1. Introduction
With the swift progress of remote sensing technologies, many remote sensing satellites, including QuickBird, the WorldView (WV) series, and the GaoFen (GF) series, have been deployed, contributing to the generation of extensive image data. The acquired data usually comprise panchromatic (PAN) images and multispectral (MS) images. The PAN image possesses high spatial resolution (HR) but only one spectral channel. Exploiting the superior spatial resolution of PAN images proves beneficial for detecting small-scale targets like buildings and vehicles. On the contrary, MS images usually comprise four or eight spectral channels, indicating superior spectral resolution. Nevertheless, they exhibit only a quarter of the spatial resolution compared to PAN images. This disparity allows low spatial resolution (LR) MS images to excel in material identification and classification, capturing diverse spectral responses from ground objects, such as vegetation, water bodies, and soil components.
Considering downstream recognition and classification tasks, relying solely on either PAN or MS modality as the source data is inefficient because they do not possess both high spatial and spectral resolution concurrently. To enhance the precision of downstream tasks, high-resolution MS (HRMS) images are essential. In addition to improving the accuracy of downstream tasks, HRMS images also reduce the data redundancy and alleviate storage pressure. However, existing sensors are constrained by limitations (e.g., data transmission bandwidth, cost, and signal-to-noise ratio, etc.), preventing them from acquiring high spatial and spectral resolution images simultaneously. Consequently, it is imperative to design fusion algorithms to exploit the complementarity between spectral and spatial information fully. This process is commonly referred to as pansharpening.
Numerous efforts have been dedicated to the advancement of pansharpening algorithms in recent decades. In the past two decades, many pansharpening algorithms have been proposed, consistently delivering promising results. These approaches can be broadly divided into four groups based on their methods: (1) component substitution (CS); (2) multiresolution analysis (MRA); (3) variational optimization (VO); and (4) convolutional neural networks (CNN).
Methods based on the CS technique assume that the spatial and spectral components in MS images are independent. Consequently, they can be projected into a certain transformation domain to extract distinct components separately, the spatial components of which are subsequently substituted with the matching PAN image, which comprises abundant spatial details. The ultimate fused HRMS image is produced by the inverse transformation. There are several representative transformations, such as Gram–Schmidt [
1], intensity–hue–saturation (IHS) [
2], and principal component analysis (PCA) [
3]. The utilization of the direct substitution strategy enhances the effectiveness of fusion results, especially concerning spatial information. Nevertheless, given the challenge of complete separation between spatial and spectral information in MS images, these methods often lack sufficient spectral fidelity.
The MRA-based method enhances spectral fidelity as an advancement over CS-based approaches by resolving spectral distortion within the multi-resolution transform domain. Under the assumption that details absent in the LRMS image regarding spatial resolution can be inferred from the PAN image, efficient tools like MRA are utilized for multiresolution decomposition on the LRMS image. This process replaces the extracted spatial components with the high frequencies of the PAN image. Different MRA instruments provide researchers with various options to properly capture the spatial information in PAN and LRMS images. For instance, to model the spatial details, techniques like Laplacian pyramid [
4], Wavelet [
5], and Contourlet [
6] have been employed. While MRA-based approaches excel in preserving spectral consistency, they consistently struggle to maintain the spatial resolution of MS images.
By developing models rooted in the physical relationship between MS and PAN images, VO-based methods strike a commendable balance between spatial and spectral quality. Drawing from this concept, we can reframe the pansharpening task as an image restoration endeavor. The energy function for this image restoration task is constructed using degradation models. Optimizing this energy function yields the fused image. However, VO-based methods necessitate iterative optimization algorithms, thereby incurring substantial computational complexity. Additionally, these methods require hand-crafted design of precise priors, further constraining the advancement of VO-based techniques.
In recent times, CNN-based pansharpening methods have gained significant popularity owing to the remarkable capability of CNN to learn non-linear relationships. These methods commonly employ an end-to-end paradigm, wherein LRMS and PAN images are utilized as inputs to generate the fused HRMS images. Representative methods include PNN [
7], PanNet [
8], MSDCNN [
9], DMDNet [
10], MUCNN [
11], and LACNet [
12], etc. CNN-based methods have greatly improved the efficiency of pansharpening tasks, and their well-designed network structures have improved the effect of HRMS image reconstruction. However, the architecture of these models is typically constructed by stacking or connecting various network modules, rendering them as black boxes with limited domain knowledge guidance. To address these limitations, methods based on deep unrolling networks that unroll the optimization of VO-based methods into networks have emerged. Representative methods include PanCSC [
13], MDCUN [
14], GPPNN [
15], VO + Net [
16], DISPNet [
17], AUP [
18], and VP-Net [
19]. However, most of these methods rely solely on implicit or explicit priors of HRMS. Using implicit regularization alone may result in less stable results, while relying solely on explicit regularization might underutilize the available data information.
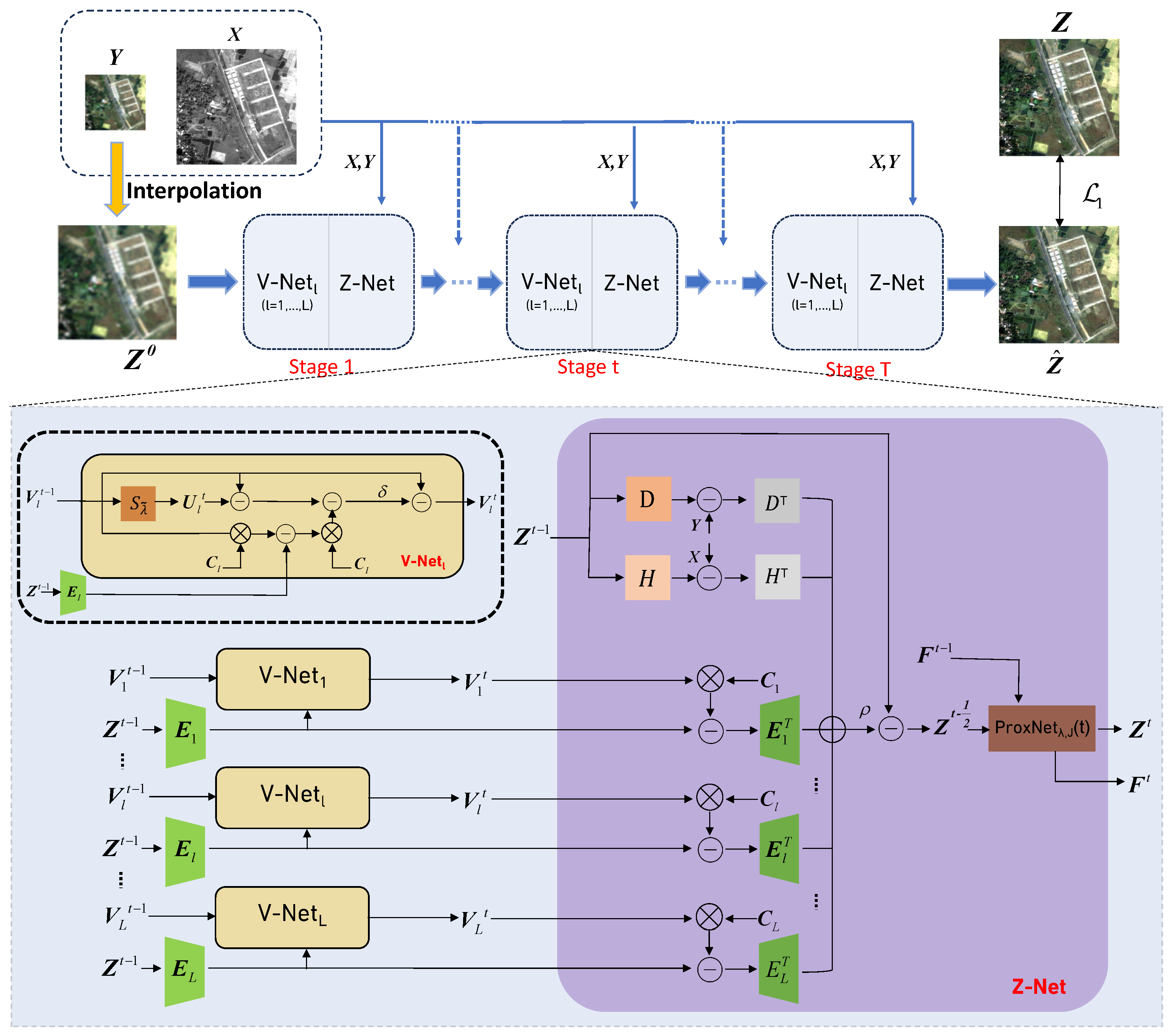
In this paper, we present a novel pansharpening model that integrates two complementary priors. The first is an implicit prior operating within the image domain, while the second is a semi-implicit prior realized by projecting the latent HRMS image into a multi-scale implicit space. The mapping of the second prior facilitates the application of convolutional sparse encoding (CSC), thereby yielding a more refined and detailed sparse representation of the image. Then, we unroll the optimization algorithms into a neural network, termed a DPDU-Net, to iteratively reconstruct the HRMS image. Specifically, this paper makes the following key contributions:
We incorporate an implicit prior with a semi-implicit prior to fully explore the domain knowledge of the HRMS image. These two types of prior information complement each other and greatly enhance the fusion results.
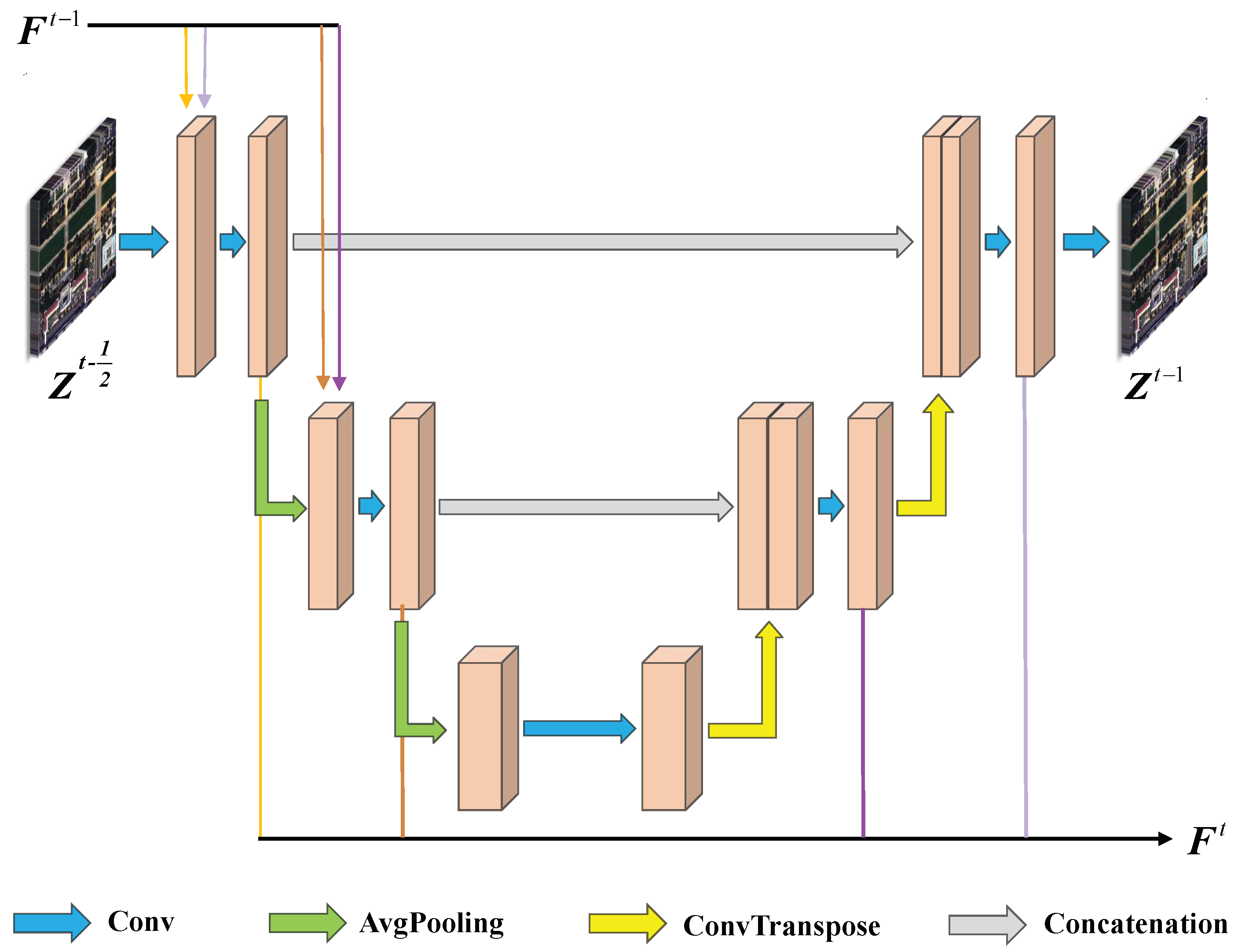
We enforce the sparsity of the HRMS image in a certain multi-scale implicit space rather than the image domain; thereby, the feature map can obtain better sparse representation ability. The CSC is applied to characterize the sparsity.
We prove the superiority of the proposed DPDU-Net over state-of-the-art (SOTA) methods via various experiments on GF2 and WV3 datasets at reduced resolution and full resolution.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}