
Enhanced Dual-Channel Model-Based with Improved Unet++ Network for Landslide Monitoring and Region Extraction in Remote Sensing Images



Abstract
1. Introduction
1.1. Background and Motivation
1.2. Contribution
2. Methodology
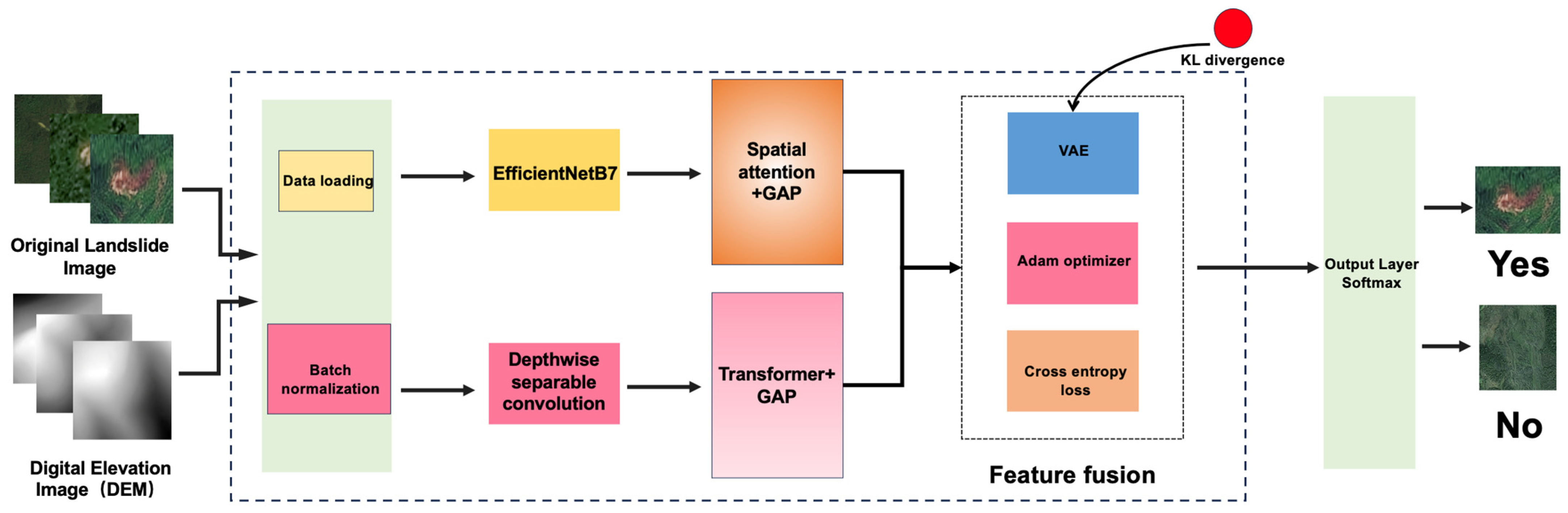
2.1. Enhanced Dual-Channel Model
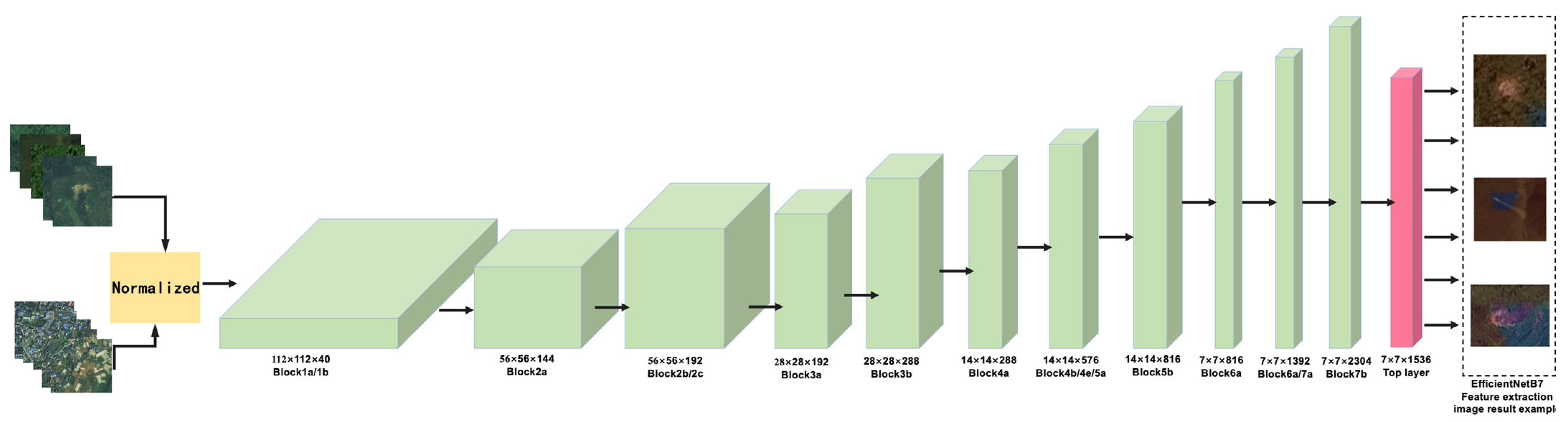
2.1.1. Image Pathway
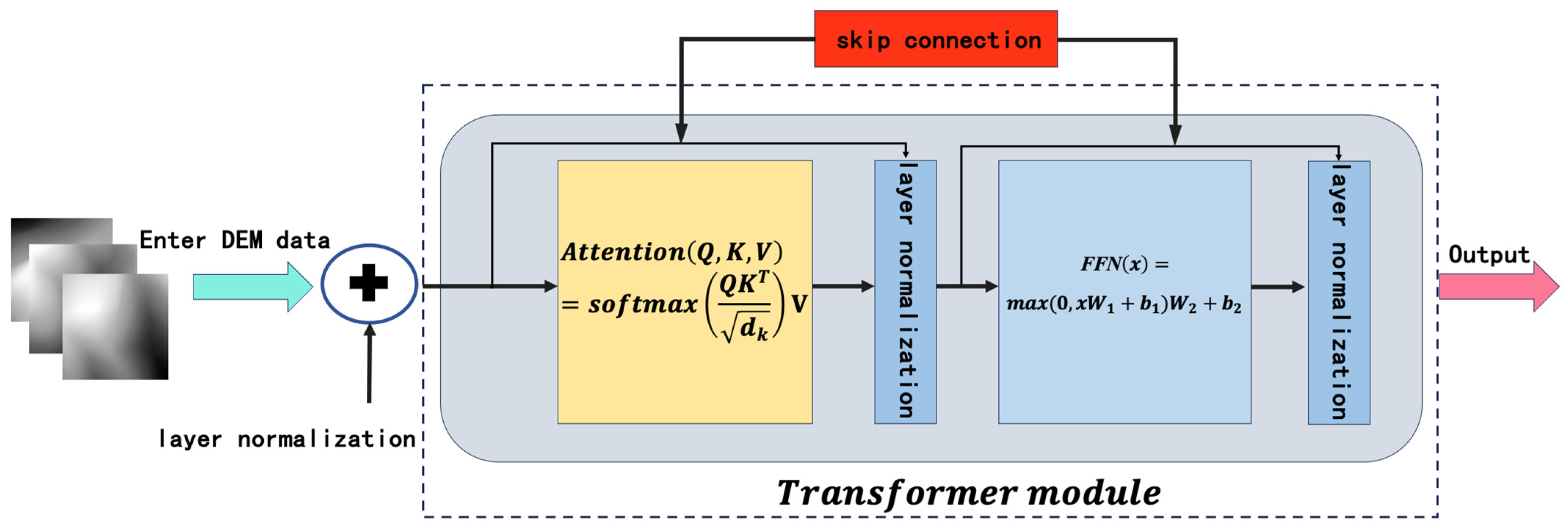
2.1.2. DEM Pathway
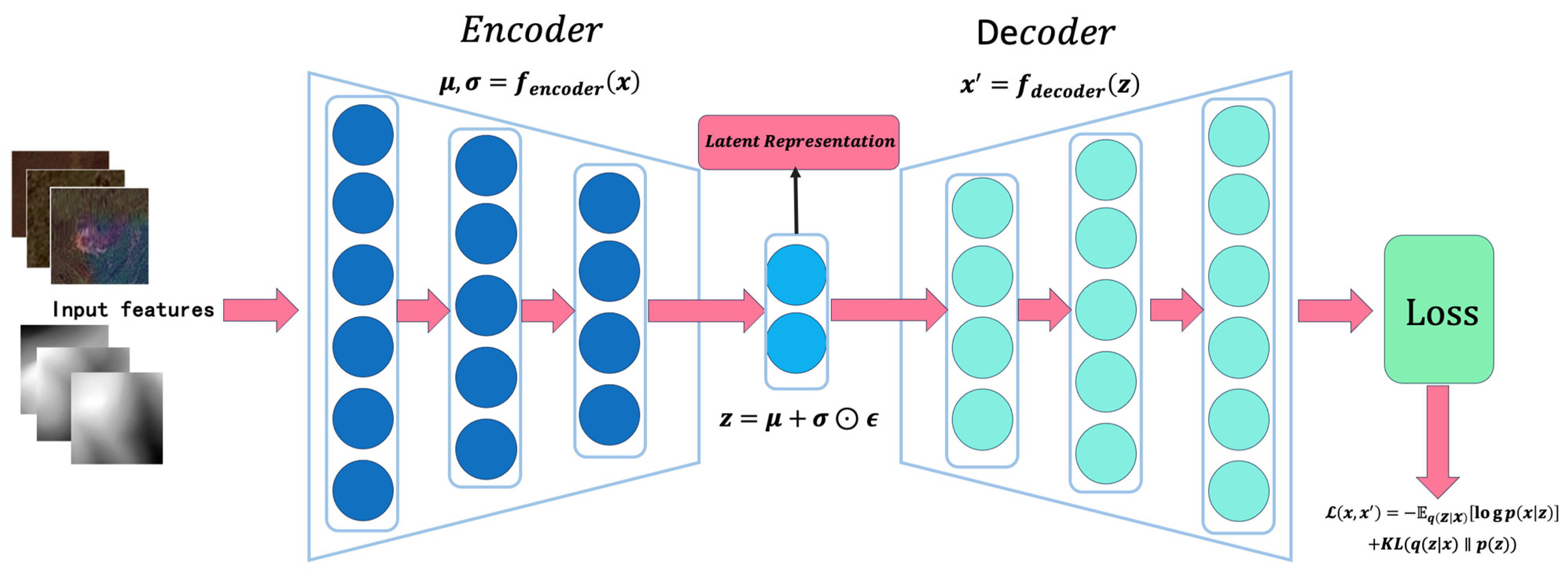
2.1.3. Feature Fusion
- (1)
- Encoder Module:
- (2)
- Latent Space Sampling:
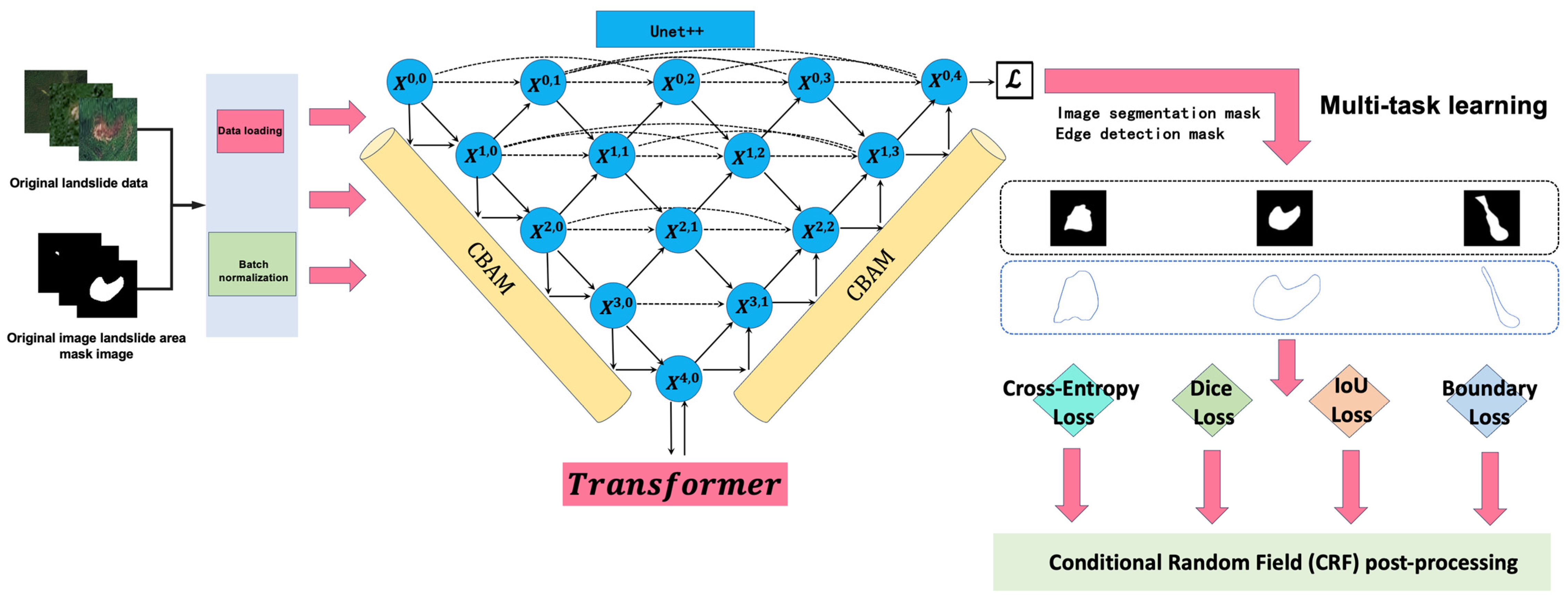
2.2. Improving the Unet++ Network for Image Region Extraction: DCT-Unet++ Model
2.2.1. Encoder
2.2.2. Convolutional Blocks
2.2.3. Decoder
2.2.4. CBAM Modules: Feature Recalibration and Attention Mechanisms
2.2.5. Composite Loss Function
2.3. Conditional Random Fields (CRFs) for Post-Processing of the DCT-Unet++ Model
2.3.1. Probabilistic Refinement
2.3.2. Spatial Consistency Enhancement
3. Experimental Results and Analysis
3.1. The Design of Experiments
3.1.1. Selection of Models for Comparison
- (1)
- Models on the landslide image recognition task
- (2)
- Models on image segmentation task
3.1.2. Selection of Indicators for Model Evaluation
3.1.3. Experimental Conditions and Hyperparameter Tuning
3.1.4. Datasets
- (1)
- Bijie Landslide Dataset
- (2)
- Landslide4Sens Dataset
- (3)
- CAS Landslide Dataset
3.2. Experiments on Dataset 1: The Bijie Landslide Dataset
3.2.1. Landslide Image Recognition Performance
- (1)
- Enhanced Dual-Channel Model
- (2)
- Comparative Analysis
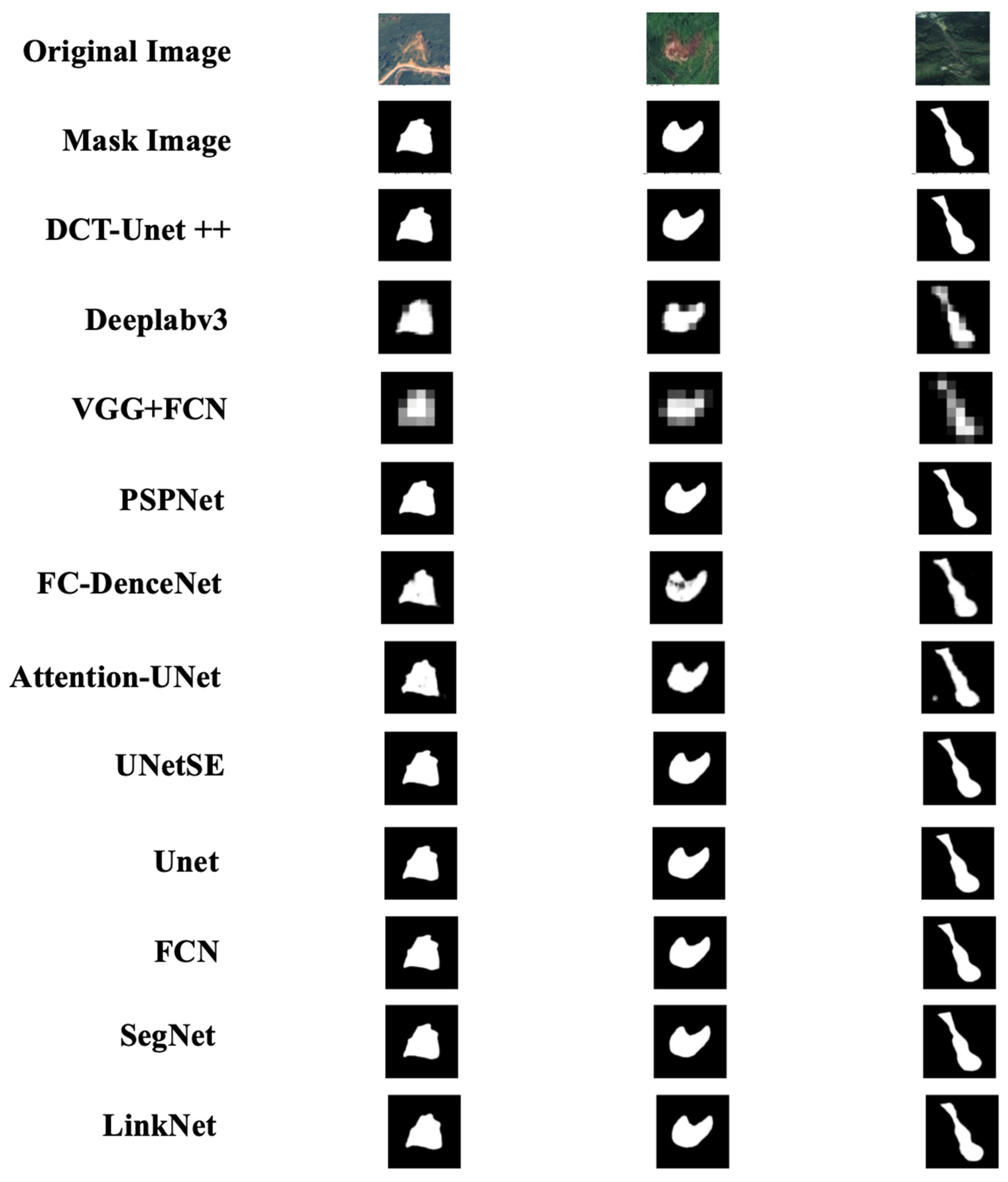
3.2.2. DCT-Unet++ Model Performance in Landslide Image Segmentation
- (1)
- DCT-Unet++ Model
- (2)
- Comparative Analysis
3.3. Experiments on Dataset 2: Landslide4Sense Dataset
3.3.1. Landslide Image Recognition Performance
- (1)
- Enhanced Dual-Channel Model
- (2)
- Comparative Analysis:
3.3.2. DCT-Unet++ Model Performance in Landslide Area Extraction
- (1)
- DCT-Unet++ Model
- (2)
- Comparative Analysis:
3.4. Experiments on Dataset 3: CAS Landslide Dataset
4. Discussion
4.1. Generalizability and Universality of Model Algorithms
4.2. Comparative Analysis and Model Superiority
4.3. Future Research Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wagner, C.S. Mental models of flash floods and landslides. Risk Anal. 2007, 27, 671–682. [Google Scholar] [CrossRef] [PubMed]
- Scaioni, M.; Longoni, L.; Melillo, V.; Papini, M. Remote Sensing for Landslide Investigations: An Overview of Recent Achievements and Perspectives. Remote Sens. 2014, 6, 9600–9652. [Google Scholar] [CrossRef]
- Stanley, T.; Kirschbaum, D.B. A heuristic approach to global landslide susceptibility mapping. Nat. Hazards 2017, 8, 145–164. [Google Scholar] [CrossRef] [PubMed]
- Medina, V.; Hürlimann, M.; Guo, Z.; Lloret, A.; Vaunat, J. Fast physically-based model for rainfall-induced landslide susceptibility assessment at regional scale. Catena 2021, 201, 105213. [Google Scholar] [CrossRef]
- Guo, Z.; Torra, O.; Hürlimann, M.; Abancó, C.; Medina, V. FSLAM: A QGIS plugin for fast regional susceptibility assessment of rainfall-induced landslides. Environ. Model. Softw. 2022, 150, 105354. [Google Scholar] [CrossRef]
- Wu, L.; Liu, R.; Li, G.; Gou, J.; Lei, Y. Landslide Detection Methods Based on Deep Learning in Remote Sensing Images. In Proceedings of the 2022 29th International Conference on Geoinformatics, Beijing, China, 15–18 August 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Bui, T.-A.; Lee, P.-J.; Lum, K.; Loh, C.; Tan, K. Deep Learning for Landslide Recognition in Satellite Architecture. IEEE Access 2020, 8, 143665–143678. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Gao, O.; Niu, C.; Liu, W.; Li, T.; Zhang, H.; Hu, Q. E-DeepLabV3+: A Landslide Detection Method for Remote Sensing Images. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; Volume 10, pp. 573–577. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, Y.; Cui, P.; Liang, L.; Pirasteh, S.; Marcato, J.; Gonçalves, W.; Li, J. Accurate landslide detection leveraging UAV-based aerial remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 12, 5047–5060. [Google Scholar] [CrossRef]
- Lissak, C.M.; Leister, A.; Zakharov, I.A. Remote Sensing for Assessing Landslides and Associated Hazards. Int. J. Remote Sens. 2020, 41, 1391–1435. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Z.; Yu, H.; Zhou, S.; Jiang, H.; Guo, Y. Comparison of landslide detection based on different deep learning algorithms. In Proceedings of the 2022 3rd International Conference on Geology, Mapping and Remote Sensing (ICGMRS), Zhoushan, China, 22–24 April 2022; pp. 158–162. [Google Scholar] [CrossRef]
- Wang, K.; Han, L. A Study of High-Resolution Remote Sensing Image Landslide Detection with Optimized Anchor Boxes and Edge Enhancement. Eur. J. Remote Sens. 2023, 2289616. [Google Scholar] [CrossRef]
- Ye, C.; Li, Y.; Cui, P.; Liang, L.; Pirasteh, S.; Marcato, J.; Gonçalves, W.; Li, J. Landslide Detection of Hyperspectral Remote Sensing Data Based on Deep Learning with Constraints. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5047–5060. [Google Scholar] [CrossRef]
- Li, H.; He, Y.; Xu, Q.; Deng, J.; Li, W.; Wei, Y.; Zhou, J. Semantic segmentation of loess landslides with STAPLE mask and fully connected conditional random field. Landslides 2023, 20, 367–380. [Google Scholar] [CrossRef]
- Zhou, N.; Hong, J.; Cui, W.; Wu, S.; Zhang, Z. A Multiscale Attention Segment Network-Based Semantic Segmentation Model for Landslide Remote Sensing Images. Remote Sens. 2024, 16, 1712. [Google Scholar] [CrossRef]
- Piralilou, S.T.; Shahabi, H.; Jarihani, B.; Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Aryal, J. Landslide Detection Using Multi-Scale Image Segmentation and Different Machine Learning Models in the Higher Himalayas. Remote Sens. 2019, 11, 2575. [Google Scholar] [CrossRef]
- Soares, L.P.; Dias, H.C.; Garcia, G.P.B.; Grohmann, C.H. Landslide Segmentation with Deep Learning: Evaluating Model Generalization in Rainfall-Induced Landslides in Brazil. Remote Sens. 2022, 14, 2237. [Google Scholar] [CrossRef]
- Liu, X.; Peng, Y.; Lu, Z.; Li, W.; Yu, J.; Ge, D. Feature-Fusion Segmentation Network for Landslide Detection Using High-Resolution Remote Sensing Images and Digital Elevation Model Data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4500314. [Google Scholar] [CrossRef]
- Mohan, A.; Singh, A.K.; Kumar, B.; Dwivedi, R. Review on remote sensing methods for landslide detection using machine and deep learning. Trans. Emerg. Telecommun. Technol. 2020, 32, e3998. [Google Scholar] [CrossRef]
- Jiang, W.; Xi, J.; Li, Z.; Zang, M.; Chen, B.; Zhang, C.; Liu, Z.; Gao, S.; Zhu, W. Deep Learning for Landslide Detection and Segmentation in High-Resolution Optical Images along the Sichuan-Tibet Transportation Corridor. Remote Sens. 2022, 14, 5490. [Google Scholar] [CrossRef]
- Chen, X.; Liu, M.; Li, D.; Jia, J.; Yang, A.; Zheng, W.; Yin, L. Conv-trans dual network for landslide detection of multi-channel optical remote sensing images. Front. Earth Sci. 2023, 11, 1182145. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Chen, X.; Yu, M.; Sun, Y.; Meng, F.; Fan, X. Landslide detection of high-resolution satellite images using asymmetric dual-channel network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4091–4094. [Google Scholar] [CrossRef]
- Shahabi, H.; Rahimzad, M.; Piralilou, S.T.; Ghorbanzadeh, O.; Homayouni, S.; Blaschke, T.; Lim, S.; Ghamisi, P. Unsupervised Deep Learning for Landslide Detection from Multispectral Sentinel-2 Imagery. Remote Sens. 2021, 13, 4698. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Travelletti, J.; Delacourt, C.; Allemand, P.; Malet, J.; Schmittbuhl, J.; Toussaint, R.; Bastard, M. Correlation of multi-temporal ground-based optical images for landslide monitoring: Application, potential and limitations. ISPRS J. Photogramm. Remote Sens. 2012, 70, 39–55. [Google Scholar] [CrossRef]
- Rau, J.; Jhan, J.; Rau, R. Semiautomatic Object-Oriented Landslide Recognition Scheme from Multisensor Optical Imagery and DEM. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1336–1349. [Google Scholar] [CrossRef]
- Dong, C.; Xue, T.; Wang, C. The feature representation ability of variational autoencoder. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 680–684. [Google Scholar] [CrossRef]
- Wiewel, F.; Yang, B. Continual Learning for Anomaly Detection with Variational Autoencoder. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019 . [Google Scholar] [CrossRef]
- Che, L.; Yang, X.; Wang, L. Text feature extraction based on stacked variational autoencoder. Microprocess. Microsyst. 2020, 76, 103063. [Google Scholar] [CrossRef]
- Xie, R.; Jan, N.M.; Hao, K.; Chen, L.; Huang, B. Supervised variational autoencoders for soft sensor modeling with missing data. IEEE Trans. Ind. Inform. 2020, 16, 2820–2828. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML ‘01), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision (ECCV), Las Vegas, NV, USA, 27–30 June 2016; pp. 630–645. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), St. Petersburg, FL, USA, 10–13 December 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional DenseNets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Xu, Y.; Zhao, H.; Wang, J.; Zhong, Y.; Zhao, D.; Zang, Q.; Wang, S.; Zhang, F.; Shi, Y.; et al. The outcome of the 2022 Landslide4Sense competition: Advanced landslide detection from multisource satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9927–9942. [Google Scholar] [CrossRef]
- Xu, Y.; Ouyang, C.; Xu, Q.; Wang, D.; Zhao, B.; Luo, Y. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Sci. Data 2024, 11, 12. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Enhanced Dual-Channel Model | DCT-Unet++ Model |
|---|---|---|
| Input Image Size | 224 × 224 | 256 × 256 |
| Batch Size | 8 | 8 |
| Number of Epochs | 20 | 100 |
| Optimizer | Adam (learning rate = 0.0001) | Adam (learning rate = 0.0001) |
| Data Split | Training = 80:20 | Training = 70:30 |
| Dropout Rate | 0.5 | None |
| Number of Heads in Multi-Head Attention | 4 | 8 |
| Key Dimension in Multi-Head Attention | 64 | 128 |
| Intermediate Layer Dimension | 512 | 4× key dimension (512) |
| Number of Transformer Attention Layers | 1 | 1 |
| Activation Function in Classification Head | Softmax | Sigmoid |
| Loss Function | Categorical Crossentropy | Composite loss function (cross-entropy + Dice + IoU) |
| Precision | Recall | F1 score | Support | |
|---|---|---|---|---|
| non-landslide | 0.99 | 0.99 | 0.99 | 399 |
| landslide | 0.98 | 0.98 | 0.98 | 156 |
| Accuracy | 0.99 | 555 | ||
| macro avg | 0.99 | 0.99 | 0.99 | 555 |
| weighted avg | 0.99 | 0.99 | 0.99 | 555 |
| non-landslide | 0.99 | 0.99 | 0.99 | 399 |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Restnet50 + CNN | 0.8799 | 0.8894 | 0.8707 | 0.8582 |
| VGG16 + InceptionV3 | 0.9275 | 0.9288 | 0.9263 | 0.9275 |
| ResNet50 + MobileNetV2 | 0.9275 | 0.9300 | 0.9250 | 0.9275 |
| MobileNetV2 + Xception | 0.9495 | 0.9519 | 0.9472 | 0.9459 |
| MoibileNet + DenseNet121 | 0.9716 | 0.9744 | 0.9688 | 0.9716 |
| MobileNetV2 + InceptionResNetV2 | 0.8630 | 0.8785 | 0.8481 | 0.8491 |
| DenseNet121 + VGG16 | 0.8593 | 0.8694 | 0.8495 | 0.8369 |
| InceptionV3 + MobileNetV2 | 0.9459 | 0.9459 | 0.9459 | 0.9459 |
| VGG19 + MobileNetV2 | 0.8805 | 0.8838 | 0.8772 | 0.8791 |
| InceptionV3 + DenseNet121 | 0.9666 | 0.9675 | 0.9656 | 0.9688 |
| MobileNetV2 + Xception | 0.7363 | 0.8382 | 0.6565 | 0.6703 |
| EfficientNetB0 + ResNet152V2 | 0.9538 | 0.9547 | 0.9528 | 0.9559 |
| NASNetMobile + Xception | 0.5494 | 0.5114 | 0.5936 | 0.5489 |
| Our model | 0.9892 | 0.9892 | 0.9892 | 0.9892 |
| IoU | Dice Coefficient | Accuracy | Precision | Recall | F1 Score | Overall Accuracy (OA) | Kappa Coefficient | |
|---|---|---|---|---|---|---|---|---|
| UNet | 0.8529 | 0.9206 | 0.9841 | 0.9300 | 0.9115 | 0.9206 | 0.9231 | 0.9118 |
| FCN | 0.8436 | 0.9151 | 0.9832 | 0.9377 | 0.8937 | 0.9151 | 0.9050 | 0.9058 |
| Segnet | 0.8185 | 0.9002 | 0.9801 | 0.9155 | 0.8854 | 0.9002 | 0.8966 | 0.8891 |
| linknet | 0.8303 | 0.9073 | 0.9815 | 0.9199 | 0.8950 | 0.9073 | 0.9064 | 0.8970 |
| Deeplabv3 | 0.7440 | 0.8532 | 0.9716 | 0.8958 | 0.8145 | 0.8532 | 0.8248 | 0.8376 |
| VGG16 + FCN | 0.6050 | 0.7539 | 0.9543 | 0.8292 | 0.6911 | 0.7539 | 0.6998 | 0.7289 |
| PSPNet | 0.8543 | 0.9214 | 0.9844 | 0.9424 | 0.9014 | 0.9214 | 0.9128 | 0.9128 |
| FC-DenseNet | 0.6962 | 0.8209 | 0.9663 | 0.8883 | 0.7630 | 0.8209 | 0.7726 | 0.8024 |
| Attention-Unet | 0.7267 | 0.8417 | 0.9675 | 0.8308 | 0.8530 | 0.8417 | 0.8638 | 0.8236 |
| UNetSE | 0.8529 | 0.9206 | 0.9843 | 0.9402 | 0.9018 | 0.9206 | 0.9133 | 0.9119 |
| Our model | 0.8631 | 0.9265 | 0.9855 | 0.9505 | 0.9038 | 0.9265 | 0.9153 | 0.9185 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| non-landslide | 0.97 | 0.96 | 0.96 | 4434 |
| Landslide | 0.90 | 0.91 | 0.91 | 1733 |
| Accuracy | 0.95 | 6167 | ||
| macro avg | 0.93 | 0.94 | 0.93 | 6167 |
| weighted avg | 0.95 | 0.95 | 0.95 | 6167 |
| non-landslide | 0.97 | 0.96 | 0.96 | 4434 |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Restnet50 + CNN | 0.8531 | 0.8641 | 0.8423 | 0.8233 |
| VGG16 + InceptionV3 | 0.9066 | 0.9044 | 0.9088 | 0.9116 |
| ResNet50 + MobileNetV2 | 0.9194 | 0.9188 | 0.9201 | 0.9173 |
| MobileNetV2 + Xception | 0.8995 | 0.9028 | 0.8961 | 0.8931 |
| MoibileNet + DenseNet121 | 0.9323 | 0.9315 | 0.9331 | 0.9273 |
| MobileNetV2 + InceptionResNetV2 | 0.8487 | 0.8561 | 0.8414 | 0.8459 |
| DenseNet121 + VGG16 | 0.8874 | 0.8633 | 0.9130 | 0.8459 |
| InceptionV3 + MobileNetV2 | 0.9102 | 0.9101 | 0.9102 | 0.9116 |
| VGG19 + MobileNetV2 | 0.5994 | 0.5155 | 0.7160 | 0.5942 |
| InceptionV3 + DenseNet121 | 0.9116 | 0.9086 | 0.9146 | 0.9116 |
| MobileNetV2 + Xception | 0.9209 | 0.9231 | 0.9186 | 0.9173 |
| EfficientNetB0 + ResNet152V2 | 0.9315 | 0.9344 | 0.9286 | 0.9301 |
| NASNetMobile + Xception | 0.8838 | 0.8870 | 0.8806 | 0.8717 |
| Our model | 0.9470 | 0.9473 | 0.9470 | 0.9471 |
| IoU | Dice Coefficient | Accuracy | Precision | Recall | F1 Score | Kappa Coefficient | |
|---|---|---|---|---|---|---|---|
| UNet | 0.8197 | 0.9009 | 0.9678 | 0.8932 | 0.9089 | 0.9009 | 0.8817 |
| FCN | 0.8241 | 0.9036 | 0.9688 | 0.9008 | 0.9063 | 0.9036 | 0.8850 |
| Segnet | 0.8231 | 0.9030 | 0.9686 | 0.8980 | 0.9080 | 0.9030 | 0.8842 |
| linknet | 0.8179 | 0.8998 | 0.9681 | 0.9092 | 0.8906 | 0.8998 | 0.8808 |
| Deeplabv3 | 0.6718 | 0.8037 | 0.9381 | 0.8211 | 0.7870 | 0.8037 | 0.7670 |
| VGG16 + FCN | 0.5346 | 0.6967 | 0.9110 | 0.7724 | 0.6345 | 0.6967 | 0.6452 |
| PSPNet | 0.8217 | 0.9021 | 0.9681 | 0.8912 | 0.9133 | 0.9021 | 0.8831 |
| FC-DenseNet | 0.8153 | 0.8983 | 0.9669 | 0.8900 | 0.9067 | 0.8983 | 0.8785 |
| Attention U-Net | 0.8159 | 0.8986 | 0.9670 | 0.8907 | 0.9067 | 0.8986 | 0.8789 |
| UNetSE | 0.8270 | 0.9053 | 0.9693 | 0.9002 | 0.9105 | 0.9053 | 0.8870 |
| UNetDC | 0.8205 | 0.9014 | 0.9688 | 0.9171 | 0.8862 | 0.9014 | 0.8828 |
| Our model | 0.8217 | 0.9021 | 0.9686 | 0.9068 | 0.8975 | 0.9021 | 0.8835 |
| IoU | Dice Coefficient | Accuracy | Precision | Recall | F1 Score | Kappa Coefficient | |
|---|---|---|---|---|---|---|---|
| UNet | 0.7158 | 0.8344 | 0.9293 | 0.9045 | 0.7743 | 0.8344 | 0.7897 |
| FCN | 0.7153 | 0.8340 | 0.9287 | 0.8984 | 0.7782 | 0.8340 | 0.7889 |
| Segnet | 0.7468 | 0.8551 | 0.9379 | 0.9242 | 0.7955 | 0.8551 | 0.8159 |
| linknet | 0.7452 | 0.8540 | 0.9378 | 0.9286 | 0.7905 | 0.8540 | 0.8148 |
| Deeplabv3 | 0.6292 | 0.7724 | 0.9048 | 0.8580 | 0.7023 | 0.7724 | 0.7129 |
| VGG16 + FCN | 0.5816 | 0.7355 | 0.8823 | 0.7613 | 0.7113 | 0.7355 | 0.6599 |
| PSPNet | 0.7177 | 0.8357 | 0.9294 | 0.9001 | 0.7798 | 0.8357 | 0.7910 |
| FC-DenseNet | 0.7393 | 0.8501 | 0.9358 | 0.9185 | 0.7912 | 0.8501 | 0.8095 |
| UNetSE | 0.7114 | 0.8314 | 0.9280 | 0.9012 | 0.7716 | 0.8314 | 0.7859 |
| Our model | 0.7284 | 0.8429 | 0.9319 | 0.8978 | 0.7943 | 0.8429 | 0.7996 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, Q.; Xie, H.; Chen, Y.; Sun, R. Enhanced Dual-Channel Model-Based with Improved Unet++ Network for Landslide Monitoring and Region Extraction in Remote Sensing Images. Remote Sens. 2024, 16, 2990. https://doi.org/10.3390/rs16162990
Wang J, Zhang Q, Xie H, Chen Y, Sun R. Enhanced Dual-Channel Model-Based with Improved Unet++ Network for Landslide Monitoring and Region Extraction in Remote Sensing Images. Remote Sensing. 2024; 16(16):2990. https://doi.org/10.3390/rs16162990
Chicago/Turabian StyleWang, Junxin, Qintong Zhang, Hao Xie, Yingying Chen, and Rui Sun. 2024. "Enhanced Dual-Channel Model-Based with Improved Unet++ Network for Landslide Monitoring and Region Extraction in Remote Sensing Images" Remote Sensing 16, no. 16: 2990. https://doi.org/10.3390/rs16162990
APA StyleWang, J., Zhang, Q., Xie, H., Chen, Y., & Sun, R. (2024). Enhanced Dual-Channel Model-Based with Improved Unet++ Network for Landslide Monitoring and Region Extraction in Remote Sensing Images. Remote Sensing, 16(16), 2990. https://doi.org/10.3390/rs16162990