
Limited Sample Radar HRRP Recognition Using FWA-GAN


Abstract
1. Introduction
- (1)
- A novel FWA-GAN feature fusion method is proposed. The method fuses deep features with handcrafted features using a generative module, uses a sample discriminator to supervise the target recognition task, and introduces a feature discriminator to supervise the fusion process of handcrafted features. This makes the handcrafted feature fusion process more stable.
- (2)
- A new loss function consisting of adversarial loss, sample category loss, and feature category loss is employed to integrate the deep feature and the handcrafted feature. This loss function is specifically designed to foster dynamic knowledge matching and mutual learning between the two domains.
- (3)
- This paper proposes a method for adaptively assigning the weights of handcrafted features and deep features. The loss weights are assigned according to the correlation between the two features and the original sample.
2. Proposed Method
2.1. General Framework
2.2. Network Structure
2.3. Loss Function
3. Experimental Results
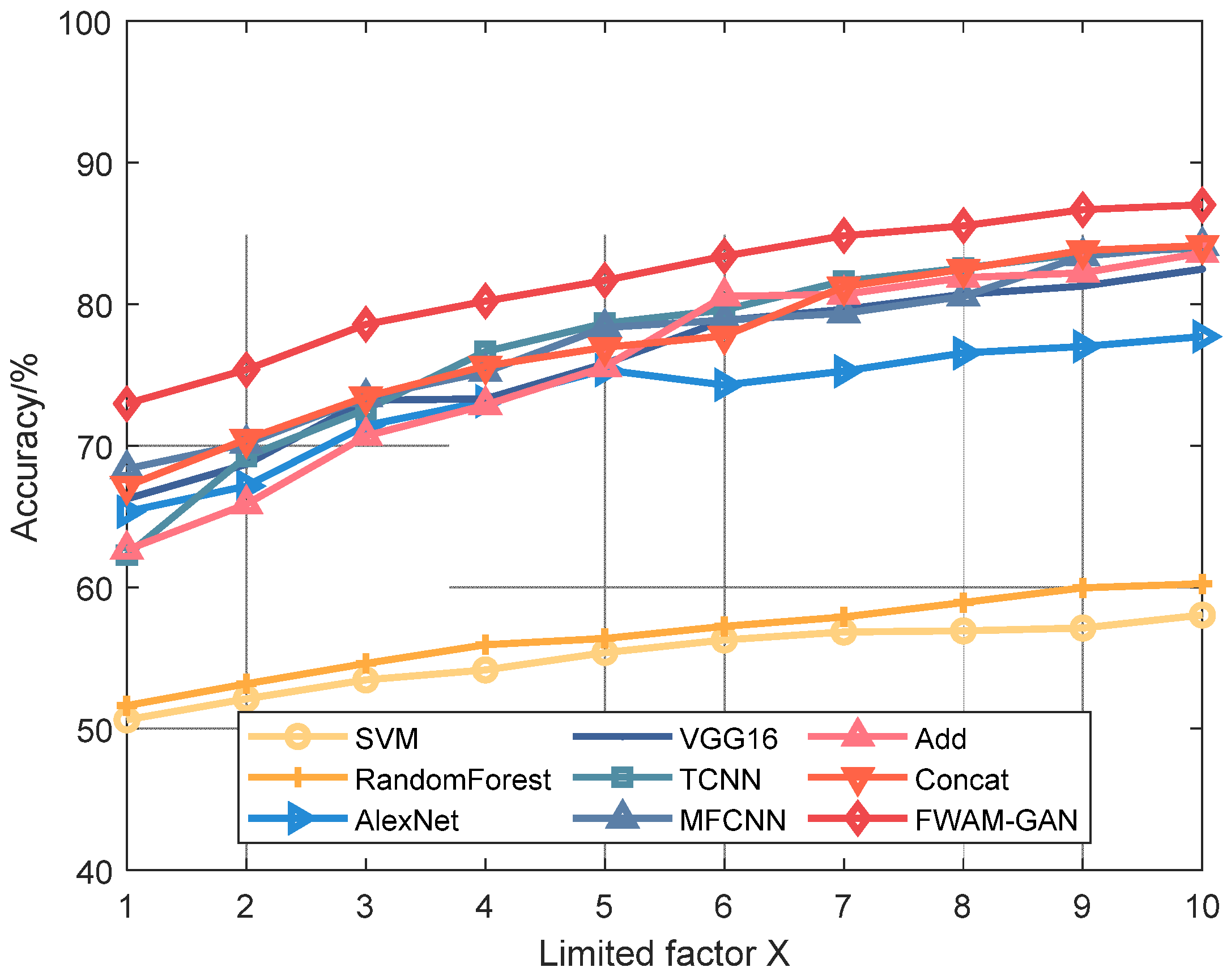
3.1. Basic Performance Evaluation
3.2. Generalization with Different Target Models
3.3. Generalization with Different Elevation Angles
3.4. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Yang, S. Using Range Profiles as Feature Vectors to Identify Aerospace Objects. IEEE Trans. Antennas Propag. 1993, 41, 261–268. [Google Scholar] [CrossRef]
- Curry, G.R. A low-cost space-based radar system concept. IEEE Aerosp. Electron. Syst. Mag. 1996, 11, 21–24. [Google Scholar] [CrossRef]
- Slomka, S.; Gibbins, D.; Gray, D.; Haywood, B. Features for High Resolution Radar Range Profile Based Ship Classification. In Proceedings of the Fifth International Symposium on Signal Processing and its Applications, Brisbane, QLD, Australia, 22–25 August 1999; pp. 329–332. [Google Scholar] [CrossRef]
- Xing, M.; Bao, Z.; Pei, B. Properties of High-resolution Range Profiles. Opt. Eng. 2002, 41, 493–504. [Google Scholar] [CrossRef]
- Du, L.; Liu, H.; Bao, Z.; Xing, M. Radar HRRP target recognition based on higher order spectra. IEEE Trans. Signal Process. 2005, 53, 2359–2368. [Google Scholar] [CrossRef]
- Zhou, D.; Shen, X.; Yang, W. Radar Target Recognition Based on Fuzzy Optimal Transformation Using High-Resolution Range Profile. Pattern Recognit. Lett. 2013, 34, 256–264. [Google Scholar] [CrossRef]
- Lei, S.Q.; Yue, D.X.; Wang, F. Natural Scene Recognition Based on HRRP Statistical Modeling. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4944–4947. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, Y.; Zhang, Z.; Zhang, X.; Zhang, L. Type-Aspect Disentanglement Network for HRRP Target Recognition With Missing Aspects. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3509305. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, X.; Liu, Y. A Prior-Knowledge-Guided Neural Network Based on Supervised Contrastive Learning for Radar HRRP Recognition. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 2854–2873. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, Y.; Zhang, X.; Zhang, L.; Long, T. Domain-Adaptive HRRP Generation Using Two-Stage Denoising Diffusion Probability Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3504305. [Google Scholar] [CrossRef]
- Liu, Y.; Long, T.; Zhang, L.; Wang, Y.; Zhang, X.; Li, Y. SDHC: Joint Semantic-Data Guided Hierarchical Classification for Fine-Grained HRRP Target Recognition. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 3993–4009. [Google Scholar] [CrossRef]
- Yang, L.; Feng, W.; Wu, Y.; Huang, L.; Quan, Y. Radar-Infrared Sensor Fusion Based on Hierarchical Features Mining. IEEE Signal Process. Lett. 2024, 31, 66–70. [Google Scholar] [CrossRef]
- Kan, S.; Cen, Y.; He, Z. Supervised Deep Feature Embedding with Hand Crafted Feature. IEEE Trans. Image Process. 2019, 28, 5809–5823. [Google Scholar] [CrossRef] [PubMed]
- Cristianint, N. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Wei, Z.; Jie, W.; Jian, G. An efficient SAR target recognition algorithm based on contour and shape context. In Proceedings of the 3rd International Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Seoul, Republic of Korea, 26–30 September 2011; pp. 1–4. [Google Scholar]
- Park, J.I.; Park, S.H.; Kim, K.T. New discrimination features for SAR automatic target recognition. IEEE Geosci. Remote Sens. Lett. 2013, 10, 476–480. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Jia, L.; Xing, M. SAR target classification using the multikernel-size feature fusion-based convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5214313. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Shi, L.; Liang, Z.; Wen, Y.; Zhuang, Y.; Huang, Y.; Ding, X. One-shot HRRP generation for radar target recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3504405. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Xie, Y. FEC: A feature fusion framework for SAR target recognition based on electromagnetic scattering features and deep CNN features. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2174–2187. [Google Scholar] [CrossRef]
- Zheng, H.; Hu, Z.; Yang, L. Multifeature Collaborative Fusion Network with Deep Supervision for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5212614. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, L.; Wen, Z. Multilevel Scattering Center and Deep Feature Fusion Learning Framework for SAR Target Recognition. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5227914. [Google Scholar] [CrossRef]
- Li, Y.; Du, L.; Wei, D. Multiscale CNN Based on Component Analysis for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2024, 60, 5211212. [Google Scholar] [CrossRef]
- Qin, J.; Zou, B.; Chen, Y. Scattering Attribute Embedded Network for Few-Shot SAR ATR. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 4182–4197. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classifica tion with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–6 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Yadav, D.; Kohli, N.; Agarwal, A. Fusion of Handcrafted and Deep Learning Features for Large-scale Multiple Iris Presentation Attack Detection. In Proceedings of the International Conference on Computer Vision and Pattern Recognition-Workshop on Biometrics (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Zhang, L.; Han, C.; Wang, Y.; Li, Y.; Long, T. Polarimetric HRRP recognition based on feature-guided transformer model. Electron. Lett. 2021, 57, 705–707. [Google Scholar] [CrossRef]
- Wan, J.; Chen, B.; Xu, B.; Liu, H.; Jin, L. Convolutional neuralnetworks for radar HRRP target recognition and rejection. EURASIP J. Adv. Signal Process. 2019, 2019, 5. [Google Scholar] [CrossRef]
- Cho, J.H.; Park, C.G. Multiple feature aggregation using convolutional neural networks for SAR image-based automatic target recognition. lEEE Geosci. Remote Sens. Lett. 2018, 15, 1882–1886. [Google Scholar] [CrossRef]
- Yang, J.; Yang, J.-Y.; Zhang, D. Feature fusion: Parallel strategy vs. serial strategy. Pattern Recognit. 2003, 36, 1369–1381. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Type | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| Elevation | Select the Number of Azimuths | Number of Training Set Samples | Elevation | Select the Number of Azimuths | Number of Test Set Samples | |
| Toyota Camery | 30° | 18 × X | 1800 × X | 40° | 180 | 18,000 |
| Mazda MPV | 30° | 18 × X | 1800 × X | 40° | 180 | 18,000 |
| Toyota Tocoma | 30° | 18 × X | 1800 × X | 40° | 180 | 18,000 |
| Target Type | Training Set | Testing Set | ||||
|---|---|---|---|---|---|---|
| Elevation | Azimuths Number | Training Set Number | Elevation | Azimuths Number | Testing Set Number | |
| BMP2 | 17° | 12 × X | 1200 × X | 15° | 45 | 4500 |
| BTR70 | 17° | 11 × X | 1100 × X | 15° | 54 | 5400 |
| T72 | 17° | 12 × X | 1200 × X | 15° | 42 | 4200 |
| Target Type | Training Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Elevation | Azimuths Number | Model | Elevation | Azimuths Number | Model | Elevation | Azimuths Number | |
| BMP2 | 17° | 12×X | 9563 | 1200 × X | 15° | 9563 | 45 | 4500 |
| BTR70 | 17° | 11×X | C71 | 1100 × X | 15° | C71 | 54 | 5400 |
| T72 | 17° | 12×X | 132 | 1200 × X | 15° | A32, A62, A63, A64 | 192 | 19,200 |
| Target Type | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| Elevation | Azimuth Number | Training Set Number | Elevation | Azimuth Number | Testing Set Number | |
| Toyota Camery | 30° | 18 × X | 1800 × X | 50° | 180 | 18,000 |
| Mazda MPV | 30° | 18 × X | 1800 × X | 50° | 180 | 18,000 |
| Toyota Tocoma | 30° | 18 × X | 1800 × X | 50° | 180 | 18,000 |
| Target Type | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| Elevation | Azimuth Number | Training Set Number | Elevation | Azimuth Number | Testing Set Number | |
| BMP2 | 17° | 12 × X | 1200 × X | 30° | 45 | 4500 |
| BTR70 | 17° | 11 × X | 1200 × X | 30° | 54 | 5400 |
| T72 | 17° | 12 × X | 1200 × X | 30° | 42 | 4200 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Zhang, L.; Wang, Y. Limited Sample Radar HRRP Recognition Using FWA-GAN. Remote Sens. 2024, 16, 2963. https://doi.org/10.3390/rs16162963
Song Y, Zhang L, Wang Y. Limited Sample Radar HRRP Recognition Using FWA-GAN. Remote Sensing. 2024; 16(16):2963. https://doi.org/10.3390/rs16162963
Chicago/Turabian StyleSong, Yiheng, Liang Zhang, and Yanhua Wang. 2024. "Limited Sample Radar HRRP Recognition Using FWA-GAN" Remote Sensing 16, no. 16: 2963. https://doi.org/10.3390/rs16162963
APA StyleSong, Y., Zhang, L., & Wang, Y. (2024). Limited Sample Radar HRRP Recognition Using FWA-GAN. Remote Sensing, 16(16), 2963. https://doi.org/10.3390/rs16162963