


An Auditory Convolutional Neural Network for Underwater Acoustic Target Timbre Feature Extraction and Recognition


Abstract
:1. Introduction
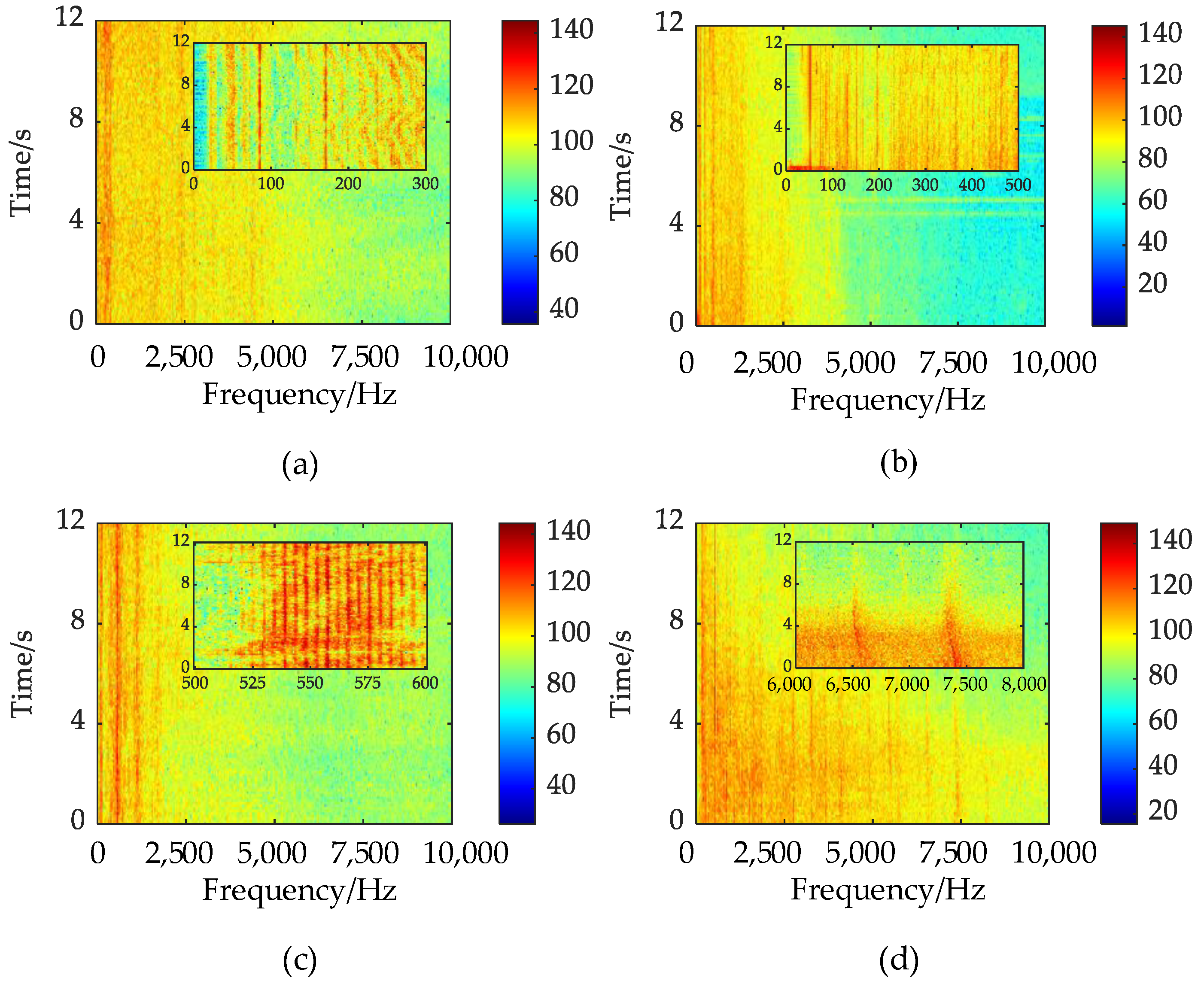
2. Line Spectra of Underwater Acoustic Targets
3. ACNN
3.1. Auditory Mechanisms
3.2. Model Structure and Theory
3.2.1. Frequency Perception Module
3.2.2. Timbre Perception Module
3.2.3. Critical Information Perception Module
- (1)
- The underwater acoustic target-radiated noise signal can be viewed as a superposition of simple harmonic components, and the average value of any sub-band signal is roughly 0. Therefore, sub-band features cannot be effectively extracted using global average pooling.
- (2)
- Although the maximum value of each sub-band signal can characterize the properties of the target, the result of the maximum pooling operation is highly random due to the interference of ambient noise.
3.3. ACNN_DRACNN
4. UATR Experiment
4.1. Introduction to the Dataset
4.2. Experiments and Analysis of Results
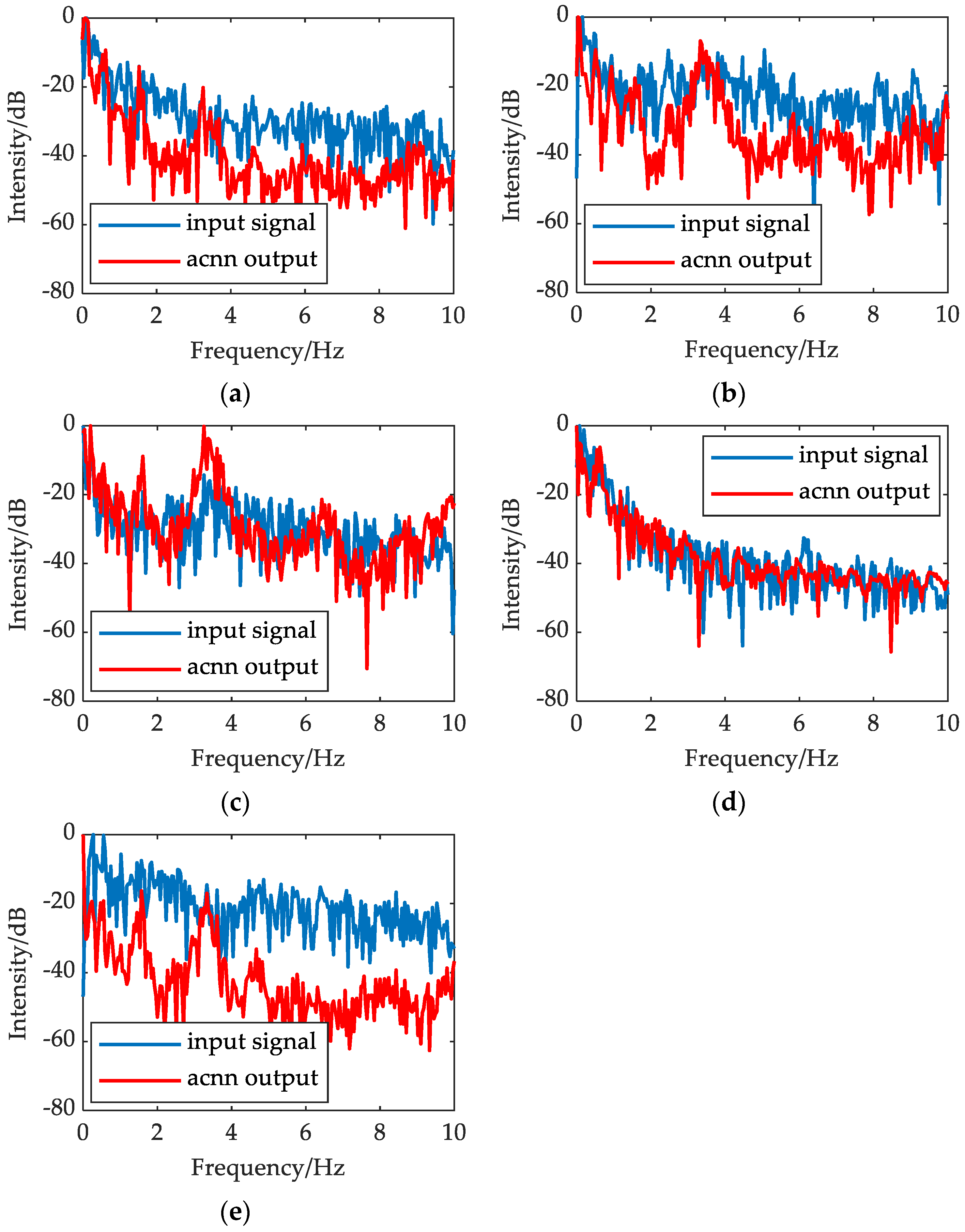
4.3. Visualization of Features
5. Conclusions
- (1)
- The design idea of the model is inspired by the human hearing mechanism, the feature extraction process is very interpretable, and the data processing results show that the finer the decomposition of the original signal, the higher the target recognition accuracy that can be achieved.
- (2)
- In this paper, a new global pooling method called a GEP layer is proposed, which integrates traditional features with deep learning, and can provide higher recognition accuracy and recognition result confidence for the network model compared with global maximum pooling and global average pooling.
- (3)
- The ACNN_DRACNN model achieves 99.8% recognition accuracy on the ShipsEar dataset, which is a 2.7% improvement over the DRACNN model, and it has better-integrated performance than DarkNet, MobileNet, CRNN and other current state-of-the-art methods.
- (1)
- Expanding the dataset using simulation data or data augmentation, to improve the recognition and generalization ability under sample imbalance and missing data for typical operating conditions.
- (2)
- Mining the time-correlation features and transient working condition features in the original signal to improve the ability of portraying the essential characteristics of underwater acoustic targets.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full Name |
| UATR | Underwater acoustic target recognition |
| CNN | Convolutional neural network |
| GAN | Generative adversarial network |
| ACNN | Auditory convolutional neural network |
| DEMON | Detection of envelope modulation on noise |
| LOFAR | Low frequency analysis and recording |
| GAP | Global average pooling |
| GMP | Global maximum pooling |
| GEP | Global energy pooling |
| CA | Channel attention |
| DRACNN | Deep residual attention convolutional neural networks |
| RACB | Residual attention convolution blocks |
| ERB | Equivalent rectangular bandwidth |
References
- Luo, X.W.; Chen, L.; Zhou, H.L.; Cao, H.L. A Survey of Underwater Acoustic Target Recognition Methods Based on Machine Learning. J. Mar. Sci. Eng. 2023, 11, 384. [Google Scholar] [CrossRef]
- Jiang, J.G.; Wu, Z.N.; Lu, J.N.; Huang, M.; Xiao, Z.Z. Interpretable features for underwater acoustic target recognition. Measurement 2020, 173, 108586. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, X.C.; Liu, D.L. Design and Optimization of 1D-CNN for Spectrum Recognition of Underwater Targets. Integr. Ferroelectr. 2021, 218, 164–179. [Google Scholar] [CrossRef]
- Kim, K.I.; Pak, M.I.; Chon, B.P.; Ri, C.H. A method for underwater acoustic signal classification using convolutional neural network combined with discrete wavelet transform. Int. J. Wavelets Multiresolut. Inf. Process. 2021, 19, 2050092. [Google Scholar] [CrossRef]
- Yao, Q.H.; Wang, Y.; Yang, Y.X. Underwater Acoustic Target Recognition Based on Data Augmentation and Residual CNN. Electronics 2023, 12, 1206. [Google Scholar] [CrossRef]
- Chen, L.; Luo, X.W.; Zhou, H.L. A ship-radiated noise classification method based on domain knowledge embedding and attention mechanism. Eng. Appl. Artif. Intell. 2024, 127, 10732. [Google Scholar] [CrossRef]
- Ju, Y.; Wei, Z.X.; Li, H.F.; Feng, X. A New Low SNR Underwater Acoustic Signal Classification Method Based on Intrinsic Modal Features Maintaining Dimensionality Reduction. Pol. Marit. Res. 2020, 27, 187–198. [Google Scholar] [CrossRef]
- Yao, H.Y.; Gao, T.; Wang, Y.; Wang, H.Y.; Chen, X. Mobile_ViT: Underwater Acoustic Target Recognition Method Based on Local–Global Feature Fusion. J. Mar. Sci. Eng. 2024, 12, 589. [Google Scholar] [CrossRef]
- Luo, X.W.; Zhang, M.H.; Liu, T.; Huang, M.; Xu, X.G. An Underwater Acoustic Target Recognition Method Based on Spectrograms with Different Resolutions. J. Mar. Sci. Eng. 2021, 9, 1246. [Google Scholar] [CrossRef]
- Ouyang, T.; Zhang, Y.J.; Zhao, H.L.; Cui, Z.W.; Yang, Y.; Xu, Y.J. A multi-color and multistage collaborative network guided by refined transmission prior for underwater image enhancement. Vis. Comput. 2024. [Google Scholar] [CrossRef]
- Yildiz, E.; Yuksel, M.E.; Sevgen, S. A Single-Image GAN Model Using Self-Attention Mechanism and DenseNets. Neurocomputing 2024, 596, 127873. [Google Scholar] [CrossRef]
- Ji, F.; Ni, J.S.; Li, G.N.; Liu, L.L.; Wang, Y.Y. Underwater Acoustic Target Recognition Based on Deep Residual Attention Convolutional Neural Network. J. Mar. Sci. Eng. 2023, 11, 1626. [Google Scholar] [CrossRef]
- Hong, F.; Liu, C.W.; Guo, L.J.; Chen, F.; Feng, H.H. Underwater Acoustic Target Recognition with a Residual Network and the Optimized Feature Extraction Method. Appl. Sci. 2021, 11, 1442. [Google Scholar] [CrossRef]
- Li, J.; Wang, B.X.; Cui, X.R.; Li, S.B.; Liu, J.H. Underwater Acoustic Target Recognition Based on Attention Residual Network. Entropy 2022, 24, 1657. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.Q.; Li, S.; Li, D.H.; Wang, Z.C.; Zhou, Q.X.; You, Q.X. Sonar image quality evaluation using deep neural network. IET Image Process. 2022, 16, 992–999. [Google Scholar] [CrossRef]
- Ashraf, H.; Shah, B.; Soomro, A.M.; Safdar, Q.A.; Halim, Z.; Shah, S.K. Ambient-noise Free Generation of Clean Underwater Ship Engine Audios from Hydrophones using Generative Adversarial Networks. Comput. Electr. Eng. 2022, 100, 107970. [Google Scholar]
- Wang, Z.; Liu, L.W.; Wang, C.Y.; Deng, J.J.; Zhang, K.; Yang, Y.C.; Zhou, J.B. Data Enhancement of Underwater High-Speed Vehicle Echo Signals Based on Improved Generative Adversarial Networks. Electronics 2022, 11, 2310. [Google Scholar] [CrossRef]
- Jin, G.H.; Liu, F.; Wu, H.; Song, Q.Z. Deep Learning-Based Framework for Expansion, Recognition and Classification of Underwater Acoustic Signal. J. Exp. Theor. Artif. Intell. 2019, 32, 205–218. [Google Scholar] [CrossRef]
- Ge, F.X.; Bai, Y.Y.; Li, M.J.; Zhu, G.P.; Yin, J.W. Label distribution-guided transfer learning for underwater source localization. J. Acoust. Soc. Am. 2022, 151, 4140–4149. [Google Scholar] [CrossRef]
- Ji, F.; Li, G.N.; Lu, S.Q.; Ni, J.S. Research on a Feature Enhancement Extraction Method for Underwater Targets Based on Deep Autoencoder Networks. Appl. Sci. 2024, 14, 1341. [Google Scholar] [CrossRef]
- Hao, Y.K.; Wu, X.J.; Wang, H.Y.; He, X.Y.; Hao, C.P.; Wang, Z.R.; Hu, Q. Underwater Reverberation Suppression via Attention and Cepstrum Analysis-Guided Network. J. Mar. Sci. Eng. 2023, 11, 313. [Google Scholar] [CrossRef]
- Li, Y.X.; Gu, Z.Y.; Fan, X.M. Research on Sea State Signal Recognition Based on Beluga Whale Optimization-Slope Entropy and One Dimensional-Convolutional Neural Network. Sensors 2024, 24, 1680. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.L.; Shen, W.H.; Cao, W.J.; Hou, W.M.; Wang, B.Z. Design of Siamese Network for Underwater Target Recognition with Small Sample Size. Appl. Sci. 2022, 12, 10659. [Google Scholar] [CrossRef]
- Li, N.; Wang, L.B.; Ge, M.; Unoki, M.; Li, S.; Dang, J.W. Robust voice activity detection using an auditory-inspired masked modulation encoder based convolutional attention network. Speech Commun. 2024, 157, 103024. [Google Scholar] [CrossRef]
- Li, J.H.; Yang, H.H. The underwater acoustic target timbre perception and recognition based on the auditory inspired deep convolutional neural network. Appl. Acoust. 2021, 182, 108210. [Google Scholar] [CrossRef]
- Yang, H.H.; Li, J.H.; Shen, S.; Xu, G.H. A Deep Convolutional Neural Network Inspired by Auditory Perception for Underwater Acoustic Target Recognition. Sensors 2019, 19, 1104. [Google Scholar] [CrossRef]
- Reiterer, S.; Erb, M.; Grodd, W.; Wildgruber, D. Cerebral Processing of Timbre and Loudness: fMRI Evidence for a Contribution of Broca’s Area to Basic Auditory Discrimination. Brain Imaging Behav. 2008, 2, 1–10. [Google Scholar] [CrossRef]
- Occelli, F.; Suied, C.; Pressnitzer, D.; Edeline, J.M.; Gourévitch, B. A Neural Substrate for Rapid Timbre Recognition? Neural and Behavioral Discrimination of Very Brief Acoustic Vowels. Cereb. Cortex 2016, 26, 2483–2496. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Kilian, Q.W. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Pathak, D.; Raju, U. Shuffled-Xception-DarkNet-53: A content-based image retrieval model based on deep learning algorithm. Comput. Electr. Eng. 2023, 107, 108647. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Liu, F.; Shen, T.S.; Luo, Z.L.; Zhao, D.; Guo, S.J. Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation. Appl. Acoust. 2021, 178, 107989. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Type of Vessel | Files | Duration |
|---|---|---|---|
| A | Fishing boats, trawlers, mussel boats, tugboats, dredgers | 17 | 1880 |
| B | Motor boats, pilot boats, sailboats | 19 | 1567 |
| C | Passenger ferries | 30 | 4276 |
| D | Ocean liners, ro-ro vessels | 12 | 2460 |
| E | Background noise recordings | 12 | 1145 |
| Category | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| A | 99.83 | 99.83 | 99.83 | 99.83 |
| B | 99.82 | 99.99 | 99.82 | 99.91 |
| C | 99.99 | 99.72 | 99.99 | 99.86 |
| D | 99.87 | 99.87 | 99.87 | 99.87 |
| E | 99.85 | 99.99 | 99.85 | 99.92 |
| Average | 99.87 | 99.88 | 99.87 | 99.88 |
| No. | Model | Accuracy (%) | Params (M) | Flops (G) |
|---|---|---|---|---|
| 1 | DenseNet [29] | 90.15 | 6.96 | 0.610 |
| 2 | DarkNet [30] | 96.68 | 40.59 | 1.930 |
| 3 | RepVGG [31] | 97.05 | 7.83 | 0.420 |
| 4 | CRNN [32] | 91.44 | 3.88 | 0.110 |
| 5 | Auto-encoder [20] | 93.32 | 0.18 | 0.410 |
| 6 | ResNet [13] | 94.97 | 0.33 | 0.110 |
| 7 | A-ResNet [14] | 98.19 | 9.47 | 1.460 |
| 8 | MobileNet [8] | 94.02 | 2.23 | 0.140 |
| 9 | DRACNN [12] | 97.10 | 0.26 | 0.005 |
| 10 | ACNN_DRACNN | 99.87 | 0.61 | 0.013 |
| SNR (dB) | −20 | −15 | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|---|---|
| A | 63.7 | 78.5 | 75.5 | 84.9 | 95.1 | 98.8 | 99.5 |
| B | 65.9 | 79.6 | 80.3 | 85.0 | 97.4 | 99.1 | 99.4 |
| C | 68.2 | 73.7 | 79.4 | 86.2 | 97.1 | 99.0 | 99.6 |
| D | 52.5 | 67.0 | 77.8 | 84.8 | 96.9 | 98.5 | 99.6 |
| E | 81.2 | 92.1 | 94.3 | 97.2 | 98.4 | 99.0 | 99.9 |
| Average | 66.3 | 78.2 | 81.5 | 87.6 | 97.0 | 98.9 | 99.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Ji, F.; Lu, S.; Feng, W. An Auditory Convolutional Neural Network for Underwater Acoustic Target Timbre Feature Extraction and Recognition. Remote Sens. 2024, 16, 3074. https://doi.org/10.3390/rs16163074
Ni J, Ji F, Lu S, Feng W. An Auditory Convolutional Neural Network for Underwater Acoustic Target Timbre Feature Extraction and Recognition. Remote Sensing. 2024; 16(16):3074. https://doi.org/10.3390/rs16163074
Chicago/Turabian StyleNi, Junshuai, Fang Ji, Shaoqing Lu, and Weijia Feng. 2024. "An Auditory Convolutional Neural Network for Underwater Acoustic Target Timbre Feature Extraction and Recognition" Remote Sensing 16, no. 16: 3074. https://doi.org/10.3390/rs16163074
APA StyleNi, J., Ji, F., Lu, S., & Feng, W. (2024). An Auditory Convolutional Neural Network for Underwater Acoustic Target Timbre Feature Extraction and Recognition. Remote Sensing, 16(16), 3074. https://doi.org/10.3390/rs16163074