Very-High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. Change Detection for High Resolution Satellite Images, Based on SIFT Descriptors and an a Contrario Approach. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1281–1284. [Google Scholar]
- Wang, Y.; Du, L.; Dai, H. Unsupervised SAR Image Change Detection Based on SIFT Keypoints and Region Information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 931–935. [Google Scholar] [CrossRef]
- Liu, G.; Gousseau, Y.; Tupin, F. A Contrario Comparison of Local Descriptors for Change Detection in Very High Spatial Resolution Satellite Images of Urban Areas. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3904–3918. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Cui, H.; Shen, S.; Gao, W.; Liu, H.; Wang, Z. Efficient and Robust Large-Scale Structure-from-Motion via Track Selection and Camera Prioritization. ISPRS J. Photogramm. Remote Sens. 2019, 156, 202–214. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultralightweight Spatial–Spectral Feature Cooperation Network for Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402114. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Nair, N.G.; Patel, V.M. DDPM-CD: Denoising Diffusion Probabilistic Models as Feature Extractors for Change Detection. arXiv 2024, arXiv:2206.11892. [Google Scholar] [CrossRef]
- Wang, L.; Fang, Y.; Li, Z.; Wu, C.; Xu, M.; Shao, M. Summator–Subtractor Network: Modeling Spatial and Channel Differences for Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5604212. [Google Scholar] [CrossRef]
- Touazi, A.; Bouchaffra, D. A K-Nearest Neighbor Approach to Improve Change Detection from Remote Sensing: Application to Optical Aerial Images. In Proceedings of the 2015 15th International Conference on Intelligent Systems Design and Applications (ISDA), Marrakesh, Morocco, 14–16 December 2015; pp. 98–103. [Google Scholar]
- Choy, C.B.; Gwak, J.; Savarese, S.; Chandraker, M. Universal Correspondence Network. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Kong, N.; Goka, H.; Park, K.; Lempitsky, V. Resolution-Robust Large Mask Inpainting with Fourier Convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar] [CrossRef]
- El-Nouby, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. XCiT: Cross-Covariance Image Transformers. arXiv 2021, arXiv:2106.09681. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | F1 (%) | IoU (%) | |
|---|---|---|---|---|---|
| xcit_small | 82.03 | 86.98 | 84.43 | 73.05 | |
| resnet50 | 87.37 | 67.07 | 75.89 | 61.14 | |
| DINO | Vit-S/16 | 80.90 | 75.72 | 78.22 | 64.24 |
| Vit-S/8 | 78.68 | 63.09 | 70.02 | 53.88 | |
| Vit-B/16 | 79.51 | 74.18 | 76.75 | 62.28 | |
| Vit-B/8 | 74.06 | 70.37 | 72.17 | 56.46 | |
| DINOv2 | Dinov2-small | 91.45 | 82.18 | 86.57 | 76.32 |
| Dinov2-base | 87.78 | 83.74 | 85.71 | 75.00 | |
| Datasets | Methods | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| Test1 | USSFC | 64.95 | 95.31 | 77.25 |
| DDPM-CD | 73.31 | 89.21 | 80.48 | |
| SSCD | 21.06 | 93.58 | 34.38 | |
| IML-ViT | 57.35 | 48.12 | 52.33 | |
| Ours | 91.45 | 82.18 | 86.57 | |
| Test2 | USSFC | 98.92 | 86.99 | 92.57 |
| DDPM-CD | 98.61 | 89.42 | 93.79 | |
| SSCD | 98.93 | 31.09 | 47.31 | |
| IML-ViT | 98.03 | 81.03 | 88.72 | |
| Ours | 98.94 | 91.57 | 95.11 |
| r | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| 1 | 80.18 | 84.92 | 82.48 |
| 2 | 80.96 | 83.97 | 82.44 |
| 3 | 82.04 | 83.44 | 82.73 |
| 4 | 82.47 | 79.14 | 80.77 |
| 5 | 82.88 | 78.30 | 80.52 |
| 6 | 83.21 | 77.37 | 80.18 |
| 7 | 83.29 | 76.67 | 79.84 |
| m | Precision (%) ↑ | Recall (%) ↑ | F1 (%) ↑ |
|---|---|---|---|
| 1 | 83.12 | 70.49 | 76.29 |
| 2 | 82.60 | 78.11 | 80.29 |
| 3 | 82.17 | 79.88 | 81.01 |
| 4 | 82.04 | 80.43 | 81.23 |
| 5 | 81.99 | 80.58 | 81.28 |
| 6 | 81.96 | 80.62 | 81.28 |
| 7 | 81.96 | 80.62 | 81.28 |
| Precision (%) | Recall (%) | F1 (%) | ||
|---|---|---|---|---|
| 0.60 | 0.55 | 93.33 | 22.77 | 36.61 |
| 0.65 | 0.60 | 94.56 | 42.80 | 58.93 |
| 0.70 | 0.65 | 93.05 | 58.50 | 71.84 |
| 0.75 | 0.70 | 89.41 | 69.84 | 78.42 |
| 0.80 | 0.75 | 84.57 | 77.46 | 80.86 |
| 0.85 | 0.80 | 81.96 | 80.62 | 81.28 |
| 0.90 | 0.85 | 80.02 | 81.69 | 80.85 |
| Compression Rate (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| 0 | 91.45 | 82.18 | 86.57 |
| 10 | 90.68 | 81.63 | 85.92 |
| 20 | 89.84 | 82.43 | 85.98 |
| 30 | 87.93 | 83.00 | 85.39 |
| 40 | 86.42 | 83.24 | 84.80 |
| 50 | 81.93 | 82.55 | 82.24 |
| 60 | 78.35 | 82.09 | 80.18 |
| 70 | 68.30 | 79.82 | 73.61 |
| 80 | 63.87 | 80.49 | 71.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, R.; Guo, W.; Liu, Y.; Sun, C. High-Precision Heterogeneous Satellite Image Manipulation Localization: Feature Point Rules and Semantic Similarity Measurement. Remote Sens. 2024, 16, 3719. https://doi.org/10.3390/rs16193719
Wu R, Guo W, Liu Y, Sun C. High-Precision Heterogeneous Satellite Image Manipulation Localization: Feature Point Rules and Semantic Similarity Measurement. Remote Sensing. 2024; 16(19):3719. https://doi.org/10.3390/rs16193719
Chicago/Turabian StyleWu, Ruijie, Wei Guo, Yi Liu, and Chenhao Sun. 2024. "High-Precision Heterogeneous Satellite Image Manipulation Localization: Feature Point Rules and Semantic Similarity Measurement" Remote Sensing 16, no. 19: 3719. https://doi.org/10.3390/rs16193719
APA StyleWu, R., Guo, W., Liu, Y., & Sun, C. (2024). High-Precision Heterogeneous Satellite Image Manipulation Localization: Feature Point Rules and Semantic Similarity Measurement. Remote Sensing, 16(19), 3719. https://doi.org/10.3390/rs16193719