
A Comprehensive Comparison of Stable and Unstable Area Sampling Strategies in Large-Scale Landslide Susceptibility Models Using Machine Learning Methods

 , , , and
, , , and
Abstract

1. Introduction
2. Material
2.1. Study Area
2.2. Landslide Data

2.3. Thematic Data
3. Methodology
3.1. General Workflow
3.2. Preparing Stable and Unstable Datasets
3.3. Preparing Thematic Data
3.4. Modelling
3.5. Comparison Metrics for Results Analysis
4. Results
4.1. Model Fitting Performance
4.2. Model Predictive Performance
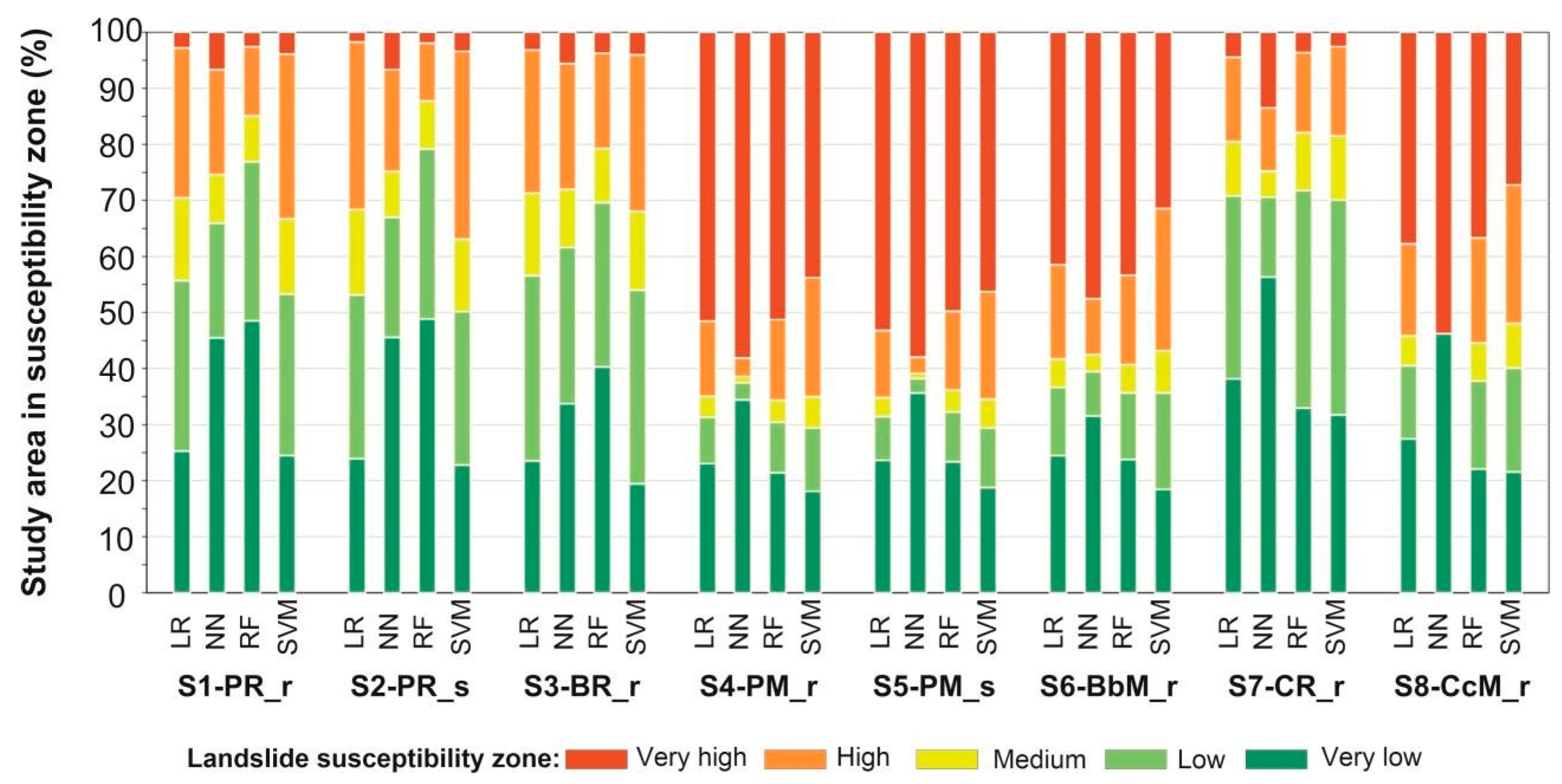
4.3. Probabilistic-Based Zonation
5. Discussion
5.1. Model Uncertainty Considering Applied Methods and Sampling Scenarios
5.2. Analysing Model Fitting, Predictive and Classification Performance
5.3. Model Verification
5.4. Highlighting the Unstable Centroid Sampling Disadvantages
6. Conclusions
- (i)
- Smoothing DTM-derived LCFs at landslide locations slightly reduces model variability, whereas RF and NN models in scenario S2-PR_s using unstable polygons and randomly generated stable points represent the best LSMs
- (ii)
- Buffering only stable or stable and unstable polygons results in the least model variability, with a significant decline in zonation performance;
- (iii)
- Using the proposed stable area inventory to define stable modelling pixels by using any tested strategy drastically lowers zonation quality, which was undetectable by commonly used fitting and predictive performance metrics;
- (iv)
- The NN method, followed by RF, is extremely sensitive to the tested sampling strategies, whereas SVM showed the least variability, followed by similar results for LR. Additionally, with proper settings, the RF method yields LSMs that are generally better than LR, NN and SVM models;
- (v)
- Sampling landslides as centroids, which is extremely common in landslide susceptibility assessments, should be avoided when developing LSMs for large-scale spatial planning purposes due to the severe inability of the model to depict spatially accurate zones, which were quantitatively and qualitatively evaluated;
- (vi)
- A qualitative assessment of classified LSMs, quantifying zonation area size and landslide presence, represents a crucial parameter to estimate LSMs for application to large-scale spatial planning systems.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fell, R.; Corominas, J.; Bonnard, C.; Cascini, L.; Leroi, E.; Savage, W.Z. Guidelines for Landslide Susceptibility, Hazard and Risk Zoning for Land Use Planning. Eng. Geol. 2008, 102, 85–98. [Google Scholar] [CrossRef]
- Guzzetti, F.; Reichenbach, P.; Cardinali, M.; Galli, M.; Ardizzone, F. Probabilistic Landslide Hazard Assessment at the Basin Scale. Geomorphology 2005, 72, 272–299. [Google Scholar] [CrossRef]
- Varnes, D.J. Landslide Hazard Zonation: A Review of Principles and Practice; Education, Scientific and Cultural Organization: Paris, France, 1984. [Google Scholar]
- Soeters, R.; van Westen, C.J. Slope Instability Recognition Analysis and Zonation. In Landslides: Investigation and Mitigation; Turner, K.T., Schuster, R.L., Eds.; National Academy Press: Washington, DC, USA, 1996; pp. 129–177. [Google Scholar]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide Hazard Evaluation: A Review of Current Techniques and Their Application in a Multi-Scale Study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- van Westen, C.J.; Rengers, N.; Soeters, R. Use of Geomorphological Information in Indirect Landslide Susceptibility Assessment. Nat. Hazards 2003, 30, 399–419. [Google Scholar] [CrossRef]
- van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial Data for Landslide Susceptibility, Hazard, and Vulnerability Assessment: An Overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Fell, R.; Corominas, J.; Bonnard, C.; Cascini, L.; Leroi, E.; Savage, W.Z. Guidelines for Landslide Susceptibility, Hazard and Risk Zoning for Land-Use Planning. Eng. Geol. 2008, 102, 99–111. [Google Scholar] [CrossRef]
- Corominas, J.; van Westen, C.; Frattini, P.; Cascini, L.; Malet, J.P.; Fotopoulou, S.; Catani, F.; Van Den Eeckhaut, M.; Mavrouli, O.; Agliardi, F.; et al. Recommendations for the Quantitative Analysis of Landslide Risk. Bull. Eng. Geol. Environ. 2014, 73, 209–263. [Google Scholar] [CrossRef]
- Dias, H.C.; Hölbling, D.; Grohmann, C.H. Landslide Susceptibility Mapping in Brazil: A Review. Geosciences 2021, 11, 425. [Google Scholar] [CrossRef]
- Das, S.; Sarkar, S.; Kanungo, D.P. A Critical Review on Landslide Susceptibility Zonation: Recent Trends, Techniques, and Practices in Indian Himalaya. Nat. Hazards 2023, 115, 23–72. [Google Scholar] [CrossRef]
- Shano, L.; Raghuvanshi, T.K.; Meten, M. Landslide Susceptibility Evaluation and Hazard Zonation Techniques—A Review. Geoenviron. Disasters 2020, 7, 18. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A Review of Statistically-Based Landslide Susceptibility Models. Earth Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the Landslide Susceptibility: Which Algorithm, Which Precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Lee, S. Current and Future Status of GIS-Based Landslide Susceptibility Mapping: A Literature Review. Korean J. Remote Sens. 2019, 35, 179–193. [Google Scholar]
- Mihalić Arbanas, S.; Bernat Gazibara, S.; Krkač, M.; Sinčić, M.; Lukačić, H.; Jagodnik, P.; Arbanas, Ž. Landslide Detection and Spatial Prediction: Application of Data and Information from Landslide Maps. In Progress in Landslide Research and Technology, Volume 1 Issue 2, 2022; Alcantara-Ayala, I., Arbanas, Ž., Huntley, D., Konagai, K., Mikoš, M., Sassa, K., Sassa, S., Tang, H., Tiwari, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2023; pp. 195–212. [Google Scholar] [CrossRef]
- Bernat Gazibara, S.; Mihalić Arbanas, S.; Sinčić, M.; Krkač, M.; Lukačić, H.; Jagodnik, P.; Arbanas, Ž. LandSlidePlan -Scientific Research Project on Landslide Susceptibility Assessment in Large Scale. In Proceedings of the Proceedings of the 5th Regional Symposium on Landslides in Adriatic—Balkan Region, Rijeka, Croatia, 23–26 March 2022; pp. 99–106. [Google Scholar]
- Bernat, S.; Mihalić Arbanas, S.; Krkač, M. Inventory of Precipitation Triggered Landslides in the Winter of 2013 in Zagreb (Croatia, Europe). In Landslide Science for a Safer Geoenvironment; Springer International Publishing: Cham, Switzerland, 2014; pp. 829–835. [Google Scholar]
- Sinčić, M.; Bernat Gazibara, S.; Krkač, M.; Lukačić, H.; Mihalić Arbanas, S. The Use of High-Resolution Remote Sensing Data in Preparation of Input Data for Large-Scale Landslide Hazard Assessments. Land 2022, 11, 1360. [Google Scholar] [CrossRef]
- Krkač, M.; Bernat Gazibara, S.; Sinčić, M.; Lukačić, H.; Mihalić Arbanas, S. Landslide Inventory Mapping Based on LiDAR Data: A Case Study from Hrvatsko Zagorje (Croatia). In Proceedings of the 5th ReSyLAB, Rijeka, Croatia, 23–26 March 2022; pp. 81–86. [Google Scholar]
- Hong, H.; Miao, Y.; Liu, J.; Zhu, A.-X. Exploring the Effects of the Design and Quantity of Absence Data on the Performance of Random Forest-Based Landslide Susceptibility Mapping. Catena 2019, 176, 45–64. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, F.; Dou, J.; Nam, K.; Ma, H. Enhanced Absence Sampling Technique for Data-Driven Landslide Susceptibility Mapping: A Case Study in Songyang County, China. Remote Sens. 2023, 15, 3345. [Google Scholar] [CrossRef]
- Busby, J.R. Bioclim—A Bioclimatic Analysis and Prediction System. In Nature Conservation; Margules, C.R., Augstin, M.P., Eds.; CSIRO: Canberra, Australia, 1993; pp. 64–68. [Google Scholar]
- Carpenter, G.; Gillison, A.N.; Winter, J. DOMAIN: A Flexible Modelling Procedure for Mapping Potential Distributions of Plants and Animals. Biodivers. Conserv. 1993, 2, 667–680. [Google Scholar] [CrossRef]
- Scholkopf, G. Support Vector Method for Novelty Detection. Adv. Neural Inf. Process Syst. 2008, 12, 582–588. [Google Scholar]
- Xiao, C.; Tian, Y.; Shi, W.; Guo, Q.; Wu, L. A New Method of Pseudo Absence Data Generation in Landslide Susceptibility Mapping with a Case Study of Shenzhen. Sci. China Technol. Sci. 2010, 53, 75–84. [Google Scholar] [CrossRef]
- Hu, J.; Xu, K.; Wang, G.; Liu, Y.; Khan, M.A.; Mao, Y.; Zhang, M. A Novel Landslide Susceptibility Mapping Portrayed by OA- HD and K-Medoids Clustering Algorithms. Bull. Eng. Geol. Environ. 2021, 80, 765–779. [Google Scholar] [CrossRef]
- Zhu, A.-X.; Miao, Y.; Liu, J.; Bai, S.; Zeng, C.; Ma, T.; Hong, H. A Similarity-Based Approach to Sampling Absence Data for Landslide Susceptibility Mapping Using Data-Driven Methods. Catena 2019, 183, 104188. [Google Scholar] [CrossRef]
- Xi, C.; Han, M.; Hu, X.; Liu, B.; He, K.; Luo, G.; Cao, X. Effectiveness of Newmark-Based Sampling Strategy for Coseismic Landslide Susceptibility Mapping Using Deep Learning, Support Vector Machine, and Logistic Regression. Bull. Eng. Geol. Environ. 2022, 81, 174. [Google Scholar] [CrossRef]
- Rabby, Y.W.; Li, Y.; Hilafu, H. An Objective Absence Data Sampling Method for Landslide Susceptibility Mapping. Sci. Rep. 2023, 13, 1740. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Wang, Y.; Cao, Y.; Singhc, R.P.; Ahmed, B.; Motagh, M.; Wang, Y.; Chen, L. Non-Landslide Sampling and Ensemble Learning Techniques to Improve Landslide Susceptibility Mapping. Nat. Hazards Earth Syst. Sci. 2023. [Google Scholar] [CrossRef]
- Lucchese, L.V.; de Oliveira, G.G.; Pedrollo, O.C. Investigation of the Influence of Nonoccurrence Sampling on Landslide Sus- ceptibility Assessment Using Artificial Neural Networks. Catena 2021, 198, 105067. [Google Scholar] [CrossRef]
- Conoscenti, C.; Rotigliano, E.; Cama, M.; Caraballo-Arias, N.A.; Lombardo, L.; Agnesi, V. Exploring the Effect of Absence Selection on Landslide Susceptibility Models: A Case Study in Sicily, Italy. Geomorphology 2016, 261, 222–235. [Google Scholar] [CrossRef]
- Dornik, A.; Drăguţ, L.; Oguchi, T.; Hayakawa, Y.; Micu, M. Influence of Sampling Design on Landslide Susceptibility Modeling in Lithologically Heterogeneous Areas. Sci. Rep. 2022, 12, 2106. [Google Scholar] [CrossRef]
- Hussin, H.Y.; Zumpano, V.; Reichenbach, P.; Sterlacchini, S.; Micu, M.; van Westen, C.; Bălteanu, D. Different Landslide Sam- pling Strategies in a Grid-Based Bi-Variate Statistical Susceptibility Model. Geomorphology 2016, 253, 508–523. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Dif- ferent Sampling Strategies for Predicting Landslide Susceptibilities Are Deemed Less Consequential with Deep Learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Huang, F.; Yan, J.; Fan, X.; Yao, C.; Huang, J.; Chen, W.; Hong, H. Uncertainty Pattern in Landslide Susceptibility Prediction Modelling: Effects of Different Landslide Boundaries and Spatial Shape Expressions. Geosci. Front. 2022, 13, 101317. [Google Scholar] [CrossRef]
- Petschko, H.; Bell, R.; Leopold, P.; Heiss, G.; Glade, T. Landslide Inventories for Reliable Susceptibility Maps in Lower Austria. In Landslide Science and Practice; Margottini, C., Canuti, P., Sassa, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 281–286. [Google Scholar]
- Poli, S.; Sterlacchini, S. Landslide Representation Strategies in Susceptibility Studies Using Weights-of-Evidence Modeling Technique. Nat. Resour. Res. 2007, 16, 121–134. [Google Scholar] [CrossRef]
- Simon, N.; Crozier, M.; de Roiste, M.; Rafek, A.G. Point Based Assessment: Selecting TheBest Way to Represent Landslide Polygon as Point Frequency in Landslide Investigation. Electron. J. Geotech. Eng. 2013, 18, 775–784. [Google Scholar]
- Lai, J.-S.; Chiang, S.-H.; Tsai, F. Exploring Influence of Sampling Strategies on Event-Based Landslide Susceptibility Modeling. ISPRS Int. J. Geoinf. 2019, 8, 397. [Google Scholar] [CrossRef]
- Süzen, M.L.; Doyuran, V. Data Driven Bivariate Landslide Susceptibility Assessment Using Geographical Information Systems: A Method and Application to Asarsuyu Catchment, Turkey. Eng. Geol. 2004, 71, 303–321. [Google Scholar] [CrossRef]
- Yilmaz, I. The Effect of the Sampling Strategies on the Landslide Susceptibility Mapping by Conditional Probability and Artificial Neural Networks. Environ. Earth Sci. 2010, 60, 505–519. [Google Scholar] [CrossRef]
- Lee, S. Landslide Susceptibility Mapping Using an Artificial Neural Network in the Gangneung Area, Korea. Int. J. Remote Sens. 2007, 28, 4763–4783. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.G.; Dai, F.C. Landslide Susceptibility Mapping Based on Support Vector Machine: A Case Study on Natural Slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Sarkar, S.; Roy, A.K.; Martha, T.R. Landslide Susceptibility Assessment Using Information Value Method in Parts of the Darjeeling Himalayas. J. Geol. Soc. India 2013, 82, 351–362. [Google Scholar] [CrossRef]
- Hemasinghe, H.; Rangali, R.S.S.; Deshapriya, N.L.; Samarakoon, L. Landslide Susceptibility Mapping Using Logistic Regression Model (a Case Study in Badulla District, Sri Lanka). Procedia Eng. 2018, 212, 1046–1053. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Luo, H.; He, J.; Cheung, R.W.M. AI-Powered Landslide Susceptibility Assessment in Hong Kong. Eng. Geol. 2021, 288, 106103. [Google Scholar] [CrossRef]
- Sinčić, M.; Bernat Gazibara, S.; Krkač, M.; Mihalić Arbanas, S. Landslide Susceptibility Assessment of the City of Karlovac Using Bivariate Statistical Analysis. Rudarsko-Geološko-Naftni Zb. 2022, 37, 149–170. [Google Scholar] [CrossRef]
- Pascale, S.; Parisi, S.; Mancini, A.; Schiattarella, M.; Conforti, M.; Sole, A.; Murgante, B.; Sdao, F. Landslide Susceptibility Mapping Using Artificial Neural Network in the Urban Area of Senise and San Costantino Albanese (Basilicata, Southern Italy). Lect. Notes Comput. Sci. 2013, 7974, 473–488. [Google Scholar] [CrossRef]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide Susceptibility Estimation by Random Forests Technique: Sensitivity and Scaling Issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]
- Pradhan, B. A Comparative Study on the Predictive Ability of the Decision Tree, Support Vector Machine and Neuro-Fuzzy Models in Landslide Susceptibility Mapping Using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Farooq, S.; Akram, M.S. Landslide Susceptibility Mapping Using Information Value Method in Jhelum Valley of the Himalayas. Arab. J. Geosci. 2021, 14, 824. [Google Scholar] [CrossRef]
- Sandić, C.; Marjanović, M.; Abolmasov, B.; Tošić, R. Integrating Landslide Magnitude in the Susceptibility Assessment of the City of Doboj, Using Machine Learning and Heuristic Approach. J. Maps 2023, 19. [Google Scholar] [CrossRef]
- Guo, Z.; Tian, B.; Zhu, Y.; He, J.; Zhang, T. How Do the Landslide and Non-Landslide Sampling Strategies Impact Landslide Susceptibility Assessment?—A Catchment-Scale Case Study from China. J. Rock Mech. Geotech. Eng. 2024, 16, 877–894. [Google Scholar] [CrossRef]
- Song, Y.; Yang, D.; Wu, W.; Zhang, X.; Zhou, J.; Tian, Z.; Wang, C.; Song, Y. Evaluating Landslide Susceptibility Using Sampling Methodology and Multiple Machine Learning Models. ISPRS Int. J. Geoinf. 2023, 12, 197. [Google Scholar] [CrossRef]
- Petschko, H.; Brenning, A.; Bell, R.; Goetz, J.; Glade, T. Assessing the Quality of Landslide Susceptibility Maps—Case Study Lower Austria. Nat. Hazards Earth Syst. Sci. 2014, 14, 95–118. [Google Scholar] [CrossRef]
- Bornaetxea, T.; Rossi, M.; Marchesini, I.; Alvioli, M. Effective Surveyed Area and Its Role in Statistical Landslide Susceptibility Assessments. Nat. Hazards Earth Syst. Sci. 2018, 18, 2455–2469. [Google Scholar] [CrossRef]
- Bernat Gazibara, S.; Sinčić, M.; Krkač, M.; Jagodnik, P.; Lukačić, H.; Mihalić Arbanas, S. Influence of the Landslide Inventory Completeness on the Accuracy of the Landslide Susceptibility Modelling: A Case Study from the City of Zagreb (Croatia). In Proceedings of the 6th World Landslide Forum, Florence, Italy, 14–17 November 2023; p. 644. [Google Scholar]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial Prediction Models for Shallow Landslide Hazards: A Comparative Assessment of the Efficacy of Support Vector Machines, Artificial Neural Networks, Kernel Logistic Regression, and Logistic Model Tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine Learning Meth- ods for Landslide Susceptibility Studies: A Comparative Overview of Algorithm Performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide Susceptibility Mapping Using Machine Learning Algorithms and Comparison of Their Performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Bernat, S.; Mihalić Arbanas, S.; Krkač, M.; Sečanj, M. Catalog of Precipitation Events That Triggered Landslides in Northwest- ern Croatia. In Proceedings of the 2nd Regional Symposium on Landslides in the Adriatic-Balkan Region, Belgrade, Serbia, 14–15 May 2015; pp. 103–107. [Google Scholar]
- Aničić, B.; Juriša, M. Basic Geological Map, Scale 1:100,000, Rogatec, Sheet 33–68; Geological Department: Belgrade, Serbia, 1984. [Google Scholar]
- Aničić, B.; Juriša, M. Geological Notes for Basic Geological Map, Scale 1:100,000, Rogatec, Sheet 33–68; Geological Department: Belgrade, Serbia, 1983. [Google Scholar]
- Šimunić, A.; Pikija, M.; Hečimović, I.; Šimunić, A. Geological Notes for Basic Geological Map, Scale 1:100,000, Varaždin, Sheet 33–69; Geological Department: Belgrade, Serbia, 1982. [Google Scholar]
- Šimunić, A.; Pikija, M.; Hečimović, I. Basic Geological Map, Scale 1:100,000, Varaždin, Sheet 33–69; Geological Department: Belgrade, Serbia, 1982. [Google Scholar]
- Zaninović, K.; Gajić-Čapka, K.; Perčec Tadić, M.; Vučetić, M.; Milković, J.; Bajić, A.; Cindrić, K.; Cvitan, L.; Katušin, Z.; Kaučić, D. Climate Atlas of Croatia 1961–1990, 1971–2000; Croatian Meteorological and Hydrological Service: Zagreb, Croatia, 2008. [Google Scholar]
- URL-1. Available online: https://meteo.hr/klima.php?section=klima_podaci¶m=k1&Grad=varazdin (accessed on 6 June 2024).
- Razak, K.A.; Straatsma, M.W.; van Westen, C.J.; Malet, J.P.; de Jong, S.M. Airborne Laser Scanning of Forested Landslides Characterization: Terrain Model Quality and Visualization. Geomorphology 2011, 126, 186–200. [Google Scholar] [CrossRef]
- Bernat Gazibara, S.; Krkač, M.; Mihalić Arbanas, S. Verificiation of Historical Landslide Inventory Maps for the Podsljeme Area in the City of Zagreb Using LiDAR Based LiDAR Landslide Inventory. Rudarsko-Geološko-Naftni Zb. 2019, 34. [Google Scholar] [CrossRef]
- Bernat Gazibara, S.; Krkač, M.; Mihalić Arbanas, S. Landslide Inventory Mapping Using LiDAR Data in the City of Zagreb (Croatia). J. Maps 2019, 15, 773–779. [Google Scholar] [CrossRef]
- Krkač, M.; Bernat Gazibara, S.; Sinčić, M.; Lukačić, H.; Šarić, G.; Snježana, M.A. Impact of Input Data on the Quality of the Landslide Susceptibility Large-Scale Maps: A Case Study from NW Croatia. In Progress in Landslide Research and Technology; Alcánta-ra-Ayala, I., Arbanas, Ž., Cuomo, S., Huntley, D., Konagai, K., Mihalić Arbanas, S., Mikoš, M., Sassa, K., Tang, H., Tiwari, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2023; pp. 135–146. [Google Scholar] [CrossRef]
- Jagodnik, P.; Bernat Gazibara, S.; Jagodnik, V. Typed and Distribution of Quaternary Deposits Originating from Carbonate Rock Slopes in the Vinodol Valley, Croatia—New Insight Using Airborne LiDAR Data. Rudarsko-Geološko-Naftni Zb. 2020, 35, 57–77. [Google Scholar] [CrossRef]
- Jagodnik, P.; Bernat Gazibara, S.; Arbanas, Ž.; Mihalić Arbanas, S. Engineering Geological Mapping Using Airborne LiDAR Datasets—An Example from the Vinodol Valley, Croatia. J. Maps 2020, 16, 855–866. [Google Scholar] [CrossRef]
- URL-2. Available online: http://Geoportal.Dgu.Hr/Wms?Layers=DOF (accessed on 6 June 2024).
- Marchesini, I.; Ardizzone, F.; Alvioli, M.; Rossi, M.; Guzzetti, F. Non-Susceptible Landslide Areas in Italy and in the Mediter- ranean Region. Nat. Hazards Earth Syst. Sci. 2014, 14, 2215–2231. [Google Scholar] [CrossRef]
- Sinčić, M.; Bernat Gazibara, S.; Rossi, M.; Mihalić Arbanas, S. Comparison of Conditioning Factors Classification Criteria in Large Scale Statistically Based Landslide Susceptibility Models. Nat. Hazards Earth Syst. Sci. 2024. [Google Scholar] [CrossRef]
- Evans, J.S.; Oakleaf, J.; Cushman, S.A.; Theobald, D. An Arc Gis Toolbox for Surface Gradient and Geo-Morphometric Modeling, Version 2.0-0; 2014. Available online: https://evansmurphy.wixsite.com/evansspatial/arcgis-gradient-metrics-toolbox (accessed on 1 June 2024).
- Bernat Gazibara, S.; Sinčić, M.; Rossi, M.; Reichenbach, P.; Krkač, M.; Lukačić, H.; Jagodnik, P.; Šarić, G.; Mihalić Arbanas, S. Ap-plication of LAND-SUITE for Landslide Susceptibility Modelling Using Different Mapping Units: A Case Study in Croatia. In Progress in Landslide Research and Technology, Volume 2 Issue 2, 2023; Alcantara-Ayala, I., Arbanas, Ž., Huntley, D., Konagai, K., Mihalić Arbanas, S., Mikoš, M., Ramesh, M.V., Sassa, K., Sassa, S., Tang, H., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2023; pp. 343–354. [Google Scholar] [CrossRef]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal Landslide Susceptibility Zonation Based on Multiple Forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Wang, L.-J.; Guo, M.; Sawada, K.; Lin, J.; Zhang, J. A Comparative Study of Landslide Susceptibility Maps Using Logistic Regression, Frequency Ratio, Decision Tree, Weights of Evidence and Artificial Neural Network. Geosci. J. 2016, 20, 117–136. [Google Scholar] [CrossRef]
- The MathWorks Inc. MATLAB, Version: 9.10.0.1602886 (R2021b; The MathWorks Inc.: Natick, MA, USA, 2021; Available online: https://www.mathworks.com (accessed on 6 June 2024).
- The MathWorks Inc. Statistics and Machine Learning, Toolbox: 12.1 (R2021); The MathWorks Inc.: Natick, MA, USA, 2021; Available online: https://www.mathworks.com/products/statistics.html (accessed on 6 June 2024).
- URL-3. Available online: https://www.mathworks.com/help/stats/choose-a-classifier.html (accessed on 6 June 2024).
- Gorsevski, P.V.; Gessler, P.E.; Foltz, R.B.; Elliot, W.J. Spatial Prediction of Landslide Hazard Using Logistic Regression and ROC Analysis. Trans. GIS 2006, 10, 395–415. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 159–174. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Rossi, M.; Reichenbach, P. LAND-SE: A Software for Statistically Based Landslide Susceptibility Zonation, Version 1.0. Geosci. Model Dev. 2016, 9, 3533–3543. [Google Scholar] [CrossRef]
- Rossi, M.; Bornaetxea, T.; Reichenbach, P. LAND-SUITE V1.0: A Suite of Tools for Statistically Based Landslide Susceptibility Zonation. Geosci. Model Dev. 2022, 15, 5651–5666. [Google Scholar] [CrossRef]
- Tyagi, A.; Tiwari, R.K.; James, N. Mapping the Landslide Susceptibility Considering Future Land-Use Land-Cover Scenario. Landslides 2023, 20, 65–76. [Google Scholar] [CrossRef]
- Sweets, J.A. Measuring the Accuracy of Diagnostic Systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Amount of Polygons (N) | Density (N/km2) | Min. (m2) | Max. (m2) | Average (m2) | Median (m2) | Standard Deviation (m2) | Total Size (km2) | |
|---|---|---|---|---|---|---|---|---|
| Landslide inventory | 912 | 45 | 3.3 | 13,779 | 448 | 173 | 880 | 0.41 |
| Stable area inventory | 912 | 45 | 4.4 | 6986 | 421 | 194 | 662 | 0.38 |
| Model Training Extents | ||||||||
|---|---|---|---|---|---|---|---|---|
| Scenario | Unstable Area | Stable Area | DTM-Derived LCFs | Abbr. * | ||||
| Sampling Type | Abbr. * | Pixel (N) | Sampling Type | Abbr. * | Pixel (N) | |||
| S1 | Landslide polygon | P | 7793 | Randomly generated stable point | R | 7793 | Regular | _r |
| A reference point scenario, using commonly used landslide polygon sampling and random stable points | ||||||||
| S2 | Landslide polygon | P | 7793 | Randomly generated stable point | R | 7793 | Smooth | _s |
| A novel scenario testing unstable area sampling by smoothing DTM derived LCFs to simulate terrain conditions prior to landslide occurrence, i.e., capturing undisturbed terrain conditions at landslide locations | ||||||||
| S3 | Buffer zone on landslide polygon | B | 10,099 | Randomly generated point | R | 10,067 | Regular | _r |
| An alternative to scenario S2, using previously researched buffer zones to capture terrain conditions not influenced by landslide presence | ||||||||
| S4 | Landslide polygon | P | 7793 | Mapped stable polygon | M | 7543 | Regular | _r |
| A novel scenario testing stable area sampling by sampling mapped stable polygons and using unstable landslide polygons as a reference point | ||||||||
| S5 | Landslide polygon | P | 7793 | Mapped stable polygon | M | 7543 | Smooth | _s |
| Testing unstable areas as in scenario S2 with an addition of novel mapped stable polygons | ||||||||
| S6 | Buffer zone on landslide polygon | B | 10,099 | Buffer zone on mapped stable polygon | bM | 9573 | Regular | _r |
| Testing unstable areas as in scenario S3 with an addition of novel mapped stable polygons | ||||||||
| S7 | Landslide centroid | C | 456 | Randomly generated stable point | R | 457 | Regular | _r |
| A reference point scenario, using commonly used landslide centroid sampling and random stable points | ||||||||
| S8 | Landslide centroid | C | 456 | Centroid from mapped stable polygon | cM | 456 | Regular | _r |
| A novel scenario testing stable area sampling by sampling centroids from mapped stable polygons and using unstable landslide centroid as a reference point | ||||||||
| Landslide Conditioning Factor | Source Data | Obtained by | |
|---|---|---|---|
| Geomorphological | Elevation | LiDAR point cloud (class 2, bare earth) | Interpolation |
| Landform curvature | Elevation | ArcGIS 10.8 Landform curvature tool [79] | |
| Aspect | Elevation | ArcGIS 10.8 Aspect tool | |
| Geological | Engineering formations | Croatian Basic Geological Maps [64,67], HR-LiDAR DTM | Digitization, visual interpretation of HR-LiDAR DTM derivatives |
| Proximity to engineering formations | Engineering formations | ArcGIS 10.8 Multiple Ring Buffer tool | |
| Hydrological | Proximity to drainage network | Elevation | ArcGIS 10.8 Spatial Analyst Toolbox |
| Site exposure index | Elevation | ArcGIS 10.8 Site Exposure Index tool [79] | |
| Integrated moisture index | Elevation | ArcGIS 10.8 Integrated Moisture Index tool [79] | |
| Anthropo-genic | Land-use | Digital orthophoto, LiDAR point cloud, HR-LiDAR DTM, Open Street Map, Land-use planning maps | see [19] Figure 3 |
| Proximity to traffic infrastructure | Roads input data (see [19] Figure 3) | ArcGIS 10.8 Multiple Ring Buffer tool | |
| Proximity to land-use contact | Land-use | ArcGIS 10.8 Multiple Ring Buffer tool |
| Landslide Conditioning Factors (LCFs) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Name | Continuous LCFs | Categorical LCFs | ||||||
| Stretched Raster | Line Vector | Classes (N) | ||||||
| Min. | Max. | Mean | St. Dev. | Interval (m) | Classes (N) | |||
| Geomorphological | Elevation R | 222.5 | 679.8 | 304.4 | 77.3 | |||
| Elevation S | 222.5 | 679.8 | 304.4 | 77.3 | ||||
| Slope R | 0 | 80.3 | 18.9 | 10.2 | ||||
| Slope S | 0 | 80.3 | 18.9 | 10.2 | ||||
| Landform curvature R | −2.6 | 2.1 | 2.1 | 0.1 | ||||
| Landform curvature S | −2.6 | 2.1 | 2.0 | 0.1 | ||||
| Aspect R | 0 | 360 | 183.8 | 89.6 | ||||
| Aspect S | 0 | 360 | 183.8 | 89.6 | ||||
| Geological | Engineering formations | 5 | ||||||
| Proximity to engineering formations | 5 | 104 | ||||||
| Hydrological | Proximity to drainage network | 5 | 32 | |||||
| Site exposure index R | −55 | 77 | 2.9 | 14.8 | ||||
| Site exposure index S | −55 | 77 | 2.9 | 14.8 | ||||
| Integrated moisture index R | −2.8 | 10,416 | 115.2 | 248.0 | ||||
| Integrated moisture index S | −2.8 | 10,416 | 114.3 | 242.0 | ||||
| Anthropogenic | Land-use | 4 | ||||||
| Proximity to traffic infrastructure | 5 | 52 | ||||||
| Proximity to land-use contact | 5 | 117 | ||||||
| Excluded LCF | S1-PR_r (SVM Method) | S4-PM_r (SVM Method) | ||
|---|---|---|---|---|
| Cohen’s Kappa | AUC | Cohen’s Kappa | AUC | |
| Elevation | 0.392 | 0.761 | 0.813 | 0.972 |
| Slope ** | 0.376 | 0.756 | 0.725 | 0.939 |
| Landform curvature | 0.365 | 0.752 | 0.812 | 0.971 |
| Aspect | 0.388 | 0.762 | 0.816 | 0.971 |
| Engineering formations * | 0.342 | 0.715 | 0.807 | 0.950 |
| Proximity to engineering formations | 0.381 | 0.755 | 0.815 | 0.972 |
| Proximity to drainage network | 0.356 | 0.739 | 0.817 | 0.959 |
| Site exposure index | 0.383 | 0.760 | 0.815 | 0.969 |
| Integrated moisture index | 0.389 | 0.762 | 0.815 | 0.972 |
| Land-use | 0.377 | 0.756 | 0.805 | 0.967 |
| Proximity to traffic infrastructure | 0.386 | 0.762 | 0.814 | 0.972 |
| Proximity to land-use contact | 0.384 | 0.758 | 0.814 | 0.967 |
| Method | S1-PR_r | S2-PR_s | S3-BR_r | S4-PM_r | S5-PM_s | S6-BbM_r | S7-CR_r | S8-CcM_r |
|---|---|---|---|---|---|---|---|---|
| LR | 0.790 | 0.772 | 0.754 | 0.683 | 0.662 | 0.690 | 0.737 | 0.696 |
| NN | 0.764 | 0.805 | 0.760 | 0.670 | 0.679 | 0.690 | 0.710 | 0.661 |
| RF | 0.796 | 0.804 | 0.753 | 0.726 | 0.727 | 0.698 | 0.757 | 0.705 |
| SVM | 0.787 | 0.769 | 0.760 | 0.680 | 0.659 | 0.697 | 0.729 | 0.705 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sinčić, M.; Bernat Gazibara, S.; Rossi, M.; Krkač, M.; Mihalić Arbanas, S. A Comprehensive Comparison of Stable and Unstable Area Sampling Strategies in Large-Scale Landslide Susceptibility Models Using Machine Learning Methods. Remote Sens. 2024, 16, 2923. https://doi.org/10.3390/rs16162923
Sinčić M, Bernat Gazibara S, Rossi M, Krkač M, Mihalić Arbanas S. A Comprehensive Comparison of Stable and Unstable Area Sampling Strategies in Large-Scale Landslide Susceptibility Models Using Machine Learning Methods. Remote Sensing. 2024; 16(16):2923. https://doi.org/10.3390/rs16162923
Chicago/Turabian StyleSinčić, Marko, Sanja Bernat Gazibara, Mauro Rossi, Martin Krkač, and Snježana Mihalić Arbanas. 2024. "A Comprehensive Comparison of Stable and Unstable Area Sampling Strategies in Large-Scale Landslide Susceptibility Models Using Machine Learning Methods" Remote Sensing 16, no. 16: 2923. https://doi.org/10.3390/rs16162923
APA StyleSinčić, M., Bernat Gazibara, S., Rossi, M., Krkač, M., & Mihalić Arbanas, S. (2024). A Comprehensive Comparison of Stable and Unstable Area Sampling Strategies in Large-Scale Landslide Susceptibility Models Using Machine Learning Methods. Remote Sensing, 16(16), 2923. https://doi.org/10.3390/rs16162923