
A Cross-Modal Semantic Alignment and Feature Fusion Method for Bionic Drone and Bird Recognition


Abstract
1. Introduction
- (1)
- Aiming to address the high visual similarity between bionic drones and birds, a CSAFF-based intelligent recognition approach for bionic drones and birds is proposed, which innovatively introduces motion behavior feature information, thus achieving robust discrimination of such targets.
- (2)
- The SAM and FFM were developed. By exploring the consistent semantic information between cross-modal data, more semantic clues are provided for robust target recognition. Additionally, through the full fusion of cross-modal features, the representational capability of cross-modal features is enhanced, improving the performance of our model.
- (3)
- Extensive experiments were conducted on datasets of bionic drones and birds. The experimental results show that, compared to other methods, the proposed CSAFF method achieves the best performance across various metrics. Further experimental analysis demonstrates the effectiveness of each designed module.
2. Proposed Method
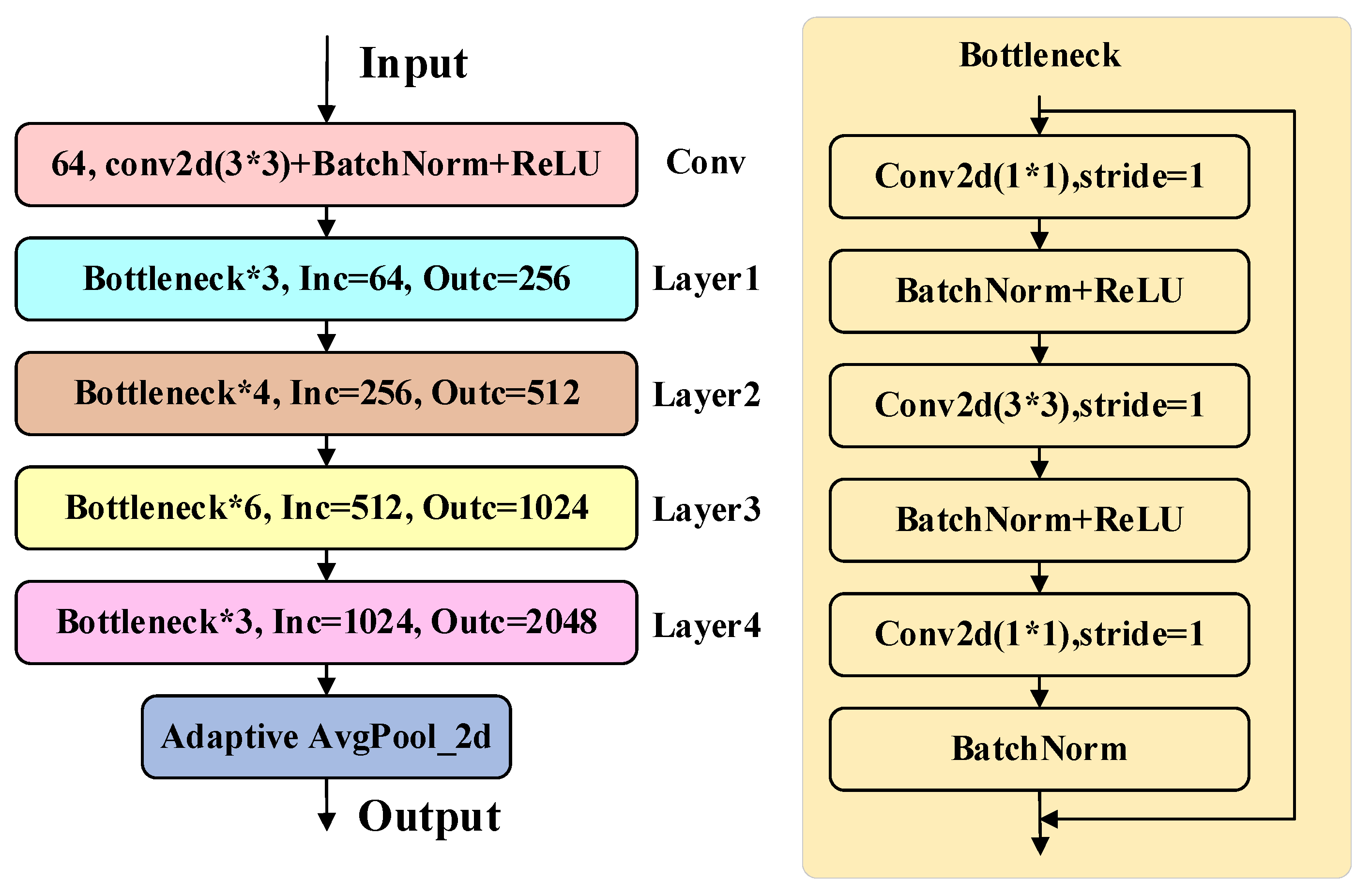
2.1. Overall Architecture
| Algorithm 1 Cross-modal semantic alignment and feature fusion (CSAFF) algorithm. |
| Input: Image data , sequence data , and corresponding class labels {1 or 0} Output: Class of unlabeled data {bionic drones or birds}
|
2.2. Representation of Motion Behavior Information
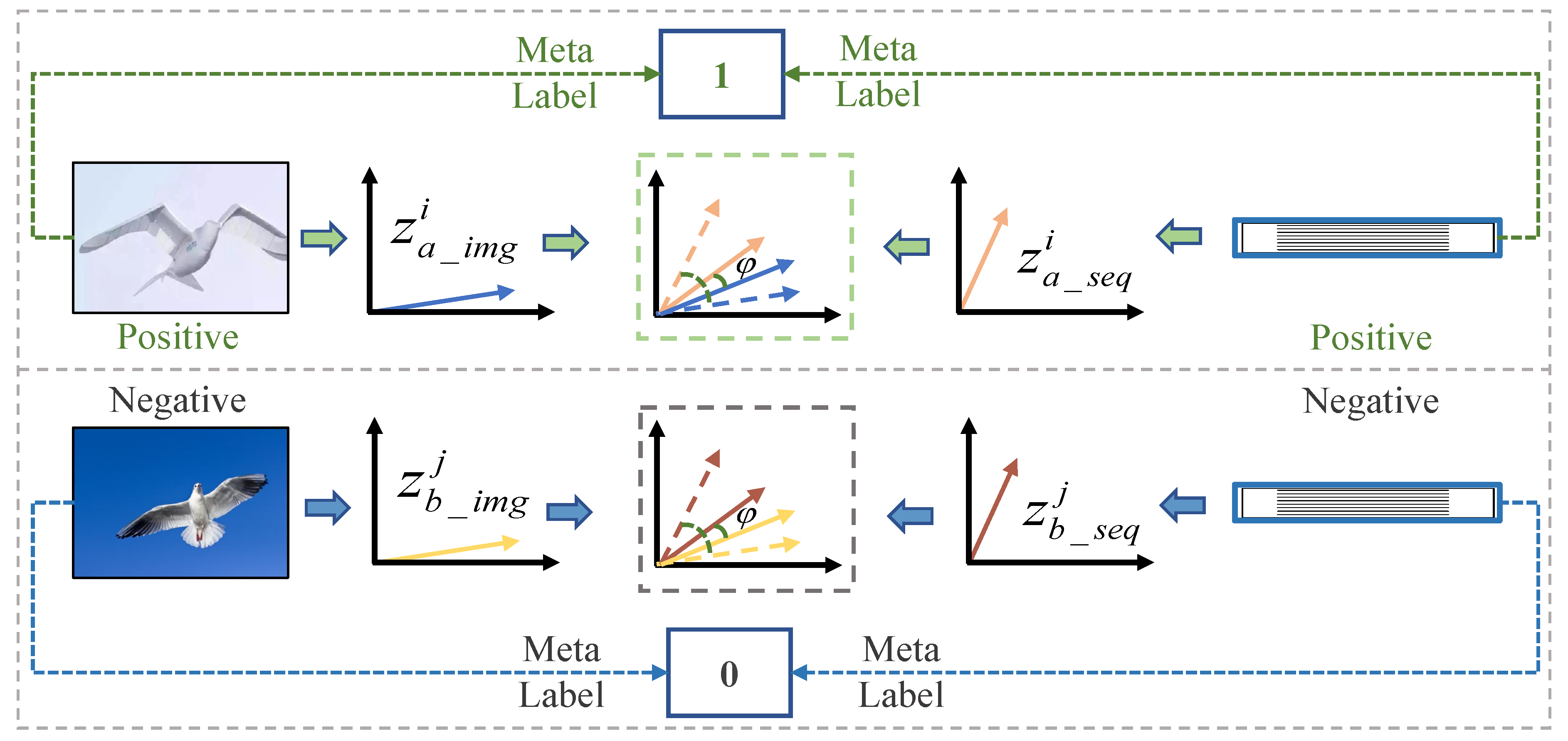
2.3. Semantic Alignment Module (SAM)
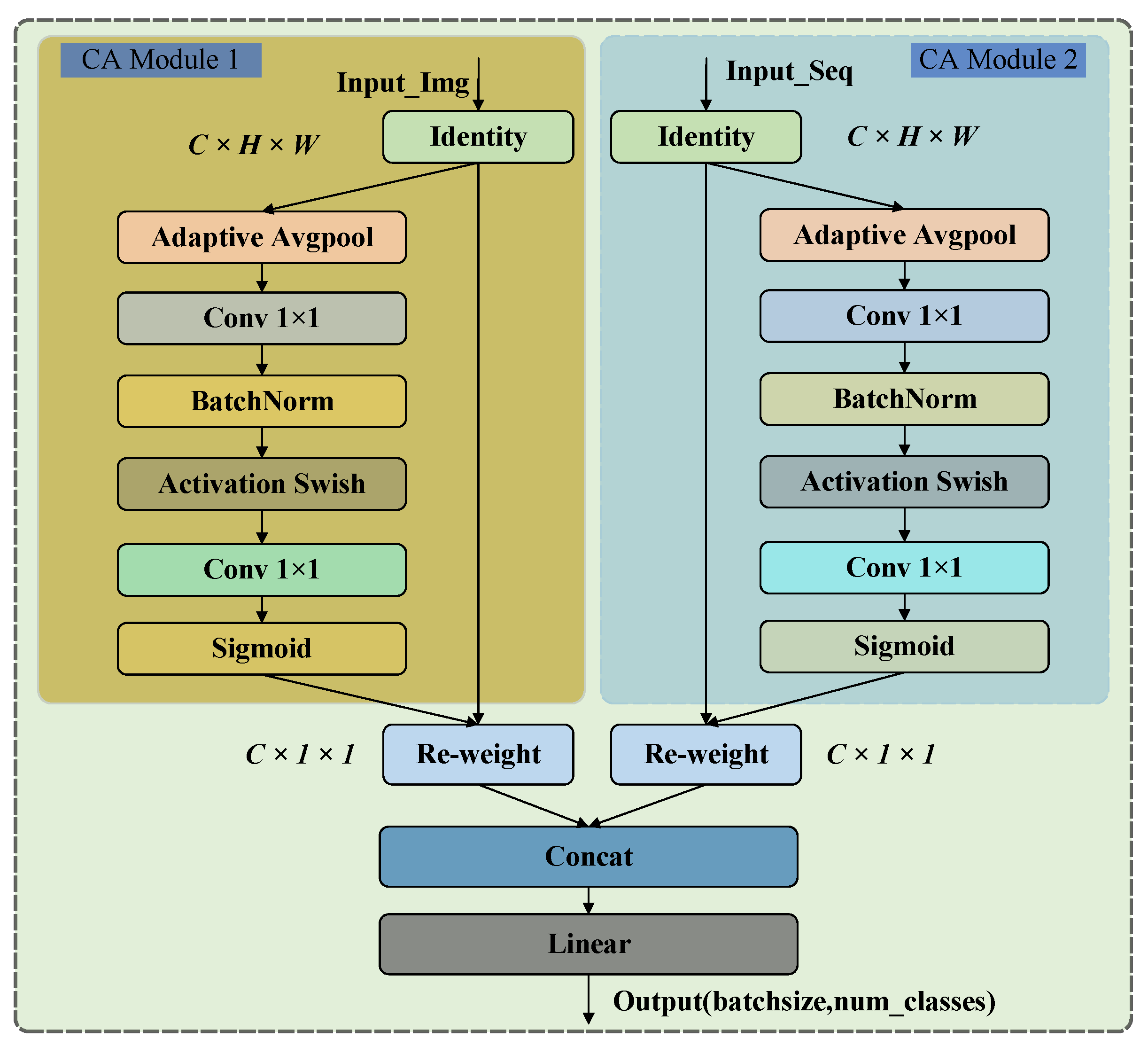
2.4. Feature Fusion Module (FFM)
2.5. Objective Loss Function
3. Experiments
3.1. Experimental Setup
3.1.1. Datasets
3.1.2. Evaluation Criteria
3.1.3. Implementation Details
3.2. Comparisons with State-of-the-Art Methods
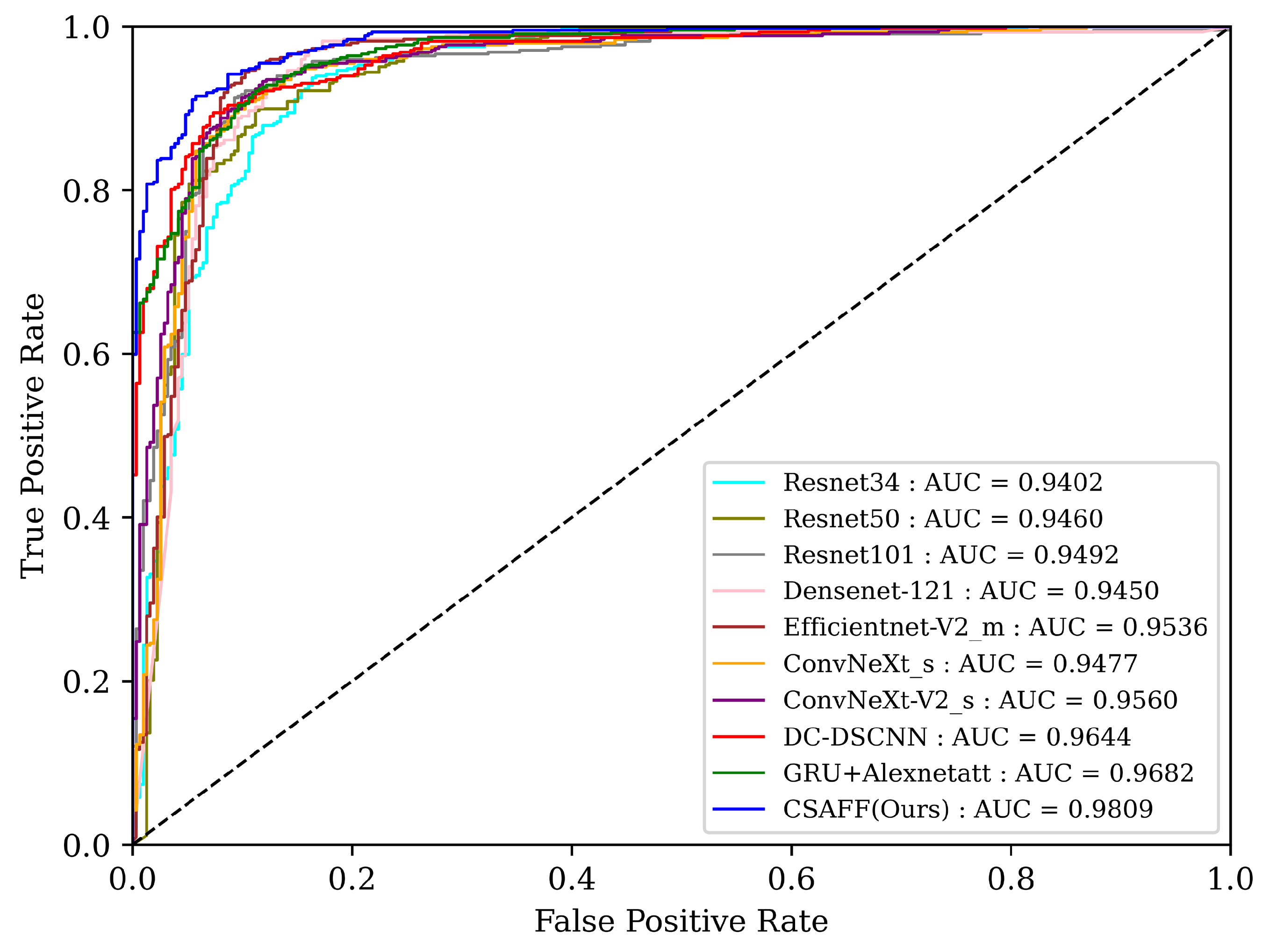
3.2.1. Quantitative Evaluation
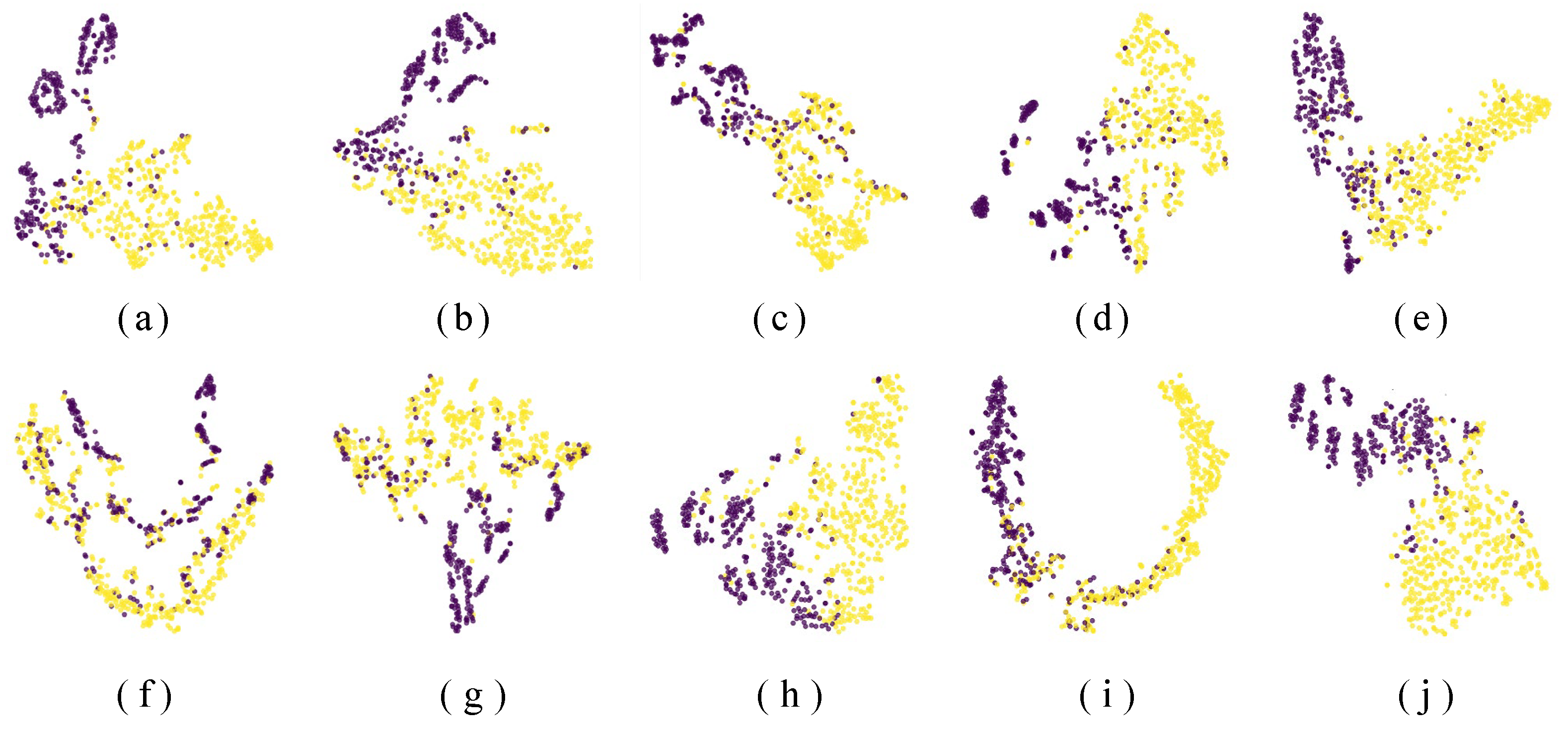
3.2.2. Qualitative Evaluation
3.3. Further Analysis of the Model
3.3.1. Ablation Studies
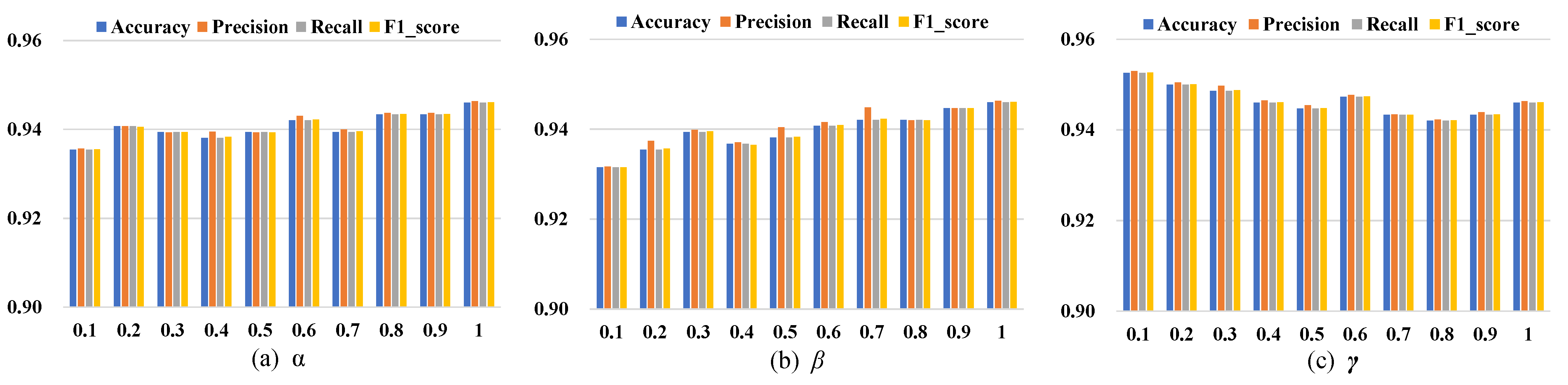
3.3.2. Sensitivity of Hyperparameter
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ross, P.E.; Romero, J.J.; Jones, W.D.; Bleicher, A.; Calamia, J.; Middleton, J.; Stevenson, R.; Moore, S.K.; Upson, S.; Schneider, D.; et al. Top 11 technologies of the decade. IEEE Spectr. 2010, 48, 27–63. [Google Scholar] [CrossRef]
- Avola, D.; Cannistraci, I.; Cascio, M.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Lanzino, R.; Mancini, M.; Mecca, A.; et al. A novel GAN-based anomaly detection and localization method for aerial video surveillance at low altitude. Remote Sens. 2022, 14, 4110. [Google Scholar] [CrossRef]
- Ritchie, M.; Fioranelli, F.; Griffiths, H.; Torvik, B. Micro-drone RCS analysis. In Proceedings of the IEEE Radar Conference, Johannesburg, South Africa, 27–30 October 2015; pp. 452–456. [Google Scholar]
- Rahman, S.; Robertson, D.A. In-flight RCS measurements of drones and birds at K-band and W-band. IET Radar Sonar Navig. 2019, 13, 300–309. [Google Scholar] [CrossRef]
- Rojhani, N.; Shaker, G. Comprehensive Review: Effectiveness of MIMO and Beamforming Technologies in Detecting Low RCS UAVs. Remote Sens. 2024, 16, 1016. [Google Scholar] [CrossRef]
- Torvik, B.; Olsen, K.E.; Griffiths, H. Classification of Birds and UAVs Based on Radar Polarimetry. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1305–1309. [Google Scholar] [CrossRef]
- Wu, S.; Wang, W.; Deng, J.; Quan, S.; Ruan, F.; Guo, P.; Fan, H. Nearshore Ship Detection in PolSAR Images by Integrating Superpixel-Level GP-PNF and Refined Polarimetric Decomposition. Remote Sens. 2024, 16, 1095. [Google Scholar] [CrossRef]
- Du, L.; Wang, P.; Liu, H.; Pan, M.; Chen, F.; Bao, Z. Bayesian spatiotemporal multitask learning for radar HRRP target recognition. IEEE Trans. Signal Process. 2011, 59, 3182–3196. [Google Scholar] [CrossRef]
- Pan, M.; Du, L.; Wang, P.; Liu, H.; Bao, Z. Noise-robust modification method for Gaussian-based models with application to radar HRRP recognition. IEEE Geosci. Remote Sens. Lett. 2012, 10, 558–562. [Google Scholar] [CrossRef]
- Yoon, S.W.; Kim, S.B.; Jung, J.H.; Cha, S.B.; Baek, Y.S.; Koo, B.T.; Choi, I.O.; Park, S.H. Efficient classification of birds and drones considering real observation scenarios using FMCW radar. J. Electromagn. Eng. Sci. 2021, 21, 270–281. [Google Scholar] [CrossRef]
- Han, L.; Feng, C. High-Resolution Imaging and Micromotion Feature Extraction of Space Multiple Targets. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 6278–6291. [Google Scholar]
- Li, K.m.; Liang, X.j.; Zhang, Q.; Luo, Y.; Li, H.j. Micro-Doppler signature extraction and ISAR imaging for target with micromotion dynamics. IEEE Geosci. Remote Sens. Lett. 2010, 8, 411–415. [Google Scholar] [CrossRef]
- Luo, J.h.; Wang, Z.y. A review of development and application of UAV detection and counter technology. J. Control Decis. 2022, 37, 530–544. [Google Scholar]
- Molchanov, P.; Harmanny, R.I.; de Wit, J.J.; Egiazarian, K.; Astola, J. Classification of small UAVs and birds by micro-Doppler signatures. Int. J. Microw. Wirel. Technolog. 2014, 6, 435–444. [Google Scholar] [CrossRef]
- Ren, J.; Jiang, X. Regularized 2-D complex-log spectral analysis and subspace reliability analysis of micro-Doppler signature for UAV detection. Pattern Recognit. 2017, 69, 225–237. [Google Scholar] [CrossRef]
- Ritchie, M.; Fioranelli, F.; Borrion, H.; Griffiths, H. Multistatic micro-Doppler radar feature extraction for classification of unloaded/loaded micro-drones. IET Radar Sonar Navig. 2017, 11, 116–124. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Oh, H.M.; Lee, H.; Kim, M.Y. Comparing Convolutional Neural Network(CNN) models for machine learning-based drone and bird classification of anti-drone system. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 15–18 October 2019; pp. 87–90. [Google Scholar]
- Liu, Y.; Liu, J. Recognition and classification of rotorcraft by micro-Doppler signatures using deep learning. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 141–152. [Google Scholar]
- Hanif, A.; Muaz, M. Deep Learning Based Radar Target Classification Using Micro-Doppler Features. In Proceedings of the 2021 Seventh International Conference on Aerospace Science and Engineering (ICASE), Islamabad, Pakistan, 14–16 December 2021; pp. 1–6. [Google Scholar]
- Kim, B.K.; Kang, H.S.; Park, S.O. Drone Classification Using Convolutional Neural Networks With Merged Doppler Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 38–42. [Google Scholar] [CrossRef]
- Kim, J.H.; Kwon, S.Y.; Kim, H.N. Spectral-Kurtosis and Image-Embedding Approach for Target Classification in Micro-Doppler Signatures. Electronics 2024, 13, 376. [Google Scholar] [CrossRef]
- Liu, L.; Li, Y. PolSAR Image Classification with Active Complex-Valued Convolutional-Wavelet Neural Network and Markov Random Fields. Remote Sens. 2024, 16, 1094. [Google Scholar] [CrossRef]
- Takeki, A.; Trinh, T.T.; Yoshihashi, R.; Kawakami, R.; Iida, M.; Naemura, T. Combining deep features for object detection at various scales: Finding small birds in landscape images. IPSJ Trans. Comput. Vis. Appl. 2016, 8, 1–7. [Google Scholar] [CrossRef]
- Zhang, H.; Diao, S.; Yang, Y.; Zhong, J.; Yan, Y. Multi-scale image recognition strategy based on convolutional neural network. J. Comput. Electron. Inf. Manag. 2024, 12, 107–113. [Google Scholar] [CrossRef]
- Wang, R.; Ding, F.; Chen, J.W.; Liu, B.; Zhang, J.; Jiao, L. SAR Image Change Detection Method via a Pyramid Pooling Convolutional Neural Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 312–315. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hong, M.; Choi, J.; Kim, G. StyleMix: Separating Content and Style for Enhanced Data Augmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14862–14870. [Google Scholar]
- Seyfioğlu, M.S.; Gürbüz, S.Z. Deep Neural Network Initialization Methods for Micro-Doppler Classification with Low Training Sample Support. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2462–2466. [Google Scholar] [CrossRef]
- Weishi, C.; Liu, J.; Chen, X.; Li, J. Non-cooperative UAV target recognition in low-altitude airspace based on motion model. J. B. Univ. Aeronaut. Astronaut. 2019, 45, 687–694. [Google Scholar]
- Liu, J.; Xu, Q.; Chen, W. Motion feature extraction and ensembled classification method based on radar tracks for drones. J. Syst. Eng. Electron. 2023, 45, 3122. [Google Scholar]
- Sun, Y.; Ren, G.; Qu, L.; Liu, Y. Classification of rotor UAVs based on dual-channel GoogLeNet network. Telecommun. Eng. 2022, 62, 1106. [Google Scholar]
- He, S.; Wang, W.; Wang, Z.; Xu, X.; Yang, Y.; Wang, X.; Shen, H.T. Category Alignment Adversarial Learning for Cross-Modal Retrieval. IEEE Trans. Knowl. Data Eng. 2023, 35, 4527–4538. [Google Scholar] [CrossRef]
- Tian, X.; Bai, X.; Zhou, F. Recognition of Micro-Motion Space Targets Based on Attention-Augmented Cross-Modal Feature Fusion Recognition Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–9. [Google Scholar] [CrossRef]
- Wang, M.; Sun, Y.; Xiang, J.; Sun, R.; Zhong, Y. Joint Classification of Hyperspectral and LiDAR Data Based on Adaptive Gating Mechanism and Learnable Transformer. Remote Sens. 2024, 16, 1080. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, S.; Li, B.; Yin, C. Cross-modal sentiment sensing with visual-augmented representation and diverse decision fusion. Sensors 2021, 22, 74. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Qian, Y.; Guo, Q.; Cheng, H.; Liang, J. AF: An Association-Based Fusion Method for Multi-Modal Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9236–9254. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.; Nguyen, D.T.; Zeng, R.; Nguyen, T.T.; Tran, S.N.; Nguyen, T.; Sridharan, S.; Fookes, C. Deep Auto-Encoders with Sequential Learning for Multimodal Dimensional Emotion Recognition. IEEE Trans. Multimed. 2022, 24, 1313–1324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, F.; Luo, J.; Wang, L.; Liu, W.; Sang, X. GCF2-Net: Global-aware cross-modal feature fusion network for speech emotion recognition. Front. Neurosci. 2023, 17, 1183132. [Google Scholar] [CrossRef] [PubMed]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. CMGFNet: A deep cross-modal gated fusion network for building extraction from very high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 184, 96–115. [Google Scholar] [CrossRef]
- Shou, Y.; Cao, X.; Meng, D.; Dong, B.; Zheng, Q. A Low-rank Matching Attention based Cross-modal Feature Fusion Method for Conversational Emotion Recognition. arXiv 2023, arXiv:2306.17799. [Google Scholar]
- Lymburn, T.; Algar, S.D.; Small, M.; Jüngling, T. Reservoir computing with swarms. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 033121. [Google Scholar] [CrossRef]
- Chieng, H.H.; Wahid, N.; Ong, P.; Perla, S.R.K. Flatten-T Swish: A thresholded ReLU-Swish-like activation function for deep learning. Int. J. Adv. Intell. Inform. 2018, 4, 76–86. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Liu, X.; Chen, M.; Liang, T.; Lou, C.; Wang, H.; Liu, X. A lightweight double-channel depthwise separable convolutional neural network for multimodal fusion gait recognition. Math. Biosci. Eng. 2022, 19, 1195–1212. [Google Scholar] [CrossRef]
- Narotamo, H.; Dias, M.; Santos, R.; Carreiro, A.V.; Gamboa, H.; Silveira, M. Deep learning for ECG classification: A comparative study of 1D and 2D representations and multimodal fusion approaches. Biomed. Signal Process. Control 2024, 93, 106141. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | Positive | Negative | |
|---|---|---|---|
| Actual | |||
| Positive | |||
| Negative | |||
| Method | Accuracy | Precision | Recall | F1_Score | Confusion_Matrix | Param. (M) | Inf. Time (ms) |
|---|---|---|---|---|---|---|---|
| Resnet34 [17] | 87.75% | 87.90% | 87.75% | 87.79% | 21.30 | 0.37 | |
| Resnet50 [17] | 88.41% | 88.39% | 88.41% | 88.36% | 23.57 | 0.44 | |
| Resnet101 [17] | 88.93% | 89.01% | 88.93% | 88.96% | 42.61 | 0.70 | |
| Densenet-121 [51] | 89.20% | 89.26% | 89.20% | 89.22% | 7.04 | 0.51 | |
| Efficientnet-V2_m [52] | 89.72% | 89.72% | 89.72% | 89.68% | 53.80 | 0.76 | |
| ConvNeXt_s [53] | 89.33% | 89.31% | 89.33% | 89.31% | 27.84 | 0.56 | |
| ConvNeXt-V2_s [54] | 89.99% | 89.97% | 89.99% | 89.97% | 27.85 | 0.60 | |
| DC-DSCNN [55] | 91.70% | 91.76% | 91.70% | 91.72% | 2.06 | 0.13 | |
| GRU + Alexnetatt [56] | 92.49% | 92.49% | 92.49% | 92.49% | 38.48 | 0.38 | |
| CSAFF (Ours) | 95.25% | 95.30% | 95.26% | 95.27% | 29.03 | 0.46 |
| Method | Accuracy | Precision | Recall | F1_Score | Confusion_Matrix |
|---|---|---|---|---|---|
| Baseline | 92.36% | 92.45% | 92.36% | 92.38% | |
| Ours w/o FFM | 93.15% | 93.21% | 93.15% | 93.16% | |
| Ours w/o SAM | 93.94% | 94.07% | 93.94% | 93.96% | |
| Ours (Full) | 95.25% | 95.30% | 95.26% | 95.27% |
| Method | Accuracy | Precision | Recall | F1_Score | Confusion_Matrix | Param. (M) | Inf. Time (ms) | |
|---|---|---|---|---|---|---|---|---|
| Single Img_Modal | Resnet50 | 88.41% | 88.39% | 88.41% | 88.36% | 23.57 | 0.44 | |
| Single Seq_Modal | Resnet18 | 88.93% | 89.18% | 88.93% | 88.98% | 4.38 | 0.10 | |
| Full_Modal | CSAFF (Ours) | 95.25% | 95.30% | 95.26% | 95.27% | 29.03 | 0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, D.; Zhang, M.; Wan, J.; Liu, S.; Zhu, H.; Liu, Q. A Cross-Modal Semantic Alignment and Feature Fusion Method for Bionic Drone and Bird Recognition. Remote Sens. 2024, 16, 3121. https://doi.org/10.3390/rs16173121
Liu H, Li D, Zhang M, Wan J, Liu S, Zhu H, Liu Q. A Cross-Modal Semantic Alignment and Feature Fusion Method for Bionic Drone and Bird Recognition. Remote Sensing. 2024; 16(17):3121. https://doi.org/10.3390/rs16173121
Chicago/Turabian StyleLiu, Hehao, Dong Li, Ming Zhang, Jun Wan, Shuang Liu, Hanying Zhu, and Qinghua Liu. 2024. "A Cross-Modal Semantic Alignment and Feature Fusion Method for Bionic Drone and Bird Recognition" Remote Sensing 16, no. 17: 3121. https://doi.org/10.3390/rs16173121
APA StyleLiu, H., Li, D., Zhang, M., Wan, J., Liu, S., Zhu, H., & Liu, Q. (2024). A Cross-Modal Semantic Alignment and Feature Fusion Method for Bionic Drone and Bird Recognition. Remote Sensing, 16(17), 3121. https://doi.org/10.3390/rs16173121