Abstract
To address the performance degradation of cross-domain object detection under various illumination conditions and adverse weather scenarios, this paper introduces a novel method a called Step-wise Domain Adaptation DEtection TRansformer (SDA-DETR). Our approach decomposes the adaptation process into three sequential steps, progressively transferring knowledge from a labeled dataset to an unlabeled one using the DETR (DEtection TRansformer) architecture. Each step precisely reduces domain discrepancy, thereby facilitating effective transfer learning. In the initial step, a target-like domain is constructed as an auxiliary to the source domain to reduce the domain gap at the image level. Then, we adaptively align the source domain and target domain features at both global and local levels. To further mitigate model bias towards the source domain, we develop a token-masked autoencoder (t-MAE) to enhance target domain features at the semantic level. Comprehensive experiments demonstrate that the SDA-DETR outperforms several popular cross-domain object detection methods on three challenging public driving datasets.
1. Introduction
Effectively detecting objects in various traffic conditions would significantly advance the development of driving safety applications for autonomous vehicles. Nonetheless, challenges such as adverse weather conditions and object occlusion can hinder the performance of camera-based object detection methods. Object detection is an important task in autonomous driving systems, and deep learning is widely applied in it [1]. Supervised algorithms are mainstream in current deep learning-based object detection, and these rely on large-scale labeled datasets i.e., PASCAL VOC [2] and MS COCO [3]. In addition, existing algorithms are based on the assumption that the distributions of the training and testing datasets are consistent. The reality is quite different. At the same time, for certain conditions, labeled datasets are particularly scarce, such as nighttime and adverse weather conditions. If use a model trained on clear weather conditions during the daytime and test it under these conditions, the test results may suffer from significant degradation. Other solutions can be broadly categorized into two main directions. One research direction enhances images and then detects objects, i.e., [4,5]. Another direction improves the robustness of algorithms, which either expand the dataset scales as much as possible for model training, i.e., [6,7] or depend on crafted features tailored to specific tasks, i.e., [8,9]. However, these methods are highly reliant on manual annotations. Manually annotating large-scale labeled datasets for every condition is not only expensive but also time-consuming. Therefore, methods that do not rely on labeled data have distinct advantages. Unsupervised domain adaptation (UDA) emerges as an effective solution to this challenge.
The goal of unsupervised domain adaptation is to align the data distribution from a label-rich source domain to that of a label-free target domain in an unsupervised manner, thereby enabling the model to achieve improved performance in the target domain without the need for manual labeling. In recent years, advancements in deep learning have significantly developed the progress of the unsupervised techniques used for domain adaptation [10,11]. Researchers have successfully applied these methods to image classification tasks [12]. However, there has been limited attention given to the more challenging task of object detection. In particular, how to transfer knowledge from a labeled dataset to an unlabeled one using the simple DETR architecture has been largely overlooked. Consequently, addressing the distribution divergence between the source and target domains and applying this to object detection is a challenging yet intriguing research topic in computer vision. The key point of domain adaptation lies in reducing domain discrepancy. A domain discrepancy can be categorized as low-level (pixel level) or high-level (feature level). For example, daytime and nighttime images have different pixel appearances in terms of brightness, color, and noise level at the low level. From the high-level perspective, the two domains have different object semantics. However, low-light image enhancement (LLIE) methods [13,14] only improve visual quality for humans. They cannot completely transform nighttime images into daytime ones. The distribution of their enhanced images still differs from that of labeled daytime images. Therefore, enhancing the images and then performing object detection is sub-optimal. To solve the problem, a novel domain adaptation method, dubbed SDA-DETR, is introduced.
In summary, it is highly meaningful to improve object detection under poor visibility conditions without labor-intensive and time-consuming manual annotation. To achieve this goal, this study is based on the concept of unsupervised domain adaptation, addressing the challenges in the field of cross-domain object detection in a step-by-step and hierarchical manner.
Specifically, the SDA-DETR can be divided into three steps which gradually reduce domain discrepancy. In the initial step, target-like samples are generated using an unpaired image-to-image translator, and these have a similar style to target domains. While this approach effectively mitigates domain shift at the image level, its capacity to reduce domain divergence at the feature level remains limited. To further mitigate domain shift at a higher level, two additional stages will be implemented. In the second step, at the global-level, an adaptive domain query feature alignment (DQFA) and an adaptive token-wise feature alignment (TFA) at the local level focus on domain-invariant feature learning. Lastly, we propose t-MAE to eliminate model bias toward the source domain, which improves the semantic-level representation of the target domain across the whole pipeline.
In this study, the driving datasets used include SODA10M [15], SHIFT [16], Cityscapes [17], Foggy Cityscapes [18]. The main contributions of this study can be summarized into three aspects:
- (1)
- The SDA-DETR, a step-wise domain adaptation pipeline, is proposed. The elegance of the step-wise approach lies in its gradual reduction of discrepancies between the source domain and target domain at different levels, providing a simple and effective solution to the cross-domain object detection (CDOD) problem.
- (2)
- Our method addresses challenges in manually annotating low-light and adverse weather images, reducing reliance on label-rich training data. This contributes to improving the development efficiency of the self-driving field.
- (3)
- Empirically, we demonstrate the effectiveness of the SDA-DETR on three challenging public datasets; the SDA-DETR outperforms several popular methods, showing its applicability in various illumination conditions, as well as in adverse weather scenarios.
2. Related Work
2.1. Object Detection
The goal of object detection is to identify and categorize objects within images or videos. It is useful for many fields, including security systems, face recognition, autonomous driving, and medical imaging. CNN-based and transformer-based detectors are the two main groups of deep learning object detectors. One-stage detectors [19,20,21,22] and two-stage detectors [23] are the two main streams of CNN-based methods, and their difference lies in whether they generate or refine object proposals. Strictly speaking, none of them are end-to-end detectors, since they all have hand-crafted components, such as anchor designs and non-maximum suppression (NMS) post-processing. With the introduction of the DETR [24], a simple yet effective end-to-end pipeline, transformer-based [25,26,27] detectors have garnered widespread attention. In this study, we utilize the deformable DETR [25] as the baseline due to its multi-scale feature and adaptable transfer-learning capabilities.
2.2. Cross-Domain Object Detection
Classical deep learning object detection methods often rely on two assumptions: that there are identical distributions across the training and test data and that the data are labeled. The reality is that it is costly and time-consuming to generate a substantial number of labeled datasets, and annotations for special conditions are more challenging. To overcome these problems, cross-domain object detection (CDOD) algorithms have drawn significant attention [28]. These algorithms fall into five main categories: (1) domain-invariant feature learning, (2) mean-teacher training, (3) pseudo-label-based self-training, (4) image-to-image translation, and (5) graph reasoning [29]. This discussion primarily focuses on domain-invariant feature learning and image-to-image translations, as they are relevant to our work.
Domain-invariant feature learning: A domain discriminator helps to train an object detector model adversarially to learn the invariant features of both domains. Our training adopts the feature learning method proposed by [30], which uses a gradient reversal layer. The domain-adaptive Faster RCNN [11] marked the initial attempt to transfer knowledge across domains. Motivated by this concept, [28,31,32,33,34,35,36,37] have leveraged feature alignment technology to propose various methods for enhancing the transferability of detectors. Image-to-image translation is a technique that can transform an image from one domain to another domain and reduces the distribution shift in its visual quality. Ref. [28] constructed a fake target domain by employing an image-to-image translation model to convert the style of the source domain to one that is close to that of the target domain. Ref. [31] reduced the domain gap by constructing an auxiliary domain, leveraging CycleGAN [38] to synthesize target-like images to reduce domain discrepancy. Study [39] employed two distinct image translation methods, CycleGAN [38] and AST-AdaIN [40], to complement each other by capturing both high-level and low-level features, thereby obtaining a more realistic synthetic training set, with the aim of reducing domain discrepancy.
These methods are not impressive when used alone, but they often achieve a better performance when used together. In this paper, we combine image-to-image translation and domain-invariant feature learning to solve the CDOD problem.
2.3. Masked Autoencoder
A masked autoencoder (MAE) [41] is a type of self-supervised learning method for computer vision that is based on the idea of inferring the random masked patches of the input from the visible part of the input. The MAE initially achieved a remarkable performance in NLP [42] and was subsequently introduced into vision models [43,44]. Ref. [45] used MAE for video pre-training and found that VideoMAE was a learner that could use less data and learn better features for self-supervised video pre-training. Ref. [46] employed an attention mask matrix to regulate the interactions among distinct object queries, ensuring the independence of query patches. Inspired by this work on MAEs, we develop the t-MAE approach, which aids the model in learning more representative features to eliminate model bias. This methodology is designed to enhance the model’s generalization capabilities by focusing on the extraction of salient features that are indicative of the underlying data distribution, thereby reducing the reliance on potentially biased or non-generalizable features.
3. Method
3.1. Preliminary
The task is to adapt an object detector trained on label-rich source domain data to label-free target domain data. We define the source domain as and the target domain as , where denotes the i-th image and represents the corresponding ground truth information of the source domain. Both and share the same category space. We assume that the data distribution of the auxiliary domain generated from is close to that of and that and share the same annotations. Our method aims to create a model capable of alleviating domain discrepancy when the source domain used for training has abundant labels with bounding box annotations while the target domain lacks labels and exhibits significantly different or even completely distinct data distributions.
3.2. Step-Wise Domain Adaptation DETR
An overview of the framework of the SDA-DETR is shown in Figure 1. The framework is divided into three parts, and each part is surrounded by a dashed box in a different color. Figure 2 summarizes the main functions of each component. Our initial step in domain adaptation is marked by the gray dashed box, where a Two-Stream Image-to-image Translation (TSIT) [47] is employed to train an unpaired image-to-image translator GN and to generate target-like images. The generated target-like samples, combined with source domain annotations, form a labeled auxiliary domain, and the auxiliary domain can bridge the domain gap at the image level. Its structure is shown in the gray dashed box in Figure 1. In the second step, domain features are aligned at the global level and local level, respectively. In detail, the labeled source domain and auxiliary domain simultaneously enter the detection pipeline with the target domain. The labeled data are trained in a supervised way. Additionally, features generated from labeled and unlabeled data (i.e., , , ) are aligned at different levels. Specifically, , , and are each passed through a Gradient Reversal Layer (GRL) [48] and then their domain-invariant features are learned using a domain discriminator in an adversarial learning framework. The detailed structure is shown in the purple dashed box in Figure 1. Lastly, due to the labeled data being trained in a supervised way, the model training process tends to favor the labeled source domain. To further eliminate the model’s bias towards the source domain, a t-MAE is developed to reconstruct the target domain’s masked tokens for eliminating model bias. This structure is depicted by the blue dashed box in Figure 1. Specific details will be discussed in the following three subsections.
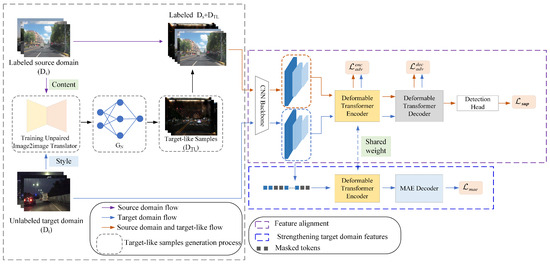
Figure 1.
An overview of the SDA-DETR.

Figure 2.
The proposed method includes three stages. In stage 1, target-like images are translated to construct an auxiliary domain for reducing the domain shift at the image level. In stage 2, the feature alignment method reduces the domain gap at the global level and local level. In stage 3, target domain features are strengthened to further eliminate model bias.
3.2.1. Image-Level Adaptation
Generally speaking, the source domain and target domain contain obvious differences in visual perception, such as the significant contrast in brightness between daytime and nighttime. The purpose of target-like sample generation is to reduce the discrepancy between them at the image level. The target-like samples share the same style as the target domain, while consistent content is contained in the source domain. Previous works [28,31,39] utilized CycleGAN [38] to generate target-like samples, which performed well in high-level feature translations but were limited in low-level feature translations [39,47]. In contrast, TSIT [47] successfully strikes the right balance between content and style, serving as a versatile tool for unsupervised image translation. Therefore, we adopt a TSIT to generate target-like samples. As shown in Figure 3, the style stream, content stream, generator, and discriminators are the four components of the TSIT.
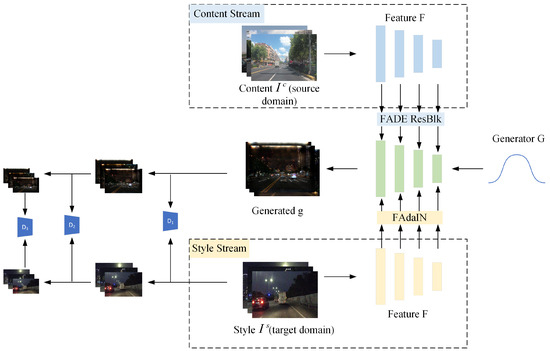
Figure 3.
The pipeline of the TSIT framework. , , and denote three discriminators. The generator receives a Gaussian noise map G as its input. The feature-adaptive instance normalization (FAdaIN) module involves applying style information via feature-adaptive instance normalization. The feature-adaptive denormalization (FADE) module applies denormalization to each element by adjusting the normalized activation with an affine transformation that is learned.
The generator loss is as follows:
The discriminator loss is as follows:
where and are from the TSIT [47] and g represents the generated image, while and refer to the style and content of the image, respectively. represents the perceptual loss [49]. Additionally, stands for the feature-matching loss [50]. and control the relative importance of and .
3.2.2. Domain-Invariant Feature Learning
As demonstrated in SFA [33], it is uncertain whether domain-invariant features on the backbone can be preserved during the transformation process. These sequence features are crucial for the ultimate prediction process. In this paper, the comprehensive feature alignment strategies used include DQFA for the global-level adaptation and TFA for the local-level adaptation.
Global-level adaptation. DQFA aligns the scene layouts in images and investigates object relationships for adaptation. For the encoder, the input consists of a token sequence extracted by the backbone and a domain query embedding , i.e., . In the encoding phase, the initial input to the encoder layer is formed by the , with positional embedding and feature-level embedding. Subsequently, the output from the encoder layer is directed to the GRL [48] and then a domain discriminator for feature alignment. Figure 4 shows the details of this structure. The encoder is composed of 6 layers. The loss can be written as
where represents the domain label, 0 corresponds to source domain, and 1 to the target domain. controls whether alignment occurs in this encoder layer. denotes the domain discriminator, consisting of a three-layer MLP. represents the domain query for the i-th encoder layer. is the aligned encoder layer number.
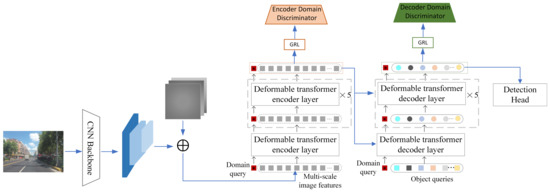
Figure 4.
The detailed structure of the DQFA and TFA in the framework. * indicates a domain query.
In the decoding phase, the object queries consist of a decoder domain query and object queries, i.e., , and the loss is computed in the same manner as .
where denotes the domain query for the i-th decoder layer and is the aligned decoder layer number.
Local-level adaptation. DQFA is successful in reducing domain gaps in inter-object relationships and scene layouts, but its performance is not satisfactory on local-level features, i.e., style and texture. To reduce the domain shift at the local level, a simple yet effective TFA is added to align the multi-scale feature tokens. Figure 4 shows the details of this structure.
Specifically, the multi-scale features output from the CNN backbone, flattened and referred to as a token sequence, serve as the input to the encoder. Each token sequence is inputted into a domain discriminator with a GRL at each encoder layer to obtain domain-invariant features.
Similarly, for the decoder, the query embedding serves as the alignment target.
where and are the aligned encoder and decoder layer numbers, respectively. N is the token number, while M is the query number. and denote the domain discriminator, which consists of a three-layer MLP. denotes the i-th layer k-th token element and represents the i-th layer k-th query element.
DQFA and TFA both use adversarial learning to align, and their losses can be combined.
where and control the relative importance of the encoder and decoder’s alignment.
3.2.3. Token-Masked Autoencoder
The fact is that the target domain lacks annotations, and only the source domain can be trained in a supervised way, while the target domain requires an unsupervised training pipeline. In the absence of appropriate bias mitigation strategies, the model exhibits a bias toward the source domain. To eliminate the model’s bias, we enhance the semantic-level features of the target domain, encouraging the model to learn more representative features from the target domain. Inspired by the simple yet effective MAE [41], we designed a token sequence-based MAE. It involves two steps: feature masking and feature reconstruction.
Token masking. The multi-scale feature maps output by the backbone are denoted as , where L represents the number of scales. The objective of feature masking is to randomly generate masking for each scale’s feature map, denoted as . The generated multi-scale masking feature maps are represented by and flattened as the input to the encoder.
Token reconstruction. After extracting features from images using ResNet50, these multi-scale features contain comprehensive low-level and high-level information. To reduce computational complexity, we choose to reconstruct only the features from the last layer. The encoder shares the same structure and weights as the detector encoder during training. We employ an asymmetric lightweight decoder comprising only two custom decoder layers. The reconstruction loss is computed using the Mean Square Error (MSE).
where is the reconstruction feature. is the last layer’s feature.
3.2.4. Full Objective
The source domain has annotations, and the supervised loss from the deformable DETR [25] can be written as
Our overall objective loss is
where controls the relative importance of .
4. Experiments and Results
4.1. Datasets
In our experiments, we evaluate our method using the following scenarios:
(1) SODA10M (daytime to nighttime): SODA10M [15] comprises images taken in various situations (such as urban or rural settings) and conditions (such as nighttime and rainy or snowy weather) across 32 different cities. There are 10 M unlabeled images, 5 k training images (labeled), 5 k validation images (labeled), and 10 k testing images. In the experiment, 5 k clear daytime images from the training set are used as the source domain, 2975 clear nighttime images from the test set are used as the target domain (without public bbox annotation), and 1656 nighttime images from the validation set are used as the target domain test set.
(2) SHIFT (daytime to nighttime): SHIFT [16] is a large-scale simulated dataset tailored to autonomous driving in various environments. It includes 6 categories, i.e., pedestrian, bicycle, motorcycle, bus, car, and truck. In our experiments, the source domain contains 20,800 daytime images, and there are 9350 nighttime images in the target domain and 1200 nighttime images in the test set.
(3) Cityscapes (normal weather to foggy weather): Cityscapes [17] consists of 2975 images from urban scenes for training. It is the source domain in our experiment. Foggy Cityscapes [18], created through a fog synthesis algorithm applied to Cityscapes, is chosen as the target domain. The trained model is tested on a validation set of Foggy Cityscapes. We use the part of , where denotes the fog’s density.
4.2. Implementation Details
In our experiment, the auxiliary domain was built by a translator TSIT [47] from the source domain to target domain images, and the parameters follow the default configuration of the TSIT, i.e., and for daytime to nighttime generation and and for normal to foggy weather generation. The information on the adaptation scenarios is shown in Table 1. The deformable DETR [25] is the baseline detector and ResNet-50 [51] is the backbone, which was pre-trained on ImageNet [52]. Following the default settings in [25], an Adam optimizer was used to optimize the parameters of the model. The base learning rate and weight decay were set to , , respectively. The linear projections, which were used to estimate the reference points and offsets for object queries, have learning rates of . The query numbers were 100 and 50 epochs in our experiment. For the other hyperparameters, detailed information is shown in Table 1. The performance of the model is measured by the Mean Average Precision (mAP) metric, with a threshold of 0.5. NVIDIA 3090 GPUs are used in our experiments.

Table 1.
Hyperparameters for different scenarios. SODA10M (D→N) denotes SODA10M (daytime to nighttime). SHIFT (D→N) denotes SHIFT (daytime to nighttime). Cityscapes (N→F) denotes Cityscapes (normal weather to foggy weather). For detailed information on , , and , please refer to Section 3.2.
4.3. Results
In this section, we assess the performance of our proposed SDA-DETR across various domain shift scenarios, including real-world and simulated environments, daytime-to-nighttime adaptations, and normal weather to foggy weather adaptations. To validate the effectiveness of our SDA-DETR, we compare it against several state-of-the-art (SOTA) methods.
4.3.1. Real-World Daytime to Nighttime Adaptation
In the real-world daytime to nighttime adaptation task, SODA10M daytime is the source domain and nighttime is the target domain. They have the same category of objects, but different data distributions. Figure 5 shows image and histogram distribution examples of the source domain, the auxiliary domain, and the target domain. We can observe that the histogram distributions of the auxiliary domain (Figure 5b) and the target domain (Figure 5c) are similar, while they are significantly different from source domain (Figure 5a), indicating that the auxiliary domain indeed reduces domain shift at the image level.
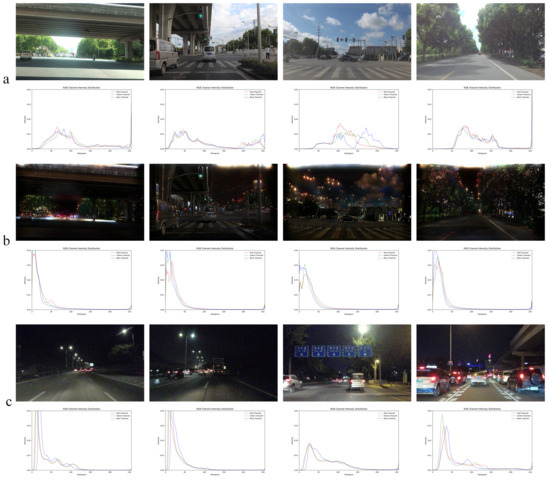
Figure 5.
(a–c) represent images and their histogram distributions across different domains. Specifically, (a) corresponds to the source domain, (b) to the auxiliary domain, and (c) to the target domain in a real-world adaptation task from daytime to nighttime.
The evaluated results of the task are shown in Table 2. The quantitative results indicate that our approach improves the mAP by compared to the source-only model and achieves a minimum mAP improvement of compared to five other SOTA methods, which show the effectiveness of our method. The detection results are shown in Figure 6. This is a real-world scenario, and domain adaptation from daytime to nighttime poses several challenges, including glare, small-scale objects, and difficulty in distinguishing black objects at night. From left to right in Figure 6, we contrast the results of the source alone (deformable DETR), SDA-DETR, and the ground truth. For example, in rows 2 and 3, the results demonstrate that our proposed method achieves a superior detection performance on small-scale nighttime objects and objects affected by glare.
Table 2.
Evaluated results of SODA10M (daytime to nighttime). Faster RCNN and deformable DETR are, respectively, abbreviated as D-DETR and FRCNN.

Figure 6.
Examples of the detection results for an adaptation task of the SODA10M from daytime to nighttime. (a,b) display the detection visualization of a source-only model and our method, respectively. (c) represents the ground truth annotations.
4.3.2. Simulated-Environment Daytime to Nighttime Adaptation
For the simulated-environment daytime to nighttime adaptation task, SHIFT daytime was the source domain and nighttime was the target domain. Figure 7 shows the image and histogram distribution examples of the source domain, the auxiliary domain, and the target domain. We can observe that the histogram distribution of the source domain (Figure 7a) spans an x-axis range of 100–250. In contrast, both the auxiliary domain (Figure 7b) and the target domain (Figure 7c) exhibit consistent histogram distributions, primarily concentrated within the range of 0–100. This observation indicates that our method can reduce domain gaps at the image level effectively.

Figure 7.
(a–c) represent images and their histogram distributions across different domains in simulated-environment daytime to nighttime adaptation tasks.
The evaluated results of the task are shown in Table 3. Comparing our algorithm with nine SOTA methods, our method achieves the highest mAP, surpassing the baseline by . Furthermore, when compared to classic domain adaptation algorithms based on deformable DETR, specifically SFA, O2net, and AQT, our method exhibits improvements of , , and , respectively. These results clearly demonstrate the significant effectiveness of our algorithm in reducing domain gaps. We report these detection results in Figure 8. Compared to the real-world SODA10M scenes, the SHIFT nighttime dataset exhibits, overall, softer lighting and fewer glare phenomena. However, the nighttime brightness is relatively low, which increases the difficulty of detection. From left to right in Figure 8, we compare the visualization results of the source alone (deformable DETR), SDA-DETR, and the ground truth. Our proposed algorithm effectively detects objects in extremely dark environments, achieving results comparable to the ground truth.
Table 3.
Evaluated results of SHIFT (daytime to nighttime).

Figure 8.
Examples of the detection results for the SHIFT daytime to nighttime adaptation task.
4.3.3. Normal to Foggy Weather Adaptation
The shift from normal weather to foggy conditions is a frequent occurrence in real-world driving scenarios. Consequently, it is crucial for object detectors to exhibit adaptability to these weather variations. For this purpose, the labeled Cityscapes dataset is employed as the source domain, while the unlabeled Foggy Cityscapes dataset serves as the target domain for the evaluation of our method. The image and histogram distribution examples of the source domain, the auxiliary domain, and the target domain are shown in Figure 9. It is evident that the histogram distributions in Figure 9b,c are consistent.
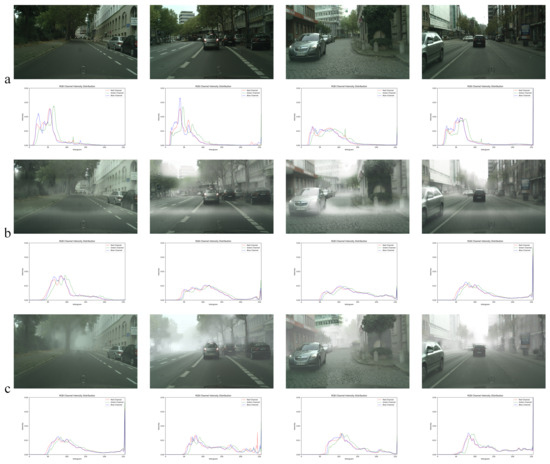
Figure 9.
(a–c) represent images and their histogram distributions across different domains in normal to foggy weather adaptation tasks.
Table 4 shows the evaluated results of the Cityscapes normal to foggy weather adaptation task, achieving a SOTA performance of on the foggy dataset. We report the visualization results in Figure 10. The visualization examples show that our algorithm can effectively detect samples that the source-only model missed and false positives. These results indicate that our method also performs well on this task, demonstrating the generalizability of our approach.
Table 4.
Evaluated results of Cityscapes (normal weather to foggy weather).

Figure 10.
Examples of the detection results for the Cityscapes normal weather to foggy weather adaptation task.
Summarizing the results of each adaptation task, the SDA-DETR consistently outperforms previous SOTA methods in these scenarios, demonstrating its effectiveness in addressing domain shift challenges across diverse weather conditions and around-the-clock illumination levels.
4.4. Ablation Study and Analysis
Quantitative ablation study. We conducted a detailed analysis by removing each component to understand its individual impact. This ablation study was performed on SODA10M (daytime to nighttime).
Table 5 shows the effect of each module, from which we can observe that (1) the target-like pipeline generates an auxiliary domain that has a close data distribution with the target domain, improving the mAP by a large margin (line 3) compared with the source-only model (line 2) and confirming its efficiency in reducing domain discrepancy. (2) Domain-invariant feature learning aligns domain features at the local and global levels through adversarial learning, leading to a significant improvement (line 4). (3) The feature-masked autoencoder further improves these results (line 5), illustrating its effectiveness.
Table 5.
Ablation studies of each module on SODA10M (daytime to nighttime). “” represents the auxiliary domain. “DIFs” is the abbreviation for domain-invariant features. “t-MAE” is the abbreviation for the token mask autoencoder.
Figure 11 shows the ablation studies’ visualization results. It can be observed that the left-hand-side source-only model exhibits a significant issue in terms of missed object detection. When the domain discrepancy is reduced step-by-step, the results become increasingly closer to the ground truth labels.

Figure 11.
Qualitative ablation study results. (a) is the source-only model results. (b) is the visualization of the SDA-DETR, removing the DIFs and t-MAE. (c) is the visualization of the SDA-DETR, removing t-MAE. (d) is the visualization of the SDA-DETR. (e) shows the ground truth labels.
Feature distribution analysis. In this experiment, we compared the sequence features extracted from the source-only model and SDA-DETR. Figure 12 shows the SODA daytime to nighttime and Cityscapes normal weather to foggy weather feature distributions, respectively. The left column is the source-only model, while right one is the SDA-DETR. We can observe that the red points and blue points have a distinct domain discrepancy in the left column compared to the right one. This demonstrates that the SDA-DETR can effectively reduce the domain gap.
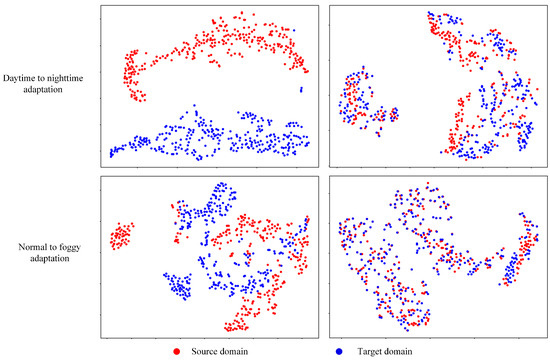
Figure 12.
Feature distribution visualization by t-SNE [77].
Convergence situation analysis. To investigate the convergence of the algorithm, in this section, we used the SODA10M (from daytime to nighttime) as an example. We conducted a convergence visual analysis on training process metrics such as train loss, class error, regression loss, and the corresponding mAP on the validation set. The results, as illustrated in Figure 13, demonstrate the satisfactory convergence performance of the SDA-DETR.
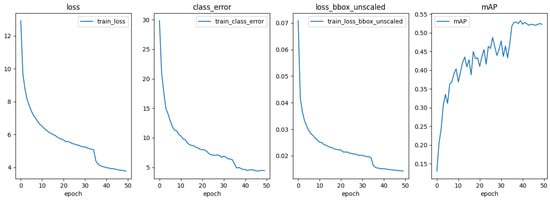
Figure 13.
Convergence of SDA-DETR on SODA10M (daytime to nighttime).
5. Discussion
Parameter sensitivity analysis. In this section, we analyzed the impact of the hyperparameters in our experiments, focusing on three key parameters: the mask ratio, the , , and the aligned layers of the encoder and decoder. The mask ratio is a crucial parameter in the t-MAE module, determining the proportion of tokens to be masked. The and values control the relative importance of encoder and decoder alignment in the overall training process. The aligned layers specify which layers should be aligned to effectively enhance feature alignment. The following conclusions are drawn from the experimental results:
- Figure 14 shows that the highest mAP is reached at a mask ratio of 0.8.
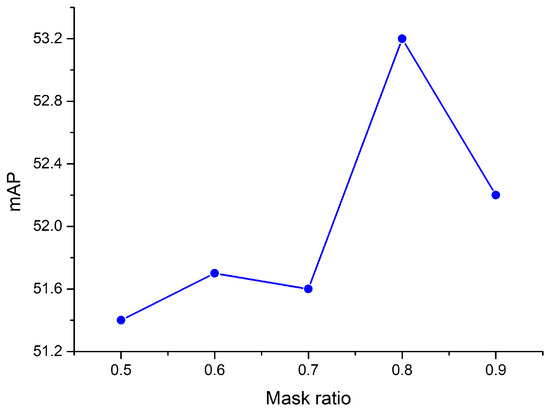 Figure 14. Mask ratio and mAP.
Figure 14. Mask ratio and mAP. - Table 6 demonstrates that the highest mAP is achieved when and .
Table 6. Different values of and correspond to varying mAPs.
- It can be observed from Figure 15 that adaptively aligning the first and sixth layers of the encoder and decoder yields the highest mAP. Aligning multiple layers may lead to over alignment.
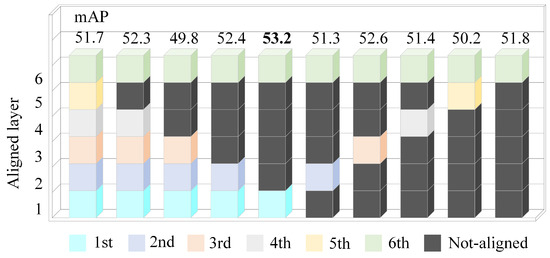 Figure 15. The relationship between the aligned layers and mAP.
Figure 15. The relationship between the aligned layers and mAP.
(1) The mask ratio analysis. Following the self-supervised learning method outlined in [41], we conducted comparative experiments with mask ratios of 0.5, 0.6, 0.7, 0.8, and 0.9. The optimal experimental results were achieved with a mask ratio of 0.8, as illustrated in Figure 14.
(2) The and analysis. Taking Cityscapes (from normal weather to foggy weather) as an example, and based on prior knowledge from the SFA [33] experiments, we initially set and at 1.0. These parameters were then gradually adjusted, either decreased by a factor of ten or increased by a factor of two, to determine their optimal values, as shown in Table 6. The results demonstrate that the highest mAP is achieved when and .
(3) Analysis of the aligned layers in the encoder and decoder. In the SDA-DETR, there are six encoder and decoder layers. The aligned layers determine which specific encoder and decoder layers can effectively align features. These aligned layers are marked with colored squares in their corresponding layer numbers, with the floating-point numbers above indicating the mAP for each alignment, as shown in Figure 15. Just aligning the first and sixth layers of the encoder and decoder results in the highest mAP = 53.2.
6. Conclusions
This research introduces a step-wise domain adaptation method for cross-domain object detection under various illumination conditions and adverse weather scenarios. Our method decomposes the adaptation process into three sequential steps to progressively adapt to tasks with minimal domain discrepancy. First, the source domain is converted to a target-like domain to reduce the domain gap at the pixel level, resulting in a increase in the mAP on SODA10M. Then, domain-invariant feature learning aligns features from both the source and target domains at local and global levels using adversarial learning, achieving a increase in the mAP. Finally, to eliminate model bias towards the source domain, we enhance the semantic-level features of the target domain at the feature representation level. This process guides the model to acquire more knowledge from the target domain, leading to an increase in the mAP. Each step effectively reduces domain discrepancy, thereby improving overall object detection performance.
Although our algorithm has surpassed several SOTA benchmarks, there is still significant work to be done in the future. For instance, (1) our method has only been tested on a limited number of datasets, and its effectiveness under conditions such as sandstorms, rainy days, and snowy days remains to be evaluated; (2) it is worth investigating whether our approach can handle larger domain shifts, such as those between ground objects and satellite remote sensing images; (3) our proposed domain adaptation method is based on a transformer detector, and exploring its applicability to models based on CNN detectors is also an important area for future research. These tasks represent meaningful and valuable directions for further exploration.
Author Contributions
Conceptualization, G.Z., L.W. and Z.C.; methodology, G.Z. and L.W.; software, G.Z.; validation, L.W. and Z.C.; formal analysis, G.Z. and L.W.; investigation, G.Z. and L.W.; resources, G.Z.; data curation, G.Z. and L.W.; writing—original draft preparation, G.Z.; writing—review and editing, G.Z. and L.W.; visualization, G.Z.; supervision, L.W. and Z.C.; project administration, Z.C.; funding acquisition, L.W. and Z.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Science and Technology Planning Project of Guangdong Science and Technology Department under Grant Guangdong Key Laboratory of Advanced IntelliSense Technology (2019B121203006).
Data Availability Statement
The data utilized in this research are accessible to the public via the official website.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Cui, X.; Ma, L.; Ma, T.; Liu, J.; Fan, X.; Liu, R. Trash to treasure: Low-light object detection via decomposition-and-aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 1417–1425. [Google Scholar]
- Hui, Y.; Wang, J.; Li, B. WSA-YOLO: Weak-supervised and Adaptive object detection in the low-light environment for YOLOV7. IEEE Trans. Instrum. Meas. 2024, 73, 2507012. [Google Scholar] [CrossRef]
- Neumann, L.; Karg, M.; Zhang, S.; Scharfenberger, C.; Piegert, E.; Mistr, S.; Prokofyeva, O.; Thiel, R.; Vedaldi, A.; Zisserman, A.; et al. Nightowls: A pedestrians at night dataset. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part I 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 691–705. [Google Scholar]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, W.J.; Wang, Z.; Zhang, T.; Zhong, Q.; Xie, D.; Pu, S.; et al. Advancing image understanding in poor visibility environments: A collective benchmark study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef]
- Makihara, Y.; Takizawa, M.; Shirai, Y.; Shimada, N. Object recognition under various lighting conditions. In Proceedings of the Image Analysis: 13th Scandinavian Conference, SCIA 2003, Halmstad, Sweden, 29 June–2 July 2003; Proceedings 13. Springer: Berlin/Heidelberg, Germany, 2003; pp. 899–906. [Google Scholar]
- Kvyetnyy, R.; Maslii, R.; Harmash, V.; Bogach, I.; Kotyra, A.; Grądz, Ż.; Zhanpeisova, A.; Askarova, N. Object detection in images with low light condition. In Proceedings of the Photonics Applications in Astronomy, Communications, Industry, and High Energy Physics Experiments 2017, Wilga, Poland, 28 May–6 June 2017; SPIE: Bellingham, WA, USA, 2017; Volume 10445, pp. 250–259. [Google Scholar]
- Yin, W.; Yu, S.; Lin, Y.; Liu, J.; Sonke, J.J.; Gavves, E. Domain Adaptation with Cauchy-Schwarz Divergence. arXiv 2024, arXiv:2405.19978. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Li, X.; Li, Y.; Du, Z.; Li, F.; Lu, K.; Li, J. Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation. arXiv 2024, arXiv:2403.06946. [Google Scholar]
- Wang, C.; Pan, J.; Wang, W.; Fu, G.; Liang, S.; Wang, M.; Wu, X.M.; Liu, J. Correlation Matching Transformation Transformers for UHD Image Restoration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5336–5344. [Google Scholar]
- Lu, X.; Yuan, Y.; Liu, X.; Wang, L.; Zhou, X.; Yang, Y. Low-Light Salient Object Detection by Learning to Highlight the Foreground Objects. IEEE Trans. Circuits Syst. Video Technol. 2024. [Google Scholar] [CrossRef]
- Han, J.; Liang, X.; Xu, H.; Chen, K.; Hong, L.; Mao, J.; Ye, C.; Zhang, W.; Li, Z.; Liang, X.; et al. SODA10M: A large-scale 2D self/Semi-supervised object detection dataset for autonomous driving. arXiv 2021, arXiv:2106.11118. [Google Scholar]
- Sun, T.; Segu, M.; Postels, J.; Wang, Y.; Van Gool, L.; Schiele, B.; Tombari, F.; Yu, F. SHIFT: A synthetic driving dataset for continuous multi-task domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21371–21382. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Zhang, S.; Wang, X.; Wang, J.; Pang, J.; Lyu, C.; Zhang, W.; Luo, P.; Chen, K. Dense Distinct Query for End-to-End Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7329–7338. [Google Scholar]
- Wang, Y.; Ha, J.E. Improved Object Detection with Content and Position Separation in Transformer. Remote Sens. 2024, 16, 353. [Google Scholar] [CrossRef]
- Li, G.; Ji, Z.; Qu, X. Stepwise domain adaptation (SDA) for object detection in autonomous vehicles using an adaptive CenterNet. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17729–17743. [Google Scholar] [CrossRef]
- Oza, P.; Sindagi, V.A.; Sharmini, V.V.; Patel, V.M. Unsupervised domain adaptation of object detectors: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 4018–4040. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Li, G.; Ji, Z.; Qu, X.; Zhou, R.; Cao, D. Cross-domain object detection for autonomous driving: A stepwise domain adaptative YOLO approach. IEEE Trans. Intell. Veh. 2022, 7, 603–615. [Google Scholar] [CrossRef]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- Wang, W.; Cao, Y.; Zhang, J.; He, F.; Zha, Z.J.; Wen, Y.; Tao, D. Exploring sequence feature alignment for domain adaptive detection transformers. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 15 July 2021; pp. 1730–1738. [Google Scholar]
- Huang, W.J.; Lu, Y.L.; Lin, S.Y.; Xie, Y.; Lin, Y.Y. AQT: Adversarial Query Transformers for Domain Adaptive Object Detection. In International Joint Conferences on Artificial Intelligence Proceedings of the 31st International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; pp. 972–979. [Google Scholar]
- Gong, K.; Li, S.; Li, S.; Zhang, R.; Liu, C.H.; Chen, Q. Improving Transferability for Domain Adaptive Detection Transformers. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1543–1551. [Google Scholar]
- He, L.; Wang, W.; Chen, A.; Sun, M.; Kuo, C.H.; Todorovic, S. Bidirectional Alignment for Domain Adaptive Detection with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 18775–18785. [Google Scholar]
- Jiang, Z.; Zhang, Y.; Wang, Z.; Yu, Y.; Zhang, Z.; Zhang, M.; Zhang, L.; Cheng, B. Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images. Remote Sens. 2024, 16, 304. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Arruda, V.F.; Berriel, R.F.; Paixão, T.M.; Badue, C.; De Souza, A.F.; Sebe, N.; Oliveira-Santos, T. Cross-domain object detection using unsupervised image translation. Expert Syst. Appl. 2022, 192, 116334. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 10078–10093. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Jiang, L.; Zhang, C.; Huang, M.; Liu, C.; Shi, J.; Loy, C.C. Tsit: A simple and versatile framework for image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 206–222. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, Y.J.; Dai, X.; Ma, C.Y.; Liu, Y.C.; Chen, K.; Wu, B.; He, Z.; Kitani, K.; Vajda, P. Cross-domain adaptive teacher for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7581–7590. [Google Scholar]
- Kennerley, M.; Wang, J.G.; Veeravalli, B.; Tan, R.T. 2PCNet: Two-Phase Consistency Training for Day-to-Night Unsupervised Domain Adaptive Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 11484–11493. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased mean teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4091–4101. [Google Scholar]
- Cai, Q.; Pan, Y.; Ngo, C.W.; Tian, X.; Duan, L.; Yao, T. Exploring object relation in mean teacher for cross-domain detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11457–11466. [Google Scholar]
- Chen, C.; Zheng, Z.; Ding, X.; Huang, Y.; Dou, Q. Harmonizing transferability and discriminability for adapting object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8869–8878. [Google Scholar]
- Chen, M.; Chen, W.; Yang, S.; Song, J.; Wang, X.; Zhang, L.; Yan, Y.; Qi, D.; Zhuang, Y.; Xie, D.; et al. Learning Domain Adaptive Object Detection with Probabilistic Teacher. In Proceedings of the International Conference on Machine Learning (PMLR), Baltimore, MD, USA, 17–23 July 2022; pp. 3040–3055. [Google Scholar]
- Zhao, L.; Wang, L. Task-specific inconsistency alignment for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14217–14226. [Google Scholar]
- He, M.; Wang, Y.; Wu, J.; Wang, Y.; Li, H.; Li, B.; Gan, W.; Wu, W.; Qiao, Y. Cross domain object detection by target-perceived dual branch distillation. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9570–9580. [Google Scholar]
- Liu, X.; Li, W.; Yang, Q.; Li, B.; Yuan, Y. Towards robust adaptive object detection under noisy annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18-24 June 2022; pp. 14207–14216. [Google Scholar]
- Liu, D.; Zhang, C.; Song, Y.; Huang, H.; Wang, C.; Barnett, M.; Cai, W. Decompose to adapt: Cross-domain object detection via feature disentanglement. IEEE Trans. Multimed. 2022, 25, 1333–1344. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, B.; Wang, J.; Long, M. Decoupled adaptation for cross-domain object detection. arXiv 2021, arXiv:2110.02578. [Google Scholar]
- Liu, Y.; Wang, J.; Wang, W.; Hu, Y.; Wang, Y.; Xu, Y. CRADA: Cross Domain Object Detection with Cyclic Reconstruction and Decoupling Adaptation. IEEE Trans. Multimed. 2024, 26, 6250–6261. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Li, W.; Liu, X.; Yao, X.; Yuan, Y. Scan: Cross domain object detection with semantic conditioned adaptation. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 27 June 2022; Volume 36, pp. 1421–1428. [Google Scholar]
- Li, W.; Liu, X.; Yuan, Y. SCAN++: Enhanced Semantic Conditioned Adaptation for Domain Adaptive Object Detection. IEEE Trans. Multimed. 2022, 25, 7051–7061. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Yuan, Y. Sigma: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5291–5300. [Google Scholar]
- Li, W.; Liu, X.; Yuan, Y. SIGMA++: Improved Semantic-complete Graph Matching for Domain Adaptive Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9022–9040. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Lu, X. Domain Adaptation of Anchor-Free object detection for urban traffic. Neurocomputing 2024, 582, 127477. [Google Scholar] [CrossRef]
- Guo, Y.; Yu, H.; Xie, S.; Ma, L.; Cao, X.; Luo, X. DSCA: A Dual Semantic Correlation Alignment Method for domain adaptation object detection. Pattern Recognit. 2024, 150, 110329. [Google Scholar] [CrossRef]
- Mattolin, G.; Zanella, L.; Ricci, E.; Wang, Y. Confmix: Unsupervised domain adaptation for object detection via confidence-based mixing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, New Orleans, LA, USA, 18–24 June 2023; pp. 423–433. [Google Scholar]
- Yu, J.; Liu, J.; Wei, X.; Zhou, H.; Nakata, Y.; Gudovskiy, D.; Okuno, T.; Li, J.; Keutzer, K.; Zhang, S. MTTrans: Cross-domain Object Detection with Mean Teacher Transformer. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part IX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 629–645. [Google Scholar]
- Zhang, J.; Huang, J.; Luo, Z.; Zhang, G.; Zhang, X.; Lu, S. DA-DETR: Domain Adaptive Detection Transformer With Information Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23787–23798. [Google Scholar]
- Jia, P.; Liu, J.; Yang, S.; Wu, J.; Xie, X.; Zhang, S. PM-DETR: Domain Adaptive Prompt Memory for Object Detection with Transformers. arXiv 2023, arXiv:2307.00313. [Google Scholar]
- Zhang, G.; Wang, L.; Zhang, Z.; Chen, Z. CPLT: Curriculum Pseudo Label Transformer for Domain Adaptive Object Detection in Foggy Weather. IEEE Sens. J. 2023, 23, 29857–29868. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).