
Thin Cloud Removal Generative Adversarial Network Based on Sparse Transformer in Remote Sensing Images



Abstract
1. Introduction
- 1.
- We introduce a sparse multi-head self-attention (sparse attention) module to build the transformer block within the generator. This module utilizes the self-attention mechanism’s outstanding long-range modeling capabilities to model global pixel relationships, enhancing the model’s ability to reconstruct cloud-free images. It employs a weight-learnable filtering mechanism to retain information from highly relevant areas while neglecting information from low-correlation areas.
- 2.
- Moreover, we propose a GEFE module to capture aggregated features from different directions and enhance the model’s extraction of perceivable surface information.
- 3.
- Our study demonstrates that the proposed SpT-GAN effectively removes clouds for both uniform and nonuniform thin cloud RS images across various scenes without significantly increasing computational complexity. Experimental results on public datasets, including RICE1 and T-Cloud, show that the generated images exhibit precise details, high color fidelity, and close resemblance to the authentic ground images.
2. Related Works
2.1. Attention-Mechanism-Based Cloud Removal Methods
2.2. Transformers in Deep Learning Tasks
3. Methodology
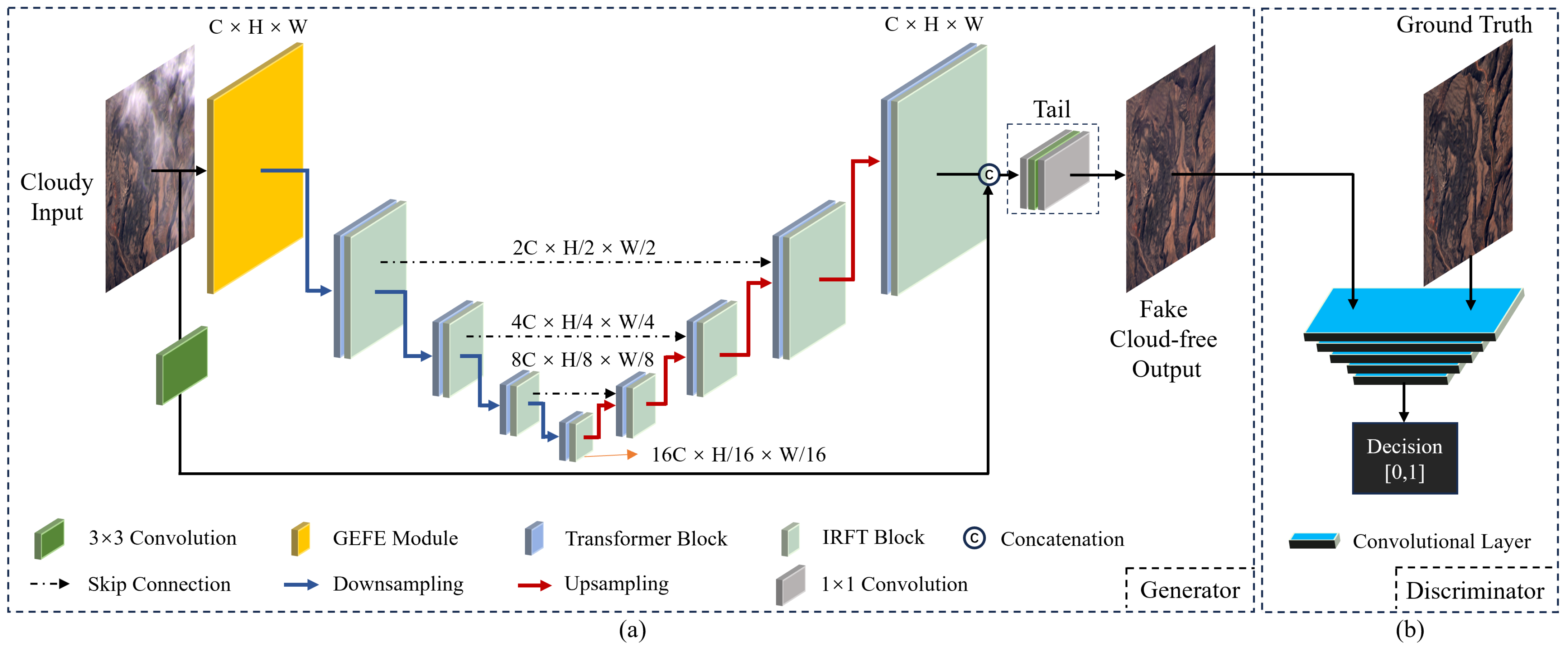
3.1. Overview of the Proposed Framework
3.1.1. Generator
3.1.2. Discriminator
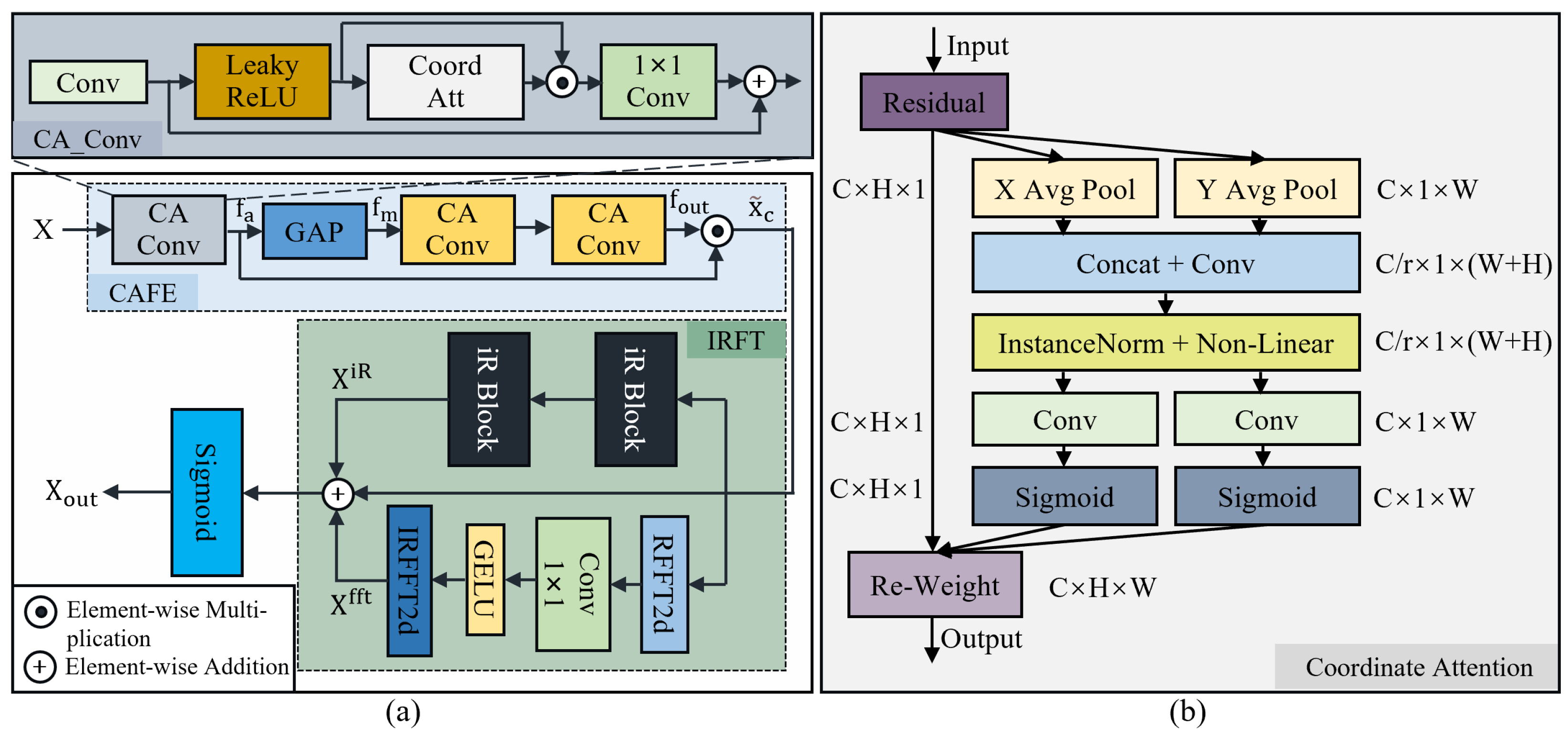
3.2. Global Enhancement Feature Extraction Module
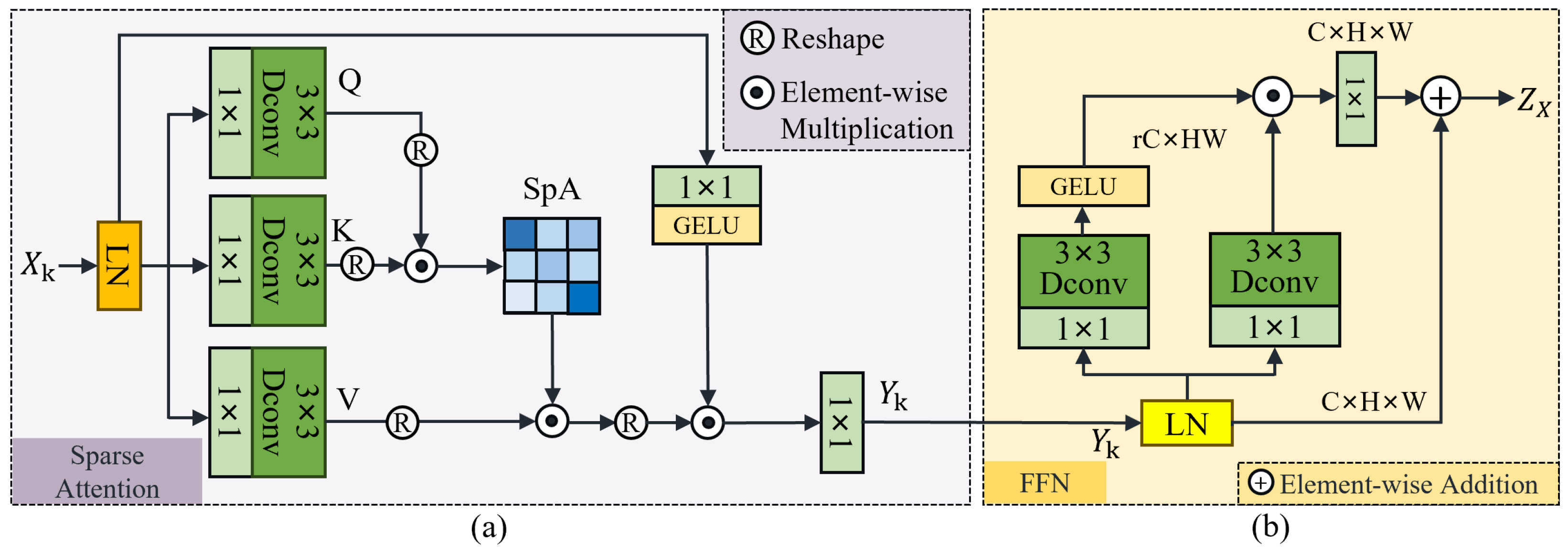
3.3. Sparse Transformer Block
3.3.1. Sparse Attention
3.3.2. Feed-Forward Network
3.4. Loss Function
4. Results and Analysis
4.1. Experimental Settings
4.1.1. Implementation Details
4.1.2. Description of Datasets
4.1.3. Evaluation Metrics
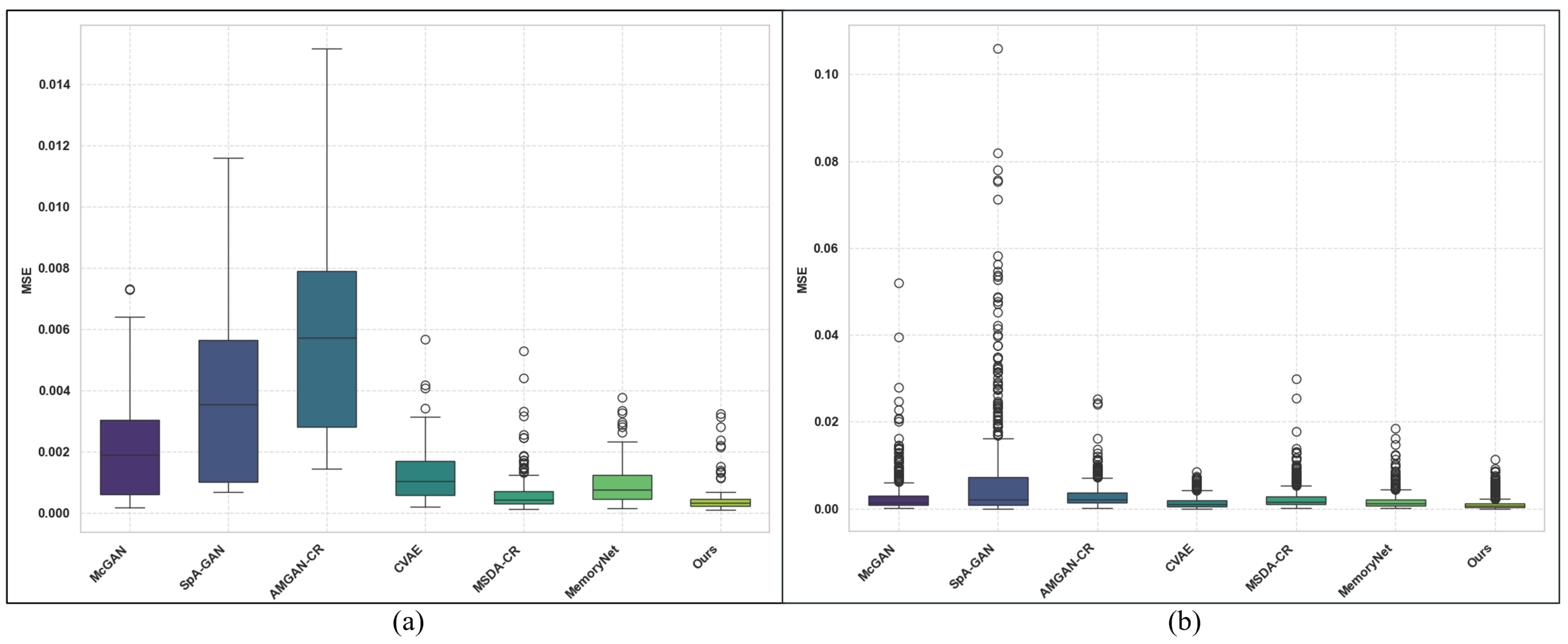
4.2. Comparison with Other Methods
4.3. Model Complexity Evaluation
4.4. Ablation Studies
4.4.1. IRFT Block and GEFE Module Ablation Study
4.4.2. Loss Function Ablation Study
4.4.3. Sparse Attention Ablation Study
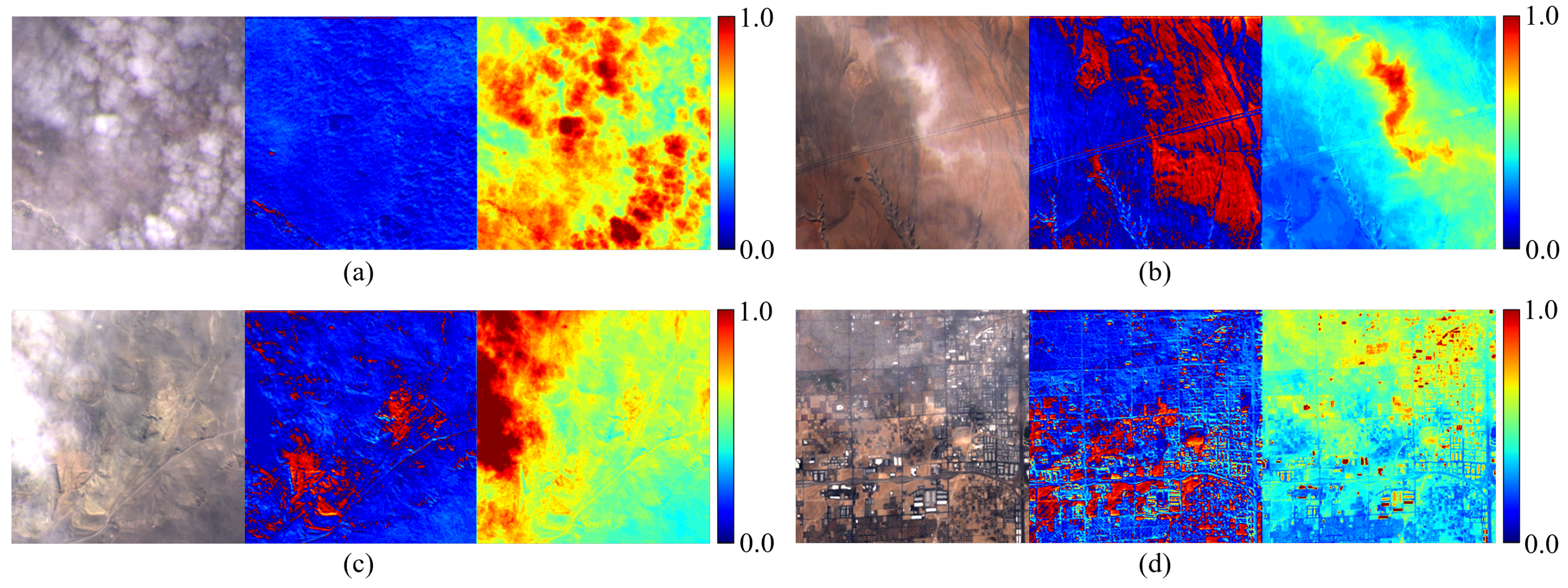
4.5. Evaluation of Cloud-Free Image Processing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. Atmos. 2004, 109, D19. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Hao, X.; Liu, L.; Yang, R.; Yin, L.; Zhang, L.; Li, X. A review of data augmentation methods of remote sensing image target recognition. Remote Sens. 2023, 15, 827. [Google Scholar] [CrossRef]
- Liu, C.; Li, W.; Zhu, G.; Zhou, H.; Yan, H.; Xue, P. Land use/land cover changes and their driving factors in the Northeastern Tibetan Plateau based on Geographical Detectors and Google Earth Engine: A case study in Gannan Prefecture. Remote Sens. 2020, 12, 3139. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Guo, J.; Yang, J.; Yue, H.; Tan, H.; Hou, C.; Li, K. RSDehazeNet: Dehazing network with channel refinement for multispectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2535–2549. [Google Scholar] [CrossRef]
- Liu, Z.; Hunt, B.R. A new approach to removing cloud cover from satellite imagery. Comput. Vis. Graph. Image Process. 1984, 25, 252–256. [Google Scholar] [CrossRef]
- Shen, H.; Li, H.; Qian, Y.; Zhang, L.; Yuan, Q. An effective thin cloud removal procedure for visible remote sensing images. ISPRS J. Photogramm. Remote Sens. 2014, 96, 224–235. [Google Scholar] [CrossRef]
- Xu, M.; Jia, X.; Pickering, M.; Jia, S. Thin cloud removal from optical remote sensing images using the noise-adjusted principal components transform. ISPRS J. Photogramm. Remote Sens. 2019, 149, 215–225. [Google Scholar] [CrossRef]
- Hu, G.; Li, X.; Liang, D. Thin cloud removal from remote sensing images using multidirectional dual tree complex wavelet transform and transfer least square support vector regression. J. Appl. Remote Sens. 2015, 9, 095053. [Google Scholar] [CrossRef]
- Lv, H.; Wang, Y.; Shen, Y. An empirical and radiative transfer model based algorithm to remove thin clouds in visible bands. Remote Sens. Environ. 2016, 179, 183–195. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, Y. A thin-cloud removal approach combining the cirrus band and RTM-based algorithm for Landsat-8 OLI data. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 1434–1437. [Google Scholar]
- Song, C.; Xiao, C.; Zhang, Y.; Sui, H. Thin Cloud Removal for Single RGB Aerial Image. Comput Graph. Forum. 2021, 40, 398–409. [Google Scholar] [CrossRef]
- Sahu, G.; Seal, A.; Krejcar, O.; Yazidi, A. Single image dehazing using a new color channel. J. Vis. Commun. Image Represent. 2021, 74, 1–16. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Liu, X.; Liu, C.; Lan, H.; Xie, L. Dehaze enhancement algorithm based on retinex theory for aerial images combined with dark channel. Open Access Libr. J. 2020, 7, 1–12. [Google Scholar] [CrossRef]
- Shi, S.; Zhang, Y.; Zhou, X.; Cheng, J. Cloud removal for single visible image based on modified dark channel prior with multiple scale. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 4127–4130. [Google Scholar]
- Tang, Q.; Yang, J.; He, X.; Jia, W.; Zhang, Q.; Liu, H. Nighttime image dehazing based on Retinex and dark channel prior using Taylor series expansion. Comput. Vis. Image Underst. 2021, 202, 103086. [Google Scholar] [CrossRef]
- Han, Y.; Yin, M.; Duan, P.; Ghamisi, P. Edge-preserving filtering-based dehazing for remote sensing images. IEEE Geosci. Remote Sens. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, G.; He, L.; Qi, Y.; Yang, M.; Zhao, X.; Chao, Y. An improved algorithm using weighted guided coefficient and union self-adaptive image enhancement for single image haze removal. IET Image Process. 2021, 15, 2680–2692. [Google Scholar] [CrossRef]
- Peli, T.; Quatieri, T. Homomorphic restoration of images degraded by light cloud cover. In Proceedings of the 1984 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), San Diego, CA, USA, 19–21 March 1984; pp. 100–103. [Google Scholar]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Chen, D.; Chan, J.C.-W. Thin cloud removal with residual symmetrical concatenation network. ISPRS J. Photogramm. Remote Sens. 2019, 153, 137–150. [Google Scholar] [CrossRef]
- Zhou, Y.; Jing, W.; Wang, J.; Chen, G.; Scherer, R.; Damaševičius, R. MSAR-DefogNet: Lightweight cloud removal network for high resolution remote sensing images based on multi scale convolution. IET Image Process. 2022, 16, 659–668. [Google Scholar] [CrossRef]
- Ding, H.; Zi, Y.; Xie, F. Uncertainty-based thin cloud removal network via conditional variational autoencoders. In Proceedings of the 2022 Asian Conference on Computer Vision (ACCV), Macau SAR, China, 4–8 December 2022; pp. 469–485. [Google Scholar]
- Zi, Y.; Ding, H.; Xie, F.; Jiang, Z.; Song, X. Wavelet integrated convolutional neural network for thin cloud removal in remote sensing images. Remote Sens. 2023, 15, 781. [Google Scholar] [CrossRef]
- Guo, Y.; He, W.; Xia, Y.; Zhang, H. Blind single-image-based thin cloud removal using a cloud perception integrated fast Fourier convolutional network. ISPRS J. Photogramm. Remote Sens. 2023, 206, 63–86. [Google Scholar] [CrossRef]
- Pan, H. Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv 2020, arXiv:2009.13015. [Google Scholar]
- Huang, G.-L.; Wu, P.-Y. Ctgan: Cloud transformer generative adversarial network. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Colombo, Sri Lanka, 16–19 October 2022; pp. 511–515. [Google Scholar]
- Ma, X.; Huang, Y.; Zhang, X.; Pun, M.-O.; Huang, B. Cloud-EGAN: Rethinking CycleGAN from a feature enhancement perspective for cloud removal by combining CNN and transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4999–5012. [Google Scholar] [CrossRef]
- Wang, X.; Xu, G.; Wang, Y.; Lin, D.; Li, P.; Lin, X. Thin and thick cloud removal on remote sensing image by conditional generative adversarial network. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium(IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 1426–1429. [Google Scholar]
- Li, J.; Wu, Z.; Hu, Z.; Zhang, J.; Li, M.; Mo, L.; Molinier, M. Thin cloud removal in optical remote sensing images based on generative adversarial networks and physical model of cloud distortion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 373–389. [Google Scholar] [CrossRef]
- Tan, Z.C.; Du, X.F.; Man, W.; Xie, X.Z.; Wang, G.S.; Nie, Q. Unsupervised remote sensing image thin cloud removal method based on contrastive learning. IET Image Process. 2024, 18, 1844–1861. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wen, X.; Pan, Z.; Hu, Y.; Liu, J. An effective network integrating residual learning and channel attention mechanism for thin cloud removal. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6507605. [Google Scholar] [CrossRef]
- Duan, C.; Li, R. Multi-head linear attention generative adversarial network for thin cloud removal. arXiv 2020, arXiv:2012.10898. [Google Scholar]
- Zou, X.; Li, K.; Xing, J.; Tao, P.; Cui, Y. PMAA: A progressive multi-scale attention autoencoder model for high-performance cloud removal from multi-temporal satellite imagery. arXiv 2023, arXiv:2303.16565. [Google Scholar]
- Chen, H.; Chen, R.; Li, N. Attentive generative adversarial network for removing thin cloud from a single remote sensing image. IET Image Process. 2021, 15, 856–867. [Google Scholar] [CrossRef]
- Jing, R.; Duan, F.; Lu, F.; Zhang, M.; Zhao, W. Cloud removal for optical remote sensing imagery using the SPA-CycleGAN network. J. Appl. Remote Sens. 2022, 16, 034520. [Google Scholar] [CrossRef]
- Wu, P.; Pan, Z.; Tang, H.; Hu, Y. Cloudformer: A cloud-removal network combining self-attention mechanism and convolution. Remote Sens. 2022, 14, 6132. [Google Scholar] [CrossRef]
- Zhao, B.; Zhou, J.; Xu, H.; Feng, X.; Sun, Y. PM-LSMN: A Physical-Model-based Lightweight Self-attention Multiscale Net For Thin Cloud Removal. Remote Sens. 2024, 21, 5003405. [Google Scholar] [CrossRef]
- Liu, J.; Hou, W.; Luo, X.; Su, J.; Hou, Y.; Wang, Z. SI-SA GAN: A generative adversarial network combined with spatial information and self-attention for removing thin cloud in optical remote sensing images. IEEE Access 2022, 10, 114318–114330. [Google Scholar] [CrossRef]
- Ding, H.; Xie, F.; Zi, Y.; Liao, W.; Song, X. Feedback network for compact thin cloud removal. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6003505. [Google Scholar] [CrossRef]
- Jin, M.; Wang, P.; Li, Y. HyA-GAN: Remote sensing image cloud removal based on hybrid attention generation adversarial network. Int. J. Remote Sens. 2024, 45, 1755–1773. [Google Scholar] [CrossRef]
- Dufter, P.; Schmitt, M.; Schütze, H. Position information in transformers: An overview. Comput. Linguist. 2022, 48, 733–763. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning A Sparse Transformer Network for Effective Image Deraining. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5896–5905. [Google Scholar]
- Han, D.; Pan, X.; Han, Y.; Song, S.; Huang, G. Flatten transformer: Vision transformer using focused linear attention. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 5961–5971. [Google Scholar]
- Kim, S.; Gholami, A.; Shaw, A.; Lee, N.; Mangalam, K.; Malik, J.; Mahoney, M.; Keutzer, K. Squeezeformer: An efficient transformer for automatic speech recognition. Adv. Neural Inf. Process. Syst. 2022, 35, 9361–9373. [Google Scholar]
- Chang, F.; Radfar, M.; Mouchtaris, A.; King, B.; Kunzmann, S. End-to-end multi-channel transformer for speech recognition. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 5884–5888. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 8–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Zhang, Y.; Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Yun, S.; Ro, Y. Shvit: Single-head vision transformer with memory efficient macro design. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, 17–21 June 2024; pp. 5756–5767. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Farina, M.; Ahmad, U.; Taha, A.; Younes, H.; Mesbah, Y.; Yu, X.; Pedrycz, W. Sparsity in Transformers: A Systematic Literature Review. Neurocomputing 2024, 582, 127468. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Z.; Tang, H.; Yi, L.; Zhao, H.; Han, S. SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2061–2070. [Google Scholar]
- Huang, W.; Deng, Y.; Hui, S.; Wu, Y.; Zhou, S.; Wang, J. Sparse self-attention transformer for image inpainting. Pattern Recognit. 2024, 145, 109897. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Yae, S.; Ikehara, M. Inverted residual Fourier transformation for lightweight single image deblurring. IEEE Access 2023, 11, 29175–29182. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Huang, L.; Zhou, Y.; Wang, T.; Luo, J.; Liu, X. Delving into the estimation shift of batch normalization in a network. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2022; pp. 763–772. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 8–12 October 2016. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhou, C.; Zhang, J.; Liu, J.; Zhang, C.; Fei, R.; Xu, S. PercepPan: Towards unsupervised pan-sharpening based on perceptual loss. Remote Sens. 2020, 12, 2318. [Google Scholar] [CrossRef]
- Niklaus, S.; Liu, F. Context-aware synthesis for video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1701–1710. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Enomoto, K.; Sakurada, K.; Wang, W.; Fukui, H.; Matsuoka, M.; Nakamura, R.; Kawaguchi, N. Filmy cloud removal on satellite imagery with multispectral conditional generative adversarial nets. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 48–56. [Google Scholar]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A.J. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Yu, W.; Zhang, X.; Pun, M.O. Cloud removal in optical remote sensing imagery using multiscale distortion-aware networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5512605. [Google Scholar] [CrossRef]
- Zhang, X.; Gu, C.; Zhu, S. Memory augment is All You Need for image restoration. arXiv 2023, arXiv:2309.01377. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are Sixteen Heads Really Better than One? Adv. Neural Inf. Process. Syst. (NeurIPS) 2019, 32, 1–11. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Spectrum | Resolution | Re-Entry Period | Image Size | Source | Quantity |
|---|---|---|---|---|---|---|---|
| RICE1 | RGB | 3 | 30 m | 15 days | Google Earth | 500 | |
| T-Cloud | RGB | 3 | 30 m | 16 days | Landsat 8 | 2939 |
| Methods | RICE1 | T-Cloud | ||||
|---|---|---|---|---|---|---|
| mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | |
| DCP [15] | 20.72 | 72.54 | 0.1992 | 19.85 | 66.30 | 0.2205 |
| McGAN [78] | 31.40 | 93.90 | 0.0302 | 26.91 | 86.96 | 0.1028 |
| SpA-GAN [28] | 30.66 | 91.02 | 0.0519 | 26.39 | 79.51 | 0.1726 |
| AMGAN-CR [79] | 29.81 | 90.01 | 0.0786 | 27.67 | 82.25 | 0.1552 |
| CVAE [25] | 34.56 | 95.44 | 0.0239 | 29.95 | 85.76 | 0.1090 |
| MSDA-CR [80] | 34.68 | 96.47 | 0.0185 | 28.68 | 88.02 | 0.0858 |
| MemoryNet [81] | 34.36 | 97.73 | 0.0113 | 29.55 | 91.47 | 0.0623 |
| Ours | 36.19 | 98.06 | 0.0081 | 30.53 | 92.19 | 0.0528 |
| Methods | Parameters/M | Flops/G | Size/MB | Speed/FPS |
|---|---|---|---|---|
| McGAN [78] | 54.40 | 142.27 | 207.58 | 27.09 |
| SpA-GAN [28] | 0.21 | 33.97 | 0.80 | 9.04 |
| AMGAN-CR [79] | 0.23 | 96.96 | 0.87 | 11.38 |
| MemoryNet [81] | 3.64 | 1097.30 | 13.88 | 14.7 |
| MSDA-CR [80] | 2.94 | 106.89 | 15.30 | 6.74 |
| CVAE [25] | 15.29 | 92.88 | 58.31 | 4.15 |
| Ours | 5.85 | 36.09 | 22.31 | 8.18 |
| IRFT | GEFE | RICE1 | T-Cloud | Parameters | ||||
|---|---|---|---|---|---|---|---|---|
| mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | |||
| × | × | 34.76 | 96.68 | 0.0221 | 28.97 | 90.01 | 0.0732 | 2.67 M |
| × | ✓ | 35.32 | 97.21 | 0.0146 | 29.44 | 91.68 | 0.0581 | 3.03 M |
| ✓ | × | 35.44 | 96.82 | 0.0152 | 29.83 | 90.90 | 0.0649 | 5.49 M |
| ✓ | × * | 35.61 | 97.53 | 0.0119 | 30.12 | 91.73 | 0.0576 | 6.14 M |
| ✓ | ✓ | 36.19 | 98.06 | 0.0081 | 30.53 | 92.19 | 0.0528 | 5.85 M |
| RICE1 | T-Cloud | |||||||
|---|---|---|---|---|---|---|---|---|
| mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | |||
| ✓ | - | - | 33.77 | 97.03 | 0.0187 | 27.90 | 90.31 | 0.0712 |
| ✓ | ✓ | - | 34.25 | 97.30 | 0.0159 | 29.17 | 90.83 | 0.0682 |
| ✓ | - | ✓ | 35.52 | 97.52 | 0.0134 | 28.43 | 91.55 | 0.0639 |
| ✓ | ✓ | ✓ | 36.19 | 98.06 | 0.0081 | 30.53 | 92.19 | 0.0528 |
| Number of Heads | Sparsity | RICE1 | T-Cloud | ||||
|---|---|---|---|---|---|---|---|
| mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | mPSNR/dB ↑ | mSSIM/% ↑ | LPIPS ↓ | ||
| 4 | × | 36.06 | 98.02 | 0.0087 | 30.24 | 91.40 | 0.0593 |
| 4 | ✓ | 35.93 | 97.82 | 0.0091 | 30.38 | 91.72 | 0.0550 |
| 8 | × | 36.11 | 97.91 | 0.0083 | 30.59 | 92.07 | 0.0533 |
| 8 | ✓ | 36.19 | 98.06 | 0.0081 | 30.53 | 92.19 | 0.0528 |
| 16 | × | 36.01 | 97.67 | 0.0092 | 30.51 | 91.93 | 0.0549 |
| 16 | ✓ | 35.86 | 97.66 | 0.0092 | 30.54 | 92.03 | 0.0547 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Zhou, Y.; Gao, X.; Zhao, Y. Thin Cloud Removal Generative Adversarial Network Based on Sparse Transformer in Remote Sensing Images. Remote Sens. 2024, 16, 3658. https://doi.org/10.3390/rs16193658
Han J, Zhou Y, Gao X, Zhao Y. Thin Cloud Removal Generative Adversarial Network Based on Sparse Transformer in Remote Sensing Images. Remote Sensing. 2024; 16(19):3658. https://doi.org/10.3390/rs16193658
Chicago/Turabian StyleHan, Jinqi, Ying Zhou, Xindan Gao, and Yinghui Zhao. 2024. "Thin Cloud Removal Generative Adversarial Network Based on Sparse Transformer in Remote Sensing Images" Remote Sensing 16, no. 19: 3658. https://doi.org/10.3390/rs16193658
APA StyleHan, J., Zhou, Y., Gao, X., & Zhao, Y. (2024). Thin Cloud Removal Generative Adversarial Network Based on Sparse Transformer in Remote Sensing Images. Remote Sensing, 16(19), 3658. https://doi.org/10.3390/rs16193658