
A Single Array Approach for Infrasound Signal Discrimination from Quarry Blasts via Machine Learning

Abstract
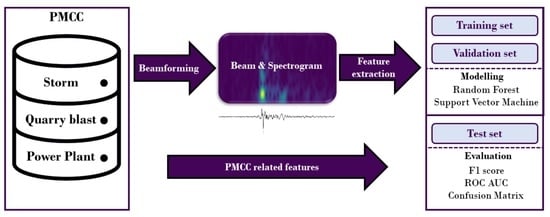
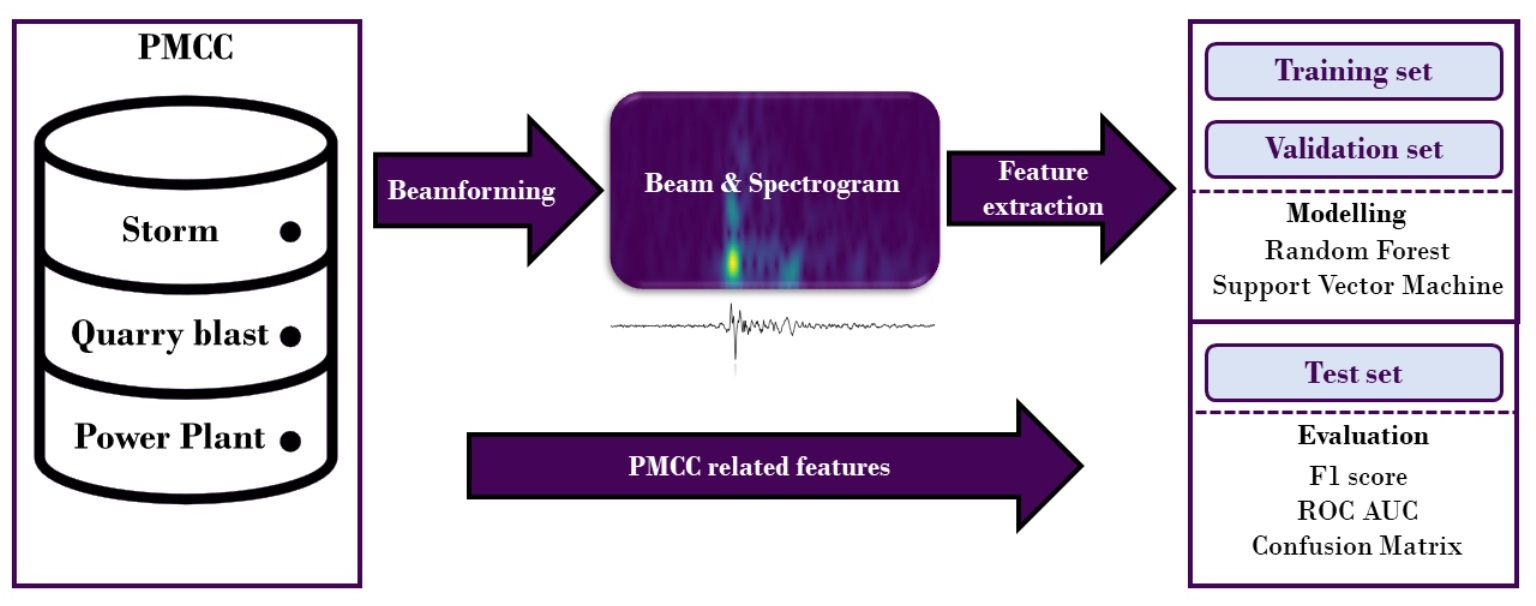
1. Introduction
2. Materials and Methods
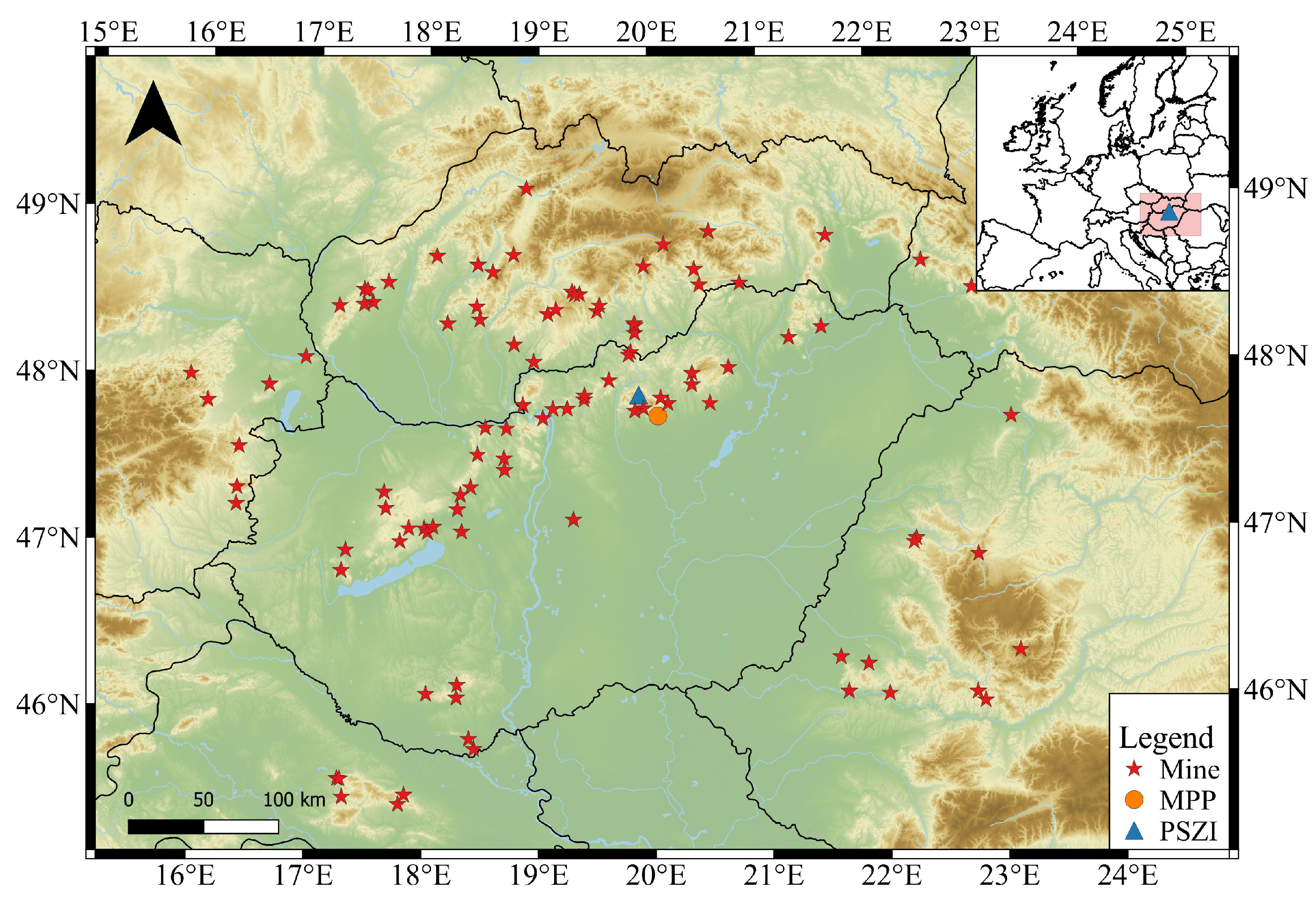
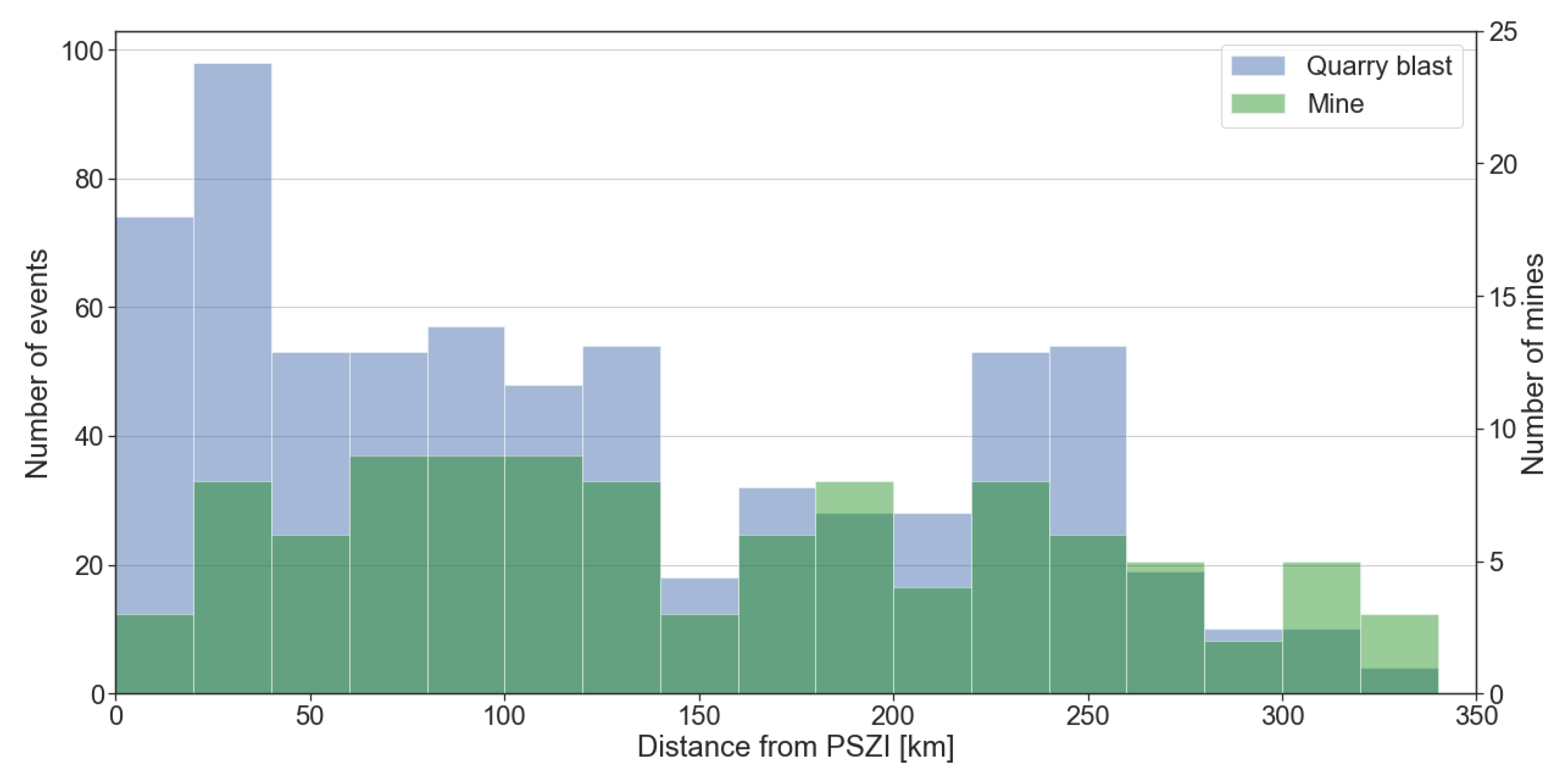
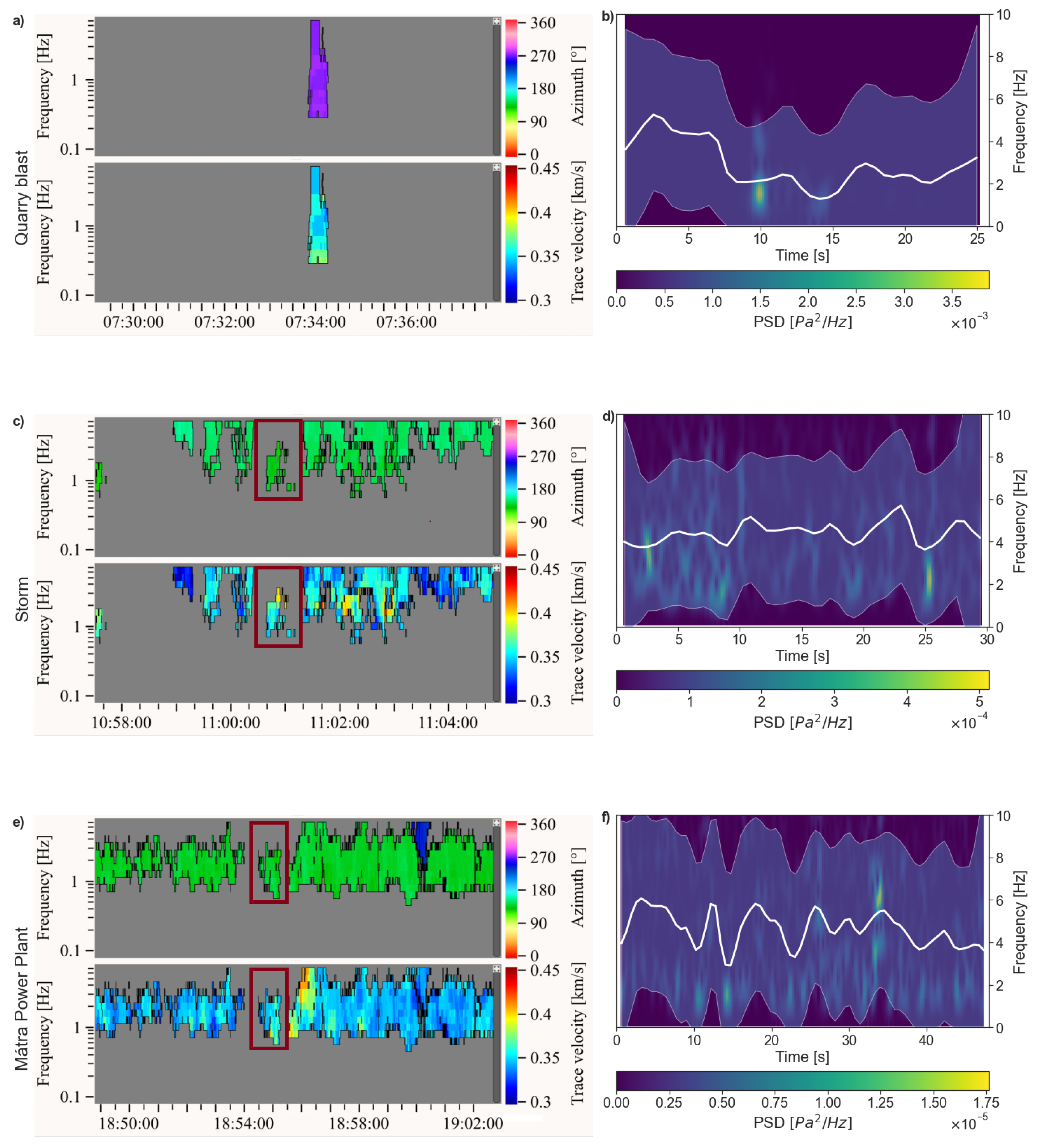
2.1. Data
2.2. Pre-Processing
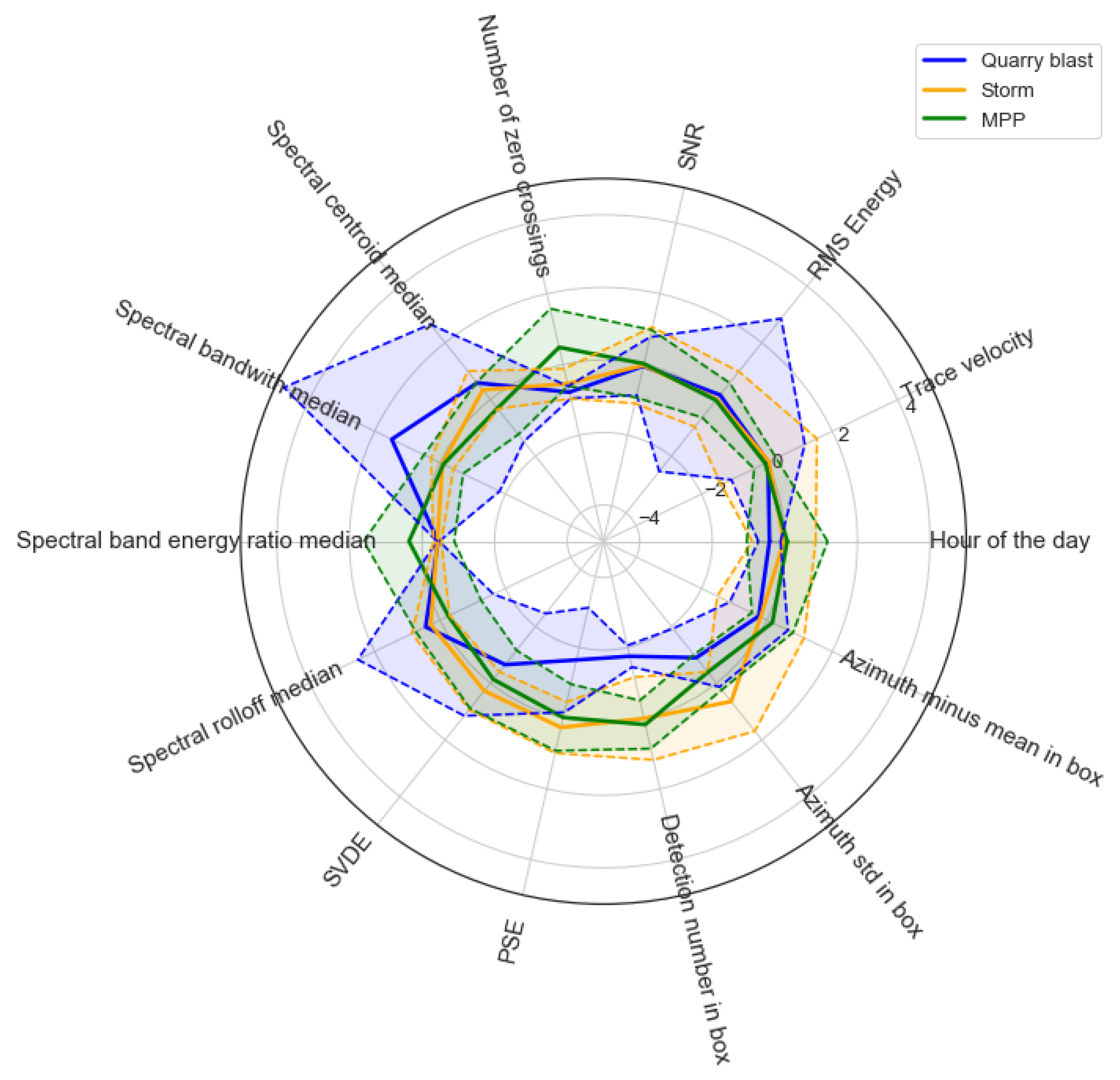
2.3. Feature Extraction
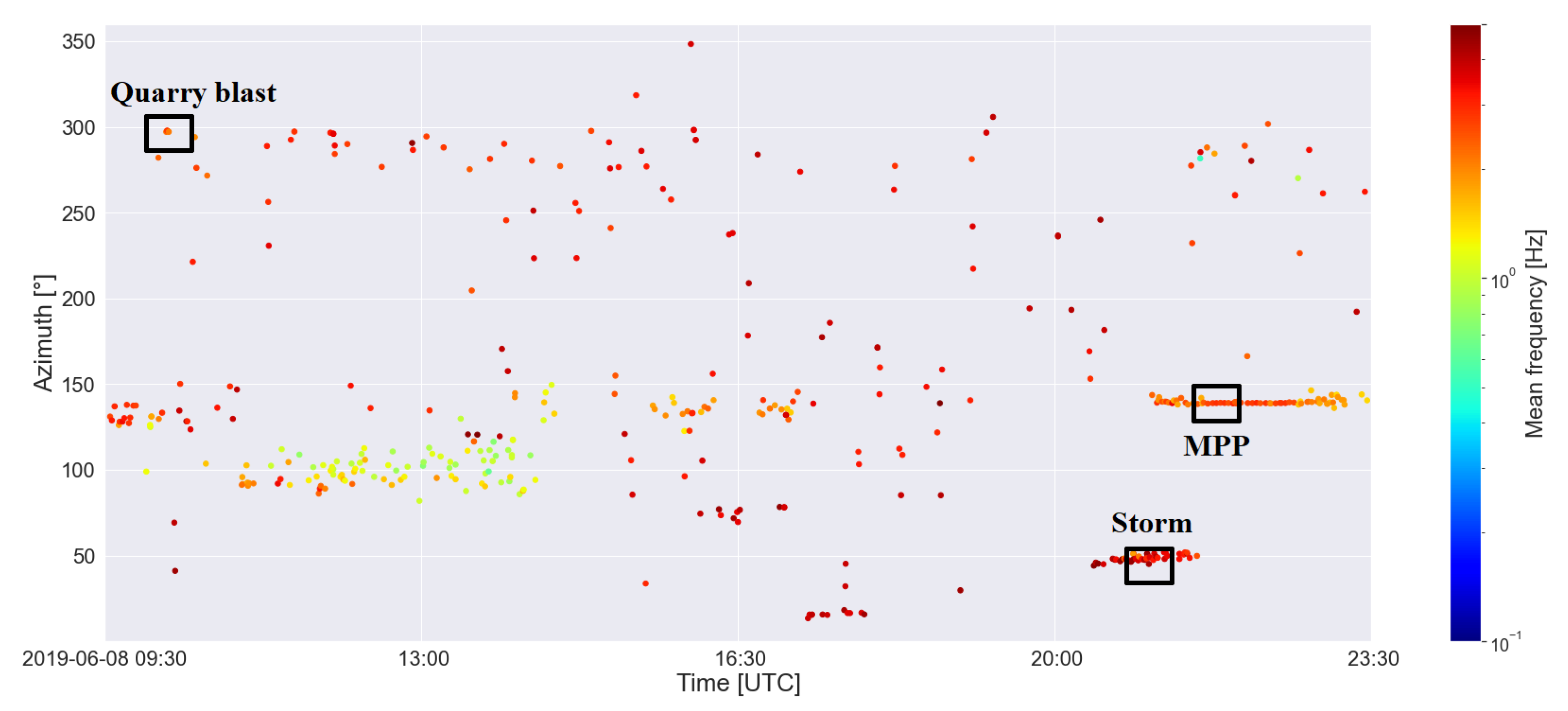
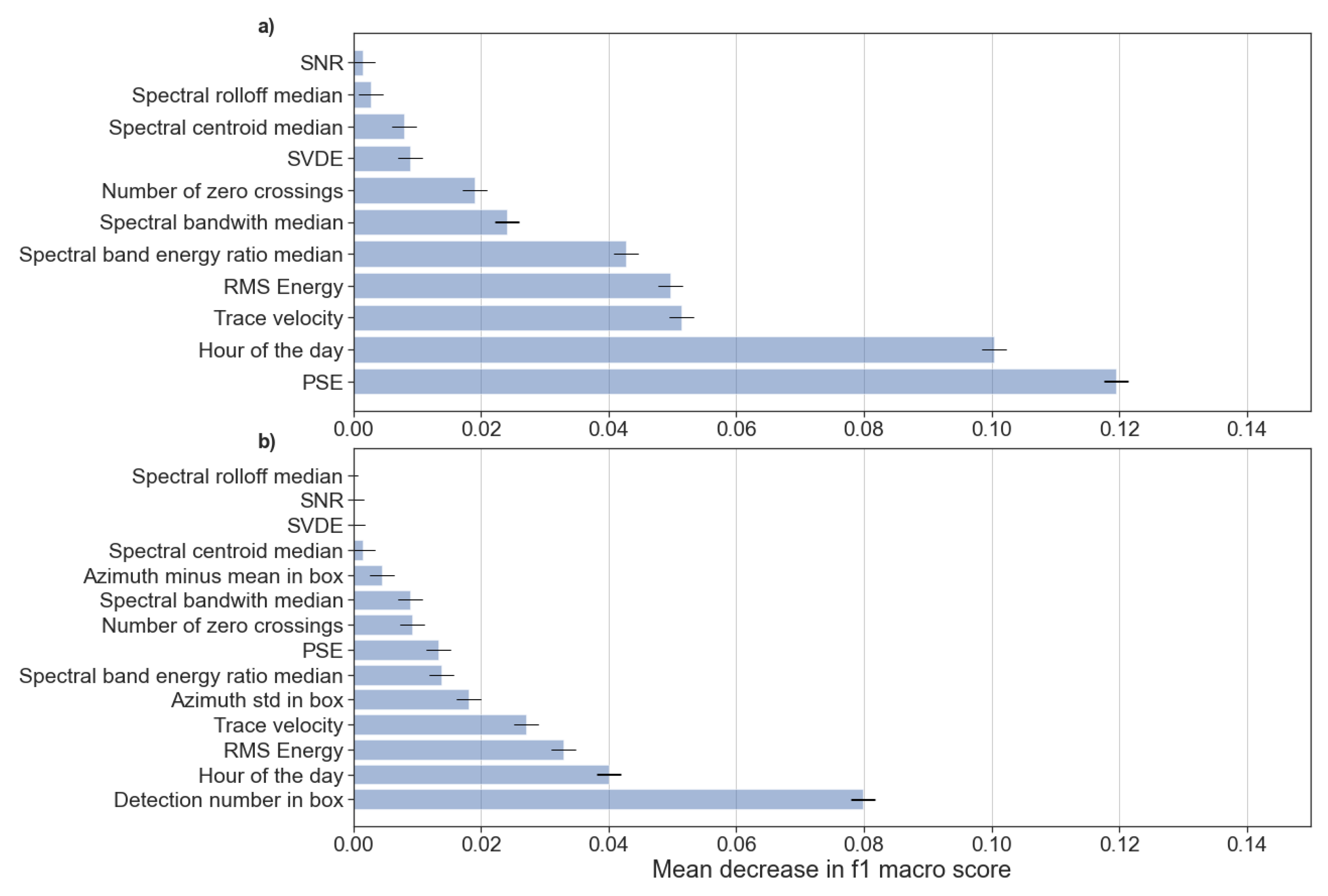
- Number of detections. This feature helps to distinguish between coherent noise sources (e.g., the power plant) and sources when multiple detections belong to the same “event” (e.g., storms) and between, for example, explosions which are usually solitary (or at least have only a few neighbors) on the time–azimuth diagram.
- The difference between the mean azimuth in the box and the detection’s azimuth. For the MPP, almost zero is expected for this value since it is not a moving source. For storms, this feature varies, depending on the movement of the storm relative to the station (visually, the angle on the time–azimuth domain). For quarry blasts, the value also varies. When no neighboring detections are present, basically this feature takes a value of zero, whereas a big difference from the mean is expected when there are adjacent detections.
- The standard deviation of the azimuths in the box. As with the previous feature, we expect larger values for storms and lower ones for MPP. For quarry blasts the same is true as with the foregoing feature.
2.4. Model Selection
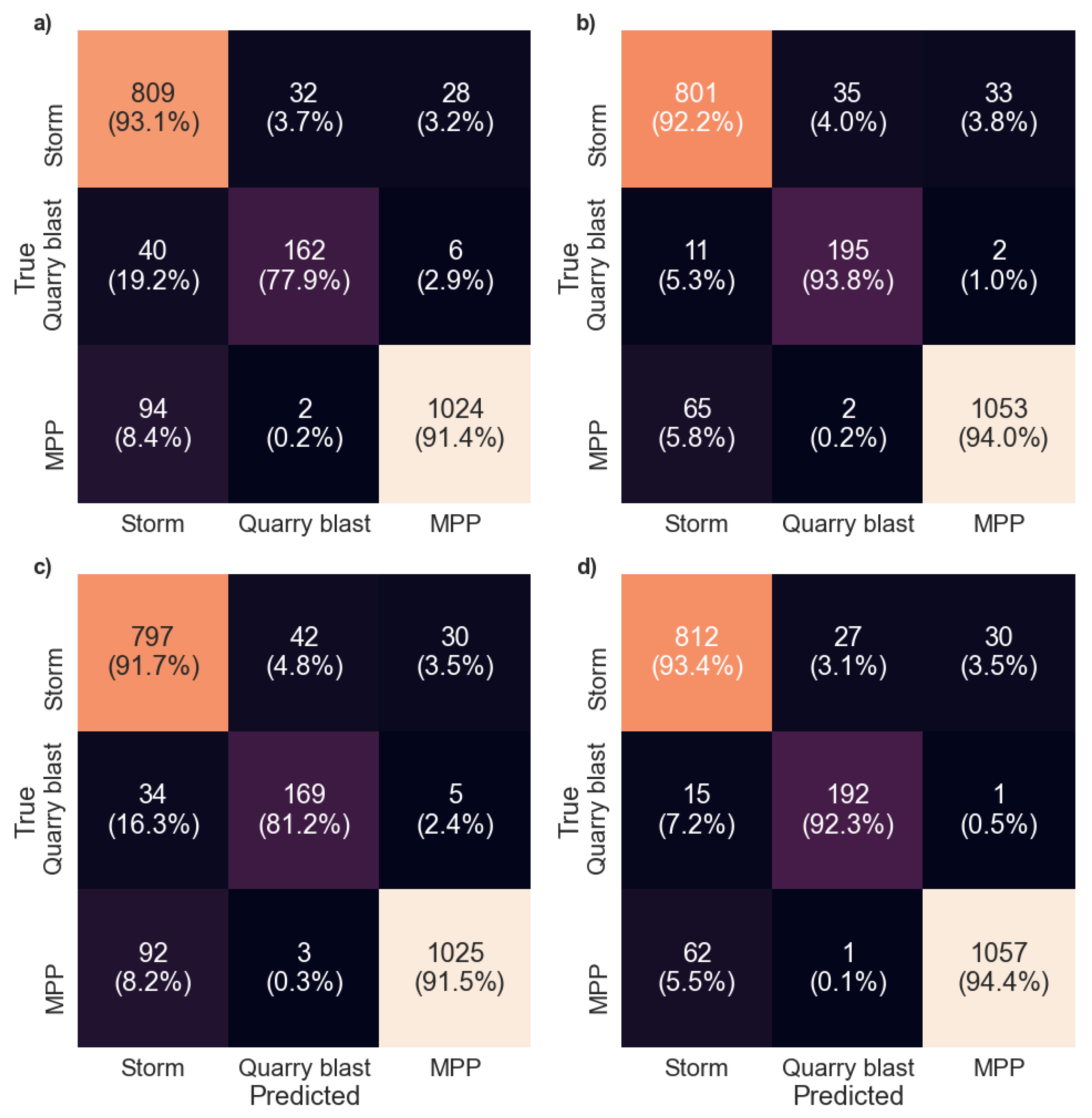
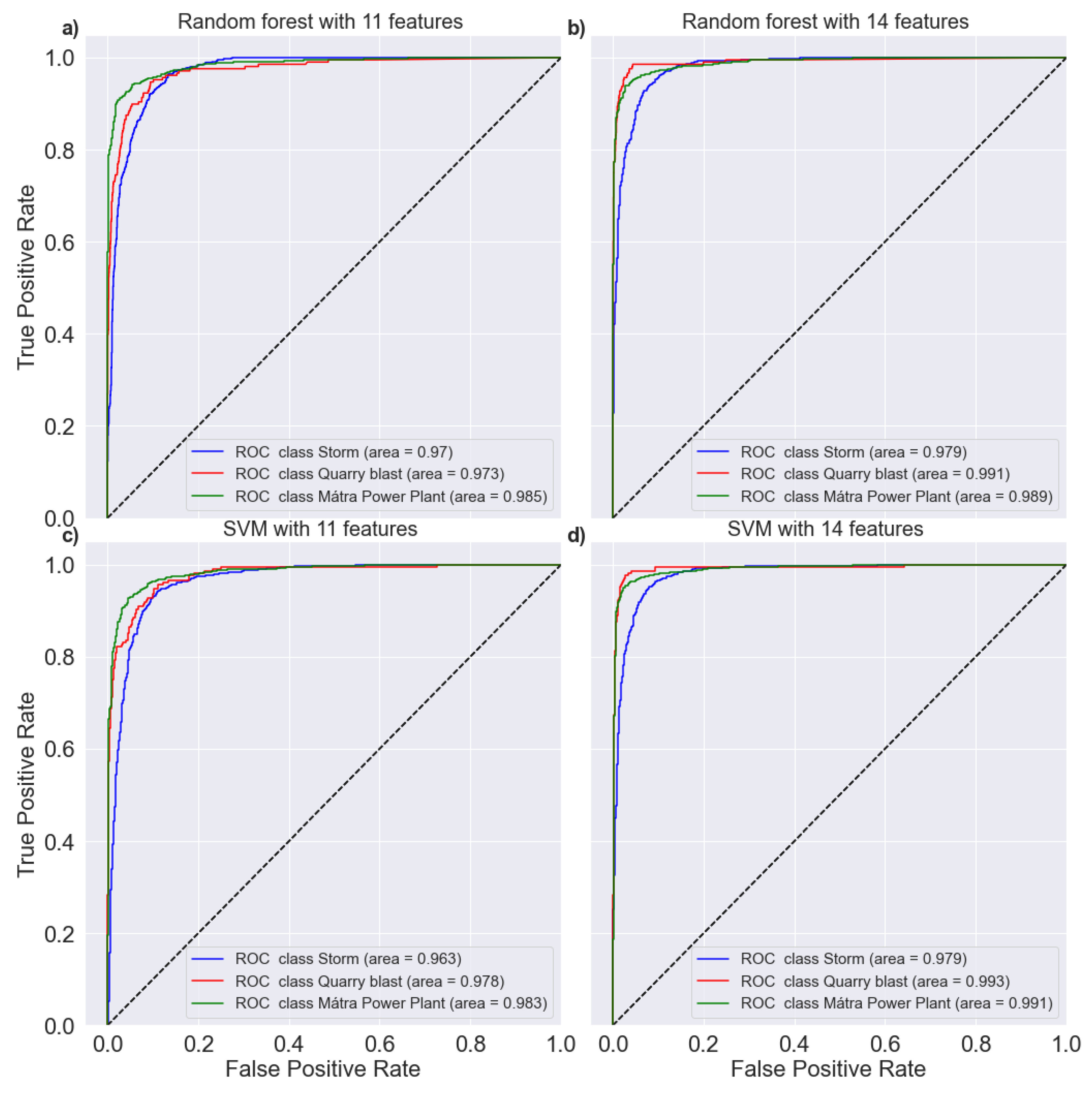
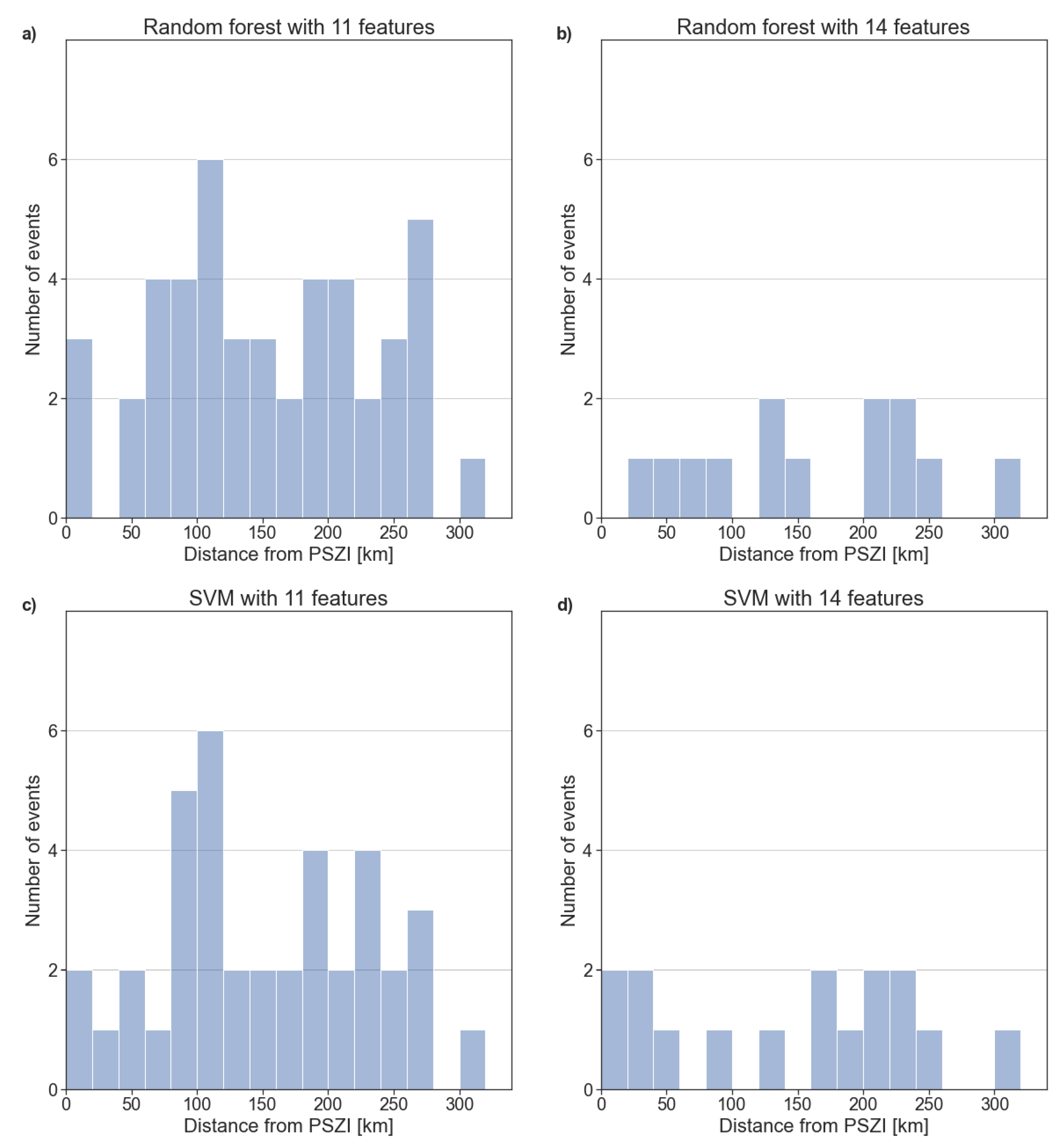
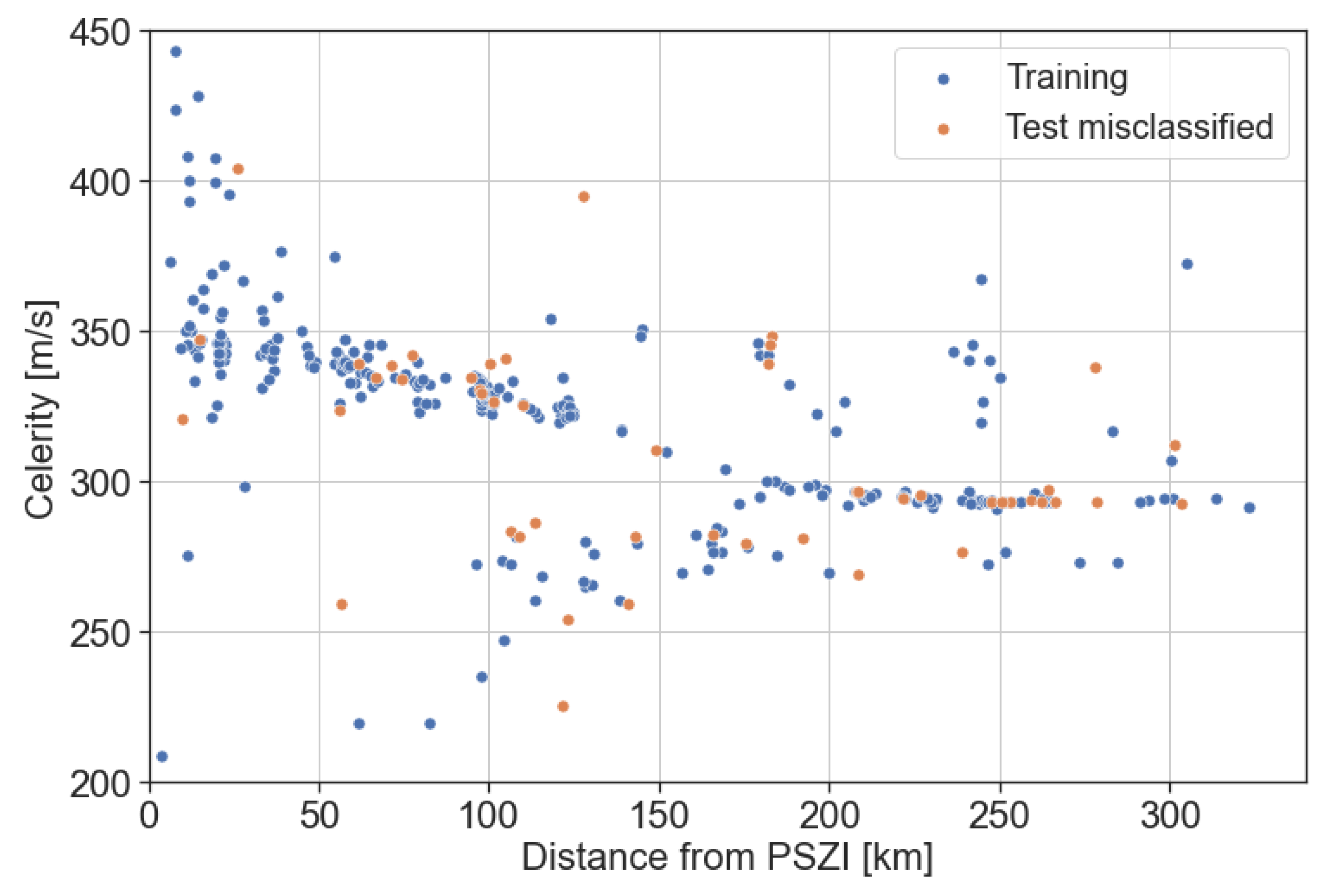
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blanc, E.; Ceranna, L.; Hauchecorne, A.; Charlton-Perez, A.; Marchetti, E.; Evers, L.G.; Kvaerna, T.; Lastovicka, J.; Eliasson, L.; Crosby, N.B.; et al. Toward an Improved Representation of Middle Atmospheric Dynamics Thanks to the ARISE Project. Surv. Geophys. 2018, 39, 171–225. [Google Scholar] [CrossRef]
- Blanc, E.; Pol, K.; Le Pichon, A.; Hauchecorne, A.; Keckhut, P.; Baumgarten, G.; Hildebrand, J.; Höffner, J.; Stober, G.; Hibbins, R.; et al. Middle Atmosphere Variability and Model Uncertainties as Investigated in the Framework of the ARISE Project. In Infrasound Monitoring for Atmospheric Studies, 2nd ed.; Le Pichon, A., Blanc, E., Hauchecorne, A., Eds.; Springer: Dordrech, The Netherlands, 2019; pp. 845–888. [Google Scholar]
- Bondár, I.; Šindelářová, T.; Ghica, D.; Mitterbauer, U.; Liashchuk, A.; Baše, J.; Chum, J.; Czanik, C.; Ionescu, C.; Neagoe, C.; et al. Central and Eastern European Infrasound Network: Contribution to infrasound monitoring. Geophys. J. Int. 2022, 230, 565–579. [Google Scholar] [CrossRef]
- Pilger, C.; Ceranna, L.; Ross, J.O.; Vergoz, J.; Le Pichon, A.; Brachet, N.; Blanc, E.; Kero, J.; Liszka, L.; Gibbons, S.; et al. The European Infrasound Bulletin. Pure Appl. Geophys. 2018, 175, 3619–3638. [Google Scholar] [CrossRef]
- Stump, B.W.; Hedlin, M.A.H.; Pearson, D.C.; Hsu, V. Characterization of mining explosions at regional distances: Implications with the International Monitoring System. Rev. Geophys. 2002, 40, 2-1–2-21. [Google Scholar] [CrossRef]
- Arrowsmith, S.; Hedlin, M.; Stump, B.; Arrowsmith, M. Infrasonic Signals from Large Mining Explosions. Bull. Seismol. Soc. Am. 2008, 98, 768–777. [Google Scholar] [CrossRef]
- Che, I.Y.; Park, J.; Kim, T.S.; Hayward, C.; Stump, B. On the use of a dense network of seismo-acoustic arrays for near-regional environmental monitoring. In Infrasound Monitoring for Atmospheric Studies, 2nd ed.; Le Pichon, A., Blanc, E., Hauchecorne, A., Eds.; Springer: Dordrecht, The Netrherlands, 2019; pp. 409–448. [Google Scholar]
- Czanik, C.; Kiszely, M.; Mónus, P.; Süle, B.; Bondár, I. Identification of Quarry Blasts Aided by Infrasound Data. Pure Appl. Geophys. 2021, 178, 2287–2300. [Google Scholar] [CrossRef]
- Belli, G.; Pace, E.; Marchetti, E. Detection and source parametrization of small-energy fireball events in Western Alps with ground-based infrasonic arrays. Geophys. J. Int. 2021, 225, 1518–1529. [Google Scholar] [CrossRef]
- Farges, T.; Blanc, E. Characteristics of infrasound from lightning and sprites near thunderstorm areas. J. Geophys. Res. Space Phys. 2010, 115, 1–17. [Google Scholar] [CrossRef]
- Chum, J.; Diendorfer, G.; Šindelářová, T.; Baše, J.; Hruška, F. Infrasound pulses from lightning and electrostatic field changes: Observation and discussion. J. Geophys. Res. Atmos. 2013, 118, 653–664. [Google Scholar] [CrossRef]
- Farges, T.; Hupe, P.; Le Pichon, A.; Ceranna, L.; Listowski, C.; Diawara, A. Infrasound Thunder Detections across 15 Years over Ivory Coast: Localization, Propagation, and Link with the Stratospheric Semi-Annual Oscillation. Atmosphere 2021, 12, 1188. [Google Scholar] [CrossRef]
- Israelsson, H. Correlation of waveforms from closely spaced regional events. Bull. Seismol. Soc. Am. 1990, 80, 2177–2193. [Google Scholar] [CrossRef]
- Harris, D.B. A waveform correlation method for identifying quarry explosions. Bull. Seismol. Soc. Am. 1991, 81, 2395–2418. [Google Scholar] [CrossRef]
- Gibbons, S.J.; Ringdal, F. The detection of low magnitude seismic events using array-based waveform correlation. Geophys. J. Int. 2006, 165, 149–166. [Google Scholar] [CrossRef]
- Kulichkov, S.N. Long-range propagation and scattering of low-frequency sound pulses in the middle atmosphere. Meteorol. Atmos. Phys. 2004, 85, 47–60. [Google Scholar] [CrossRef]
- Gibbons, S.; Asming, V.; Fedorov, A.; Fyen, J.; Kero, J.; Kozlovskaya, E.; Kvaerna, T.; Liszka, L.; Näsholm, S.P.; Raita, T.; et al. The European Arctic: A Laboratory for Seismoacoustic Studies. Seismol. Res. Lett. 2015, 86, 917–928. [Google Scholar] [CrossRef]
- Albert, S.; Linville, L. Benchmarking Current and Emerging Approaches to Infrasound Signal Classification. Seismol. Res. Lett. 2020, 91, 921–929. [Google Scholar] [CrossRef]
- Chai, C.; Ramirez, C.; Maceira, M.; Marcillo, O. Monitoring Operational States of a Nuclear Reactor Using Seismoacoustic Signatures and Machine Learning. Seismol. Res. Lett. 2022, 93, 1660–1672. [Google Scholar] [CrossRef]
- Brissaud, Q.; Näsholm, S.P.; Turquet, A.; Le Pichon, A. Predicting infrasound transmission loss using deep learning. Geophys. J. Int. 2023, 232, 274–286. [Google Scholar] [CrossRef]
- Ham F., M.; Park, S. A robust neural network classifier for infrasound events using multiple array data. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002. [Google Scholar]
- Chilo, J.; Lindblad, T.; Olsson, R.; Hansen, S. Comparison of Three Feature Extraction Techniques to Distinguish between Different 72 Infrasound Signals. In Progress in Pattern Recognition; Sameer, S., Maneesha, S., Eds.; Springer: London, UK, 2007; pp. 75–82. [Google Scholar]
- Liu, X.; Li, M.; Tang, W.; Wang, S.; Wu, X. A New Classification Method of Infrasound Events Using Hilbert-Huang Transform and Support Vector Machine. Math. Probl. Eng. 2014, 2014, e456818. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Li, M.; Liu, X.; Liu, X. Infrasound signal classification based on spectral entropy and support vector machine. Appl. Acoust. 2016, 113, 116–120. [Google Scholar] [CrossRef]
- Hungarian National Infrasound Network on Geofon Website. Available online: https://geofon.gfz-potsdam.de/waveform/archive/network.php?ncode=HN (accessed on 10 March 2023).
- Cansi, Y. An automatic seismic event processing for detection and location: The P.M.C.C. Method. Geophys. Res. Lett. 1995, 22, 1021–1024. [Google Scholar] [CrossRef]
- Šindelářová, T.; De Carlo, M.; Czanik, C.; Ghica, D.; Kozubek, M.; Podolská, K.; Baše, J.; Chum, J.; Mitterbauer, U. Infrasound signature of the post-tropical storm Ophelia at the Central and Eastern European Infrasound Network. J. Atmos. Solar-Terr. Phys. 2021, 217, 105603. [Google Scholar] [CrossRef]
- Kereszturi, A.; Barta, V.; Bondar, I.; Czanik, C.; Igaz, A.; Monus, P. Connecting ionospheric, optical, infrasound and seismic data from meteors over Hungary. J. Int. Meteor Organ. 2020, 48, 188–192. [Google Scholar]
- Kereszturi, Á.; Barta, V.; Bondár, I.; Czanik, C.; Igaz, A.; Mónus, P.; Rezes, D.; Szabados, L.; Pál, B.D. Review of synergic meteor observations: Linking the results from cameras, ionosondes, infrasound and seismic detectors. Mon. Notices R. Astron. Soc. 2021, 506, 3629–3640. [Google Scholar] [CrossRef]
- Pásztor, M.; Czanik, C.; Bondár, I. Exploiting infrasound detections to identify and track regional storms. In Proceedings of the EGU General Assembly Conference Abstracts, Online Conference, 19–30 April 2021. EGU21-6525. [Google Scholar]
- Pásztor, M.; Czanik, C.; Sindelarova, T.; Chum, J.; Bondár, I. Identifying and tracking regional storms with infrasound data. In Proceedings of the CTBTO Science and Technology Conference Book of Abstracts, Online Conference, 28 June–2 July 2021; p. P2.3-585. [Google Scholar]
- Bondár, I.; Czanik, C.; Czecze, B.; Kalmár, D.; Kiszely, M.; Mónus, P.; Süle, B. Hungarian Seismo-Acoustic Bulletin, 2017–2018; MTA CSFK GGI-Kövesligethy Radó Seismological Observatory: Budapest, Hugary, 2019. [Google Scholar]
- Bondár, I.; Czanik, C.; Czecze, B.; Kalmár, D.; Kiszely, M.; Mónus, P.; Pásztor, M.; Süle, B. Hungarian Seismo-Acoustic Bulletin, 2019–2020; MTA CSFK GGI-Kövesligethy Radó Seismological Observatory: Budapest, Hugary, 2020. [Google Scholar]
- Bondár, I.; Czanik, C.; Czecze, B.; Kalmár, D.; Kiszely, M.; Mónus, P.; Pásztor, M.; Süle, B. Hungarian Seismo-Acoustic Bulletin, 2020–2021; MTA CSFK GGI-Kövesligethy Radó Seismological Observatory: Budapest, Hugary, 2021. [Google Scholar]
- Bondár, I.; Pásztor, M.; Czanik, C.; Kiszely, M.; Mónus, P.; Süle, B. Hungarian Seismo-Acoustic Bulletin; 2019–2020; Bondár, I., Ed.; Institute for Geological and Geochemical Research, Research Centre for Astronomy and Earth Sciences: Budapest, Hungary; ELKH Budapest and Kövesligethy Radó Seismological Observatory, Institute of Earth Physics and Space Science, ELKH: Sopron, Hungary, 2022. [Google Scholar]
- Bondár, I.; Storchak, D. Improved location procedures at the International Seismological Centre. Geophys. J. Int. 2011, 186, 1220–1244. [Google Scholar] [CrossRef]
- Blitzortung. Available online: https://www.blitzortung.org (accessed on 11 March 2023).
- Bowman, H.S.; Bedard, A.J. Observations of Infrasound and Subsonic Disturbances Related to Severe Weather. Geophys. J. Int. 1971, 26, 215–242. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; Roumeliotis, R., Tache, N., Eds.; O’Reilly Media: North Sepastopol, CA, USA, 2019. [Google Scholar]
- Krishnamurthi, R.; Dhanalekshmi, G.; Adarsh, K. Chapter 10—Using Wavelet Transformation for Acoustic Signal Processing in Heavy Vehicle Detection and Classification. In Autonomous and Connected Heavy Vehicle Technology; Krishnamurthi, R., Kumar, A., Gill, S.S., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 199–209. [Google Scholar] [CrossRef]
- Inouye, T.; Shinosaki, K.; Sakamoto, H.; Toi, S.; Ukai, S.; Iyama, A.; Katsuda, Y.; Hirano, M. Quantification of EEG Irregularity by Use of the Entropy of the Power Spectrum. Electroencephalogr. Clin. Neurophysiol. 1991, 79, 204–210. [Google Scholar] [CrossRef]
- Roberts, S.J.; Penny, W.; Rezek, I. Temporal and Spatial Complexity Measures for Electroencephalogram Based Brain-Computer. Med. Biol. Eng. Comput. 1999, 39, 93–98. [Google Scholar] [CrossRef] [PubMed]
- Bao, F.S.; Liu, X.; Zhang, C. PyEEG: An Open Source Python Module for EEG/MEG Feature Extraction. Comput. Intell. Neurosci. 2011, 2011, 406391. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.; Ho, L.S.; Al-Ansari, N.; Le, H.V.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Math. Probl. Eng. 2021, 2021, 4832864. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kulichkov, S.N. On infrasonic arrivals in the zone of geometric shadow at long distances from surface explosions. In Proceedings of the Ninth Annual Symposium on Long-Range Propagation, Oxford, MS, USA, 14–15 September 2000. [Google Scholar]
- Negraru, P.T.; Golden, P.; Herrin, E.T. Infrasound Propagation in the “Zone of Silence”. Seismol. Res. Lett. 2010, 81, 614–624. [Google Scholar] [CrossRef]
- Nippress, A.; Green, N.D.; Marcillo, E.O.; Arrowsmith, J.S. Generating regional infrasound celerity-range models using ground-truth information and the implications for event location. Geophys. J. Int. 2014, 197, 1154–1165. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformation | Parameter Range | Probability |
|---|---|---|
| Gaussian noise | 0.01–0.05 | 0.5 |
| Time shift | 0.0–0.3 | 1 |
| Time domain mask | 0.0–0.03 | 1 |
| Frequency domain mask | 0.0–0.03 | 1 |
| Storm | Quarry Blast | MPP | |
|---|---|---|---|
| Training | 3962 (75%) | 568 (58%) | 5334 (75%) |
| Validation | 834 (15%) | 203 (21%) | 1161 (15%) |
| Test | 869 (15%) | 208 (21%) | 1120 (15%) |
| Parameter | Values |
|---|---|
| Number of trees | 20, 30, 40, 50, 60, 80 |
| Minimum samples per leaf | 2, 4, 8, 12, 16, 20, 24 |
| Minimum samples per split | 2, 4, 8, 12, 16, 20, 24 |
| Maximum depth | 10, 20, 30, 40, 50 |
| Maximum features | all, log2, square root |
| Parameter | Values |
|---|---|
| C | 1, 2, 3, 4, 5, 10, 20, 50, 100, 200, 500, 1000 |
| kernel | Radial Basis Function |
| scale, auto |
| Training CV Mean f1 Score | Training CV f1 Score Standard Deviation | Validation f1 Score | Test f1 Score | |
|---|---|---|---|---|
| Random forest with 11 features | 0.84 | 0.009 | 0.89 | 0.88 |
| Random forest with 14 features | 0.86 | 0.005 | 0.92 | 0.92 |
| SVM with 11 features | 0.83 | 0.016 | 0.88 | 0.88 |
| SVM with 14 features | 0.88 | 0.012 | 0.93 | 0.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pásztor, M.; Czanik, C.; Bondár, I. A Single Array Approach for Infrasound Signal Discrimination from Quarry Blasts via Machine Learning. Remote Sens. 2023, 15, 1657. https://doi.org/10.3390/rs15061657
Pásztor M, Czanik C, Bondár I. A Single Array Approach for Infrasound Signal Discrimination from Quarry Blasts via Machine Learning. Remote Sensing. 2023; 15(6):1657. https://doi.org/10.3390/rs15061657
Chicago/Turabian StylePásztor, Marcell, Csenge Czanik, and István Bondár. 2023. "A Single Array Approach for Infrasound Signal Discrimination from Quarry Blasts via Machine Learning" Remote Sensing 15, no. 6: 1657. https://doi.org/10.3390/rs15061657
APA StylePásztor, M., Czanik, C., & Bondár, I. (2023). A Single Array Approach for Infrasound Signal Discrimination from Quarry Blasts via Machine Learning. Remote Sensing, 15(6), 1657. https://doi.org/10.3390/rs15061657