


MUREN: MUltistage Recursive Enhanced Network for Coal-Fired Power Plant Detection
 ,
,  , ,
, ,
Abstract
1. Introduction
- (a)
- We construct a new dataset of CFPPs, including the location and working status of over 300 CFPPs collected from Google Earth at 1-meter resolution. The dataset is published in https://github.com/yuanshuai0914/MUREN (accessed on: 14 April 2023).
- (b)
- We design two enhancement mechanisms, i.e., a channel-enhanced subnetwork and a spatial-enhanced subnetwork embedded into the backbone of our detection method. CEN enhances feature representation for CFPPs and restrains the effects of noise for better training and testing performance. SEN learns the spatial relationship of components in CFPP and enriches the semantic and context information for better localization.
- (c)
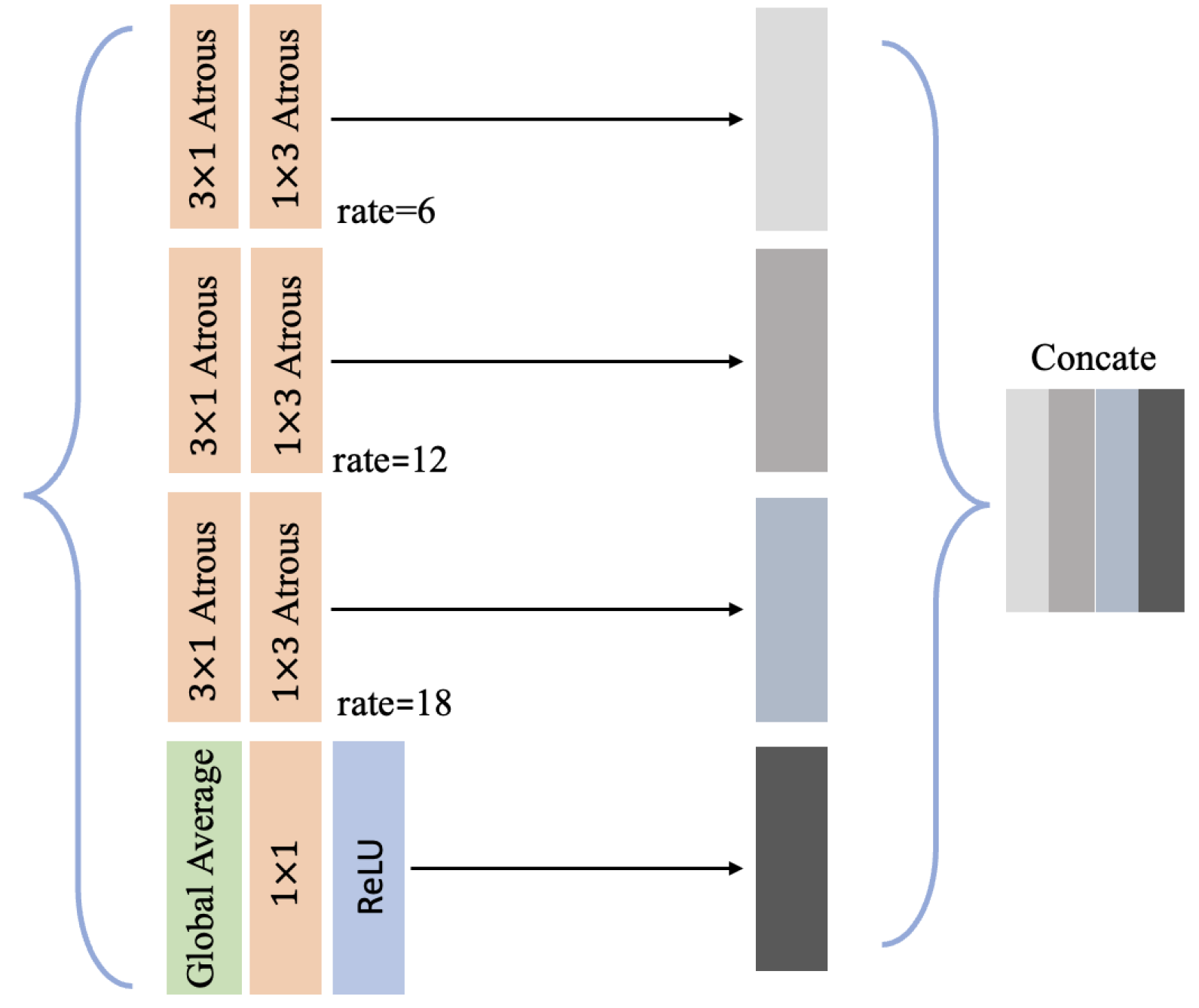
- We integrate the recursive connections and improved Atrous Spatial Pyramid Pooling (ASPP) module into the Feature Pyramid Network (FPN). FPN fuses multilevel semantic and spatial information for small object detection. Recursive connections and the ASPP module make FPN receive features twice, boosting feature learning for small and irregular CFPPs.
2. Related Works
2.1. Object Detection in Remote Sensing
2.1.1. Algorithms in Related Works
2.1.2. Datasets in Related Works
2.2. Coal-Fired Power Plant Detection
3. MUREN
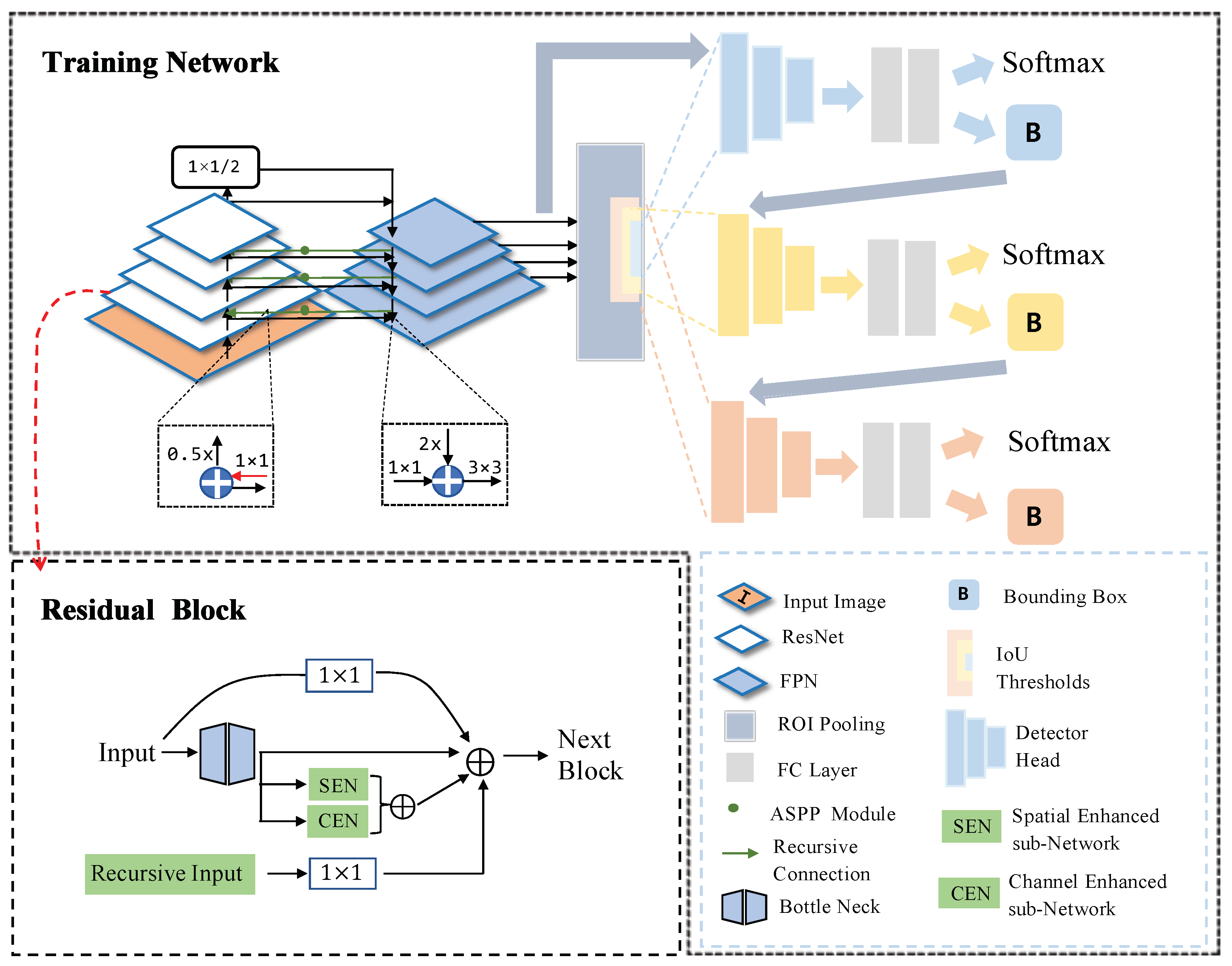
3.1. Overview of Our Method
- (1)
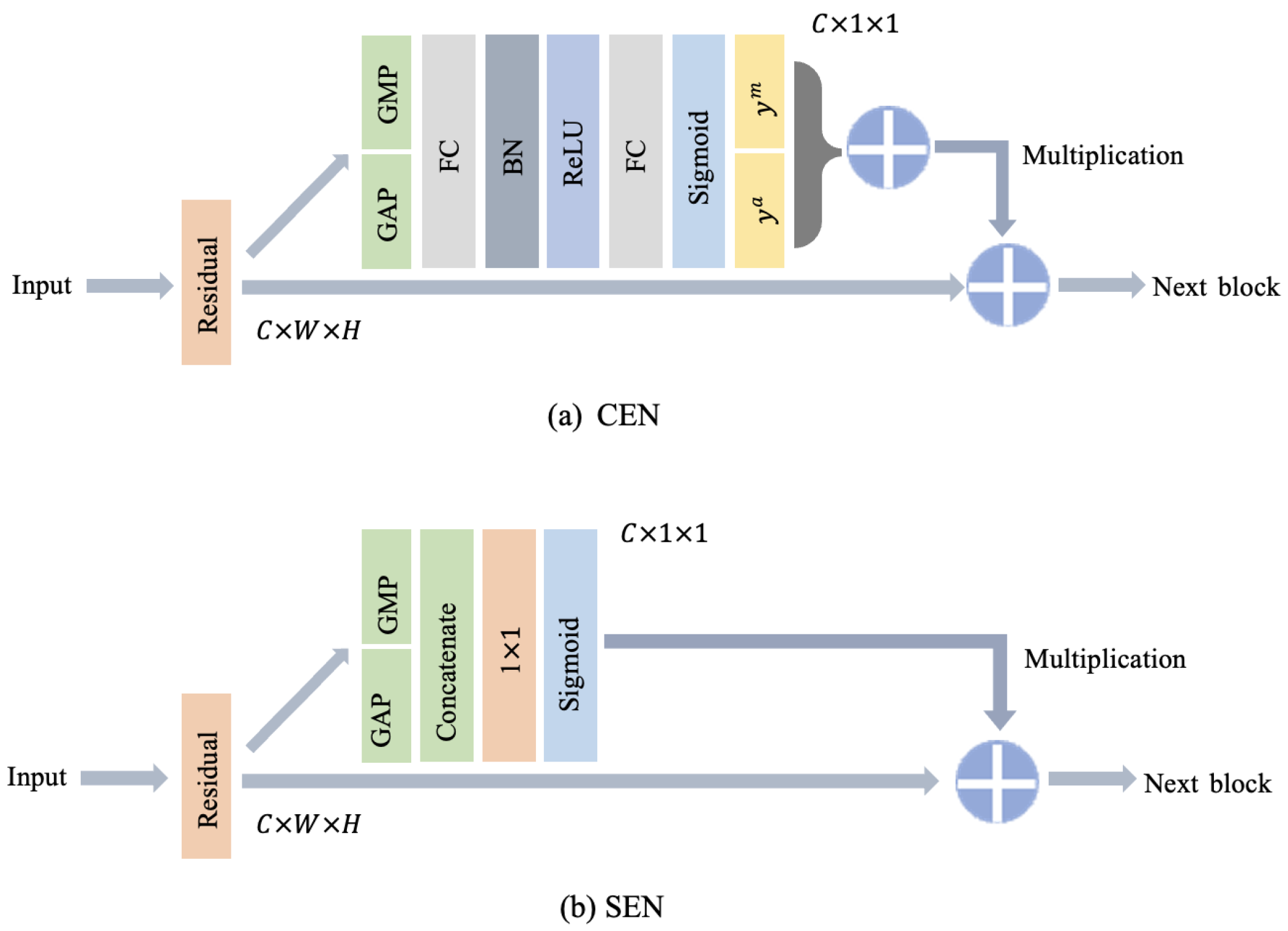
- A channel-enhanced subnetwork (CEN) for tackling the similarity of background patterns. In parallel with ResNet-50 [64], we add a channel-enhanced subnetwork consisting of a global average pooling layer, a global max pooling layer, two fully connected layers, and a batch normalization layer followed by an activation layer, which reaps adaptive channel recalibration and improves the object feature representation.
- (2)
- A spatial-enhanced subnetwork (SEN) for tackling the spatial interrelationship of CFPPs’ complex components. In addition to CEN and ResNet-50, we propose a symmetrical spatial-enhanced subnetwork consisting of a global average pooling layer, a global max pooling layer, and a convolutional layer followed by an activation layer.
- (3)
- A recursive connection is added in FPN to strengthen the global feature and receptive field. FPN constructs the feature pyramid to gain different scale features and build connections between the same-scale feature map. We use a recursive connection from the FPN layers to the backbone layers. This connection gives feedback received from the FPN to the previous backbone to strengthen the object feature extraction.
- (4)
- A multistage detector after Region of Interests (RoI) Pooling. We adopt a Cascade R-CNN-based multistage detector in the end, containing three detectors with different Intersection of Union (IoU) thresholds trained sequentially, using the output of a detector as the training set for the next.
3.2. Symmetrically Enhanced Network
3.2.1. Channel-Enhanced Subnetwork
3.2.2. Spatial-Enhanced Subnetwork
3.3. Recursive Connection in FPN
3.3.1. Feature Pyramid Network
3.3.2. Recursive Connection
3.3.3. Improved ASPP Module
3.4. Multistage Detector
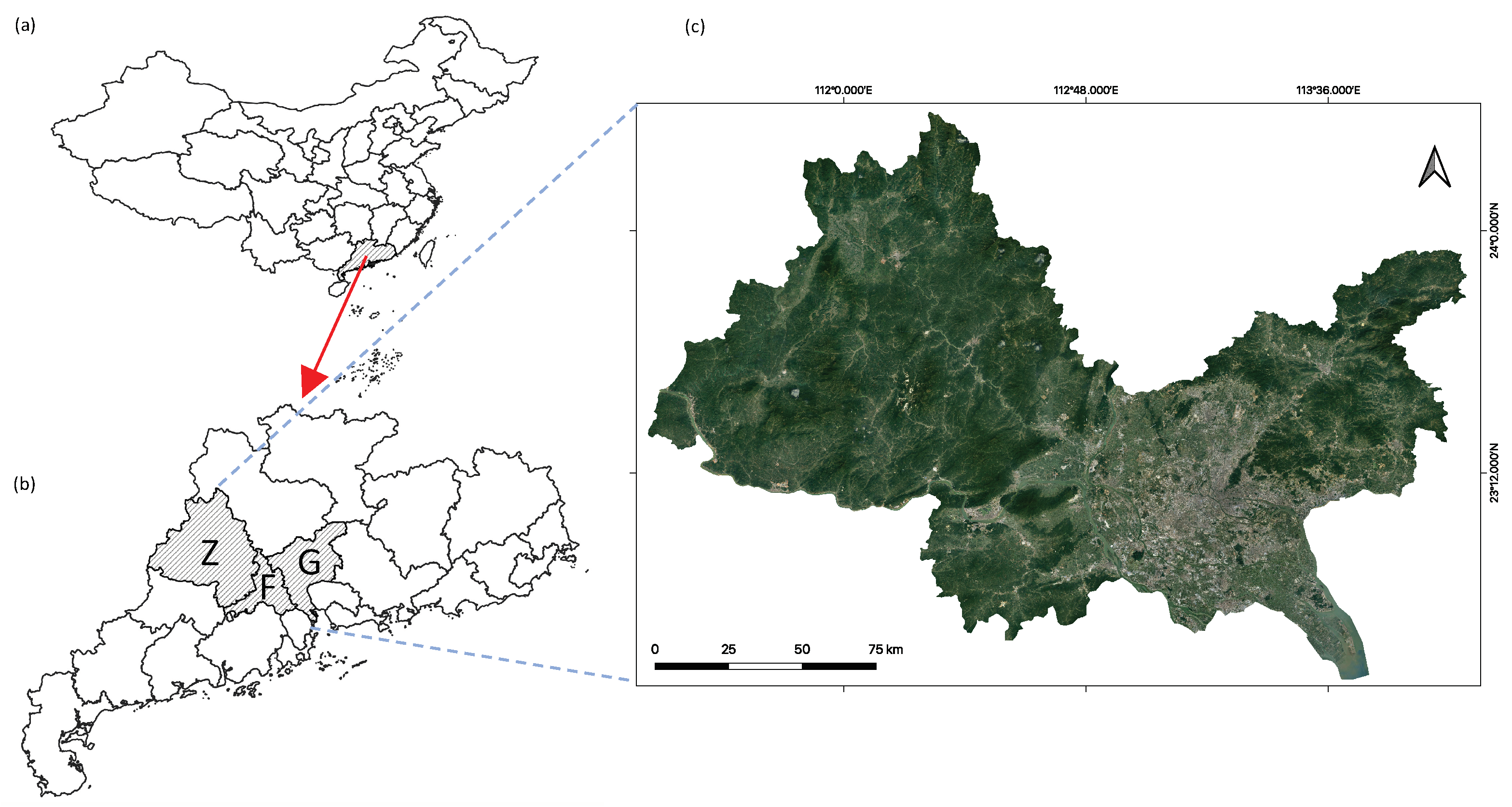
4. Datasets and Study Area
5. Experimental Results
5.1. Parameter Settings and Evaluation Metric
5.2. MUREN Detection Results
5.3. Large-Scale Applications
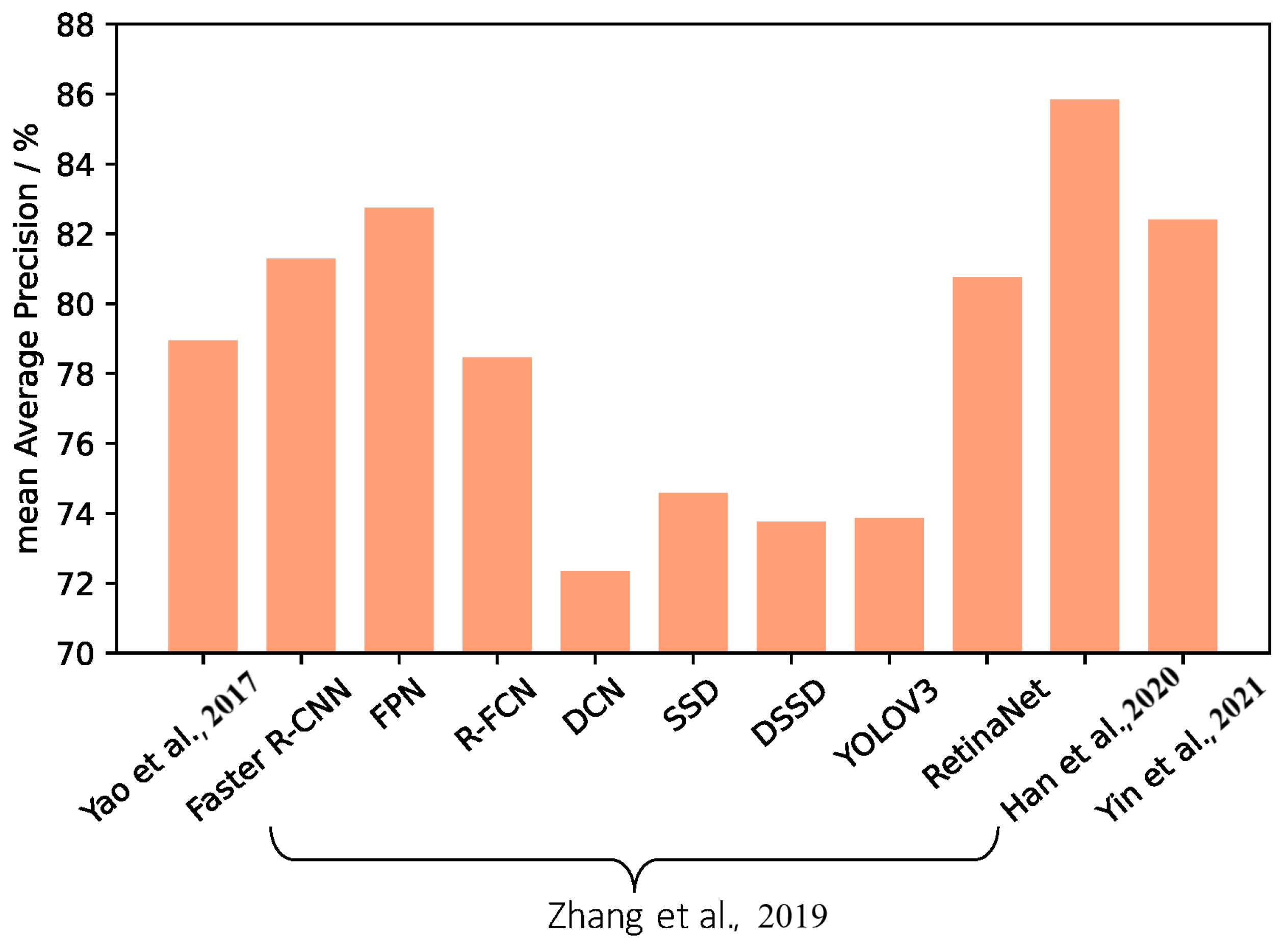
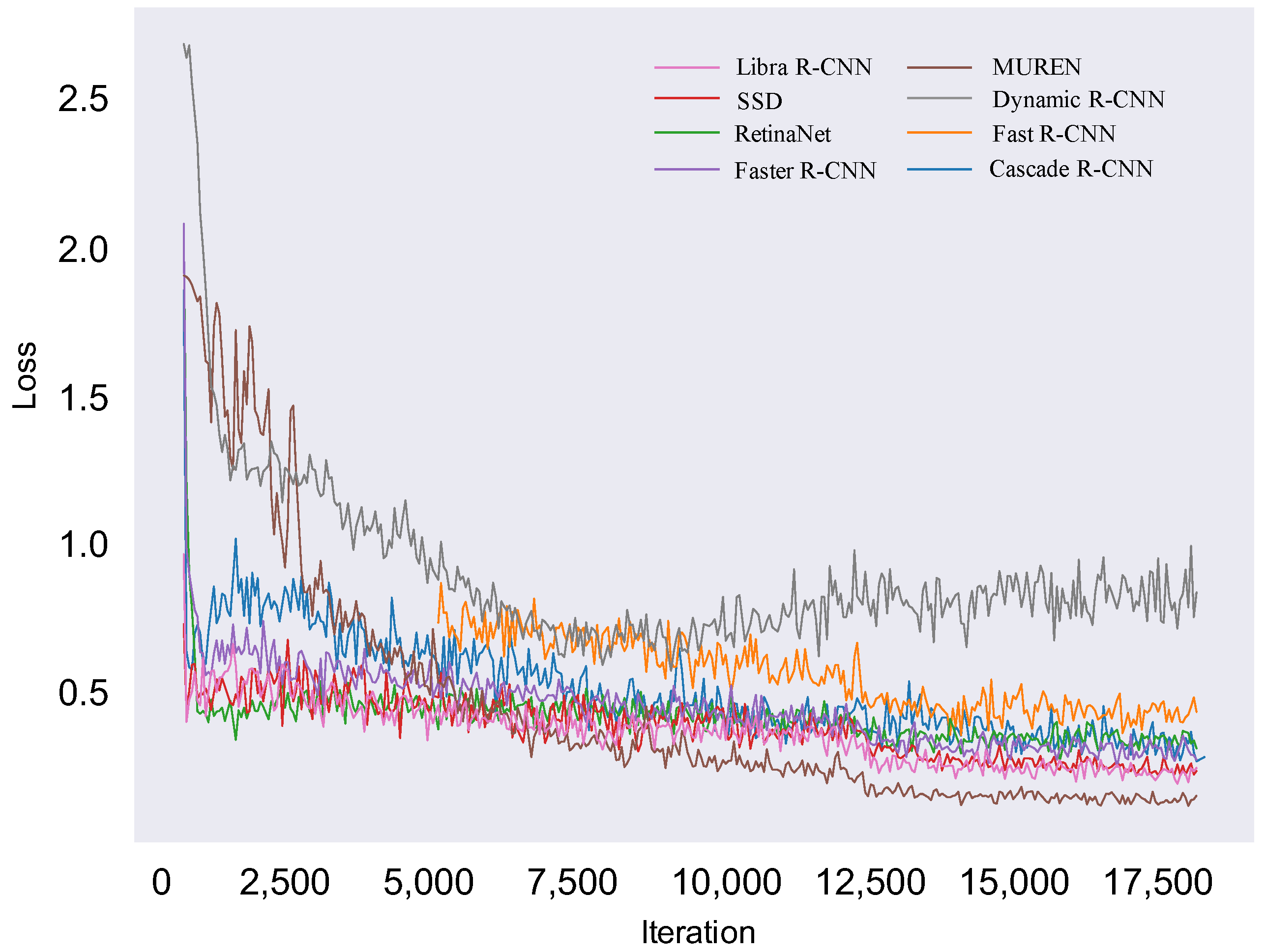
5.4. Comparative Study between MUREN and Other Object Detection Methods
6. Discussion
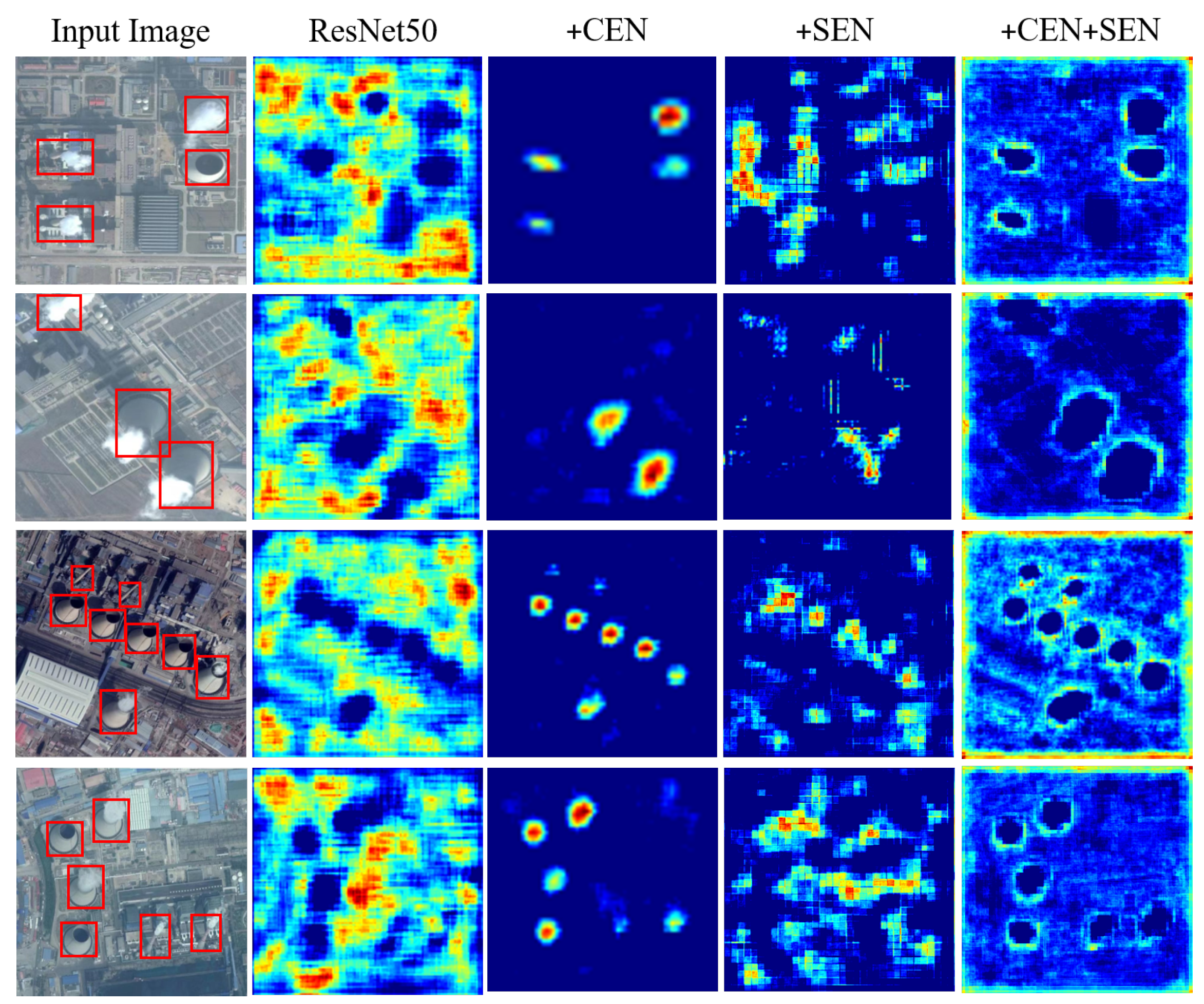
6.1. Ablation Study of the Symmetrically Enhanced Network
6.2. Ablation Study of Recursive Connections
6.3. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A




References
- Liu, Z.; Guan, D.; Crawford-Brown, D.; Zhang, Q.; He, K.; Liu, J. A low-carbon road map for China. Nature 2013, 500, 143–145. [Google Scholar] [CrossRef]
- Li, Z.Z.; Li, R.Y.M.; Malik, M.Y.; Murshed, M.; Khan, Z.; Umar, M. Determinants of carbon emission in China: How good is green investment? Sustain. Prod. Consum. 2021, 27, 392–401. [Google Scholar] [CrossRef]
- He, K.; Huo, H.; Zhang, Q.; He, D.; An, F.; Wang, M.; Walsh, M.P. Oil consumption and CO2 emissions in China’s road transport: Current status, future trends, and policy implications. Energy Policy 2005, 33, 1499–1507. [Google Scholar] [CrossRef]
- Zhou, S.; Wei, W.; Chen, L.; Zhang, Z.; Liu, Z.; Wang, Y.; Kong, J.; Li, J. Impact of a coal-fired power plant shutdown campaign on heavy metal emissions in China. Environ. Sci. Technol. 2019, 53, 14063–14069. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Yang, W.; Yang, Y.; Yuan, G. Analysis of the air quality and the effect of governance policies in China’s Pearl River Delta, 2015–2018. Atmosphere 2019, 10, 412. [Google Scholar] [CrossRef]
- Zhong, L.; Louie, P.K.; Zheng, J.; Yuan, Z.; Yue, D.; Ho, J.W.; Lau, A.K. Science–policy interplay: Air quality management in the Pearl River Delta region and Hong Kong. Atmos. Environ. 2013, 76, 3–10. [Google Scholar] [CrossRef]
- Zhang, H.; Deng, Q. Deep learning based fossil-fuel power plant monitoring in high resolution remote sensing images: A comparative study. Remote. Sens. 2019, 11, 1117. [Google Scholar] [CrossRef]
- Han, C.; Li, G.; Ding, Y.; Yan, F.; Bai, L. Chimney detection based on faster R-CNN and spatial analysis methods in high resolution remote sensing images. Sensors 2020, 20, 4353. [Google Scholar] [CrossRef]
- Deng, Q.; Zhang, H. Chimney and condensing tower detection based on FPN in high resolution remote sensing images. In Proceedings of the Image and Signal Processing for Remote Sensing XXV, International Society for Optics and Photonics, Strasbourg, France, 9–12 September 2019; Volume 11155, p. 111552B. [Google Scholar]
- Yao, Y.; Jiang, Z.; Zhang, H.; Cai, B.; Meng, G.; Zuo, D. Chimney and condensing tower detection based on faster R-CNN in high resolution remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3329–3332. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards high quality object detection via dynamic training. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 260–275. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Danaee, P.; Ghaeini, R.; Hendrix, D.A. A deep learning approach for cancer detection and relevant gene identification. In Proceedings of the Pacific Symposium on Biocomputing, Kohala Coast, Hawaii, 4–8 January 2017; pp. 219–229. [Google Scholar]
- Barbedo, J.G.A.; Koenigkan, L.V.; Santos, T.T.; Santos, P.M. A study on the detection of cattle in UAV images using deep learning. Sensors 2019, 19, 5436. [Google Scholar] [CrossRef]
- Duporge, I.; Isupova, O.; Reece, S.; Macdonald, D.W.; Wang, T. Using very-high-resolution satellite imagery and deep learning to detect and count African elephants in heterogeneous landscapes. Remote Sens. Ecol. Conserv. 2020, 7, 369–381. [Google Scholar] [CrossRef]
- Kulkarni, R.; Dhavalikar, S.; Bangar, S. Traffic light detection and recognition for self driving cars using deep learning. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–4. [Google Scholar]
- Wang, J.G.; Zhou, L.B. Traffic light recognition with high dynamic range imaging and deep learning. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1341–1352. [Google Scholar] [CrossRef]
- Najibi, M.; Singh, B.; Davis, L.S. Fa-rpn: Floating region proposals for face detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7723–7732. [Google Scholar]
- Sun, X.; Wu, P.; Hoi, S.C. Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef]
- Li, C.; Wang, R.; Li, J.; Fei, L. Face detection based on YOLOv3. In Recent Trends in Intelligent Computing, Communication and Devices; Springer: Singapore, 2020; pp. 277–284. [Google Scholar]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Zhao, Y.; Dong, R.; Yu, L. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 154–177. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Yu, L.; Yuan, S.; Tao, W.Y.W.; Pang, T.K.; Kanniah, K.D. Growing status observation for oil palm trees using Unmanned Aerial Vehicle (UAV) images. ISPRS J. Photogramm. Remote Sens. 2021, 173, 95–121. [Google Scholar] [CrossRef]
- Li, W.; Dong, R.; Fu, H.; Yu, L. Large-scale oil palm tree detection from high-resolution satellite images using two-stage convolutional neural networks. Remote. Sens. 2019, 11, 11. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote. Sens. 2017, 9, 312. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. Car detection from low-altitude UAV imagery with the faster R-CNN. J. Adv. Transp. 2017, 2017, 2823617. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Hikosaka, S. Building detection from satellite imagery using ensemble of size-specific detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 187–191. [Google Scholar]
- Zhang, L.; Dong, R.; Yuan, S.; Li, W.; Zheng, J.; Fu, H. Making low-resolution satellite images reborn: A deep learning approach for super-resolution building extraction. Remote Sens. 2021, 13, 2872. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Peng, J.; Liu, Y. Model and context-driven building extraction in dense urban aerial images. Int. J. Remote Sens. 2005, 26, 1289–1307. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A. Semi-automated road detection from high resolution satellite images by directional morphological enhancement and segmentation techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Eikvil, L.; Aurdal, L.; Koren, H. Classification-based vehicle detection in high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 65–72. [Google Scholar] [CrossRef]
- Yao, X.; Han, J.; Guo, L.; Bu, S.; Liu, Z. A coarse-to-fine model for airport detection from remote sensing images using target-oriented visual saliency and CRF. Neurocomputing 2015, 164, 162–172. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep learning based oil palm tree detection and counting for high-resolution remote sensing images. Remote. Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-oriented ship detection framework in optical remote-sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-attentioned object detection in remote sensing imagery. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, China, 22–25 September 2019; pp. 3886–3890. [Google Scholar]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Farooq, A.; Hu, J.; Jia, X. Efficient object proposals extraction for target detection in VHR remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3337–3340. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Guo, Y.; Yan, J. Learning modulated loss for rotated object detection. arXiv 2019, arXiv:1911.08299. [Google Scholar] [CrossRef]
- Zhao, P.; Qu, Z.; Bu, Y.; Tan, W.; Guan, Q. Polardet: A fast, more precise detector for rotated target in aerial images. Int. J. Remote Sens. 2021, 42, 5821–5851. [Google Scholar] [CrossRef]
- Bao, S.; Zhong, X.; Zhu, R.; Zhang, X.; Li, Z.; Li, M. Single shot anchor refinement network for oriented object detection in optical remote sensing imagery. IEEE Access 2019, 7, 87150–87161. [Google Scholar] [CrossRef]
- Tian, H.; Wang, Y.; Xue, Z.; Qu, Y.; Chai, F.; Hao, J. Atmospheric emissions estimation of Hg, As, and Se from coal-fired power plants in China, 2007. Sci. Total Environ. 2011, 409, 3078–3081. [Google Scholar] [CrossRef] [PubMed]
- Büke, T.; Köne, A.Ç. Estimation of the health benefits of controlling air pollution from the Yatağan coal-fired power plant. Environ. Sci. Policy 2011, 14, 1113–1120. [Google Scholar] [CrossRef]
- Mittal, M.L.; Sharma, C.; Singh, R. Estimates of emissions from coal fired thermal power plants in India. In Proceedings of the 2012 International Emission Inventory Conference, Tampa, FL, USA, 13–16 August 2012; pp. 13–16. [Google Scholar]
- Yin, W.; Diao, W.; Wang, P.; Gao, X.; Li, Y.; Sun, X. PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 1243. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the Icml, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Alvarez, J.; Petersson, L. Decomposeme: Simplifying convnets for end-to-end learning. arXiv 2016, arXiv:1606.05426. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 5561–5569. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
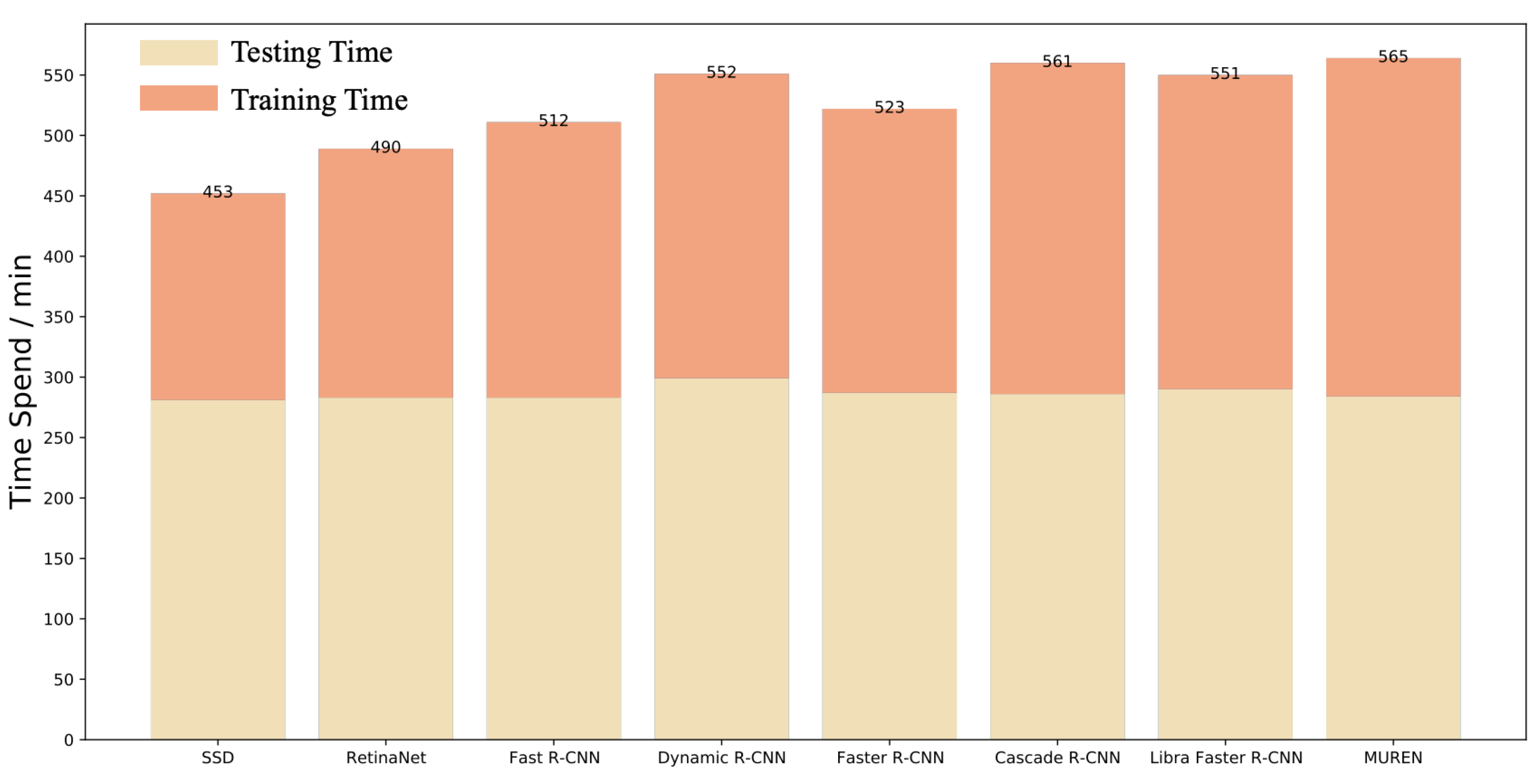{kind=link}
{kind=link}
{kind=link}
| Index | Chimney | Condensing Tower | ||
|---|---|---|---|---|
| Working | Nonworking | Working | Nonworking | |
| recall | 88.17% | 83.02% | 98.32% | 97.28% |
| precision | 86.92% | 80.46% | 99% | 92.23% |
| AP | 88.92% | 86.32% | 98.10% | 96.49% |
| mAP | 92.46% | |||
| Index | Chimney | Condensing Tower | ||
|---|---|---|---|---|
| Working | Nonworking | Working | Nonworking | |
| TP | 66 | 89 | 43 | 57 |
| FP | 13 | 19 | 6 | 7 |
| FN | 11 | 14 | 1 | 4 |
| precision | 83.43% | 82.41% | 87.76% | 89.06% |
| recall | 85.71% | 86.41% | 97.73% | 93.44% |
| AP | 84.67% | 82.72% | 92.75% | 90.19% |
| mAP | 87.58% | |||
| Method | Working Chimney | Nonworking Chimney | Working Condensing Tower | Nonworking Condensing Tower | mAP |
|---|---|---|---|---|---|
| SSD | 55.31% | 56.38% | 88.41% | 84.23% | 71.08% |
| RetinaNet | 59.78% | 58.19% | 89.90% | 84.21% | 73.02% |
| Fast R-CNN | 62.02% | 61.56% | 90.67% | 84.67% | 74.73% |
| Dynamic R-CNN | 71.29% | 72.76% | 92.31% | 91.07% | 81.85% |
| Faster R-CNN | 70.73% | 66.24% | 93.44% | 89.41% | 79.95% |
| Cascade R-CNN | 80.34% | 79.92% | 93.76% | 91.93% | 86.48% |
| Libra Faster R-CNN | 82.23% | 78.45% | 94.32% | 96.67% | 87.89% |
| MUREN(Ours) | 88.92% | 86.32% | 98.10% | 96.49% | 92.46% |
| Method | Parameter Amount | Space Occupancy |
|---|---|---|
| SSD | 35 million | 224 MB |
| RetinaNet | 40 million | 633 MB |
| Fast R-CNN | 42 million | 428 MB |
| Dynamic R-CNN | 47 million | 631 MB |
| Faster R-CNN | 42 million | 437 MB |
| Cascade R-CNN | 44 million | 552 MB |
| Libra Faster R-CNN | 45 million | 575MB |
| MUREN(Ours) | 45 million | 587 MB |
| Strategy | Working Chimney | Nonworking Chimney | Working Condensing Tower | Nonworking Condensing Tower | mAP |
|---|---|---|---|---|---|
| Baseline | 80.34% | 79.92% | 95.76% | 92.93% | 87.23% |
| Baseline+CEN | 82.30% | 82.15% | 96.12% | 93.78% | 88.58% |
| Baseline+SEN | 81.33% | 80.45% | 96.25% | 92.67% | 87.63% |
| Baseline+CEN+SEN | 83.91% | 82.93% | 96.17% | 94.07% | 89.27% |
| Strategy | Working Chimney | Nonworking Chimney | Working Condensing Tower | Nonworking Condensing Tower | mAP | ||
|---|---|---|---|---|---|---|---|
| Baseline | 80.34% | 79.92% | 95.76% | 92.93% | 87.23% | ||
| Recursive Connections | 82.38% | 81.41% | 96.83% | 94.21% | 88.71% | ||
| Recursive | + | Vanilla | 83.02% | 82.19% | 97.11% | 94.76% | 89.27% |
| Connections | ASPP | ||||||
| Recursive | + | Improved | 83.98% | 82.61% | 97.32% | 95.33% | 89.81% |
| Connections | ASPP | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, S.; Zheng, J.; Zhang, L.; Dong, R.; Cheung, R.C.C.; Fu, H. MUREN: MUltistage Recursive Enhanced Network for Coal-Fired Power Plant Detection. Remote Sens. 2023, 15, 2200. https://doi.org/10.3390/rs15082200
Yuan S, Zheng J, Zhang L, Dong R, Cheung RCC, Fu H. MUREN: MUltistage Recursive Enhanced Network for Coal-Fired Power Plant Detection. Remote Sensing. 2023; 15(8):2200. https://doi.org/10.3390/rs15082200
Chicago/Turabian StyleYuan, Shuai, Juepeng Zheng, Lixian Zhang, Runmin Dong, Ray C. C. Cheung, and Haohuan Fu. 2023. "MUREN: MUltistage Recursive Enhanced Network for Coal-Fired Power Plant Detection" Remote Sensing 15, no. 8: 2200. https://doi.org/10.3390/rs15082200
APA StyleYuan, S., Zheng, J., Zhang, L., Dong, R., Cheung, R. C. C., & Fu, H. (2023). MUREN: MUltistage Recursive Enhanced Network for Coal-Fired Power Plant Detection. Remote Sensing, 15(8), 2200. https://doi.org/10.3390/rs15082200