
Development of a Fast Convergence Gray-Level Co-Occurrence Matrix for Sea Surface Wind Direction Extraction from Marine Radar Images



Abstract
1. Introduction
2. Data Overview
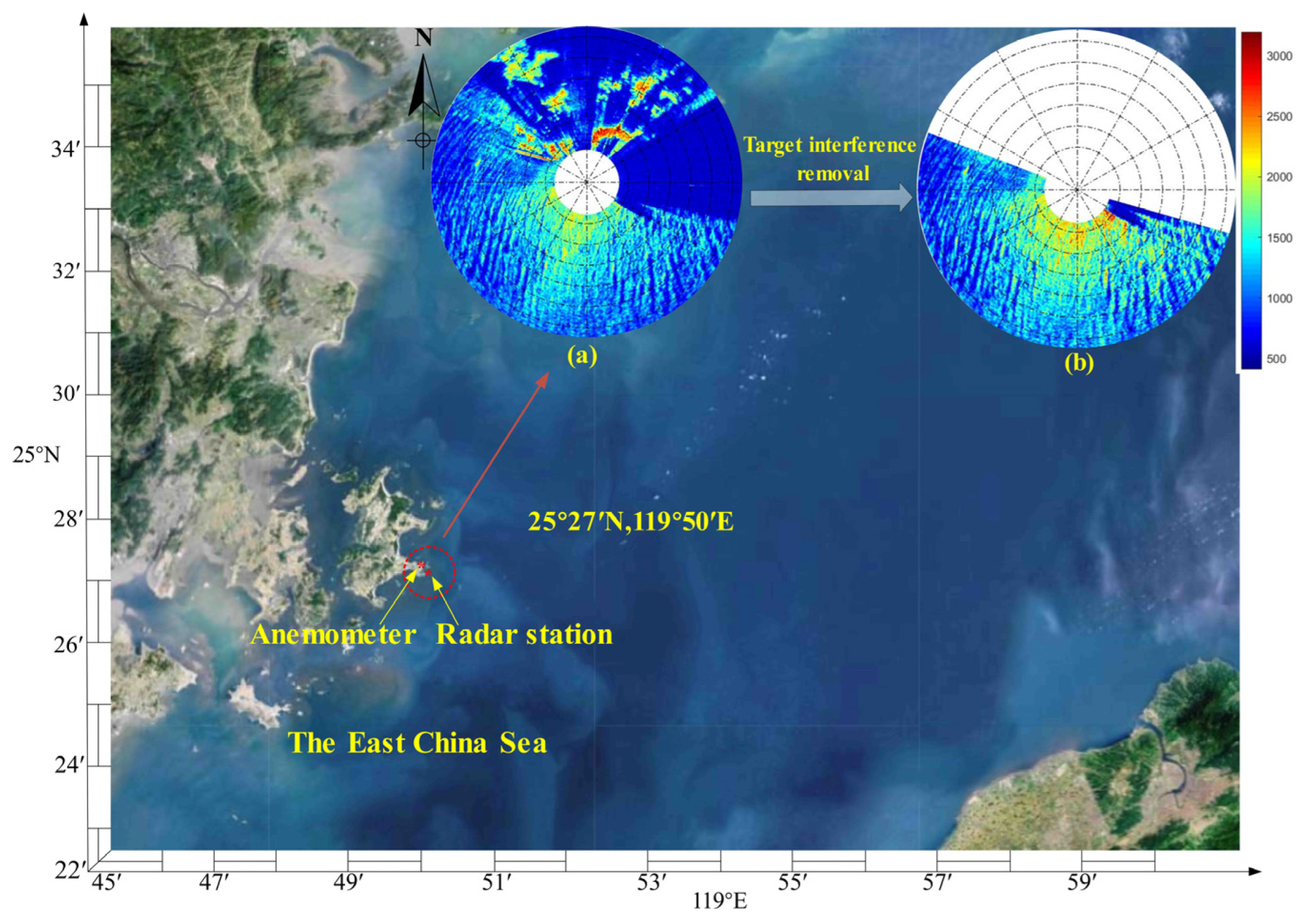
2.1. Data Source
2.2. Polar Co-Ordinate Sea Surface Static Feature Image
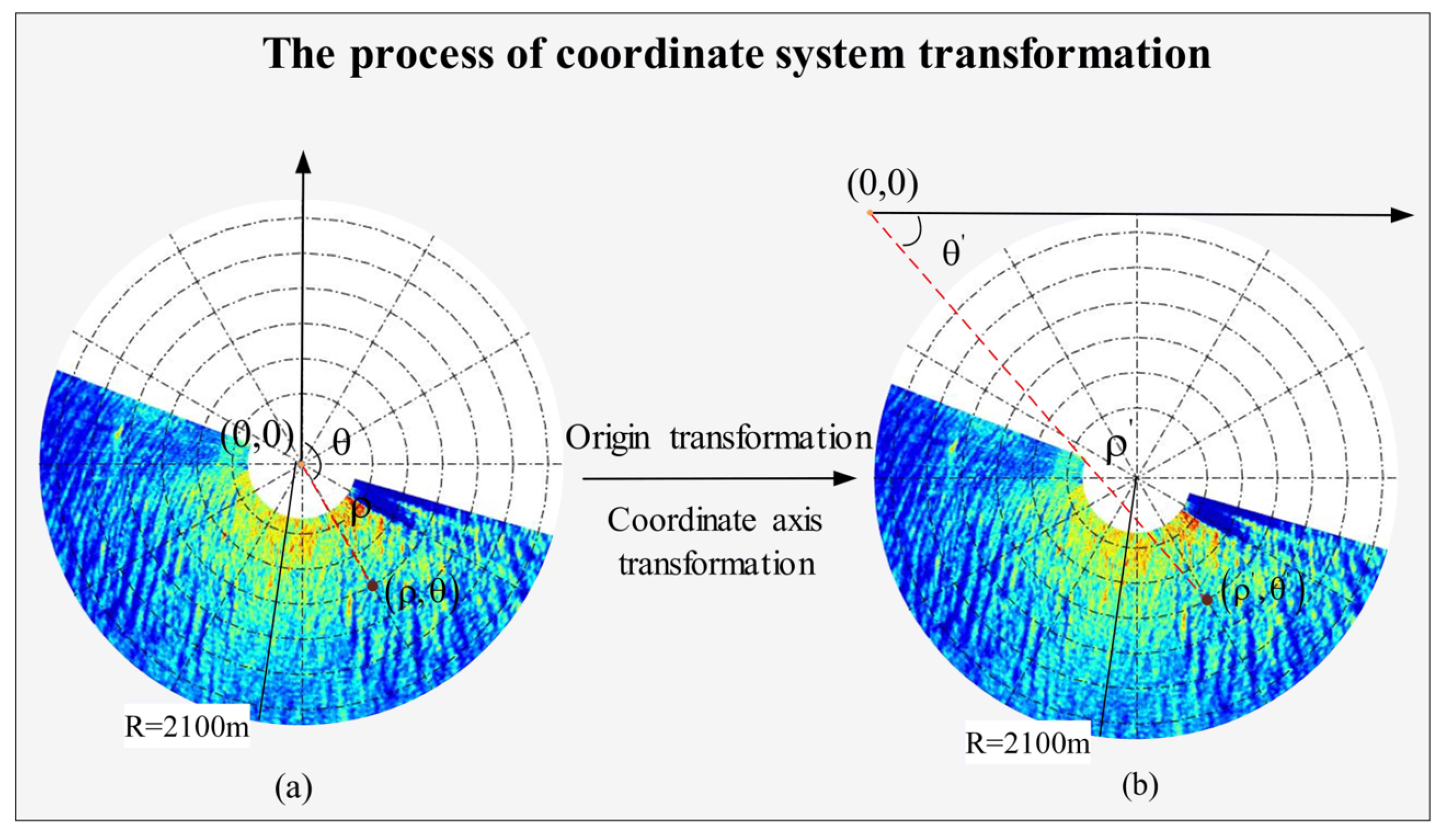
2.2.1. Co-Ordinate System Transformation
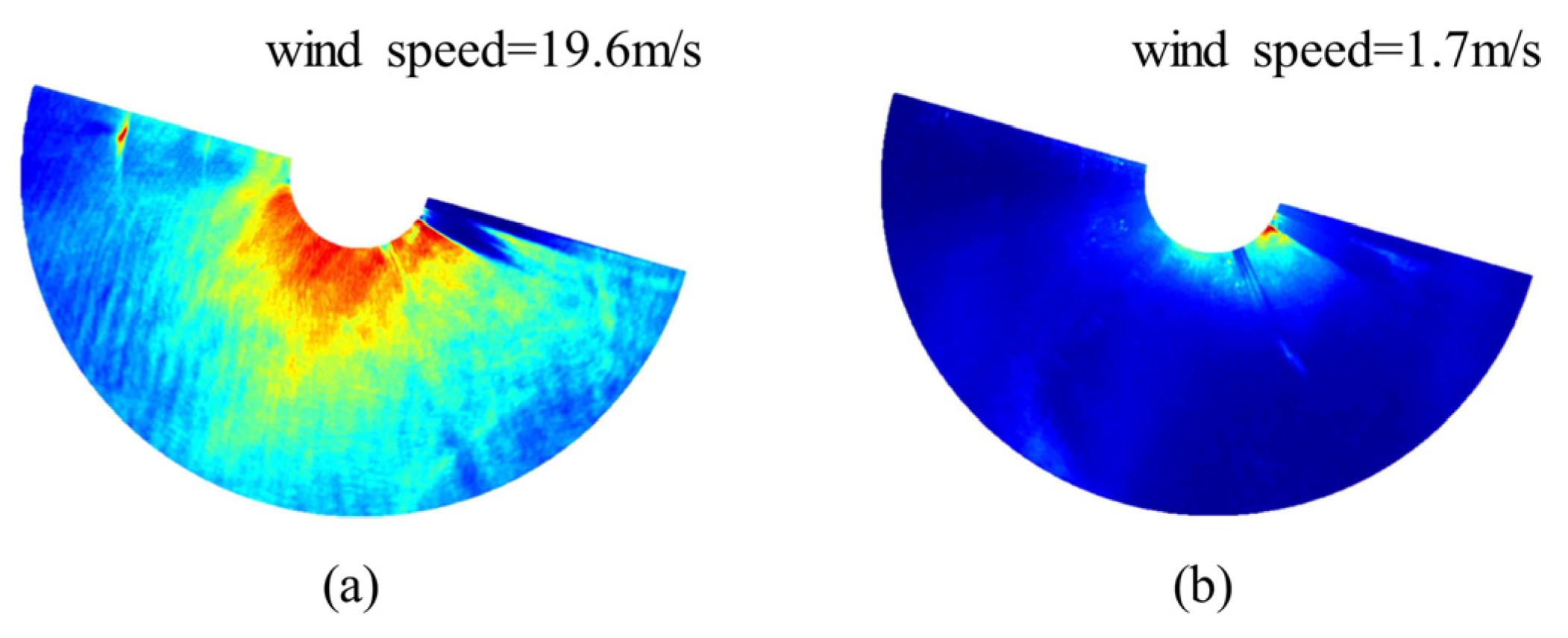
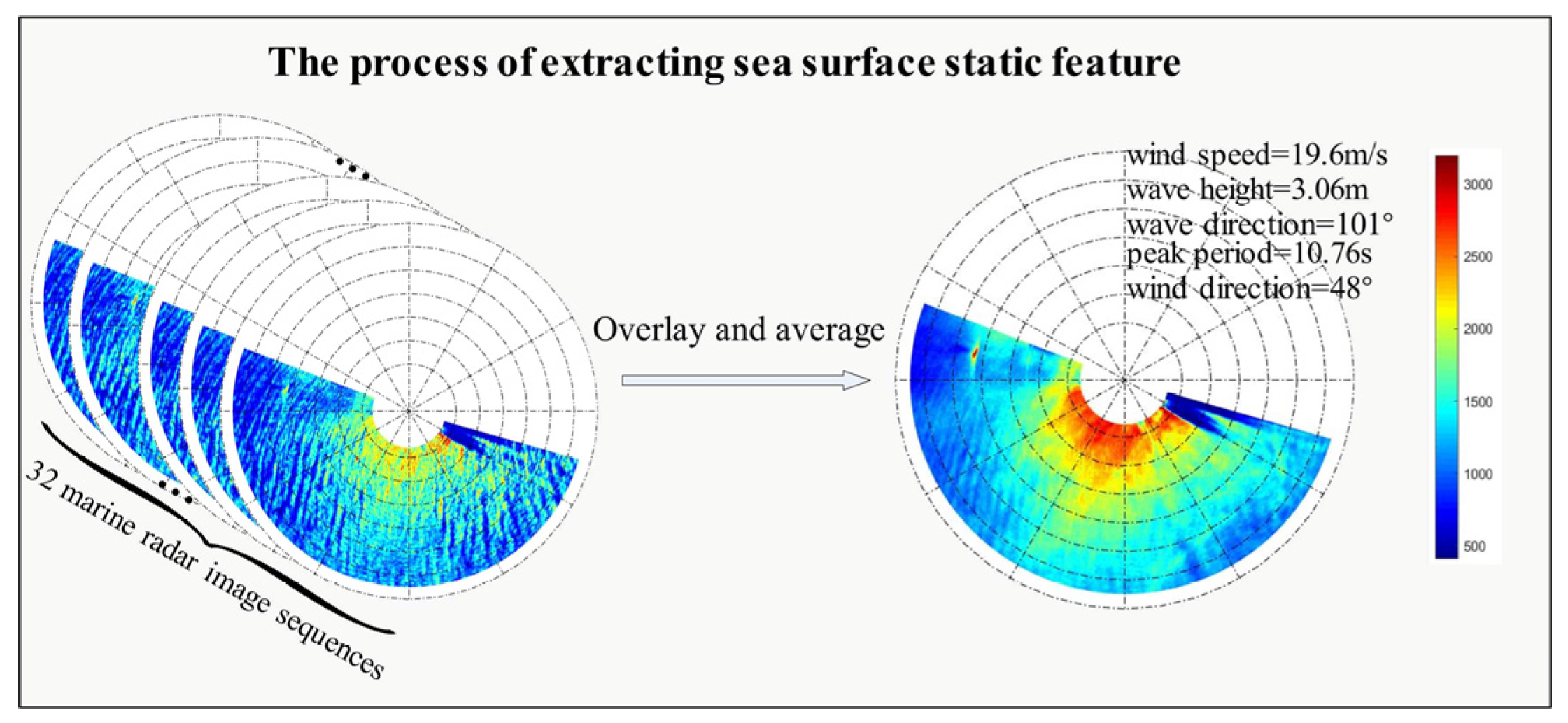
2.2.2. Process of Extracting Sea Surface Static Features
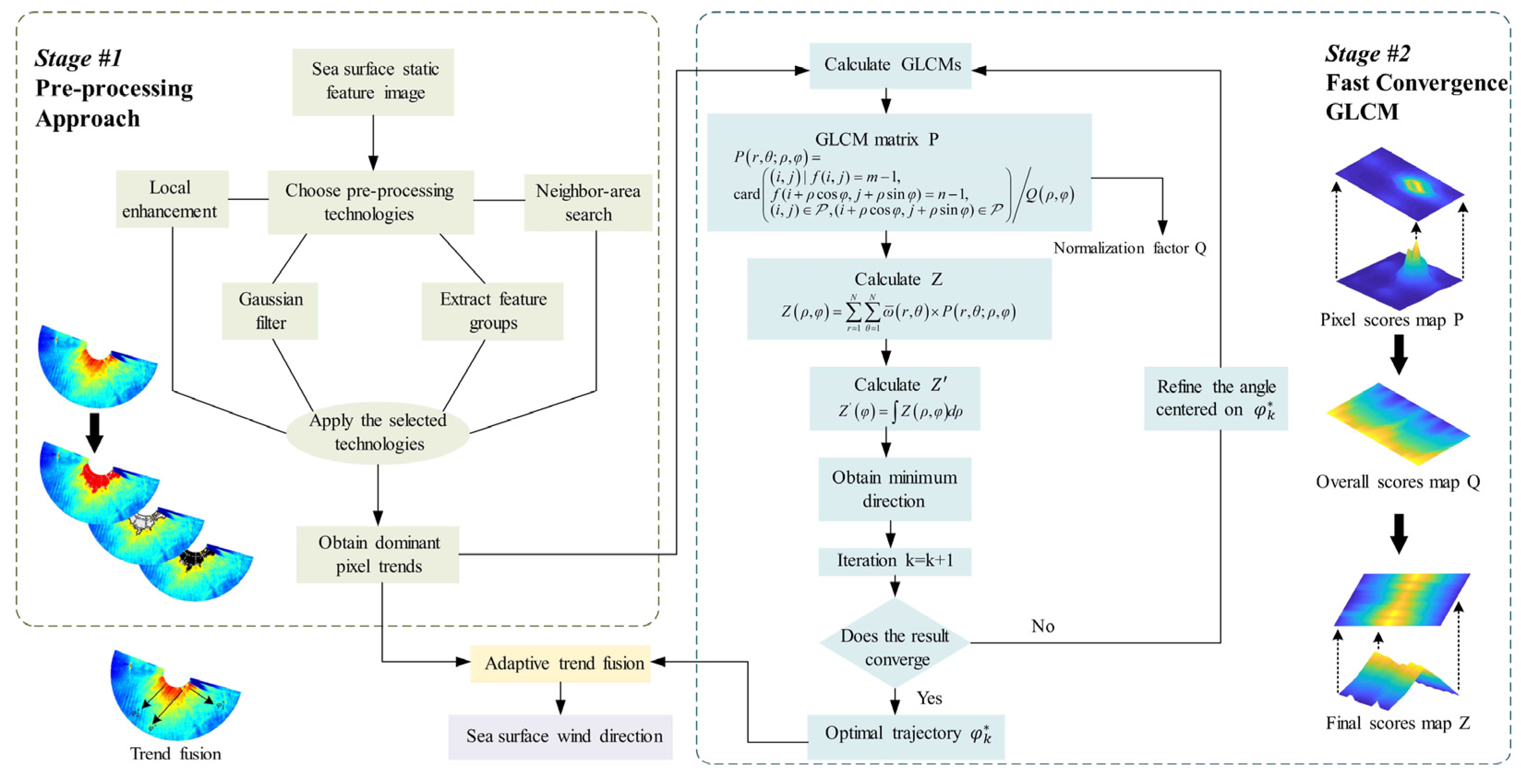
3. Sea Surface Wind Direction Extraction Algorithm
3.1. Image Preprocessing of Polar Co-Ordinate Sea Surface Static Features
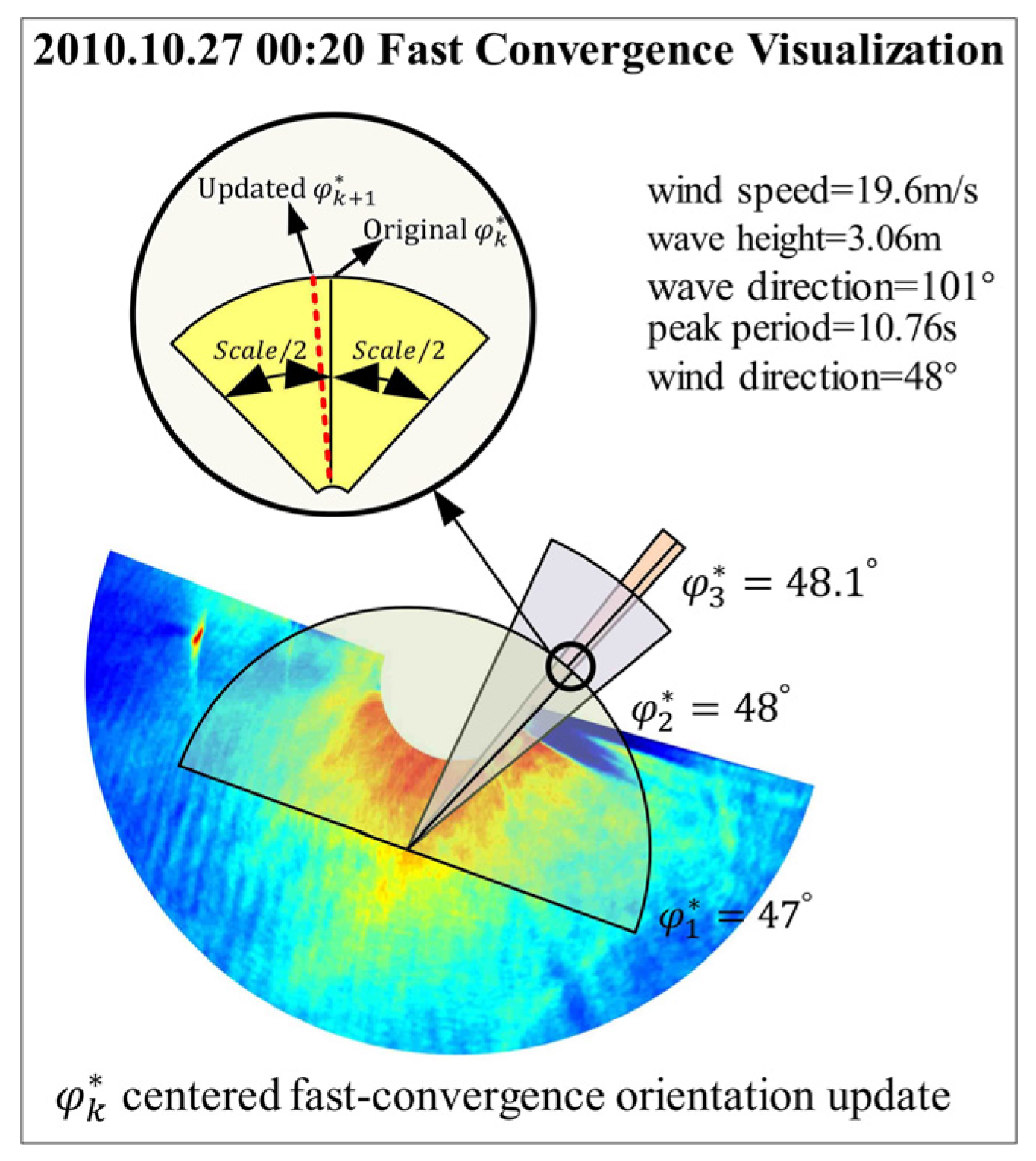
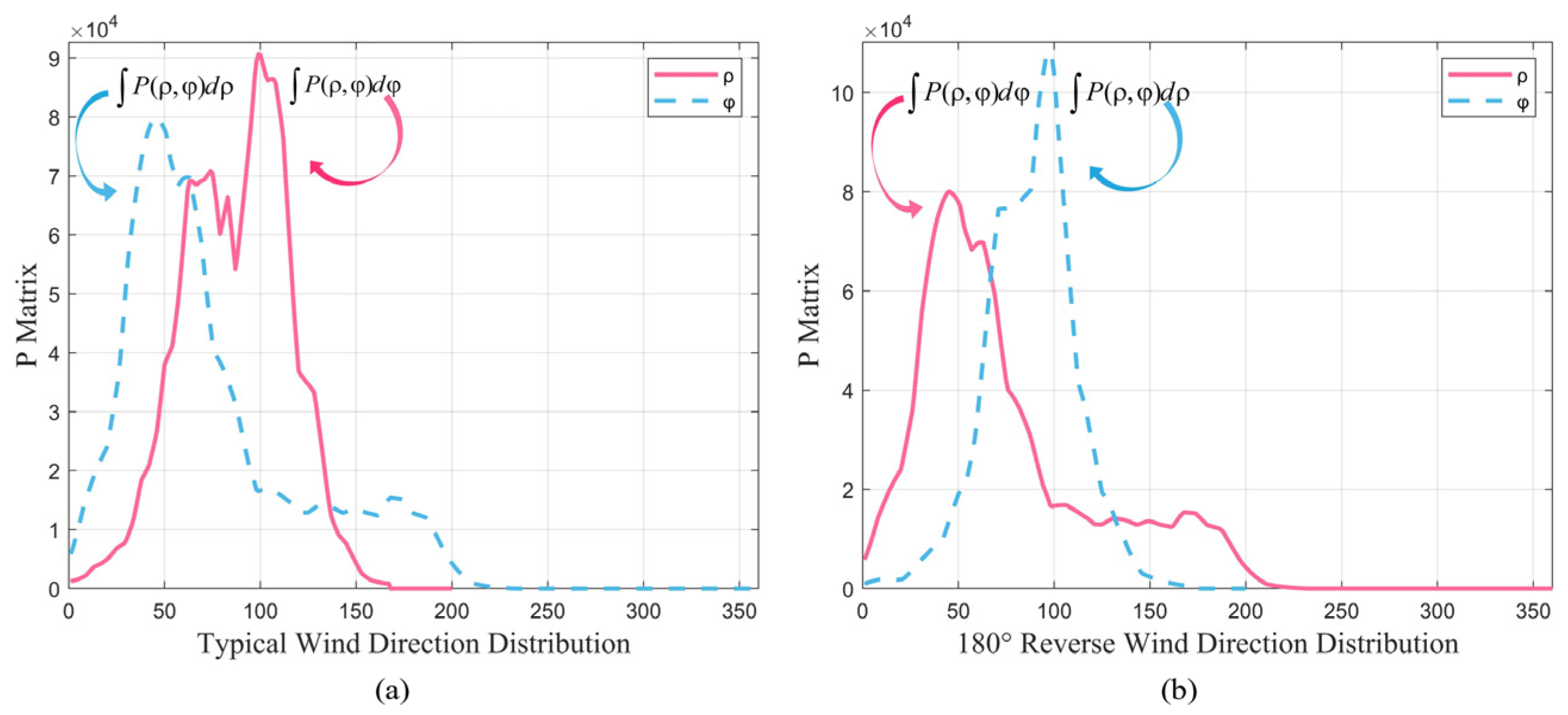
3.2. Fast-Convergence Gray-Level Co-Occurrence Matrix
3.3. How to Improve the Efficiency of the FC-GLCM
- Step 1: Interval Calculation
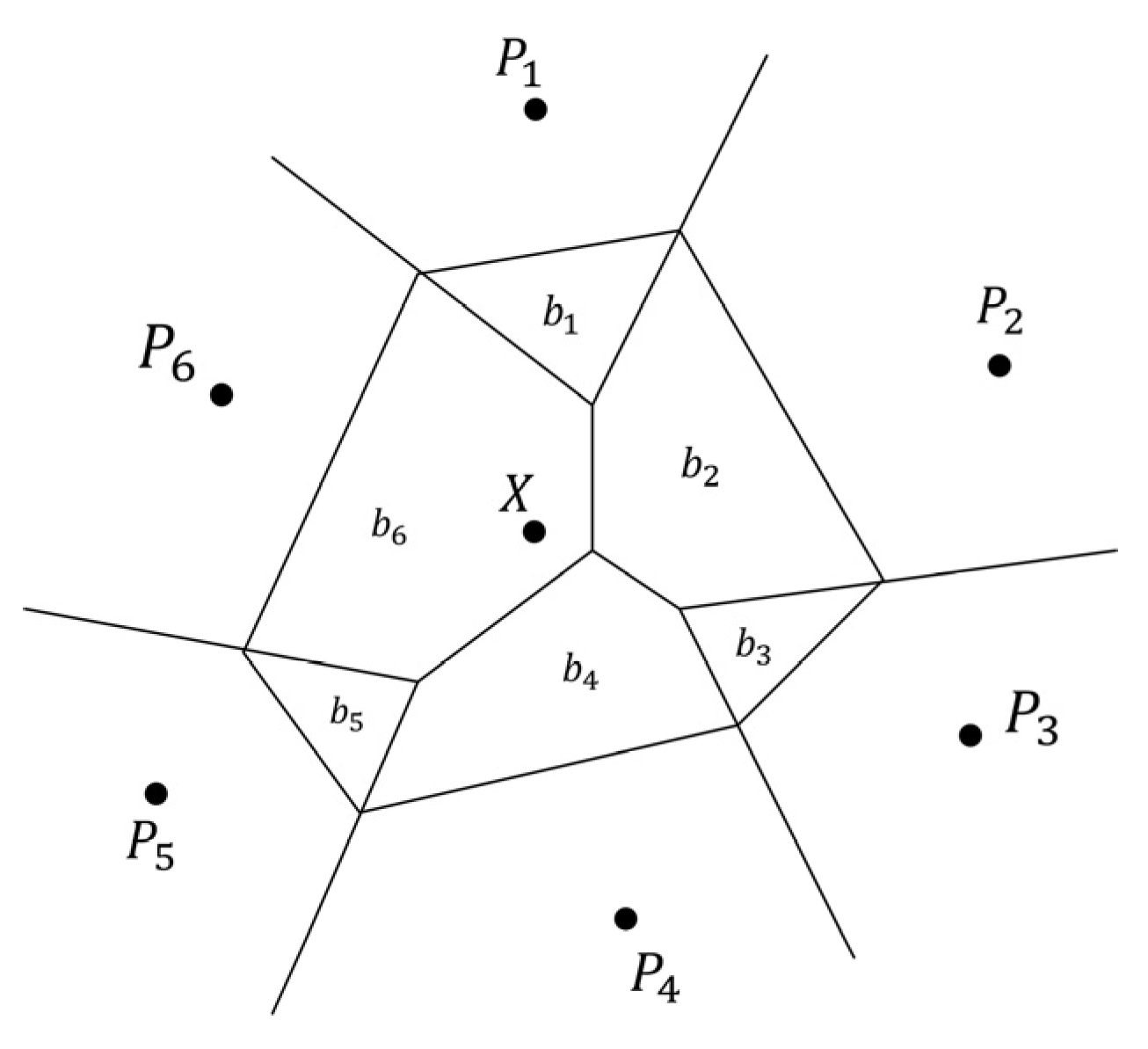
- Step 2: Interpolation Completion
3.4. Adaptive Trend Fusion
3.5. How to Resolve the 180° Ambiguity Problem
- Step 1: Create 360° augmented search domain
- Step 2: Coupling angle evaluation strategy
4. Experiments Results
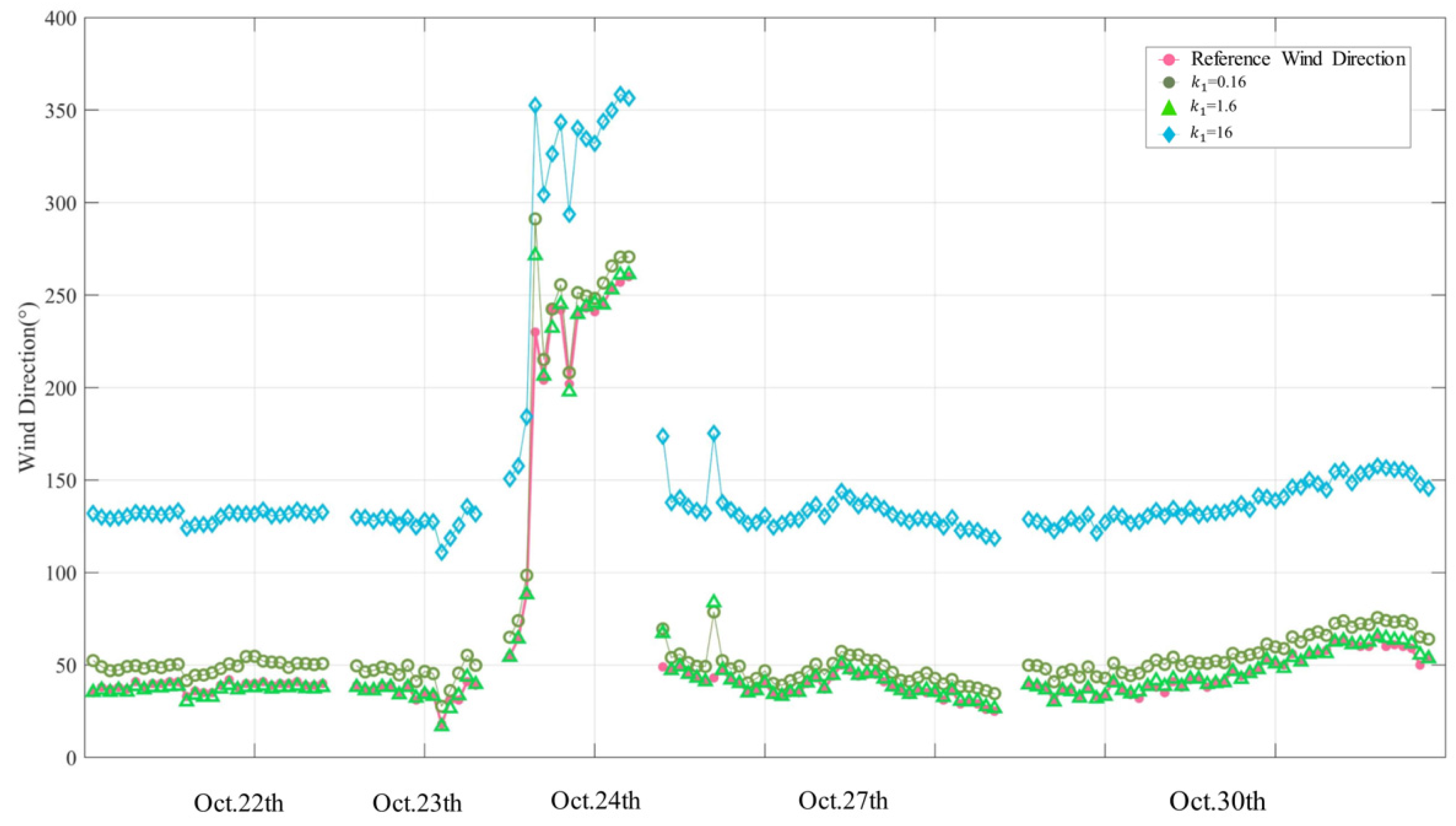
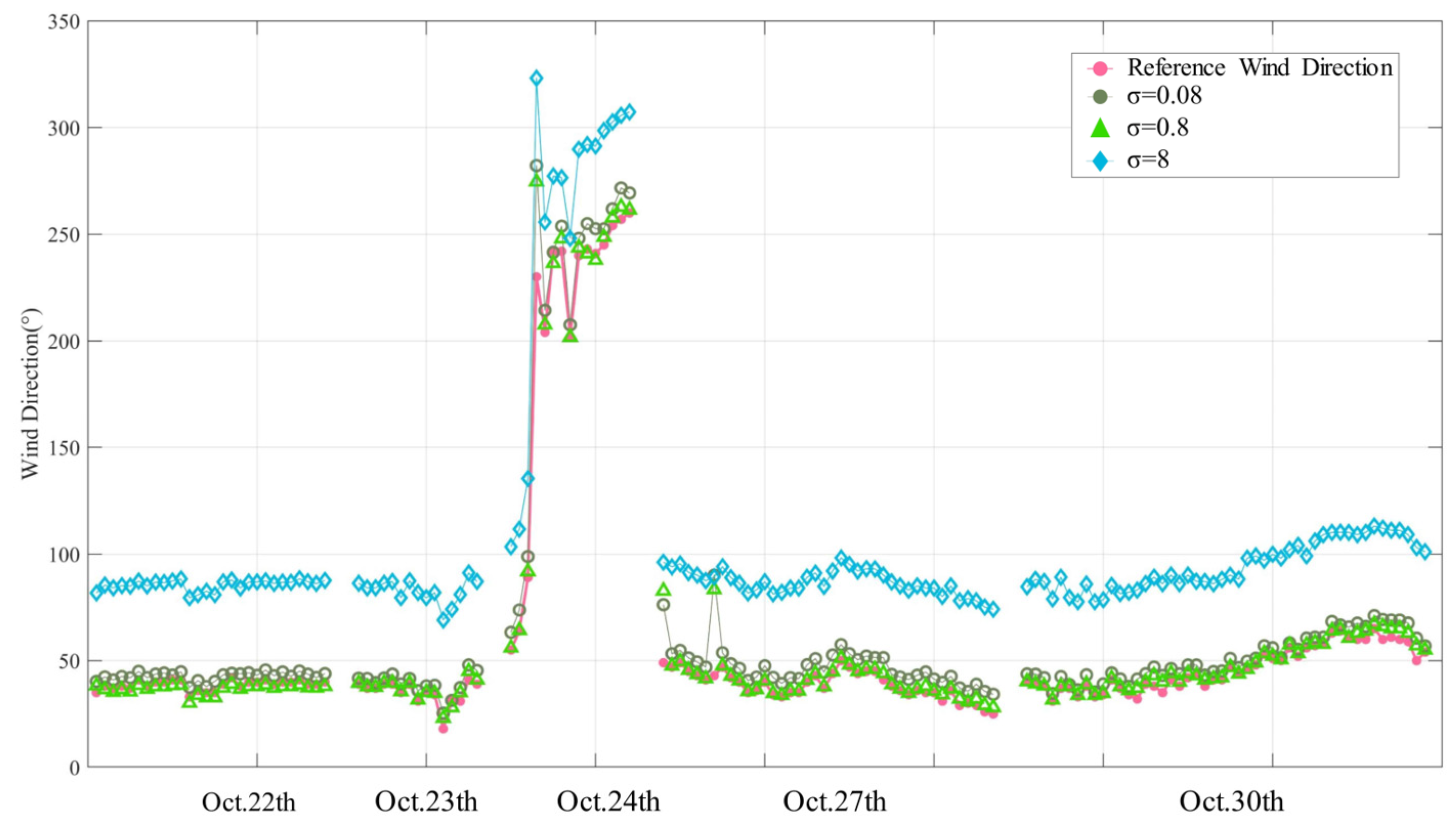
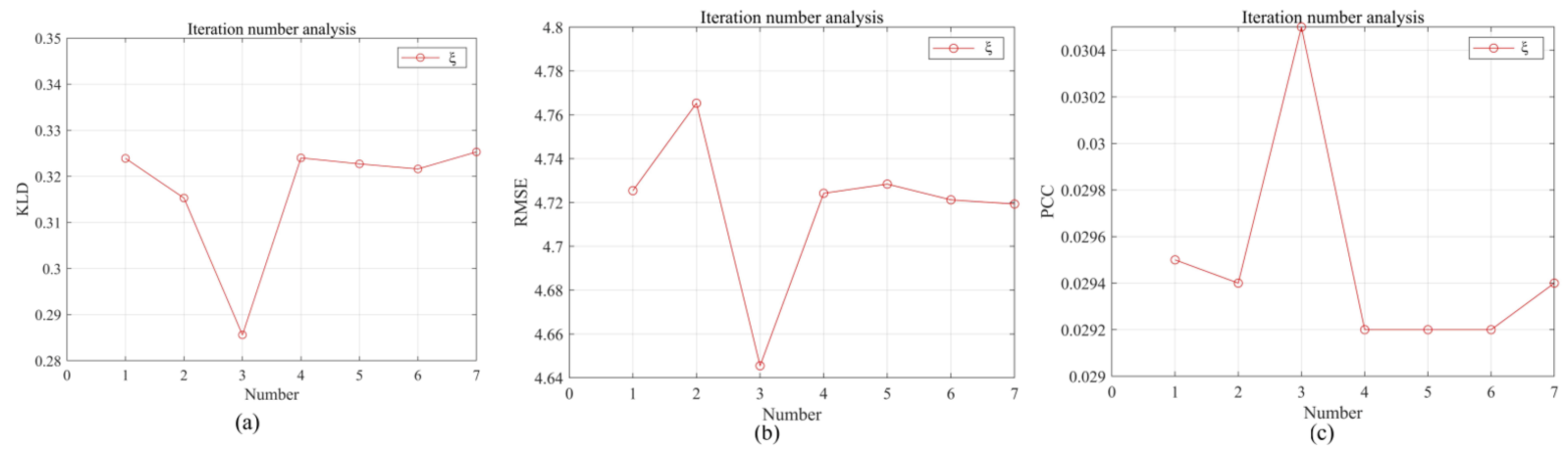
4.1. Sensitivity Analysis
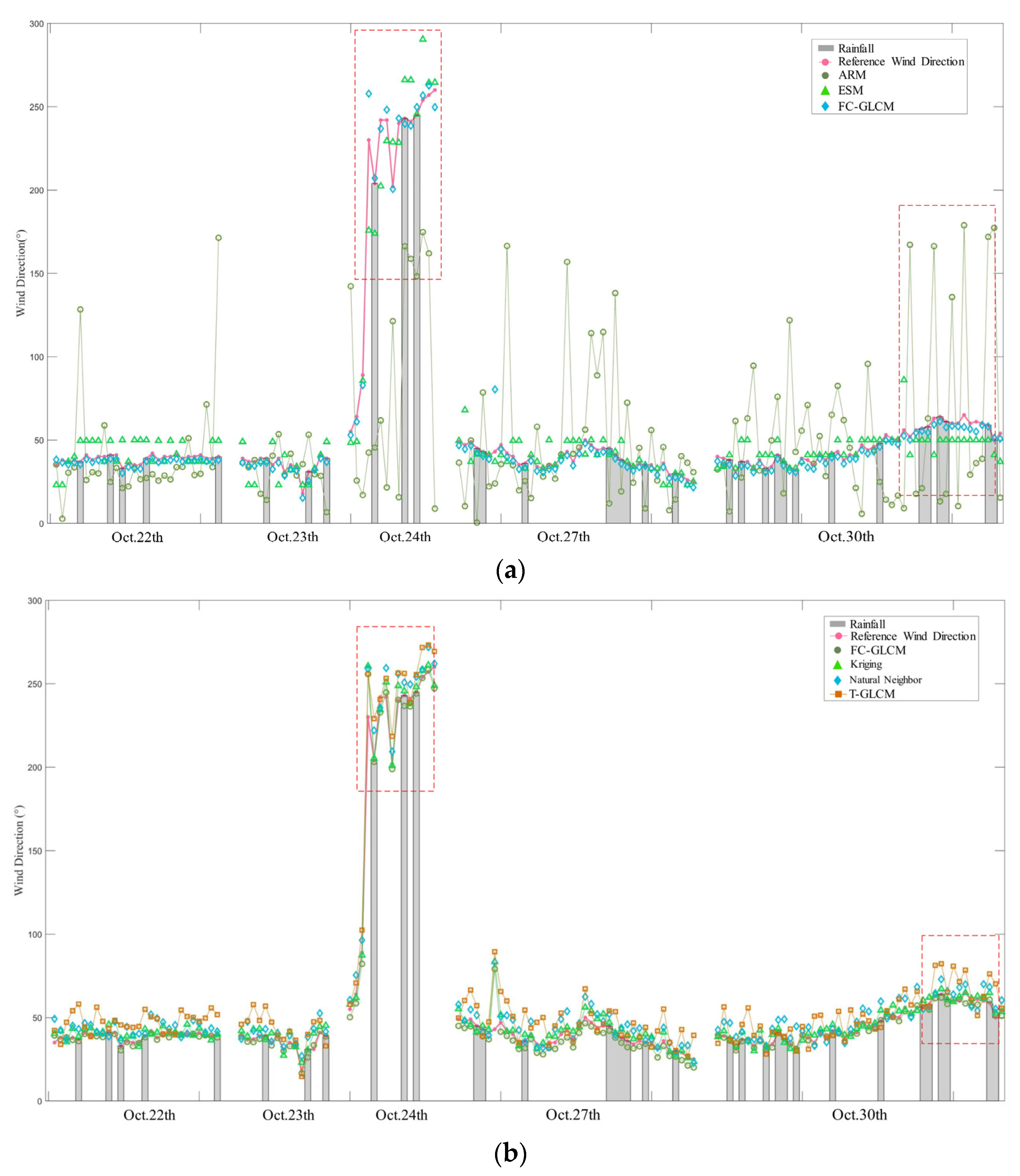
4.2. Accuracy Validation
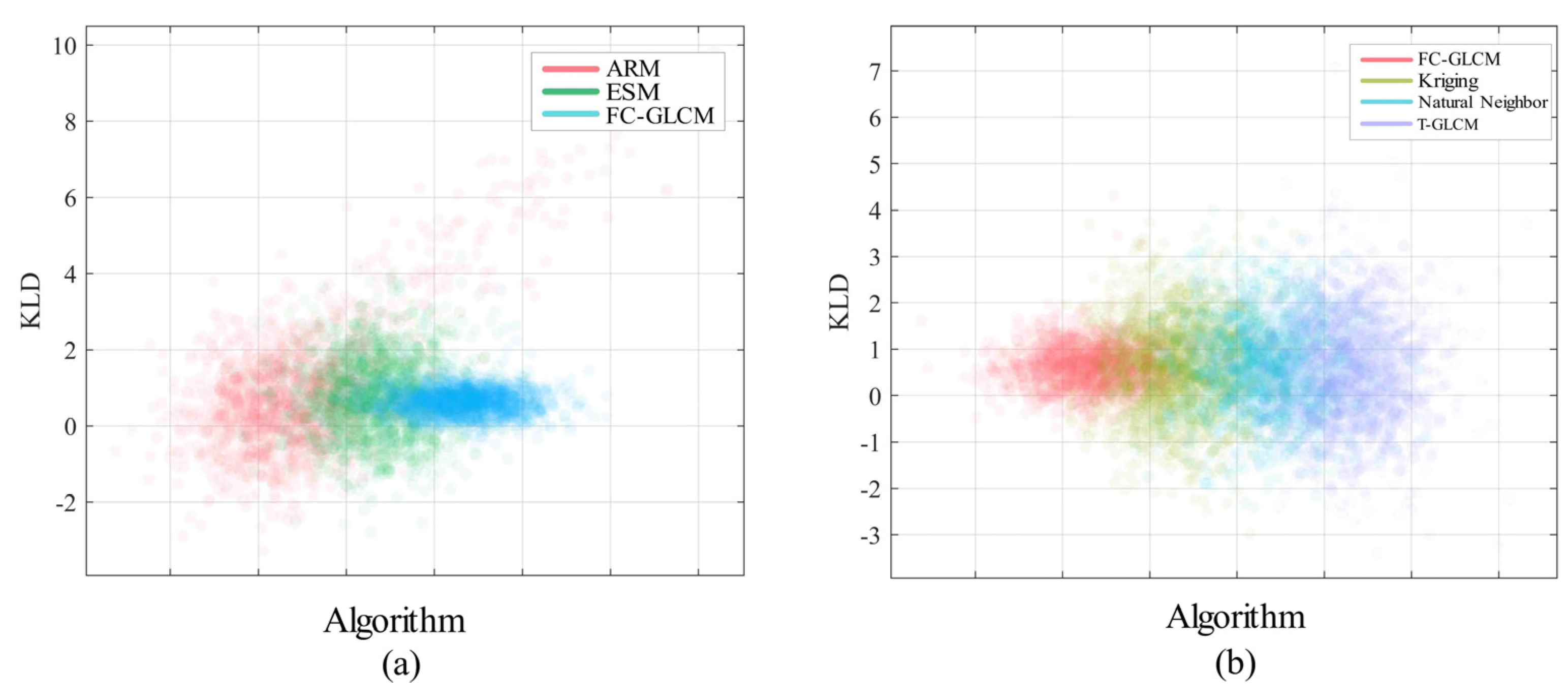
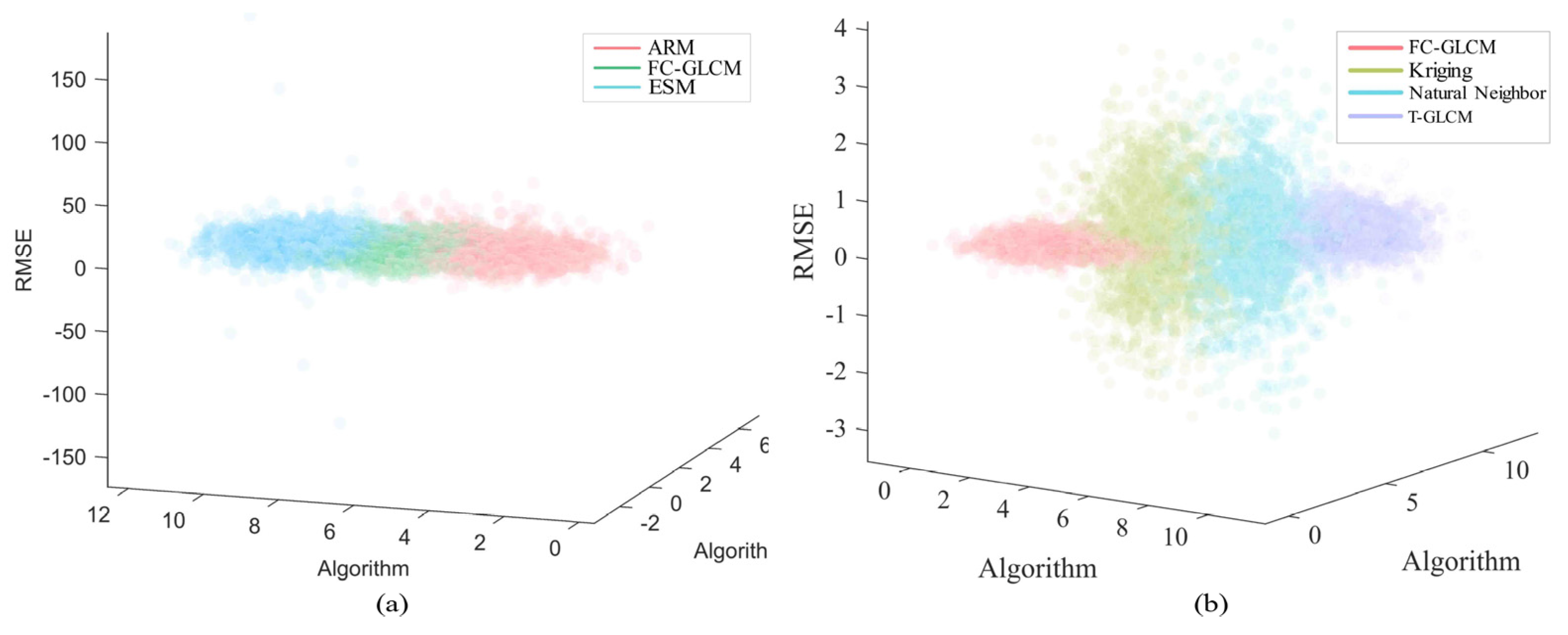
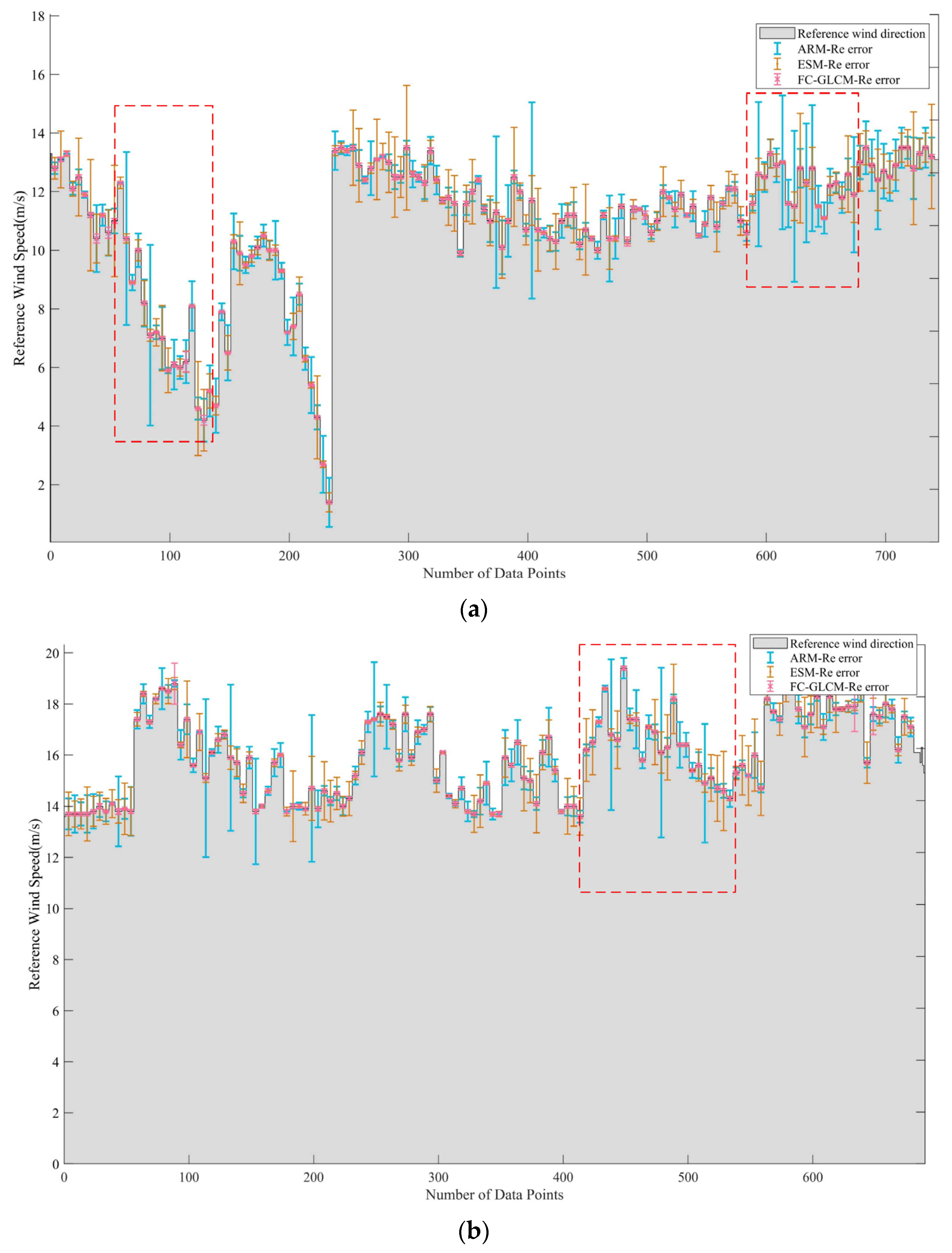
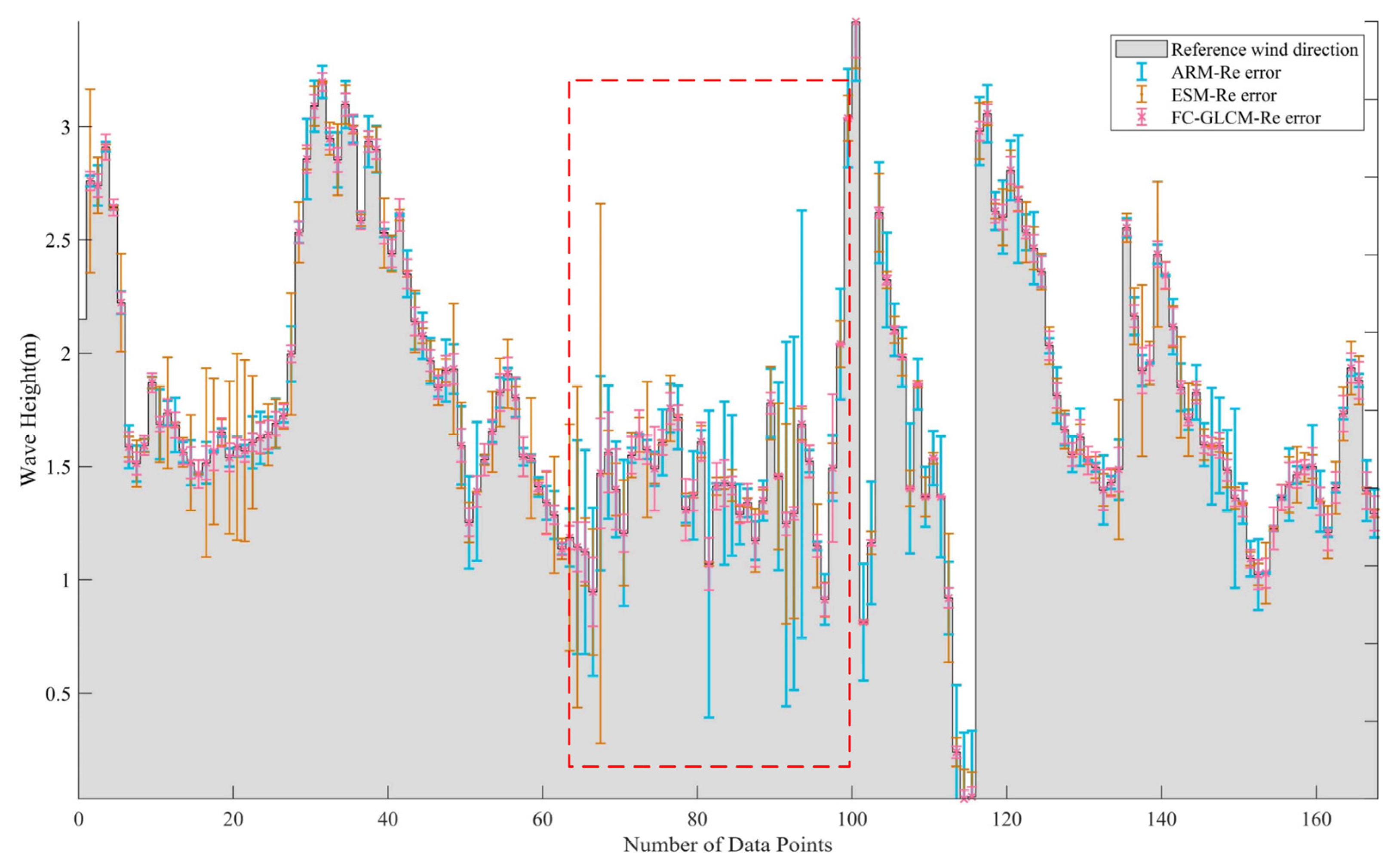
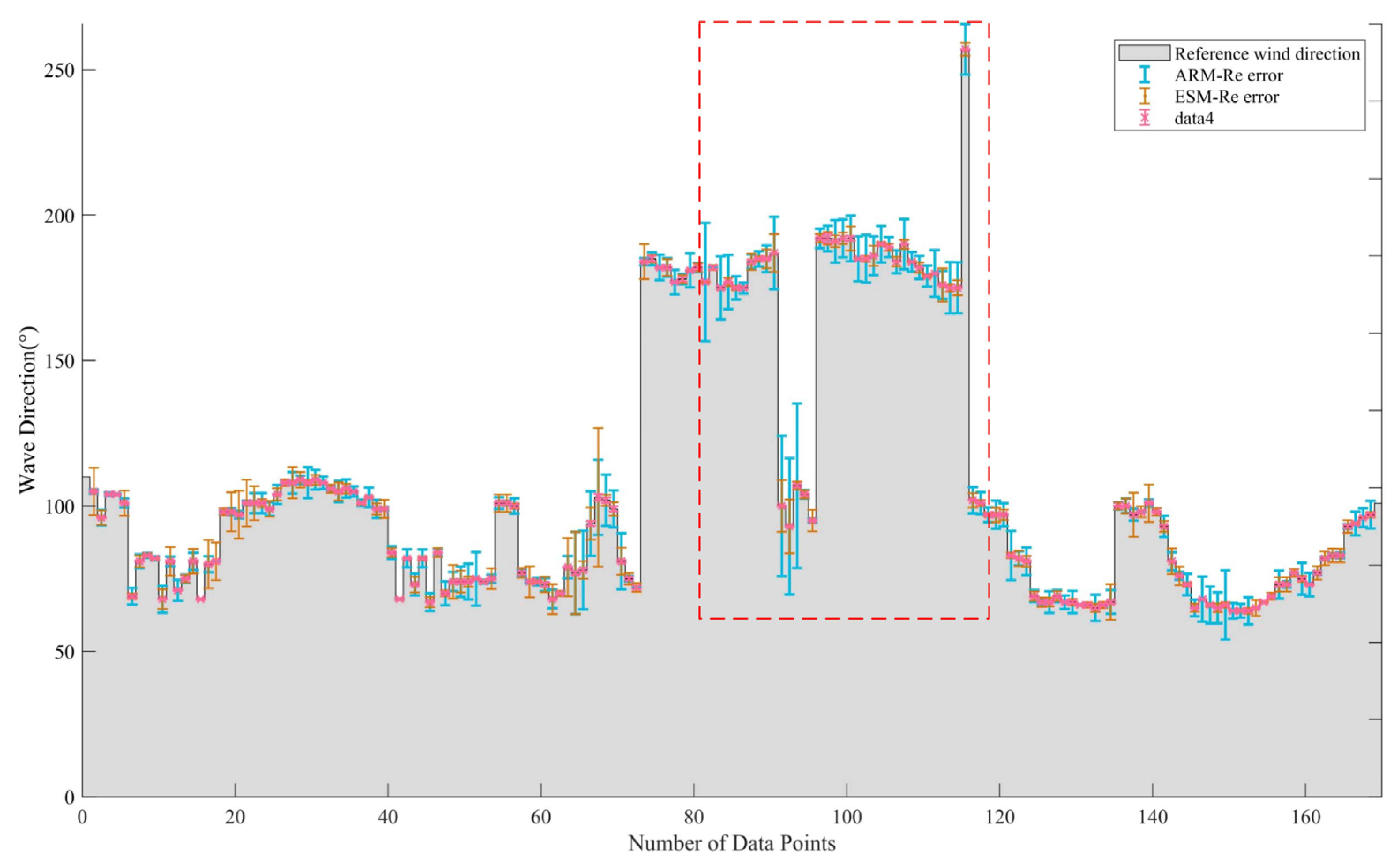
4.3. Robustness Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Sullivan, P.P.; McWilliams, J.C. Dynamics of winds and currents coupled to surface waves. Annu. Rev. Fluid Mech. 2010, 42, 19–42. [Google Scholar] [CrossRef]
- Chen, X.; Huang, W.; Haller, M.C. A novel scheme for extracting sea surface wind information from rain-contaminated X-band marine radar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5220–5234. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Zheng, Q.; Gu, X.; Pichel, W.G.; Li, Z. Comparison of ocean-surface winds retrieved from QuikSCAT scatterometer and Radarsat-1 SAR in offshore waters of the U.S. West Coast. IEEE Geosci. Remote Sens. Lett. 2011, 8, 163–167. [Google Scholar] [CrossRef]
- Atlas, R.; Hoffman, R.; Leidner, S.M.; Sienkiewicz, J.; Yu, T.-W.; Bloom, S.C.; Brin, E.; Ardizzone, J.; Terry, J.; Bungato, D.; et al. The effects of marine winds from scatterometer data on weather analysis and forecasting. Bull. Am. Meteorol. Soc. 2001, 82, 1965–1990. [Google Scholar] [CrossRef]
- Meissner, T.; Ricciardulli, L.; Wentz, F.J. Capability of the SMAP mission to measure ocean surface winds in storms. Bull. Am. Meteorol. Soc. 2017, 98, 1660–1677. [Google Scholar] [CrossRef]
- Zheng, G.; Yang, J.; Ren, L.; Zhou, W.; Huang, L. The preliminary cross-calibration of the HY-2A calibration microwave radiometer with the Jason-1/2 microwave radiometers. Int. J. Remote Sens. 2014, 35, 4515–4531. [Google Scholar] [CrossRef]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An anchor-free detection method for ship targets in high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- Chen, X.; Huang, W. Spatial–temporal convolutional gated recurrent unit network for significant wave height estimation from shipborne marine radar data. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4201711. [Google Scholar] [CrossRef]
- Huang, W.; Carrasco, R.; Shen, C.; Gill, E.W.; Horstmann, J. Surface current measurements using X-band marine radar with vertical polarization. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2988–2997. [Google Scholar] [CrossRef]
- Chen, X.; Huang, W.; Haller, M.C.; Pittman, R. Rain-contaminated region segmentation of X-band marine radar images with an ensemble of SegNets. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 141–154. [Google Scholar] [CrossRef]
- Horstmann, J.; Bödewadt, J.; Carrasco, R.; Cysewski, M.; Seemann, J.; Streβer, M. A coherent on receive X-band marine radar for ocean observations. Sensors 2021, 21, 7828. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.Y.; Liu, F.M.; Lu, Z. Estimation of steady-state wind direction and speed on ship surface based on radar wind measurement combination. J. Harbin Eng. Univ. 2022, 43, 235–242. [Google Scholar]
- Huang, W.; Liu, X.; Gill, E.W. Ocean wind and wave measurements using X-band marine radar: A comprehensive review. Remote Sens. 2017, 9, 1261. [Google Scholar] [CrossRef]
- Hatten, H.; Seemann, J.; Horstmann, J.; Ziemer, F. Azimuthal dependence of the radar cross section and the spectral background noise of a nautical radar at grazing incidence. Int. Geosci. Remote Sens. Symp. 1998, 5, 2490–2492. [Google Scholar]
- Lund, B.; Graber, H.C.; Romeiser, R. Wind retrieval from shipborne marine X-band radar data. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3800–3811. [Google Scholar] [CrossRef]
- Liu, X.; Huang, W.; Gill, E.W. Wind Direction Estimation from Rain-Contaminated Marine Radar Data Using the Ensemble Empirical Mode Decomposition Method. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1833–1841. [Google Scholar] [CrossRef]
- Chen, X.; Huang, W.; Zhao, C.; Tian, Y. Rain detection from X-band marine radar images: A support vector machine-based approach. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2115–2123. [Google Scholar] [CrossRef]
- Chen, X.; Huang, W. Identification of Rain and Low-Backscatter Regions in X-Band Marine Radar Images: An Unsupervised Approach. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4225–4236. [Google Scholar] [CrossRef]
- Dankert, H.; Horstmann, J.; Rosenthal, W. Ocean wind fields retrieved from radar-image sequences. J. Geophys. Res. Ocean 2003, 108, 2150–2152. [Google Scholar] [CrossRef]
- Dankert, H.; Horstmann, J. Wind measurements at FINO-I marine radar image sequences. Int. Geosci. Remote Sens. Symp. 2005, 7, 4777–4780. [Google Scholar]
- Sourice, A.; Plantier, G.; Saumet, J.-L. Autocorrelation fitting for texture orientation estimation. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–18 September 2003; Volume 1, pp. I-281–I-284. [Google Scholar]
- Jafari-Khouzani, K.; Soltanian-Zadeh, H. Radon transform orientation estimation for rotation invariant texture analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1004–1008. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Mai, X.; Wu, X. Rotation invariant texture classification with dominant orientation estimation based on Gabor filters. In Proceedings of the 2011 IEEE International Conference on Computer Science and Automation Engineering, Shanghai, China, 10–12 June 2011; Volume 1, pp. 606–609. [Google Scholar]
- Lefebvre, A.; Corpetti, T.; Moy, L.H. Estimation of the orientation of textured patterns via wavelet analysis. Pattern Recognit. Lett. 2011, 32, 190–196. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, W. An Algorithm for Wind Direction Retrieval from X-Band Marine Radar Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 252–256. [Google Scholar] [CrossRef]
- Wang, H.; Qiu, H.; Lu, Z.; Wang, L.; Akhtar, R.; Wei, Y. An Energy Spectrum Algorithm for Wind Direction Retrieval From X-Band Marine Radar Image Sequences. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4074–4088. [Google Scholar] [CrossRef]
- Zhou, L.; Zheng, G.; Li, X.; Yang, J.; Ren, L.; Chen, P.; Zhang, H.; Lou, X. An improved local gradient method for sea surface wind direction retrieval from SAR imagery. Remote Sens. 2017, 9, 671. [Google Scholar] [CrossRef]
- Dankert, H.; Horstmann, J.; Rosenthal, W. Ocean surface winds retrieved from marine radar-image sequences. Int. Geosci. Remote Sens. Symp. 2004, 3, 1903–1906. [Google Scholar]
- Dankert, H.; Horstmann, J. A marine radar wind sensor. J. Atmos. Ocean. Technol. 2007, 24, 1629–1642. [Google Scholar] [CrossRef]
- Wang, H.; Lu, Z. Determination of X-band radar images ocean wind direction using ARM. J. Huazhong Univ. Sci. Technol. 2015, 10, 42–47. [Google Scholar]
- Mohanaiah, P.; Sathyanarayana, P.; GuruKumar, L. Image texture feature extraction using GLCM approach. Int. J. Sci. Res. Publ. 2013, 5, 1–5. [Google Scholar]
- Li, B.; Xu, J.; Pan, X.; Ma, L.; Zhao, Z.; Chen, R.; Liu, Q.; Wang, H. Marine Oil Spill Detection with X-Band Shipborne Radar Using GLCM. Remote Sens. 2022, 15, 3715. [Google Scholar] [CrossRef]
- Zheng, G.; Li, X.; Zhou, L.; Yang, J.; Ren, L.; Chen, P.; Zhang, H.; Lou, X. Development of a gray-level co-occurrence matrix-based texture orientation estimation method and its application in sea surface wind direction retrieval from SAR imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5244–5260. [Google Scholar] [CrossRef]
- Wei, Y.; Liu, Y.; Song, H.; Lu, Z. A Method of Rainfall Detection from X-band Marine Radar Image Based on the Principal Component Feature Extracted. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Sun, L.; Lu, Z.; Wang, H.; Liu, H.; Shang, X. A Wave Texture Difference Method for Rainfall Detection Using X-Band Marine Radar. J. Sens. 2022, 2022, 1068885. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic Pixel-level Pavement Crack Detection Using Information of Multi-Scale Neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. ACM Trans. Graph. 2002, 21, 267–276. [Google Scholar] [CrossRef]
- Zamir, R.; Kochman, Y.; Erez, U. Achieving the Gaussian Rate-Distortion Function by Prediction. IEEE Trans. Inf. Theory 2008, 54, 3354–3364. [Google Scholar] [CrossRef]
- Parekh, R. Using texture analysis for medical diagnosis. IEEE Multimed. 2015, 19, 28–37. [Google Scholar] [CrossRef]
- Wcm, V.B.; Jpc, K. Kriging for interpolation in random simulation. J. Oper. Res. Soc. 2003, 54, 255–262. [Google Scholar]
- Yang, G.; Jian, Z. Data interpolation research based on the natural neighbor method. J. Univ. Chin. Acad. Sci. 2005, 22, 346. [Google Scholar]
- Wang, X.; Bai, S.; Li, Z.; Sui, Y.; Tao, J. The PAN and MS image fusion algorithm based on adaptive guided filtering and gradient information regulation. Inf. Sci. 2021, 545, 381–402. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step Title | FC-GLCM | Traditional GLCM |
|---|---|---|
| Preprocessing | - |
| 0.16 | 0.64 | 1.12 | 1.60 | 1.76 | 1.88 | 16.00 | |
|---|---|---|---|---|---|---|---|
| KLD | 0.9742 | 0.8788 | 0.7600 | 0.6954 | 0.7380 | 2.3865 | 4.5658 |
| RMSE (°) | 11.0756 | 8.4816 | 5.0022 | 4.3236 | 4.3669 | 47.3704 | 92.8893 |
| PCC | 0.0289 | 0.0288 | 0.0291 | 0.0301 | 0.0293 | 0.0291 | 0.0292 |
| 0.08 | 0.32 | 0.56 | 0.80 | 0.88 | 4.40 | 8.00 | |
|---|---|---|---|---|---|---|---|
| KLD | 0.8758 | 0.8294 | 0.7839 | 0.7277 | 0.7652 | 1.5085 | 2.4246 |
| RMSE (°) | 7.6117 | 6.3330 | 5.2913 | 5.2017 | 5.3398 | 25.3538 | 48.0796 |
| PCC | 0.0293 | 0.0293 | 0.0291 | 0.0295 | 0.0291 | 0.0295 | 0.0292 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| KLD | 0.3239 | 0.3153 | 0.2856 | 0.3240 | 0.3227 | 0.3216 | 0.3253 |
| RMSE (°) | 4.7254 | 4.7653 | 4.6455 | 4.7242 | 4.7284 | 4.7212 | 4.7193 |
| PCC | 0.0295 | 0.0294 | 0.0305 | 0.0292 | 0.0292 | 0.0292 | 0.0294 |
| Method | KLD | RMSE (°) | PCC | Computing Time(s) |
|---|---|---|---|---|
| ARM | 0.9516 | 59.3512 | 0.3112 | 25.2679 |
| ESM | 0.7699 | 15.4349 | 0.9122 | 18.4831 |
| FC-GLCM | 0.6404 | 4.9867 | 0.9268 | 9.1391 |
| Kriging | 0.6137 | 5.4483 | 0.9267 | 7.2608 |
| Natural Neighbor | 0.6182 | 5.3769 | 0.9267 | 6.7746 |
| T-GLCM | 0.6713 | 6.0533 | 0.9265 | 15.9731 |
| Sea Condition | Indicator | ARM | ESM | T-GLCM | FC-GLCM |
|---|---|---|---|---|---|
| Weak Wind | KLD | 0.9361 | 0.7735 | 0.6054 | 0.4518 |
| RMSE (°) | 74.7396 | 19.7976 | 6.9043 | 4.4738 | |
| PCC | 0.3545 | 0.9140 | 0.9252 | 0.9277 | |
| Strong Wind | KLD | 0.9670 | 0.7655 | 0.6114 | 0.5124 |
| RMSE (°) | 35.8954 | 8.4672 | 6.0449 | 4.4738 | |
| PCC | 0.2081 | 0.3978 | 0.8289 | 0.8395 | |
| Wave Height | KLD | 0.8931 | 0.7906 | 0.5987 | 0.4523 |
| RMSE (°) | 56.4481 | 10.7277 | 6.3990 | 5.2223 | |
| PCC | 0.4723 | 0.9158 | 0.9169 | 0.9272 | |
| Wave Direction | KLD | 0.8931 | 0.7906 | 0.5987 | 0.4523 |
| RMSE (°) | 56.4481 | 10.7321 | 6.3979 | 5.2222 | |
| PCC | 0.4733 | 0.9158 | 0.9169 | 0.9272 | |
| Rainfall | KLD | 2.3897 | 0.6503 | 0.6445 | 0.5579 |
| RMSE (°) | 91.2342 | 29.0755 | 6.5193 | 5.0167 | |
| PCC | -0.0322 | 0.8569 | 0.9061 | 0.9263 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Li, S.; Qiu, H.; Lu, Z.; Wei, Y.; Zhu, Z.; Ge, H. Development of a Fast Convergence Gray-Level Co-Occurrence Matrix for Sea Surface Wind Direction Extraction from Marine Radar Images. Remote Sens. 2023, 15, 2078. https://doi.org/10.3390/rs15082078
Wang H, Li S, Qiu H, Lu Z, Wei Y, Zhu Z, Ge H. Development of a Fast Convergence Gray-Level Co-Occurrence Matrix for Sea Surface Wind Direction Extraction from Marine Radar Images. Remote Sensing. 2023; 15(8):2078. https://doi.org/10.3390/rs15082078
Chicago/Turabian StyleWang, Hui, Shiyu Li, Haiyang Qiu, Zhizhong Lu, Yanbo Wei, Zhiyu Zhu, and Huilin Ge. 2023. "Development of a Fast Convergence Gray-Level Co-Occurrence Matrix for Sea Surface Wind Direction Extraction from Marine Radar Images" Remote Sensing 15, no. 8: 2078. https://doi.org/10.3390/rs15082078
APA StyleWang, H., Li, S., Qiu, H., Lu, Z., Wei, Y., Zhu, Z., & Ge, H. (2023). Development of a Fast Convergence Gray-Level Co-Occurrence Matrix for Sea Surface Wind Direction Extraction from Marine Radar Images. Remote Sensing, 15(8), 2078. https://doi.org/10.3390/rs15082078