





MFFnet: Multimodal Feature Fusion Network for Synthetic Aperture Radar and Optical Image Land Cover Classification


Abstract
1. Introduction
- We propose a new multimodal feature fusion network, MFFnet, which consists of a ResNet network specializing in extracting depth features from optical images and another network, PidiNet, for capturing fine-grained texture features of synthetic aperture radar images.
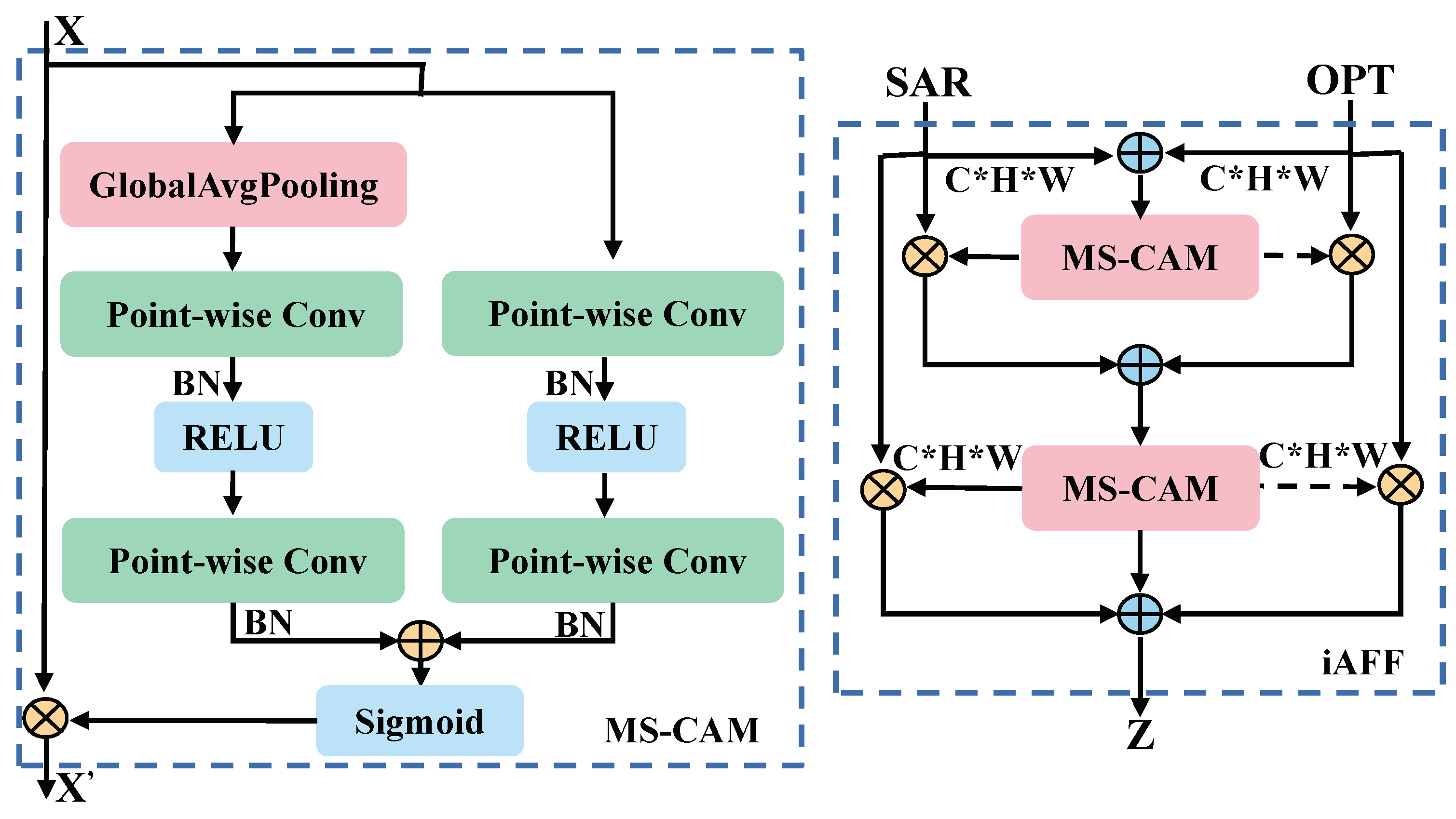
- We employ an iterative attentional feature fusion (iAFF) module to align features from SAR and optical images, which enables deep feature interactions by focusing on features from different modalities in the space and channel.
- The effectiveness and sophistication of our network is verified through extensive comparisons with existing SAR land classification networks and multimodal land classification networks.
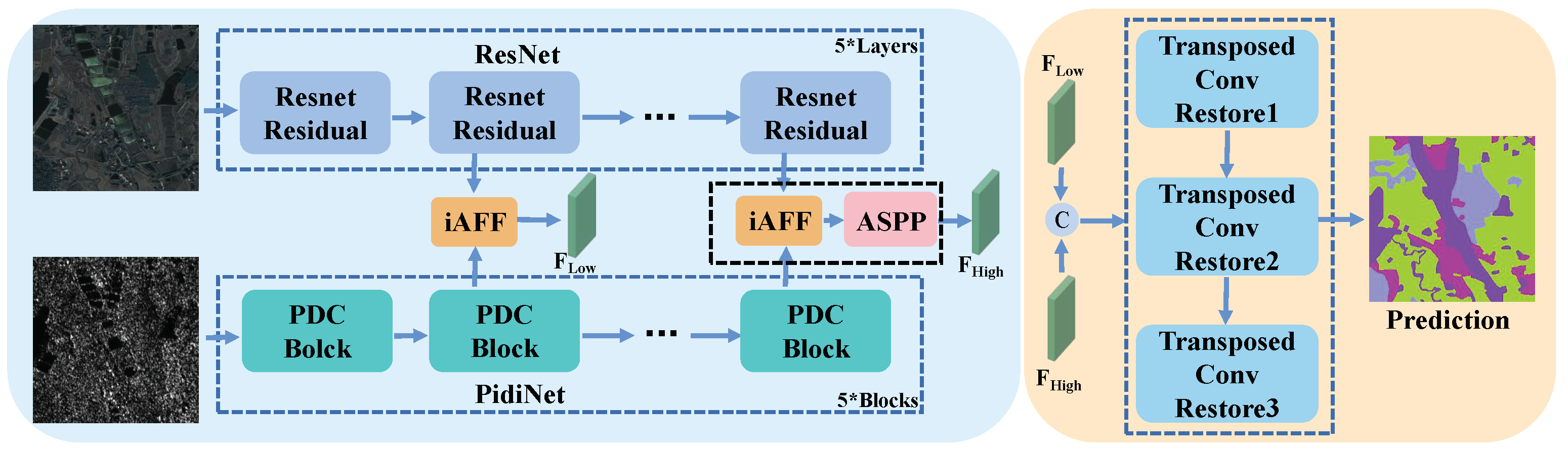
2. Methodology
2.1. Encoder Feature Extraction
2.1.1. Overview
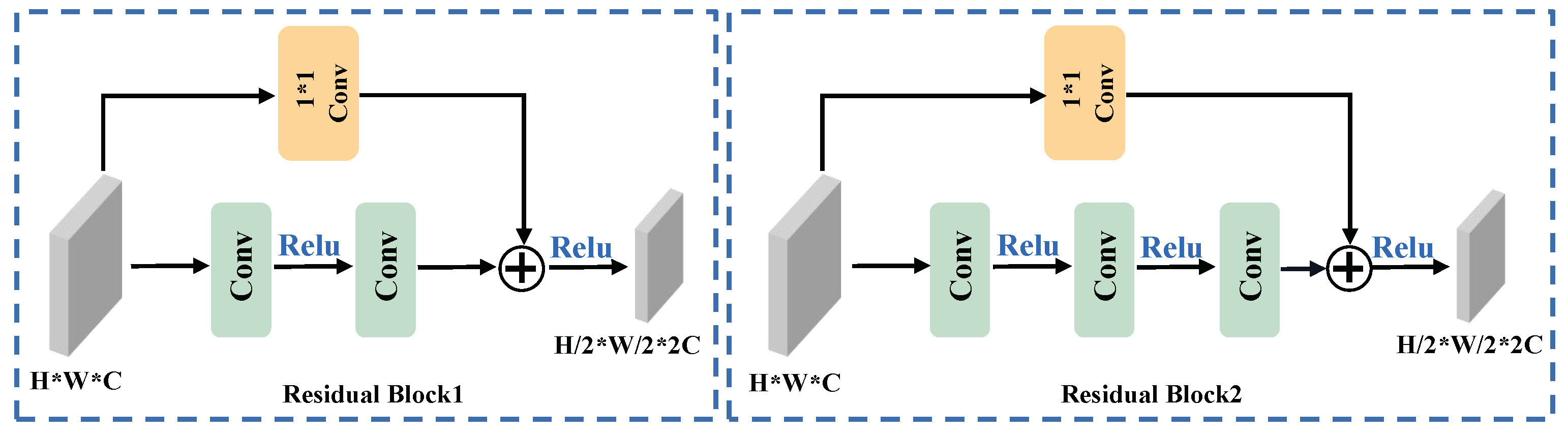
2.1.2. Optical Feature Extraction
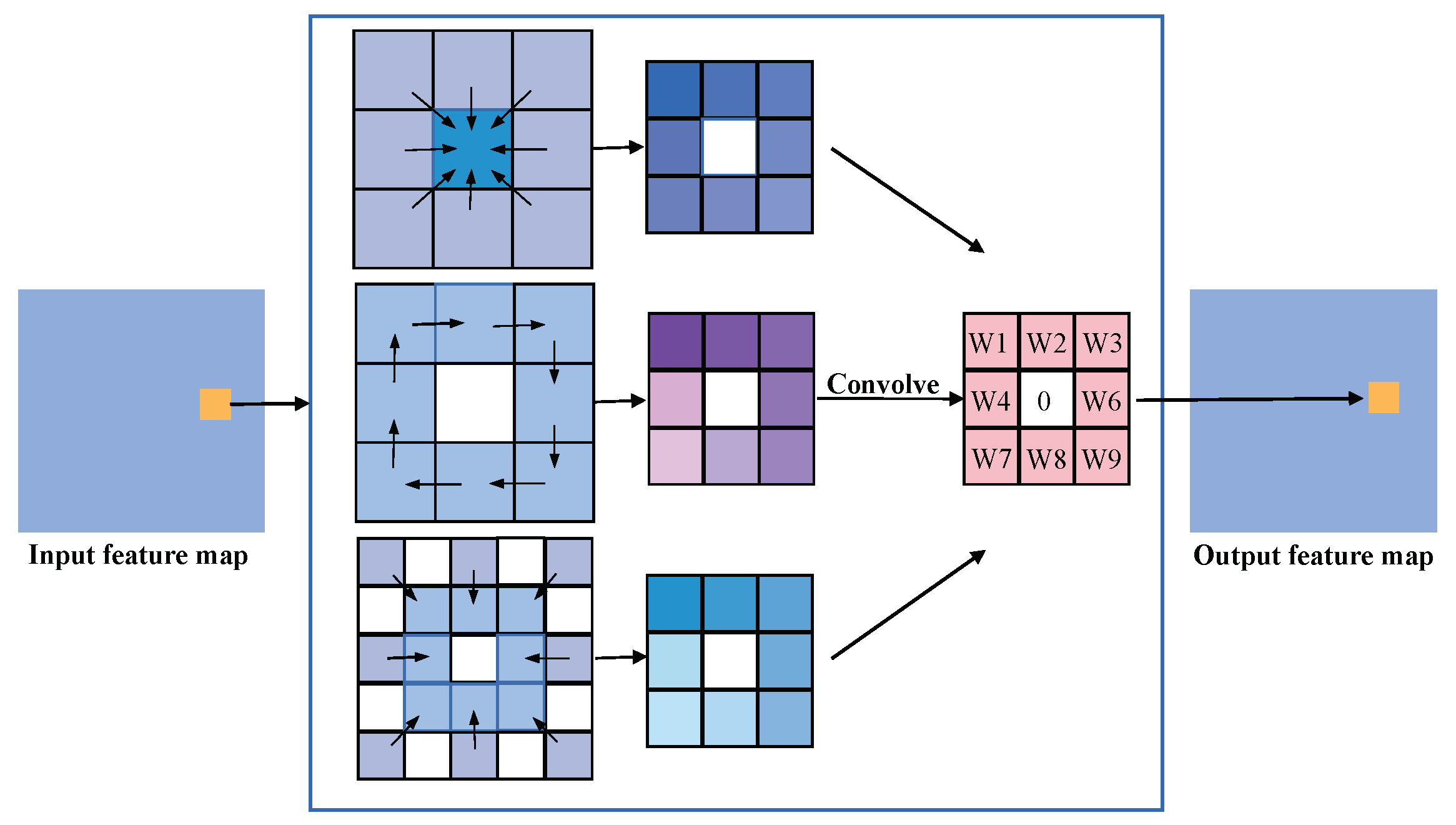
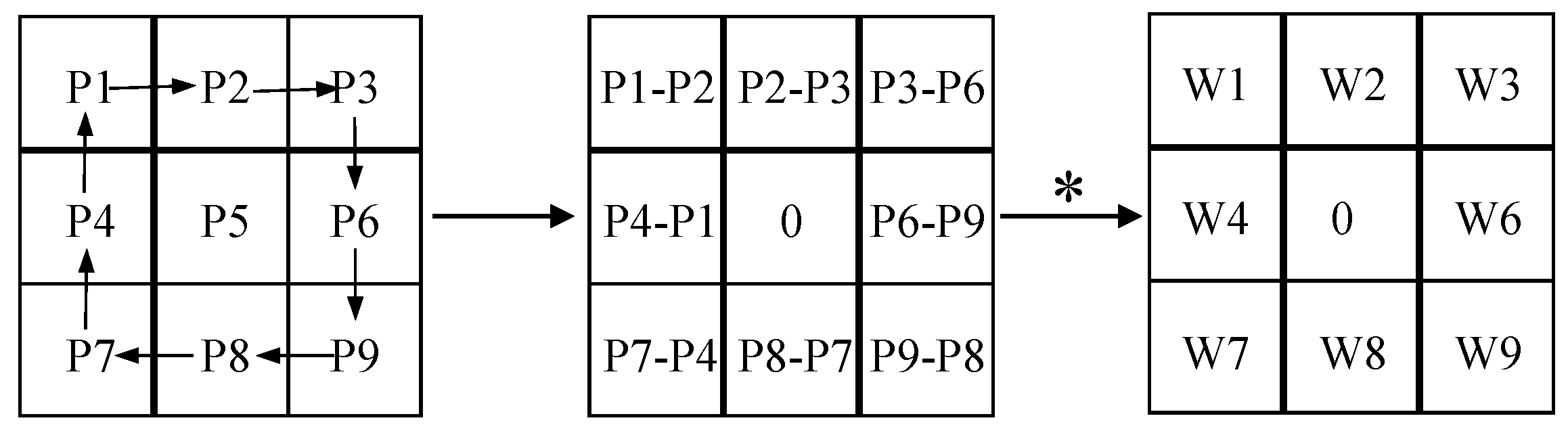
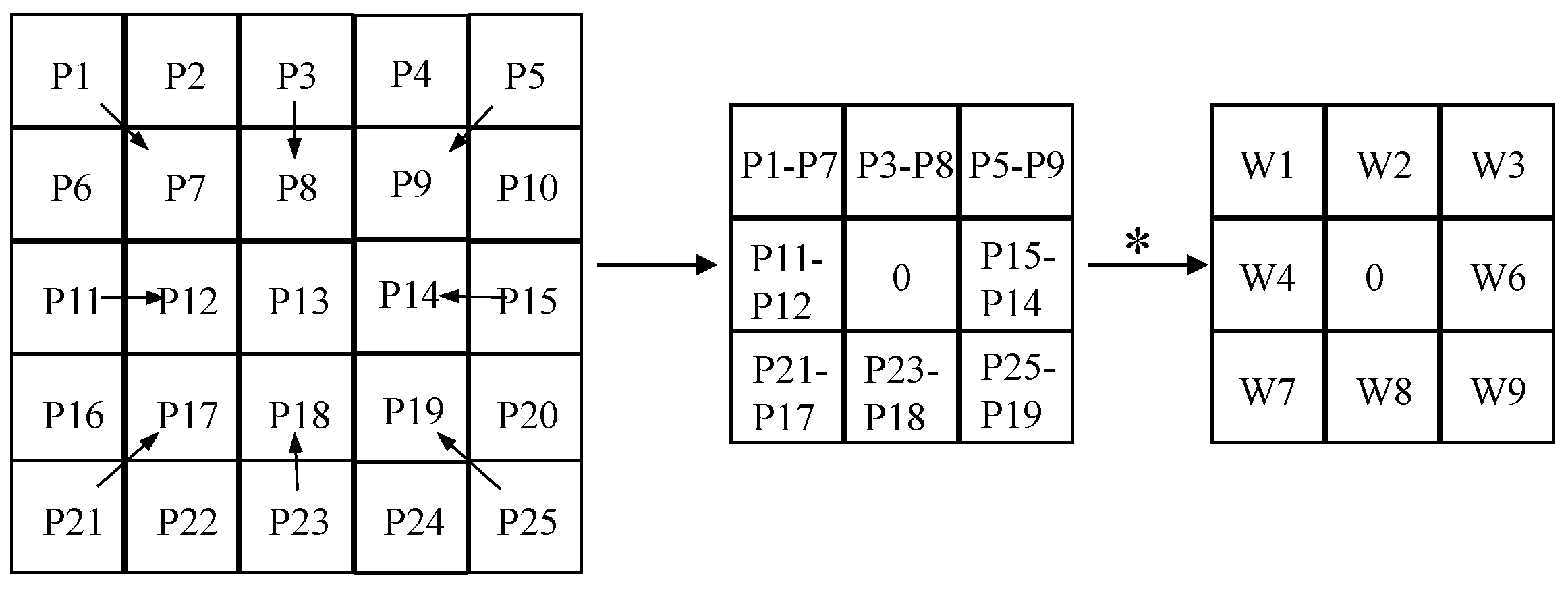
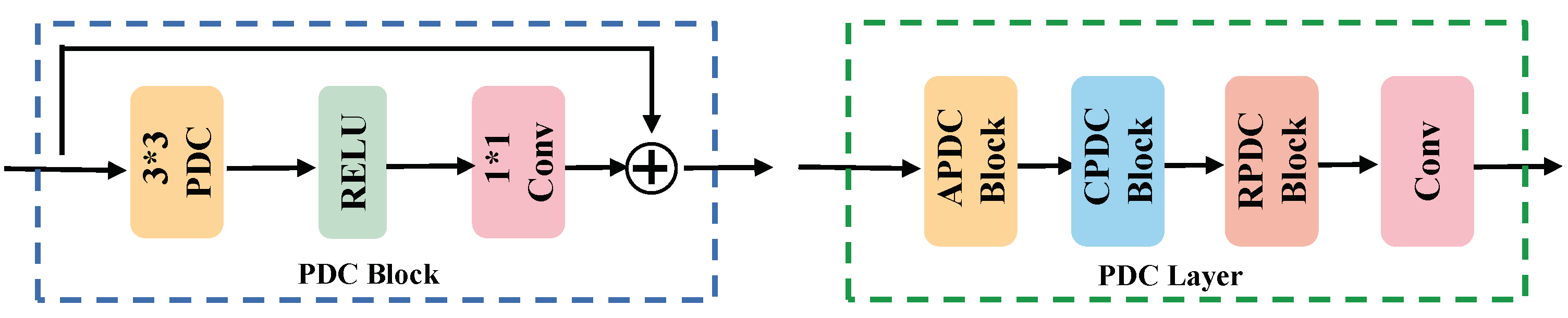
2.1.3. SAR Feature Extraction
2.2. Feature Fusion Module
2.2.1. Overview
2.2.2. Cross-Modal Fusion
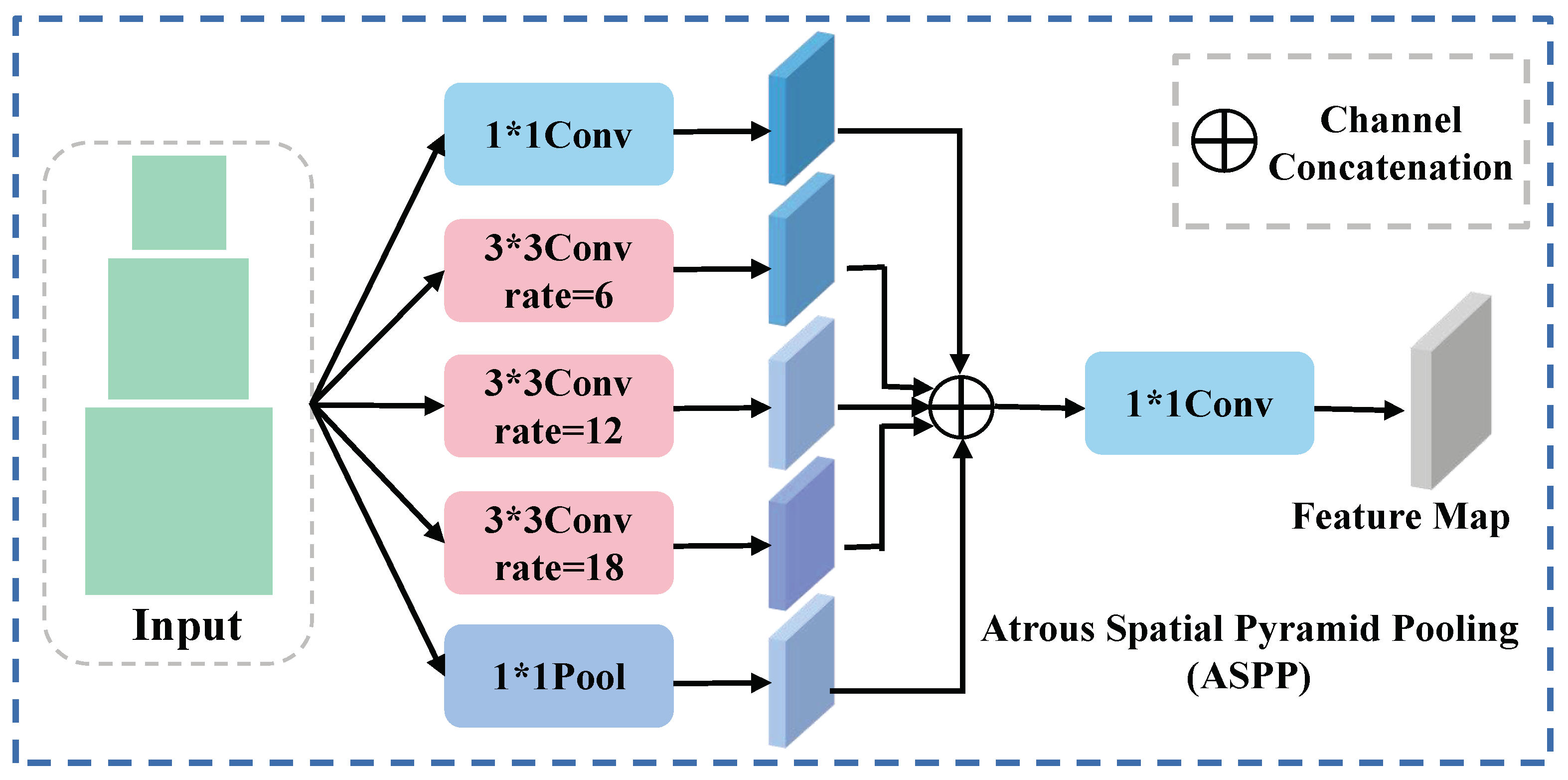
2.2.3. Multiscale Fusion
2.3. Decoder Feature Restoration
3. Experiments
3.1. Training Details and Dataset
3.2. Loss Function
3.3. Quantitative Analysis
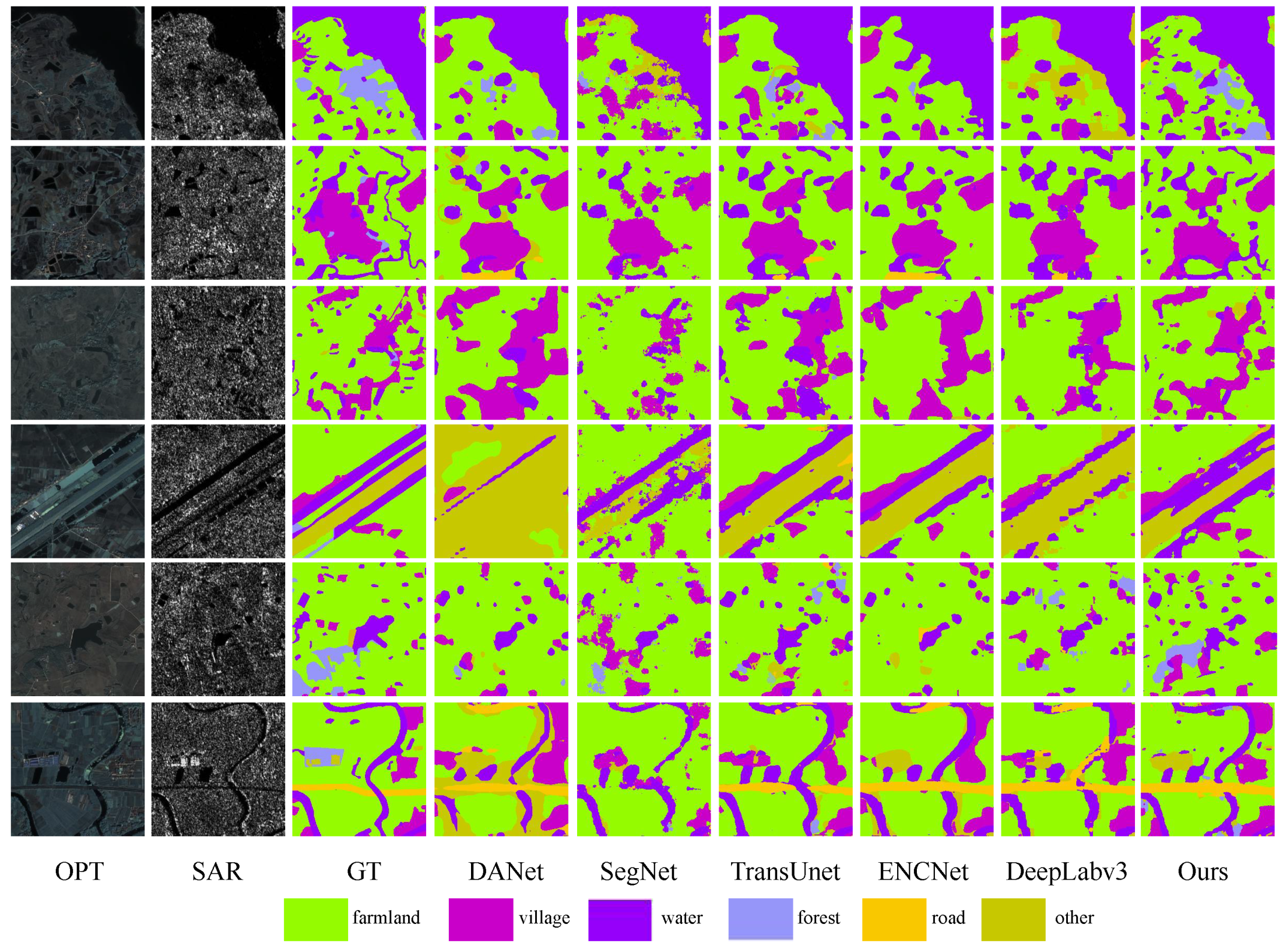
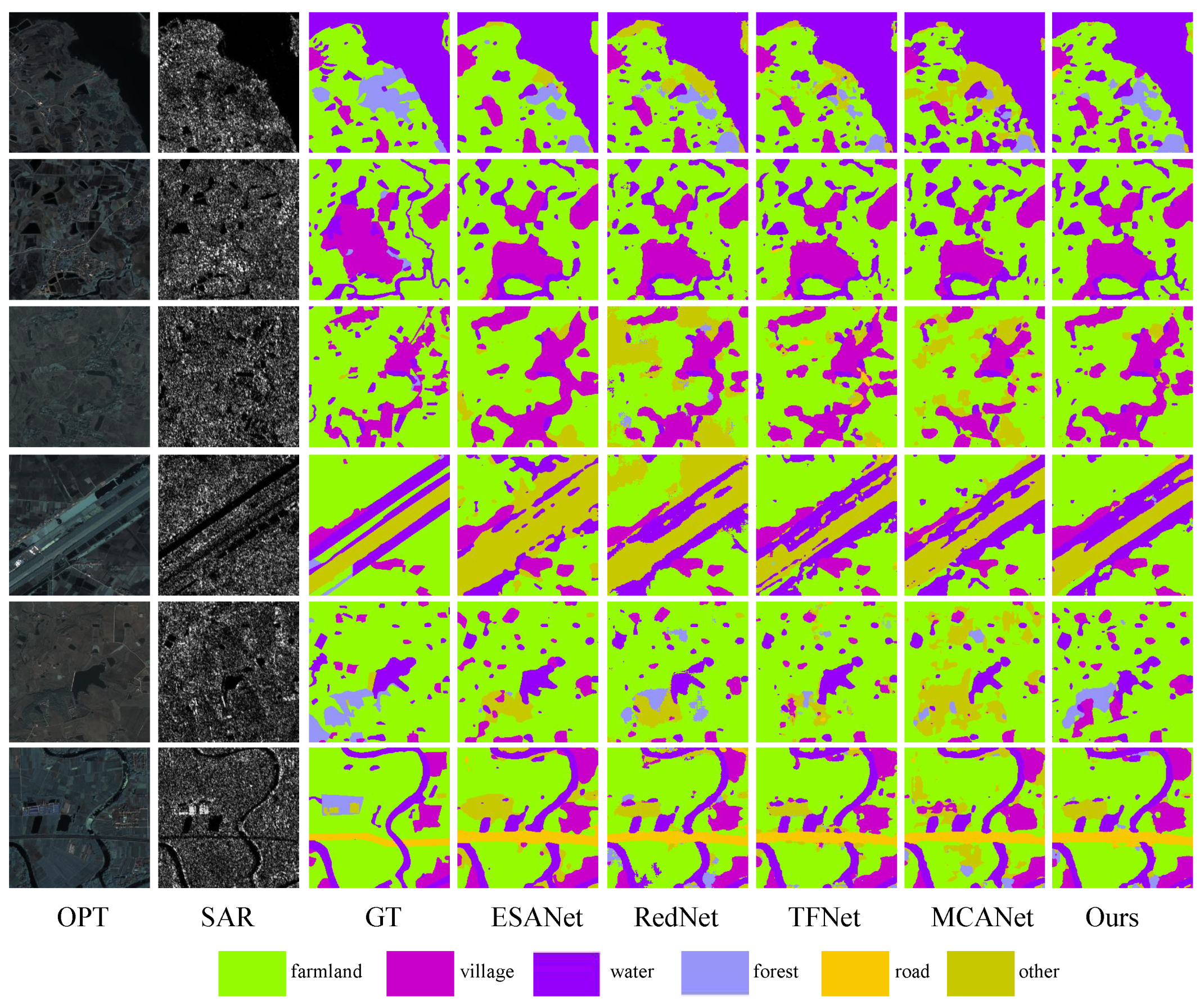
3.4. Land Cover Classification Experiments
3.4.1. Baselines
- SwinUnet [36]: A method utilizing a transformer architecture akin to Unet for medical image segmentation is proposed. This methodology integrates input patches into a transformer-based U-shaped architecture, enabling the effective capture of both local and global features.
- SegNet [37]: An integrated convolutional neural network framework, encompassing an encoder-decoder architecture and culminating in a pixel-wise classification layer, is introduced.
- TransUnet [38]: TransUnet presents a novel integration of transformer and U-Net functionalities. In this approach, the transformer component processes the feature maps encoded by a CNN as input sequences.
- DANet [39]: The presented methodology incorporates attention mechanisms into the enhanced Fully Convolutional Network (FCN), enabling the modeling of semantic dependencies across both spatial and channel dimensions.
- EncNet [40]: A context-encoding module is incorporated into the proposed approach to capture the semantic context. Feature maps are highlighted based on class dependencies, enhancing the model’s ability to discern relevant contextual information.
- Deeplabv3 [41]: DeepLabv3 is harnessed to encode intricate contextual information, while a succinct decoder module is leveraged for precise boundary reconstruction.
- ESANet [42]: An efficient semantic segmentation method designed for multimodal RGB images and depth images is proposed. The feature extraction and fusion of the two inputs occur in stages within the encoder. The decoder incorporates a Multi-Scale Supervision strategy, employing the jump-junction fusion method. Notably, all upsampling is conducted using a learned method rather than bilinear upsampling.
- RedNet [43]: This method employs classical two-stream encoder and decoder architecture, utilizing residual blocks as fundamental building components for both the encoder and decoder. The algorithm integrates encoder outputs and decoder outputs through hopping connections, incorporating an Agent Block operation before each connection layer to decrease the encoder channel size, thereby facilitating fusion.
- TFNet [44]: TFNet is a two-stream fusion algorithm that merges data from distinct modality domains in reconstructing images. In this method, all pooling operations are replaced with a convolution operation. Additionally, transposed convolution is employed for upsampling, and to maintain a symmetric structure in the encoder, feature mapping is conducted for layers in pairs.
- MCANet [45]: The approach is rooted in Deeplabv3, presenting a multimodal segmentation algorithm utilizing optical and SAR images as input. A cross-modal attention module is introduced to enhance and fuse features from both optical and SAR modalities.
3.4.2. Comparison Experiments
3.4.3. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Letsoin, S.M.A.; Herak, D.; Purwestri, R.C. Evaluation Land Use Cover Changes Over 29 Years in Papua Province of Indonesia Using Remote Sensing Data. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2022. [Google Scholar]
- Dahhani, S.; Raji, M.; Hakdaoui, M.; Lhissou, R. Land cover mapping using sentinel-1 time-series data and machine-learning classifiers in agricultural sub-saharan landscape. Remote Sens. 2022, 15, 65. [Google Scholar] [CrossRef]
- Kaul, H.A.; Sopan, I. Land use land cover classification and change detection using high resolution temporal satellite data. J. Environ. 2012, 1, 146–152. [Google Scholar]
- Xu, F.; Shi, Y.; Ebel, P.; Yu, L.; Xia, G.S.; Yang, W.; Zhu, X.X. GLF-CR: SAR-enhanced cloud removal with global–local fusion. ISPRS J. Photogramm. Remote Sens. 2022, 192, 268–278. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Zhang, T. Lite-yolov5: A lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D.; et al. HOG-ShipCLSNet: A novel deep learning network with hog feature fusion for SAR ship classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5210322. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Shao, Z.; Shi, J.; Wei, S.; Zhang, T.; Zeng, T. A group-wise feature enhancement-and-fusion network with dual-polarization feature enrichment for SAR ship detection. Remote Sens. 2022, 14, 5276. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. CFNet: A cross fusion network for joint land cover classification using optical and SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1562–1574. [Google Scholar] [CrossRef]
- Li, X.; Ling, F.; Cai, X.; Ge, Y.; Li, X.; Yin, Z.; Shang, C.; Jia, X.; Du, Y. Mapping water bodies under cloud cover using remotely sensed optical images and a spatiotemporal dependence model. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102470. [Google Scholar] [CrossRef]
- Ye, Y.; Zhang, J.; Zhou, L.; Li, J.; Ren, X.; Fan, J. Optical and SAR image fusion based on complementary feature decomposition and visual saliency features. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5205315. [Google Scholar] [CrossRef]
- Liu, S.; Qi, Z.; Li, X.; Yeh, A.G. Integration of convolutional neural networks and object-based post-classification refinement for land use and land cover mapping with optical and SAR data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef]
- Hong, D.; Hu, J.; Yao, J.; Chanussot, J.; Zhu, X.X. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model. ISPRS J. Photogramm. Remote Sens. 2021, 178, 68–80. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S. Classifying multilevel imagery from SAR and optical sensors by decision fusion. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1457–1466. [Google Scholar] [CrossRef]
- Kulkarni, S.C.; Rege, P.P. Pixel level fusion techniques for SAR and optical images: A review. Inf. Fusion 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Nirmala, D.E.; Vaidehi, V. Comparison of Pixel-level and feature level image fusion methods. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015. [Google Scholar]
- Xiao, G.; Bavirisetti, D.P.; Liu, G.; Zhang, X.; Xiao, G.; Bavirisetti, D.P.; Liu, G.; Zhang, X. Decision-level image fusion. In Image Fusion; Springer: Singapore, 2020. [Google Scholar]
- Dupas, C.A. SAR And LANDSAT TM image fusion for land cover classification inthe brazilian atlantic forest domain. Remote Sens. 2000, 33, 96–103. [Google Scholar]
- Zhang, Y.; Zhang, H.; Lin, H. Improving the impervious surface estimation with combined use of optical and SAR remote sensing images. Remote Sens. Environ. 2014, 141, 155–167. [Google Scholar] [CrossRef]
- Masjedi, A.; Zoej, M.J.; Maghsoudi, Y. Classification of polarimetric SAR images based on modeling contextual information and using texture features. IEEE Trans. Geosci. Remote Sens. 2015, 54, 932–943. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Quan, Y.; Zhang, R.; Li, J.; Ji, S.; Guo, H.; Yu, A. Learning SAR-Optical Cross Modal Features for Land Cover Classification. Remote Sens. 2024, 16, 431. [Google Scholar] [CrossRef]
- Zhang, R.; Tang, X.; You, S.; Duan, K.; Xiang, H.; Luo, H. A novel feature-level fusion framework using optical and SAR remote sensing images for land use/land cover (LULC) classification in cloudy mountainous area. Appl. Sci. 2020, 10, 2928. [Google Scholar] [CrossRef]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Zhu, Y.; Tian, D.; Yan, F. Effectiveness of entropy weight method in decision-making. Math. Probl. Eng. 2020, 2020, 3564835. [Google Scholar] [CrossRef]
- Messner, M.; Polborn, M.K. Voting on majority rules. Rev. Econ. Stud. 2004, 71, 115–132. [Google Scholar] [CrossRef]
- Waske, B.; Benediktsson, J.A. Fusion of support vector machinesfor classification of multisensor data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3858–3866. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Su, Z.; Liu, W.; Yu, Z.; Hu, D.; Liao, Q.; Tian, Q.; Pietikäinen, M.; Liu, L. Pixel difference networks for efficient edge detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, L.; Fieguth, P.; Kuang, G.; Zha, H. Sorted random projections for robust texture classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Liu, L.; Zhao, L.; Long, Y.; Kuang, G.; Fieguth, P. Extended local binary patterns for texture classification. Image Vis. Comput. 2012, 30, 86–99. [Google Scholar] [CrossRef]
- Su, Z.; Pietikäinen, M.; Liu, L. Bird: Learning binary and illumination robust descriptor for face recognition. In Proceedings of the 30th British Machine Visison Conference: BMVC, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Seichter, D.; Köhler, M.; Lewowski, B.; Wengefeld, T.; Gross, H.M. Efficient rgb-d semantic segmentation for indoor scene analysis. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Jiang, J.; Zheng, L.; Luo, F.; Zhang, Z. Rednet: Residual encoder-decoder network for indoor rgb-d semantic segmentation. arXiv 2018, arXiv:1806.01054. [Google Scholar]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion 2020, 55, 1–55. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102638. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA | Kappa | mIoU | IoU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Farmland | City | Village | Water | Forest | Road | Others | ||||
| SwinUnet | 70.53 | 57.80 | 34.04 | 56.22 | 30.84 | 32.87 | 32.64 | 77.27 | 6.04 | 2.42 |
| SegNet | 73.21 | 60.51 | 36.00 | 59.35 | 29.55 | 36.03 | 27.76 | 77.88 | 15.48 | 5.93 |
| TransUnet | 73.40 | 61.87 | 38.09 | 61.22 | 32.49 | 36.15 | 33.01 | 77.82 | 15.63 | 9.88 |
| DANet | 69.18 | 56.82 | 34.31 | 61.09 | 26.41 | 34.62 | 23.71 | 74.61 | 12.82 | 6.92 |
| EncNet | 73.67 | 61.73 | 35.34 | 63.72 | 25.33 | 32.88 | 32.46 | 78.70 | 10.67 | 3.64 |
| Deeplabv3 | 73.59 | 62.33 | 38.44 | 62.46 | 29.01 | 38.76 | 32.67 | 77.96 | 15.43 | 12.82 |
| MFFnet (our network) | 81.29 | 73.59 | 50.64 | 61.23 | 34.34 | 49.04 | 73.26 | 82.82 | 24.96 | 28.84 |
| Method | OA | Kappa | mIoU | IoU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Farmland | City | Village | Water | Forest | Road | Others | ||||
| MCANet | 76.64 | 67.27 | 45.07 | 55.15 | 28.34 | 47.49 | 67.86 | 80.19 | 26.35 | 10.12 |
| ESANet | 79.42 | 71.11 | 46.74 | 59.90 | 23.83 | 41.23 | 72.98 | 82.48 | 23.24 | 23.52 |
| RedNet | 79.45 | 71.14 | 48.41 | 58.16 | 34.55 | 50.83 | 71.04 | 82.68 | 24.41 | 17.21 |
| TFNet | 79.57 | 71.33 | 47.93 | 59.73 | 38.54 | 50.01 | 70.71 | 81.38 | 18.20 | 16.96 |
| MFFnet (our network) | 81.29 | 73.59 | 50.64 | 61.23 | 34.34 | 49.04 | 73.26 | 82.82 | 24.96 | 28.84 |
| Model | MCANet | ESANet | RedNet | TFNet | MFFnet (Our Network) |
|---|---|---|---|---|---|
| GFLOPs | 88.69 | 11.52 | 23.30 | 30.90 | 22.95 |
| Params/M | 72.03 | 54.41 | 81.94 | 23.65 | 21.27 |
| ResNet | PidiNet | ASPP | iAFF | OA | Kappa | mIoU |
|---|---|---|---|---|---|---|
| ✔ | × | × | × | 77.52 | 68.72 | 46.29 |
| ✔ | ✔ | × | × | 80.46 | 72.47 | 47.93 |
| ✔ | ✔ | ✔ | × | 80.50 | 72.58 | 49.26 |
| ✔ | ✔ | ✔ | ✔ | 81.29 | 73.59 | 50.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhang, W.; Chen, W.; Chen, C.; Liang, Z. MFFnet: Multimodal Feature Fusion Network for Synthetic Aperture Radar and Optical Image Land Cover Classification. Remote Sens. 2024, 16, 2459. https://doi.org/10.3390/rs16132459
Wang Y, Zhang W, Chen W, Chen C, Liang Z. MFFnet: Multimodal Feature Fusion Network for Synthetic Aperture Radar and Optical Image Land Cover Classification. Remote Sensing. 2024; 16(13):2459. https://doi.org/10.3390/rs16132459
Chicago/Turabian StyleWang, Yangyang, Wengang Zhang, Weidong Chen, Chang Chen, and Zhenyu Liang. 2024. "MFFnet: Multimodal Feature Fusion Network for Synthetic Aperture Radar and Optical Image Land Cover Classification" Remote Sensing 16, no. 13: 2459. https://doi.org/10.3390/rs16132459
APA StyleWang, Y., Zhang, W., Chen, W., Chen, C., & Liang, Z. (2024). MFFnet: Multimodal Feature Fusion Network for Synthetic Aperture Radar and Optical Image Land Cover Classification. Remote Sensing, 16(13), 2459. https://doi.org/10.3390/rs16132459