1. Introduction
In recent years, propelled by advancements in sensor technology, the acquisition of remote sensing (RS) images has become increasingly convenient. In the field of remote sensing, tasks such as ground crop detection [
1,
2], change detection [
3,
4,
5], and urban scene segmentation [
6,
7,
8] have attracted increasing attention. For a more detailed field of remote sensing, remote sensing-based fire detection or segmentation can be important to reduce damage and analyze carbon emissions [
9].
Thanks to the availability of publicly accessible satellite data, hyperspectral images (HSIs) acquired through satellites have been widely employed for fire segmentation [
10,
11,
12]. Some works [
13,
14] use satellite post-disaster images as data and focus on detecting burned areas after wildfires. The reasons why these satellite images are not convenient for direct real-time wildfire detection are as follows: the inherent characteristics of satellites, such as low revisit rates and limited spatial resolution, significantly impede their utility in emergency situations, including fire disaster, as shown in
Figure 1. Consequently, relying solely on satellite remote sensing images proves challenging in meeting the real-time demands necessitated by such unforeseen events.
Unmanned aerial vehicles (UAVs) offer a flexible and cost-effective solution for capturing high-resolution remote sensing images at low altitudes, addressing the challenges associated with satellite imagery. Low-altitude UAV-based wildfire detection algorithms have been explored previously [
15,
16,
17]; these early methods leverage enhanced CNN architectures to extract information from low-altitude remote sensing images [
18,
19]. However, due to the inherent characteristics of CNNs, i.e., locality and translation invariance, they struggle to effectively capture global information within the images.
Visual Transformer (ViT) can obtain higher accuracy rates than CNNs in tasks, including image segmentation, for its effective attention mechanism [
20,
21,
22,
23,
24]. However, it requires a higher computational load. Even though several approaches have been proposed addressing this issue, e.g., the shifted window attention mechanism introduced in [
25], the existing methods [
26,
27] are still limited in fulfilling the task of real-time precise fire segmentation for low-altitude remote sensing images. Since images captured by UAV usually possess higher resolutions (typically 3840 × 2140) and encompass more advanced semantic information than common images, this is particularly true for UAV fire images. In order to achieve accurate segmentation results in RS images, the connection between the small fire point region and the overall image is indispensable, just like the annotated local information and global information in
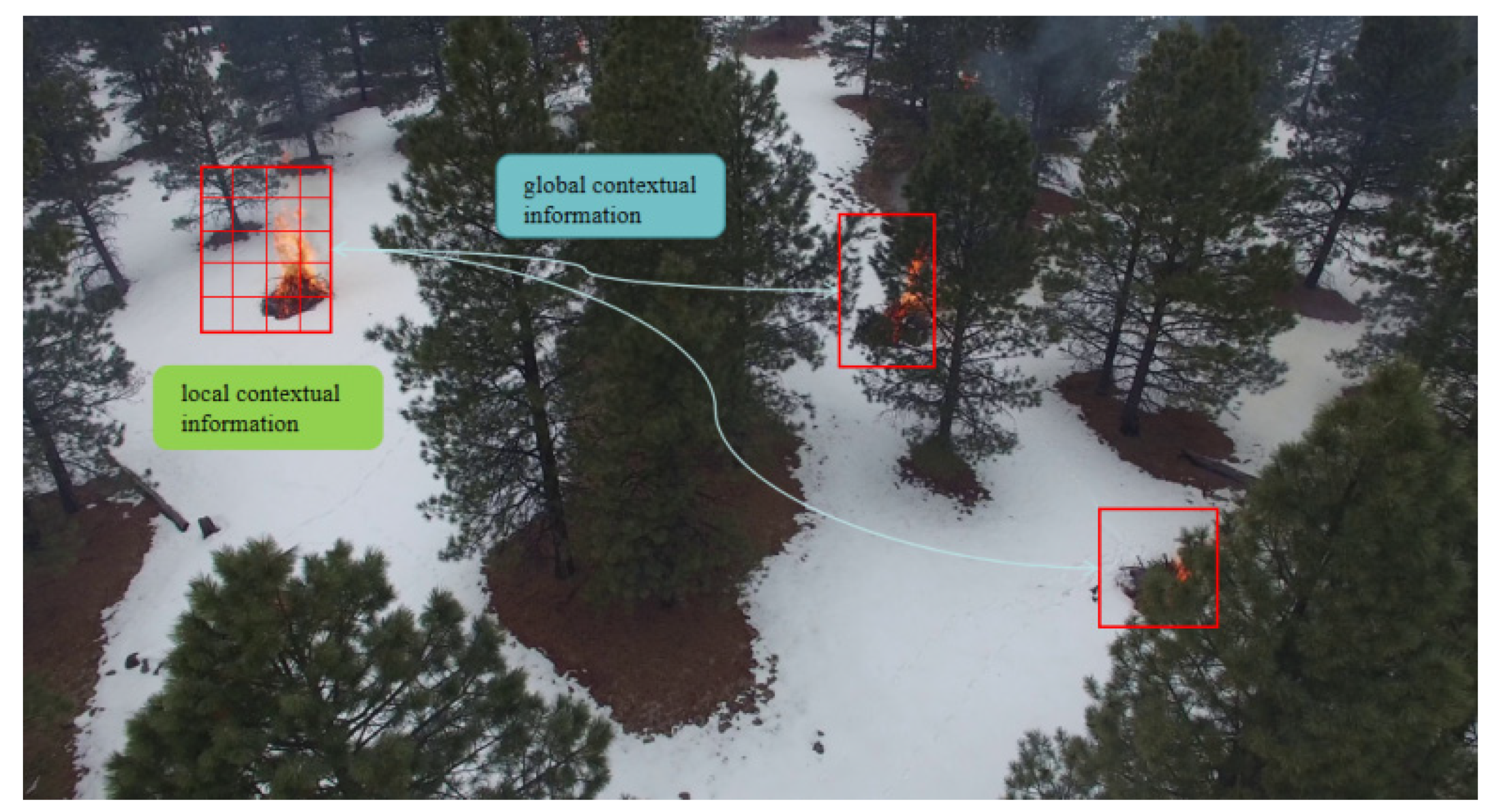
Figure 2.
This paper presents a novel network named FireFormer for the real-time wildfire segmentation of UAV RS images. FireFormer adopts a hybrid structure, comprising a ResNet18-based encoder [
28] and Transformer-based decoder. In the decoder, we introduce the Forest Fire Transformer Block (FFTB) as a key component to effectively integrate global and local contexts through a lightweight dual-branch structure. Moreover, to overcome the issue of blurred-edge features caused in a series of downsampling and upsampling operations in the network, we propose the Feature Refinement Net (FRN).
The main contributions of this research are outlined as follows:
- (1)
We propose the FFTB, which incorporates two parallel branches. These branches focus on capturing both the global and local information of the RS image.
- (2)
To acquire global information of an image with a lower computational cost, we have devised a Cross-Scaled Dot-Product attention mechanism. This mechanism captures global information at different scales and performs feature fusion.
- (3)
We propose the FRN to refine the output feature maps with finer details. This structure addresses the challenge of losing small objects during the segmentation process by leveraging parallel spatial and channel operations.
3. Methods
In this section, we begin by presenting an overview of the FireFormer model. Subsequently, we delve into the introduction of two pivotal modules within FireFormer, namely, the Forest Fire Transformer Block (FFTB) and the Feature Refinement Network (FRN).
3.1. Network Structure
The FireFormer model’s overall architecture, depicted in
Figure 4, is introduced. FireFormer adopts a hybrid structure comprising a CNN-based encoder and a Transformer-based decoder. By employing Weighted Feature map fusion (WF), FireFormer effectively obtains the discriminative features that are crucial for identifying forest fires in RS images. The formula denoting this feature map fusion is represented as Equation (1).
where
represents the output feature map of the Resnet encoder and
represents the output feature map of the decoder, and
is the a learnable weight value. Furthermore, the FRN is introduced to further enhance the segmentation accuracy of FireFormer.
In the CNN-based encoder of FireFormer, we have chosen to use a pre-trained ResNet18 as the encoder. ResNet18 is composed of four stages of residual blocks (Res Blocks), where each block downsamples the feature maps by a factor of two and doubles the number of channels. Assuming the size of the given RS image is , the output defined for each stage when passing the RS image through the encoder is , where .
In the Transformer-based decoder of FireFormer, we have designed a parallel dual-branch (e.g., global branch and local branch) FFTB to enhance the overall representation of the RS image features extracted by the CNN-based encoder, where each block upsamples the feature maps by a factor of two and halves the number of channels. When the given feature maps pass through the global branch of FFTB, Cross-Scaled Dot-Product attention (CDA) is employed to aggregate information from both the local details and the global context. Specifically, CDA divides the feature maps into patches, with each patch having a size of 2 × 2. These patches are then flattened and separated into Key (K), Query (Q) and Value (V) through linear operations. The aggregation of global information in the feature maps is achieved through Equation (2).
In the local branch of the FFTB, FireFormer incorporates a simple yet effective Local Feature Enhancement (LFE) block. This block is specifically designed to enhance FireFormer’s capability to accurately identify fire points in vast forests and improve its ability to discern fire edges. Lastly, the FFTB performs a summation operation on the output feature maps of both the global and local branches. This operation ensures that the output feature maps maintain their original resolution. The output of the each FFTB is defined as , where .
After the four encoding and decoding stages, we obtain the encoded feature maps and perform a weighted summation with the corresponding in skip connection. This process ensures a balance between local and global information in the feature maps. After four iterations, the final output feature maps are denoted as .
Segmenting small fire points in high-resolution RS images is challenging due to factors like tree occlusion and variations in fire intensity. To address this, we introduce the FRN at the end of FireFormer. The FRN refines the feature maps spatially and channel-wise, and the feature maps are upsampled four times to restore the original resolution. The refined feature maps obtained through the FRN are represented as , where denotes the number of classes. These refined feature maps play a crucial role in achieving accurate segmentation results.
3.2. Forest Fire Transformer Block
The semantic segmentation of RS images requires a network with robust information extraction capabilities. This capability should prioritize the extraction of local information, while also considering the extraction of global information. To address these challenges, we have developed the FFTB. The structure of the FFTB is visually depicted in
Figure 5.
The FFTB global branch is constructed with Transformer Blocks that incorporate the CDA mechanism. This branch is specifically designed to extract global information from the feature maps, while preserving their resolution and channel size. Suppose the given feature map as
, then the output feature map after passing through the global branch can be represented as
. The entire process can be succinctly summarized by the following:
The FFTB local branch consists of two parallel depthwise separable convolutions (DWconv). Suppose the given feature map as
. To ensure the preservation of features across channels, we have maintained the same number of channels in the feature map without any alterations. The outputs of the parallel depthwise separable convolutions applied to the feature map
are denoted as
and
. Subsequently, we fuse
and
along the channel dimension to obtain the final output feature map
of the local branch. Lastly, we merge the feature map
L with the corresponding output
$G
$ from the global branch. Additionally, we employ the
activation function to eliminate information redundancy within the fused feature map. The entire process can be concisely summarized as follows:
3.3. Cross-Scaled Dot-Product Attention Mechanism
After conducting our observations, we have discovered that the feature maps derived from RS images during the process of feature extraction contain a wealth of information. These include intricate texture details that exhibit strong local characteristics, as well as semantic information that showcases robust global characteristics.
In order to fully exploit the detailed texture information in remote sensing images, we have opted for a straightforward non-overlapping window partitioning approach (specifically, we have utilized 2 × 2 windows in our experiments).
The advanced semantic information in remote sensing images is crucial for semantic segmentation. Therefore, we propose the Cross-Scaled Dot-Product Attention Mechanism to globally model the feature maps of remote sensing images, as illustrated in
Figure 6. In order to enable the exchange of information between windows, we employ convolution in both the horizontal and vertical directions. The cross-shaped window interaction module merges features from both the vertical and horizontal directions, thereby achieving global information interaction. Specifically, in the horizontal direction, the information interaction between any point
in window 1 and any point
in window 2 can be effectively modeled using Equation (5).
where
represents the size of the windows. Simultaneously, the relationships between points within individual windows, as exemplified by the red path within window 1, have already been established during the window self-attention process, as Equation (6). Consequently, in the horizontal direction, the interaction of information between windows is facilitated by the convolution operation.
Similarly, in the vertical direction, inter-window information exchange is established through vertical convolution. The relationship between window 1 and window 3 can be described using Equation (5). Information exchange can be achieved by connecting multiple intermediate windows; for instance, points in window 4 can interact with points in window 2, and subsequently, points in window 2 can interact with points in window 1, thereby facilitating information exchange between windows in different directions. Thus, the cross-shaped window interaction method effectively simulates global relationships in window directions, thereby capturing the global information present in the feature map.
3.4. Feature Refinement Net
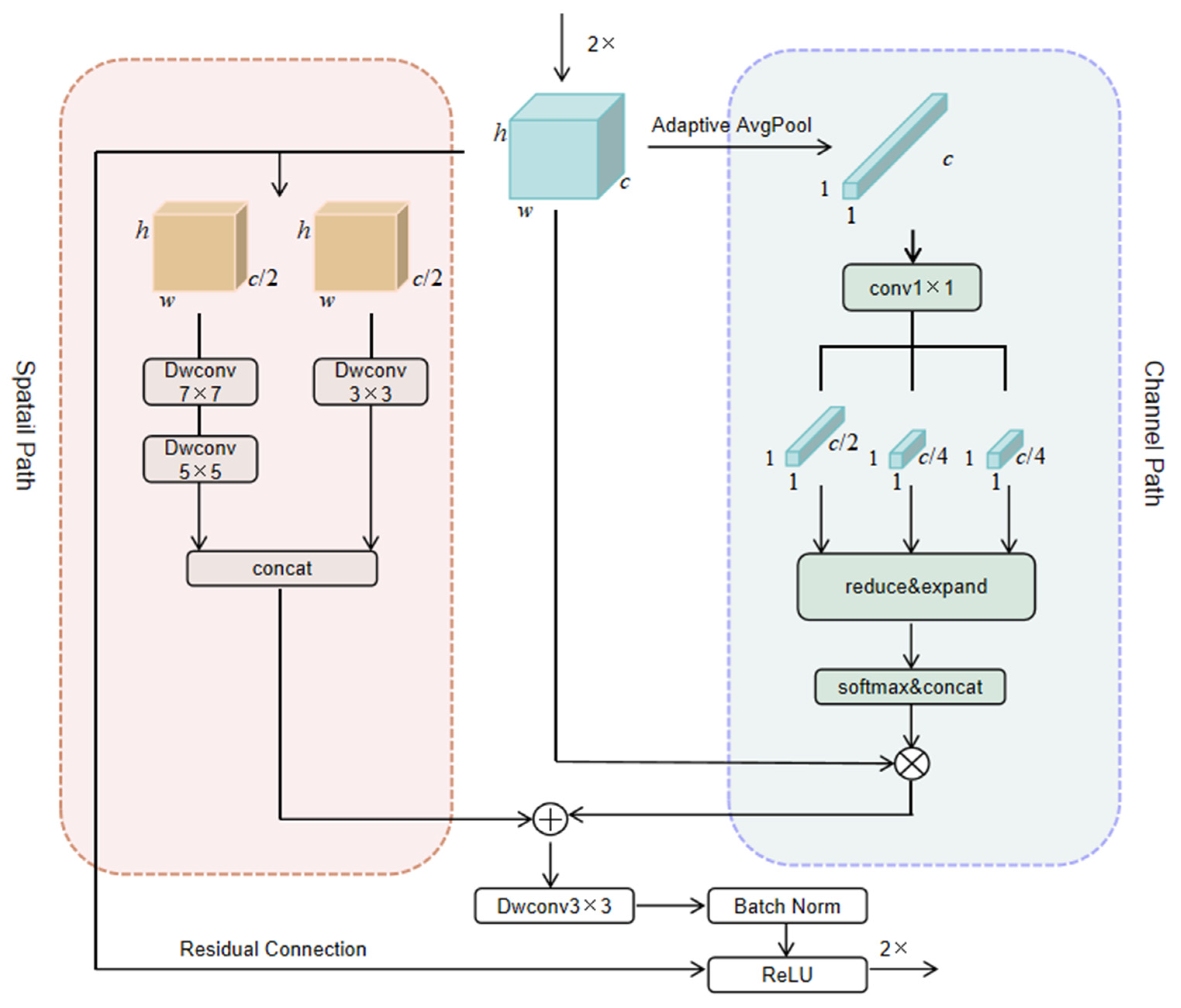
In the context of semantic segmentation tasks involving RS images, feature map fusion plays a pivotal role within the U-Net-like framework. The utilization of skip connections has a limited impact on enhancing the segmentation accuracy of the final fused feature map. Hence, we propose the Feature Refinement Net, which refines the ultimate fused feature map from two distinct perspectives: the Spatial Path and the Channel Path, as depicted in
Figure 7.
We commence by upsampling the fused feature map by a factor of 2, denoting it as . In the Channel Path, we employ Adaptive Avgpool to diminish the spatial dimensions of the feature map to 1 × 1, which we define as . To ensure a precise recovery of the channel information in the FRN, we allocate the channel numbers in a ratio of 2:1:1, represented as , and . Subsequently, within each channel branch, we apply the reduce and expand operation, comprised of four 1×1 convolutional layers. This operation reduces the channel count by half, then by a quarter, before restoring them to their original quantity. Following this, the outcomes from the three channel branches are concatenated along the channel dimension, resulting in the final channel-wise recovered feature map denoted as . Finally, the spatial recovery is achieved through the matrix multiplication between and .
To refine spatial features at different levels in the Spatial Path, we divide the feature map into two parts along the channel dimension, referred to as and . In the first branch, we apply deep separable convolution layers twice consecutively to segment , using convolution kernels of size 7 × 7 and 5 × 5. The use of larger convolution kernels allows for a wider receptive field, thereby enhancing the global semantic information of the feature map. In the second branch, we perform a depth-separable convolution on segment , utilizing a 3 × 3 convolution kernel to increase the spatial texture details of the feature map. Finally, and are merged along the channel dimension and added together to obtain the refined feature map. It is important to note that a residual module has been incorporated to prevent any degradation in network performance.
3.5. Datasets
3.5.1. FLAME Dataset
The FLAME dataset was gathered in northern Arizona, USA, utilizing drones for controlled pile burning. This dataset comprises multiple collections, encompassing aerial videos captured by drone cameras and thermal images recorded by infrared cameras. Within this dataset, there are 2003 photos annotated with fire areas, each with a size of 3840 × 2140. These annotated images serve as valuable resources for conducting fire semantic segmentation research. To facilitate training, we allocated 60% of the images for training purposes, 20% for validation and the remaining 20% for testing. Prior to training, each image is cropped to a size of 1024 × 1024, ensuring consistency across the dataset.
3.5.2. FLAME2 Dataset
To assess the generalization capability of FireFormer and mitigate the impact of similar images during training or segmentation results, we conducted segmentation tests on the FLAME2 dataset [
53]. Additionally, based on the obtained test results, we performed an analysis of carbon emissions during forest fire burning processes. The FLAME2 dataset primarily comprises original and manipulated aerial images captured during a controlled fire in November 2021 in an open canopy pine forest in northern Arizona. It includes 7 sets of original RGB and infrared (IR) videos that have not been annotated. For the experiment, we primarily selected a portion of the third fire’s RGB video for segmentation testing. We extracted frames from the RGB video and subsequently cropped the extracted frame images to a size of 1024 × 1024.
3.6. Implementation Details
3.6.1. Training and Testing Settings
In the experiment, all models were implemented using the PyTorch framework on an NVIDIA GTX 3060 GPU. To achieve fast convergence, we used the AdamW optimizer to train all models. The base learning rate was set to 6 × 10−4. The learning rate was adjusted using the cosine annealing strategy. The maximum number of epochs during training was set to 40, and the batch size was set to 4. During the training process, we randomly cropped the FLAME dataset to a size of 1024 × 1024.
3.6.2. Evaluation Metrics
In our experiment, we employed two main categories of evaluation metrics. The first category focuses on assessing the accuracy of the network and includes the following metrics: overall accuracy (OA), average F1 score (F1) and mean intersection over union (mIoU).
The second category evaluates the efficiency of the network and includes the following metrics: floating-point operations (Flops), frames per second (FPS), memory usage in megabytes (MB) and the number of model parameters (M). By considering both accuracy and efficiency metrics, we can comprehensively evaluate the performance of the network in terms of its accuracy, computational complexity, speed and memory usage.
3.6.3. Loss Functions
In order to expedite the convergence of the network during the training process, we employ a unified loss function that amalgamates the Dice loss
and cross-entropy loss
to oversee the model’s progress. The calculation of this joint loss function is as follows:
The Dice loss function has a robustness to class imbalance and higher sensitivity to the pixel overlap of small targets. Therefore, the Dice loss function performs better in segmenting small targets. The cross-entropy loss function penalizes misclassifications more heavily during training, promoting the model to learn more classification boundaries. To improve the accuracy of the segmentation results, we used a combination of these two loss functions.
3.7. Hardware
The FLAME dataset used in this study was collected using various drones and cameras.
Table 1 describes the technical specification of the utilized drones and cameras and the specific information obtained from the FLAME dataset.
5. Discussion
In this work, we used low-altitude remote sensing images of early forest fires based on unmanned aerial vehicles as data to develop a novel CNN–Transformer hybrid forest fire identification algorithm.
Firstly, the impetus for this work originated from our observation that within the field of remote sensing, there is a limited but significant amount of research on monitoring fires using UAV remote sensing imagery [
59,
60]. These efforts have advanced fire detection methodologies within the domain of remote sensing. LUFFD-YOLO [
61] introduced an algorithm for wildfire detection that is based on attention mechanisms and the fusion of multi-scale features, enabling the automated identification of fire regions in remote sensing images. The authors of [
56], building upon the Deeplabv3+ framework, have achieved the detection of fires in UAV imagery. However, we have noted that the aforementioned methods are predominantly founded on visual models for object recognition, which are only capable of outlining the fire areas within the remote sensing images. This can lead to the inclusion of pixels that do not actually belong to the fire region. Therefore, the FireFormer we propose is constructed on a semantic segmentation visual model, facilitating pixel-level detection.
Secondly, the reason for proposing FireFormer is that most current fire detection algorithms still utilize satellite imagery as data [
62,
63]. Rida Kanwal and colleagues [
64] employed a CNN neural network to achieve fire segmentation based on satellite remote sensing images. Mukul Badhan and colleagues [
65] used VIIRS satellite remote sensing images to implement more accurate large-scale fire identification. We believe that satellite images have a relatively low spatial resolution and long revisit cycles, making it difficult to clearly and promptly reflect fire conditions on the ground. For the early small flames of forest fires, relying solely on satellite images is even more challenging. Unmanned aerial vehicles, as low-altitude remote sensing image acquisition devices, can more quickly and rapidly obtain real-time fire conditions.
To address the shortcomings we identified in the existing work during our research process, we proposed FireFormer. Considering the high resolution of remote sensing images, we introduced a lightweight Transformer framework, the Forest Fire Transformer Block. The experimental results have demonstrated that this module enhances the network’s ability for real-time fire monitoring. We believe that FireFormer can be deployed on unmanned aerial vehicle systems, enabling ground detection personnel to respond to forest fires more conveniently and accurately.
However, our work still has two areas of insufficiency. First, the algorithm we proposed is a supervised algorithm, which requires a significant amount of human labor to annotate remote sensing images in order to successfully complete the model training. Second, we believe that there is still room for improvement in the feature extraction module of FireFormer, and more advanced feature extraction methods can achieve more accurate recognition accuracy. In the future, we are considering using self-supervised learning methods for model training to alleviate the predicament that fire recognition algorithms require a large amount of annotated data for training. In addition, we will continue to develop new feature extraction modules to achieve more accurate fire detection.
6. Conclusions
This work aims to extract valuable information from early wildfire images obtained from low-altitude unmanned aerial vehicles (UAVs), to achieve higher flame segmentation accuracy with a smaller computational cost. Based on our findings, traditional CNN segmentation methods and Transformer-based segmentation methods struggle to strike a good balance between real-time performance and accuracy when faced with wildfire images captured by UAVs. To address this problem, we designed a novel real-time semantic segmentation network with a hybrid structure that incorporates our innovative Forest Fire Transformer Block (FFTB) and Feature Refinement Net (FRN). Specifically, in the Lo-Fi branch of FFTB, we designed a bi-paths attention (BPA) mechanism that allows the network to perform the global modeling of feature maps with a lower computational cost, effectively reducing the computational load and improving real-time performance. Additionally, in segmentation tasks, feature maps undergo multiple downsampling and upsampling, resulting in the loss of edge details. Therefore, we designed the FRN, which was validated through experiments and result visualization. Finally, we proposed an approximate calculation method for estimating carbon emissions from early forest fires from the perspective of low-altitude UAVs based on the segmentation results of FireFormer. In future work, we will continue to research better image feature encoders to replace the concise encoding in FireFormer, to achieve higher segmentation accuracy.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

