



Assessing Land Cover Classification Accuracy: Variations in Dataset Combinations and Deep Learning Models

Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Research Method
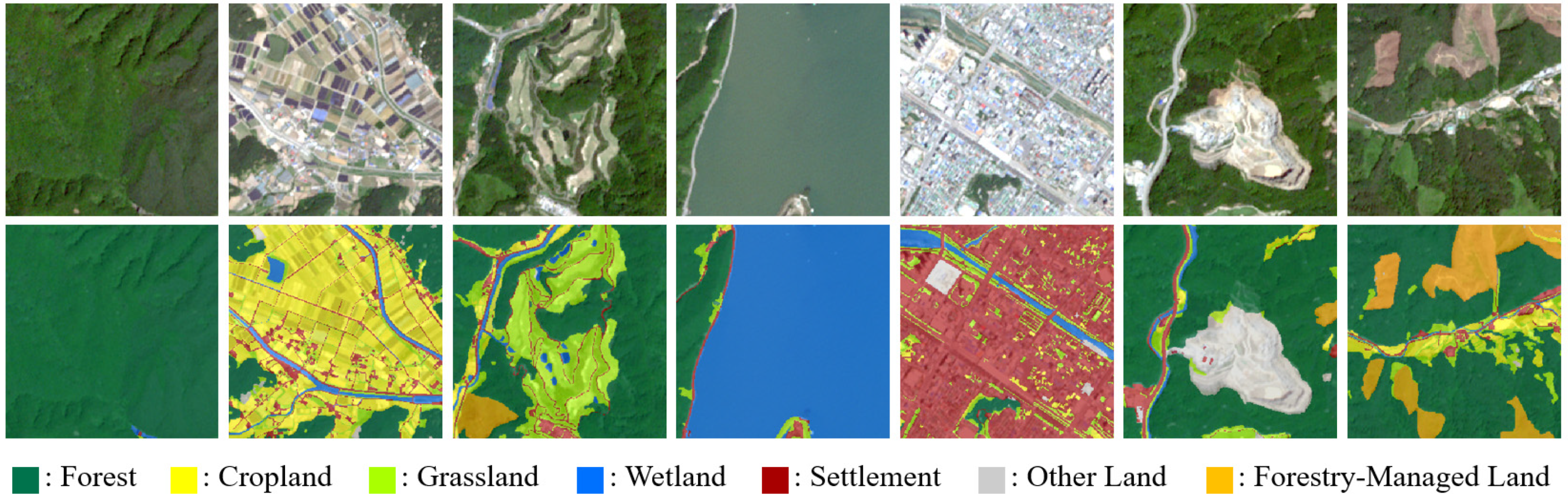
2.2.1. Construction of Datasets for Land-Use Categories Using Spectral and Textural Information
2.2.2. Building and Configuring Deep Learning Models for Land Cover Classification
2.2.3. Evaluation of Consistency for Deep Learning-Based Land Cover Maps
3. Results and Discussion
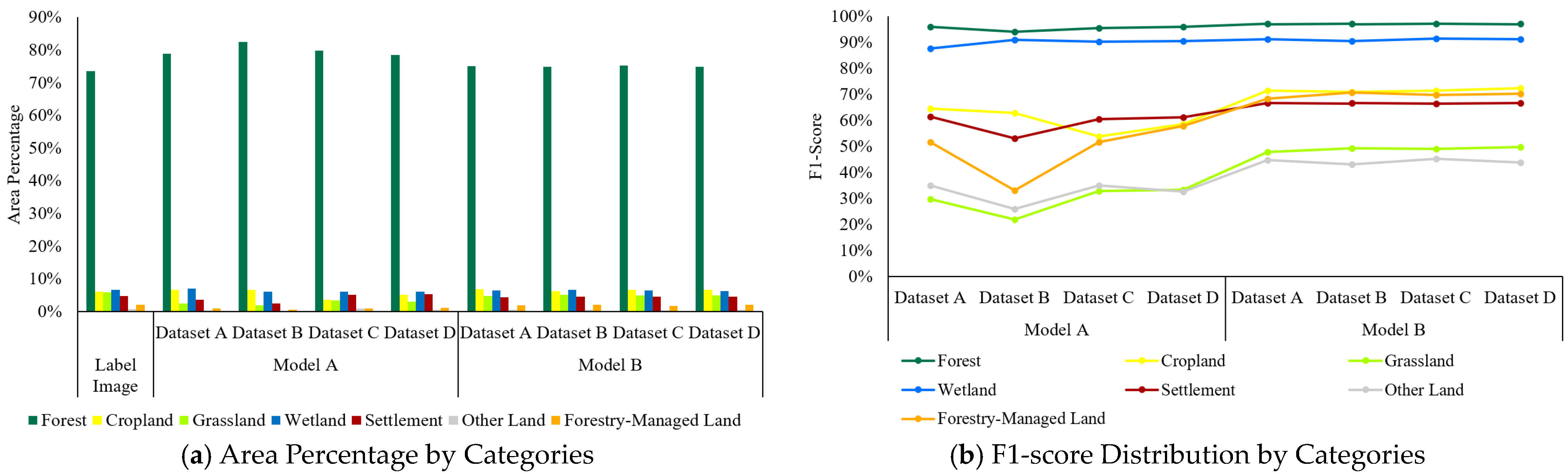
3.1. Distribution Patterns of Area Ratios, Surface Reflectance, and GLCM across Land Cover Categories in Deep Learning Training Data
3.2. Comparison of Training and Validation Accuracy in Deep Learning Model for Land Cover Classification
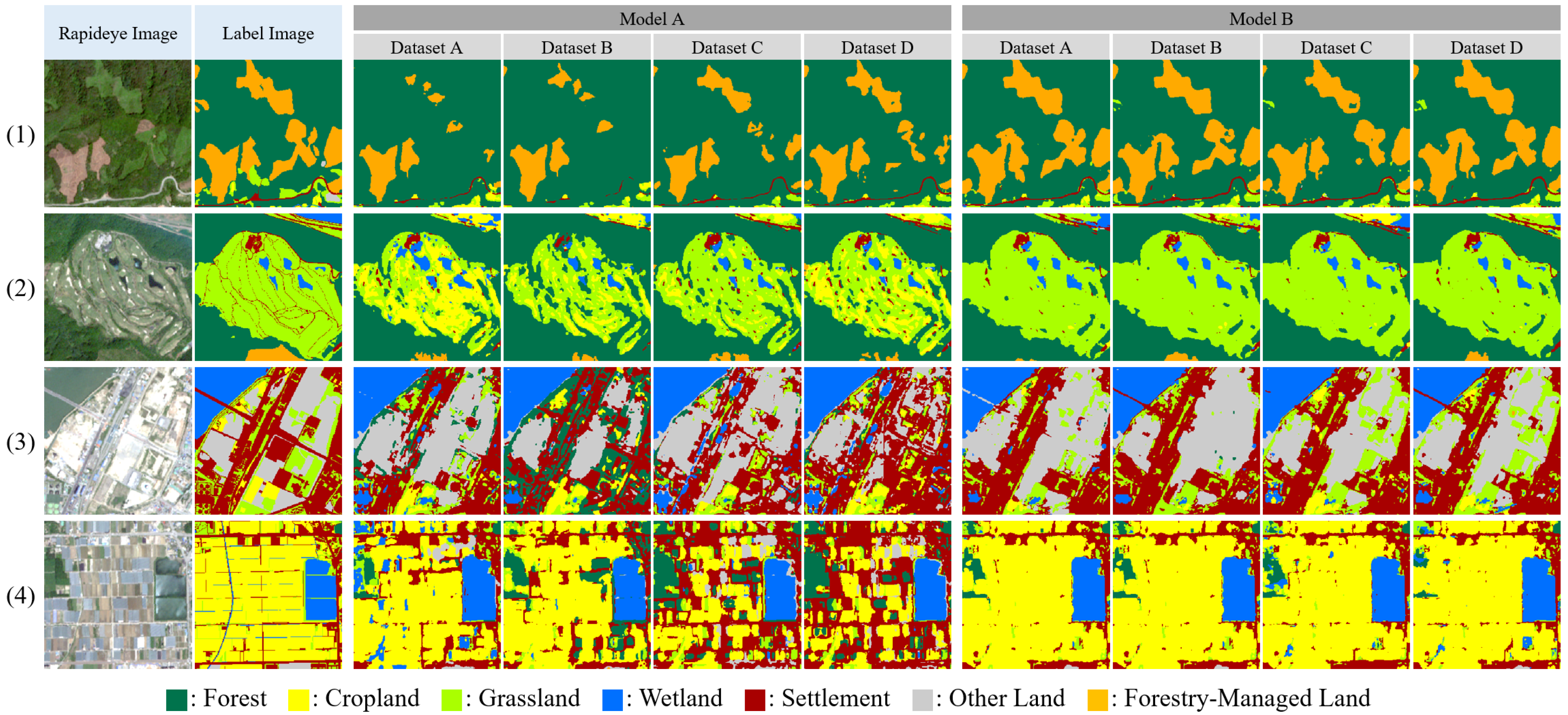
3.3. Evaluation of Land Cover Classification Accuracy for Each Deep Learning Model
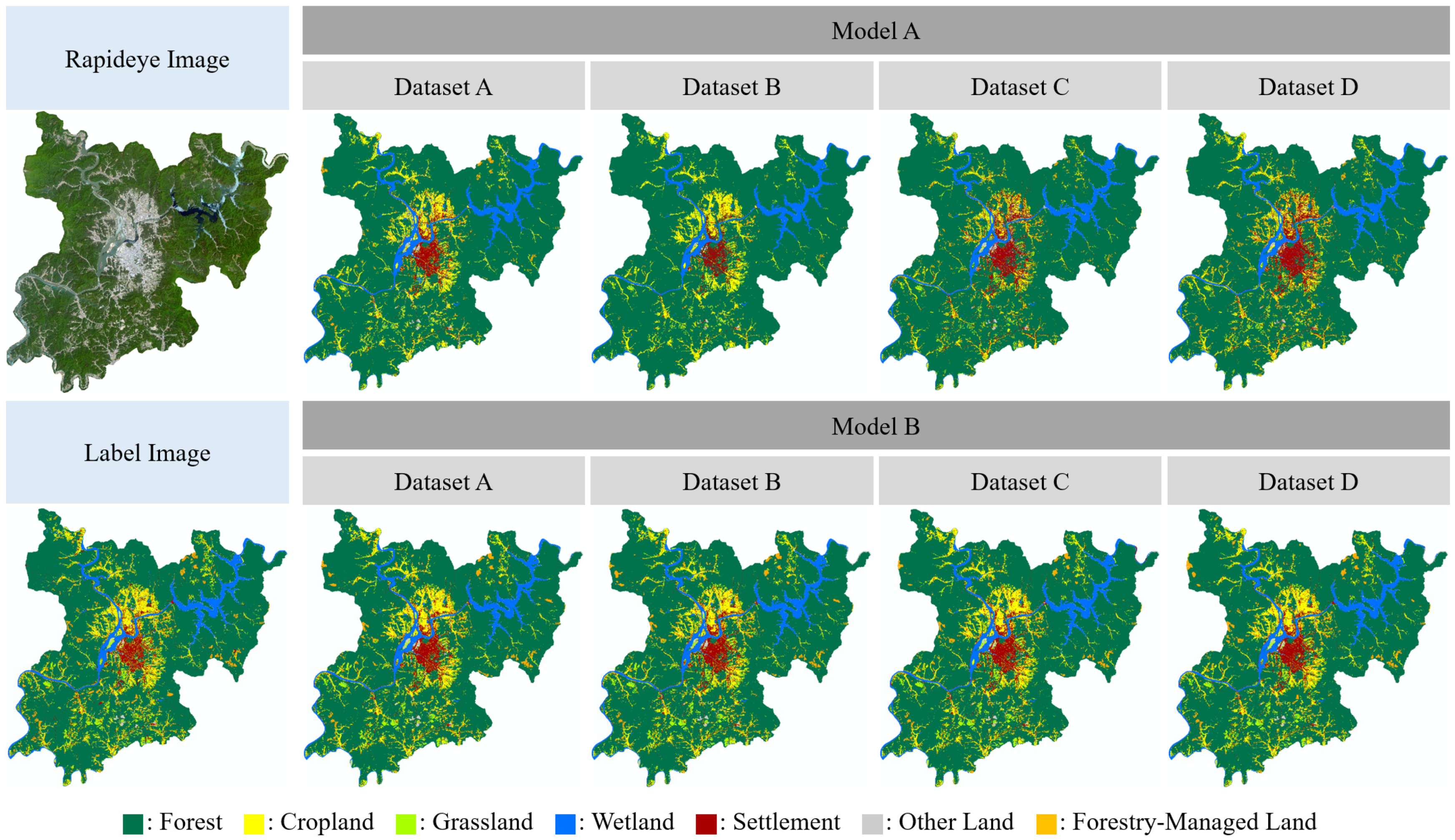
3.4. Comparison of Land Cover Accuracy between Deep Learning Model and Label Images by Categories
3.5. Utilization of Land Cover Maps Based on Deep Learning Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schwab, K. The Fourth Industrial Revolution; Currency: New York, NY, USA, 2017; Available online: https://play.google.com/store/books/details?id=ST_FDAAAQBAJ (accessed on 2 February 2024).
- KFS (Korea Forest Service). K-Forest. Available online: https://www.forest.go.kr/kfsweb/kfi/kfs/cms/cmsView.do?mn=NKFS_02_13_04&cmsId=FC_003420 (accessed on 2 February 2024).
- Kim, E.S.; Won, M.; Kim, K.; Park, J.; Lee, J.S. Forest management research using optical sensors and remote sensing technologies. Korean J. Remote Sens. 2019, 35, 1031–1035. [Google Scholar] [CrossRef]
- Woo, H.; Cho, S.; Jung, G.; Park, J. Precision forestry using remote sensing techniques: Opportunities and limitations of remote sensing application in forestry. Korean J. Remote Sens. 2019, 35, 1067–1082. [Google Scholar] [CrossRef]
- Lee, W.K.; Kim, M.; Song, C.; Lee, S.G.; Cha, S.; Kim, G. Application of Remote Sensing and Geographic Information System in Forest Sector. J. Cadastre Land InformatiX 2016, 46, 27–42. [Google Scholar] [CrossRef]
- Park, E.B.; Song, C.H.; Ham, B.Y.; Kim, J.W.; Lee, J.Y.; Choi, S.E.; Lee, W.K. Comparison of sampling and wall-to-wall methodologies for reporting the GHG inventory of the LULUCF sector in Korea. J. Climate Chang. Res. 2018, 9, 385–398. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014. [Google Scholar] [CrossRef]
- Solórzano, J.V.; Mas, J.F.; Gao, Y.; Gallardo-Cruz, J.A. Land use land cover classification with U-net: Advantages of combining sentinel-1 and sentinel-2 imagery. Remote Sens. 2021, 13, 3600. [Google Scholar] [CrossRef]
- Son, S.; Lee, S.H.; Bae, J.; Ryu, M.; Lee, D.; Park, S.R.; Seo, D.; Kim, J. Land-cover-change detection with aerial orthoimagery using segnet-based semantic segmentation in Namyangju City, South Korea. Sustainability 2022, 14, 12321. [Google Scholar] [CrossRef]
- Lee, Y.; Sim, W.; Park, J.; Lee, J. Evaluation of hyperparameter combinations of the U-net model for land cover classification. Forests 2022, 13, 1813. [Google Scholar] [CrossRef]
- Yaloveha, V.; Podorozhniak, A.; Kuchuk, H. Convolutional neural network hyperparameter optimization applied to land cover classification. Radioelectron. Comput. Syst. 2022, 23, 115–128. [Google Scholar] [CrossRef]
- Azedou, A.; Amine, A.; Kisekka, I.; Lahssini, S.; Bouziani, Y.; Moukrim, S. Enhancing land cover/land use (LCLU) classification through a comparative analysis of hyperparameters optimization approaches for deep neural network (DNN). Ecol. Inf. 2023, 78, 102333. [Google Scholar] [CrossRef]
- Yuan, J.; Ru, L.; Wang, S.; Wu, C. WH-MAVS: A novel dataset and deep learning benchmark for multiple land use and land cover applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1575–1590. [Google Scholar] [CrossRef]
- Zhang, X.; Han, L.; Han, L.; Zhu, L. How well do deep learning-based methods for land cover classification and object detection perform on high resolution remote sensing imagery? Remote Sens. 2020, 12, 417. [Google Scholar] [CrossRef]
- Lee, S.H.; Lee, M.J. A study on deep learning optimization by land cover classification item using satellite imagery. Korean J. Remote Sens. 2020, 36, 1591–1604. [Google Scholar] [CrossRef]
- Jeong, M.; Choi, H.; Choi, J. Analysis of change detection results by UNet++ models according to the characteristics of loss function. Korean J. Remote Sens. 2020, 36, 929–937. [Google Scholar] [CrossRef]
- Baek, W.K.; Lee, M.J.; Jung, H.S. The performance improvement of U-Net model for landcover semantic segmentation through data augmentation. Korean J. Remote Sens. 2022, 38, 1663–1676. [Google Scholar] [CrossRef]
- Chuncheon-si. Introduce Chuncheon. Available online: https://www.chuncheon.go.kr/cityhall/about-chuncheon/introduction/general/ (accessed on 2 February 2024).
- Ministry of Land, Infrastructure and Transport. Cadastral Statistics. Available online: https://stat.molit.go.kr/portal/cate/statMetaView.do?hRsId=24 (accessed on 2 February 2024).
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022; Available online: https://dl.acm.org/doi/abs/10.5555/3378999 (accessed on 2 February 2024).
- Ministry of Environment. Land Cover Map. Available online: https://egis.me.go.kr/intro/land.do (accessed on 2 February 2024).
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Clausi, D.A. An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote Sens. 2002, 28, 45–62. [Google Scholar] [CrossRef]
- Kyoto Protocol. Kyoto Protocol. UNFCCC Website. Available online: http://unfccc.int/kyoto_protocol/items/2830.php (accessed on 2 February 2024).
- Intergovernmental Panel on Climate Change. 2006 IPCC Guidelines for National Greenhouse Gas Inventories; Institute for Global Environmental Strategies: Hayama, Kanagawa, Japan, 2006; Available online: http://www.ipcc-nggip.iges.or.jp/ (accessed on 2 February 2024).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. Available online: https://openreview.net/forum?id=rk6qdGgCZ (accessed on 2 February 2024).
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications; SPIE: New York, NY, USA, 2019; Volume 11006, pp. 369–386. [Google Scholar] [CrossRef]
- Rouhi, R.; Jafari, M.; Kasaei, S.; Keshavarzian, P. Benign and malignant breast tumors classification based on region growing and CNN segmentation. Expert Syst. Appl. 2015, 42, 990–1002. [Google Scholar] [CrossRef]
- Huang, M.H.; Rust, R.T. Artificial intelligence in service. J. Serv. Res. 2018, 21, 155–172. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 2, pp. 1398–1402. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_paper.html (accessed on 2 February 2024).
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–9 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Yu, L.; Su, J.; Li, C.; Wang, L.; Luo, Z.; Yan, B. Improvement of moderate resolution land use and land cover classification by introducing adjacent region features. Remote Sens. 2018, 10, 414. [Google Scholar] [CrossRef]
- Zheng, X.; Han, L.; He, G.; Wang, N.; Wang, G.; Feng, L. Semantic segmentation model for wide-area coseismic landslide extraction based on embedded multichannel spectral–topographic feature fusion: A case study of the Jiu-zhaigou Ms7.0 earthquake in Sichuan, China. Remote Sens. 2023, 15, 1084. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Gong, J.; Feng, Q.; Zhou, J.; Sun, J.; Shi, C.; Hu, W. Urban water extraction with UAV high-resolution remote sensing data based on an improved U-Net model. Remote Sens. 2021, 13, 3165. [Google Scholar] [CrossRef]
- Giang, T.L.; Dang, K.B.; Le, Q.T.; Nguyen, V.G.; Tong, S.S.; Pham, V.M. U-Net convolutional networks for mining land cover classification based on high-resolution UAV imagery. IEEE Access 2020, 8, 186257–186273. [Google Scholar] [CrossRef]
- Kim, J.; Lim, C.H.; Jo, H.W.; Lee, W.K. Phenological classification using deep learning and the sentinel-2 satellite to identify priority afforestation sites in North Korea. Remote Sens. 2021, 13, 2946. [Google Scholar] [CrossRef]
- Ulmas, P.; Liiv, I. Segmentation of satellite imagery using u-net models for land cover classification. arXiv 2020. [Google Scholar] [CrossRef]
- Nanni, L.; Cuza, D.; Lumini, A.; Loreggia, A.; Brahnam, S. Deep ensembles in bioimage segmentation. arXiv 2021. [Google Scholar] [CrossRef]
- Llugsi, R.; El Yacoubi, S.; Fontaine, A.; Lupera, P. Comparison between Adam, AdaMax and Adam W optimizers to implement a weather forecast based on neural networks for the Andean city of Quito. In Proceedings of the 2021 IEEE Fifth Ecuador Technical Chapters Meeting (ETCM), Cuenca, Spain, 12–15 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef] [PubMed]
- Han, Z.; Dian, Y.; Xia, H.; Zhou, J.; Jian, Y.; Yao, C.; Wang, X.; Li, Y. Comparing fully deep convolutional neural networks for land cover classification with high-spatial-resolution Gaofen-2 images. ISPRS Int. J. Geo-Inf. 2020, 9, 478. [Google Scholar] [CrossRef]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land cover maps production with high resolution satellite image time series and convolutional neural networks: Adaptations and limits for operational systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Xu, X. ObjectAug: Object-Level Data Augmentation for Semantic Image Segmentation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Virtual, 18–22 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, L.; Yuan, Y.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Interlaced Sparse Self-Attention for Semantic Segmentation. arXiv 2019. [Google Scholar] [CrossRef]
- Wu, Y.H.; Zhang, S.C.; Liu, Y.; Zhang, L.; Zhan, X.; Zhou, D.; Zhen, L. Low-Resolution Self-Attention for Semantic Seg-mentation. arXiv 2023. [Google Scholar] [CrossRef]
- Wang, Z.; Fan, B.; Tu, Z.; Li, H.; Chen, D. Cloud and Snow Identification Based on DeepLab V3+ and CRF Combined Model for GF-1 WFV Images. Remote Sens. 2022, 14, 4880. [Google Scholar] [CrossRef]
- Sefrin, O.; Riese, F.M.; Keller, S. Deep learning for land cover change detection. Remote Sens. 2020, 13, 78. [Google Scholar] [CrossRef]
- Ministry of Environment, Land Cover Map, Approved as National Statistics. Available online: https://www.me.go.kr/home/web/board/read.do?menuId=10525&boardMasterId=1&boardCategoryId=39&boardId=1671630 (accessed on 14 June 2024).
- Mahmoudzadeh, H.; Abedini, A.; Aram, F. Urban Growth Modeling and Land-Use/Land-Cover Change Analysis in a Metropolitan Area (Case Study: Tabriz). Land 2022, 11, 2162. [Google Scholar] [CrossRef]
- Mehra, N.; Swain, J.B. Assessment of Land Use Land Cover Change and Its Effects Using Artificial Neural Network-Based Cellular Automation. J. Eng. Appl. Sci. 2024, 71, 70. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data | Validation Data | Test Data | Deep Learning Dataset |
|---|---|---|---|
| 113 | 47 | 6162 | Dataset A: R, G, B, RE, NIR Dataset B: R, G, B, RE, NIR, GLCM Dataset C: R, G, B, RE, NIR, Slope Dataset D: R, G, B, RE, NIR, GLCM, Slope |
| Category | Model Classification | Total | ||
|---|---|---|---|---|
| Positive | Negative | |||
| Label image (True value) | Positive | TP (true positive) | FN (false negative) | TP + FN |
| Negative | FP (false positive) | TN (true negative) | FP + TN | |
| Total | TP + FP | FN + TN | TP + FN + FP + TN | |
| Category | Surface Reflectance | GLCM | Slope | |||
|---|---|---|---|---|---|---|
| Red | NIR | Correlation | Entropy | Homogeneity | ||
| Forest | 260 ± 127 | 3337 ± 659 | −0.05 ± 0.31 | 7.83 ± 0.05 | 0.04 ± 0.02 | 27.2 ± 10.9 |
| Cropland | 1101 ± 507 | 2547 ± 748 | −0.03 ± 0.34 | 7.80 ± 0.09 | 0.05 ± 0.03 | 4.8 ± 5.0 |
| Grassland | 690 ± 435 | 3186 ± 761 | −0.07 ± 0.34 | 7.82 ± 0.07 | 0.04 ± 0.02 | 11.9 ± 10.1 |
| Wetland | 459 ± 288 | 821 ± 921 | −0.01 ± 0.30 | 7.53 ± 0.59 | 0.08 ± 0.09 | 1.3 ± 5.3 |
| Settlement | 1369 ± 664 | 2632 ± 651 | −0.06 ± 0.31 | 7.81 ± 0.08 | 0.04 ± 0.02 | 7.4 ± 8.3 |
| Other land | 1690 ± 935 | 2747 ± 910 | 0.02 ± 0.37 | 7.77 ± 0.18 | 0.05 ± 0.04 | 17.0 ± 16.2 |
| Forestry-managed land | 640 ± 366 | 3083 ± 823 | 0.01 ± 0.35 | 7.82 ± 0.06 | 0.04 ± 0.02 | 25.6 ± 10.0 |
| Deep Learning Model | Dataset | Training Results | Validation Results | Training Time (min) | ||
|---|---|---|---|---|---|---|
| Accuracy | Loss | Accuracy | Loss | |||
| Model A | A | 92.6 ± 0.7 | 0.231 ± 0.030 | 82.5 ± 0.5 | 0.539 ± 0.019 | 124.3 ± 4.0 |
| B | 91.9 ± 1.4 | 0.250 ± 0.043 | 81.7 ± 0.9 | 0.522 ± 0.023 | 135.5 ± 2.6 | |
| C | 91.3 ± 1.1 | 0.302 ± 0.054 | 80.9 ± 1.2 | 0.545 ± 0.022 | 129.7 ± 3.5 | |
| D | 91.2 ± 0.8 | 0.270 ± 0.025 | 80.9 ± 0.6 | 0.552 ± 0.011 | 139.2 ± 3.9 | |
| Model B | A | 85.7 ± 0.4 | 0.821 ± 0.005 | 85.4 ± 0.3 | 0.829 ± 0.004 | 124.3 ± 0.7 |
| B | 85.6 ± 0.3 | 0.822 ± 0.004 | 85.3 ± 0.3 | 0.830 ± 0.004 | 135.3 ± 0.8 | |
| C | 86.2 ± 0.3 | 0.815 ± 0.004 | 86.0 ± 0.3 | 0.823 ± 0.003 | 129.0 ± 4.0 | |
| D | 86.2 ± 0.2 | 0.814 ± 0.003 | 86.1 ± 0.3 | 0.821 ± 0.003 | 139.8 ± 3.7 | |
| Dataset | Model A | Model B | ||
|---|---|---|---|---|
| Overall Accuracy (%) | Kappa | Overall Accuracy (%) | Kappa | |
| Dataset A | 88.1 ± 0.3 | 0.71 ± 0.01 | 89.8 ± 0.3 | 0.77 ± 0.01 |
| Dataset B | 86.5 ± 3.3 | 0.65 ± 0.05 | 89.7 ± 0.3 | 0.76 ± 0.01 |
| Dataset C | 87.3 ± 3.3 | 0.68 ± 0.05 | 90.1 ± 0.4 | 0.77 ± 0.01 |
| Dataset D | 88.0 ± 0.6 | 0.71 ± 0.01 | 90.0 ± 0.4 | 0.77 ± 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sim, W.-D.; Yim, J.-S.; Lee, J.-S. Assessing Land Cover Classification Accuracy: Variations in Dataset Combinations and Deep Learning Models. Remote Sens. 2024, 16, 2623. https://doi.org/10.3390/rs16142623
Sim W-D, Yim J-S, Lee J-S. Assessing Land Cover Classification Accuracy: Variations in Dataset Combinations and Deep Learning Models. Remote Sensing. 2024; 16(14):2623. https://doi.org/10.3390/rs16142623
Chicago/Turabian StyleSim, Woo-Dam, Jong-Su Yim, and Jung-Soo Lee. 2024. "Assessing Land Cover Classification Accuracy: Variations in Dataset Combinations and Deep Learning Models" Remote Sensing 16, no. 14: 2623. https://doi.org/10.3390/rs16142623
APA StyleSim, W.-D., Yim, J.-S., & Lee, J.-S. (2024). Assessing Land Cover Classification Accuracy: Variations in Dataset Combinations and Deep Learning Models. Remote Sensing, 16(14), 2623. https://doi.org/10.3390/rs16142623