Author Contributions
Conceptualization, Y.L.; methodology, Y.L. and L.C.; software, Y.L.; validation, Y.L., N.L., X.H. and Y.Z.; formal analysis, Y.Z., Y.L. and X.N.; investigation, D.D., N.L., X.H., Y.Z. and Y.L.; resources, D.D., Y.L., X.N. and N.L.; data curation, Y.L., X.H. and N.L.; writing—original draft preparation, X.N., Y.L., N.L. and D.D.; writing—review and editing, Y.L. and L.C.; supervision, X.N., L.C. and Y.L.; project administration, X.H. and Y.L.; funding acquisition, L.C. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Infrared and visible comparative images.
Figure 1.
Infrared and visible comparative images.
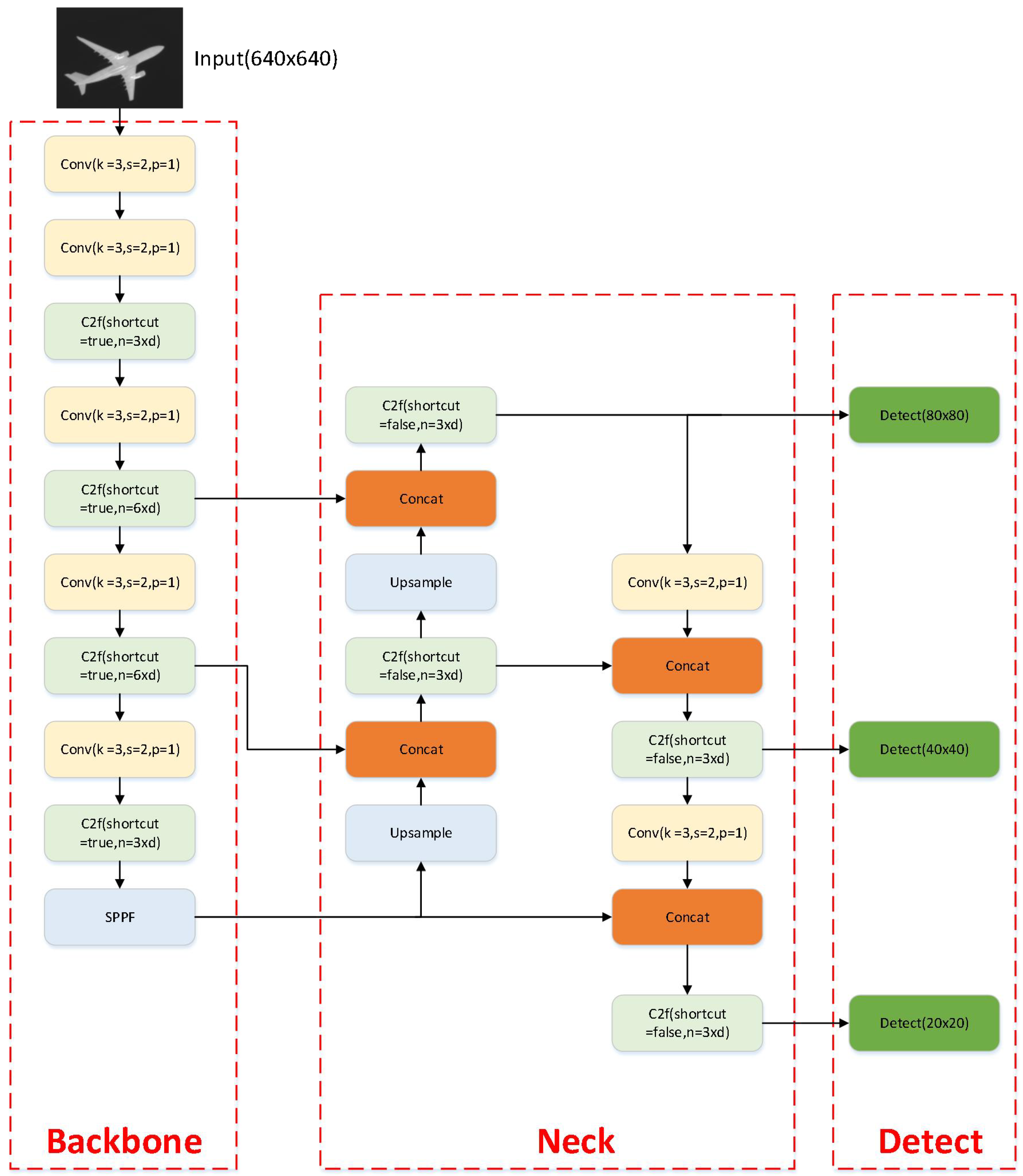
Figure 2.
Structure of the YOLOv8 Model. YOLOv8 is an advanced real-time object detection algorithm that achieves efficient and accurate detection performance through its unique network architecture design. The figure annotates the main components of the YOLOv8 network, including the input layer, feature extraction layers (which may consist of various convolutional blocks, residual connections, etc.), feature fusion layers, and the final detection layer. These layers work together to process the input image and output the results of object detection.
Figure 2.
Structure of the YOLOv8 Model. YOLOv8 is an advanced real-time object detection algorithm that achieves efficient and accurate detection performance through its unique network architecture design. The figure annotates the main components of the YOLOv8 network, including the input layer, feature extraction layers (which may consist of various convolutional blocks, residual connections, etc.), feature fusion layers, and the final detection layer. These layers work together to process the input image and output the results of object detection.
Figure 3.
Schematic diagram of the SA attention mechanism model.
Figure 3.
Schematic diagram of the SA attention mechanism model.
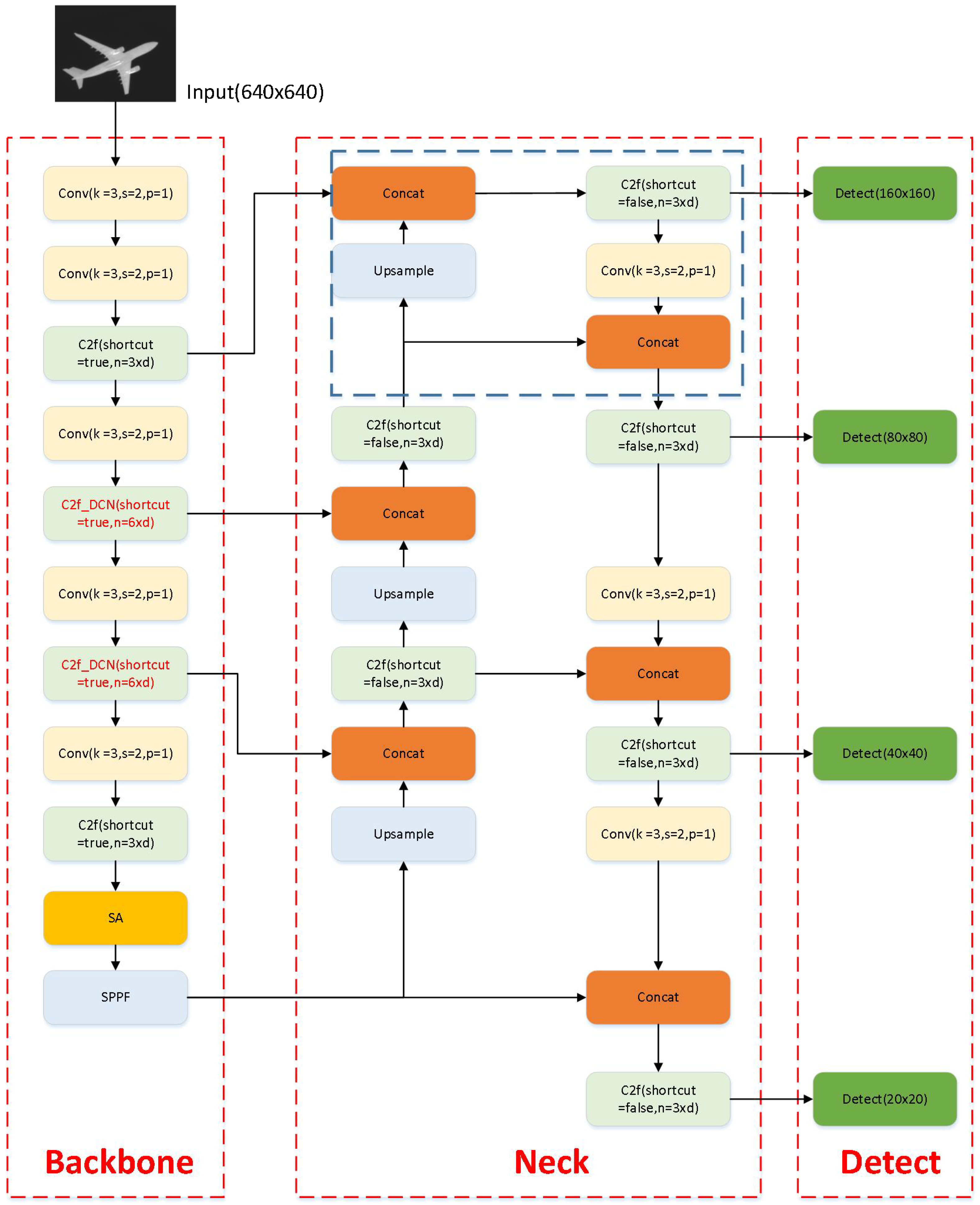
Figure 4.
Enhancing small object detection in YOLOv8 with a deformable convolution layer.
Figure 4.
Enhancing small object detection in YOLOv8 with a deformable convolution layer.
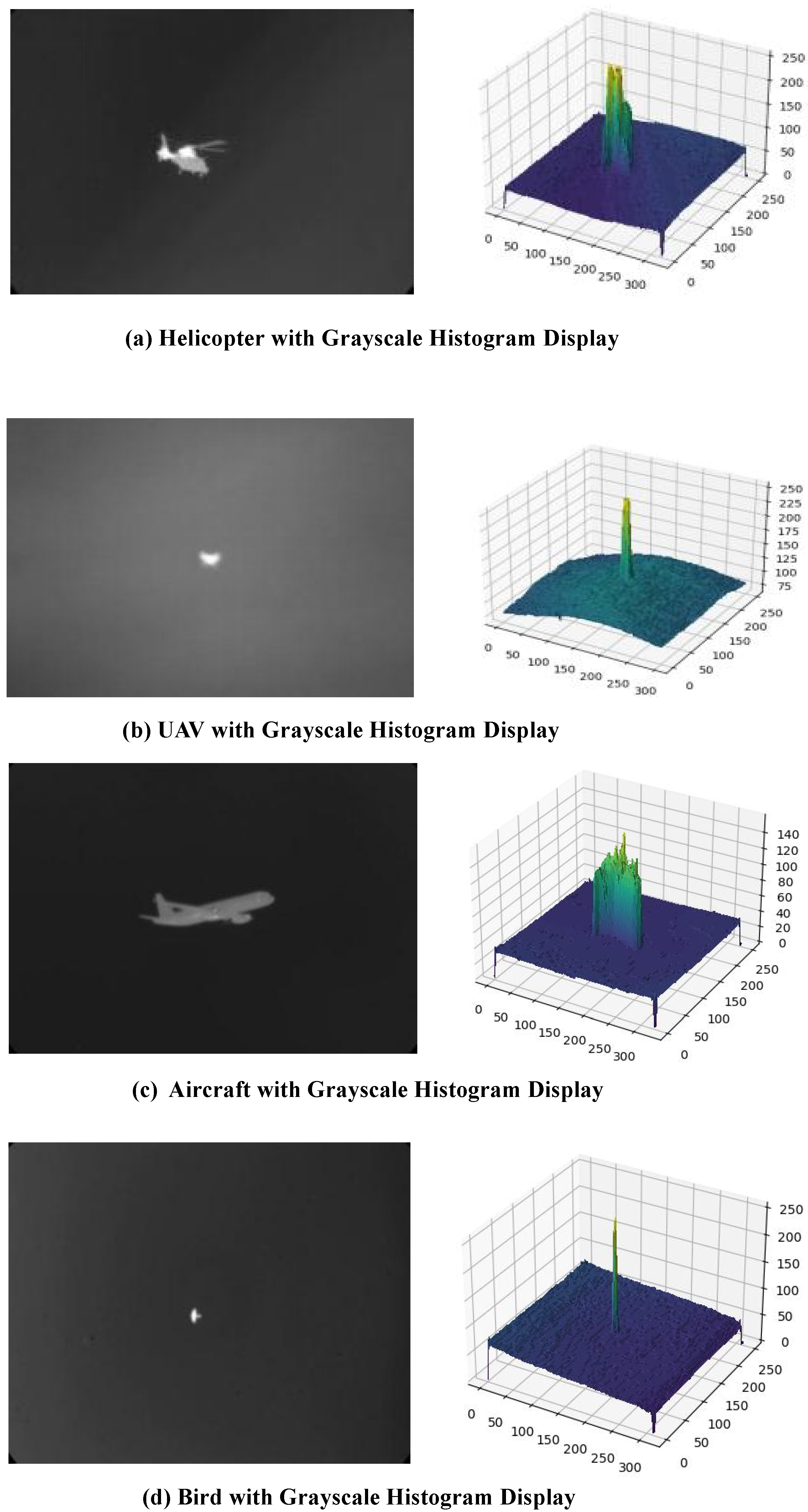
Figure 5.
Infrared weak targets of various spatial objects and their grayscale displays. The above displays infrared images of a helicopter (a), drone (b), civil aircraft (c), and bird (d), with corresponding grayscale histograms. The histograms show prominent target peaks against a relatively uniform background, facilitating target identification.
Figure 5.
Infrared weak targets of various spatial objects and their grayscale displays. The above displays infrared images of a helicopter (a), drone (b), civil aircraft (c), and bird (d), with corresponding grayscale histograms. The histograms show prominent target peaks against a relatively uniform background, facilitating target identification.
Figure 6.
Spatial infrared weak target (image inverted 180°). This figure presents the results of 180° inversion for infrared images of a helicopter (a), a drone (b), a civil aviation aircraft (c), and a bird (d), along with their corresponding grayscale histograms. Despite the mirroring effect caused by the inversion, the grayscale histograms clearly indicate that the contrast between the targets and the background remains unchanged, with the target grayscale values remaining prominently visible against the background.
Figure 6.
Spatial infrared weak target (image inverted 180°). This figure presents the results of 180° inversion for infrared images of a helicopter (a), a drone (b), a civil aviation aircraft (c), and a bird (d), along with their corresponding grayscale histograms. Despite the mirroring effect caused by the inversion, the grayscale histograms clearly indicate that the contrast between the targets and the background remains unchanged, with the target grayscale values remaining prominently visible against the background.
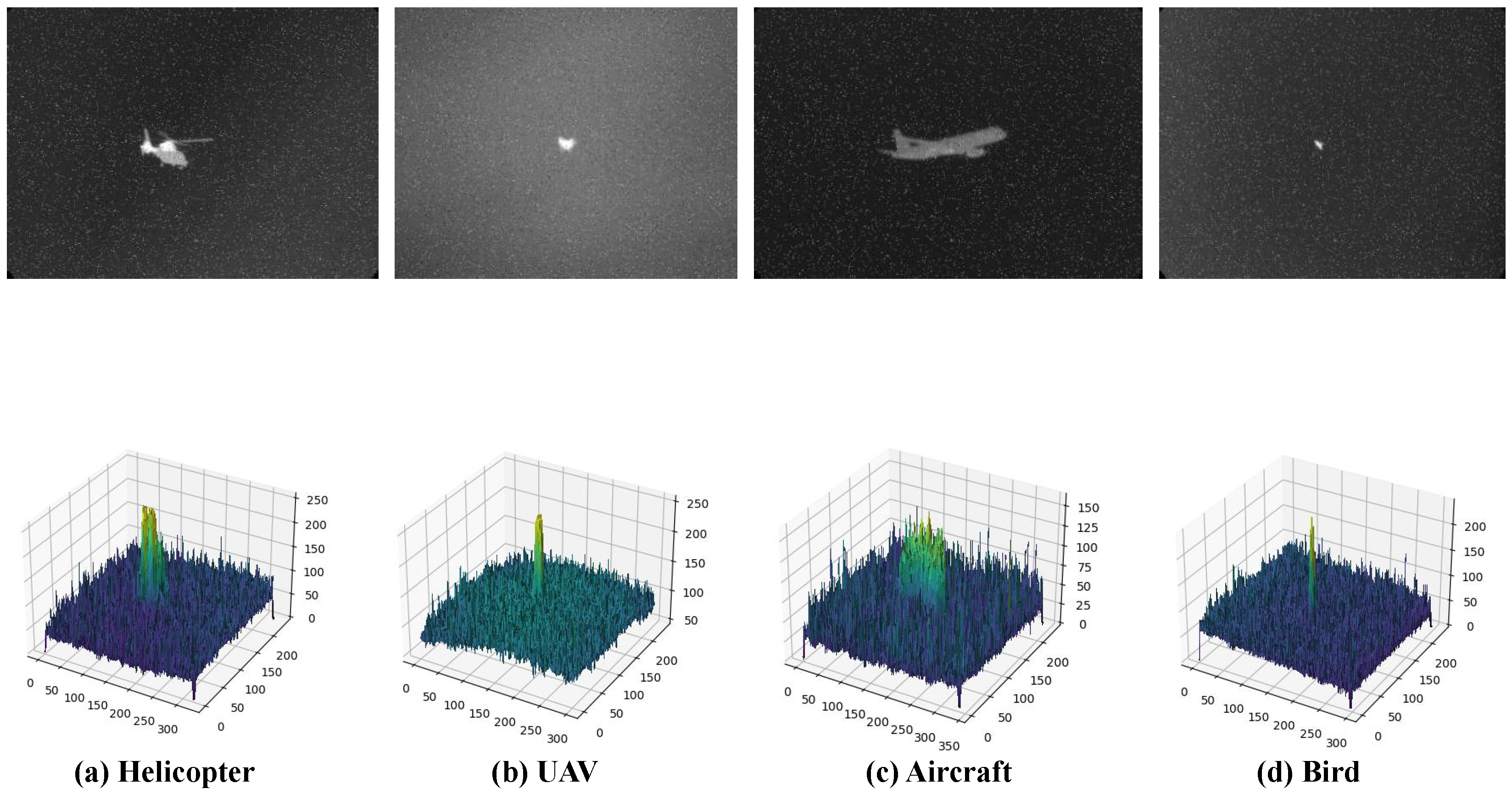
Figure 7.
Spatial infrared weak targets (with noise added).This figure presents infrared images of spatial infrared weak targets, including a helicopter (a), UAV (b), civilian aircraft (c), and bird (d), after the addition of salt-and-pepper noise. The noise, appearing as randomly distributed black and white pixels, simulates common noise conditions in real environments. Image inversion is utilized to further analyze the impact of noise on infrared imagery. The grayscale histogram above reveals significant changes in the grayscale distribution post-noise addition, notably the prominent peaks at extreme grayscale values (pure black and pure white), reflecting the randomness of the noise. Remarkably, despite the increased complexity introduced by the noise, the target objects, such as helicopters and UAV, maintain a certain level of contrast against the background.
Figure 7.
Spatial infrared weak targets (with noise added).This figure presents infrared images of spatial infrared weak targets, including a helicopter (a), UAV (b), civilian aircraft (c), and bird (d), after the addition of salt-and-pepper noise. The noise, appearing as randomly distributed black and white pixels, simulates common noise conditions in real environments. Image inversion is utilized to further analyze the impact of noise on infrared imagery. The grayscale histogram above reveals significant changes in the grayscale distribution post-noise addition, notably the prominent peaks at extreme grayscale values (pure black and pure white), reflecting the randomness of the noise. Remarkably, despite the increased complexity introduced by the noise, the target objects, such as helicopters and UAV, maintain a certain level of contrast against the background.
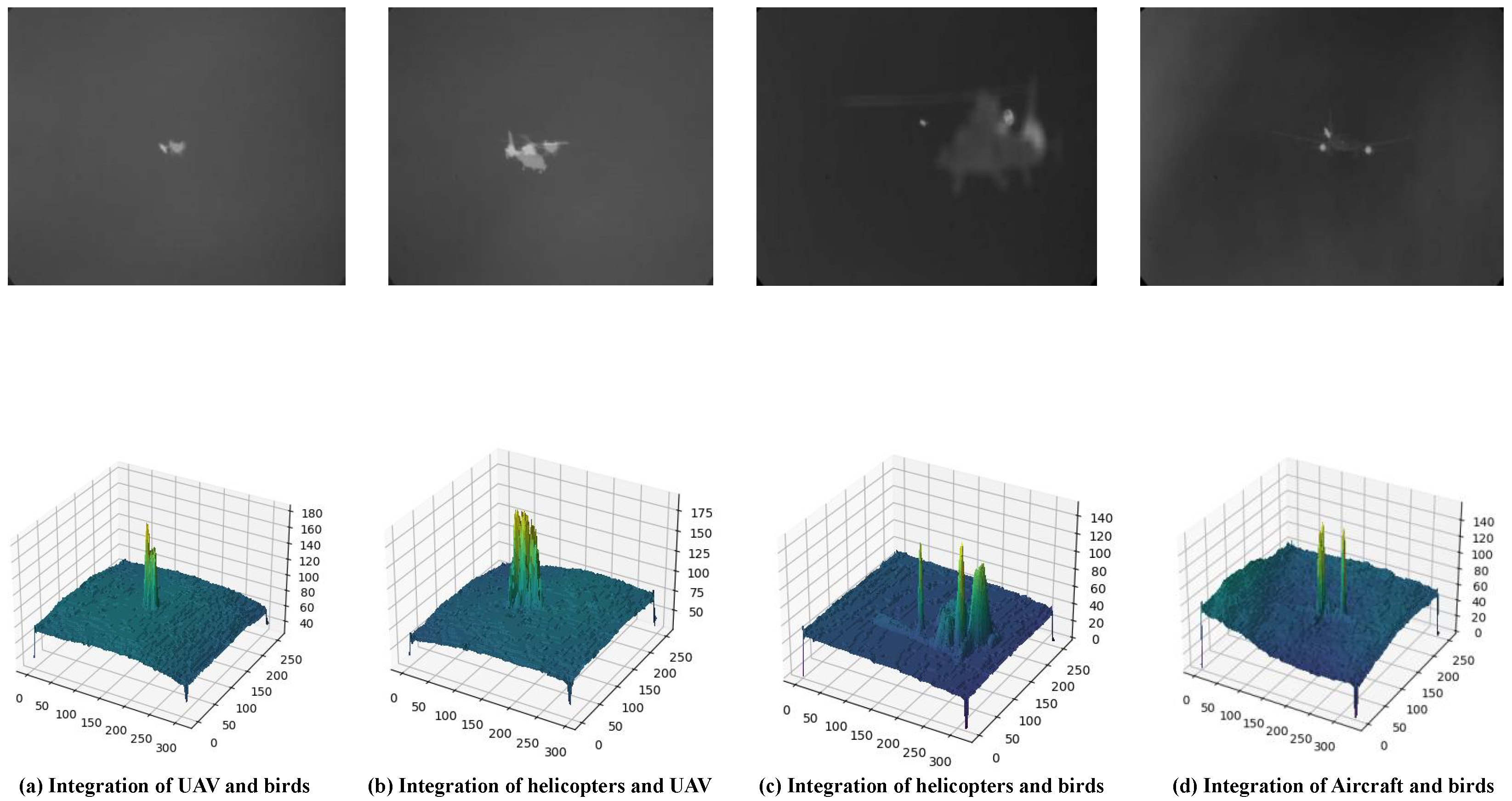
Figure 8.
Spatial infrared weak targets (image fusion). (a–d) demonstrate the infrared image fusion results of drone–bird, helicopter–drone, helicopter–bird, and airliner–bird pairs. These fusions span across different perspectives, significantly enriching the dataset, enhancing its diversity, and effectively expanding the sample size. By comparing the grayscale histograms before and after fusion, it is evident that noise peaks at extreme grayscale values are significantly suppressed, while the grayscale distribution of target objects becomes more concentrated and stable, resulting in improved contrast and enhanced recognizability. This validates the effectiveness of the fused images as high-quality, newly added samples.
Figure 8.
Spatial infrared weak targets (image fusion). (a–d) demonstrate the infrared image fusion results of drone–bird, helicopter–drone, helicopter–bird, and airliner–bird pairs. These fusions span across different perspectives, significantly enriching the dataset, enhancing its diversity, and effectively expanding the sample size. By comparing the grayscale histograms before and after fusion, it is evident that noise peaks at extreme grayscale values are significantly suppressed, while the grayscale distribution of target objects becomes more concentrated and stable, resulting in improved contrast and enhanced recognizability. This validates the effectiveness of the fused images as high-quality, newly added samples.
Figure 9.
Illustration of the loss function.
Figure 9.
Illustration of the loss function.
Figure 10.
Display of spatial infrared weak target dataset images and their grayscale versions. This figure presents a carefully selected sample of images from the current training dataset along with their corresponding grayscale distribution characteristics. Located at the top left corner, four image blocks showcase the infrared imaging effects of UAVs, civil aircraft, birds, and helicopters under varying environmental conditions. Each block contains four images, displaying the infrared features of their respective targets against diverse backgrounds, thoroughly demonstrating the remarkable capability of infrared imaging technology in capturing a wide range of targets. Immediately following each image block are their corresponding average grayscale histograms. These histograms, derived from statistical analysis, visually represent the distribution differences in grayscale levels between the target images and their backgrounds. Clearly discernible from the histograms, the grayscale value distributions within the target regions of UAVs, civil aircraft, birds, and helicopters are more concentrated and stable compared to their backgrounds, creating a sharp contrast. This indicates that these spatial infrared targets exhibit higher contrast in infrared images, making them more prominent and facilitating subsequent tasks such as recognition, tracking, and analysis.
Figure 10.
Display of spatial infrared weak target dataset images and their grayscale versions. This figure presents a carefully selected sample of images from the current training dataset along with their corresponding grayscale distribution characteristics. Located at the top left corner, four image blocks showcase the infrared imaging effects of UAVs, civil aircraft, birds, and helicopters under varying environmental conditions. Each block contains four images, displaying the infrared features of their respective targets against diverse backgrounds, thoroughly demonstrating the remarkable capability of infrared imaging technology in capturing a wide range of targets. Immediately following each image block are their corresponding average grayscale histograms. These histograms, derived from statistical analysis, visually represent the distribution differences in grayscale levels between the target images and their backgrounds. Clearly discernible from the histograms, the grayscale value distributions within the target regions of UAVs, civil aircraft, birds, and helicopters are more concentrated and stable compared to their backgrounds, creating a sharp contrast. This indicates that these spatial infrared targets exhibit higher contrast in infrared images, making them more prominent and facilitating subsequent tasks such as recognition, tracking, and analysis.
![Remotesensing 16 02878 g010]()
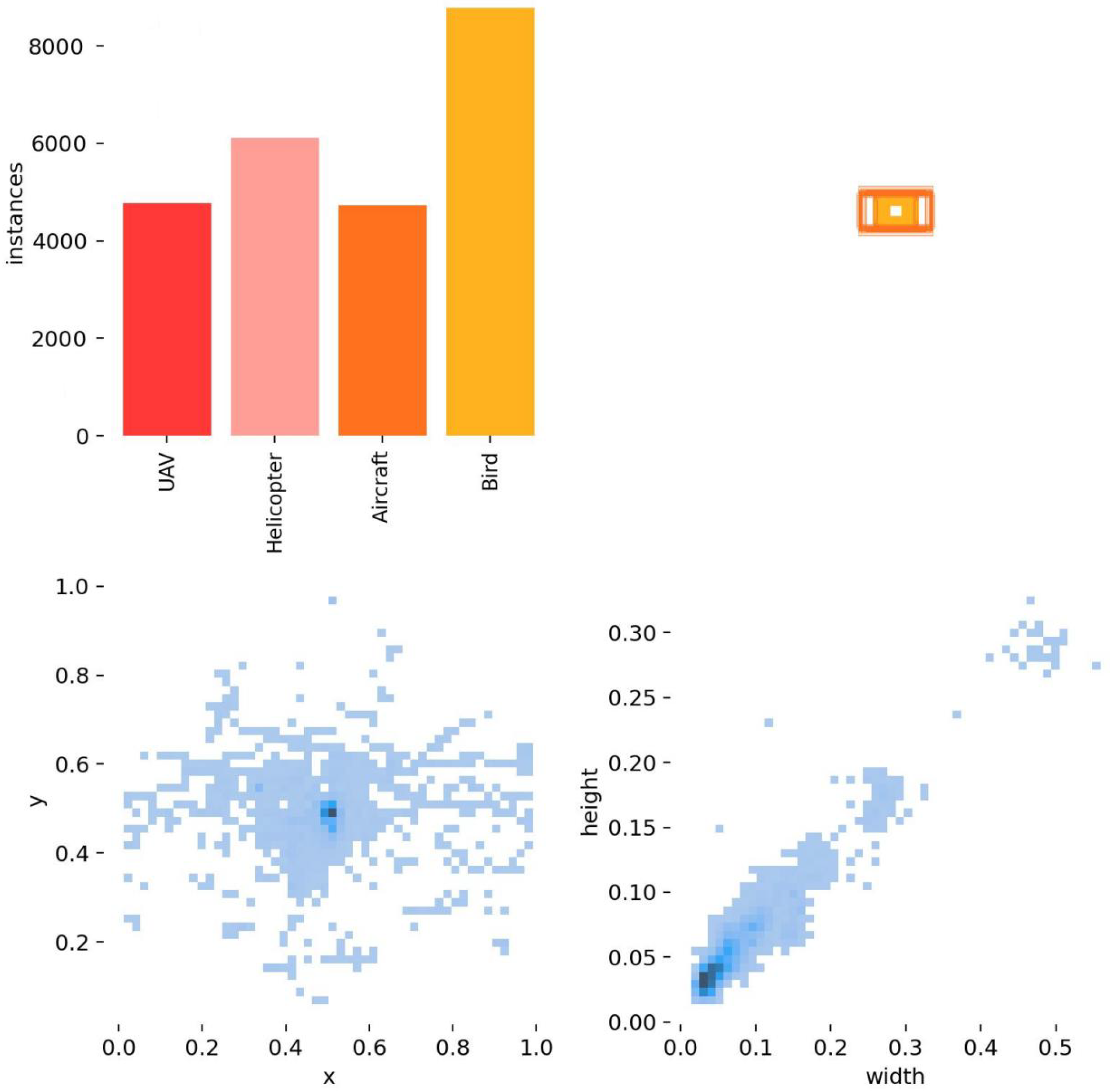
Figure 11.
Detailed schematic diagram of the spatial infrared weak target dataset.
Figure 11.
Detailed schematic diagram of the spatial infrared weak target dataset.
Figure 12.
Confusion matrix.
Figure 12.
Confusion matrix.
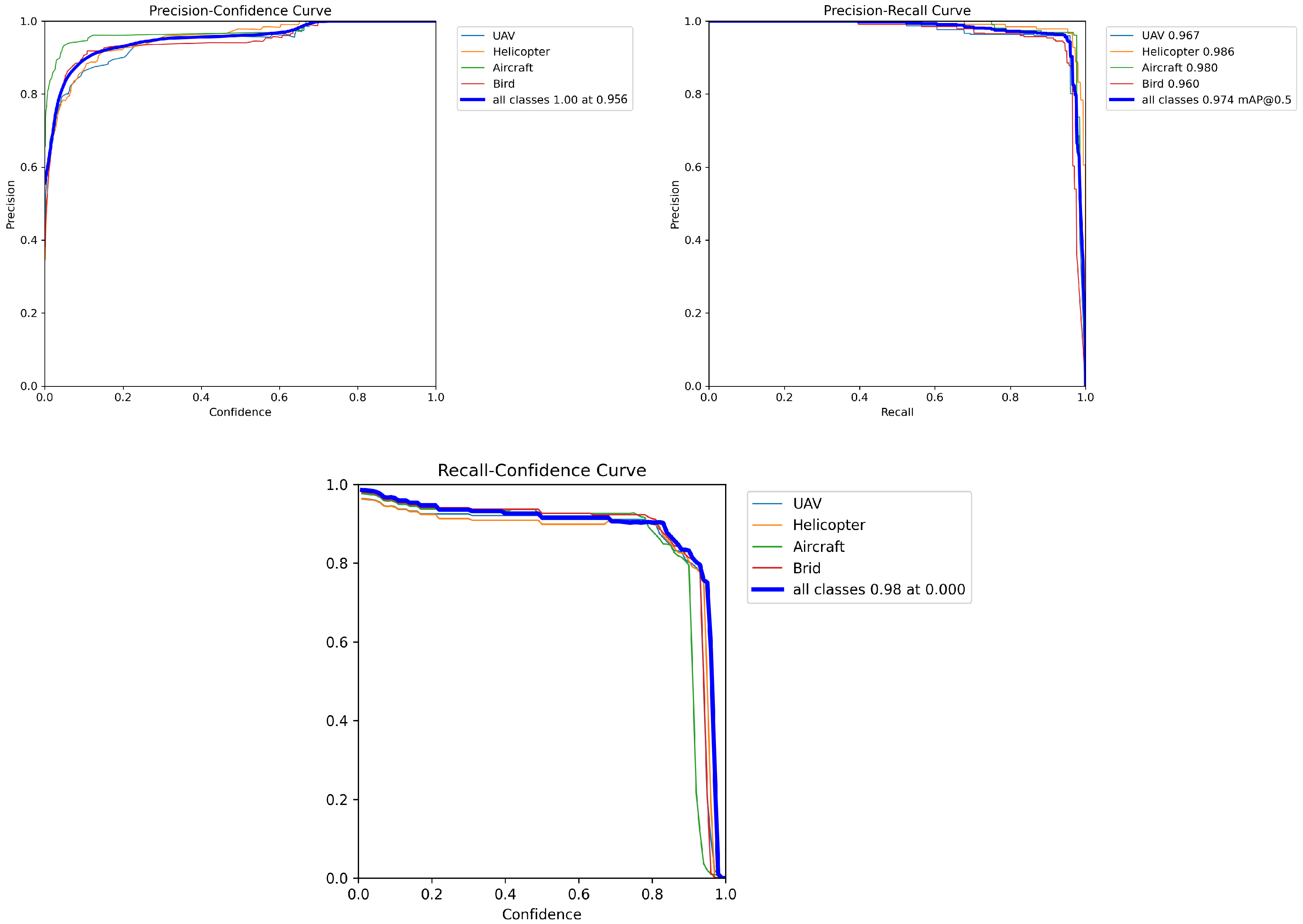
Figure 13.
Training model result curves (precision, recall, mAP).
Figure 13.
Training model result curves (precision, recall, mAP).
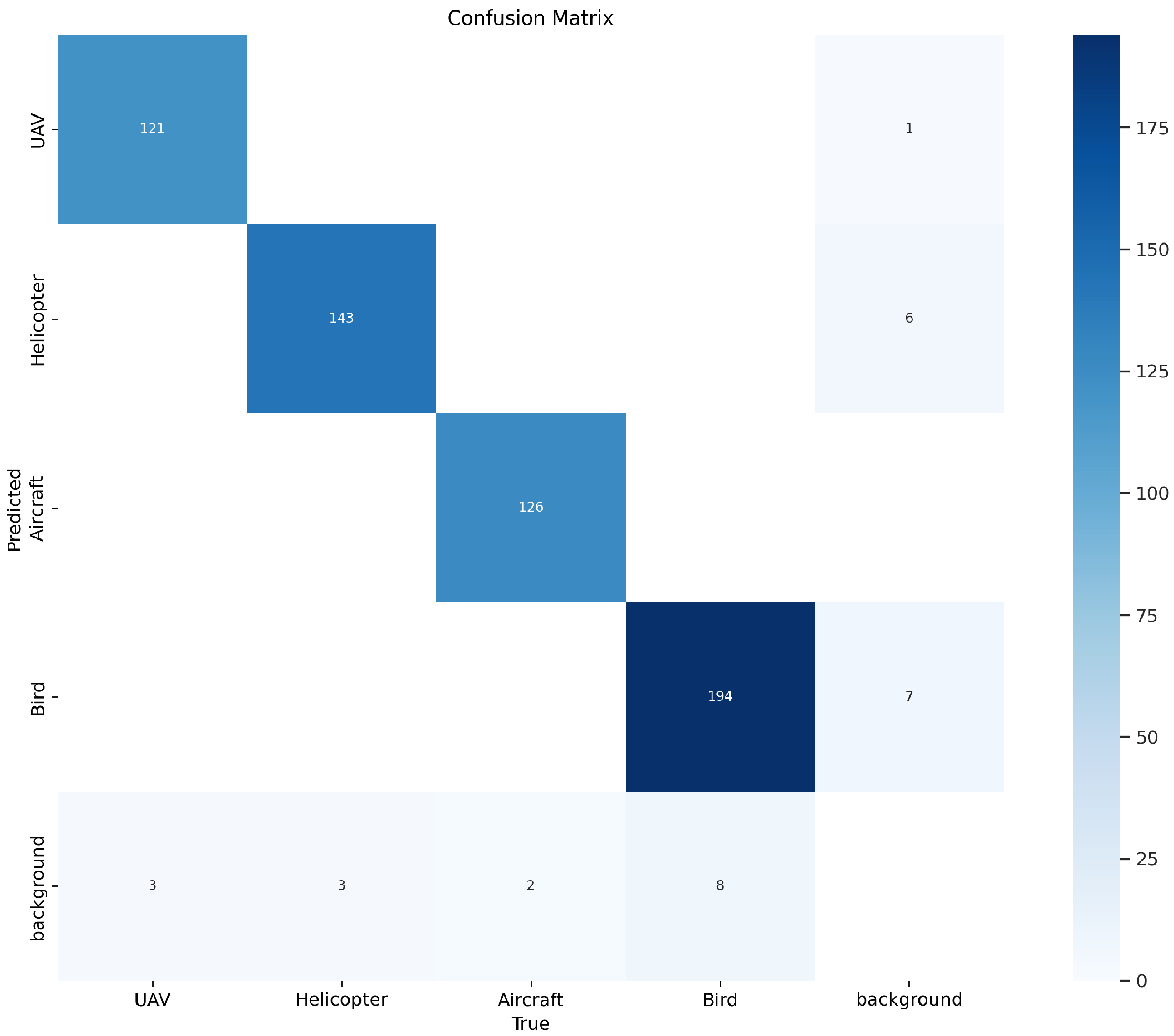
Figure 14.
Confusion matrix of the MY-YOLOv8 model.
Figure 14.
Confusion matrix of the MY-YOLOv8 model.
Figure 15.
Exhibition of detection results. This figure set showcases the remarkable achievements of the optimized MY-YOLOv8 model in detecting four specific targets: civil aviation aircraft, birds, drones, and helicopters. The first column on the left features five images focusing on the detection of civil aviation aircraft, followed by detection results for birds, drones, and helicopters, respectively. Upon close examination of these detection outcomes, it becomes evident that the MY-YOLOv8 model demonstrates exceptionally high detection accuracy, achieving a stable recognition accuracy rate of over 95% for all target categories. This solidifies the model’s robust capability for efficient and precise detection of multiple target types in complex environments.
Figure 15.
Exhibition of detection results. This figure set showcases the remarkable achievements of the optimized MY-YOLOv8 model in detecting four specific targets: civil aviation aircraft, birds, drones, and helicopters. The first column on the left features five images focusing on the detection of civil aviation aircraft, followed by detection results for birds, drones, and helicopters, respectively. Upon close examination of these detection outcomes, it becomes evident that the MY-YOLOv8 model demonstrates exceptionally high detection accuracy, achieving a stable recognition accuracy rate of over 95% for all target categories. This solidifies the model’s robust capability for efficient and precise detection of multiple target types in complex environments.
Table 1.
Performance comparison of YOLOv8 model on spatial infrared weak target detection tasks.
Table 1.
Performance comparison of YOLOv8 model on spatial infrared weak target detection tasks.
| Attention Mechanism | Precision (%) | Recall (%) | mAP (%) | FPS (Frames/s) |
|---|
| No Attention | 90.3 | 91.2 | 93.2 | 147 |
| EMHSA | 90.1 | 90.6 | 94.5 | 128 |
| SGE | 91.2 | 90.1 | 93.2 | 120 |
| AFT | 91.4 | 89.8 | 93.5 | 132 |
| Outlook Attention | 90.5 | 89.2 | 94.1 | 136 |
| Shuffle Attention (SA) | 92.4 | 90.8 | 94.3 | 132 |
Table 2.
Performance comparison between YOLOv8 model and the model integrated with small target detection layer.
Table 2.
Performance comparison between YOLOv8 model and the model integrated with small target detection layer.
| Model | Precision (%) | Recall (%) | mAP (%) | FPS (Frames/s) |
|---|
| YOLOv8_n (Original Model) | 90.3 | 91.2 | 93.2 | 147 |
| YOLOv8_n_Small | 94.4 | 93.8 | 96.3 | 66 |
Table 3.
Performance comparison of YOLOv8 model before and after incorporating the DCNV4 module.
Table 3.
Performance comparison of YOLOv8 model before and after incorporating the DCNV4 module.
| Model | Precision (%) | Recall (%) | mAP (%) | FPS (Frames/s) |
|---|
| YOLOv8_n (Original Model) | 90.3 | 91.2 | 93.2 | 147 |
| YOLOv8_n_DCNV4 | 91.7 | 91.4 | 94.2 | 103 |
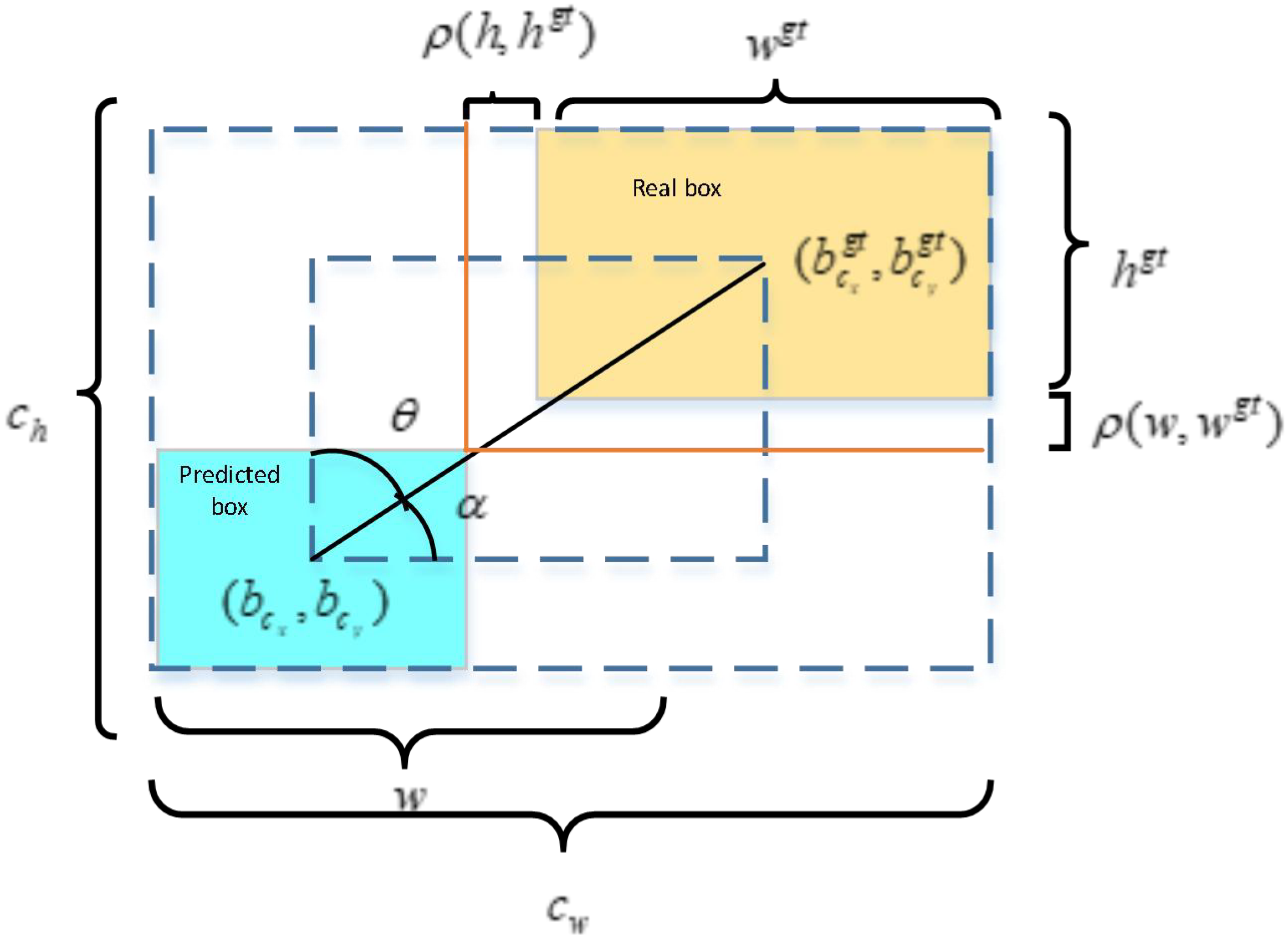
Table 4.
Performance comparison of different loss functions in training the YOLOv8 model.
Table 4.
Performance comparison of different loss functions in training the YOLOv8 model.
| Loss Function | Precision (%) | Recall (%) | mAP (%) | FPS |
|---|
| IoU | 90.3 | 91.2 | 93.2 | 147 |
| CIoU | 91.5 | 91.7 | 93.8 | 142 |
| DIoU | 91.1 | 91.6 | 93.3 | 144 |
| GIoU | 90.9 | 89.2 | 93.5 | 140 |
| EIoU | 91.2 | 90.8 | 94.1 | 141 |
| WIoU-v3 | 92.6 | 92.5 | 94.7 | 143 |
Table 5.
Detection results of multiple spatial infrared weak targets.
Table 5.
Detection results of multiple spatial infrared weak targets.
| Target | Precision (%) | Recall (%) | mAP (%) | FPS (Frames/s) |
|---|
| UAV | 95.1 | 94.3 | 96.7 | 58 |
| Helicopter | 96.7 | 94.2 | 98.6 | 61 |
| Civil Aviation | 96.3 | 95.1 | 98.0 | 59 |
| Bird | 94.3 | 95.3 | 96.0 | 61 |
| Overall | 95.6 | 94.7 | 97.4 | 59 |
Table 6.
Experimental results comparing MY-YOLOv8 model with other models.
Table 6.
Experimental results comparing MY-YOLOv8 model with other models.
| Model | Precision (%) | Recall (%) | mAP (%) | FPS (Frames/s) |
|---|
| MY-YOLOv8 | 95.6 | 94.7 | 97.4 | 59 |
| YOLOv8 | 90.3 | 91.2 | 93.2 | 147 |
| YOLOv7 | 81.2 | 83.1 | 84.4 | 95 |
| YOLOv5 | 82.6 | 81.2 | 85.1 | 94 |
| YOLOv4 | 86.3 | 82.8 | 84.5 | 38 |
| SSD | 82.1 | 81.5 | 83.2 | 44 |
| Faster R-CNN | 84.5 | 86.9 | 85.8 | 32 |
| CNN | 85.2 | 88.6 | 84.1 | 27 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}