1. Introduction
Auroras are the most captivating manifestations of solar winds, which arise from the collision of charged particles ejected from the solar and molecules in the Earth’s upper atmosphere [
1]. Different shapes or colors of auroras are linked to the physical characteristics of the Earth’s atmosphere, and a variation in auroral morphology indicates the development of an auroral substorm. Akasofu [
2] modeled the development of an auroral substorm by different auroral morphology. Sado et al. [
3] attempted to predict magnetometer value with the integration of magnetometer data and auroral image. Therefore, classifying auroral images specifically by shape or color helps in discovering physical messages in near-Earth space and understanding the mechanisms of the phenomena caused by disturbances in the magnetosphere [
4]. All-sky imagers are the main source of auroral images, and they provide continuous observation of auroras with high resolution, which are conducive to analyzing auroral variation and morphology [
5].
Initially, auroral images are manually labeled [
6], which is not capable of leveraging an enormous number of auroral images. Traditional auroral image classification methods design features to correspond to different tasks and then feed classifiers with the extracted features [
7,
8]. Since it is difficult to distinguish complex auroral structures by using only a single feature to represent the image, methods are devised to model the correlation among different features [
9,
10]. Recently, deep learning networks for automatic feature extraction have rapidly evolved as handcraft feature-based aurora image classification methods relying on expert knowledge. Convolutional neural networks (CNN) are widely used in image classification tasks [
11,
12,
13,
14,
15,
16,
17,
18,
19], and several effective CNN architectures are utilized to classify auroral images [
15,
16]. In addition, CNNs can be considered feature extractors, and the features generated based on CNNs can be used to train classifiers [
17]. Yang et al. [
19] integrated multiwavelength information from auroral images to enhance classification performance. A CNN automatically extracts features in the local receptive field and aggregates all channels using the same weights. But the human visual system tends to focus more on essential and differential features. To apply such a mechanism in the computer vision domain, attention methods are introduced into different models.
Channel attention methods calculate attention scores for every channel and then rescale the input features. A large attention score means its corresponding component plays a crucial role in classification, and a small attention score indicates that the information needs to be suppressed. Squeeze-and-excitation networks (SENets) [
20] adaptively assign attention scores by simple operations: the SE block first applies global average pooling (GAP) to initialize each attention score, and two multi-layer perceptron (MLP) layers with nonlinear activation functions are followed to learn the interdependency among channels. Finally, attention scores are imposed on each channel to rescale the input features. Subsequently, the convolutional block attention module (CBAM) [
21] demonstrates the information loss during global pooling and addresses this issue by adding global max pooling (GMP) information. To better understand this problem, frequency channel attention (FcaNet) views channel compression as a discrete cosine transform (DCT) [
22] and points out that all frequency components still contain discriminative information, creating the need for a better way to initialize attention scores. Paralleling this channel attention strategy, the self-attention mechanism also advances image representation. It encodes the internal correlations within an image by assessing the mutual alignment of features via their query, key, and value representations. Transformer was originally proposed for natural language processing (NLP) problems by Vaswani et al. [
23], which is based on a pure self-attention mechanism. Hence, the Transformer architecture is adapted for image processing, giving rise to a multitude of Transformer variants tailored for visual tasks [
24,
25,
26,
27,
28]. While Transformers show superior performance on large datasets, their efficacy on smaller datasets is comparatively limited, as they possess less inductive bias than CNNs [
26]. Furthermore, the existing deep learning networks rarely explore feature distribution higher than first-order statistics.
Second-order statistics encapsulate the feature interdependencies, contributing to more discriminative representations than first-order statistics. These statistics, exemplified by covariance matrices, inhabit a curved manifold space as opposed to the flat Euclidean space, which presents challenges in exploring the geometric properties of the covariance matrix space. Aided by two pivotal metrics, the Log-Euclidean (Log-E) metric [
29] and Power-Euclidean (Pow-E) metric [
30], a multitude of methodologies are introduced to delve into the geometry of second-order statistics space [
29,
30,
31,
32,
33,
34]. Huang et al. [
32] built a deep Riemannian network for a symmetric positive definite (SPD) matrix involving the Log-E metric. Li et al. [
33] proposed matrix power normalized covariance (MPN-COV) by changing the way to calculate covariance and utilizing the Pow-E metric. Hu et al. [
34] exploited the manifold geometry by Log-E metric and adopted Riemannian manifold learning to obtain more compact and separatable CovDs. These methods successfully embed second-order statistics into deep networks, and MPN-COV presents slight differences between Log-E and Pow-E: the Log-E metric measures geodesic distance precisely, and the Pow-E metric measures it in a proximate way. They demonstrate that Pow-E acquires competitive results on large-scale datasets, but the efficiency of the above two metrics on task-specific datasets, like the auroral image dataset, is still unknown. Both second-order statistics and channel attention explore the feature correlation among channels; to learn more representative feature expression, second-order attention methods are proposed [
35,
36,
37,
38]. However, a limited number of methods are specifically designed for auroral image classification within this paradigm.
In conclusion, the main challenges in existing auroral image classification methods are summarized as follows: (1) existing CNN-based methods cannot directly exploit second-order statistics; (2) the interdependencies are not considered in feature representations. To address these two problems, a novel method named learning representative channel attention information from second-order statistics (LRCAISS) is proposed. Extensive experiments are conducted on two public auroral image datasets. The main contributions are as follows:
- (1)
A second-order convolutional network is built. The second-order statistics are exploited by calculating covariance matrices from CNN-based features. Experimental results demonstrate that the Log-E metric explores the geometry of covariance matrix space better than the Pow-E metric for auroral image classification.
- (2)
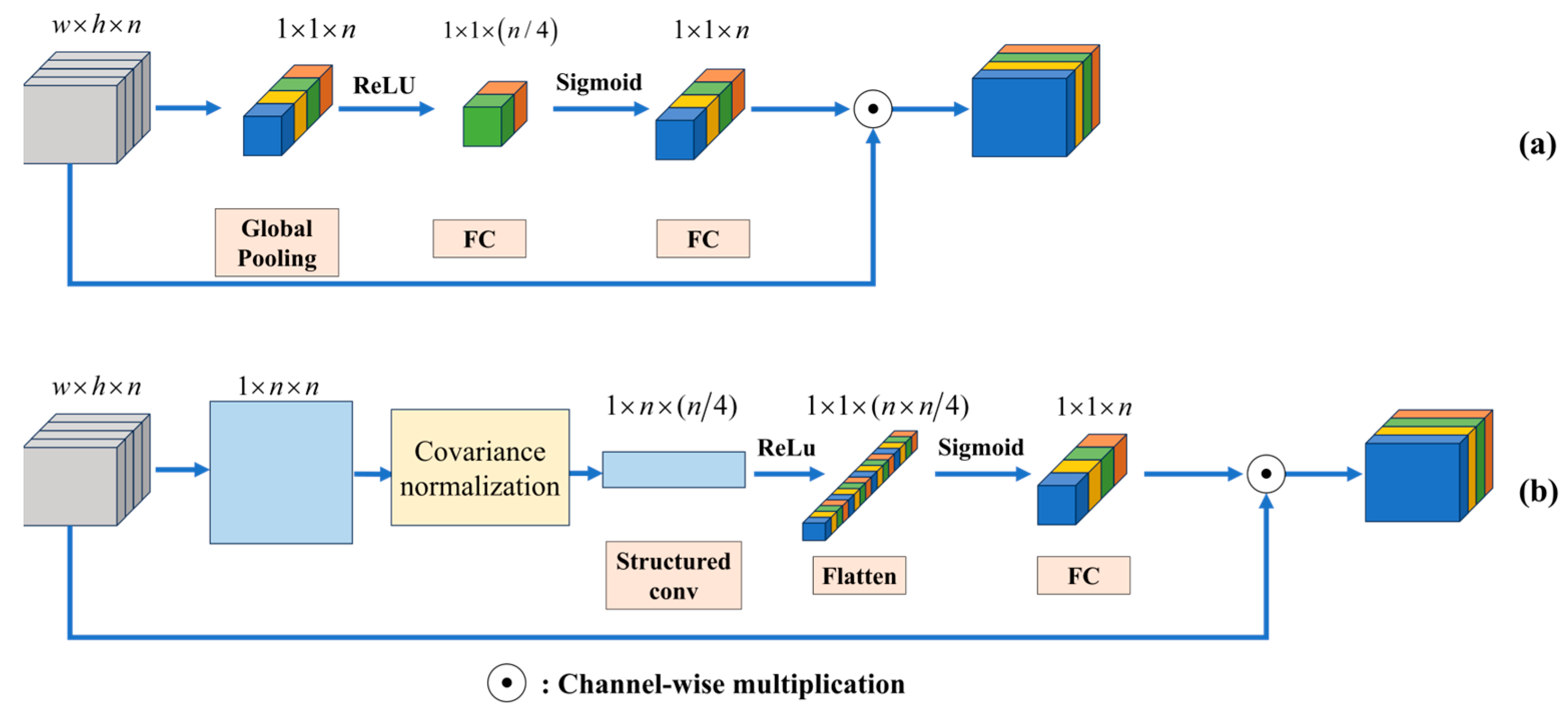
A novel second-order attention block is designed. LRCAISS learns attention scores from second-order statistics rather than first-order statistics and replaces covariance pooling with a trainable 1D convolutional layer to adaptively inherit more information from second-order statistics.
- (3)
Experimental results on two public datasets show the superiority of LRCAISS over existing auroral image classification and attention-based image classification methods.
4. Experiments
In this section, extensive experiments are conducted on the two datasets. The experiments are employed to find out the best configuration and then compare LRCAISS with other methods based on attention mechanisms and second-order statistics. The best results are bolded.
4.1. Effectiveness of Different Configurations
Several configurations in LRCAISS, namely, the backbone network settings, the attention blocks, and the metrics, that seem to have an impact on the results, and a series of experiments are employed on two ground-based auroral image datasets to analyze their performance. In this subsection, two datasets are divided into training sets and testing sets by four random seeds 42, 306, 3406, 114,514, to identify better configurations in a more generalized context.
Previous research only provides the difference between the two metrics theoretically but does not analyze them on specific tasks [
33]. The performances of two second-order channel attention methods with different metrics are shown in
Table 4. Generally, SCA + Log obtains the best results, and the Log-E metric outperforms the Pow-E metric. This demonstrates that the Log-E metric explores the geometric properties of covariance matrix space geometry better in the context of the second-order channel attention mechanism approach, and the Log-E metric is adopted in the subsequent experiments.
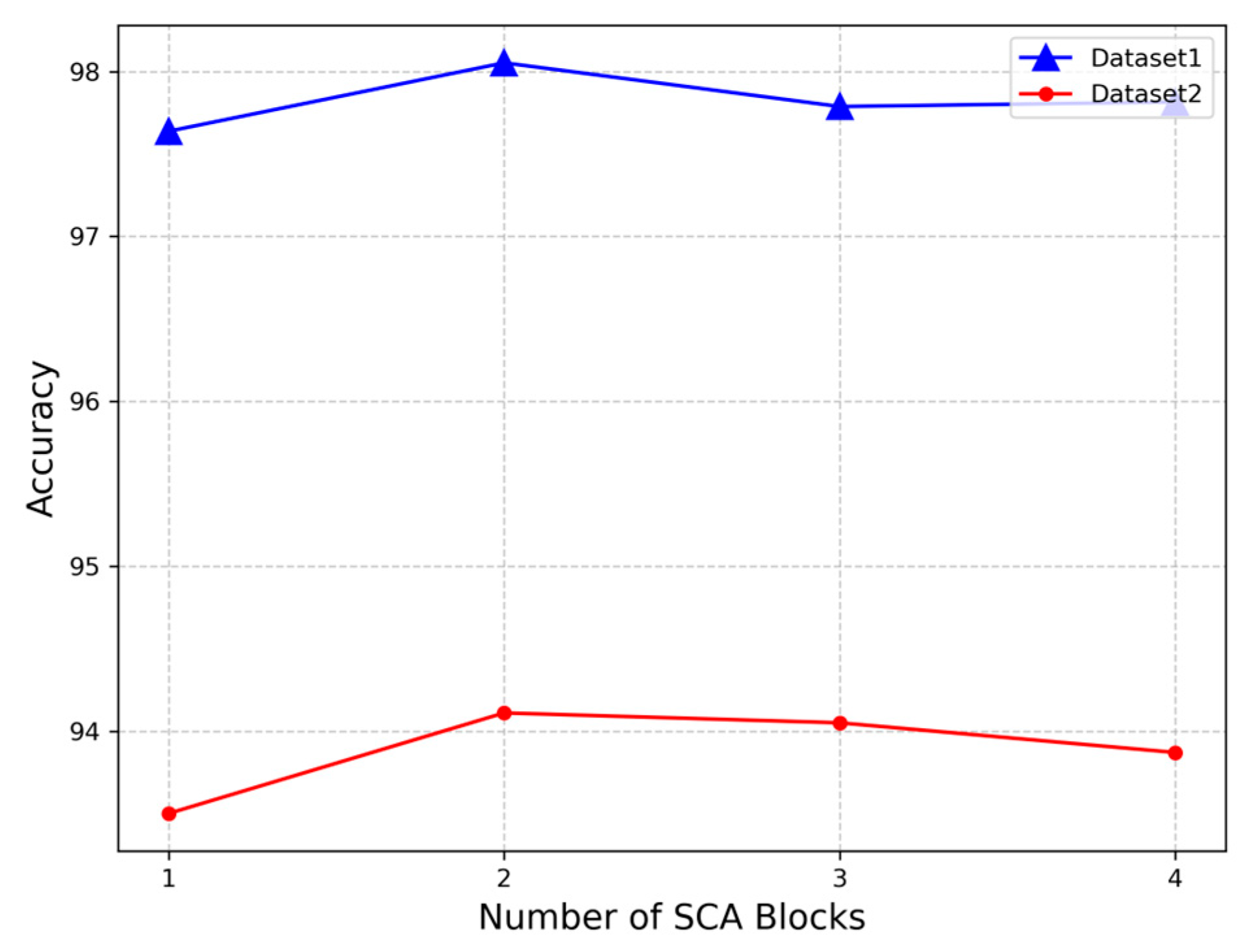
The SCA block can be cascaded multiple times to comprehensively capture channel attention information, and the optimal number of SCA blocks for aurora image classification is needed.
Figure 5 illustrates how accuracy varies with the number of SCA blocks ranging from one to four. The trend in classification accuracy change is similar across both datasets. Specifically, the accuracy peaks when there are two SCA blocks. However, deviating from this optimal number, either increasing or decreasing the count, leads to diminished classification accuracy. Hence, LRCAISS is designed with two SCA blocks.
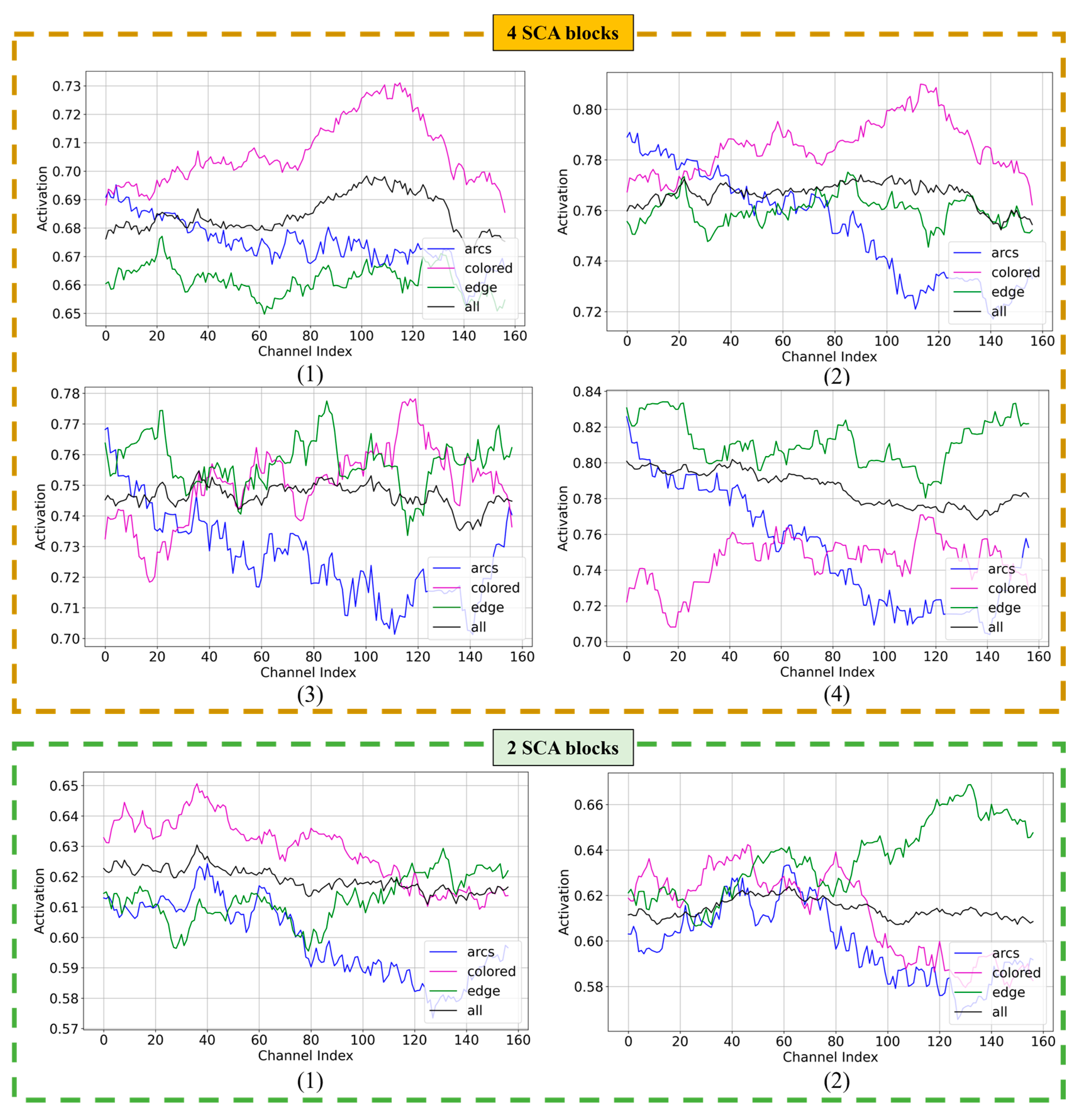
To further understand the second-order channel attention mechanism operating in LRCAISS, three classes of auroral images are sampled in Dataset 1, and the distribution of average channel attention activation is shown in
Figure 6. And the distribution of average activation over all classes is provided for comparison. Directly drawing the activation of each channel would result in an irregular graph, so shift smoothing is applied to enhance its clarity, and the horizontal coordinate is less than 256, the number of channels. The number below each graph denotes the distribution output by the corresponding SCA block, and larger activation values mean the channel plays a more important role in classification. As for the LRCAISS with four SCA blocks, the activation distributions of each SCA block are provided in the upper part of
Figure 6. From the first to the fourth block, the activation values become more class-specific. For LRCAISS with two SCA blocks, a consistent pattern is observed, which is that the variation in attentional values between channels increases progressively from the first to the second block. This suggests that the blocks help the network to better discern differences between classes. Furthermore, according to the results in
Figure 5, two blocks achieved the best performance. This may be because two blocks are sufficient to learn the necessary differences, while more blocks led to overfitting and fewer blocks did not capture enough distinctions. This phenomenon also suggests that directly cascading the SCA block may not significantly enhance the network’s representational capacity.
Generally, features extracted from the shallow layer contain basic information like texture and edge, and features from the deep layer concentrate more on the semantic representation, such as the holistic concept [
16]. Moreover, to better explore the discriminative ability of features extracted from different layers, the results are obtained by different configurations of the backbone network in
Table 5. The application of the backbone network, using the backbone ticked in Stage 1 of
Table 5 as an example, consists of Conv 1, Stage 1, and Conv 2. Obviously, the backbone with only Stage 1 achieves the best results on both datasets. The reason behind this is that second-order information may be more abundant in low-level features. Additionally, the classification accuracy on training sets with the four backbone configurations approaches 100%. However, with increasingly complex backbones, accuracy on the testing sets decreases, suggesting that complexity in the backbone architecture leads to overfitting.
Finally, the effectiveness of each component in LRCAISS is evaluated in
Table 6. The network with attention or second-order methods acquires higher classification accuracy than the network structure without either technique, which validates the effectiveness of the two mechanisms in auroral image classification. LRCAISS obtains the best results on the two datasets since the CovD captures more representative information from the feature map, and the channel attention mechanism allows the network to focus on vital features.
Following the aforementioned ablation study, the main component of LRCAISS for auroral image classification consists of the first stage of Resnet50, two SCA blocks, and a Log metric. Additionally, the two-layer MLP is configured, with the first layer having a dimension of 256 and the second layer’s dimension corresponding to the number of aurora image categories.
4.2. Main Results
To address the effectiveness of the LRCAISS, a series of auroral image classification methods [
16,
17], attention methods [
20,
27], and second-order statistics methods [
32,
34,
35] were evaluated. Novock et al. [
17] utilized pretrained inception-v4 to extract features by cutting off the FC layers and training ridge classifier, which is a concise and effective solution to auroral image classification. Zhong et al. [
16] utilized a pretrained CNN, which achieves competitive performance. Huang et al. [
32] opened the direction of SPD matrix non-linear learning in deep learning models by solving the backpropagation on the Stiefel manifold. SE network [
20] is a classic channel attention method, and SOCA [
35] mines the channel attention scores from second-order statistics. CrossVIT [
27] learns self-attention information, which is an improved version of VIT for more efficient and effective training. Hu et al. [
34] proposed a method named learning deep tensor feature representation (LDTFR) on the Riemannian manifold to improve auroral image classification performance on a small sample set.
Table 7 shows the classification accuracy of different methods on the two datasets. Obviously, LRCAISS outperforms the channel attention method and second-order convolutional networks, demonstrating the effectiveness of the integration of the two mechanisms. Moreover, LRCAISS also acquires better results than SOCA block since the proposed method improves the calculation of second-order statistics and utilizes a 1D convolutional layer to substitute the global covariance pooling to inherit more information.
Figure 7a exhibits the confusion matrix of predictions with Dataset 1. Except for
discrete and
faint, the classification accuracies of the other types are higher than 90%. The reason for the high rate of misclassification of
discrete is due to the small number of
discrete in Dataset 1, which makes it difficult for the model to capture its characteristic, and any misclassification will lead to a significant decrease in the accuracy of this category.
Figure 7b illustrates the confusion matrix of LRCAISS predictions of Dataset 2. Obviously, the proposed method recognizes the image types without auroral well, achieving precise detection of auroras. Misclassification occurs mostly among the three image types containing auroras since the classification criteria are occasionally ambiguous. Examples of misclassification are provided in the following section.
Table 8 shows the detailed performance assessment of Dataset 1.
Colored has the lowest precision of 84.85% and F1 score of 87.50%, and the rest of the categories show scores ranging from 89% to 100%. Therefore, LRCAISS achieves near-perfect performance for most classes of auroral images.
Discrete appears in various shapes and orientations of auroral arcs [
15], which makes the boundary between
discrete and other auroral images unclear, resulting in the largest misclassification.
Table 9 provides the results of each class in three evaluation metrics. The category
discrete also has the lowest precision of 88.56%, and
arcs has the lowest recall of 77.78%. Note that although some categories, like
discrete, are presented in both datasets, they are defined slightly differently.
Discrete is characterized by distinct auroras and sharp edges, but the auroras are not arc-shaped according to [
17]. There are times when the arc is incomplete, or the combination of multiple arcs makes the boundaries of the arcs not obvious, making it difficult to distinguish between
discrete and
arcs.
Figure 8a is derived from Dataset 1. The difference between
discrete and
arcs is in whether the auroral arc is complete in an image.
Figure 8a shows two discrete shapes connected in the middle of the image, which looks like an auroral arc with bright edges and a dark center, resulting in the misclassification from
discrete to
arcs.
Figure 8b–d are misclassified samples selected from Dataset 2. The bottom of
Figure 8b is arc-shaped, and it is incorrectly predicted as
arcs. The classification model recognizes a bright and well-defined auroral arc in
Figure 8c, but ignoring the boundary is ambiguous, and large patches of auroras are covered. Consequently, it is misclassified from
discrete to
arcs.
Figure 8d depicts multiple auroras in an image, but the shapes are not strictly arced.
5. Discussion
The LRCAISS method is distinguished from existing approaches to auroral image classification in several notable ways. In contrast to methods such as those used by Zhong et al. [
10] and Novock et al. [
17], which apply deep learning models to the domain of auroral image classification with minimal adaptation, LRCAISS modifies the Resnet50 backbone for more effective feature extraction. By integrating the SCA block to capture channel interdependencies and rescale feature maps, LRCAISS achieves significant accuracy improvements of at least 3.44% and 2.55% on the two datasets, respectively.
While Huang et al. [
32] concentrate on the dimension reduction of second-order statistics on the manifold, LRCAISS opts to control the size of second-order statistics by adjusting the dimensions of the final convolutional layer. Furthermore, by incorporating channel attention blocks, LRCAISS enhances the computation of second-order statistics, resulting in accuracy gains of 1.87% and 7.17% on the two datasets.
When compared to existing attention mechanisms, such as channel attention [
20] and self-attention methods [
27], LRCAISS demonstrates its superiority on auroral imager datasets. For instance, SENet [
20] derives attention scores from first-order statistics, namely the mean values of each feature map. In contrast, LRCAISS derives attention values from second-order statistics, considering the variances of each channel and the covariances between channels. This approach allows the SCA block to extract richer discriminative information, leading to higher accuracy improvements of 0.89% and 0.53% on the two datasets. One plausible explanation for this enhancement is that LRCAISS not only replicates SENet’s strategy of capturing channel interdependencies but also expands upon it by calculating second-order statistics, thereby acquiring a more detailed understanding of channel relationships. CrossVIT [
27] may necessitate larger datasets to achieve satisfactory results, indicating that LRCAISS could be more efficient in scenarios with limited data availability.
The SOCA [
35] method diverges from LRCAISS in two key respects: LRCAISS subtracts the mean vector of features when calculating second-order statistics, boosting feature robustness, which SOCA does not perform subtraction operation. Additionally, the initialization of the channel attention scores differs; while SOCA uses global covariance pooling, LRCAISS employs a learnable 1D convolutional layer to better assimilate information from second-order statistics. This distinction results in LRCAISS achieving higher accuracy increases of 3.66% and 2% on the two datasets.
6. Conclusions
This paper introduces a second-order channel attention network named LRCAISS for auroral image classification. Experimental results on two auroral image datasets demonstrate the generalization ability of the proposed method, underscoring the effectiveness of LRCAISS. It is superior to the traditional channel attention methods based on first-order statistics, showing the advantage of learning attention scores from second-order statistics over first-order counterparts. Moreover, LRCAISS outperforms methods relying solely on second-order convolutional networks, indicating that integrating an attention mechanism improves auroral representation learning. Thus, the dual mechanism approach enhances performance, facilitating more effective auroral analysis. However, the current implementation of LRCAISS runs with a long computation time, which could be a limitation when processing large-scale image datasets. Future research should concentrate on refining the computational efficiency and incorporating the latest deep learning models into LRCAISS for better effectiveness. Additionally, diverse attention mechanisms, such as spatial attention, are proven effective in the domain of image classification. Therefore, exploring their relationships and integrating their strengths holds promise for advancing auroral image processing.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}