Abstract
In airport ground-traffic surveillance systems, the detection of an aircraft and its head (AIH) is an important task in aircraft trajectory judgment. However, accurately detecting an AIH in high-resolution optical remote sensing images is a challenging task due to the difficulty in effectively modeling the features of aircraft objects, such as changes in appearance, large-scale differences, complex compositions, and cluttered background. In this paper, we propose an end-to-end rotated aircraft and aircraft head detector (RAIH-Det) based on ConvNeXt-T (Tiny) and cyclical local loss. Firstly, a new U-shaped network based on ConvNeXt-T with the same performance as the Local Vision Transformer (e.g., Swin Transformer) is presented to assess the relationships among aircraft in the spatial domain. Then, in order to enhance the sharing of more mutual information, the extended BBAVectors with six vectors captures the oriented bounding box (OBB) of the aircraft in any direction, which can assist in head keypoint detection by exploiting the relationship between the local and overall structural information of aircraft. Simultaneously, variant cyclical focal loss is adopted to regress the heatmap location of keypoints on the aircraft head to focus on more reliable samples. Furthermore, to perform a study on AIH detection and simplify aircraft head detection, the OBBs of the “plane” category in the DOTA-v1.5 dataset and the corresponding head keypoints annotated by our volunteers were integrated into a new dataset called DOTA-Plane. Compared with other state-of-the-art rotated object and keypoint detectors, RAIH-Det, as evaluated on DOTA-Plane, offered superior performance.
1. Introduction
In recent years, the detection of aircraft in optical remote sensing images has become a significant task in various civilian and military applications [1,2,3]. The distribution of an airport is shown in Figure 1. Accurately predicting the orientation (or the head) of the aircraft, besides detecting the position of the aircraft, is an essential step in aircraft trajectory judgment in the airport ground-traffic monitoring system [4]. However, aircraft detection and aircraft head detection remain independent tasks. In the case of aircraft head detection in an image, first, the aircraft must be accurately detected; then, its head can be detected. These complicated steps increase the requirements of training samples to train deep learning models and reduce computational efficiency. Therefore, we consider merging aircraft detection and head detection into a unified network for end-to-end training in this paper.

Figure 1.
Distribution of an airport in an optical remote sensing image. The orientation of the aircraft head is helpful to judge aircraft movement states (taxiing and stop) and aircraft flight states (takeoff and landing) with the airport ground-traffic monitoring system.
With the rapid development of remote sensing systems, various high-resolution (HR) optical remote sensing images (e.g., Worldview, Quickbird, GeoEye, and Chinese GF 1–14) are being acquired daily to obtain rich and detailed structures of the Earth’s surface [5]. So far, these images have been annotated for object detection by professional teams such as UCAS-AOD [6], RSOD-Dataset [7], DOTA [8], and NWPU VHR-10 [9]. DOTA provides two types of annotations: horizontal bounding boxes (HBBs) and oriented bounding boxes (OBBs). Compared with the former, the width and height of the latter directly reflect the relative size of the target. Recently, deep learning-based algorithms have emerged as an effective strategy for object detection research, such as the well-known YOLO series [10,11,12], single-shot multibox detector (SSD) [13], RetinaNet [14], CornerNet [15], CenterNet [16], IR R-CNN [17], rotation-sensitive regression for oriented scene text detection (RRD) [18], ROI Transformer [19], box boundary-aware vectors (BBAVectors) [20], and multiknowledge learning module (MKLM) [21], which have significantly improved detection accuracy. In nature scenes, most existing target head detection methods also directly treat head detection as a specific form of object detection. However, there is very little theory and research on target head detection in optical remote sensing images, with only a few studies on different scene tasks [4,22,23]. For example, to perform aircraft head detection, Jia et al. [4] clipped the recognized aircraft and pre-trained a head prediction module using a classification network. FGSD provides a new annotation for ship head detection [22]. Inspired by this, we annotated a new dataset for aircraft head detection.
The detection of an aircraft and its head (AIH) is a complex multitasking problem in the computer vision community, involving three main tasks: localization, classification, and head keypoint detection. Just as a human discovers an aircraft, an object detector must show where the aircraft is located, whether it is an aircraft, and where its head is pointing. This is simple for humans, but incredibly troubling for neural networks. Currently, the following several obstacles limit the ability of AIH detection tasks in HR remote sensing images: (i) These images, acquired with long-distance and wide-angle remote sensing systems, contain aircraft with significant differences. (ii) Differently from object detection in natural scenes, targets in an optical remote sensing image exist in different orientations due to the special top-down imaging perspective [24]. (iii) Many objects of interest in large-scale remote sensing images can be inevitably surrounded by complex compositions and cluttered backgrounds, which can seriously interfere with detecting the object of interest. (iv) Aircraft head detection is a challenging because the aircraft head occupies only a few pixels in a remote sensing image. Therefore, effective feature representation is essential to making AIH detection more accurate.
Since object detection is usually performed on feature space, effective feature representation is of great significance to constructing a high-performance object detection system. For this reason, various feature representation methods have been built to effectively distinguish among different types of interest objects in complex and irrelevant scenes. In general, region proposal network (RPN) [25] and feature pyramid network (FPN) [26] are incorporated to extract multiscale strong and weak semantic features. However, the dense candidate boxes generated with these methods are most often only a few boxes containing objects. As a result, background samples dominate the training process and degrade the model. In CornerNet [15] and CenterNet [16], fewer bounding boxes are obtained by estimating a keypoint-based detection pipeline, rather than defining dense candidate boxes. Rotation-equivariant detector (ReDet) [27] incorporates rotation-equivariant features, which can obtain the orientation and result with a huge reduction in model size. A recent method, box boundary-aware vectors (BBAVectors) [20], extends the keypoint-based CenterNet to rotated object detection and can capture the four vectors with mutual information of OBBs in the Cartesian coordinate system. Objects in an image are usually not independent; instead, they emerge in some available spatial relationship. Therefore, IR R-CNN [17] and HK R-CNN [28] establish intrinsic semantic and spatial location relationships among objects. More recently, Vision Transformer (ViT), based on multi-head self-attention mechanisms, can also effectively model the interaction among various spatial locations. ConvNeXt [29] can achieve the same level of scalability as Swin Transformer. Inspired by previous studies, we aim to achieve an end-to-end AIH detector by availing ourselves of the respective advantages of ConvNeXt, BBAVectors, and deep supervision techniques.
In this paper, we present an end-to-end trainable rotated aircraft and aircraft head detector (RAIH-Det) based on ConvNeXt-T and the variant cyclical focal loss (CFL). To facilitate AIH detection and aircraft head detection, we integrated the OBBs from the “plane” category of the DOTA-v1.5 dataset with our annotated aircraft head keypoints into a new dataset called DOTA-Plane. Then, we performed an evaluation, an ablation study and a comparison on the DOTA-Plane dataset. The experiments showed that the proposed RAIH-Det obtained superior performance on the DOTA-Plane dataset. Moreover, to show the universality of the proposed RAIH-Det, we detected arbitrarily orientated ships on the widely used HRSC2016 dataset. The main contributions of this work are four-fold:
- 1.
- We propose the novel RAIH-Det, which integrates two independent tasks into a unified network: aircraft detection and aircraft head detection. RAIH-Det fully uses the spatial and context relationships to identify aircraft of various scales, orientations, shapes, and spatial distributions.
- 2.
- We incorporated ConvNeXt-T with the same performance as the Local Vision Transformer (Swin Transformer) into a new U-shaped architecture to obtain an output feature map more distinguishable in the spatial domain. Instead of BBAVectors with the original four vectors, six vectors containing the head keypoint mutual information were adopted to generate the OBBs.
- 3.
- We used a variant CFL to focus on more reliable training samples, thus overcoming the imbalance issue caused by the fact that the aircraft head occupies a small number of pixels in optical remote sensing images. Meanwhile, the added head keypoint mutual information can further assist in head keypoint detection by exploring the relationship between head keypoints and the OBBs.
- 4.
- We present a new DOTA-Plane dataset consisting of OBBs of the “plane” category and aircraft head keypoints that we annotated in the DOTA-v1.5 dataset.
The remainder of this paper is organized as follows: Section 2 provides a brief review of related work. Section 3 provides an overview of the proposed method, followed by a detailed description of the framework. Section 4 describes the AIH detection dataset and the information contained therein. Section 5 outlines the comprehensive experimental results. Finally, the presentation of the proposed RAIH-Det is concluded in Section 6.
2. Related Works
2.1. Vision Backbones
Convolutional neural networks (CNNs) have become dominant in computer vision modeling. Starting with AlexNet [30] and its revolutionary performance in ImageNet image classification tasks, CNN architectures (e.g., VGGNet [31], ResNet [32], EfficientNet [33], and ConvNeXt [29]) have evolved to become increasingly powerful with greater scale, wider connections, and more complicated forms of convolution [34]. The progress of network architectures has caused performance improvements that have greatly promoted the whole field, since CNNs serve as the backbone network in various vision tasks. Recently, ViT pioneering work directly adopted transformers on a sequence of non-overlapping fixed-size image patches for image classification tasks. Compared with CNNs, ViT successfully achieves reconciliation between running speed and detection accuracy in image classification. However, vanilla ViT encountered some difficulties when employed in common computer vision tasks such as change detection, object detection, scene understanding, and semantic segmentation. Therefore, to expand the applicability of transformers as generic vision backbones [35], Swin Transformer [35] was reintroduced by using the shifted window-based block with an independent self-attention mechanism separately for each partition. The Neighborhood Attention Transformer (NAT) adopts a simple and flexible multi-head attention mechanism to localize the receptive field of each query to its nearest neighboring pixels. More recently, ConvNeXt [29] was proposed as a new CNN backbone influenced by Swin Transformer. However, it was not attention-based and managed to outperform Swin Transformer with respect to several benchmarks.
2.2. Rotated Object and Keypoint Detectors
In natural scene images, HBBs are generally adopted to describe the location of objects. However, all objects of interest in optical remote sensing images are located with different orientations due to the unique perspective of special top-down photography. Therefore, various superior rotated object detectors have emerged to more accurately capture targets using OBBs (see Table 1). Current rotated object detectors are generally extensions of horizontal object detectors. For example, the rotational region CNN (R2CNN) based on region proposal network (RPN) and ROI-pooled features [36] was proposed to produce rotational and horizontal bounding boxes. Simultaneously, rotation region proposal networks (RRPNs) [37] and rotated region proposal networks (RPNs) [38] have been designed to obtain inclined proposals with orientation angle information. ROI Transformer [19] adopts spatial transformations in ROIs to maintain rotation invariance. ICN [39] incorporates image cascades and feature pyramid networks with multi-size convolution kernels to extract multiscale strong and weak semantic feature maps. As a result, satisfactory performance was obtained on the DOTA dataset. All these approaches involve generating a lot of anchor boxes. Meanwhile, the position offsets between the target bounding boxes and the anchor boxes are regressed to refine the position of the prediction box. Here, the anchor-based strategy is affected by the imbalance problem between negative and positive anchor boxes, which leads to slow training speed and suboptimal detection performance. The critical feature capturing network (CFC-Net) [40] is a one-stage detector with only one anchor corresponding to each position of the feature map, which is equivalent to anchor-free methods with higher inference speed.

Table 1.
The summary table of rotated object and keypoint detectors.
Compared with traditional keypoint detectors [42,43,44], deep learning methods are more general and can be categorized into the following: (i) the keypoint position is directly regressed, and (ii) heatmap regression followed by post-processing is adopted to search for the keypoint with maximal heat value, which is also adopted in this study. Regarding approaches based on heatmap regression, Tompson et al. [45] proposed a multi-resolution framework that generates heatmaps representing the pixel-by-pixel likelihood of keypoints. CornerNet [15] uses heatmaps to capture the top-left and bottom-right corner points of HBBs. Corner points are grouped by comparing the embedding distance of the points for each object. Duan’s CenterNet [46] detects a pair of corners and the center point of a bounding box. ExtremeNet [47] was presented as able to locate the extreme and center points of the boxes. Both approaches adopt the center information and geometry of box points to group and match points. However, these works relied on post-grouping processing, which is a computationally expensive and time-consuming operation. Without the post-grouping process, Zhou’s CenterNet [16] directly regresses the bounding box parameters at the center point. To further improve the performance of keypoint-based detectors, CentripetalNet [41] adopts centripetal shift to pair corner keypoints from the same target. A recent method, BBAVectors [20], extends the keypoint-based CenterNet to rotated object detection in a single stage without anchor boxes. BBAVectors specializes in improving the performance of center keypoint detection and OBB regression. Our AH detection is a complex multitasking problem consisting of three main tasks: localization, classification, and head keypoint detection. Therefore, we extended BBAVectors to aircraft and aircraft head detection tasks.
3. Methods
The overall architecture of the proposed detector (RAIH-Det) is shown in Figure 2. Our model begins with a U-shaped architecture to obtain the feature map for each input image and then feeds them to the detection module to predict the parameters of the OBB and the head keypoint of the aircraft. Finally, the formula of the loss function is defined.
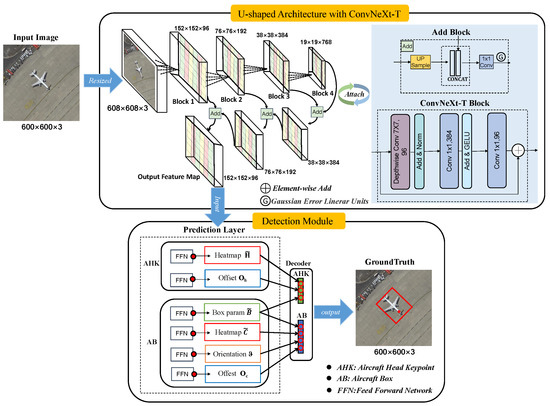
Figure 2.
Flowchart of the proposed detector of rotated aircraft and its head (RAIH-Det) based on ConvNeXt-T and variant CFL. Each input image of size is resized to the size of before being input to RAIH-Det. A new U-shaped architecture based on ConvNeXt-T was built to generate the multistage features with the interaction among different spatial locations. Its output feature map is fed to two submodules (detection module), one for the aircraft box prediction and one for the aircraft head keypoint prediction. The network design is intentionally simple, which enables this work to focus on the end-to-end detection of two tasks while running at faster speed.
The proposed RAIH-Det has three main components: (1) a U-shaped architecture based on ConvNeXt-T, which merges the multistage features with the interaction among different spatial locations; (2) a box parameter prediction layer with six vectors (extended BBAVectors), which groups the head keypoint mutual information into semantic features (visual attributes) to generate the OBB; (3) a head keypoint detection layer, which applies a likelihood heatmap to obtain correspondence for the location of each keypoint and utilizes variant CFL to focus on more reliable training samples. The inference detail of the proposed RAIH-Det for aircraft and aircraft head detection is summarized in Algorithm 1.
| Algorithm 1: RAIH-Det: An End-to-End Rotated Aircraft and Aircraft Head Detector Based on ConvNeXt and Cyclical Focal Loss in Optical Remote Sensing Images. |
Input: The input images . Output: Aircraft head keypoints and rotated bounding box with score. 1 ⊳ U−shaped architecture with ConvNeXt−T. 2 (i) The contracting path (left side): 3 Output basic blocks 1−5 in ConvNeXt−T; 4 The feature maps . 5 (ii) The contracting path (right side): 6 Obtain the feature map . 7 ⊳ Detection Module. 8 Aircraft Head keypoint prediction: 10 Offsets ; Compute the difference between quantified floating head keypoints and integer head keypoint by Equation (9). 11 Aircraft box prediction: 12 Box parameters ; Compute to optimize the box parameters with six vectors at the center point by Equation (3). 13 Heatmaps of center keypoints ; Compute to learn the heatmap of center keypoints. 14 Offsets ; Compute the difference between quantified floating center keypoints and integer center keypoint. 15 The orientation maps ; Compute the difference between predicted and ground-truth orientation classes by Equation (11) |
3.1. U-Shaped Architecture Based on ConvNeXt-T
When the complexity of scene visibility is formed by multiple aspects, including multiscale shape, quantity, and position of aircraft and other targets in an airport, AIH detection can exploit the global and local relationships among the targets to enhance the detection performance [48]. The success of ViT (or Swin Transformer) suggests that multi-head self-attention mechanisms can model the interaction among different spatial locations. The recently developed ConvNeXt [29] can achieve the same performance level (as Swin Transformer) and improve the running speed. In response to such observations, we built a new U-shaped architecture to learn multiscale features for detecting objects with specific scales.
The proposed U-shaped architecture is also composed of a contracting path (left side) and an expansive path (right side). The contracting path adopts a new pre-trained ConvNeXt-T (Tiny) architecture consisting of a repeating block of depthwise convolutions (a “patchify” layer similar to Swin Transformer), one BatchNorm2d, two convolutions, and a Gaussian error linear unit (GELU) layer between the two convolutions. Aircraft at different airports present heterogeneity in shape and size. Therefore, the outputs of ConvNeXt-T basic blocks 1–5 are applied as a backbone. Given an image acquired with a remote sensing system, where H, W, and 3 denote the height, width, and channel number of the image, respectively, by down-sampling the ratio , corresponding to the input image at different layers , the feature maps with depths 96, 192, 384, and 768 are sequentially obtained. To halve the number of feature channels, each step of the expansive path adopts an “add” block that consists of linear up-sampling and convolution layers. The bilinear interpolation method is applied in the up-sampling layer. Additionally, each layer is followed by one InstanceNorm2d and a GELU layer and is concatenated with a feature map cropped from the corresponding contracting path. Finally, the output feature map can be obtained.
3.2. Detection Module
As described in Figure 2, the output feature map M is sent to the detection module, which consists of two submodules, aircraft box prediction and head keypoint prediction:
- Aircraft box prediction: box parameters , heatmaps of center keypoints , offsets , and orientation classes (see Section 3.3).
- Head keypoint prediction: head keypoint heatmaps and offsets .
Six prediction branches are computed by the feed-forward network (FFN) (i.e., n-layer perceptron with GELU activation function, hidden dimension, and linear projection layer).
(1) Box parameters with six vectors: Existing rotated object detectors often regress five parameters (coordinates of the center point, width, height, and rotated angle) and utilize smooth L1 loss as the loss function to represent the OBB of an object in any direction. However, such an approach has three fundamental problems in practice: (1) The loss discontinuities are induced by variations in angle. When the angle is close to its range limits, the loss value skips. The position of the reference rectangle slightly changes, but its angle significantly changes due to parameterization. (2) For each target, the width w and height h of its OBB change in the five-parameter rotating coordinate system and make the case more difficult. (3) Most approaches employ ln-norm loss to independently optimize the five parameters, but the five variables are actually correlated.
Hence, Wen et al. [49] introduced a rotation-sensitive detector (RSDet) based on an eight-parameter box. RSDet modulates the rotational loss to eliminate the inconsistent parameter regression and the loss discontinuity. A recent method, BBAVectors [20], can also represent the OBBs of objects in any direction in optical remote sensing images and adopts the regression model of four vectors with mutual information. Specifically, Cartesian coordinates are first established, with the center point of the object as the origin point. Afterwards, four vectors (top , right , bottom , and left ) from the coordinate origin to the four different side midpoints of the OBB can be represented (see Figure 3a). With these vectors, the top-to-left corner (), top-to-right corner (), bottom-to-right corner (), and bottom-to-left corner () of the OBB in the image can be calculated as follows:
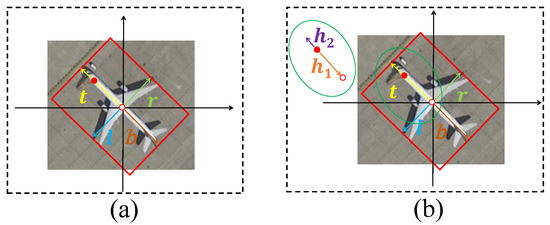
Figure 3.
OBB description. (a) BBAVectors with four vectors; (b) BBAVectors with six vectors, where represents the vector from the head keypoint of the aircraft to the ordinate origin (center point) and represents the vector from the head keypoint to the nearest midpoint of the head keypoint.
Moreover, when the long axis of the OBB is close to the origin of the coordinate system, the OBB of the arbitrarily oriented target can be assumed as the HBB. The top-to-left corner (), top-to-right corner (), bottom-to-left corner (), and bottom-to-right corner () of the HBB in the image can be written as
where and represent the width and height of the HBB surrounding the arbitrarily oriented targets, respectively.
Except for the overall structural information of the aircraft, local structural (or mutual) information belonging to the aircraft head can also provide semantic features (visual attributes) in a concise and efficient manner. Especially when the texture and structure of a single object are not obvious, the information is instrumental in human–computer interaction and knowledge transfer. To share more mutual information, we intentionally designed six vectors based on BBAVectors (, , , , , and ) instead of four vectors (see Figure 3b), where represents the vector from the aircraft head keypoint to the ordinate origin (center point) and represents the vector from the nearest midpoint of the head keypoint to the head keypoint. The added head mutual information can assist in the detection of the head keypoint by exploiting the relationship between the head keypoint and the OBB. Smooth L1 loss was also adopted to optimize the box parameters with six vectors in the center point:
where and refer to six vectors of the predicted and ground-truth bounding boxes, respectively.
(2) Head keypoint detection: Most of the top-performing methods for keypoint detection generate likelihood heatmaps that correspond to the location of each keypoint (e.g., facial landmarks [50,51]) in the input image. Inspired by these, we adopted heatmaps to detect the head keypoint of an airplane in optical remote sensing images. Figure 4 shows the heatmap annotation of an aircraft and its head keypoint.
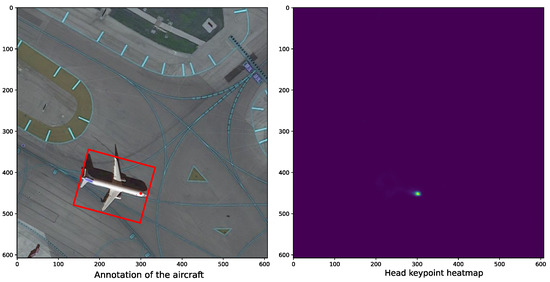
Figure 4.
Annotation of the aircraft and its head keypoint heatmap generated with the Gaussian function.
Ground-truth of head keypoint. Let us suppose that is an aircraft head keypoint. In this case, we place a 2D Gaussian blob centered in each keypoint and construct a ground-truth heatmap . is the index of pixel points on . usually depends on the box size-adaptive standard deviation [16]. Considering that the aircraft head occupies only a small area in the entire fuselage and that the position of the head keypoint may be assigned to multiple objects due to the overlapping boxes, we can select a box with the minimal area as the corresponding regression aircraft head. More specifically, we first calculate the shortest distance (i.e., the radius of the head area) from the head keypoint to the four sides of the OBB and then construct a square area with the shortest distance.
Heatmap regression of head keypoint. When training the heatmaps of the head, only the keypoint is positive, and additional bumps such as the sample points are negative. Directly learning positive head keypoints is difficult due to imbalance issues. Focal loss has proven to be effective in tasks with imbalanced class data. However, it cannot be fully guaranteed that all training is optimal, because different datasets have different degrees of balance [52]. In particular, the radius of the head area is quite small and not fixed, which provides a more variable degree of balance to calculate the extent of the heatmap. Recently, CFL [52] based on the principle of general cyclical training has been proposed for balanced, imbalanced, and long-tailed datasets. Following the work by [52], we reduce the penalties for points inside Gaussian bumps and learn the heatmap of head keypoints using variant CFL.
where is the total number of aircraft heads; t indexes pixel positions on the feature map; causes the loss to focus on more reliable training samples; p and represent the predicted and ground-truth heatmaps, respectively; the hyperparameters and quantify the contribution of each point. Empirically, we select and as in Ref. [9]. The parameter varies with the training epoch as follows:
where denotes the cyclical factor that offers variability to the cyclical schedule (), and and represent the current training epoch number and the total number of training epochs, respectively.
Head keypoint offset. During the implementation of the algorithm, we are required to extract the peak points of the predicted heatmap as the head keypoint positions of the aircraft. This head keypoint is an integer. However, the down-scaling of points from the input image to the output heatmap is no longer an integer but a floating-point number. Therefore, an offset map is calculated for the difference between quantified floating head keypoints and integer head keypoint, i.e., . The offset is optimized with smooth loss.
where is the ground-truth offset. As shown in Figure 3b, it is intuitive and reasonable that a pair of vectors and belonging to the fuselage orientation share the keypoint of that aircraft head. Since we can decode the corresponding center (starting point) of a predicted vector from its location and the relationship between it and other vectors with extended BBAVectors, it is easy to compare whether the starting points of a pair of vectors and are close enough and close to the keypoint of aircraft head. To match the vectors and , we further adjust the head keypoint position of the aircraft using their locations and the relationship between vectors with extended BBAVectors.
The detection of aircraft center keypoints is governed by and , as is the detection of head keypoints.
3.3. Loss Function
To aid the learning of the proposed RAIH-Det, the multitasking loss function can be divided into six parts as follows:
where is computed to learn the box parameters with six vectors using Equation (3); and are computed to regress the keypoint heatmap using Equations (3)–(6), respectively; and are calculated for the difference between quantified floating and integer head keypoints using Equation (9), respectively; the orientation class is derived from the binary cross-entropy, which can help the network to capture precise OBBs when encountering corner situations [20].
where and refer to predicted and ground-truth orientation classes, respectively; denotes the intersection over union between OBB and HBB; and indicates that the long axis of the OBB is close to the origin of the coordinate system and that the arbitrarily oriented target can be equivalent to the HBB.
4. Datasets
DOTA [8] is a large-scale dataset for object detection in optical remote sensing images, with images collected at multiple resolution levels. DOTA images range in resolution from pixels to pixels. The dataset provides two types of annotations: HBBs and OBBs. Compared with the former, the width and height of the latter directly reflect the relative size of the aircraft. DOTA-v1.5 comprises 2806 images of 16 target categories from the Google Earth, GF-2, and JL-1 satellites provided by the China Center for Resources Satellite Data and Application. This is an updated version of DOTA-1.0, where tiny instances (smaller than 10 pixels) are additionally annotated. The OBBs in DOTA are more flexible and easier to understand and are annotated as , where are the positions of the OBB vertices in the optical remote sensing image, c denotes the target category, and d is the difficulty level of target discrimination. Following the work by [53], we selected the “plane” category with 269 images from DOTA-v1.5 as our dataset for the AIH detection study, named DOTA-Plane. It was divided into a training set (198 images) and a test set (71 images). Each aircraft instance contained two labels: the OBB label and the head keypoint label. The former was derived from DOTA-v1.5, and the latter was annotated by our volunteers.
Since the head is only a small part of the entire fuselage, our volunteers spent two weeks manually marking the ground truth of the head center keypoints of all types of aircraft in DOTA-Plane with LabelMe software (https://github.com/wkentaro/labelme, accessed on 9 May 2016) to facilitate aircraft head detection. During the marking process, the annotations sometimes resulted to be coarse or erroneous, because the volunteers occasionally missed an aircraft or were inaccurate in marking the head center location. Therefore, to avoid such errors, three other volunteers visually cross-checked all annotations. The coordinates of the OBBs derived from DOTA-v1.5 were used as a reference for further correction of the head center position. As shown in Figure 5, given a plane with an OBB and the head center position , denotes the head center point of that plane. The center position of the plane, , is calculated using the OBB. The orientation of the plane can be expressed with the vector , pointing from the center position of the plane to the head center position of the plane.
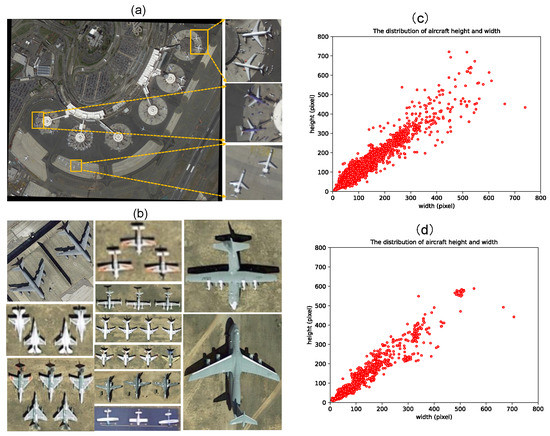
Figure 5.
Experimental dataset (DOTA-Plane) analysis. (a) Example pictures of aircraft taken with a remote sensing system. (b) The different categories of aircraft. (c,d) Aircraft height and width distribution in the training set and test set, respectively.
5. Experiments and Results
This section first presents the implementation details (parameter settings) of the proposed RAIH-Det and the evaluation metrics used in the experiments. A series of comparative experiments were conducted to verify the effectiveness of the proposed RAIH-Det on the DOTA-Plane dataset. The results obtained in AIH detection are then discussed.
5.1. Implementation Details
In our experiments, owing to the limitation issues of the GPU memory, the original images were cropped into small patches of size and stride 300. Most of the patches, including the aircraft, corresponding to a small fraction of the large HR optical remote sensing images in the training set, were occupied by empty backgrounds. Therefore, map shifting and spinning were performed while sampling some of the aircraft samples to significantly increase the number of data and ensure the diversity of the dataset. All input images were resized to pixels and used in the training and testing stages.
We implemented RAIH-Det using the deep learning framework PyTorch library. Adam optimizer was employed for training. The learning rate was set to 1.25 × 10 until 100 epochs were trained. The batch size of RAIH-Det was set to 4, and ConvNeXt-T’s pre-trained weight parameters were loaded. All experiments were performed on a single workstation equipped with a 4.20 GHz Intel (R) Core (TM) i7-7700K CPU with 32 GB RAM and an NVIDIA GeForce Titan Xp GPU with 12 GB VRAM.
5.2. Evaluation of AIH Detection
Precision () and recall () comprehensively reflect the detection accuracy and completion rate in the aircraft detection task, respectively. The related formulations are as follows:
where denotes the number of true positives and reflects properly detected aircraft, indicates the number of false positives and reflects false alarms, and is the number of all ground-truth values. Precision and recall values differ depending on the confidence threshold. The precision–recall curve (PRC) can then be drawn with recall values on the abscissa and precision values on the ordinate. Average precision () is not the average value of precision but considers precision and recall rates and is the area under the PRC. In our experiments, is a metric calculated at . Simultaneously, F1-score is comprehensively calculated as the harmonic average of precision and recall. Furthermore, a standard evaluation metric (percentage of correct keypoints (PCK) [54]) was used to evaluate the aircraft head keypoints. Given a set of predicted and ground-truth head keypoint pairs ,
where and denote the width and height of the OBB, respectively, and is a tolerance factor, with .
5.3. Ablation Studies
We developed a serial of ablation experiments to evaluate the contribution of each component to the performance of RAIH-Det. All experiments followed the same data augmentation strategy. The relevant settings are discussed in the following:
- RAIH-Det (W): U-shaped architecture with ConvNeXt-T + detection module (without head keypoint prediction) + box parameters with four vectors (without head keypoint mutual information).
- RAIH-Det (WW): U-shaped architecture with ConvNeXt-T + detection module (without aircraft box prediction).
- RAIH-Det (Res-HW): U-shaped architecture with ResNet101 + detection module (with head keypoint prediction) + box parameters with four vectors (without head keypoint mutual information).
- RAIH-Det (Res-HH): U-shaped architecture with ResNet101 + detection module (with head keypoint prediction) + box parameters with six vectors (with head keypoint mutual information).
- RAIH-Det (HW): U-shaped architecture with ConvNeXt-T + detection module (with head keypoint prediction) + box parameters with four vectors (without head keypoint mutual information).
- RAIH-Det: U-shaped architecture with ConvNeXt-T + detection module (with head keypoint prediction) + box parameters with six vectors (with head keypoint mutual information).
Backbone. Table 2 presents comparisons with other backbones, including both the ResNet-based and ConvNeXt-based ones, using DOTA-Plane training. RAIH-Det and RAIH-Det (HW) noticeably surpassed RAIH-Det (Res-HH) and RAIH-Det (Res-HW) with similar detection modules: RAIH-Det improved over RAIH-Det (Res-HH) using ResNet101 by +1.25% AP; +0.69% F1; and +1.38%, +1.88%, and +1.66% PCKs (, , and , respectively). RAIH-Det (HW) improved over RAIH-Det (Res-HW) using ResNet101 by +1.31% AP; +0.68% F1; and +1.64%, +2.15%, and +2.56% PCKs (, , and , respectively). According to these results, it can be seen that ConvNeXt-T improved the model’s ability. Figure 6 presents the localization with RAIH-Det (Res-HH) and RAIH-Det using class activation maps (CAMs) [55,56] and heatmaps. With the help of ConvNext-T, the relationship among the various spatial positions of AIH can be obtained more effectively.
Table 2.
Ablation studies of RAIH-Det on DOTA-Plane dataset. Ablations were performed on aircraft box prediction (ABP), head keypoint prediction (HKP), box parameters with four vectors (without head keypoint mutual information) (BPFVs), and box parameters with six vectors (BPSVs). PCK, AP, and F1-score are reported.
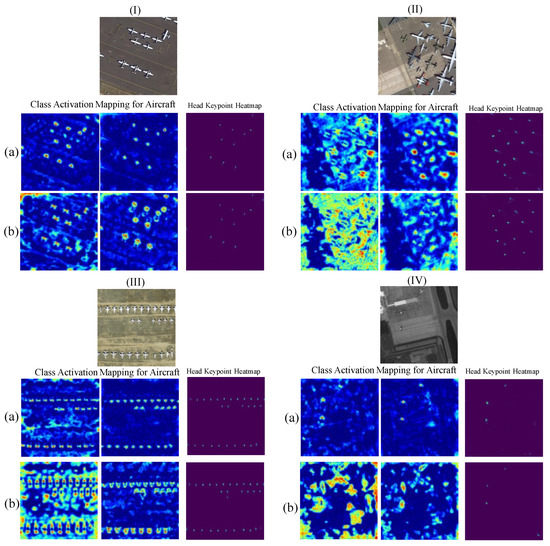
Figure 6.
Visualization and comparison of the localization with RAIH-Det (Res-HW) and RAIH-Det using class activation mapping (CAM) and head keypoint heatmaps for aircraft. The first row (a) and the second row (b) denote the CAM and head keypoint heatmaps of RAIH-Det and RAIH-Det (Res-HH), respectively. Compared with RAIH-Det (Res-HH), RAIH-Det has a potentially high concentration.
Parameter settings of the detection module. Compared with RAIH-Det (HW), the AP, F1, and PCKs (, , and ) of RAIH-Det, which includes the U-shaped architecture with ConvNeXt-T and the box parameters with six vectors (with head keypoint mutual information), were improved by +0.65%; +0.51%; and +1.38%, +1.43 %, and +1.2%, respectively (see Table 2). According to these results, the added head mutual information can improve the performance of the proposed method.
In the detection module, the dimension of each prediction branch is a very important parameter, which directly affects the AIH detection results of each aircraft. Therefore, we discuss the parameter settings of the FFN (i.e., n-layers perceptron with GELU activation function, hidden dimension, and linear projection layer) for six prediction branches. Table 3 reports the AIH detection results under different parameter settings. As a comparison, when the parameters of six prediction branches were set to 1, the best result was obtained. Note that higher-dimensional FFNs also required a longer test time.
Table 3.
The experiments on the choice of parameters n in the prediction branch.
Suitable box . In aircraft head keypoint detection based on heatmaps and cyclical focal loss, the aircraft head occupies only a small area of the entire fuselage. The head keypoint position can be assigned to multiple objects due to the overlapping boxes. Thus, we conducted experiments to search for the suitable box as the corresponding regression aircraft head. The experimental results are shown in Table 4. When box was a rectangular area (width and height were obtained with the width and height of the OBB), the head keypoint PCKs were close to 89.14 % (), 87.61% (), and 83.35% (). As box became smaller (), the head keypoint PCKs gradually increased. Compared with and , improved the head keypoint PCKs by 90.27% (), 88.41% (), and 84.41% (), respectively.
Table 4.
Ablation studies of head keypoint detection. and denote the rectangular areas, and their width and height were obtained with the width and height, or width/3 and height/3 of the OBB, respectively. On the other hand, represents a square area, and its width and height were obtained by calculating the shortest distance from the head keypoint to the four sides of the OBB.
Focal loss (FL) and cyclical focal loss (CFL). The ablations of FL-based and CFL-based RAIH-Det in the two tasks are reported in Table 5. On the DOTA-Plane test set, the RAIH-Det based on CFL outperformed the RAIH-Det based on CFL by +1.0% AP; +1.1% F1; and +1.95%, +2.01%, and +2.11% PCKs (, , and , respectively). According to these results, it can be seen that CFL can improve the model’s ability. Note that the RAIH-Det based on FL often greatly fluctuated in the training process.
Table 5.
Comparison results of the proposed RAIH-Det based on focal loss (RAIH-Det (FL)) and RAIH-Det based on cyclical focal loss (RAIH-Det (CFL)).
The success of RAIH-Det not only further suggests the effectiveness of the U-shaped architecture with ConvNeXt-T and the box parameters with six vectors but also proves the gain effect of their combination.
5.4. Comparison with the State-of-the-Art Models
We evaluated the performance of the proposed RAIH-Det on the DOTA-Plane dataset with comparisons to seven state-of-the-art rotated object and keypoint detectors: RetinaNet-O (OBB) [57], CenterNet [16], CentripetalNet [41], BBAVectors [20], CFC-Net [40], ReDet [27], and MKLM [21]. Table 6 reports the OBB results on the DOTA-Plane test dataset. Figure 7 shows the performance metrics of different methods.
Table 6.
Performance comparisons on DOTA-Plane test set. AHK denotes aircraft head keypoint. * denotes that the prediction module performs additional fine-tuning procedures according to the task of aircraft head keypoint detection.
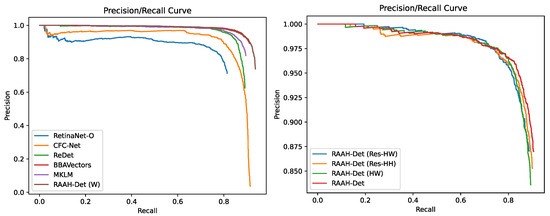
Figure 7.
Precision–recall curves (PRCs) of the proposed methods (RAIH-Det (Res-HW), RAIH-Det (Res-HH), RAIH-Det (HW), and RAIH-Det) compared with RetinaNet-O (OBB), BBAVectors, CFC-Net, ReDet, and MKLM.
In the aircraft detection task, RAIH-Det (W) achieved 92.40% AP and 88.52% F1, outperforming RetinaNet-O, BBAVectors, CFC-Net, ReDet, and MKLM. RetinaNet-O had a lower performance than the other methods, reaching the lowest AP and F1 of 74.29% and 74.52%, respectively. CFC-Net adopts rotation equivariance to generate oriented anchors from horizontal anchors to achieve better spatial alignment with oriented objects; it obtained 85.18% AP and 83.15% F1. MKLM employs two types of knowledge, internal and external, and interacts with information to adaptively improve Fast RCNN’s original feature representation; it achieved better performance, with 88.23% AP and 86.11% AP. ReDet can extract rotation-equivariant features to train an accurate object detector, obtaining 87.54% AP and 85.68% F1. However, aircraft detection is time-consuming. Unlike these methods, BBAVectors represents a new concept for rotated object detection in remote sensing images and is also a keypoint-based detector with box parameters with four boundary-aware vectors. BBAVectors could yield a better performance, with 90.21% AP and 87.77% F1 on the DOTA-Plane dataset. The box regression approach of BBAVectors was extended to the task of the detection of aircraft and aircraft head. As illustrated in Figure 8, the proposed RAIH-Det (W) could more effectively distinguish different types of aircraft from optical remote sensing images with complex and irrelevant background.

Figure 8.
Comparison and visualization of detection results of RAIH-Det (W) and BBAVectors on DOTA-Plane test set. For each example, the first row (a) and the second row (b) show the results of BBAVectors and RAIH-Det (W), respectively. The missed and erroneous detections are highlighted using the red ellipses.
For the aircraft head keypoint task, we selected the same box as the corresponding regression aircraft head area for all comparison methods (CenterNet, CentripetalNet, and BBAVectors). As shown in Table 6, RAIH-Det (WW) achieved 89.32%, 87.73%, and 84.21% PCKs (, , and , respectively), outperforming CenterNet, CentripetalNet, and BBAVectors. Unlike other methods, CentripetalNet introduces the corner point-matching strategy using the centripetal shifts and locations of corner points; it obtained 88.23%, 86.11%, and 82.59% PCKs (, , and , respectively).
Furthermore, we achieved the consolidation of AIH detection into a unified network (i.e., RAIH-Det) for end-to-end training. As reported in Table 6, RAIH-Det achieved 89.14% AP; 86.13% F1; and 90.27%, 88.41%, and 84.41% PCKs (, , and , respectively). This result shows that learning head mutual information with the extended BBAVectors can improve head keypoint detection with RAIH-Det. In reference [58], the authors indicate that loss addition inevitably leads to better results in some tasks due to the complexity of different tasks, but to greater errors in other tasks. As shown in Table 6, the detection results of aircraft with RAIH-Det were lower detection results than those obtained in a single task (RAIH-Det (W)), but RAIH-Det also provided better performance than other state-of-the-art object detection methods. Figure 9 and Figure 10 show part of the visualization results of RAIH-Det.

Figure 9.
Visualization of detection results of RAIH-Det on DOTA-Plane test set. The performance in the localization of aircraft of different types is good.

Figure 10.
Visualization of detection results of RAIH-Det on DOTA-Plane test set. The performance in the localization of aircraft with large-scale differences is good.
Extensive experiments on different detectors and representation methods demonstrate that the proposed RAIH-Det can effectively optimize the representation learning method for AIH detection and achieve consistent performance improvements. Next, we will discuss whether the proposed method can be applied to detecting other arbitrarily orientated objects (e.g., ships). The effectiveness of the proposed rotated detector on the public ship dataset HRSC2016 [59] was validated. The performance comparison results between RAIH-Det (W) and generic models (RPN [38], RRD [18], ROI Transformer [19], BBAVectors [20], and RDet [60]) on the HRSC2016 dataset are illustrated in Table 7. The experimental results demonstrate that the proposed method is useful for the detection of arbitrarily oriented ships. We give some detection results of RAIH-Det without head keypoint prediction (“RAIH-Det (W)”) on the HRSC2016 dataset in Figure 11.
Table 7.
Detection results obtained using different general models on the ship dataset HRSC2016.

Figure 11.
Visualization of the detection results of RAIH-Det without head keypoint prediction (“RAIH-Det (W)”) on HRSC2016 dataset.
6. Conclusions
In this paper, we present an end-to-end rotated aircraft and aircraft head detector (RAIH-Det) that consists of a U-shaped network with ConvNeXt-T for multiscale feature representation and a detection module with extended BBAVectors for mutual information sharing (e.g., head keypoint mutual information). ConvNext-T can facilitate incorporating the relationships among various AIH spatial locations into multiscale feature maps. Our BBAVectors can share more head keypoint mutual information, as it consists of six vectors instead of the original four vectors. This added information can assist in the detection of the head keypoints by exploiting the relationship among the head keypoints, the center point, and the OBB. Additionally, we apply variant CFL, which can focus on more reliable samples, to regress the heatmap locations of the aircraft head keypoints. To facilitate the detection of aircraft and aircraft head, we introduce a DOTA-Plane dataset as a modification of the DOTA-v1.5 dataset. Each aircraft in the new dataset is annotated with the OBB and aircraft head keypoints. Finally, we provide an evaluation and ablation study of the proposed RAIH-Det. The experiments show that the proposed RAIH-Det obtained excellent detection performance improvements on the DOTA-Plane dataset. In the future, the proposed RAIH-Det and the change detection method could be jointed to detect and describe the aircraft changes occurring at an airport using multi-temporal optical remote sensing images. This study can be effectively applied to the real-time monitoring of civilian and military airports. Furthermore, the concept can be extended to multiple tasks. For example, the detection of ships and ship heads in optical remote sensing images is becoming significant in port management, maritime rescue, and maritime and inland freight transport systems.
Author Contributions
F.S.: formal analysis; methodology; supervision; writing—original draft; writing—review and editing. R.M.: validation; writing—review and editing. T.L.: conceptualization; formal analysis; methodology; supervision; writing—review and editing. Z.P.: conceptualization; formal analysis; methodology; supervision; writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Natural Science Foundation of Sichuan Province of China under grant 2022NSFSC40574 and partially supported by National Natural Science Foundation of China under grants 61775030 and 61571096.
Institutional Review Board Statement
We used approved and publicly available datasets. Many previous studies have also used these datasets.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
DOTA is a publicly available object detection dataset of optical remote sensing images (available for download at https://captain-whu.github.io/DOTA/index.html, accessed on 26 January 2018).
Acknowledgments
The authors would like to thank all the researchers who kindly shared the codes used in our studies and all the volunteers who helped us constructing the dataset.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Abbreviation | Description |
| AIH | Aircraft and its head |
| HBB | Horizontal bounding box |
| OBB | Oriented bounding box |
| ViT | Vision Transformer |
| CFL | Cyclical focal loss |
| AP | Average precision |
| PCK | Percentage of correct keypoints |
References
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Ma, L.; Gou, Y.; Lei, T.; Jin, L.; Song, Y. Small object detection based on multiscale features fusion using remote sensing images. Opto-Electron. Eng. 2022, 4, 210363. [Google Scholar]
- Jia, H.; Guo, Q.; Zhou, R.; Xu, F. Airplane detection and recognition incorporating target component detection. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4188–4191. [Google Scholar]
- Song, F.; Zhang, S.; Lei, T.; Song, Y.; Peng, Z. MSTDSNet-CD: Multiscale Swin Transformer and Deeply Supervised Network for Change Detection of the Fast-Growing Urban Regions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 June 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Fu, K.; Li, J.; Ma, L.; Mu, K.; Tian, Y. Intrinsic relationship reasoning for small object detection. arXiv 2020, arXiv:2009.00833. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.S.; Bai, X. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5909–5918. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 2150–2159. [Google Scholar]
- Zhang, S.; Song, F.; Lei, T.; Jiang, P.; Liu, G. MKLM: A multiknowledge learning module for object detection in remote sensing images. Int. J. Remote Sens. 2022, 43, 2244–2267. [Google Scholar] [CrossRef]
- Chen, K.; Wu, M.; Liu, J.; Zhang, C. Fgsd: A dataset for fine-grained ship detection in high resolution satellite images. arXiv 2020, arXiv:2003.06832. [Google Scholar]
- Xiong, Y.; Niu, X.; Dou, Y.; Qie, H.; Wang, K. Non-locally enhanced feature fusion network for aircraft recognition in remote sensing images. Remote Sens. 2020, 12, 681. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1503.08083. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Zhai, Y.; Yang, X.; Wang, Q.; Zhao, Z.; Zhao, W. Hybrid knowledge R-CNN for transmission line multifitting detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 150–165. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. Centripetalnet: Pursuing high-quality keypoint pairs for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10519–10528. [Google Scholar]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 23.1–23.6. [Google Scholar]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 27–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning modulated loss for rotated object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 2458–2466. [Google Scholar]
- Scherhag, U.; Budhrani, D.; Gomez-Barrero, M.; Busch, C. Detecting morphed face images using facial landmarks. In Proceedings of the International Conference on Image and Signal Processing, Cherbourg, France, 2–4 July 2018; pp. 444–452. [Google Scholar]
- Zhang, J.; Hu, H.; Feng, S. Robust facial landmark detection via heatmap-offset regression. IEEE Trans. Image Process. 2020, 29, 5050–5064. [Google Scholar] [CrossRef]
- Smith, L.N. Cyclical Focal Loss. arXiv 2022, arXiv:2202.08978. [Google Scholar]
- Zhang, X.; Wang, G.; Zhu, P.; Zhang, T.; Li, C.; Jiao, L. GRS-Det: An Anchor-Free Rotation Ship Detector Based on Gaussian-Mask in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3518–3531. [Google Scholar] [CrossRef]
- Lu, C.; Koniusz, P. Few-shot Keypoint Detection with Uncertainty Learning for Unseen Species. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19416–19426. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Zhang, Q.; Rao, L.; Yang, Y. Group-CAM: Group score-weighted visual explanations for deep convolutional networks. arXiv 2021, arXiv:2103.13859. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Kumar, V.R.; Yogamani, S.; Rashed, H.; Sitsu, G.; Witt, C.; Leang, I.; Milz, S.; Mäder, P. Omnidet: Surround view cameras based multi-task visual perception network for autonomous driving. IEEE Robot. Autom. Lett. 2021, 6, 2830–2837. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. Proc. AAAI Conf. Artif. Intell. 2012, 35, 3163–3171. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).