



LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion


Abstract
1. Introduction
- (1)
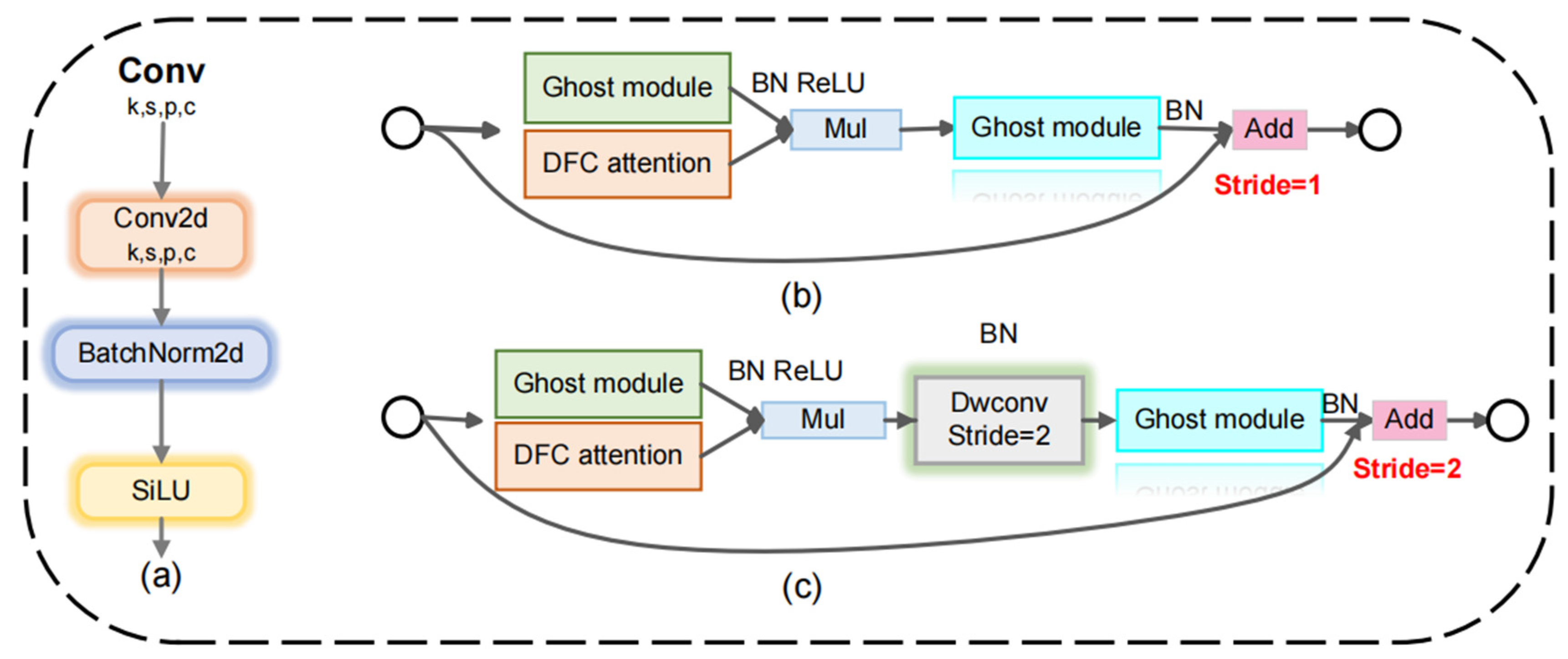
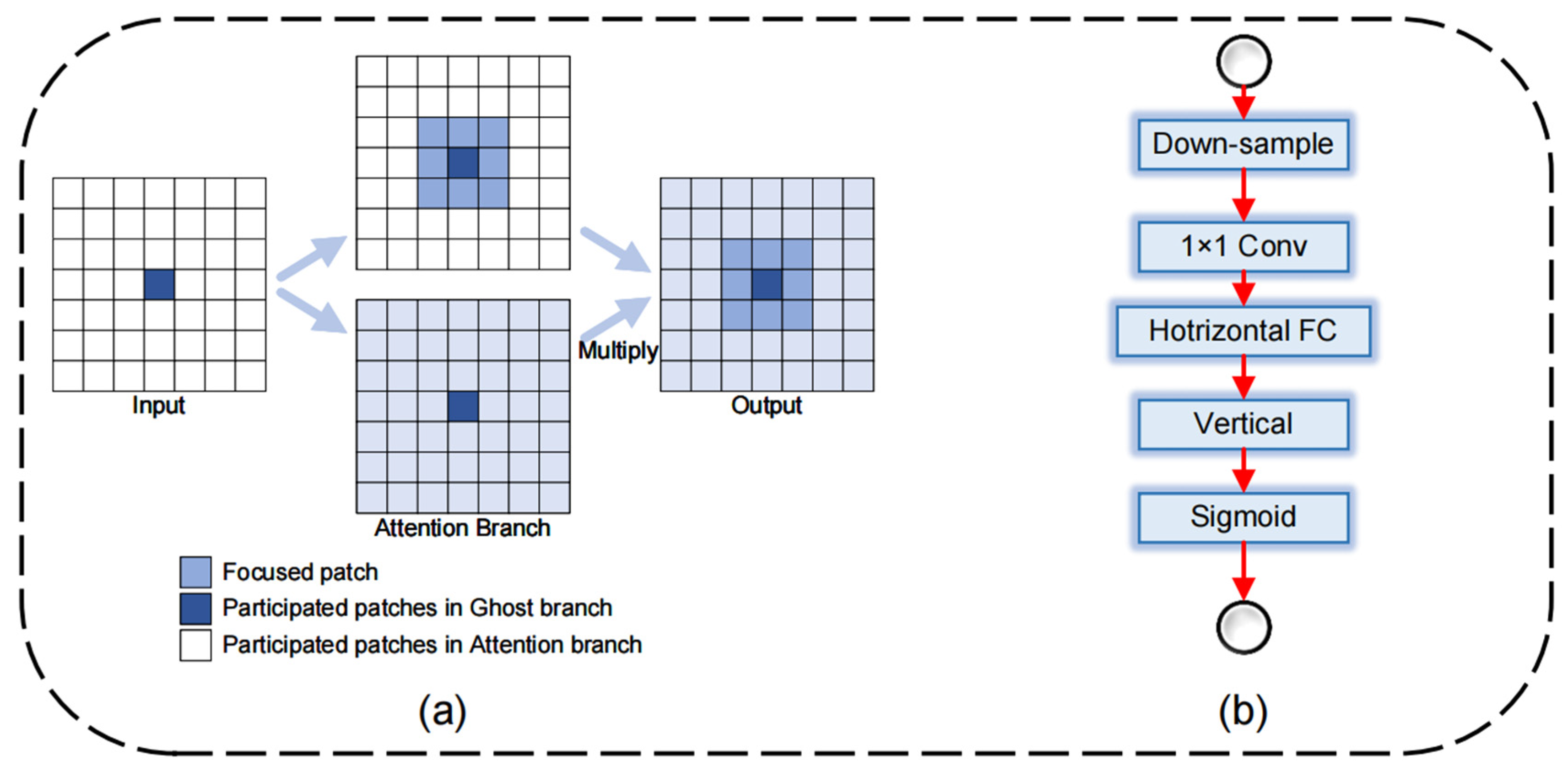
- Innovatively, the LUFFD-YOLO model adopts the GhostNetV2 structure to optimize the conventional convolutions of the YOLOv8n backbone layer, resulting in a more efficient and streamlined network design. This significantly reduces the model’s complexity and computational requirements.
- (2)
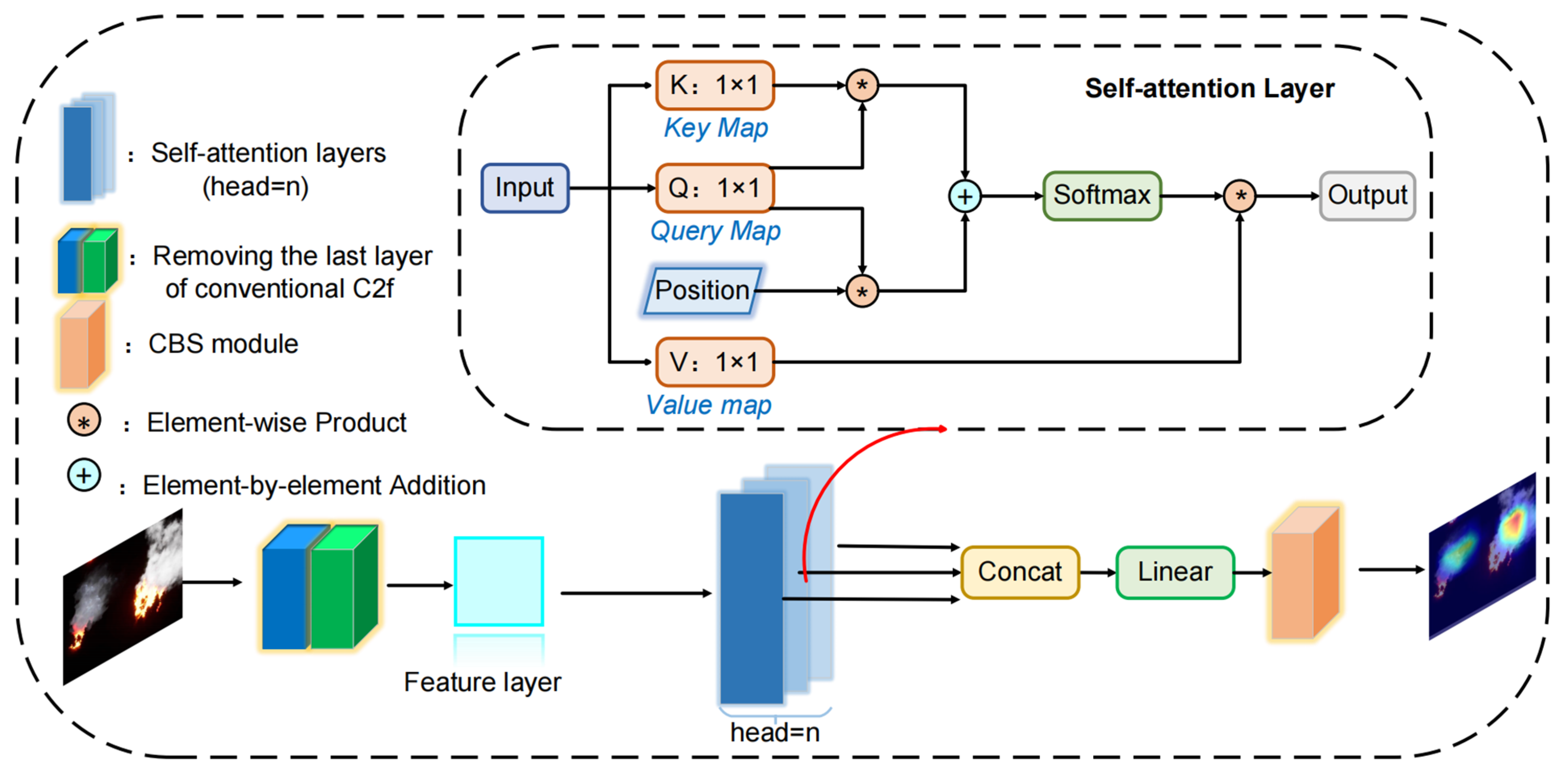
- This study proposes a plug-and-play enhanced small-object forest fire detection C2f (ESDC2f) module that utilizes the Multi-Head Self Attention (MHSA) mechanism to boost the detection capability for small objects and compensate for the loss caused by lightweight in LUFFD-YOLO model. It greatly enhances the capability to extract features from various subspaces of UAV images, hence increasing the accuracy of forest fire detection.
- (3)
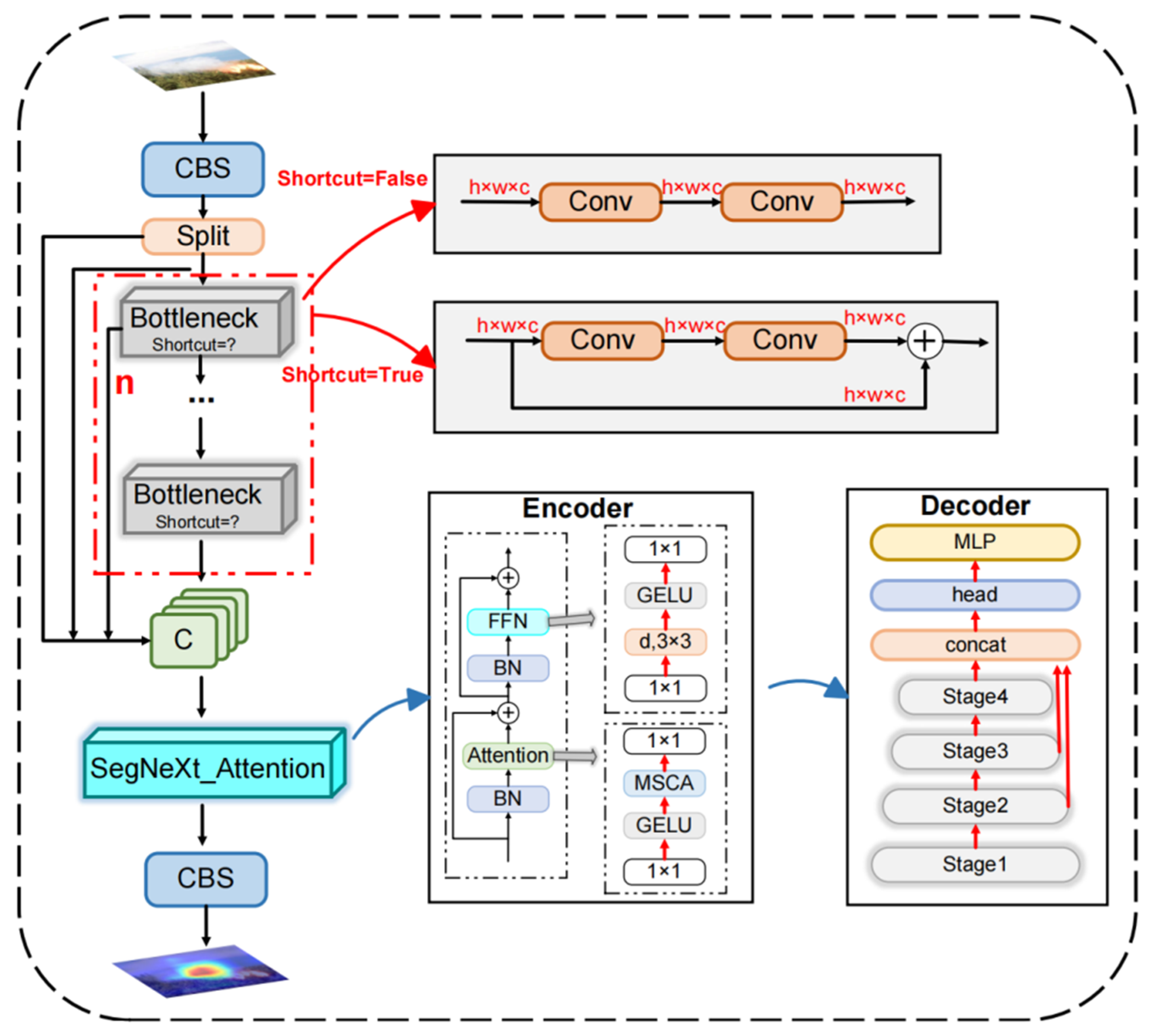
- A hierarchical feature-integrated C2f (HFIC2f) model, using the SegNeXt attention mechanism, has been proposed to effectively tackle the problem of low accuracy in detecting forest fire objects against complicated backgrounds.
2. Materials and Methods
2.1. Datasets
2.2. Methods
2.2.1. The YOLOv8 Network Architecture
2.2.2. The Proposed LUFFD-YOLO Network
- Lightweight optimization.
- Optimization of small forest fire detection using attention mechanisms.
- Optimization of forest fire feature extraction capability.
2.3. Experimental Setup and Accuracy Assessment
3. Results
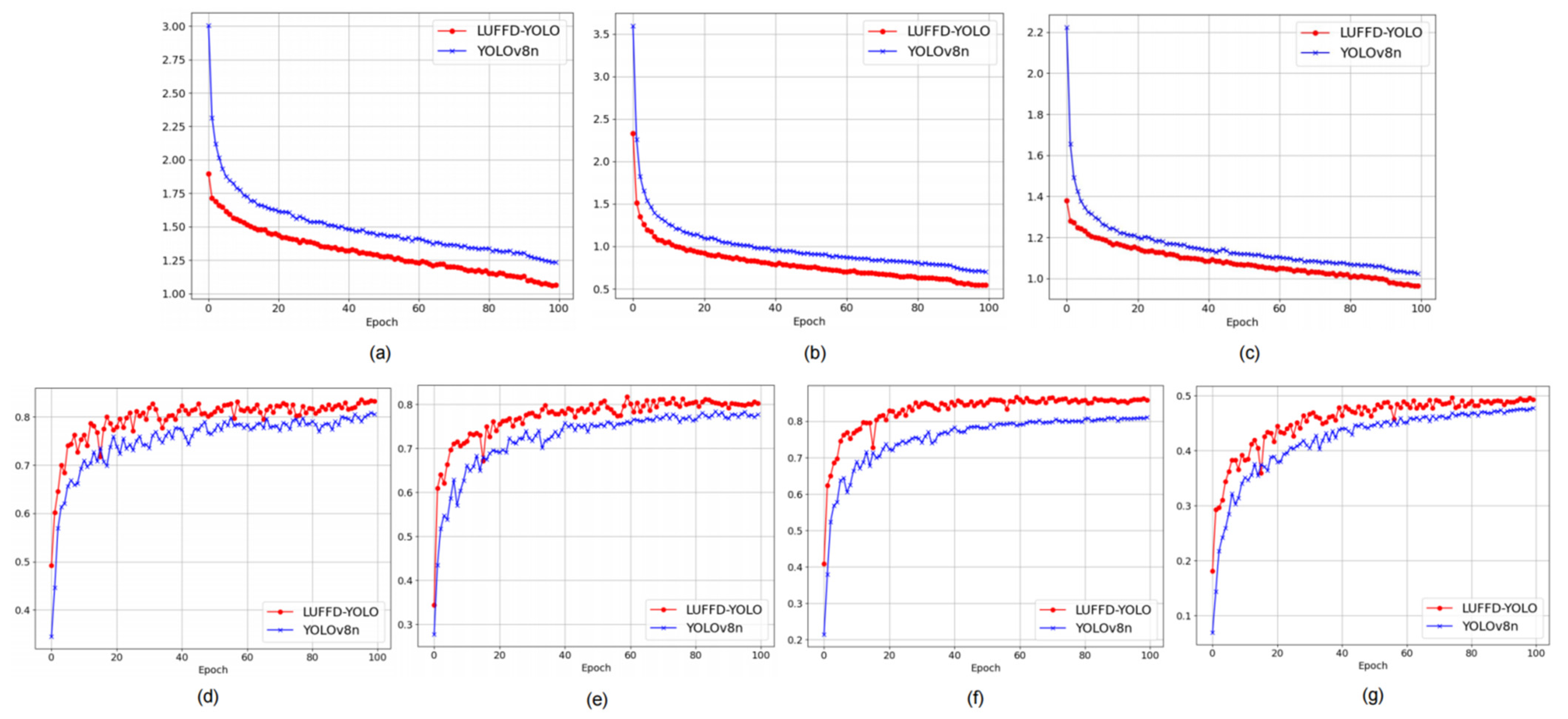
3.1. Comparison between YOLOv8n and LUFFD-YOLO
3.2. Ablation Experiment
3.3. Verification Experiment
4. Discussion
4.1. The Advantages of the Proposed LUFFD-YOLO Model
4.2. Comparative Experiments of Different Models
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Flannigan, M.D.; Stocks, B.J.; Wotton, B.M. Climate Change and Forest Fires. Sci. Total Environ. 2000, 262, 221–229. [Google Scholar] [CrossRef]
- Flannigan, M.D.; Amiro, B.D.; Logan, K.A.; Stocks, B.J.; Wotton, B.M. Forest Fires and Climate Change in the 21ST Century. Mitig. Adapt. Strat. Glob. Chang. 2006, 11, 847–859. [Google Scholar] [CrossRef]
- Stocks, B.J.; Mason, J.A.; Todd, J.B.; Bosch, E.M.; Wotton, B.M.; Amiro, B.D.; Flannigan, M.D.; Hirsch, K.G.; Logan, K.A.; Martell, D.L.; et al. Large Forest Fires in Canada, 1959–1997. J. Geophys. Res. 2002, 107, FFR 5-1–FFR 5-12. [Google Scholar] [CrossRef]
- Crist, M.R. Rethinking the Focus on Forest Fires in Federal Wildland Fire Management: Landscape Patterns and Trends of Non-Forest and Forest Burned Area. J. Environ. Manag. 2023, 327, 116718. [Google Scholar] [CrossRef] [PubMed]
- Grünig, M.; Seidl, R.; Senf, C. Increasing Aridity Causes Larger and More Severe Forest Fires across Europe. Glob. Chang. Biol. 2023, 29, 1648–1659. [Google Scholar] [CrossRef] [PubMed]
- Hillayová, M.K.; Holécy, J.; Korísteková, K.; Bakšová, M.; Ostrihoň, M.; Škvarenina, J. Ongoing Climatic Change Increases the Risk of Wildfires. Case Study: Carpathian Spruce Forests. J. Environ. Manag. 2023, 337, 117620. [Google Scholar] [CrossRef]
- Turco, M.; Abatzoglou, J.T.; Herrera, S.; Zhuang, Y.; Jerez, S.; Lucas, D.D.; AghaKouchak, A.; Cvijanovic, I. Anthropogenic Climate Change Impacts Exacerbate Summer Forest Fires in California. Proc. Natl. Acad. Sci. USA 2023, 120, e2213815120. [Google Scholar] [CrossRef]
- Howell, A.N.; Belmont, E.L.; McAllister, S.S.; Finney, M.A. An Investigation of Oxygen Availability in Spreading Fires. Fire Technol. 2023, 59, 2147–2176. [Google Scholar] [CrossRef]
- Menut, L.; Cholakian, A.; Siour, G.; Lapere, R.; Pennel, R.; Mailler, S.; Bessagnet, B. Impact of Landes Forest Fires on Air Quality in France during the 2022 Summer. Atmos. Chem. Phys. 2023, 23, 7281–7296. [Google Scholar] [CrossRef]
- Chen, Y.-J.; Lai, Y.-S.; Lin, Y.-H. BIM-Based Augmented Reality Inspection and Maintenance of Fire Safety Equipment. Autom. Constr. 2020, 110, 103041. [Google Scholar] [CrossRef]
- Sharma, A.; Singh, P.K.; Kumar, Y. An Integrated Fire Detection System Using IoT and Image Processing Technique for Smart Cities. Sustain. Cities Soc. 2020, 61, 102332. [Google Scholar] [CrossRef]
- Wooster, M.J.; Roberts, G.J.; Giglio, L.; Roy, D.P.; Freeborn, P.H.; Boschetti, L.; Justice, C.; Ichoku, C.; Schroeder, W.; Davies, D. Satellite Remote Sensing of Active Fires: History and Current Status, Applications and Future Requirements. Remote Sens. Environ. 2021, 267, 112694. [Google Scholar] [CrossRef]
- Hua, L.; Shao, G. The Progress of Operational Forest Fire Monitoring with Infrared Remote Sensing. J. For. Res. 2017, 28, 215–229. [Google Scholar] [CrossRef]
- Bessho, K.; Date, K.; Hayashi, M.; Ikeda, A.; Imai, T.; Inoue, H.; Kumagai, Y.; Miyakawa, T.; Murata, H.; Ohno, T. An Introduction to Himawari-8/9—Japan’s New-Generation Geostationary Meteorological Satellites. J. Meteorol. Soc. Jpn. Ser. II 2016, 94, 151–183. [Google Scholar] [CrossRef]
- Justice, C.O.; Giglio, L.; Korontzi, S.; Owens, J.; Morisette, J.T.; Roy, D.; Descloitres, J.; Alleaume, S.; Petitcolin, F.; Kaufman, Y. The MODIS Fire Products. Remote Sens. Environ. 2002, 83, 244–262. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A Review on Deep Learning in UAV Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Li, C.; Li, G.; Song, Y.; He, Q.; Tian, Z.; Xu, H.; Liu, X. Fast Forest Fire Detection and Segmentation Application for UAV-Assisted Mobile Edge Computing System. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Yang, X.; Hua, Z.; Zhang, L.; Fan, X.; Zhang, F.; Ye, Q.; Fu, L. Preferred Vector Machine for Forest Fire Detection. Pattern Recognit. 2023, 143, 109722. [Google Scholar] [CrossRef]
- Maeda, N.; Tonooka, H. Early Stage Forest Fire Detection from Himawari-8 AHI Images Using a Modified MOD14 Algorithm Combined with Machine Learning. Sensors 2022, 23, 210. [Google Scholar] [CrossRef]
- Liu, J.; Guan, R.; Li, Z.; Zhang, J.; Hu, Y.; Wang, X. Adaptive Multi-Feature Fusion Graph Convolutional Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 5483. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Li, X.; Tang, C. Pixel-Superpixel Contrastive Learning and Pseudo-Label Correction for Hyperspectral Image Clustering. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 6795–6799. [Google Scholar]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest Fire and Smoke Detection Using Deep Learning-Based Learning without Forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Liu, F.; Chen, R.; Zhang, J.; Xing, K.; Liu, H.; Qin, J. R2YOLOX: A Lightweight Refined Anchor-Free Rotated Detector for Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5632715. [Google Scholar] [CrossRef]
- Peng, G.; Yang, Z.; Wang, S.; Zhou, Y. AMFLW-YOLO: A Lightweight Network for Remote Sensing Image Detection Based on Attention Mechanism and Multiscale Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4600916. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Tu, W.; Wang, J.; Liu, Y.; Li, X.; Tang, C.; Feng, R. Contrastive Multi-View Subspace Clustering of Hyperspectral Images Based on Graph Convolutional Networks. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5510514. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Li, T.; Li, X.; Yang, J.; Chen, W. Classification of Heterogeneous Mining Areas Based on ResCapsNet and Gaofen-5 Imagery. Remote Sens. 2022, 14, 3216. [Google Scholar] [CrossRef]
- Xie, S.; Zhou, M.; Wang, C.; Huang, S. CSPPartial-YOLO: A Lightweight YOLO-Based Method for Typical Objects Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 388–399. [Google Scholar] [CrossRef]
- Lv, Q.; Quan, Y.; Sha, M.; Feng, W.; Xing, M. Deep Neural Network-Based Interrupted Sampling Deceptive Jamming Countermeasure Method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9073–9085. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Wang, W.-Q. A Lightweight Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4006105. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Z.; Zhou, S.; Qi, W.; Wu, X.; Zhang, T.; Han, L. LS-YOLO: A Novel Model for Detecting Multi-Scale Landslides with Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4952–4965. [Google Scholar] [CrossRef]
- Xu, Q.; Li, Y.; Shi, Z. LMO-YOLO: A Ship Detection Model for Low-Resolution Optical Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4117–4131. [Google Scholar] [CrossRef]
- Zhao, Z.; Du, J.; Li, C.; Fang, X.; Xiao, Y.; Tang, J. Dense Tiny Object Detection: A Scene Context Guided Approach and a Unified Benchmark. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606913. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, M.; Ding, Y.; Bu, X. MS-FRCNN: A Multi-Scale Faster RCNN Model for Small Target Forest Fire Detection. Forests 2023, 14, 616. [Google Scholar] [CrossRef]
- Pan, J.; Ou, X.; Xu, L. A Collaborative Region Detection and Grading Framework for Forest Fire Smoke Using Weakly Supervised Fine Segmentation and Lightweight Faster-RCNN. Forests 2021, 12, 768. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Luo, M.; Xu, L.; Yang, Y.; Cao, M.; Yang, J. Laboratory Flame Smoke Detection Based on an Improved YOLOX Algorithm. Appl. Sci. 2022, 12, 12876. [Google Scholar] [CrossRef]
- Xue, Q.; Lin, H.; Wang, F. FCDM: An Improved Forest Fire Classification and Detection Model Based on YOLOv5. Forests 2022, 13, 2129. [Google Scholar] [CrossRef]
- Chen, G.; Cheng, R.; Lin, X.; Jiao, W.; Bai, D.; Lin, H. LMDFS: A Lightweight Model for Detecting Forest Fire Smoke in UAV Images Based on YOLOv7. Remote Sens. 2023, 15, 3790. [Google Scholar] [CrossRef]
- Wang, G.; Li, H.; Li, P.; Lang, X.; Feng, Y.; Ding, Z.; Xie, S. M4SFWD: A Multi-Faceted Synthetic Dataset for Remote Sensing Forest Wildfires Detection. Expert. Syst. Appl. 2024, 248, 123489. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial Imagery Pile Burn Detection Using Deep Learning: The FLAME Dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Wang, Z.; Hua, Z.; Wen, Y.; Zhang, S.; Xu, X.; Song, H. E-YOLO: Recognition of Estrus Cow Based on Improved YOLOv8n Model. Expert. Syst. Appl. 2024, 238, 122212. [Google Scholar] [CrossRef]
- Yi, H.; Liu, B.; Zhao, B.; Liu, E. Small Object Detection Algorithm Based on Improved YOLOv8 for Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1734–1747. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 850–855. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance Cheap Operation with Long-Range Attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tan, H.; Liu, X.; Yin, B.; Li, X. MHSA-Net: Multihead Self-Attention Network for Occluded Person Re-Identification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8210–8224. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S.-M. Segnext: Rethinking Convolutional Attention Design for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO V3-Tiny: Object Detection and Recognition Using One Stage Improved Model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 687–694. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Wong, C.; Yifu, Z.; Montes, D. Ultralytics/Yolov5: V6. 2-Yolov5 Classification Models, Apple M1, Reproducibility, Clearml and Deci. Ai Integrations. Zenodo 2022. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475.
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | F1 (%) | mAP (%) | Parameters (M) |
|---|---|---|---|---|---|
| YOLOv8n | 77.6 | 75.6 | 76.6 | 82.1 | 3.0 |
| LUFFD-YOLO | 80.9 | 81.1 | 81.0 | 86.3 | 2.6 |
| Name | Models | Precision (%) | Recall (%) | F1 (%) | mAP (%) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv8n | YOLOv8n (baseline) | 77.6 | 75.6 | 76.6 | 82.1 | 8.1 |
| Methods (1) | YOLOv8n+GN | 75.8 | 74.2 | 75.0 | 80.3 | 6.9 |
| Methods (2) | YOLOv8n+GN+ESDC2f | 78.8 | 79.1 | 78.9 | 84.5 | 7.0 |
| Methods (3) (ours) | YOLOv8n+GN+ESDC2+HFIC2f | 80.9 | 81.1 | 81.0 | 86.3 | 7.0 |
| Dataset | Model | Precision (%) | Recall (%) | mAP (%) | Parameters (M) |
|---|---|---|---|---|---|
| FLAME | YOLOv3-tiny | 83.9 | 78.0 | 85.4 | 8.1 |
| YOLOv5 | 83.2 | 80.4 | 85.6 | 47.1 | |
| YOLOv7-tiny | 74.5 | 72.8 | 70.0 | 6.0 | |
| YOLOv8n | 84.8 | 82.7 | 87.4 | 3.0 | |
| LUFFD-YOLO | 87.1 | 87.5 | 90.1 | 2.6 | |
| SURSFF | YOLOv3-tiny | 83.9 | 81.4 | 86.4 | 8.1 |
| YOLOv5 | 87.2 | 84.9 | 88.9 | 47.1 | |
| YOLOv7-tiny | 85.2 | 82.9 | 87.1 | 6.0 | |
| YOLOv8n | 86.4 | 83.5 | 87.8 | 3.0 | |
| LUFFD-YOLO | 88.9 | 86.7 | 90.9 | 2.6 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP (%) | Parameters (M) |
|---|---|---|---|---|---|
| Faster-RCNN | 69.4 | 68.3 | 68.9 | 76.8 | 120.4 |
| SSD | 70.6 | 70.5 | 70.6 | 77.5 | 560.6 |
| YOLOv3-tiny | 72.7 | 71.4 | 72.0 | 78.1 | 8.1 |
| YOLOv5 | 73.1 | 72.7 | 72.9 | 79.3 | 47.1 |
| YOLOv6s | 74.2 | 72.9 | 73.5 | 79.9 | 17.2 |
| YOLOv7-tiny | 75.4 | 73.5 | 74.4 | 80.4 | 6.0 |
| LUFFD-YOLO | 80.9 | 81.1 | 81.0 | 88.3 | 2.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Duan, B.; Guan, R.; Yang, G.; Zhen, Z. LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion. Remote Sens. 2024, 16, 2177. https://doi.org/10.3390/rs16122177
Han Y, Duan B, Guan R, Yang G, Zhen Z. LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion. Remote Sensing. 2024; 16(12):2177. https://doi.org/10.3390/rs16122177
Chicago/Turabian StyleHan, Yuhang, Bingchen Duan, Renxiang Guan, Guang Yang, and Zhen Zhen. 2024. "LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion" Remote Sensing 16, no. 12: 2177. https://doi.org/10.3390/rs16122177
APA StyleHan, Y., Duan, B., Guan, R., Yang, G., & Zhen, Z. (2024). LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion. Remote Sensing, 16(12), 2177. https://doi.org/10.3390/rs16122177